

Upload pancreas_ct_dints_segmentation version 0.5.1
Browse files- .gitattributes +1 -0
- LICENSE +201 -0
- configs/evaluate.yaml +65 -0
- configs/inference.yaml +130 -0
- configs/inference_trt.yaml +9 -0
- configs/logging.conf +21 -0
- configs/metadata.json +109 -0
- configs/multi_gpu_train.yaml +54 -0
- configs/search.yaml +275 -0
- configs/train.yaml +355 -0
- docs/README.md +194 -0
- docs/data_license.txt +6 -0
- models/model.pt +3 -0
- models/model.ts +3 -0
- models/search_code_18590.pt +3 -0
- scripts/__init__.py +10 -0
- scripts/prepare_datalist.py +58 -0
- scripts/search.py +517 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
models/model.ts filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
configs/evaluate.yaml
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
validate#postprocessing:
|
| 3 |
+
_target_: Compose
|
| 4 |
+
transforms:
|
| 5 |
+
- _target_: Activationsd
|
| 6 |
+
keys: pred
|
| 7 |
+
softmax: true
|
| 8 |
+
- _target_: Invertd
|
| 9 |
+
keys:
|
| 10 |
+
- pred
|
| 11 |
+
- label
|
| 12 |
+
transform: "@validate#preprocessing"
|
| 13 |
+
orig_keys: image
|
| 14 |
+
meta_key_postfix: meta_dict
|
| 15 |
+
nearest_interp:
|
| 16 |
+
- false
|
| 17 |
+
- true
|
| 18 |
+
to_tensor: true
|
| 19 |
+
- _target_: AsDiscreted
|
| 20 |
+
keys:
|
| 21 |
+
- pred
|
| 22 |
+
- label
|
| 23 |
+
argmax:
|
| 24 |
+
- true
|
| 25 |
+
- false
|
| 26 |
+
to_onehot: 3
|
| 27 |
+
- _target_: CopyItemsd
|
| 28 |
+
keys: "pred"
|
| 29 |
+
times: 1
|
| 30 |
+
names: "pred_save"
|
| 31 |
+
- _target_: AsDiscreted
|
| 32 |
+
keys:
|
| 33 |
+
- pred_save
|
| 34 |
+
argmax:
|
| 35 |
+
- true
|
| 36 |
+
- _target_: SaveImaged
|
| 37 |
+
keys: pred_save
|
| 38 |
+
meta_keys: pred_meta_dict
|
| 39 |
+
output_dir: "@output_dir"
|
| 40 |
+
resample: false
|
| 41 |
+
squeeze_end_dims: true
|
| 42 |
+
validate#dataset:
|
| 43 |
+
_target_: Dataset
|
| 44 |
+
data: "@val_datalist"
|
| 45 |
+
transform: "@validate#preprocessing"
|
| 46 |
+
validate#handlers:
|
| 47 |
+
- _target_: CheckpointLoader
|
| 48 |
+
load_path: "$@ckpt_dir + '/model.pt'"
|
| 49 |
+
load_dict:
|
| 50 |
+
model: "@network"
|
| 51 |
+
- _target_: StatsHandler
|
| 52 |
+
iteration_log: false
|
| 53 |
+
- _target_: MetricsSaver
|
| 54 |
+
save_dir: "@output_dir"
|
| 55 |
+
metrics:
|
| 56 |
+
- val_mean_dice
|
| 57 |
+
- val_acc
|
| 58 |
+
metric_details:
|
| 59 |
+
- val_mean_dice
|
| 60 |
+
batch_transform: "$monai.handlers.from_engine(['image_meta_dict'])"
|
| 61 |
+
summary_ops: "*"
|
| 62 |
+
initialize:
|
| 63 |
+
- "$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 64 |
+
run:
|
| 65 |
+
- "$@validate#evaluator.run()"
|
configs/inference.yaml
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
imports:
|
| 3 |
+
- "$import glob"
|
| 4 |
+
- "$import numpy"
|
| 5 |
+
- "$import os"
|
| 6 |
+
input_channels: 1
|
| 7 |
+
output_classes: 3
|
| 8 |
+
arch_ckpt_path: "$@bundle_root + '/models/search_code_18590.pt'"
|
| 9 |
+
arch_ckpt: "$torch.load(@arch_ckpt_path, map_location=torch.device('cuda'))"
|
| 10 |
+
bundle_root: "."
|
| 11 |
+
image_key: "image"
|
| 12 |
+
output_dir: "$@bundle_root + '/eval'"
|
| 13 |
+
output_ext: ".nii.gz"
|
| 14 |
+
output_dtype: "$numpy.float32"
|
| 15 |
+
output_postfix: "trans"
|
| 16 |
+
separate_folder: true
|
| 17 |
+
load_pretrain: true
|
| 18 |
+
dataset_dir: "/workspace/data/msd/Task07_Pancreas"
|
| 19 |
+
data_list_file_path: "$@bundle_root + '/configs/dataset_0.json'"
|
| 20 |
+
datalist: "$monai.data.load_decathlon_datalist(@data_list_file_path, data_list_key='testing',
|
| 21 |
+
base_dir=@dataset_dir)"
|
| 22 |
+
device: "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')"
|
| 23 |
+
dints_space:
|
| 24 |
+
_target_: monai.networks.nets.TopologyInstance
|
| 25 |
+
channel_mul: 1
|
| 26 |
+
num_blocks: 12
|
| 27 |
+
num_depths: 4
|
| 28 |
+
use_downsample: true
|
| 29 |
+
arch_code:
|
| 30 |
+
- "$@arch_ckpt['arch_code_a']"
|
| 31 |
+
- "$@arch_ckpt['arch_code_c']"
|
| 32 |
+
device: "$torch.device('cuda')"
|
| 33 |
+
network_def:
|
| 34 |
+
_target_: monai.networks.nets.DiNTS
|
| 35 |
+
dints_space: "@dints_space"
|
| 36 |
+
in_channels: "@input_channels"
|
| 37 |
+
num_classes: "@output_classes"
|
| 38 |
+
use_downsample: true
|
| 39 |
+
node_a: "$torch.from_numpy(@arch_ckpt['node_a'])"
|
| 40 |
+
network: "$@network_def.to(@device)"
|
| 41 |
+
preprocessing:
|
| 42 |
+
_target_: Compose
|
| 43 |
+
transforms:
|
| 44 |
+
- _target_: LoadImaged
|
| 45 |
+
keys: "@image_key"
|
| 46 |
+
- _target_: EnsureChannelFirstd
|
| 47 |
+
keys: "@image_key"
|
| 48 |
+
- _target_: Orientationd
|
| 49 |
+
keys: "@image_key"
|
| 50 |
+
axcodes: RAS
|
| 51 |
+
- _target_: Spacingd
|
| 52 |
+
keys: "@image_key"
|
| 53 |
+
pixdim:
|
| 54 |
+
- 1
|
| 55 |
+
- 1
|
| 56 |
+
- 1
|
| 57 |
+
mode: bilinear
|
| 58 |
+
- _target_: ScaleIntensityRanged
|
| 59 |
+
keys: "@image_key"
|
| 60 |
+
a_min: -87
|
| 61 |
+
a_max: 199
|
| 62 |
+
b_min: 0
|
| 63 |
+
b_max: 1
|
| 64 |
+
clip: true
|
| 65 |
+
- _target_: EnsureTyped
|
| 66 |
+
keys: "@image_key"
|
| 67 |
+
dataset:
|
| 68 |
+
_target_: Dataset
|
| 69 |
+
data: "@datalist"
|
| 70 |
+
transform: "@preprocessing"
|
| 71 |
+
dataloader:
|
| 72 |
+
_target_: DataLoader
|
| 73 |
+
dataset: "@dataset"
|
| 74 |
+
batch_size: 1
|
| 75 |
+
shuffle: false
|
| 76 |
+
num_workers: 4
|
| 77 |
+
inferer:
|
| 78 |
+
_target_: SlidingWindowInferer
|
| 79 |
+
roi_size:
|
| 80 |
+
- 96
|
| 81 |
+
- 96
|
| 82 |
+
- 96
|
| 83 |
+
sw_batch_size: 4
|
| 84 |
+
overlap: 0.625
|
| 85 |
+
postprocessing:
|
| 86 |
+
_target_: Compose
|
| 87 |
+
transforms:
|
| 88 |
+
- _target_: Activationsd
|
| 89 |
+
keys: pred
|
| 90 |
+
softmax: true
|
| 91 |
+
- _target_: Invertd
|
| 92 |
+
keys: pred
|
| 93 |
+
transform: "@preprocessing"
|
| 94 |
+
orig_keys: "@image_key"
|
| 95 |
+
meta_key_postfix: meta_dict
|
| 96 |
+
nearest_interp: false
|
| 97 |
+
to_tensor: true
|
| 98 |
+
- _target_: AsDiscreted
|
| 99 |
+
keys: pred
|
| 100 |
+
argmax: true
|
| 101 |
+
- _target_: SaveImaged
|
| 102 |
+
keys: pred
|
| 103 |
+
meta_keys: pred_meta_dict
|
| 104 |
+
output_dir: "@output_dir"
|
| 105 |
+
output_ext: "@output_ext"
|
| 106 |
+
output_dtype: "@output_dtype"
|
| 107 |
+
output_postfix: "@output_postfix"
|
| 108 |
+
separate_folder: "@separate_folder"
|
| 109 |
+
handlers:
|
| 110 |
+
- _target_: StatsHandler
|
| 111 |
+
iteration_log: false
|
| 112 |
+
evaluator:
|
| 113 |
+
_target_: SupervisedEvaluator
|
| 114 |
+
device: "@device"
|
| 115 |
+
val_data_loader: "@dataloader"
|
| 116 |
+
network: "@network"
|
| 117 |
+
inferer: "@inferer"
|
| 118 |
+
postprocessing: "@postprocessing"
|
| 119 |
+
val_handlers: "@handlers"
|
| 120 |
+
amp: true
|
| 121 |
+
checkpointloader:
|
| 122 |
+
_target_: CheckpointLoader
|
| 123 |
+
load_path: "$@bundle_root + '/models/model.pt'"
|
| 124 |
+
load_dict:
|
| 125 |
+
model: "@network"
|
| 126 |
+
initialize:
|
| 127 |
+
- "$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 128 |
+
- "$@checkpointloader(@evaluator) if @load_pretrain else None"
|
| 129 |
+
run:
|
| 130 |
+
- "[email protected]()"
|
configs/inference_trt.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
imports:
|
| 3 |
+
- "$import glob"
|
| 4 |
+
- "$import os"
|
| 5 |
+
- "$import torch_tensorrt"
|
| 6 |
+
network_def: "$torch.jit.load(@bundle_root + '/models/model_trt.ts')"
|
| 7 |
+
evaluator#amp: false
|
| 8 |
+
initialize:
|
| 9 |
+
- "$setattr(torch.backends.cudnn, 'benchmark', True)"
|
configs/logging.conf
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[loggers]
|
| 2 |
+
keys=root
|
| 3 |
+
|
| 4 |
+
[handlers]
|
| 5 |
+
keys=consoleHandler
|
| 6 |
+
|
| 7 |
+
[formatters]
|
| 8 |
+
keys=fullFormatter
|
| 9 |
+
|
| 10 |
+
[logger_root]
|
| 11 |
+
level=INFO
|
| 12 |
+
handlers=consoleHandler
|
| 13 |
+
|
| 14 |
+
[handler_consoleHandler]
|
| 15 |
+
class=StreamHandler
|
| 16 |
+
level=INFO
|
| 17 |
+
formatter=fullFormatter
|
| 18 |
+
args=(sys.stdout,)
|
| 19 |
+
|
| 20 |
+
[formatter_fullFormatter]
|
| 21 |
+
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
configs/metadata.json
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20240725.json",
|
| 3 |
+
"version": "0.5.1",
|
| 4 |
+
"changelog": {
|
| 5 |
+
"0.5.1": "update to huggingface hosting",
|
| 6 |
+
"0.5.0": "use monai 1.4 and update large files",
|
| 7 |
+
"0.4.9": "update to use monai 1.3.1",
|
| 8 |
+
"0.4.8": "add load_pretrain flag for infer",
|
| 9 |
+
"0.4.7": "add missing yaml lib requirement in metadata",
|
| 10 |
+
"0.4.6": "add checkpoint loader for infer",
|
| 11 |
+
"0.4.5": "set image_only to False",
|
| 12 |
+
"0.4.4": "update the benchmark results of TensorRT",
|
| 13 |
+
"0.4.3": "add support for TensorRT conversion and inference",
|
| 14 |
+
"0.4.2": "update search function to match monai 1.2",
|
| 15 |
+
"0.4.1": "fix the wrong GPU index issue of multi-node",
|
| 16 |
+
"0.4.0": "remove error dollar symbol in readme",
|
| 17 |
+
"0.3.9": "add cpu ram requirement in readme",
|
| 18 |
+
"0.3.8": "add non-deterministic note",
|
| 19 |
+
"0.3.7": "re-train model with updated dints implementation",
|
| 20 |
+
"0.3.6": "black autofix format and add name tag",
|
| 21 |
+
"0.3.5": "restructure readme to match updated template",
|
| 22 |
+
"0.3.4": "correct typos",
|
| 23 |
+
"0.3.3": "update learning rate and readme",
|
| 24 |
+
"0.3.2": "update to use monai 1.0.1",
|
| 25 |
+
"0.3.1": "fix license Copyright error",
|
| 26 |
+
"0.3.0": "update license files",
|
| 27 |
+
"0.2.0": "unify naming",
|
| 28 |
+
"0.1.1": "fix data type issue in searching/training configurations",
|
| 29 |
+
"0.1.0": "complete the model package",
|
| 30 |
+
"0.0.1": "initialize the model package structure"
|
| 31 |
+
},
|
| 32 |
+
"monai_version": "1.4.0",
|
| 33 |
+
"pytorch_version": "2.4.0",
|
| 34 |
+
"numpy_version": "1.24.4",
|
| 35 |
+
"required_packages_version": {
|
| 36 |
+
"fire": "0.6.0",
|
| 37 |
+
"nibabel": "5.2.1",
|
| 38 |
+
"pytorch-ignite": "0.4.11",
|
| 39 |
+
"PyYAML": "6.0.1",
|
| 40 |
+
"scikit-learn": "1.5.1",
|
| 41 |
+
"tensorboard": "2.17.0"
|
| 42 |
+
},
|
| 43 |
+
"supported_apps": {},
|
| 44 |
+
"name": "Pancreas CT DiNTS segmentation",
|
| 45 |
+
"task": "Neural architecture search on pancreas CT segmentation",
|
| 46 |
+
"description": "Searched architectures for volumetric (3D) segmentation of the pancreas from CT image",
|
| 47 |
+
"authors": "MONAI team",
|
| 48 |
+
"copyright": "Copyright (c) MONAI Consortium",
|
| 49 |
+
"data_source": "Task07_Pancreas.tar from http://medicaldecathlon.com/",
|
| 50 |
+
"data_type": "nibabel",
|
| 51 |
+
"image_classes": "single channel data, intensity scaled to [0, 1]",
|
| 52 |
+
"label_classes": "single channel data, 1 is pancreas, 2 is pancreatic tumor, 0 is everything else",
|
| 53 |
+
"pred_classes": "3 channels OneHot data, channel 1 is pancreas, channel 2 is pancreatic tumor, channel 0 is background",
|
| 54 |
+
"eval_metrics": {
|
| 55 |
+
"mean_dice": 0.62
|
| 56 |
+
},
|
| 57 |
+
"intended_use": "This is an example, not to be used for diagnostic purposes",
|
| 58 |
+
"references": [
|
| 59 |
+
"He, Y., Yang, D., Roth, H., Zhao, C. and Xu, D., 2021. Dints: Differentiable neural network topology search for 3d medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5841-5850)."
|
| 60 |
+
],
|
| 61 |
+
"network_data_format": {
|
| 62 |
+
"inputs": {
|
| 63 |
+
"image": {
|
| 64 |
+
"type": "image",
|
| 65 |
+
"format": "hounsfield",
|
| 66 |
+
"modality": "CT",
|
| 67 |
+
"num_channels": 1,
|
| 68 |
+
"spatial_shape": [
|
| 69 |
+
96,
|
| 70 |
+
96,
|
| 71 |
+
96
|
| 72 |
+
],
|
| 73 |
+
"dtype": "float32",
|
| 74 |
+
"value_range": [
|
| 75 |
+
0,
|
| 76 |
+
1
|
| 77 |
+
],
|
| 78 |
+
"is_patch_data": true,
|
| 79 |
+
"channel_def": {
|
| 80 |
+
"0": "image"
|
| 81 |
+
}
|
| 82 |
+
}
|
| 83 |
+
},
|
| 84 |
+
"outputs": {
|
| 85 |
+
"pred": {
|
| 86 |
+
"type": "image",
|
| 87 |
+
"format": "segmentation",
|
| 88 |
+
"num_channels": 3,
|
| 89 |
+
"spatial_shape": [
|
| 90 |
+
96,
|
| 91 |
+
96,
|
| 92 |
+
96
|
| 93 |
+
],
|
| 94 |
+
"dtype": "float32",
|
| 95 |
+
"value_range": [
|
| 96 |
+
0,
|
| 97 |
+
1,
|
| 98 |
+
2
|
| 99 |
+
],
|
| 100 |
+
"is_patch_data": true,
|
| 101 |
+
"channel_def": {
|
| 102 |
+
"0": "background",
|
| 103 |
+
"1": "pancreas",
|
| 104 |
+
"2": "pancreatic tumor"
|
| 105 |
+
}
|
| 106 |
+
}
|
| 107 |
+
}
|
| 108 |
+
}
|
| 109 |
+
}
|
configs/multi_gpu_train.yaml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
device: "$torch.device('cuda:' + os.environ['LOCAL_RANK'])"
|
| 3 |
+
network:
|
| 4 |
+
_target_: torch.nn.parallel.DistributedDataParallel
|
| 5 |
+
module: "$@network_def.to(@device)"
|
| 6 |
+
find_unused_parameters: true
|
| 7 |
+
device_ids:
|
| 8 |
+
- "@device"
|
| 9 |
+
optimizer#lr: "$0.025*dist.get_world_size()"
|
| 10 |
+
lr_scheduler#step_size: "$80*dist.get_world_size()"
|
| 11 |
+
train#handlers:
|
| 12 |
+
- _target_: LrScheduleHandler
|
| 13 |
+
lr_scheduler: "@lr_scheduler"
|
| 14 |
+
print_lr: true
|
| 15 |
+
- _target_: ValidationHandler
|
| 16 |
+
validator: "@validate#evaluator"
|
| 17 |
+
epoch_level: true
|
| 18 |
+
interval: "$10*dist.get_world_size()"
|
| 19 |
+
- _target_: StatsHandler
|
| 20 |
+
tag_name: train_loss
|
| 21 |
+
output_transform: "$monai.handlers.from_engine(['loss'], first=True)"
|
| 22 |
+
- _target_: TensorBoardStatsHandler
|
| 23 |
+
log_dir: "@output_dir"
|
| 24 |
+
tag_name: train_loss
|
| 25 |
+
output_transform: "$monai.handlers.from_engine(['loss'], first=True)"
|
| 26 |
+
train#trainer#max_epochs: "$400*dist.get_world_size()"
|
| 27 |
+
train#trainer#train_handlers: "$@train#handlers[: -2 if dist.get_rank() > 0 else None]"
|
| 28 |
+
validate#evaluator#val_handlers: "$None if dist.get_rank() > 0 else @validate#handlers"
|
| 29 |
+
initialize:
|
| 30 |
+
- "$import torch.distributed as dist"
|
| 31 |
+
- "$dist.is_initialized() or dist.init_process_group(backend='nccl')"
|
| 32 |
+
- "$torch.cuda.set_device(@device)"
|
| 33 |
+
- "$monai.utils.set_determinism(seed=123)"
|
| 34 |
+
- "$setattr(torch.backends.cudnn, 'benchmark', True)"
|
| 35 |
+
run:
|
| 36 |
+
- "$@train#trainer.run()"
|
| 37 |
+
finalize:
|
| 38 |
+
- "$dist.is_initialized() and dist.destroy_process_group()"
|
| 39 |
+
train_data_partition: "$monai.data.partition_dataset(data=@train_datalist, num_partitions=dist.get_world_size(),
|
| 40 |
+
shuffle=True, even_divisible=True,)[dist.get_rank()]"
|
| 41 |
+
train#dataset:
|
| 42 |
+
_target_: CacheDataset
|
| 43 |
+
data: "@train_data_partition"
|
| 44 |
+
transform: "@train#preprocessing"
|
| 45 |
+
cache_rate: 1
|
| 46 |
+
num_workers: 4
|
| 47 |
+
val_data_partition: "$monai.data.partition_dataset(data=@val_datalist, num_partitions=dist.get_world_size(),
|
| 48 |
+
shuffle=False, even_divisible=False,)[dist.get_rank()]"
|
| 49 |
+
validate#dataset:
|
| 50 |
+
_target_: CacheDataset
|
| 51 |
+
data: "@val_data_partition"
|
| 52 |
+
transform: "@validate#preprocessing"
|
| 53 |
+
cache_rate: 1
|
| 54 |
+
num_workers: 4
|
configs/search.yaml
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
imports:
|
| 3 |
+
- "$from scipy import ndimage"
|
| 4 |
+
arch_ckpt_path: models
|
| 5 |
+
amp: true
|
| 6 |
+
data_file_base_dir: /workspace/data/msd/Task07_Pancreas
|
| 7 |
+
data_list_file_path: configs/dataset_0.json
|
| 8 |
+
determ: true
|
| 9 |
+
input_channels: 1
|
| 10 |
+
learning_rate: 0.025
|
| 11 |
+
learning_rate_arch: 0.001
|
| 12 |
+
learning_rate_milestones:
|
| 13 |
+
- 0.4
|
| 14 |
+
- 0.8
|
| 15 |
+
num_images_per_batch: 1
|
| 16 |
+
num_epochs: 1430
|
| 17 |
+
num_epochs_per_validation: 100
|
| 18 |
+
num_epochs_warmup: 715
|
| 19 |
+
num_patches_per_image: 1
|
| 20 |
+
num_sw_batch_size: 6
|
| 21 |
+
output_classes: 3
|
| 22 |
+
overlap_ratio: 0.625
|
| 23 |
+
patch_size:
|
| 24 |
+
- 96
|
| 25 |
+
- 96
|
| 26 |
+
- 96
|
| 27 |
+
patch_size_valid:
|
| 28 |
+
- 96
|
| 29 |
+
- 96
|
| 30 |
+
- 96
|
| 31 |
+
ram_cost_factor: 0.8
|
| 32 |
+
image_key: image
|
| 33 |
+
label_key: label
|
| 34 |
+
transform_train:
|
| 35 |
+
_target_: Compose
|
| 36 |
+
transforms:
|
| 37 |
+
- _target_: LoadImaged
|
| 38 |
+
keys:
|
| 39 |
+
- "@image_key"
|
| 40 |
+
- "@label_key"
|
| 41 |
+
- _target_: EnsureChannelFirstd
|
| 42 |
+
keys:
|
| 43 |
+
- "@image_key"
|
| 44 |
+
- "@label_key"
|
| 45 |
+
- _target_: Orientationd
|
| 46 |
+
keys:
|
| 47 |
+
- "@image_key"
|
| 48 |
+
- "@label_key"
|
| 49 |
+
axcodes: RAS
|
| 50 |
+
- _target_: Spacingd
|
| 51 |
+
keys:
|
| 52 |
+
- "@image_key"
|
| 53 |
+
- "@label_key"
|
| 54 |
+
pixdim:
|
| 55 |
+
- 1
|
| 56 |
+
- 1
|
| 57 |
+
- 1
|
| 58 |
+
mode:
|
| 59 |
+
- bilinear
|
| 60 |
+
- nearest
|
| 61 |
+
align_corners:
|
| 62 |
+
- true
|
| 63 |
+
- true
|
| 64 |
+
- _target_: CastToTyped
|
| 65 |
+
keys: "@image_key"
|
| 66 |
+
dtype: "$torch.float32"
|
| 67 |
+
- _target_: ScaleIntensityRanged
|
| 68 |
+
keys: "@image_key"
|
| 69 |
+
a_min: -87
|
| 70 |
+
a_max: 199
|
| 71 |
+
b_min: 0
|
| 72 |
+
b_max: 1
|
| 73 |
+
clip: true
|
| 74 |
+
- _target_: CastToTyped
|
| 75 |
+
keys:
|
| 76 |
+
- "@image_key"
|
| 77 |
+
- "@label_key"
|
| 78 |
+
dtype:
|
| 79 |
+
- "$np.float16"
|
| 80 |
+
- "$np.uint8"
|
| 81 |
+
- _target_: CopyItemsd
|
| 82 |
+
keys: "@label_key"
|
| 83 |
+
times: 1
|
| 84 |
+
names:
|
| 85 |
+
- label4crop
|
| 86 |
+
- _target_: Lambdad
|
| 87 |
+
keys: label4crop
|
| 88 |
+
func: "$lambda x, s=@output_classes: np.concatenate(tuple([ndimage.binary_dilation((x==_k).astype(x.dtype), iterations=48).astype(float) for _k in range(s)]), axis=0)"
|
| 89 |
+
overwrite: true
|
| 90 |
+
- _target_: EnsureTyped
|
| 91 |
+
keys:
|
| 92 |
+
- "@image_key"
|
| 93 |
+
- "@label_key"
|
| 94 |
+
- _target_: CastToTyped
|
| 95 |
+
keys: "@image_key"
|
| 96 |
+
dtype: "$torch.float32"
|
| 97 |
+
- _target_: SpatialPadd
|
| 98 |
+
keys:
|
| 99 |
+
- "@image_key"
|
| 100 |
+
- "@label_key"
|
| 101 |
+
- label4crop
|
| 102 |
+
spatial_size: "@patch_size"
|
| 103 |
+
mode:
|
| 104 |
+
- reflect
|
| 105 |
+
- constant
|
| 106 |
+
- constant
|
| 107 |
+
- _target_: RandCropByLabelClassesd
|
| 108 |
+
keys:
|
| 109 |
+
- "@image_key"
|
| 110 |
+
- "@label_key"
|
| 111 |
+
label_key: label4crop
|
| 112 |
+
num_classes: "@output_classes"
|
| 113 |
+
ratios: "$[1,] * @output_classes"
|
| 114 |
+
spatial_size: "@patch_size"
|
| 115 |
+
num_samples: "@num_patches_per_image"
|
| 116 |
+
- _target_: Lambdad
|
| 117 |
+
keys: label4crop
|
| 118 |
+
func: "$lambda x: 0"
|
| 119 |
+
- _target_: RandRotated
|
| 120 |
+
keys:
|
| 121 |
+
- "@image_key"
|
| 122 |
+
- "@label_key"
|
| 123 |
+
range_x: 0.3
|
| 124 |
+
range_y: 0.3
|
| 125 |
+
range_z: 0.3
|
| 126 |
+
mode:
|
| 127 |
+
- bilinear
|
| 128 |
+
- nearest
|
| 129 |
+
prob: 0.2
|
| 130 |
+
- _target_: RandZoomd
|
| 131 |
+
keys:
|
| 132 |
+
- "@image_key"
|
| 133 |
+
- "@label_key"
|
| 134 |
+
min_zoom: 0.8
|
| 135 |
+
max_zoom: 1.2
|
| 136 |
+
mode:
|
| 137 |
+
- trilinear
|
| 138 |
+
- nearest
|
| 139 |
+
align_corners:
|
| 140 |
+
- null
|
| 141 |
+
- null
|
| 142 |
+
prob: 0.16
|
| 143 |
+
- _target_: RandGaussianSmoothd
|
| 144 |
+
keys: "@image_key"
|
| 145 |
+
sigma_x:
|
| 146 |
+
- 0.5
|
| 147 |
+
- 1.15
|
| 148 |
+
sigma_y:
|
| 149 |
+
- 0.5
|
| 150 |
+
- 1.15
|
| 151 |
+
sigma_z:
|
| 152 |
+
- 0.5
|
| 153 |
+
- 1.15
|
| 154 |
+
prob: 0.15
|
| 155 |
+
- _target_: RandScaleIntensityd
|
| 156 |
+
keys: "@image_key"
|
| 157 |
+
factors: 0.3
|
| 158 |
+
prob: 0.5
|
| 159 |
+
- _target_: RandShiftIntensityd
|
| 160 |
+
keys: "@image_key"
|
| 161 |
+
offsets: 0.1
|
| 162 |
+
prob: 0.5
|
| 163 |
+
- _target_: RandGaussianNoised
|
| 164 |
+
keys: "@image_key"
|
| 165 |
+
std: 0.01
|
| 166 |
+
prob: 0.15
|
| 167 |
+
- _target_: RandFlipd
|
| 168 |
+
keys:
|
| 169 |
+
- "@image_key"
|
| 170 |
+
- "@label_key"
|
| 171 |
+
spatial_axis: 0
|
| 172 |
+
prob: 0.5
|
| 173 |
+
- _target_: RandFlipd
|
| 174 |
+
keys:
|
| 175 |
+
- "@image_key"
|
| 176 |
+
- "@label_key"
|
| 177 |
+
spatial_axis: 1
|
| 178 |
+
prob: 0.5
|
| 179 |
+
- _target_: RandFlipd
|
| 180 |
+
keys:
|
| 181 |
+
- "@image_key"
|
| 182 |
+
- "@label_key"
|
| 183 |
+
spatial_axis: 2
|
| 184 |
+
prob: 0.5
|
| 185 |
+
- _target_: CastToTyped
|
| 186 |
+
keys:
|
| 187 |
+
- "@image_key"
|
| 188 |
+
- "@label_key"
|
| 189 |
+
dtype:
|
| 190 |
+
- "$torch.float32"
|
| 191 |
+
- "$torch.uint8"
|
| 192 |
+
- _target_: ToTensord
|
| 193 |
+
keys:
|
| 194 |
+
- "@image_key"
|
| 195 |
+
- "@label_key"
|
| 196 |
+
transform_validation:
|
| 197 |
+
_target_: Compose
|
| 198 |
+
transforms:
|
| 199 |
+
- _target_: LoadImaged
|
| 200 |
+
keys:
|
| 201 |
+
- "@image_key"
|
| 202 |
+
- "@label_key"
|
| 203 |
+
- _target_: EnsureChannelFirstd
|
| 204 |
+
keys:
|
| 205 |
+
- "@image_key"
|
| 206 |
+
- "@label_key"
|
| 207 |
+
- _target_: Orientationd
|
| 208 |
+
keys:
|
| 209 |
+
- "@image_key"
|
| 210 |
+
- "@label_key"
|
| 211 |
+
axcodes: RAS
|
| 212 |
+
- _target_: Spacingd
|
| 213 |
+
keys:
|
| 214 |
+
- "@image_key"
|
| 215 |
+
- "@label_key"
|
| 216 |
+
pixdim:
|
| 217 |
+
- 1
|
| 218 |
+
- 1
|
| 219 |
+
- 1
|
| 220 |
+
mode:
|
| 221 |
+
- bilinear
|
| 222 |
+
- nearest
|
| 223 |
+
align_corners:
|
| 224 |
+
- true
|
| 225 |
+
- true
|
| 226 |
+
- _target_: CastToTyped
|
| 227 |
+
keys: "@image_key"
|
| 228 |
+
dtype: "$torch.float32"
|
| 229 |
+
- _target_: ScaleIntensityRanged
|
| 230 |
+
keys: "@image_key"
|
| 231 |
+
a_min: -87
|
| 232 |
+
a_max: 199
|
| 233 |
+
b_min: 0
|
| 234 |
+
b_max: 1
|
| 235 |
+
clip: true
|
| 236 |
+
- _target_: CastToTyped
|
| 237 |
+
keys:
|
| 238 |
+
- "@image_key"
|
| 239 |
+
- "@label_key"
|
| 240 |
+
dtype:
|
| 241 |
+
- "$np.float16"
|
| 242 |
+
- "$np.uint8"
|
| 243 |
+
- _target_: CastToTyped
|
| 244 |
+
keys:
|
| 245 |
+
- "@image_key"
|
| 246 |
+
- "@label_key"
|
| 247 |
+
dtype:
|
| 248 |
+
- "$torch.float32"
|
| 249 |
+
- "$torch.uint8"
|
| 250 |
+
- _target_: ToTensord
|
| 251 |
+
keys:
|
| 252 |
+
- "@image_key"
|
| 253 |
+
- "@label_key"
|
| 254 |
+
loss:
|
| 255 |
+
_target_: DiceCELoss
|
| 256 |
+
include_background: false
|
| 257 |
+
to_onehot_y: true
|
| 258 |
+
softmax: true
|
| 259 |
+
squared_pred: true
|
| 260 |
+
batch: true
|
| 261 |
+
smooth_nr: 0.00001
|
| 262 |
+
smooth_dr: 0.00001
|
| 263 |
+
dints_space:
|
| 264 |
+
_target_: monai.networks.nets.TopologySearch
|
| 265 |
+
channel_mul: 0.5
|
| 266 |
+
num_blocks: 12
|
| 267 |
+
num_depths: 4
|
| 268 |
+
use_downsample: true
|
| 269 |
+
device: "$torch.device('cuda')"
|
| 270 |
+
network:
|
| 271 |
+
_target_: monai.networks.nets.DiNTS
|
| 272 |
+
dints_space: "@dints_space"
|
| 273 |
+
in_channels: "@input_channels"
|
| 274 |
+
num_classes: "@output_classes"
|
| 275 |
+
use_downsample: true
|
configs/train.yaml
ADDED
|
@@ -0,0 +1,355 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
imports:
|
| 3 |
+
- "$import glob"
|
| 4 |
+
- "$import json"
|
| 5 |
+
- "$import os"
|
| 6 |
+
- "$import ignite"
|
| 7 |
+
- "$from scipy import ndimage"
|
| 8 |
+
input_channels: 1
|
| 9 |
+
output_classes: 3
|
| 10 |
+
arch_ckpt_path: "$@bundle_root + '/models/search_code_18590.pt'"
|
| 11 |
+
arch_ckpt: "$torch.load(@arch_ckpt_path, map_location=torch.device('cuda'))"
|
| 12 |
+
bundle_root: "."
|
| 13 |
+
ckpt_dir: "$@bundle_root + '/models'"
|
| 14 |
+
output_dir: "$@bundle_root + '/eval'"
|
| 15 |
+
dataset_dir: "/workspace/data/msd/Task07_Pancreas"
|
| 16 |
+
data_list_file_path: "$@bundle_root + '/configs/dataset_0.json'"
|
| 17 |
+
train_datalist: "$monai.data.load_decathlon_datalist(@data_list_file_path, data_list_key='training',
|
| 18 |
+
base_dir=@dataset_dir)"
|
| 19 |
+
val_datalist: "$monai.data.load_decathlon_datalist(@data_list_file_path, data_list_key='validation',
|
| 20 |
+
base_dir=@dataset_dir)"
|
| 21 |
+
device: "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')"
|
| 22 |
+
dints_space:
|
| 23 |
+
_target_: monai.networks.nets.TopologyInstance
|
| 24 |
+
channel_mul: 1
|
| 25 |
+
num_blocks: 12
|
| 26 |
+
num_depths: 4
|
| 27 |
+
use_downsample: true
|
| 28 |
+
arch_code:
|
| 29 |
+
- "$@arch_ckpt['arch_code_a']"
|
| 30 |
+
- "$@arch_ckpt['arch_code_c']"
|
| 31 |
+
device: "$torch.device('cuda')"
|
| 32 |
+
network_def:
|
| 33 |
+
_target_: monai.networks.nets.DiNTS
|
| 34 |
+
dints_space: "@dints_space"
|
| 35 |
+
in_channels: "@input_channels"
|
| 36 |
+
num_classes: "@output_classes"
|
| 37 |
+
use_downsample: true
|
| 38 |
+
node_a: "$@arch_ckpt['node_a']"
|
| 39 |
+
network: "$@network_def.to(@device)"
|
| 40 |
+
loss:
|
| 41 |
+
_target_: DiceCELoss
|
| 42 |
+
include_background: false
|
| 43 |
+
to_onehot_y: true
|
| 44 |
+
softmax: true
|
| 45 |
+
squared_pred: true
|
| 46 |
+
batch: true
|
| 47 |
+
smooth_nr: 1.0e-05
|
| 48 |
+
smooth_dr: 1.0e-05
|
| 49 |
+
optimizer:
|
| 50 |
+
_target_: torch.optim.SGD
|
| 51 |
+
params: "[email protected]()"
|
| 52 |
+
momentum: 0.9
|
| 53 |
+
weight_decay: 4.0e-05
|
| 54 |
+
lr: 0.025
|
| 55 |
+
lr_scheduler:
|
| 56 |
+
_target_: torch.optim.lr_scheduler.StepLR
|
| 57 |
+
optimizer: "@optimizer"
|
| 58 |
+
step_size: 80
|
| 59 |
+
gamma: 0.5
|
| 60 |
+
image_key: image
|
| 61 |
+
label_key: label
|
| 62 |
+
val_interval: 10
|
| 63 |
+
train:
|
| 64 |
+
deterministic_transforms:
|
| 65 |
+
- _target_: LoadImaged
|
| 66 |
+
keys:
|
| 67 |
+
- "@image_key"
|
| 68 |
+
- "@label_key"
|
| 69 |
+
image_only: false
|
| 70 |
+
- _target_: EnsureChannelFirstd
|
| 71 |
+
keys:
|
| 72 |
+
- "@image_key"
|
| 73 |
+
- "@label_key"
|
| 74 |
+
- _target_: Orientationd
|
| 75 |
+
keys:
|
| 76 |
+
- "@image_key"
|
| 77 |
+
- "@label_key"
|
| 78 |
+
axcodes: RAS
|
| 79 |
+
- _target_: Spacingd
|
| 80 |
+
keys:
|
| 81 |
+
- "@image_key"
|
| 82 |
+
- "@label_key"
|
| 83 |
+
pixdim:
|
| 84 |
+
- 1
|
| 85 |
+
- 1
|
| 86 |
+
- 1
|
| 87 |
+
mode:
|
| 88 |
+
- bilinear
|
| 89 |
+
- nearest
|
| 90 |
+
align_corners:
|
| 91 |
+
- true
|
| 92 |
+
- true
|
| 93 |
+
- _target_: CastToTyped
|
| 94 |
+
keys: "@image_key"
|
| 95 |
+
dtype: "$torch.float32"
|
| 96 |
+
- _target_: ScaleIntensityRanged
|
| 97 |
+
keys: "@image_key"
|
| 98 |
+
a_min: -87
|
| 99 |
+
a_max: 199
|
| 100 |
+
b_min: 0
|
| 101 |
+
b_max: 1
|
| 102 |
+
clip: true
|
| 103 |
+
- _target_: CastToTyped
|
| 104 |
+
keys:
|
| 105 |
+
- "@image_key"
|
| 106 |
+
- "@label_key"
|
| 107 |
+
dtype:
|
| 108 |
+
- "$np.float16"
|
| 109 |
+
- "$np.uint8"
|
| 110 |
+
- _target_: CopyItemsd
|
| 111 |
+
keys: "@label_key"
|
| 112 |
+
times: 1
|
| 113 |
+
names:
|
| 114 |
+
- label4crop
|
| 115 |
+
- _target_: Lambdad
|
| 116 |
+
keys: label4crop
|
| 117 |
+
func: "$lambda x, s=@output_classes: np.concatenate(tuple([ndimage.binary_dilation((x==_k).astype(x.dtype),
|
| 118 |
+
iterations=48).astype(float) for _k in range(s)]), axis=0)"
|
| 119 |
+
overwrite: true
|
| 120 |
+
- _target_: EnsureTyped
|
| 121 |
+
keys:
|
| 122 |
+
- "@image_key"
|
| 123 |
+
- "@label_key"
|
| 124 |
+
- _target_: CastToTyped
|
| 125 |
+
keys: "@image_key"
|
| 126 |
+
dtype: "$torch.float32"
|
| 127 |
+
- _target_: SpatialPadd
|
| 128 |
+
keys:
|
| 129 |
+
- "@image_key"
|
| 130 |
+
- "@label_key"
|
| 131 |
+
- label4crop
|
| 132 |
+
spatial_size:
|
| 133 |
+
- 96
|
| 134 |
+
- 96
|
| 135 |
+
- 96
|
| 136 |
+
mode:
|
| 137 |
+
- reflect
|
| 138 |
+
- constant
|
| 139 |
+
- constant
|
| 140 |
+
random_transforms:
|
| 141 |
+
- _target_: RandCropByLabelClassesd
|
| 142 |
+
keys:
|
| 143 |
+
- "@image_key"
|
| 144 |
+
- "@label_key"
|
| 145 |
+
label_key: label4crop
|
| 146 |
+
num_classes: "@output_classes"
|
| 147 |
+
ratios: "$[1,] * @output_classes"
|
| 148 |
+
spatial_size:
|
| 149 |
+
- 96
|
| 150 |
+
- 96
|
| 151 |
+
- 96
|
| 152 |
+
num_samples: 1
|
| 153 |
+
- _target_: Lambdad
|
| 154 |
+
keys: label4crop
|
| 155 |
+
func: "$lambda x: 0"
|
| 156 |
+
- _target_: RandRotated
|
| 157 |
+
keys:
|
| 158 |
+
- "@image_key"
|
| 159 |
+
- "@label_key"
|
| 160 |
+
range_x: 0.3
|
| 161 |
+
range_y: 0.3
|
| 162 |
+
range_z: 0.3
|
| 163 |
+
mode:
|
| 164 |
+
- bilinear
|
| 165 |
+
- nearest
|
| 166 |
+
prob: 0.2
|
| 167 |
+
- _target_: RandZoomd
|
| 168 |
+
keys:
|
| 169 |
+
- "@image_key"
|
| 170 |
+
- "@label_key"
|
| 171 |
+
min_zoom: 0.8
|
| 172 |
+
max_zoom: 1.2
|
| 173 |
+
mode:
|
| 174 |
+
- trilinear
|
| 175 |
+
- nearest
|
| 176 |
+
align_corners:
|
| 177 |
+
- true
|
| 178 |
+
-
|
| 179 |
+
prob: 0.16
|
| 180 |
+
- _target_: RandGaussianSmoothd
|
| 181 |
+
keys: "@image_key"
|
| 182 |
+
sigma_x:
|
| 183 |
+
- 0.5
|
| 184 |
+
- 1.15
|
| 185 |
+
sigma_y:
|
| 186 |
+
- 0.5
|
| 187 |
+
- 1.15
|
| 188 |
+
sigma_z:
|
| 189 |
+
- 0.5
|
| 190 |
+
- 1.15
|
| 191 |
+
prob: 0.15
|
| 192 |
+
- _target_: RandScaleIntensityd
|
| 193 |
+
keys: "@image_key"
|
| 194 |
+
factors: 0.3
|
| 195 |
+
prob: 0.5
|
| 196 |
+
- _target_: RandShiftIntensityd
|
| 197 |
+
keys: "@image_key"
|
| 198 |
+
offsets: 0.1
|
| 199 |
+
prob: 0.5
|
| 200 |
+
- _target_: RandGaussianNoised
|
| 201 |
+
keys: "@image_key"
|
| 202 |
+
std: 0.01
|
| 203 |
+
prob: 0.15
|
| 204 |
+
- _target_: RandFlipd
|
| 205 |
+
keys:
|
| 206 |
+
- "@image_key"
|
| 207 |
+
- "@label_key"
|
| 208 |
+
spatial_axis: 0
|
| 209 |
+
prob: 0.5
|
| 210 |
+
- _target_: RandFlipd
|
| 211 |
+
keys:
|
| 212 |
+
- "@image_key"
|
| 213 |
+
- "@label_key"
|
| 214 |
+
spatial_axis: 1
|
| 215 |
+
prob: 0.5
|
| 216 |
+
- _target_: RandFlipd
|
| 217 |
+
keys:
|
| 218 |
+
- "@image_key"
|
| 219 |
+
- "@label_key"
|
| 220 |
+
spatial_axis: 2
|
| 221 |
+
prob: 0.5
|
| 222 |
+
- _target_: CastToTyped
|
| 223 |
+
keys:
|
| 224 |
+
- "@image_key"
|
| 225 |
+
- "@label_key"
|
| 226 |
+
dtype:
|
| 227 |
+
- "$torch.float32"
|
| 228 |
+
- "$torch.uint8"
|
| 229 |
+
- _target_: ToTensord
|
| 230 |
+
keys:
|
| 231 |
+
- "@image_key"
|
| 232 |
+
- "@label_key"
|
| 233 |
+
preprocessing:
|
| 234 |
+
_target_: Compose
|
| 235 |
+
transforms: "$@train#deterministic_transforms + @train#random_transforms"
|
| 236 |
+
dataset:
|
| 237 |
+
_target_: CacheDataset
|
| 238 |
+
data: "@train_datalist"
|
| 239 |
+
transform: "@train#preprocessing"
|
| 240 |
+
cache_rate: 0.125
|
| 241 |
+
num_workers: 4
|
| 242 |
+
dataloader:
|
| 243 |
+
_target_: DataLoader
|
| 244 |
+
dataset: "@train#dataset"
|
| 245 |
+
batch_size: 2
|
| 246 |
+
shuffle: true
|
| 247 |
+
num_workers: 4
|
| 248 |
+
inferer:
|
| 249 |
+
_target_: SimpleInferer
|
| 250 |
+
postprocessing:
|
| 251 |
+
_target_: Compose
|
| 252 |
+
transforms:
|
| 253 |
+
- _target_: Activationsd
|
| 254 |
+
keys: pred
|
| 255 |
+
softmax: true
|
| 256 |
+
- _target_: AsDiscreted
|
| 257 |
+
keys:
|
| 258 |
+
- pred
|
| 259 |
+
- label
|
| 260 |
+
argmax:
|
| 261 |
+
- true
|
| 262 |
+
- false
|
| 263 |
+
to_onehot: "@output_classes"
|
| 264 |
+
handlers:
|
| 265 |
+
- _target_: LrScheduleHandler
|
| 266 |
+
lr_scheduler: "@lr_scheduler"
|
| 267 |
+
print_lr: true
|
| 268 |
+
- _target_: ValidationHandler
|
| 269 |
+
validator: "@validate#evaluator"
|
| 270 |
+
epoch_level: true
|
| 271 |
+
interval: "@val_interval"
|
| 272 |
+
- _target_: StatsHandler
|
| 273 |
+
tag_name: train_loss
|
| 274 |
+
output_transform: "$monai.handlers.from_engine(['loss'], first=True)"
|
| 275 |
+
- _target_: TensorBoardStatsHandler
|
| 276 |
+
log_dir: "@output_dir"
|
| 277 |
+
tag_name: train_loss
|
| 278 |
+
output_transform: "$monai.handlers.from_engine(['loss'], first=True)"
|
| 279 |
+
key_metric:
|
| 280 |
+
train_accuracy:
|
| 281 |
+
_target_: ignite.metrics.Accuracy
|
| 282 |
+
output_transform: "$monai.handlers.from_engine(['pred', 'label'])"
|
| 283 |
+
trainer:
|
| 284 |
+
_target_: SupervisedTrainer
|
| 285 |
+
max_epochs: 400
|
| 286 |
+
device: "@device"
|
| 287 |
+
train_data_loader: "@train#dataloader"
|
| 288 |
+
network: "@network"
|
| 289 |
+
loss_function: "@loss"
|
| 290 |
+
optimizer: "@optimizer"
|
| 291 |
+
inferer: "@train#inferer"
|
| 292 |
+
postprocessing: "@train#postprocessing"
|
| 293 |
+
key_train_metric: "@train#key_metric"
|
| 294 |
+
train_handlers: "@train#handlers"
|
| 295 |
+
amp: true
|
| 296 |
+
validate:
|
| 297 |
+
preprocessing:
|
| 298 |
+
_target_: Compose
|
| 299 |
+
transforms: "%train#deterministic_transforms"
|
| 300 |
+
dataset:
|
| 301 |
+
_target_: CacheDataset
|
| 302 |
+
data: "@val_datalist"
|
| 303 |
+
transform: "@validate#preprocessing"
|
| 304 |
+
cache_rate: 0.125
|
| 305 |
+
dataloader:
|
| 306 |
+
_target_: DataLoader
|
| 307 |
+
dataset: "@validate#dataset"
|
| 308 |
+
batch_size: 1
|
| 309 |
+
shuffle: false
|
| 310 |
+
num_workers: 4
|
| 311 |
+
inferer:
|
| 312 |
+
_target_: SlidingWindowInferer
|
| 313 |
+
roi_size:
|
| 314 |
+
- 96
|
| 315 |
+
- 96
|
| 316 |
+
- 96
|
| 317 |
+
sw_batch_size: 6
|
| 318 |
+
overlap: 0.625
|
| 319 |
+
postprocessing: "%train#postprocessing"
|
| 320 |
+
handlers:
|
| 321 |
+
- _target_: StatsHandler
|
| 322 |
+
iteration_log: false
|
| 323 |
+
- _target_: TensorBoardStatsHandler
|
| 324 |
+
log_dir: "@output_dir"
|
| 325 |
+
iteration_log: false
|
| 326 |
+
- _target_: CheckpointSaver
|
| 327 |
+
save_dir: "@ckpt_dir"
|
| 328 |
+
save_dict:
|
| 329 |
+
model: "@network"
|
| 330 |
+
save_key_metric: true
|
| 331 |
+
key_metric_filename: model.pt
|
| 332 |
+
key_metric:
|
| 333 |
+
val_mean_dice:
|
| 334 |
+
_target_: MeanDice
|
| 335 |
+
include_background: false
|
| 336 |
+
output_transform: "$monai.handlers.from_engine(['pred', 'label'])"
|
| 337 |
+
additional_metrics:
|
| 338 |
+
val_accuracy:
|
| 339 |
+
_target_: ignite.metrics.Accuracy
|
| 340 |
+
output_transform: "$monai.handlers.from_engine(['pred', 'label'])"
|
| 341 |
+
evaluator:
|
| 342 |
+
_target_: SupervisedEvaluator
|
| 343 |
+
device: "@device"
|
| 344 |
+
val_data_loader: "@validate#dataloader"
|
| 345 |
+
network: "@network"
|
| 346 |
+
inferer: "@validate#inferer"
|
| 347 |
+
postprocessing: "@validate#postprocessing"
|
| 348 |
+
key_val_metric: "@validate#key_metric"
|
| 349 |
+
additional_metrics: "@validate#additional_metrics"
|
| 350 |
+
val_handlers: "@validate#handlers"
|
| 351 |
+
amp: true
|
| 352 |
+
initialize:
|
| 353 |
+
- "$monai.utils.set_determinism(seed=123)"
|
| 354 |
+
run:
|
| 355 |
+
- "$@train#trainer.run()"
|
docs/README.md
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Overview
|
| 2 |
+
A neural architecture search algorithm for volumetric (3D) segmentation of the pancreas and pancreatic tumor from CT image. This model is trained using the neural network model from the neural architecture search algorithm, DiNTS [1].
|
| 3 |
+
|
| 4 |
+
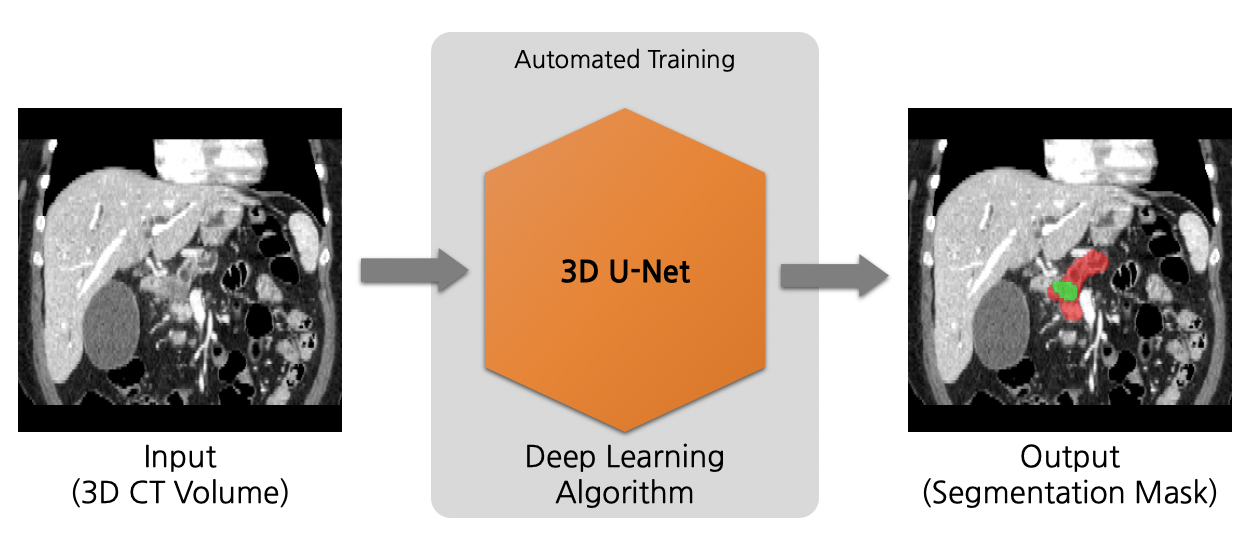
|
| 5 |
+
|
| 6 |
+
## Data
|
| 7 |
+
The training dataset is the Pancreas Task from the Medical Segmentation Decathalon. Users can find more details on the datasets at http://medicaldecathlon.com/.
|
| 8 |
+
|
| 9 |
+
- Target: Pancreas and pancreatic tumor
|
| 10 |
+
- Modality: Portal venous phase CT
|
| 11 |
+
- Size: 420 3D volumes (282 Training +139 Testing)
|
| 12 |
+
- Source: Memorial Sloan Kettering Cancer Center
|
| 13 |
+
- Challenge: Label unbalance with large (background), medium (pancreas) and small (tumour) structures.
|
| 14 |
+
|
| 15 |
+
### Preprocessing
|
| 16 |
+
The data list/split can be created with the script `scripts/prepare_datalist.py`.
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
python scripts/prepare_datalist.py --path /path-to-Task07_Pancreas/ --output configs/dataset_0.json
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
## Training configuration
|
| 23 |
+
The training was performed with at least 16GB-memory GPUs.
|
| 24 |
+
|
| 25 |
+
Actual Model Input: 96 x 96 x 96
|
| 26 |
+
|
| 27 |
+
### Neural Architecture Search Configuration
|
| 28 |
+
The neural architecture search was performed with the following:
|
| 29 |
+
|
| 30 |
+
- AMP: True
|
| 31 |
+
- Optimizer: SGD
|
| 32 |
+
- Initial Learning Rate: 0.025
|
| 33 |
+
- Loss: DiceCELoss
|
| 34 |
+
|
| 35 |
+
### Optimial Architecture Training Configuration
|
| 36 |
+
The training was performed with the following:
|
| 37 |
+
|
| 38 |
+
- AMP: True
|
| 39 |
+
- Optimizer: SGD
|
| 40 |
+
- (Initial) Learning Rate: 0.025
|
| 41 |
+
- Loss: DiceCELoss
|
| 42 |
+
|
| 43 |
+
The segmentation of pancreas region is formulated as the voxel-wise 3-class classification. Each voxel is predicted as either foreground (pancreas body, tumour) or background. And the model is optimized with gradient descent method minimizing soft dice loss and cross-entropy loss between the predicted mask and ground truth segmentation.
|
| 44 |
+
|
| 45 |
+
### Input
|
| 46 |
+
One channel
|
| 47 |
+
- CT image
|
| 48 |
+
|
| 49 |
+
### Output
|
| 50 |
+
Three channels
|
| 51 |
+
- Label 2: pancreatic tumor
|
| 52 |
+
- Label 1: pancreas
|
| 53 |
+
- Label 0: everything else
|
| 54 |
+
|
| 55 |
+
### Memory Consumption
|
| 56 |
+
|
| 57 |
+
- Dataset Manager: CacheDataset
|
| 58 |
+
- Data Size: 420 3D Volumes
|
| 59 |
+
- Cache Rate: 1.0
|
| 60 |
+
- Multi GPU (8 GPUs) - System RAM Usage: 400G
|
| 61 |
+
|
| 62 |
+
### Memory Consumption Warning
|
| 63 |
+
|
| 64 |
+
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
|
| 65 |
+
|
| 66 |
+
## Performance
|
| 67 |
+
Dice score is used for evaluating the performance of the model. This model achieves a mean dice score of 0.62.
|
| 68 |
+
|
| 69 |
+
Please note that this bundle is non-deterministic because of the trilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
|
| 70 |
+
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 71 |
+
|
| 72 |
+
#### Training Loss
|
| 73 |
+
The loss over 3200 epochs (the bright curve is smoothed, and the dark one is the actual curve)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
#### Validation Dice
|
| 78 |
+
The mean dice score over 3200 epochs (the bright curve is smoothed, and the dark one is the actual curve)
|
| 79 |
+
|
| 80 |
+
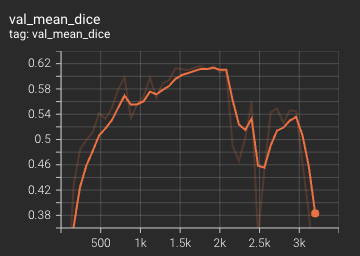
|
| 81 |
+
|
| 82 |
+
#### TensorRT speedup
|
| 83 |
+
This bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
|
| 84 |
+
|
| 85 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 86 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 87 |
+
| model computation | 133.93 | 43.41 | 35.65 | 26.63 | 3.09 | 3.76 | 5.03 | 1.63 |
|
| 88 |
+
| end2end | 54611.72 | 19240.66 | 16104.8 | 11443.57 | 2.84 | 3.39 | 4.77 | 1.68 |
|
| 89 |
+
|
| 90 |
+
Where:
|
| 91 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 92 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 93 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 94 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 95 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 96 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 97 |
+
|
| 98 |
+
This result is benchmarked under:
|
| 99 |
+
- TensorRT: 8.6.1+cuda12.0
|
| 100 |
+
- Torch-TensorRT Version: 1.4.0
|
| 101 |
+
- CPU Architecture: x86-64
|
| 102 |
+
- OS: ubuntu 20.04
|
| 103 |
+
- Python version:3.8.10
|
| 104 |
+
- CUDA version: 12.1
|
| 105 |
+
- GPU models and configuration: A100 80G
|
| 106 |
+
|
| 107 |
+
### Searched Architecture Visualization
|
| 108 |
+
Users can install Graphviz for visualization of searched architectures (needed in [decode_plot.py](https://github.com/Project-MONAI/tutorials/blob/main/automl/DiNTS/decode_plot.py)). The edges between nodes indicate global structure, and numbers next to edges represent different operations in the cell searching space. An example of searched architecture is shown as follows:
|
| 109 |
+
|
| 110 |
+

|
| 111 |
+
|
| 112 |
+
## MONAI Bundle Commands
|
| 113 |
+
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 114 |
+
|
| 115 |
+
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
|
| 116 |
+
|
| 117 |
+
#### Execute model searching:
|
| 118 |
+
|
| 119 |
+
```
|
| 120 |
+
python -m scripts.search run --config_file configs/search.yaml
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
#### Execute multi-GPU model searching (recommended):
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
torchrun --nnodes=1 --nproc_per_node=8 -m scripts.search run --config_file configs/search.yaml
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
#### Execute training:
|
| 130 |
+
|
| 131 |
+
```
|
| 132 |
+
python -m monai.bundle run --config_file configs/train.yaml
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
python -m monai.bundle run --config_file configs/train.yaml --dataset_dir <actual dataset path>
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
#### Override the `train` config to execute multi-GPU training:
|
| 142 |
+
|
| 143 |
+
```
|
| 144 |
+
torchrun --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train.yaml','configs/multi_gpu_train.yaml']"
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
#### Override the `train` config to execute evaluation with the trained model:
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
python -m monai.bundle run --config_file "['configs/train.yaml','configs/evaluate.yaml']"
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
#### Execute inference:
|
| 154 |
+
|
| 155 |
+
```
|
| 156 |
+
python -m monai.bundle run --config_file configs/inference.yaml
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
#### Export checkpoint for TorchScript:
|
| 160 |
+
|
| 161 |
+
```
|
| 162 |
+
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.yaml
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 166 |
+
|
| 167 |
+
```
|
| 168 |
+
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.yaml --precision <fp32/fp16> --use_trace "True" --dynamic_batchsize "[1, 4, 8]" --converter_kwargs "{'truncate_long_and_double':True, 'torch_executed_ops': ['aten::upsample_trilinear3d']}"
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
#### Execute inference with the TensorRT model:
|
| 172 |
+
|
| 173 |
+
```
|
| 174 |
+
python -m monai.bundle run --config_file "['configs/inference.yaml', 'configs/inference_trt.yaml']"
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
# References
|
| 178 |
+
|
| 179 |
+
[1] He, Y., Yang, D., Roth, H., Zhao, C. and Xu, D., 2021. Dints: Differentiable neural network topology search for 3d medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5841-5850).
|
| 180 |
+
|
| 181 |
+
# License
|
| 182 |
+
Copyright (c) MONAI Consortium
|
| 183 |
+
|
| 184 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 185 |
+
you may not use this file except in compliance with the License.
|
| 186 |
+
You may obtain a copy of the License at
|
| 187 |
+
|
| 188 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 189 |
+
|
| 190 |
+
Unless required by applicable law or agreed to in writing, software
|
| 191 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 192 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 193 |
+
See the License for the specific language governing permissions and
|
| 194 |
+
limitations under the License.
|
docs/data_license.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Third Party Licenses
|
| 2 |
+
-----------------------------------------------------------------------
|
| 3 |
+
|
| 4 |
+
/*********************************************************************/
|
| 5 |
+
i. Medical Segmentation Decathlon
|
| 6 |
+
http://medicaldecathlon.com/
|
models/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a18ae8b837f6affe778d7e9f130e6045c04a6f7d5b5dd8470155b9a18b6bcb65
|
| 3 |
+
size 553830837
|
models/model.ts
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:39d6087354fcff7b90e27191e5654774b98e6d7b503aa5752edfa9b07867bd5a
|
| 3 |
+
size 554038651
|
models/search_code_18590.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5049f457b4cdbee036faf56ff5445c633300128d582731e6364c97fa3dc8a515
|
| 3 |
+
size 4355
|
scripts/__init__.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
scripts/prepare_datalist.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import monai
|
| 7 |
+
from sklearn.model_selection import train_test_split
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def produce_sample_dict(line: str):
|
| 11 |
+
return {"label": line, "image": line.replace("labelsTr", "imagesTr")}
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def produce_datalist(dataset_dir: str, train_size: int = 196):
|
| 15 |
+
"""
|
| 16 |
+
This function is used to split the dataset.
|
| 17 |
+
It will produce "train_size" number of samples for training.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
samples = sorted(glob.glob(os.path.join(dataset_dir, "labelsTr", "*"), recursive=True))
|
| 21 |
+
samples = [_item.replace(os.path.join(dataset_dir, "labelsTr"), "labelsTr") for _item in samples]
|
| 22 |
+
datalist = []
|
| 23 |
+
for line in samples:
|
| 24 |
+
datalist.append(produce_sample_dict(line))
|
| 25 |
+
train_list, other_list = train_test_split(datalist, train_size=train_size)
|
| 26 |
+
val_list, test_list = train_test_split(other_list, train_size=0.66)
|
| 27 |
+
|
| 28 |
+
return {"training": train_list, "validation": val_list, "testing": test_list}
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def main(args):
|
| 32 |
+
"""
|
| 33 |
+
split the dataset and output the data list into a json file.
|
| 34 |
+
"""
|
| 35 |
+
data_file_base_dir = args.path
|
| 36 |
+
output_json = args.output
|
| 37 |
+
# produce deterministic data splits
|
| 38 |
+
monai.utils.set_determinism(seed=123)
|
| 39 |
+
datalist = produce_datalist(dataset_dir=data_file_base_dir, train_size=args.train_size)
|
| 40 |
+
with open(output_json, "w") as f:
|
| 41 |
+
json.dump(datalist, f, ensure_ascii=True, indent=4)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
if __name__ == "__main__":
|
| 45 |
+
parser = argparse.ArgumentParser(description="")
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--path",
|
| 48 |
+
type=str,
|
| 49 |
+
default="/workspace/data/msd/Task07_Pancreas",
|
| 50 |
+
help="root path of MSD Task07_Pancreas dataset.",
|
| 51 |
+
)
|
| 52 |
+
parser.add_argument(
|
| 53 |
+
"--output", type=str, default="dataset_0.json", help="relative path of output datalist json file."
|
| 54 |
+
)
|
| 55 |
+
parser.add_argument("--train_size", type=int, default=196, help="number of training samples.")
|
| 56 |
+
args = parser.parse_args()
|
| 57 |
+
|
| 58 |
+
main(args)
|
scripts/search.py
ADDED
|
@@ -0,0 +1,517 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import json
|
| 13 |
+
import logging
|
| 14 |
+
import os
|
| 15 |
+
import random
|
| 16 |
+
import sys
|
| 17 |
+
import time
|
| 18 |
+
from datetime import datetime
|
| 19 |
+
from typing import Sequence, Union
|
| 20 |
+
|
| 21 |
+
import monai
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
import torch.distributed as dist
|
| 25 |
+
import torch.nn.functional as F
|
| 26 |
+
import yaml
|
| 27 |
+
from monai import transforms
|
| 28 |
+
from monai.bundle import ConfigParser
|
| 29 |
+
from monai.data import ThreadDataLoader, partition_dataset
|
| 30 |
+
from monai.inferers import sliding_window_inference
|
| 31 |
+
from monai.metrics import compute_dice
|
| 32 |
+
from monai.utils import set_determinism
|
| 33 |
+
from torch.nn.parallel import DistributedDataParallel
|
| 34 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def run(config_file: Union[str, Sequence[str]]):
|
| 38 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 39 |
+
|
| 40 |
+
parser = ConfigParser()
|
| 41 |
+
parser.read_config(config_file)
|
| 42 |
+
|
| 43 |
+
arch_ckpt_path = parser["arch_ckpt_path"]
|
| 44 |
+
amp = parser["amp"]
|
| 45 |
+
data_file_base_dir = parser["data_file_base_dir"]
|
| 46 |
+
data_list_file_path = parser["data_list_file_path"]
|
| 47 |
+
determ = parser["determ"]
|
| 48 |
+
learning_rate = parser["learning_rate"]
|
| 49 |
+
learning_rate_arch = parser["learning_rate_arch"]
|
| 50 |
+
learning_rate_milestones = np.array(parser["learning_rate_milestones"])
|
| 51 |
+
num_images_per_batch = parser["num_images_per_batch"]
|
| 52 |
+
num_epochs = parser["num_epochs"] # around 20k iterations
|
| 53 |
+
num_epochs_per_validation = parser["num_epochs_per_validation"]
|
| 54 |
+
num_epochs_warmup = parser["num_epochs_warmup"]
|
| 55 |
+
num_sw_batch_size = parser["num_sw_batch_size"]
|
| 56 |
+
output_classes = parser["output_classes"]
|
| 57 |
+
overlap_ratio = parser["overlap_ratio"]
|
| 58 |
+
patch_size_valid = parser["patch_size_valid"]
|
| 59 |
+
ram_cost_factor = parser["ram_cost_factor"]
|
| 60 |
+
print("[info] GPU RAM cost factor:", ram_cost_factor)
|
| 61 |
+
|
| 62 |
+
train_transforms = parser.get_parsed_content("transform_train")
|
| 63 |
+
val_transforms = parser.get_parsed_content("transform_validation")
|
| 64 |
+
|
| 65 |
+
# deterministic training
|
| 66 |
+
if determ:
|
| 67 |
+
set_determinism(seed=0)
|
| 68 |
+
|
| 69 |
+
print("[info] number of GPUs:", torch.cuda.device_count())
|
| 70 |
+
if torch.cuda.device_count() > 1:
|
| 71 |
+
# initialize the distributed training process, every GPU runs in a process
|
| 72 |
+
dist.init_process_group(backend="nccl", init_method="env://")
|
| 73 |
+
world_size = dist.get_world_size()
|
| 74 |
+
else:
|
| 75 |
+
world_size = 1
|
| 76 |
+
print("[info] world_size:", world_size)
|
| 77 |
+
|
| 78 |
+
with open(data_list_file_path, "r") as f:
|
| 79 |
+
json_data = json.load(f)
|
| 80 |
+
|
| 81 |
+
list_train = json_data["training"]
|
| 82 |
+
list_valid = json_data["validation"]
|
| 83 |
+
|
| 84 |
+
# training data
|
| 85 |
+
files = []
|
| 86 |
+
for _i in range(len(list_train)):
|
| 87 |
+
str_img = os.path.join(data_file_base_dir, list_train[_i]["image"])
|
| 88 |
+
str_seg = os.path.join(data_file_base_dir, list_train[_i]["label"])
|
| 89 |
+
|
| 90 |
+
if (not os.path.exists(str_img)) or (not os.path.exists(str_seg)):
|
| 91 |
+
continue
|
| 92 |
+
|
| 93 |
+
files.append({"image": str_img, "label": str_seg})
|
| 94 |
+
train_files = files
|
| 95 |
+
|
| 96 |
+
random.shuffle(train_files)
|
| 97 |
+
|
| 98 |
+
train_files_w = train_files[: len(train_files) // 2]
|
| 99 |
+
if torch.cuda.device_count() > 1:
|
| 100 |
+
train_files_w = partition_dataset(
|
| 101 |
+
data=train_files_w, shuffle=True, num_partitions=world_size, even_divisible=True
|
| 102 |
+
)[dist.get_rank()]
|
| 103 |
+
|
| 104 |
+
train_files_a = train_files[len(train_files) // 2 :]
|
| 105 |
+
if torch.cuda.device_count() > 1:
|
| 106 |
+
train_files_a = partition_dataset(
|
| 107 |
+
data=train_files_a, shuffle=True, num_partitions=world_size, even_divisible=True
|
| 108 |
+
)[dist.get_rank()]
|
| 109 |
+
|
| 110 |
+
# validation data
|
| 111 |
+
files = []
|
| 112 |
+
for _i in range(len(list_valid)):
|
| 113 |
+
str_img = os.path.join(data_file_base_dir, list_valid[_i]["image"])
|
| 114 |
+
str_seg = os.path.join(data_file_base_dir, list_valid[_i]["label"])
|
| 115 |
+
|
| 116 |
+
if (not os.path.exists(str_img)) or (not os.path.exists(str_seg)):
|
| 117 |
+
continue
|
| 118 |
+
|
| 119 |
+
files.append({"image": str_img, "label": str_seg})
|
| 120 |
+
val_files = files
|
| 121 |
+
|
| 122 |
+
if torch.cuda.device_count() > 1:
|
| 123 |
+
val_files = partition_dataset(data=val_files, shuffle=False, num_partitions=world_size, even_divisible=False)[
|
| 124 |
+
dist.get_rank()
|
| 125 |
+
]
|
| 126 |
+
|
| 127 |
+
# network architecture
|
| 128 |
+
if torch.cuda.device_count() > 1:
|
| 129 |
+
device = torch.device(f"cuda:{dist.get_rank()}")
|
| 130 |
+
else:
|
| 131 |
+
device = torch.device("cuda:0")
|
| 132 |
+
torch.cuda.set_device(device)
|
| 133 |
+
|
| 134 |
+
if torch.cuda.device_count() > 1:
|
| 135 |
+
train_ds_a = monai.data.CacheDataset(
|
| 136 |
+
data=train_files_a, transform=train_transforms, cache_rate=1.0, num_workers=8
|
| 137 |
+
)
|
| 138 |
+
train_ds_w = monai.data.CacheDataset(
|
| 139 |
+
data=train_files_w, transform=train_transforms, cache_rate=1.0, num_workers=8
|
| 140 |
+
)
|
| 141 |
+
val_ds = monai.data.CacheDataset(data=val_files, transform=val_transforms, cache_rate=1.0, num_workers=2)
|
| 142 |
+
else:
|
| 143 |
+
train_ds_a = monai.data.CacheDataset(
|
| 144 |
+
data=train_files_a, transform=train_transforms, cache_rate=0.125, num_workers=8
|
| 145 |
+
)
|
| 146 |
+
train_ds_w = monai.data.CacheDataset(
|
| 147 |
+
data=train_files_w, transform=train_transforms, cache_rate=0.125, num_workers=8
|
| 148 |
+
)
|
| 149 |
+
val_ds = monai.data.CacheDataset(data=val_files, transform=val_transforms, cache_rate=0.125, num_workers=2)
|
| 150 |
+
|
| 151 |
+
train_loader_a = ThreadDataLoader(train_ds_a, num_workers=6, batch_size=num_images_per_batch, shuffle=True)
|
| 152 |
+
train_loader_w = ThreadDataLoader(train_ds_w, num_workers=6, batch_size=num_images_per_batch, shuffle=True)
|
| 153 |
+
val_loader = ThreadDataLoader(val_ds, num_workers=0, batch_size=1, shuffle=False)
|
| 154 |
+
|
| 155 |
+
model = parser.get_parsed_content("network")
|
| 156 |
+
dints_space = parser.get_parsed_content("dints_space")
|
| 157 |
+
|
| 158 |
+
model = model.to(device)
|
| 159 |
+
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
|
| 160 |
+
|
| 161 |
+
post_pred = transforms.Compose(
|
| 162 |
+
[transforms.EnsureType(), transforms.AsDiscrete(argmax=True, to_onehot=output_classes)]
|
| 163 |
+
)
|
| 164 |
+
post_label = transforms.Compose([transforms.EnsureType(), transforms.AsDiscrete(to_onehot=output_classes)])
|
| 165 |
+
|
| 166 |
+
# loss function
|
| 167 |
+
loss_func = parser.get_parsed_content("loss")
|
| 168 |
+
|
| 169 |
+
# optimizer
|
| 170 |
+
optimizer = torch.optim.SGD(
|
| 171 |
+
model.weight_parameters(), lr=learning_rate * world_size, momentum=0.9, weight_decay=0.00004
|
| 172 |
+
)
|
| 173 |
+
arch_optimizer_a = torch.optim.Adam(
|
| 174 |
+
[dints_space.log_alpha_a], lr=learning_rate_arch * world_size, betas=(0.5, 0.999), weight_decay=0.0
|
| 175 |
+
)
|
| 176 |
+
arch_optimizer_c = torch.optim.Adam(
|
| 177 |
+
[dints_space.log_alpha_c], lr=learning_rate_arch * world_size, betas=(0.5, 0.999), weight_decay=0.0
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
if torch.cuda.device_count() > 1:
|
| 181 |
+
model = DistributedDataParallel(model, device_ids=[device], find_unused_parameters=True)
|
| 182 |
+
|
| 183 |
+
# amp
|
| 184 |
+
if amp:
|
| 185 |
+
from torch.cuda.amp import GradScaler, autocast
|
| 186 |
+
|
| 187 |
+
scaler = GradScaler()
|
| 188 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 189 |
+
print("[info] amp enabled")
|
| 190 |
+
|
| 191 |
+
# start a typical PyTorch training
|
| 192 |
+
val_interval = num_epochs_per_validation
|
| 193 |
+
best_metric = -1
|
| 194 |
+
best_metric_epoch = -1
|
| 195 |
+
idx_iter = 0
|
| 196 |
+
|
| 197 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 198 |
+
writer = SummaryWriter(log_dir=os.path.join(arch_ckpt_path, "Events"))
|
| 199 |
+
|
| 200 |
+
with open(os.path.join(arch_ckpt_path, "accuracy_history.csv"), "a") as f:
|
| 201 |
+
f.write("epoch\tmetric\tloss\tlr\ttime\titer\n")
|
| 202 |
+
|
| 203 |
+
dataloader_a_iterator = iter(train_loader_a)
|
| 204 |
+
|
| 205 |
+
start_time = time.time()
|
| 206 |
+
for epoch in range(num_epochs):
|
| 207 |
+
decay = 0.5 ** np.sum(
|
| 208 |
+
[(epoch - num_epochs_warmup) / (num_epochs - num_epochs_warmup) > learning_rate_milestones]
|
| 209 |
+
)
|
| 210 |
+
lr = learning_rate * decay * world_size
|
| 211 |
+
for param_group in optimizer.param_groups:
|
| 212 |
+
param_group["lr"] = lr
|
| 213 |
+
|
| 214 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 215 |
+
print("-" * 10)
|
| 216 |
+
print(f"epoch {epoch + 1}/{num_epochs}")
|
| 217 |
+
print("learning rate is set to {}".format(lr))
|
| 218 |
+
|
| 219 |
+
model.train()
|
| 220 |
+
epoch_loss = 0
|
| 221 |
+
loss_torch = torch.zeros(2, dtype=torch.float, device=device)
|
| 222 |
+
epoch_loss_arch = 0
|
| 223 |
+
loss_torch_arch = torch.zeros(2, dtype=torch.float, device=device)
|
| 224 |
+
step = 0
|
| 225 |
+
|
| 226 |
+
for batch_data in train_loader_w:
|
| 227 |
+
step += 1
|
| 228 |
+
inputs, labels = batch_data["image"].to(device), batch_data["label"].to(device)
|
| 229 |
+
if world_size == 1:
|
| 230 |
+
for _ in model.weight_parameters():
|
| 231 |
+
_.requires_grad = True
|
| 232 |
+
else:
|
| 233 |
+
for _ in model.module.weight_parameters():
|
| 234 |
+
_.requires_grad = True
|
| 235 |
+
dints_space.log_alpha_a.requires_grad = False
|
| 236 |
+
dints_space.log_alpha_c.requires_grad = False
|
| 237 |
+
|
| 238 |
+
optimizer.zero_grad()
|
| 239 |
+
|
| 240 |
+
if amp:
|
| 241 |
+
with autocast():
|
| 242 |
+
outputs = model(inputs)
|
| 243 |
+
if output_classes == 2:
|
| 244 |
+
loss = loss_func(torch.flip(outputs, dims=[1]), 1 - labels)
|
| 245 |
+
else:
|
| 246 |
+
loss = loss_func(outputs, labels)
|
| 247 |
+
|
| 248 |
+
scaler.scale(loss).backward()
|
| 249 |
+
scaler.step(optimizer)
|
| 250 |
+
scaler.update()
|
| 251 |
+
else:
|
| 252 |
+
outputs = model(inputs)
|
| 253 |
+
if output_classes == 2:
|
| 254 |
+
loss = loss_func(torch.flip(outputs, dims=[1]), 1 - labels)
|
| 255 |
+
else:
|
| 256 |
+
loss = loss_func(outputs, labels)
|
| 257 |
+
loss.backward()
|
| 258 |
+
optimizer.step()
|
| 259 |
+
|
| 260 |
+
epoch_loss += loss.item()
|
| 261 |
+
loss_torch[0] += loss.item()
|
| 262 |
+
loss_torch[1] += 1.0
|
| 263 |
+
epoch_len = len(train_loader_w)
|
| 264 |
+
idx_iter += 1
|
| 265 |
+
|
| 266 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 267 |
+
print("[{0}] ".format(str(datetime.now())[:19]) + f"{step}/{epoch_len}, train_loss: {loss.item():.4f}")
|
| 268 |
+
writer.add_scalar("train_loss", loss.item(), epoch_len * epoch + step)
|
| 269 |
+
|
| 270 |
+
if epoch < num_epochs_warmup:
|
| 271 |
+
continue
|
| 272 |
+
|
| 273 |
+
try:
|
| 274 |
+
sample_a = next(dataloader_a_iterator)
|
| 275 |
+
except StopIteration:
|
| 276 |
+
dataloader_a_iterator = iter(train_loader_a)
|
| 277 |
+
sample_a = next(dataloader_a_iterator)
|
| 278 |
+
inputs_search, labels_search = (sample_a["image"].to(device), sample_a["label"].to(device))
|
| 279 |
+
if world_size == 1:
|
| 280 |
+
for _ in model.weight_parameters():
|
| 281 |
+
_.requires_grad = False
|
| 282 |
+
else:
|
| 283 |
+
for _ in model.module.weight_parameters():
|
| 284 |
+
_.requires_grad = False
|
| 285 |
+
dints_space.log_alpha_a.requires_grad = True
|
| 286 |
+
dints_space.log_alpha_c.requires_grad = True
|
| 287 |
+
|
| 288 |
+
# linear increase topology and RAM loss
|
| 289 |
+
entropy_alpha_c = torch.tensor(0.0).to(device)
|
| 290 |
+
entropy_alpha_a = torch.tensor(0.0).to(device)
|
| 291 |
+
ram_cost_full = torch.tensor(0.0).to(device)
|
| 292 |
+
ram_cost_usage = torch.tensor(0.0).to(device)
|
| 293 |
+
ram_cost_loss = torch.tensor(0.0).to(device)
|
| 294 |
+
topology_loss = torch.tensor(0.0).to(device)
|
| 295 |
+
|
| 296 |
+
probs_a, arch_code_prob_a = dints_space.get_prob_a(child=True)
|
| 297 |
+
entropy_alpha_a = -((probs_a) * torch.log(probs_a + 1e-5)).mean()
|
| 298 |
+
entropy_alpha_c = -(
|
| 299 |
+
F.softmax(dints_space.log_alpha_c, dim=-1) * F.log_softmax(dints_space.log_alpha_c, dim=-1)
|
| 300 |
+
).mean()
|
| 301 |
+
topology_loss = dints_space.get_topology_entropy(probs_a)
|
| 302 |
+
|
| 303 |
+
ram_cost_full = dints_space.get_ram_cost_usage(inputs.shape, full=True)
|
| 304 |
+
ram_cost_usage = dints_space.get_ram_cost_usage(inputs.shape)
|
| 305 |
+
ram_cost_loss = torch.abs(ram_cost_factor - ram_cost_usage / ram_cost_full)
|
| 306 |
+
|
| 307 |
+
arch_optimizer_a.zero_grad()
|
| 308 |
+
arch_optimizer_c.zero_grad()
|
| 309 |
+
|
| 310 |
+
combination_weights = (epoch - num_epochs_warmup) / (num_epochs - num_epochs_warmup)
|
| 311 |
+
|
| 312 |
+
if amp:
|
| 313 |
+
with autocast():
|
| 314 |
+
outputs_search = model(inputs_search)
|
| 315 |
+
if output_classes == 2:
|
| 316 |
+
loss = loss_func(torch.flip(outputs_search, dims=[1]), 1 - labels_search)
|
| 317 |
+
else:
|
| 318 |
+
loss = loss_func(outputs_search, labels_search)
|
| 319 |
+
|
| 320 |
+
loss += combination_weights * (
|
| 321 |
+
(entropy_alpha_a + entropy_alpha_c) + ram_cost_loss + 0.001 * topology_loss
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
scaler.scale(loss).backward()
|
| 325 |
+
scaler.step(arch_optimizer_a)
|
| 326 |
+
scaler.step(arch_optimizer_c)
|
| 327 |
+
scaler.update()
|
| 328 |
+
else:
|
| 329 |
+
outputs_search = model(inputs_search)
|
| 330 |
+
if output_classes == 2:
|
| 331 |
+
loss = loss_func(torch.flip(outputs_search, dims=[1]), 1 - labels_search)
|
| 332 |
+
else:
|
| 333 |
+
loss = loss_func(outputs_search, labels_search)
|
| 334 |
+
|
| 335 |
+
loss += 1.0 * (
|
| 336 |
+
combination_weights * (entropy_alpha_a + entropy_alpha_c) + ram_cost_loss + 0.001 * topology_loss
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
loss.backward()
|
| 340 |
+
arch_optimizer_a.step()
|
| 341 |
+
arch_optimizer_c.step()
|
| 342 |
+
|
| 343 |
+
epoch_loss_arch += loss.item()
|
| 344 |
+
loss_torch_arch[0] += loss.item()
|
| 345 |
+
loss_torch_arch[1] += 1.0
|
| 346 |
+
|
| 347 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 348 |
+
print(
|
| 349 |
+
"[{0}] ".format(str(datetime.now())[:19])
|
| 350 |
+
+ f"{step}/{epoch_len}, train_loss_arch: {loss.item():.4f}"
|
| 351 |
+
)
|
| 352 |
+
writer.add_scalar("train_loss_arch", loss.item(), epoch_len * epoch + step)
|
| 353 |
+
|
| 354 |
+
# synchronizes all processes and reduce results
|
| 355 |
+
if torch.cuda.device_count() > 1:
|
| 356 |
+
dist.barrier()
|
| 357 |
+
dist.all_reduce(loss_torch, op=torch.distributed.ReduceOp.SUM)
|
| 358 |
+
|
| 359 |
+
loss_torch = loss_torch.tolist()
|
| 360 |
+
loss_torch_arch = loss_torch_arch.tolist()
|
| 361 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 362 |
+
loss_torch_epoch = loss_torch[0] / loss_torch[1]
|
| 363 |
+
print(
|
| 364 |
+
f"epoch {epoch + 1} average loss: {loss_torch_epoch:.4f}, "
|
| 365 |
+
f"best mean dice: {best_metric:.4f} at epoch {best_metric_epoch}"
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
if epoch >= num_epochs_warmup:
|
| 369 |
+
loss_torch_arch_epoch = loss_torch_arch[0] / loss_torch_arch[1]
|
| 370 |
+
print(
|
| 371 |
+
f"epoch {epoch + 1} average arch loss: {loss_torch_arch_epoch:.4f}, "
|
| 372 |
+
f"best mean dice: {best_metric:.4f} at epoch {best_metric_epoch}"
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
if (epoch + 1) % val_interval == 0 or (epoch + 1) == num_epochs:
|
| 376 |
+
torch.cuda.empty_cache()
|
| 377 |
+
model.eval()
|
| 378 |
+
with torch.no_grad():
|
| 379 |
+
metric = torch.zeros((output_classes - 1) * 2, dtype=torch.float, device=device)
|
| 380 |
+
metric_sum = 0.0
|
| 381 |
+
metric_count = 0
|
| 382 |
+
metric_mat = []
|
| 383 |
+
val_images = None
|
| 384 |
+
val_labels = None
|
| 385 |
+
val_outputs = None
|
| 386 |
+
|
| 387 |
+
_index = 0
|
| 388 |
+
for val_data in val_loader:
|
| 389 |
+
val_images = val_data["image"].to(device)
|
| 390 |
+
val_labels = val_data["label"].to(device)
|
| 391 |
+
|
| 392 |
+
roi_size = patch_size_valid
|
| 393 |
+
sw_batch_size = num_sw_batch_size
|
| 394 |
+
|
| 395 |
+
if amp:
|
| 396 |
+
with torch.cuda.amp.autocast():
|
| 397 |
+
pred = sliding_window_inference(
|
| 398 |
+
val_images,
|
| 399 |
+
roi_size,
|
| 400 |
+
sw_batch_size,
|
| 401 |
+
lambda x: model(x),
|
| 402 |
+
mode="gaussian",
|
| 403 |
+
overlap=overlap_ratio,
|
| 404 |
+
)
|
| 405 |
+
else:
|
| 406 |
+
pred = sliding_window_inference(
|
| 407 |
+
val_images,
|
| 408 |
+
roi_size,
|
| 409 |
+
sw_batch_size,
|
| 410 |
+
lambda x: model(x),
|
| 411 |
+
mode="gaussian",
|
| 412 |
+
overlap=overlap_ratio,
|
| 413 |
+
)
|
| 414 |
+
val_outputs = pred
|
| 415 |
+
|
| 416 |
+
val_outputs = post_pred(val_outputs[0, ...])
|
| 417 |
+
val_outputs = val_outputs[None, ...]
|
| 418 |
+
val_labels = post_label(val_labels[0, ...])
|
| 419 |
+
val_labels = val_labels[None, ...]
|
| 420 |
+
|
| 421 |
+
value = compute_dice(y_pred=val_outputs, y=val_labels, include_background=False)
|
| 422 |
+
|
| 423 |
+
print(_index + 1, "/", len(val_loader), value)
|
| 424 |
+
|
| 425 |
+
metric_count += len(value)
|
| 426 |
+
metric_sum += value.sum().item()
|
| 427 |
+
metric_vals = value.cpu().numpy()
|
| 428 |
+
if len(metric_mat) == 0:
|
| 429 |
+
metric_mat = metric_vals
|
| 430 |
+
else:
|
| 431 |
+
metric_mat = np.concatenate((metric_mat, metric_vals), axis=0)
|
| 432 |
+
|
| 433 |
+
for _c in range(output_classes - 1):
|
| 434 |
+
val0 = torch.nan_to_num(value[0, _c], nan=0.0)
|
| 435 |
+
val1 = 1.0 - torch.isnan(value[0, 0]).float()
|
| 436 |
+
metric[2 * _c] += val0 * val1
|
| 437 |
+
metric[2 * _c + 1] += val1
|
| 438 |
+
|
| 439 |
+
_index += 1
|
| 440 |
+
|
| 441 |
+
# synchronizes all processes and reduce results
|
| 442 |
+
if torch.cuda.device_count() > 1:
|
| 443 |
+
dist.barrier()
|
| 444 |
+
dist.all_reduce(metric, op=torch.distributed.ReduceOp.SUM)
|
| 445 |
+
|
| 446 |
+
metric = metric.tolist()
|
| 447 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 448 |
+
for _c in range(output_classes - 1):
|
| 449 |
+
print("evaluation metric - class {0:d}:".format(_c + 1), metric[2 * _c] / metric[2 * _c + 1])
|
| 450 |
+
avg_metric = 0
|
| 451 |
+
for _c in range(output_classes - 1):
|
| 452 |
+
avg_metric += metric[2 * _c] / metric[2 * _c + 1]
|
| 453 |
+
avg_metric = avg_metric / float(output_classes - 1)
|
| 454 |
+
print("avg_metric", avg_metric)
|
| 455 |
+
|
| 456 |
+
if avg_metric > best_metric:
|
| 457 |
+
best_metric = avg_metric
|
| 458 |
+
best_metric_epoch = epoch + 1
|
| 459 |
+
best_metric_iterations = idx_iter
|
| 460 |
+
|
| 461 |
+
(node_a_d, arch_code_a_d, arch_code_c_d, arch_code_a_max_d) = dints_space.decode()
|
| 462 |
+
torch.save(
|
| 463 |
+
{
|
| 464 |
+
"node_a": node_a_d,
|
| 465 |
+
"arch_code_a": arch_code_a_d,
|
| 466 |
+
"arch_code_a_max": arch_code_a_max_d,
|
| 467 |
+
"arch_code_c": arch_code_c_d,
|
| 468 |
+
"iter_num": idx_iter,
|
| 469 |
+
"epochs": epoch + 1,
|
| 470 |
+
"best_dsc": best_metric,
|
| 471 |
+
"best_path": best_metric_iterations,
|
| 472 |
+
},
|
| 473 |
+
os.path.join(arch_ckpt_path, "search_code_" + str(idx_iter) + ".pt"),
|
| 474 |
+
)
|
| 475 |
+
print("saved new best metric model")
|
| 476 |
+
|
| 477 |
+
dict_file = {}
|
| 478 |
+
dict_file["best_avg_dice_score"] = float(best_metric)
|
| 479 |
+
dict_file["best_avg_dice_score_epoch"] = int(best_metric_epoch)
|
| 480 |
+
dict_file["best_avg_dice_score_iteration"] = int(idx_iter)
|
| 481 |
+
with open(os.path.join(arch_ckpt_path, "progress.yaml"), "w") as out_file:
|
| 482 |
+
_ = yaml.dump(dict_file, stream=out_file)
|
| 483 |
+
|
| 484 |
+
print(
|
| 485 |
+
"current epoch: {} current mean dice: {:.4f} best mean dice: {:.4f} at epoch {}".format(
|
| 486 |
+
epoch + 1, avg_metric, best_metric, best_metric_epoch
|
| 487 |
+
)
|
| 488 |
+
)
|
| 489 |
+
|
| 490 |
+
current_time = time.time()
|
| 491 |
+
elapsed_time = (current_time - start_time) / 60.0
|
| 492 |
+
with open(os.path.join(arch_ckpt_path, "accuracy_history.csv"), "a") as f:
|
| 493 |
+
f.write(
|
| 494 |
+
"{0:d}\t{1:.5f}\t{2:.5f}\t{3:.5f}\t{4:.1f}\t{5:d}\n".format(
|
| 495 |
+
epoch + 1, avg_metric, loss_torch_epoch, lr, elapsed_time, idx_iter
|
| 496 |
+
)
|
| 497 |
+
)
|
| 498 |
+
|
| 499 |
+
if torch.cuda.device_count() > 1:
|
| 500 |
+
dist.barrier()
|
| 501 |
+
|
| 502 |
+
torch.cuda.empty_cache()
|
| 503 |
+
|
| 504 |
+
print(f"train completed, best_metric: {best_metric:.4f} at epoch: {best_metric_epoch}")
|
| 505 |
+
|
| 506 |
+
if torch.cuda.device_count() == 1 or dist.get_rank() == 0:
|
| 507 |
+
writer.close()
|
| 508 |
+
|
| 509 |
+
if torch.cuda.device_count() > 1:
|
| 510 |
+
dist.destroy_process_group()
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
if __name__ == "__main__":
|
| 514 |
+
from monai.utils import optional_import
|
| 515 |
+
|
| 516 |
+
fire, _ = optional_import("fire")
|
| 517 |
+
fire.Fire()
|