
_id
string | id
string | author
string | baseModels
dict | downloads
int64 | downloads_all_time
int64 | gated
string | created_at
timestamp[us, tz=UTC] | last_modified
timestamp[us, tz=UTC] | library_name
string | likes
int64 | trending_score
float64 | model_index
string | pipeline_tag
string | safetensors
string | siblings
list | sizes
list | total_size
int64 | sha
string | tags
list | gguf
string | card
string | spaces
list | licenses
list | datasets
list | languages
list | safetensors_params
float64 | gguf_params
float64 | tasks
list | metrics
list | architectures
list | modalities
list | input_modalities
list | output_modalities
list | org_model
string | org_type
string | org_country
list | a_gated
string | a_baseModels
string | a_input_modalities
list | a_output_modalities
list | a_architectures
list | a_languages
list | a_training_methods
list | a_ddpa
string | annotator
int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
68a48e63edb05188cb234917
|
Kijai/WanVideo_comfy_GGUF
|
Kijai
|
{
"models": [
{
"_id": "68a2e834fdfab51069736146",
"id": "MeiGen-AI/InfiniteTalk"
}
],
"relation": "quantized"
}
| 12,072
| 12,072
|
False
| 2025-08-19T14:46:59Z
| 2025-08-23T14:34:49Z
|
diffusion-single-file
| 29
| 18
| null | null | null |
[
".gitattributes",
"InfiniteTalk/Wan2_1-InfiniteTalk_Multi_Q4_K_M.gguf",
"InfiniteTalk/Wan2_1-InfiniteTalk_Multi_Q6_K.gguf",
"InfiniteTalk/Wan2_1-InfiniteTalk_Multi_Q8.gguf",
"InfiniteTalk/Wan2_1-InfiniteTalk_Single_Q4_K_M.gguf",
"InfiniteTalk/Wan2_1-InfiniteTalk_Single_Q6_K.gguf",
"InfiniteTalk/Wan2_1-InfiniteTalk_Single_Q8.gguf",
"README.md",
"VACE/Wan2_1-VACE_module_14B_Q4_K_M.gguf",
"VACE/Wan2_1-VACE_module_14B_Q8_0.gguf"
] |
[
2182,
1403374240,
2044273312,
2646330016,
1403374240,
2044273312,
2646330016,
304,
1979522560,
3248463360
] | 17,415,943,542
|
80e4d2a071db521045b975237ba4c470f3cb7a91
|
[
"diffusion-single-file",
"gguf",
"comfyui",
"base_model:MeiGen-AI/InfiniteTalk",
"base_model:quantized:MeiGen-AI/InfiniteTalk",
"license:apache-2.0",
"region:us"
] |
{"total": 2487168000, "architecture": "wan"}
|
Various GGUF quants of WanVideo models and modules, mainly for ComfyUI usage.
---
InfiniteTalk:
[MeiGen-AI/InfiniteTalk](https://huggingface.co/MeiGen-AI/InfiniteTalk)
| null |
[
"apache-2.0"
] | null | null | null | 2,487,168,000
| null | null |
[
"wan"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a6d1a73fccbb7547b6507b
|
unsloth/DeepSeek-V3.1-GGUF
|
unsloth
|
{
"models": [
{
"_id": "68a686808e8db90f8998697a",
"id": "deepseek-ai/DeepSeek-V3.1"
}
],
"relation": "quantized"
}
| 32,326
| 32,326
|
False
| 2025-08-21T07:58:31Z
| 2025-08-31T06:13:25Z
|
transformers
| 68
| 18
| null | null | null |
[
".gitattributes",
"BF16/DeepSeek-V3.1-BF16-00001-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00002-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00003-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00004-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00005-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00006-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00007-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00008-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00009-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00010-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00011-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00012-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00013-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00014-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00015-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00016-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00017-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00018-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00019-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00020-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00021-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00022-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00023-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00024-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00025-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00026-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00027-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00028-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00029-of-00030.gguf",
"BF16/DeepSeek-V3.1-BF16-00030-of-00030.gguf",
"DeepSeek-V3.1-UD-TQ1_0.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00001-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00002-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00003-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00004-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00005-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00006-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00007-of-00008.gguf",
"IQ4_NL/DeepSeek-V3.1-IQ4_NL-00008-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00001-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00002-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00003-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00004-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00005-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00006-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00007-of-00008.gguf",
"IQ4_XS/DeepSeek-V3.1-IQ4_XS-00008-of-00008.gguf",
"Q2_K/DeepSeek-V3.1-Q2_K-00001-of-00005.gguf",
"Q2_K/DeepSeek-V3.1-Q2_K-00002-of-00005.gguf",
"Q2_K/DeepSeek-V3.1-Q2_K-00003-of-00005.gguf",
"Q2_K/DeepSeek-V3.1-Q2_K-00004-of-00005.gguf",
"Q2_K/DeepSeek-V3.1-Q2_K-00005-of-00005.gguf",
"Q2_K_L/DeepSeek-V3.1-Q2_K_L-00001-of-00005.gguf",
"Q2_K_L/DeepSeek-V3.1-Q2_K_L-00002-of-00005.gguf",
"Q2_K_L/DeepSeek-V3.1-Q2_K_L-00003-of-00005.gguf",
"Q2_K_L/DeepSeek-V3.1-Q2_K_L-00004-of-00005.gguf",
"Q2_K_L/DeepSeek-V3.1-Q2_K_L-00005-of-00005.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00001-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00002-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00003-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00004-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00005-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00006-of-00007.gguf",
"Q3_K_M/DeepSeek-V3.1-Q3_K_M-00007-of-00007.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00001-of-00006.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00002-of-00006.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00003-of-00006.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00004-of-00006.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00005-of-00006.gguf",
"Q3_K_S/DeepSeek-V3.1-Q3_K_S-00006-of-00006.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00001-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00002-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00003-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00004-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00005-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00006-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00007-of-00008.gguf",
"Q4_0/DeepSeek-V3.1-Q4_0-00008-of-00008.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00001-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00002-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00003-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00004-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00005-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00006-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00007-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00008-of-00009.gguf",
"Q4_1/DeepSeek-V3.1-Q4_1-00009-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00001-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00002-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00003-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00004-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00005-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00006-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00007-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00008-of-00009.gguf",
"Q4_K_M/DeepSeek-V3.1-Q4_K_M-00009-of-00009.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00001-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00002-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00003-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00004-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00005-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00006-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00007-of-00008.gguf",
"Q4_K_S/DeepSeek-V3.1-Q4_K_S-00008-of-00008.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00001-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00002-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00003-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00004-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00005-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00006-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00007-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00008-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00009-of-00010.gguf",
"Q5_K_M/DeepSeek-V3.1-Q5_K_M-00010-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00001-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00002-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00003-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00004-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00005-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00006-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00007-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00008-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00009-of-00010.gguf",
"Q5_K_S/DeepSeek-V3.1-Q5_K_S-00010-of-00010.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00001-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00002-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00003-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00004-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00005-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00006-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00007-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00008-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00009-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00010-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00011-of-00012.gguf",
"Q6_K/DeepSeek-V3.1-Q6_K-00012-of-00012.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00001-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00002-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00003-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00004-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00005-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00006-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00007-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00008-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00009-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00010-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00011-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00012-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00013-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00014-of-00015.gguf",
"Q8_0/DeepSeek-V3.1-Q8_0-00015-of-00015.gguf",
"README.md",
"UD-IQ1_M/DeepSeek-V3.1-UD-IQ1_M-00001-of-00005.gguf",
"UD-IQ1_M/DeepSeek-V3.1-UD-IQ1_M-00002-of-00005.gguf",
"UD-IQ1_M/DeepSeek-V3.1-UD-IQ1_M-00003-of-00005.gguf",
"UD-IQ1_M/DeepSeek-V3.1-UD-IQ1_M-00004-of-00005.gguf",
"UD-IQ1_M/DeepSeek-V3.1-UD-IQ1_M-00005-of-00005.gguf",
"UD-IQ1_S/DeepSeek-V3.1-UD-IQ1_S-00001-of-00004.gguf",
"UD-IQ1_S/DeepSeek-V3.1-UD-IQ1_S-00002-of-00004.gguf",
"UD-IQ1_S/DeepSeek-V3.1-UD-IQ1_S-00003-of-00004.gguf",
"UD-IQ1_S/DeepSeek-V3.1-UD-IQ1_S-00004-of-00004.gguf",
"UD-IQ2_M/DeepSeek-V3.1-UD-IQ2_M-00001-of-00005.gguf",
"UD-IQ2_M/DeepSeek-V3.1-UD-IQ2_M-00002-of-00005.gguf",
"UD-IQ2_M/DeepSeek-V3.1-UD-IQ2_M-00003-of-00005.gguf",
"UD-IQ2_M/DeepSeek-V3.1-UD-IQ2_M-00004-of-00005.gguf",
"UD-IQ2_M/DeepSeek-V3.1-UD-IQ2_M-00005-of-00005.gguf",
"UD-IQ2_XXS/DeepSeek-V3.1-UD-IQ2_XXS-00001-of-00005.gguf",
"UD-IQ2_XXS/DeepSeek-V3.1-UD-IQ2_XXS-00002-of-00005.gguf",
"UD-IQ2_XXS/DeepSeek-V3.1-UD-IQ2_XXS-00003-of-00005.gguf",
"UD-IQ2_XXS/DeepSeek-V3.1-UD-IQ2_XXS-00004-of-00005.gguf",
"UD-IQ2_XXS/DeepSeek-V3.1-UD-IQ2_XXS-00005-of-00005.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00001-of-00006.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00002-of-00006.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00003-of-00006.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00004-of-00006.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00005-of-00006.gguf",
"UD-IQ3_XXS/DeepSeek-V3.1-UD-IQ3_XXS-00006-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00001-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00002-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00003-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00004-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00005-of-00006.gguf",
"UD-Q2_K_XL/DeepSeek-V3.1-UD-Q2_K_XL-00006-of-00006.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00001-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00002-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00003-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00004-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00005-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00006-of-00007.gguf",
"UD-Q3_K_XL/DeepSeek-V3.1-UD-Q3_K_XL-00007-of-00007.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00001-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00002-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00003-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00004-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00005-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00006-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00007-of-00008.gguf",
"UD-Q4_K_XL/DeepSeek-V3.1-UD-Q4_K_XL-00008-of-00008.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00001-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00002-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00003-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00004-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00005-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00006-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00007-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00008-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00009-of-00010.gguf",
"UD-Q5_K_XL/DeepSeek-V3.1-UD-Q5_K_XL-00010-of-00010.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00001-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00002-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00003-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00004-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00005-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00006-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00007-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00008-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00009-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00010-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00011-of-00012.gguf",
"UD-Q6_K_XL/DeepSeek-V3.1-UD-Q6_K_XL-00012-of-00012.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00001-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00002-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00003-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00004-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00005-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00006-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00007-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00008-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00009-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00010-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00011-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00012-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00013-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00014-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00015-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00016-of-00017.gguf",
"UD-Q8_K_XL/DeepSeek-V3.1-UD-Q8_K_XL-00017-of-00017.gguf",
"imatrix_unsloth.gguf_file",
"params",
"template"
] |
[
23625,
43879929504,
46036554112,
46036554112,
46036554112,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
46036554144,
47889912288,
7516250400,
170499768256,
47898444128,
49737219584,
49845588992,
49851008128,
49737219584,
49845588992,
49851008128,
32369874144,
49360384768,
49116857600,
49116857600,
49116857600,
49116857600,
49116857600,
49116857600,
14285795872,
49744376896,
48841516736,
49138270304,
49219614272,
48752803936,
49961567296,
48841516736,
49138270304,
49219614272,
48752803936,
49880134560,
49398590880,
49398590880,
49398590880,
49398590880,
49398590880,
23577994048,
48442256160,
49740125728,
49740125728,
49740125728,
49740125728,
43045598880,
48862740832,
49737219584,
49845588992,
49851008128,
49737219584,
49845588992,
49851008128,
32369874144,
48226142592,
48124218336,
48000042368,
48118799232,
48124218336,
48000042368,
48118799232,
48124218336,
35934639328,
48473901440,
49549016448,
49657385856,
48386509952,
49543597312,
48386509952,
49549016448,
47035800288,
14816275232,
49827037536,
49737219584,
49845588992,
49851008128,
49737219584,
49845588992,
49851008128,
32369874144,
49669538304,
48584741856,
48584741856,
48584741856,
48584741856,
48584741856,
48584741856,
48584741856,
47479005920,
38919656544,
47620407808,
47586497504,
47586497504,
47586497504,
47586497504,
47586497504,
47586497504,
47586497504,
47586497504,
34320065344,
47152398720,
47270390560,
47270390624,
47270390624,
47270390624,
47270390624,
47270390624,
47270390624,
47270390624,
47270390624,
47270390624,
31457090240,
47784556448,
48927728256,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
48927728320,
29441495680,
12540,
48917664992,
48421509248,
49056503936,
49152727168,
11276248000,
49898294784,
49914135040,
49865578496,
42636335488,
49537013056,
49222757952,
48647202656,
49076135904,
39026143008,
48771619904,
49279541216,
49437776096,
49274134496,
29116058880,
49517882144,
48665638432,
49334548160,
48758040384,
48522804512,
34897577472,
49989772224,
48565530304,
49649872704,
49277509568,
48894440896,
9347951392,
50002621216,
49868813728,
49709690688,
49305847072,
49313215904,
48571022880,
3253498368,
48360767840,
49481698560,
48547478912,
48608793472,
48504409344,
48504208768,
48154284928,
46751401472,
48631107840,
49727329216,
48347403232,
49727329248,
48758445024,
48758445024,
48758445024,
48758445024,
47157400416,
45957797088,
47950631296,
47939185184,
49766881984,
49588622432,
48314473312,
47404309344,
47404309344,
47404309344,
47404309344,
47404309344,
47404309344,
46482842432,
47011932160,
47353915904,
49045693120,
46154867360,
48552964544,
47353915936,
49045693120,
49045693120,
49045693120,
49045693120,
49045693120,
49045693120,
49045693120,
49045693120,
49045693120,
46154867360,
7531790592,
1007096000,
247,
1671
] | 11,067,009,245,283
|
f938c2568d34511a0e9fb5d340c7050a9df3cb13
|
[
"transformers",
"gguf",
"deepseek",
"deepseek_v3",
"unsloth",
"arxiv:2412.19437",
"base_model:deepseek-ai/DeepSeek-V3.1",
"base_model:quantized:deepseek-ai/DeepSeek-V3.1",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 671026419200, "architecture": "deepseek2", "context_length": 163840, "quantize_imatrix_file": "DeepSeek-V3.1-GGUF/imatrix_unsloth.gguf", "chat_template": "{#- Unsloth template fixes #}{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% if enable_thinking is defined and enable_thinking is false %}{% set thinking = false %}{% elif enable_thinking is defined and enable_thinking is true %}{% set thinking = true %}{% elif not thinking is defined %}{% set thinking = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, system_prompt='', is_first_sp=true, is_last_user=false) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '\n\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{%- set ns.is_first = false -%}{%- set ns.is_last_user = true -%}{{'<\uff5cUser\uff5c>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['tool_calls'] is defined and message['tool_calls'] is not none %}{%- if ns.is_last_user %}{{'<\uff5cAssistant\uff5c></think>'}}{%- endif %}{%- set ns.is_last_user = false -%}{%- set ns.is_first = false %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<\uff5ctool\u2581calls\u2581begin\uff5c><\uff5ctool\u2581call\u2581begin\uff5c>'+ tool['function']['name'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['arguments'] + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- else %}{{message['content'] + '<\uff5ctool\u2581calls\u2581begin\uff5c><\uff5ctool\u2581call\u2581begin\uff5c>' + tool['function']['name'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['arguments'] + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'<\uff5ctool\u2581call\u2581begin\uff5c>'+ tool['function']['name'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['arguments'] + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- endif %}{%- endfor %}{{'<\uff5ctool\u2581calls\u2581end\uff5c><\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- if message['role'] == 'assistant' and (message['tool_calls'] is not defined or message['tool_calls'] is none) %}{%- if ns.is_last_user %}{{'<\uff5cAssistant\uff5c>'}}{%- if message['prefix'] is defined and message['prefix'] and thinking %}{{'<think>'}} {%- else %}{{'</think>'}}{%- endif %}{%- endif %}{%- set ns.is_last_user = false -%}{%- if ns.is_tool %}{{message['content'] + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- set ns.is_tool = false -%}{%- else %}{%- set content = message['content'] -%}{%- if '</think>' in content %}{%- set splitted = content.split('</think>') -%}{%- set content = splitted[1:] | join('</think>') -%}{%- endif %}{{content + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_last_user = false -%}{%- set ns.is_tool = true -%}{{'<\uff5ctool\u2581output\u2581begin\uff5c>' + message['content'] + '<\uff5ctool\u2581output\u2581end\uff5c>'}}{%- endif %}{%- endfor -%}{%- if add_generation_prompt and ns.is_last_user and not ns.is_tool %}{{'<\uff5cAssistant\uff5c>'}}{%- if not thinking %}{{'</think>'}}{%- else %}{{'<think>'}}{%- endif %}{% endif %}{#- Copyright 2025-present Unsloth. Apache 2.0 License. #}", "bos_token": "<\uff5cbegin\u2581of\u2581sentence\uff5c>", "eos_token": "<\uff5cend\u2581of\u2581sentence\uff5c>"}
|
<div>
<p style="margin-bottom: 0; margin-top: 0;">
<strong>Learn how to run DeepSeek-V3.1 correctly - <a href="https://docs.unsloth.ai/basics/deepseek-v3.1">Read our Guide</a>.</strong>
</p>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/basics/deepseek-v3.1-how-to-run-locally">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
<h1 style="margin-top: 0rem;">🐋 DeepSeek-V3.1 Usage Guidelines</h1>
</div>
These quants include our Unsloth chat template fixes, specifically for llama.cpp supported backends.
- You must use --jinja for llama.cpp quants
- Set the temperature **~0.6** (recommended) and Top_P value of **0.95** (recommended)
- UD-Q2_K_XL (247GB) is recommended
- For complete detailed instructions, see our guide: [unsloth.ai/blog/deepseek-v3.1](https://docs.unsloth.ai/basics/deepseek-v3.1)
<br>
# DeepSeek-V3.1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20V3-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## Introduction
DeepSeek-V3.1 is a hybrid model that supports both thinking mode and non-thinking mode. Compared to the previous version, this upgrade brings improvements in multiple aspects:
- **Hybrid thinking mode**: One model supports both thinking mode and non-thinking mode by changing the chat template.
- **Smarter tool calling**: Through post-training optimization, the model's performance in tool usage and agent tasks has significantly improved.
- **Higher thinking efficiency**: DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
DeepSeek-V3.1 is post-trained on the top of DeepSeek-V3.1-Base, which is built upon the original V3 base checkpoint through a two-phase long context extension approach, following the methodology outlined in the original DeepSeek-V3 report. We have expanded our dataset by collecting additional long documents and substantially extending both training phases. The 32K extension phase has been increased 10-fold to 630B tokens, while the 128K extension phase has been extended by 3.3x to 209B tokens. Additionally, DeepSeek-V3.1 is trained using the UE8M0 FP8 scale data format to ensure compatibility with microscaling data formats.
## Model Downloads
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-V3.1-Base | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Base) |
| DeepSeek-V3.1 | 671B | 37B | 128K | [HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-V3.1) \| [ModelScope](https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1) |
</div>
## Chat Template
The details of our chat template is described in `tokenizer_config.json` and `assets/chat_template.jinja`. Here is a brief description.
### Non-Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>`
With the given prefix, DeepSeek V3.1 generates responses to queries in non-thinking mode. Unlike DeepSeek V3, it introduces an additional token `</think>`.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|></think>`
By concatenating the context and the prefix, we obtain the correct prompt for the query.
### Thinking
#### First-Turn
Prefix:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|><think>`
The prefix of thinking mode is similar to DeepSeek-R1.
#### Multi-Turn
Context:
`<|begin▁of▁sentence|>{system prompt}<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>...<|User|>{query}<|Assistant|></think>{response}<|end▁of▁sentence|>`
Prefix:
`<|User|>{query}<|Assistant|><think>`
The multi-turn template is the same with non-thinking multi-turn chat template. It means the thinking token in the last turn will be dropped but the `</think>` is retained in every turn of context.
### ToolCall
Toolcall is supported in non-thinking mode. The format is:
`<|begin▁of▁sentence|>{system prompt}{tool_description}<|User|>{query}<|Assistant|></think>` where the tool_description is
```
## Tools
You have access to the following tools:
### {tool_name1}
Description: {description}
Parameters: {json.dumps(parameters)}
IMPORTANT: ALWAYS adhere to this exact format for tool use:
<|tool▁calls▁begin|><|tool▁call▁begin|>tool_call_name<|tool▁sep|>tool_call_arguments<|tool▁call▁end|>{{additional_tool_calls}}<|tool▁calls▁end|>
Where:
- `tool_call_name` must be an exact match to one of the available tools
- `tool_call_arguments` must be valid JSON that strictly follows the tool's Parameters Schema
- For multiple tool calls, chain them directly without separators or spaces
```
### Code-Agent
We support various code agent frameworks. Please refer to the above toolcall format to create your own code agents. An example is shown in `assets/code_agent_trajectory.html`.
### Search-Agent
We design a specific format for searching toolcall in thinking mode, to support search agent.
For complex questions that require accessing external or up-to-date information, DeepSeek-V3.1 can leverage a user-provided search tool through a multi-turn tool-calling process.
Please refer to the `assets/search_tool_trajectory.html` and `assets/search_python_tool_trajectory.html` for the detailed template.
## Evaluation
| Category | Benchmark (Metric) | DeepSeek V3.1-NonThinking | DeepSeek V3 0324 | DeepSeek V3.1-Thinking | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|---|---|
| General |
| | MMLU-Redux (EM) | 91.8 | 90.5 | 93.7 | 93.4
| | MMLU-Pro (EM) | 83.7 | 81.2 | 84.8 | 85.0
| | GPQA-Diamond (Pass@1) | 74.9 | 68.4 | 80.1 | 81.0
| | Humanity's Last Exam (Pass@1) | - | - | 15.9 | 17.7
|Search Agent|
| | BrowseComp | - | - | 30.0 | 8.9
| | BrowseComp_zh | - | - | 49.2 | 35.7
| | Humanity's Last Exam (Python + Search) |- | - | 29.8 | 24.8
| | SimpleQA | - | - | 93.4 | 92.3
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 56.4 | 43.0 | 74.8 | 73.3
| | Codeforces-Div1 (Rating) | - | - | 2091 | 1930
| | Aider-Polyglot (Acc.) | 68.4 | 55.1 | 76.3 | 71.6
| Code Agent|
| | SWE Verified (Agent mode) | 66.0 | 45.4 | - | 44.6
| | SWE-bench Multilingual (Agent mode) | 54.5 | 29.3 | - | 30.5
| | Terminal-bench (Terminus 1 framework) | 31.3 | 13.3 | - | 5.7
| Math |
| | AIME 2024 (Pass@1) | 66.3 | 59.4 | 93.1 | 91.4
| | AIME 2025 (Pass@1) | 49.8 | 51.3 | 88.4 | 87.5
| | HMMT 2025 (Pass@1) | 33.5 | 29.2 | 84.2 | 79.4 |
Note:
- Search agents are evaluated with our internal search framework, which uses a commercial search API + webpage filter + 128K context window. Seach agent results of R1-0528 are evaluated with a pre-defined workflow.
- SWE-bench is evaluated with our internal code agent framework.
- HLE is evaluated with the text-only subset.
### Usage Example
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.1")
messages = [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "<think>Hmm</think>I am DeepSeek"},
{"role": "user", "content": "1+1=?"}
]
tokenizer.apply_chat_template(messages, tokenize=False, thinking=True, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|><think>'
tokenizer.apply_chat_template(messages, tokenize=False, thinking=False, add_generation_prompt=True)
# '<|begin▁of▁sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end▁of▁sentence|><|User|>1+1=?<|Assistant|></think>'
```
## How to Run Locally
The model structure of DeepSeek-V3.1 is the same as DeepSeek-V3. Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running this model locally.
## License
This repository and the model weights are licensed under the [MIT License](LICENSE).
## Citation
```
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
```
## Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
| null |
[
"mit"
] | null | null | null | 671,026,419,200
|
[
null
] | null |
[
"deepseek2",
"AutoModel"
] | null | null | null |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68ac331ec4a4895d6c4ea8cf
|
ESpeech/ESpeech-TTS-1_RL-V2
|
ESpeech
| null | 0
| 0
|
False
| 2025-08-25T09:55:42Z
| 2025-08-25T16:10:17Z
| null | 18
| 18
| null | null | null |
[
".gitattributes",
"README.md",
"espeech_tts_rlv2.pt",
"vocab.txt"
] | null | null |
f582b6e5897fe8a5835059405a8439d13bdf7684
|
[
"TTS",
"F5-TTS",
"ru",
"dataset:ESpeech/ESpeech-webinars2",
"license:apache-2.0",
"region:us"
] | null |
Установите необходимые зависимости:
```
pip install f5-tts gradio ruaccent transformers torch torchaudio huggingface_hub
```
Запустите код и ждите сообщения с адресом веб-интерфейса
```py
#!/usr/bin/env python3
import os
import gc
import tempfile
import traceback
from pathlib import Path
import gradio as gr
import numpy as np
import soundfile as sf
import torch
import torchaudio
from huggingface_hub import hf_hub_download, snapshot_download
from ruaccent import RUAccent
from f5_tts.infer.utils_infer import (
infer_process,
load_model,
load_vocoder,
preprocess_ref_audio_text,
remove_silence_for_generated_wav,
save_spectrogram,
tempfile_kwargs,
)
from f5_tts.model import DiT
MODEL_CFG = dict(dim=1024, depth=22, heads=16, ff_mult=2, text_dim=512, conv_layers=4)
MODEL_REPO = "ESpeech/ESpeech-TTS-1_RL-V2"
MODEL_FILE = "espeech_tts_rlv2.pt"
VOCAB_FILE = "vocab.txt"
loaded_model = None
def ensure_model():
global loaded_model
if loaded_model is not None:
return loaded_model
model_path = None
vocab_path = None
print(f"Trying to download model file '{MODEL_FILE}' and '{VOCAB_FILE}' from hub '{MODEL_REPO}'")
try:
model_path = hf_hub_download(repo_id=MODEL_REPO, filename=MODEL_FILE)
vocab_path = hf_hub_download(repo_id=MODEL_REPO, filename=VOCAB_FILE)
print(f"Downloaded model to {model_path}")
print(f"Downloaded vocab to {vocab_path}")
except Exception as e:
print("hf_hub_download failed:", e)
if model_path is None or vocab_path is None:
try:
local_dir = f"cache_{MODEL_REPO.replace('/', '_')}"
print(f"Attempting snapshot_download into {local_dir}...")
snapshot_dir = snapshot_download(repo_id=MODEL_REPO, cache_dir=None, local_dir=local_dir, token=hf_token)
possible_model = os.path.join(snapshot_dir, MODEL_FILE)
possible_vocab = os.path.join(snapshot_dir, VOCAB_FILE)
if os.path.exists(possible_model):
model_path = possible_model
if os.path.exists(possible_vocab):
vocab_path = possible_vocab
print(f"Snapshot downloaded to {snapshot_dir}")
except Exception as e:
print("snapshot_download failed:", e)
if not model_path or not os.path.exists(model_path):
raise FileNotFoundError(f"Model file not found after download attempts: {model_path}")
if not vocab_path or not os.path.exists(vocab_path):
raise FileNotFoundError(f"Vocab file not found after download attempts: {vocab_path}")
print(f"Loading model from: {model_path}")
loaded_model = load_model(DiT, MODEL_CFG, model_path, vocab_file=vocab_path)
return loaded_model
print("Preloading model...")
try:
ensure_model()
print("Model preloaded.")
except Exception as e:
print(f"Model preload failed: {e}")
print("Loading RUAccent...")
accentizer = RUAccent()
accentizer.load(omograph_model_size='turbo3.1', use_dictionary=True, tiny_mode=False)
print("RUAccent loaded.")
print("Loading vocoder...")
vocoder = load_vocoder()
print("Vocoder loaded.")
def process_text_with_accent(text, accentizer):
if not text or not text.strip():
return text
if '+' in text:
return text
else:
return accentizer.process_all(text)
def process_texts_only(ref_text, gen_text):
processed_ref_text = process_text_with_accent(ref_text, accentizer)
processed_gen_text = process_text_with_accent(gen_text, accentizer)
return processed_ref_text, processed_gen_text
def synthesize(
ref_audio,
ref_text,
gen_text,
remove_silence,
seed,
cross_fade_duration=0.15,
nfe_step=32,
speed=1.0,
):
if not ref_audio:
gr.Warning("Please provide reference audio.")
return None, None, ref_text, gen_text
if seed is None or seed < 0 or seed > 2**31 - 1:
seed = np.random.randint(0, 2**31 - 1)
torch.manual_seed(int(seed))
if not gen_text or not gen_text.strip():
gr.Warning("Please enter text to generate.")
return None, None, ref_text, gen_text
if not ref_text or not ref_text.strip():
gr.Warning("Please provide reference text.")
return None, None, ref_text, gen_text
processed_ref_text = process_text_with_accent(ref_text, accentizer)
processed_gen_text = process_text_with_accent(gen_text, accentizer)
try:
model = ensure_model()
except Exception as e:
gr.Warning(f"Failed to load model: {e}")
return None, None, processed_ref_text, processed_gen_text
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
try:
if device.type == "cuda":
try:
model.to(device)
vocoder.to(device)
except Exception as e:
print("Warning: failed to move model/vocoder to cuda:", e)
try:
ref_audio_proc, processed_ref_text_final = preprocess_ref_audio_text(
ref_audio,
processed_ref_text,
show_info=gr.Info
)
except Exception as e:
gr.Warning(f"Preprocess failed: {e}")
traceback.print_exc()
return None, None, processed_ref_text, processed_gen_text
try:
final_wave, final_sample_rate, combined_spectrogram = infer_process(
ref_audio_proc,
processed_ref_text_final,
processed_gen_text,
model,
vocoder,
cross_fade_duration=cross_fade_duration,
nfe_step=nfe_step,
speed=speed,
show_info=gr.Info,
progress=gr.Progress(),
)
except Exception as e:
gr.Warning(f"Infer failed: {e}")
traceback.print_exc()
return None, None, processed_ref_text, processed_gen_text
if remove_silence:
try:
with tempfile.NamedTemporaryFile(suffix=".wav", **tempfile_kwargs) as f:
temp_path = f.name
sf.write(temp_path, final_wave, final_sample_rate)
remove_silence_for_generated_wav(temp_path)
final_wave_tensor, _ = torchaudio.load(temp_path)
final_wave = final_wave_tensor.squeeze().cpu().numpy()
except Exception as e:
print("Remove silence failed:", e)
try:
with tempfile.NamedTemporaryFile(suffix=".png", **tempfile_kwargs) as tmp_spectrogram:
spectrogram_path = tmp_spectrogram.name
save_spectrogram(combined_spectrogram, spectrogram_path)
except Exception as e:
print("Save spectrogram failed:", e)
spectrogram_path = None
return (final_sample_rate, final_wave), spectrogram_path, processed_ref_text_final, processed_gen_text
finally:
if device.type == "cuda":
try:
model.to("cpu")
vocoder.to("cpu")
torch.cuda.empty_cache()
gc.collect()
except Exception as e:
print("Warning during cuda cleanup:", e)
with gr.Blocks(title="ESpeech-TTS") as app:
gr.Markdown("# ESpeech-TTS")
gr.Markdown("💡 **Совет:** Добавьте символ '+' для ударения (например, 'прив+ет')")
gr.Markdown("❌ **Совет:** Референс должен быть не более 12 секунд")
with gr.Row():
with gr.Column():
ref_audio_input = gr.Audio(label="Reference Audio", type="filepath")
ref_text_input = gr.Textbox(
label="Reference Text",
lines=2,
placeholder="Text corresponding to reference audio"
)
with gr.Column():
gen_text_input = gr.Textbox(
label="Text to Generate",
lines=5,
max_lines=20,
placeholder="Enter text to synthesize..."
)
process_text_btn = gr.Button("✏️ Process Text (Add Accents)", variant="secondary")
with gr.Accordion("Advanced Settings", open=False):
with gr.Row():
seed_input = gr.Number(label="Seed (-1 for random)", value=-1, precision=0)
remove_silence = gr.Checkbox(label="Remove Silences", value=False)
with gr.Row():
speed_slider = gr.Slider(label="Speed", minimum=0.3, maximum=2.0, value=1.0, step=0.1)
nfe_slider = gr.Slider(label="NFE Steps", minimum=4, maximum=64, value=48, step=2)
cross_fade_slider = gr.Slider(label="Cross-Fade Duration (s)", minimum=0.0, maximum=1.0, value=0.15, step=0.01)
generate_btn = gr.Button("🎤 Generate Speech", variant="primary", size="lg")
with gr.Row():
audio_output = gr.Audio(label="Generated Audio", type="numpy")
spectrogram_output = gr.Image(label="Spectrogram", type="filepath")
process_text_btn.click(
process_texts_only,
inputs=[ref_text_input, gen_text_input],
outputs=[ref_text_input, gen_text_input]
)
generate_btn.click(
synthesize,
inputs=[
ref_audio_input,
ref_text_input,
gen_text_input,
remove_silence,
seed_input,
cross_fade_slider,
nfe_slider,
speed_slider,
],
outputs=[audio_output, spectrogram_output, ref_text_input, gen_text_input]
)
if __name__ == "__main__":
app.launch()
```
|
[
"Den4ikAI/ESpeech-TTS"
] |
[
"apache-2.0"
] |
[
"ESpeech/ESpeech-webinars2"
] |
[
"ru"
] | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ac918f75bc0cb57b763bc3
|
OpenGVLab/InternVL3_5-4B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac9193d3bca8f4ccbf1a4c",
"id": "OpenGVLab/InternVL3_5-4B-MPO"
}
],
"relation": "finetune"
}
| 1,712
| 1,712
|
False
| 2025-08-25T16:38:39Z
| 2025-08-29T17:57:05Z
|
transformers
| 18
| 18
| null |
image-text-to-text
|
{"parameters": {"BF16": 4732489216}, "total": 4732489216}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] | null | null |
481f6e32467eab4e922ccd7fd6cf420441a62331
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-4B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-4B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-4B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 4,732,489,216
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac919875bc0cb57b763cd2
|
OpenGVLab/InternVL3_5-14B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac9197b40ceecaf2cd29f1",
"id": "OpenGVLab/InternVL3_5-14B-MPO"
}
],
"relation": "finetune"
}
| 2,044
| 2,044
|
False
| 2025-08-25T16:38:48Z
| 2025-08-29T17:57:02Z
|
transformers
| 18
| 18
| null |
image-text-to-text
|
{"parameters": {"BF16": 15119523840}, "total": 15119523840}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model-00001-of-00007.safetensors",
"model-00002-of-00007.safetensors",
"model-00003-of-00007.safetensors",
"model-00004-of-00007.safetensors",
"model-00005-of-00007.safetensors",
"model-00006-of-00007.safetensors",
"model-00007-of-00007.safetensors",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
53705,
892,
475,
2482,
5546,
4700,
15309,
69,
1671853,
4828063160,
4897177760,
4995650856,
4873990872,
4889632184,
4827651696,
926979528,
72742,
18151,
16518,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 30,255,221,192
|
a1e37197b393ce9eec9df700fef65c11f4a6ffbd
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-14B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-14B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-14B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 15,119,523,840
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68adba848d8eb59e15803747
|
Shakker-Labs/AWPortrait-QW
|
Shakker-Labs
|
{
"models": [
{
"_id": "688d9adf9f62ee5c9a3804eb",
"id": "Qwen/Qwen-Image"
}
],
"relation": "adapter"
}
| 1,278
| 1,278
|
False
| 2025-08-26T13:45:40Z
| 2025-08-26T14:00:49Z
|
diffusers
| 18
| 18
| null |
text-to-image
| null |
[
".gitattributes",
"AWPortrait-QW_1.0.safetensors",
"README.md",
"images/08fdaf6b644b61136340d5c908ca37993e47f34cdbe2e8e8251c4c72.jpg",
"images/7e329cb5f01a81b72219f94f5708a4f258514e810976111fd553986c.jpg",
"images/cover.png",
"images/d722529f47767f3b446c829aa0681f6d155643e80f92e1c62d2f7075.jpg"
] | null | null |
d873eedefccbe8c4b075eae60cd58e552569edf7
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"qwen-image",
"en",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] | null | null |
[
"prithivMLmods/Qwen-Image-LoRA-DLC"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
team
|
community
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68aad845bf149075fd49cfbd
|
unsloth/Seed-OSS-36B-Instruct-GGUF
|
unsloth
|
{
"models": [
{
"_id": "68a5e3be37edead1bf9642f1",
"id": "ByteDance-Seed/Seed-OSS-36B-Instruct"
}
],
"relation": "quantized"
}
| 40,919
| 40,919
|
False
| 2025-08-24T09:15:49Z
| 2025-08-24T11:24:28Z
|
transformers
| 20
| 17
| null |
text-generation
| null |
[
".gitattributes",
"BF16/Seed-OSS-36B-Instruct-BF16-00001-of-00002.gguf",
"BF16/Seed-OSS-36B-Instruct-BF16-00002-of-00002.gguf",
"README.md",
"Seed-OSS-36B-Instruct-IQ4_NL.gguf",
"Seed-OSS-36B-Instruct-IQ4_XS.gguf",
"Seed-OSS-36B-Instruct-Q2_K.gguf",
"Seed-OSS-36B-Instruct-Q2_K_L.gguf",
"Seed-OSS-36B-Instruct-Q3_K_M.gguf",
"Seed-OSS-36B-Instruct-Q3_K_S.gguf",
"Seed-OSS-36B-Instruct-Q4_0.gguf",
"Seed-OSS-36B-Instruct-Q4_1.gguf",
"Seed-OSS-36B-Instruct-Q4_K_M.gguf",
"Seed-OSS-36B-Instruct-Q4_K_S.gguf",
"Seed-OSS-36B-Instruct-Q5_K_M.gguf",
"Seed-OSS-36B-Instruct-Q5_K_S.gguf",
"Seed-OSS-36B-Instruct-Q6_K.gguf",
"Seed-OSS-36B-Instruct-Q8_0.gguf",
"Seed-OSS-36B-Instruct-UD-IQ1_M.gguf",
"Seed-OSS-36B-Instruct-UD-IQ1_S.gguf",
"Seed-OSS-36B-Instruct-UD-IQ2_M.gguf",
"Seed-OSS-36B-Instruct-UD-IQ2_XXS.gguf",
"Seed-OSS-36B-Instruct-UD-IQ3_XXS.gguf",
"Seed-OSS-36B-Instruct-UD-Q2_K_XL.gguf",
"Seed-OSS-36B-Instruct-UD-Q3_K_XL.gguf",
"Seed-OSS-36B-Instruct-UD-Q4_K_XL.gguf",
"Seed-OSS-36B-Instruct-UD-Q5_K_XL.gguf",
"Seed-OSS-36B-Instruct-UD-Q6_K_XL.gguf",
"Seed-OSS-36B-Instruct-UD-Q8_K_XL.gguf",
"imatrix_unsloth.gguf_file"
] |
[
3465,
49980180096,
22331217376,
19821,
20592987296,
19523439776,
13604187296,
13790350496,
17620950176,
15855410336,
20621823136,
22760754336,
21762149536,
20695223456,
25594367136,
24970464416,
29666098336,
38421093536,
9080892576,
8473742496,
12729568416,
10160802976,
14253649056,
14041271456,
18048101536,
22030273696,
25629306016,
31848815776,
42938162336,
16321824
] | 587,041,628,182
|
f862bd43f207278c1481812c11cd6d70fa6f70a8
|
[
"transformers",
"gguf",
"vllm",
"unsloth",
"text-generation",
"base_model:ByteDance-Seed/Seed-OSS-36B-Instruct",
"base_model:quantized:ByteDance-Seed/Seed-OSS-36B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 36151104512, "architecture": "seed_oss", "context_length": 524288, "quantize_imatrix_file": "Seed-OSS-36B-Instruct-GGUF/imatrix_unsloth.gguf", "chat_template": "{# Unsloth Chat template fixes #}\n{# ----------\u2011\u2011\u2011 special token variables \u2011\u2011\u2011---------- #}\n{%- set bos_token = '<seed:bos>' -%}\n{%- set eos_token = '<seed:eos>' -%}\n{%- set pad_token = '<seed:pad>' -%}\n{%- set toolcall_begin_token = '<seed:tool_call>' -%}\n{%- set toolcall_end_token = '</seed:tool_call>' -%}\n{%- set think_begin_token = '<seed:think>' -%}\n{%- set think_end_token = '</seed:think>' -%}\n{%- set budget_begin_token = '<seed:cot_budget_reflect>'-%}\n{%- set budget_end_token = '</seed:cot_budget_reflect>'-%}\n{# -------------- reflection-interval lookup -------------- #}\n{%- if not thinking_budget is defined %}\n{%- set thinking_budget = -1 -%}\n{%- endif -%}\n{%- set budget_reflections_v05 = {\n 0: 0,\n 512: 128,\n 1024: 256,\n 2048: 512,\n 4096: 512,\n 8192: 1024,\n 16384: 1024\n} -%}\n{# \u627e\u5230 \u201c\u5927\u4e8e\u7b49\u4e8e thinking_budget\u201d \u7684\u7b2c\u4e00\u4e2a\u6863\u4f4d #}\n{%- set ns = namespace(interval = None) -%}\n{%- for k, v in budget_reflections_v05 | dictsort -%}\n {%- if ns.interval is none and thinking_budget <= k -%}\n {%- set ns.interval = v -%}\n {%- endif -%}\n{%- endfor -%}\n{# \u82e5\u8d85\u8fc7\u6700\u5927\u6863\u4f4d\uff0c\u5219\u7528\u6700\u540e\u4e00\u4e2a\u6863\u4f4d\u7684\u503c #}\n{%- if ns.interval is none -%}\n {%- set ns.interval = budget_reflections_v05[16384] -%}\n{%- endif -%}\n{# ---------- \u9884\u5904\u7406 system \u6d88\u606f ---------- #}\n{%- if messages[0][\"role\"] == \"system\" %}\n{%- set system_message = messages[0][\"content\"] %}\n{%- set loop_messages = messages[1:] %}\n{%- else %}\n{%- set loop_messages = messages %}\n{%- endif %}\n{# ---------- \u786e\u4fdd tools \u5b58\u5728 ---------- #}\n{%- if not tools is defined or tools is none %}\n{%- set tools = [] %}\n{%- endif %}\n{# tools2doc.jinja #}\n{%- macro py_type(t) -%}\n {%- if t == \"string\" -%}str\n {%- elif t in (\"number\", \"integer\") -%}int\n {%- elif t == \"boolean\" -%}bool\n {%- elif t == \"array\" -%}list\n {%- else -%}Any{%- endif -%}\n{%- endmacro -%}\n{# ---------- \u8f93\u51fa system \u5757 ---------- #}\n{%- if system_message is defined %}\n{{ bos_token + \"system\\n\" + system_message }}\n{%- else %}\n{%- if tools is iterable and tools | length > 0 %}\n{{ bos_token + \"system\\nYou are Doubao, a helpful AI assistant. You may call one or more functions to assist with the user query.\" }}\n{%- endif %}\n{%- endif %}\n{%- if use_json_tooldef is defined and use_json_tooldef %}\n\n{{\"Tool List:\\nYou are authorized to use the following tools (described in JSON Schema format). Before performing any task, you must decide how to call them based on the descriptions and parameters of these tools.\"}}\n{{ tools | tojson|string }}\n{%- else %}\n{%- for item in tools if item.type == \"function\" %}\n\n\nFunction:\ndef {{ item.function.name }}(\n{%- for name, spec in item.function.parameters.properties.items() %}\n {{- name }}: {{ py_type(spec.type) }}{% if not loop.last %},{% endif %}\n{%- endfor %}):\n \"\"\"\n {{ item.function.description | trim }}\n\n {# ---------- Args ---------- #}\n {%- if item.function.parameters.properties %}\n Args:\n {%- for name, spec in item.function.parameters.properties.items() %}\n\n - {{ name }} ({{ py_type(spec.type) }})\n {%- if name in item.function.parameters.required %} [\u5fc5\u586b]{% else %} [\u9009\u586b]{% endif %}:\n {{- \" \" ~ (spec.description or \"\") }}\n {%- endfor %}\n {%- endif %}\n\n {# ---------- Returns ---------- #}\n {%- if item.function.returns is defined\n and item.function.returns.properties is defined\n and item.function.returns.properties %}\n Returns:\n {%- for name, spec in item.function.returns.properties.items() %}\n\n - {{ name }} ({{ py_type(spec.type) }}):\n {{- \" \" ~ (spec.description or \"\") }}\n {%- endfor %}\n {%- endif %}\n\n \"\"\"\n{%- endfor %}\n{%- endif %}\n{%- if tools is iterable and tools | length > 0 %}\n\n{{\"\u5de5\u5177\u8c03\u7528\u8bf7\u9075\u5faa\u5982\u4e0b\u683c\u5f0f:\\n<seed:tool_call>\\n<function=example_function_name>\\n<parameter=example_parameter_1>value_1</parameter>\\n<parameter=example_parameter_2>This is the value for the second parameter\\nthat can span\\nmultiple lines</parameter>\\n</function>\\n</seed:tool_call>\\n\"}}\n{%- endif %}\n{# \u7ed3\u675f system \u5757\u884c\u5c3e #}\n{%- if system_message is defined or tools is iterable and tools | length > 0 %}\n{{ eos_token }}\n{%- endif %}\n{# ---------- Thinking Budget ---------- #}\n{%- if thinking_budget is defined %}\n{%- if thinking_budget == 0 %}\n{{ bos_token+\"system\" }}\n{{ \"You are an intelligent assistant that can answer questions in one step without the need for reasoning and thinking, that is, your thinking budget is 0. Next, please skip the thinking process and directly start answering the user's questions.\" }}\n{{ eos_token }}\n{%- elif not thinking_budget == -1 %}\n{{ bos_token+\"system\" }}\n{{ \"You are an intelligent assistant with reflective ability. In the process of thinking and reasoning, you need to strictly follow the thinking budget, which is \"}}{{thinking_budget}}{{\". That is, you need to complete your thinking within \"}}{{thinking_budget}}{{\" tokens and start answering the user's questions. You will reflect on your thinking process every \"}}{{ns.interval}}{{\" tokens, stating how many tokens have been used and how many are left.\"}}\n{{ eos_token }}\n{%- endif %}\n{%- endif %}\n{# ---------- \u9010\u6761\u5199\u51fa\u5386\u53f2\u6d88\u606f ---------- #}\n{%- for message in loop_messages %}\n{%- if message.role == \"assistant\"\n and message.tool_calls is defined\n and message.tool_calls is iterable\n and message.tool_calls | length > 0 %}\n{{ bos_token + message.role }}\n{%- if message.reasoning_content is defined and message.reasoning_content is string and message.reasoning_content | trim | length > 0 %}\n{{ \"\\n\" + think_begin_token + message.reasoning_content | trim + think_end_token }}\n{%- endif %}\n{%- if message.content is defined and message.content is string and message.content | trim | length > 0 %}\n{{ \"\\n\" + message.content | trim + \"\\n\" }}\n{%- endif %}\n{%- for tool_call in message.tool_calls %}\n{%- if tool_call.function is defined %}{% set tool_call = tool_call.function %}{% endif %}\n{{ \"\\n\" + toolcall_begin_token + \"\\n<function=\" + tool_call.name + \">\\n\" }}\n{%- if tool_call.arguments is defined and tool_call.arguments is mapping %}\n{%- for arg_name, arg_value in tool_call.arguments | items %}\n{{ \"<parameter=\" + arg_name + \">\" }}\n{%- set arg_value = arg_value if arg_value is string else arg_value | string %}\n{{ arg_value+\"</parameter>\\n\" }}\n{%- endfor %}\n{%- endif %}\n{{ \"</function>\\n\" + toolcall_end_token }}\n{%- endfor %}\n{{ eos_token }}\n{%- elif message.role in [\"user\", \"system\"] %}\n{{ bos_token + message.role + \"\\n\" + message.content + eos_token }}\n{%- elif message.role == \"assistant\" %}\n{{ bos_token + message.role }}\n{%- if message.reasoning_content is defined and message.reasoning_content is string and message.reasoning_content | trim | length > 0 %}\n{{ \"\\n\" + think_begin_token + message.reasoning_content | trim + think_end_token }}\n{%- endif %}\n{%- if message.content is defined and message.content is string and message.content | trim | length > 0 %}\n{{ \"\\n\" + message.content | trim + eos_token }}\n{%- endif %}\n{# \u5305\u62ec tool \u89d2\u8272\uff0c\u5728\u8fd9\u4e2a\u903b\u8f91 #}\n{%- else %}\n{{ bos_token + message.role + \"\\n\" + message.content + eos_token }}\n{%- endif %}\n{%- endfor %}\n{# ---------- \u63a7\u5236\u6a21\u578b\u5f00\u59cb\u7eed\u5199 ---------- #}\n{%- if add_generation_prompt %}\n{{ bos_token+\"assistant\\n\" }}\n{%- if thinking_budget == 0 %}\n{{ think_begin_token+budget_begin_token }}\n{%- endif %}\n{%- endif %}\n{# Copyright 2025-present Unsloth. Apache 2.0 License. #}", "bos_token": "<seed:bos>", "eos_token": "<seed:eos>"}
|
<div align="center">
👋 Hi, everyone!
<br>
We are <b>ByteDance Seed Team.</b>
</div>
<p align="center">
You can get to know us better through the following channels👇
<br>
<a href="https://seed.bytedance.com/">
<img src="https://img.shields.io/badge/Website-%231e37ff?style=for-the-badge&logo=bytedance&logoColor=white"></a>
</p>

# Seed-OSS Open-Source Models
<p align="center">
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Project Page-yellow"></a>
<a href="https://github.com/ByteDance-Seed/seed-oss">
<img src="https://img.shields.io/badge/Seed-Tech Report Coming Soon-red"></a>
<a href="https://huggingface.co/ByteDance-Seed">
<img src="https://img.shields.io/badge/Seed-Hugging Face-orange"></a>
<br>
<a href="./LICENSE">
<img src="https://img.shields.io/badge/License-Apache2.0-blue"></a>
</p>
> [!NOTE]
> This model card is dedicated to the `Seed-OSS-36B-Instruct` model.
## News
- [2025/08/20]🔥We release `Seed-OSS-36B-Base` (both with and without synthetic data versions) and `Seed-OSS-36B-Instruct`.
## Introduction
Seed-OSS is a series of open-source large language models developed by ByteDance's Seed Team, designed for powerful long-context, reasoning, agent and general capabilities, and versatile developer-friendly features. Although trained with only 12T tokens, Seed-OSS achieves excellent performance on several popular open benchmarks.
We release this series of models to the open-source community under the Apache-2.0 license.
> [!NOTE]
> Seed-OSS is primarily optimized for international (i18n) use cases.
### Key Features
- **Flexible Control of Thinking Budget**: Allowing users to flexibly adjust the reasoning length as needed. This capability of dynamically controlling the reasoning length enhances inference efficiency in practical application scenarios.
- **Enhanced Reasoning Capability**: Specifically optimized for reasoning tasks while maintaining balanced and excellent general capabilities.
- **Agentic Intelligence**: Performs exceptionally well in agentic tasks such as tool-using and issue resolving.
- **Research-Friendly**: Given that the inclusion of synthetic instruction data in pre-training may affect the post-training research, we released pre-trained models both with and without instruction data, providing the research community with more diverse options.
- **Native Long Context**: Trained with up-to-512K long context natively.
### Model Summary
Seed-OSS adopts the popular causal language model architecture with RoPE, GQA attention, RMSNorm and SwiGLU activation.
<div align="center">
| | |
|:---:|:---:|
| | **Seed-OSS-36B** |
| **Parameters** | 36B |
| **Attention** | GQA |
| **Activation Function** | SwiGLU |
| **Number of Layers** | 64 |
| **Number of QKV Heads** | 80 / 8 / 8 |
| **Head Size** | 128 |
| **Hidden Size** | 5120 |
| **Vocabulary Size** | 155K |
| **Context Length** | 512K |
| **RoPE Base Frequency** | 1e7 |
</div>
## Evaluation Results
### Seed-OSS-36B-Base
Incorporating synthetic instruction data into pretraining leads to improved performance on most benchmarks. We adopt the version augmented with synthetic instruction data (i.e., *w/ syn.*) as `Seed-OSS-36B-Base`. We also release `Seed-OSS-36B-Base-woSyn` trained without such data (i.e., *w/o syn.*), offering the community a high-performance foundation model unaffected by synthetic instruction data.
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://seed.bytedance.com/en/seed1_6">Seed1.6-Base</a></sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Base-2507*</sup></th>
<th align="center"><sup>Qwen2.5-32B-Base*</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base<br>(<i>w/ syn.</i>)</sup></th>
<th align="center"><sup>Seed-OSS-36B-Base-woSyn<br>(<i>w/o syn.</i>)</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=6><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">70</td>
<td align="center">59.8</td>
<td align="center">58.5 (55.1)</td>
<td align="center"><b>65.1</b></td>
<td align="center">60.4</td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">88.8</td>
<td align="center">82.7</td>
<td align="center">84 (83.3)</td>
<td align="center"><b>84.9</b></td>
<td align="center">84.8</td>
</tr>
<tr>
<td align="center">TriviaQA</td>
<td align="center">91</td>
<td align="center">76.2</td>
<td align="center">76</td>
<td align="center"><b>82.1</b></td>
<td align="center">81.9</td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">43.4</td>
<td align="center"><b>37</b></td>
<td align="center">29.3</td>
<td align="center">31.7</td>
<td align="center">35.2</td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">17.1</td>
<td align="center">7.2</td>
<td align="center">6.1</td>
<td align="center">5.8</td>
<td align="center"><b>7.4</b></td>
</tr>
<tr>
<td align="center" colspan=6><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">BBH</td>
<td align="center">92.1</td>
<td align="center">81.4</td>
<td align="center">79.1 (84.5)</td>
<td align="center"><b>87.7</b></td>
<td align="center">87.2</td>
</tr>
<tr>
<td align="center">AGIEval-en</td>
<td align="center">78</td>
<td align="center">66.4</td>
<td align="center">65.6</td>
<td align="center"><b>70.7</b></td>
<td align="center">70.1</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Math</strong></td>
</tr>
<tr>
<td align="center">GSM8K</td>
<td align="center">93.1</td>
<td align="center">87</td>
<td align="center">87.5 (92.9)</td>
<td align="center"><b>90.8</b></td>
<td align="center">90.3</td>
</tr>
<tr>
<td align="center">MATH</td>
<td align="center">72.9</td>
<td align="center">61.1</td>
<td align="center">63.5 (57.7)</td>
<td align="center"><b>81.7</b></td>
<td align="center">61.3</td>
</tr>
<tr>
<td align="center" colspan=6><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">MBPP</td>
<td align="center">83.6</td>
<td align="center">78.8</td>
<td align="center">77.8 (84.5)</td>
<td align="center"><b>80.6</b></td>
<td align="center">74.6</td>
</tr>
<tr>
<td align="center">HumanEval</td>
<td align="center">78</td>
<td align="center">70.7</td>
<td align="center">47.6 (58.5)</td>
<td align="center"><b>76.8</b></td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)".
</sup>
### Seed-OSS-36B-Instruct
<div align="center">
<table>
<thead>
<tr>
<th align="center">Benchmark</th>
<th align="center"><sup><a href="https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-1-6-thinking">Seed1.6-Thinking-0715</a></sup></th>
<th align="center"><sup>OAI-OSS-20B*</sup></th>
<th align="center"><sup>Qwen3-30B-A3B-Thinking-2507*</sup></th>
<th align="center"><sup>Qwen3-32B*</sup></th>
<th align="center"><sup>Gemma3-27B</sup></th>
<th align="center"><sup>Seed-OSS-36B-Instruct</sup></th>
</tr>
</thead>
<tbody>
<tr>
<td align="center" colspan=7><strong>Knowledge</strong></td>
</tr>
<tr>
<td align="center">MMLU-Pro</td>
<td align="center">86.6</td>
<td align="center">76.2</td>
<td align="center"><ins>81.9</ins> (80.9)</td>
<td align="center">81.8</td>
<td align="center">67.5</td>
<td align="center"><b>82.7</b></td>
</tr>
<tr>
<td align="center">MMLU</td>
<td align="center">90.6</td>
<td align="center">81.7 (85.3)</td>
<td align="center"><ins>86.9</ins></td>
<td align="center">86.2</td>
<td align="center">76.9</td>
<td align="center"><b>87.4</b></td>
</tr>
<tr>
<td align="center">GPQA-D</td>
<td align="center">80.7</td>
<td align="center"><b>72.2</b> (71.5)</td>
<td align="center"><ins>71.4</ins> (73.4)</td>
<td align="center">66.7 (68.4)</td>
<td align="center">42.4</td>
<td align="center"><ins>71.4</ins></td>
</tr>
<tr>
<td align="center">SuperGPQA</td>
<td align="center">63.4</td>
<td align="center">50.1</td>
<td align="center"><b>57.3</b> (56.8)</td>
<td align="center">49.3</td>
<td align="center">-</td>
<td align="center"><ins>55.7</ins></td>
</tr>
<tr>
<td align="center">SimpleQA</td>
<td align="center">23.7</td>
<td align="center">6.7</td>
<td align="center"><b>23.6</b></td>
<td align="center">8.6</td>
<td align="center"><ins>10</ins></td>
<td align="center">9.7</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Math</strong></td>
</tr>
<tr>
<td align="center">AIME24</td>
<td align="center">90.3</td>
<td align="center"><b>92.7</b> (92.1)</td>
<td align="center">87.7</td>
<td align="center">82.7 (81.4)</td>
<td align="center">-</td>
<td align="center"><ins>91.7</ins></td>
</tr>
<tr>
<td align="center">AIME25</td>
<td align="center">86</td>
<td align="center"><b>90.3</b> (91.7)</td>
<td align="center">81.3 (85)</td>
<td align="center">73.3 (72.9)</td>
<td align="center">-</td>
<td align="center"><ins>84.7</ins></td>
</tr>
<tr>
<td align="center">BeyondAIME</td>
<td align="center">60</td>
<td align="center"><b>69</b></td>
<td align="center">56</td>
<td align="center">29</td>
<td align="center">-</td>
<td align="center"><ins>65</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Reasoning</strong></td>
</tr>
<tr>
<td align="center">ArcAGI V2</td>
<td align="center">50.3</td>
<td align="center"><b>41.7</b></td>
<td align="center">37.8</td>
<td align="center">14.4</td>
<td align="center">-</td>
<td align="center"><ins>40.6</ins></td>
</tr>
<tr>
<td align="center">KORBench</td>
<td align="center">74.8</td>
<td align="center"><b>72.3</b></td>
<td align="center">70.2</td>
<td align="center">65.4</td>
<td align="center">-</td>
<td align="center"><ins>70.6</ins></td>
</tr>
<tr>
<td align="center">HLE</td>
<td align="center">13.9</td>
<td align="center"><b>12.7</b> (10.9)</td>
<td align="center">8.7</td>
<td align="center">6.9</td>
<td align="center">-</td>
<td align="center"><ins>10.1</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Coding</strong></td>
</tr>
<tr>
<td align="center">LiveCodeBench v6<br/><sup>(02/2025-05/2025)</sup></td>
<td align="center">66.8</td>
<td align="center"><ins>63.8</ins></td>
<td align="center">60.3 (66)</td>
<td align="center">53.4</td>
<td align="center">-</td>
<td align="center"><b>67.4</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Instruction Following</strong></td>
</tr>
<tr>
<td align="center">IFEval</td>
<td align="center">86.3</td>
<td align="center"><b>92.8</b></td>
<td align="center">88 (88.9)</td>
<td align="center">88.4 (85)</td>
<td align="center"><ins>90.4</ins></td>
<td align="center">85.8</td>
</tr>
<tr>
<td align="center" colspan=7><strong>Agent</strong></td>
</tr>
<tr>
<td align="center">TAU1-Retail</td>
<td align="center">63</td>
<td align="center">(54.8)</td>
<td align="center"><ins>58.7</ins> (67.8)</td>
<td align="center">40.9</td>
<td align="center">-</td>
<td align="center"><b>70.4</b></td>
</tr>
<tr>
<td align="center">TAU1-Airline</td>
<td align="center">49</td>
<td align="center">(38)</td>
<td align="center"><b>47</b> (48)</td>
<td align="center">38</td>
<td align="center">-</td>
<td align="center"><ins>46</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(OpenHands)</sup></td>
<td align="center">41.8</td>
<td align="center"><b>(60.7)</b></td>
<td align="center">31</td>
<td align="center">23.4</td>
<td align="center">-</td>
<td align="center"><ins>56</ins></td>
</tr>
<tr>
<td align="center">SWE-Bench Verified<br/><sup>(AgentLess 4*10)</sup></td>
<td align="center">48.4</td>
<td align="center">-</td>
<td align="center">33.5</td>
<td align="center"><ins>39.7</ins></td>
<td align="center">-</td>
<td align="center"><b>47</b></td>
</tr>
<tr>
<td align="center">Multi-SWE-Bench</td>
<td align="center">17.7</td>
<td align="center">-</td>
<td align="center"><ins>9.5</ins></td>
<td align="center">7.7</td>
<td align="center">-</td>
<td align="center"><b>17</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Multilingualism</strong></td>
</tr>
<tr>
<td align="center">MMMLU</td>
<td align="center">84.3</td>
<td align="center">77.4 (75.7)</td>
<td align="center"><b>79</b></td>
<td align="center"><b>79</b> (80.6)</td>
<td align="center">-</td>
<td align="center"><ins>78.4</ins></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Long Context</strong></td>
</tr>
<tr>
<td align="center">RULER<br/><sup>(128K)</sup></td>
<td align="center">94.5</td>
<td align="center">78.7</td>
<td align="center"><ins>94.5</ins></td>
<td align="center">77.5</td>
<td align="center">-</td>
<td align="center"><b>94.6</b></td>
</tr>
<tr>
<td align="center" colspan=7><strong>Safety</strong></td>
</tr>
<tr>
<td align="center">AIR-Bench</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">-</td>
<td align="center">75.6</td>
</tr>
</tbody>
</table>
</div>
<sup>
- <b>Bold</b> denotes open-source SOTA. <ins>Underlined</ins> indicates the second place in the open-source model.
</sup><br/><sup>
- "*" indicates that the results in this column are presented in the format of "reproduced_results (reported_results_if_any)". Some results have been omitted due to the failure of the evaluation run.
</sup><br/><sup>
- The results of Gemma3-27B are sourced directly from its technical report.
</sup><br/><sup>
- Generation configs for Seed-OSS-36B-Instruct: temperature=1.1, top_p=0.95. Specifically, for Taubench, temperature=1, top_p=0.7.
</sup><br/><sup>
</sup>
> [!NOTE]
> We recommend sampling with `temperature=1.1` and `top_p=0.95`.
### Thinking Budget
Users can flexibly specify the model's thinking budget. The figure below shows the performance curves across different tasks as the thinking budget varies. For simpler tasks (such as IFEval), the model's chain of thought (CoT) is shorter, and the score exhibits fluctuations as the thinking budget increases. For more challenging tasks (such as AIME and LiveCodeBench), the model's CoT is longer, and the score improves with an increase in the thinking budget.

Here is an example with a thinking budget set to 512: during the reasoning process, the model periodically triggers self-reflection to estimate the consumed and remaining budget, and delivers the final response once the budget is exhausted or the reasoning concludes.
```
<seed:think>
Got it, let's try to solve this problem step by step. The problem says ... ...
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
Using the power rule, ... ...
<seed:cot_budget_reflect>I have used 258 tokens, and there are 254 tokens remaining for use.</seed:cot_budget_reflect>
Alternatively, remember that ... ...
<seed:cot_budget_reflect>I have used 393 tokens, and there are 119 tokens remaining for use.</seed:cot_budget_reflect>
Because if ... ...
<seed:cot_budget_reflect>I have exhausted my token budget, and now I will start answering the question.</seed:cot_budget_reflect>
</seed:think>
To solve the problem, we start by using the properties of logarithms to simplify the given equations: (full answer omitted).
```
If no thinking budget is set (default mode), Seed-OSS will initiate thinking with unlimited length. If a thinking budget is specified, users are advised to prioritize values that are integer multiples of 512 (e.g., 512, 1K, 2K, 4K, 8K, or 16K), as the model has been extensively trained on these intervals. Models are instructed to output a direct response when the thinking budget is 0, and we recommend setting any budget below 512 to this value.
## Quick Start
```shell
pip3 install -r requirements.txt
pip install git+ssh://[email protected]/Fazziekey/transformers.git@seed-oss
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
import re
model_name_or_path = "ByteDance-Seed/Seed-OSS-36B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "How to make pasta?"},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
thinking_budget=512 # control the thinking budget
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])
```
## Inference
### Download Model
Download Seed-OSS checkpoint to `./Seed-OSS-36B-Instruct`
### Transformers
The `generate.py` script provides a simple interface for model inference with configurable options.
#### Basic Usage
```shell
cd inference
python3 generate.py --model_path /path/to/model
```
#### Key Parameters
| Parameter | Description |
|-----------|-------------|
| `--model_path` | Path to the pretrained model directory (required) |
| `--prompts` | Input prompts (default: sample cooking/code questions) |
| `--max_new_tokens` | Maximum tokens to generate (default: 4096) |
| `--attn_implementation` | Attention mechanism: `flash_attention_2` (default) or `eager` |
| `--load_in_4bit/8bit` | Enable 4-bit/8-bit quantization (reduces memory usage) |
| `--thinking_budget` | Thinking budget in tokens (default: -1 for unlimited budget) |
#### Quantization Examples
```shell
# 8-bit quantization
python3 generate.py --model_path /path/to/model --load_in_8bit True
# 4-bit quantization
python3 generate.py --model_path /path/to/model --load_in_4bit True
```
#### Custom Prompts
```shell
python3 generate.py --model_path /path/to/model --prompts "['What is machine learning?', 'Explain quantum computing']"
```
### vLLM
Use vllm >= 0.10.0 or higher for inference.
- First install vLLM with Seed-OSS support version:
```shell
VLLM_USE_PRECOMPILED=1 VLLM_TEST_USE_PRECOMPILED_NIGHTLY_WHEEL=1 pip install git+ssh://[email protected]/FoolPlayer/vllm.git@seed-oss
```
- Start vLLM API server:
```shell
python3 -m vllm.entrypoints.openai.api_server \
--host localhost \
--port 4321 \
--enable-auto-tool-choice \
--tool-call-parser seed_oss \
--trust-remote-code \
--model ./Seed-OSS-36B-Instruct \
--chat-template ./Seed-OSS-36B-Instruct/chat_template.jinja \
--tensor-parallel-size 8 \
--dtype bfloat16 \
--served-model-name seed_oss
```
- Test with OpenAI client:
Chat
```shell
# no stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1 --stream
```
Tool Call
```shell
# no stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1 --stream
```
## Model Card
See [MODEL_CARD](./MODEL_CARD.md).
## License
This project is licensed under Apache-2.0. See the [LICENSE](./LICENSE) flie for details.
## Citation
```bibtex
@misc{seed2025seed-oss,
author={ByteDance Seed Team},
title={Seed-OSS Open-Source Models},
year={2025},
howpublished={\url{https://github.com/ByteDance-Seed/seed-oss}}
}
```
## About [ByteDance Seed Team](https://seed.bytedance.com/)
Founded in 2023, ByteDance Seed Team is dedicated to crafting the industry's most advanced AI foundation models. The team aspires to become a world-class research team and make significant contributions to the advancement of science and society.
| null |
[
"apache-2.0"
] | null | null | null | 36,151,104,512
|
[
null,
"text-generation"
] | null |
[
"AutoModel",
"seed_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68aaec754d6db6f6417a5572
|
openbmb/MiniCPM-V-4_5-gguf
|
openbmb
| null | 12,690
| 12,690
|
False
| 2025-08-24T10:41:57Z
| 2025-08-30T05:53:48Z
|
transformers
| 17
| 17
| null |
image-text-to-text
| null |
[
".gitattributes",
"MiniCPM-V-4_5-F16.gguf",
"MiniCPM-V-4_5-Q4_0.gguf",
"MiniCPM-V-4_5-Q4_K_M.gguf",
"MiniCPM-V-4_5-Q5_1.gguf",
"MiniCPM-V-4_5-Q5_K_M.gguf",
"MiniCPM-V-4_5-Q5_K_S.gguf",
"MiniCPM-V-4_5-Q6_K.gguf",
"MiniCPM-V-4_5-Q8_0.gguf",
"Model-8.2B-F16.gguf",
"README.md",
"ggml-model-Q4_0.gguf",
"ggml-model-Q4_1.gguf",
"ggml-model-Q4_K_M.gguf",
"ggml-model-Q4_K_S.gguf",
"ggml-model-Q5_0.gguf",
"ggml-model-Q5_1.gguf",
"ggml-model-Q5_K_M.gguf",
"ggml-model-Q5_K_S.gguf",
"ggml-model-Q6_K.gguf",
"ggml-model-Q8_0.gguf",
"mmproj-model-f16.gguf"
] |
[
1562,
16384959040,
4773679808,
5026714304,
6192553664,
5849946816,
5719595712,
6724631360,
8707877440,
16384959040,
24697,
4773679808,
5246637760,
5026714304,
4800942784,
5719595712,
6192553664,
5849946816,
5719595712,
6724631360,
8707877440,
1095113184
] | 135,622,231,987
|
c6de0998e33db95098e404676d9561f5c665f6b4
|
[
"transformers",
"gguf",
"minicpm-v",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"image-text-to-text",
"multilingual",
"dataset:openbmb/RLAIF-V-Dataset",
"arxiv:2403.11703",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 8189195264, "architecture": "qwen3", "context_length": 40960, "chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set content = message.content %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is defined and message.reasoning_content is not none %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in message.content %}\n {%- set content = message.content.split('</think>')[-1].lstrip('\\n') %}\n {%- set reasoning_content = message.content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n {%- if enable_thinking is defined and enable_thinking is false %}\n {{- '<think>\\n\\n</think>\\n\\n' }}\n {%- endif %}\n {%- if enable_thinking is defined and enable_thinking is true %}\n {{- '<think>\\n' }}\n {%- endif %}\n{%- endif %}", "bos_token": "<|endoftext|>", "eos_token": "<|im_end|>"}
|
<h1>A GPT-4o Level MLLM for Single Image, Multi Image and High-FPS Video Understanding on Your Phone</h1>
[GitHub](https://github.com/OpenBMB/MiniCPM-o) | [Demo](http://101.126.42.235:30910/)</a>
## MiniCPM-V 4.5
**MiniCPM-V 4.5** is the latest and most capable model in the MiniCPM-V series. The model is built on Qwen3-8B and SigLIP2-400M with a total of 8B parameters. It exhibits a significant performance improvement over previous MiniCPM-V and MiniCPM-o models, and introduces new useful features. Notable features of MiniCPM-V 4.5 include:
- 🔥 **State-of-the-art Vision-Language Capability.**
MiniCPM-V 4.5 achieves an average score of 77.0 on OpenCompass, a comprehensive evaluation of 8 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4o-latest, Gemini-2.0 Pro, and strong open-source models like Qwen2.5-VL 72B** for vision-language capabilities, making it the most performant MLLM under 30B parameters.
- 🎬 **Efficient High-FPS and Long Video Understanding.** Powered by a new unified 3D-Resampler over images and videos, MiniCPM-V 4.5 can now achieve 96x compression rate for video tokens, where 6 448x448 video frames can be jointly compressed into 64 video tokens (normally 1,536 tokens for most MLLMs). This means that the model can perceive significantly more video frames without increasing the LLM inference cost. This brings state-of-the-art high-FPS (up to 10FPS) video understanding and long video understanding capabilities on Video-MME, LVBench, MLVU, MotionBench, FavorBench, etc., efficiently.
- ⚙️ **Controllable Hybrid Fast/Deep Thinking.** MiniCPM-V 4.5 supports both fast thinking for efficient frequent usage with competitive performance, and deep thinking for more complex problem solving. To cover efficiency and performance trade-offs in different user scenarios, this fast/deep thinking mode can be switched in a highly controlled fashion.
- 💪 **Strong OCR, Document Parsing and Others.**
Based on [LLaVA-UHD](https://arxiv.org/pdf/2403.11703) architecture, MiniCPM-V 4.5 can process high-resolution images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), using 4x less visual tokens than most MLLMs. The model achieves **leading performance on OCRBench, surpassing proprietary models such as GPT-4o-latest and Gemini 2.5**. It also achieves state-of-the-art performance for PDF document parsing capability on OmniDocBench among general MLLMs. Based on the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) and [VisCPM](https://github.com/OpenBMB/VisCPM) techniques, it features **trustworthy behaviors**, outperforming GPT-4o-latest on MMHal-Bench, and supports **multilingual capabilities** in more than 30 languages.
- 💫 **Easy Usage.**
MiniCPM-V 4.5 can be easily used in various ways: (1) [llama.cpp](https://github.com/tc-mb/llama.cpp/blob/Support-MiniCPM-V-4.5/docs/multimodal/minicpmv4.5.md) and [ollama](https://github.com/tc-mb/ollama/tree/MIniCPM-V) support for efficient CPU inference on local devices, (2) [int4](https://huggingface.co/openbmb/MiniCPM-V-4_5-int4), [GGUF](https://huggingface.co/openbmb/MiniCPM-V-4_5-gguf) and [AWQ](https://github.com/tc-mb/AutoAWQ) format quantized models in 16 sizes, (3) [SGLang](https://github.com/tc-mb/sglang/tree/main) and [vLLM](#efficient-inference-with-llamacpp-ollama-vllm) support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks with [Transformers](https://github.com/tc-mb/transformers/tree/main) and [LLaMA-Factory](./docs/llamafactory_train_and_infer.md), (5) quick [local WebUI demo](#chat-with-our-demo-on-gradio), (6) optimized [local iOS app](https://github.com/tc-mb/MiniCPM-o-demo-iOS) on iPhone and iPad, and (7) online web demo on [server](http://101.126.42.235:30910/). See our [Cookbook](https://github.com/OpenSQZ/MiniCPM-V-CookBook) for full usages!
### Key Techniques
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpm-v-4dot5-framework.png" , width=100%>
</div>
- **Architechture: Unified 3D-Resampler for High-density Video Compression.** MiniCPM-V 4.5 introduces a 3D-Resampler that overcomes the performance-efficiency trade-off in video understanding. By grouping and jointly compressing up to 6 consecutive video frames into just 64 tokens (the same token count used for a single image in MiniCPM-V series), MiniCPM-V 4.5 achieves a 96× compression rate for video tokens. This allows the model to process more video frames without additional LLM computational cost, enabling high-FPS video and long video understanding. The architecture supports unified encoding for images, multi-image inputs, and videos, ensuring seamless capability and knowledge transfer.
- **Pre-training: Unified Learning for OCR and Knowledge from Documents.** Existing MLLMs learn OCR capability and knowledge from documents in isolated training approaches. We observe that the essential difference between these two training approaches is the visibility of the text in images. By dynamically corrupting text regions in documents with varying noise levels and asking the model to reconstruct the text, the model learns to adaptively and properly switch between accurate text recognition (when text is visible) and multimodal context-based knowledge reasoning (when text is heavily obscured). This eliminates reliance on error-prone document parsers in knowledge learning from documents, and prevents hallucinations from over-augmented OCR data, resulting in top-tier OCR and multimodal knowledge performance with minimal engineering overhead.
- **Post-training: Hybrid Fast/Deep Thinking with Multimodal RL.** MiniCPM-V 4.5 offers a balanced reasoning experience through two switchable modes: fast thinking for efficient daily use and deep thinking for complex tasks. Using a new hybrid reinforcement learning method, the model jointly optimizes both modes, significantly enhancing fast-mode performance without compromising deep-mode capability. Incorporated with [RLPR](https://github.com/OpenBMB/RLPR) and [RLAIF-V](https://github.com/RLHF-V/RLAIF-V), it generalizes robust reasoning skills from broad multimodal data while effectively reducing hallucinations.
### Evaluation
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/radar_minicpm_v45.png", width=60%>
</div>
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv_4_5_evaluation_result.png" , width=100%>
</div>
### Inference Efficiency
**OpenCompass**
<div align="left">
<table style="margin: 0px auto;">
<thead>
<tr>
<th align="left">Model</th>
<th>Size</th>
<th>Avg Score ↑</th>
<th>Total Inference Time ↓</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td nowrap="nowrap" align="left">GLM-4.1V-9B-Thinking</td>
<td>10.3B</td>
<td>76.6</td>
<td>17.5h</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiMo-VL-7B-RL</td>
<td>8.3B</td>
<td>76.4</td>
<td>11h</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiniCPM-V 4.5</td>
<td>8.7B</td>
<td><b>77.0</td>
<td><b>7.5h</td>
</tr>
</tbody>
</table>
</div>
**Video-MME**
<div align="left">
<table style="margin: 0px auto;">
<thead>
<tr>
<th align="left">Model</th>
<th>Size</th>
<th>Avg Score ↑</th>
<th>Total Inference Time ↓</th>
<th>GPU Mem ↓</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td nowrap="nowrap" align="left">Qwen2.5-VL-7B-Instruct</td>
<td>8.3B</td>
<td>71.6</td>
<td>3h</td>
<td>60G</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">GLM-4.1V-9B-Thinking</td>
<td>10.3B</td>
<td><b>73.6</td>
<td>2.63h</td>
<td>32G</td>
</tr>
<tr>
<td nowrap="nowrap" align="left">MiniCPM-V 4.5</td>
<td>8.7B</td>
<td>73.5</td>
<td><b>0.26h</td>
<td><b>28G</td>
</tr>
</tbody>
</table>
</div>
Both Video-MME and OpenCompass were evaluated using 8×A100 GPUs for inference. The reported inference time of Video-MME excludes the cost of video frame extraction.
### Examples
<div align="center">
<a href="https://www.youtube.com/watch?v=Cn23FujYMMU"><img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/MiniCPM-V%204.5-8.26_img.jpeg", width=70%></a>
</div>
<div style="display: flex; flex-direction: column; align-items: center;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case1.png" alt="en_case1" style="margin-bottom: 5px;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case2.png" alt="en_case2" style="margin-bottom: 5px;">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/en_case3.jpeg" alt="en_case3" style="margin-bottom: 5px;">
</div>
We deploy MiniCPM-V 4.5 on iPad M4 with [iOS demo](https://github.com/tc-mb/MiniCPM-o-demo-iOS). The demo video is the raw screen recording without editing.
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_en_handwriting.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_en_cot.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
</div>
<div align="center">
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_cn_handwriting.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
<img src="https://raw.githubusercontent.com/openbmb/MiniCPM-o/main/assets/minicpmv4_5/v45_cn_travel.gif" width="45%" style="display: inline-block; margin: 0 10px;"/>
</div>
## Usage
If you wish to enable thinking mode, provide the argument `enable_thinking=True` to the chat function.
#### Chat with Image
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
```
You will get the following output:
```shell
# round1
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# round2
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
```
#### Chat with Video
```python
## The 3d-resampler compresses multiple frames into 64 tokens by introducing temporal_ids.
# To achieve this, you need to organize your video data into two corresponding sequences:
# frames: List[Image]
# temporal_ids: List[List[Int]].
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
from scipy.spatial import cKDTree
import numpy as np
import math
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=180 # Indicates the maximum number of frames received after the videos are packed. The actual maximum number of valid frames is MAX_NUM_FRAMES * MAX_NUM_PACKING.
MAX_NUM_PACKING=3 # indicates the maximum packing number of video frames. valid range: 1-6
TIME_SCALE = 0.1
def map_to_nearest_scale(values, scale):
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps()
video_duration = len(vr) / fps
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
print(video_path, ' duration:', video_duration)
print(f'get video frames={len(frame_idx)}, packing_nums={packing_nums}')
frames = vr.get_batch(frame_idx).asnumpy()
frame_idx_ts = frame_idx / fps
scale = np.arange(0, video_duration, TIME_SCALE)
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
assert len(frames) == len(frame_ts_id)
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
video_path="video_test.mp4"
fps = 5 # fps for video
force_packing = None # You can set force_packing to ensure that 3D packing is forcibly enabled; otherwise, encode_video will dynamically set the packing quantity based on the duration.
frames, frame_ts_id_group = encode_video(video_path, fps, force_packing=force_packing)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group
)
print(answer)
```
#### Chat with multiple images
<details>
<summary> Click to show Python code running MiniCPM-V 4.5 with multiple images input. </summary>
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
```
</details>
## License
#### Model License
* The code in this repo is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
* The usage of MiniCPM-V series model weights must strictly follow [MiniCPM Model License.md](https://github.com/OpenBMB/MiniCPM-o/blob/main/MiniCPM%20Model%20License.md).
* The models and weights of MiniCPM are completely free for academic research. After filling out a ["questionnaire"](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, MiniCPM-V 4.5 weights are also available for free commercial use.
#### Statement
* As an LMM, MiniCPM-V 4.5 generates contents by learning a large amount of multimodal corpora, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 4.5 does not represent the views and positions of the model developers
* We will not be liable for any problems arising from the use of the MinCPM-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
## Key Techniques and Other Multimodal Projects
👏 Welcome to explore key techniques of MiniCPM-V 4.5 and other multimodal projects of our team:
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLPR](https://github.com/OpenBMB/RLPR) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
## Citation
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
```bib
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}
```
| null | null |
[
"openbmb/RLAIF-V-Dataset"
] |
[
"multilingual"
] | null | 8,189,195,264
|
[
null,
"image-text-to-text"
] | null |
[
"AutoModel",
"qwen3"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac2a0ca3f58b98f628f324
|
microsoft/VibeVoice-Tokenizer
|
microsoft
| null | 0
| 0
|
False
| 2025-08-25T09:17:00Z
| 2025-08-25T09:17:00Z
| null | 17
| 17
| null | null | null |
[
".gitattributes",
"README.md"
] | null | null |
b1a6df43100fe648cb7b938d773da7a798dd516b
|
[
"license:mit",
"region:us"
] | null | null | null |
[
"mit"
] | null | null | null | null | null | null | null | null | null | null |
free
|
company
|
[
"United States of America",
"International",
"India",
"Belgium"
] | null | null | null | null | null | null | null | null | null |
68ad7563d3bca8f4ccdd370d
|
BasedBase/Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill
|
BasedBase
|
{
"models": [
{
"_id": "6888aae7c54baad7997d7b4b",
"id": "Qwen/Qwen3-30B-A3B-Thinking-2507"
}
],
"relation": "quantized"
}
| 2,515
| 2,515
|
False
| 2025-08-26T08:50:43Z
| 2025-08-28T23:37:06Z
| null | 17
| 17
| null | null | null |
[
".gitattributes",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q3_K_M.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q4_0.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q4_K_M.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q4_K_S.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q5_K_M.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q6_K.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-Q8_0.gguf",
"Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill-model-Q2_K.gguf",
"README.md"
] |
[
2301,
14711846272,
17304489344,
18556685696,
17456008576,
21725580672,
25092531584,
32483931520,
11258609024,
5126
] | 158,589,690,115
|
e6518a637832594e074a1a89b2b8f5e8faca2864
|
[
"gguf",
"causal-lm",
"moe",
"mixture-of-experts",
"qwen",
"distillation",
"svd",
"lora-merged",
"code-generation",
"base_model:Qwen/Qwen3-30B-A3B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Thinking-2507",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 30532122624, "architecture": "qwen3moe", "context_length": 262144, "chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is string %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n<think>\\n' }}\n{%- endif %}", "bos_token": "<|endoftext|>", "eos_token": "<|im_end|>"}
|
# Qwen3-30B-A3B-Thinking-2507-Deepseek-v3.1-Distill
## Model Description
This model is a distilled version of **`Qwen/Qwen3-30B-A3B-Instruct`** designed to inherit the reasoning and behavioral characteristics of its much larger teacher model, **`deepseek-ai/DeepSeek-V3.1`**.
It is the result of applying a LoRA created via an SVD-based distillation pipeline, and then merging those weights into the base model. The core of this process was to transfer the nuanced knowledge from a **62-layer, 256-expert teacher model** into the more efficient **48-layer, 128-expert architecture** of the student model.
The primary goal was to explore the high-fidelity transfer of complex reasoning patterns, particularly those encoded within the Mixture-of-Experts (MoE) layers, from a frontier-class model to a consumer-accessible one.
You should notice that the model has a more confident and linear chain-of-thought compared to the base qwen3-30b-a3b-thinking-2507 model like Deepseek 3.1 has. This distill tends to overthink much less than the base model and provides more accurate better structured answers.
## The Distillation Methodology
This model was not trained in a conventional sense. Instead, it was created using a layer-by-layer distillation SVD based distillation process.
### Core Components
* **Teacher Model:** `deepseek-ai/DeepSeek-V3.1`.
* **Student Model:** `Qwen/Qwen3-30B-A3B-Thinking-2507`.
* **LoRA Rank:** A high rank of **`r=2048`** was used for all modules to ensure a comprehensive capture of information from the teacher model.
### The Distillation Pipeline
For each corresponding layer in the student and teacher, the following pipeline was executed:
1. **Teacher Layer Interpolation (SLERP):** For student layers that fall between two teacher layers (based on a sigmoid mapping), Spherical Linear Interpolation (SLERP) was used to create a geometrically sound blend of the teacher's weights. This preserves the integrity of the high-dimensional representations.
2. **SVD Projection:** The core of the distillation. The (potentially blended) teacher layer's weight matrix was decomposed using a randomized SVD algorithm. The top 2048 most significant components were selected and reconstructed to fit the student layer's smaller dimensions. This high-rank projection is designed for maximum fidelity.
3. **Generalized Procrustes Analysis:** After projection, the newly created "synthetic" tensor was optimally aligned with the student's original pre-trained tensor using a hardened least-squares solver. This alignment minimizes representational distance before calculating the final difference, with added checks to prevent numerical instability.
4. **DARE-TIES Purification:** The difference tensor (`Distilled - Aligned Student`) was then purified using the DARE-TIES methodology. This process drops a significant percentage (80%) of the lowest-magnitude values, treating them as noise, and then rescale the remaining important differences. This creates a clean, high-signal delta for the final LoRA.
### Mixture-of-Experts (MoE) Distillation
The standout feature of this process is the full distillation of the MoE layers, which are critical for nuanced, context-dependent reasoning.
* **Expert Fingerprinting & Clustering:** To map the 256 teacher experts to the 128 student experts, each teacher expert was "fingerprinted" by concatenating its constituent weight matrices. **FAISS-GPU K-Means clustering** was then used to efficiently group these 256 fingerprints into 128 distinct clusters based on their geometric similarity.
* **Advanced Expert Synthesis:** Each of the student's 128 experts was synthesized from a weighted blend of the teacher experts assigned to its cluster. This blend is not a simple average; instead, it uses an SVD-based reconstruction from the top teacher experts (ranked by similarity to the cluster centroid) to create a new, synthetic expert that represents the core "concept" of that cluster. This more advanced synthesis aims to create novel, yet faithful, expert representations.
## Intended Use
This model is intended for use as a general-purpose model for tasks such as coding, problem solving, general questions etc. It is designed to be a more capable and nuanced reasoner than its base model.
* **Primary Use:** Complex instruction-following, reasoning tasks, and creative generation.
* **Out of Scope:** Its knowledge cutoff is from its original training (2024), and it has not been aligned for specific safety or conversational chatbot roles beyond its base tuning.
## Critical Usage Note
For inference, you can use either the default settings for the 30B model or the optimized settings used for the 685B model. The choice depends on your specific task,
Use the 30B defaults for general tasks.
For coding-related work, the 685B settings appear to yield significantly better results based on empirical testing but will slow down inference.
| null |
[
"apache-2.0"
] | null | null | null | 30,532,122,624
| null | null |
[
"qwen3moe"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
672379b045bf745cb0f1a79a
|
Lightricks/LTX-Video
|
Lightricks
| null | 568,546
| 3,034,040
|
False
| 2024-10-31T12:36:00Z
| 2025-07-16T14:32:35Z
|
diffusers
| 1,895
| 16
| null |
image-to-video
| null |
[
".gitattributes",
"LTX-Video-Open-Weights-License-0.X.txt",
"README.md",
"ltx-video-2b-v0.9.1.license.txt",
"ltx-video-2b-v0.9.1.safetensors",
"ltx-video-2b-v0.9.5.license.txt",
"ltx-video-2b-v0.9.5.safetensors",
"ltx-video-2b-v0.9.license.txt",
"ltx-video-2b-v0.9.safetensors",
"ltxv-13b-0.9.7-dev-fp8.safetensors",
"ltxv-13b-0.9.7-dev.safetensors",
"ltxv-13b-0.9.7-distilled-fp8.safetensors",
"ltxv-13b-0.9.7-distilled-lora128.safetensors",
"ltxv-13b-0.9.7-distilled.safetensors",
"ltxv-13b-0.9.8-dev-fp8.safetensors",
"ltxv-13b-0.9.8-dev.safetensors",
"ltxv-13b-0.9.8-distilled-fp8.safetensors",
"ltxv-13b-0.9.8-distilled.safetensors",
"ltxv-2b-0.9.6-dev-04-25.safetensors",
"ltxv-2b-0.9.6-distilled-04-25.safetensors",
"ltxv-2b-0.9.8-distilled-fp8.safetensors",
"ltxv-2b-0.9.8-distilled.safetensors",
"ltxv-spatial-upscaler-0.9.7.safetensors",
"ltxv-spatial-upscaler-0.9.8.safetensors",
"ltxv-temporal-upscaler-0.9.7.safetensors",
"ltxv-temporal-upscaler-0.9.8.safetensors",
"media/ltx-video_example_00001.gif",
"media/ltx-video_example_00005.gif",
"media/ltx-video_example_00006.gif",
"media/ltx-video_example_00007.gif",
"media/ltx-video_example_00010.gif",
"media/ltx-video_example_00011.gif",
"media/ltx-video_example_00013.gif",
"media/ltx-video_example_00014.gif",
"media/ltx-video_example_00015.gif",
"media/ltx-video_i2v_example_00001.gif",
"media/ltx-video_i2v_example_00002.gif",
"media/ltx-video_i2v_example_00003.gif",
"media/ltx-video_i2v_example_00004.gif",
"media/ltx-video_i2v_example_00005.gif",
"media/ltx-video_i2v_example_00006.gif",
"media/ltx-video_i2v_example_00007.gif",
"media/ltx-video_i2v_example_00008.gif",
"media/ltx-video_i2v_example_00009.gif",
"media/trailer.gif",
"model_index.json",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/model-00001-of-00004.safetensors",
"text_encoder/model-00002-of-00004.safetensors",
"text_encoder/model-00003-of-00004.safetensors",
"text_encoder/model-00004-of-00004.safetensors",
"text_encoder/model.safetensors.index.json",
"tokenizer/added_tokens.json",
"tokenizer/special_tokens_map.json",
"tokenizer/spiece.model",
"tokenizer/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00002.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00002.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
3407,
14536,
21065,
15981,
5716863844,
16061,
6340729500,
16046,
9370442108,
15694279916,
28579183340,
15694280020,
1325666536,
28579183444,
15694279916,
28579183340,
15694280140,
28579183564,
6340743924,
6340744028,
4461695684,
6340744492,
505024432,
505024432,
523894768,
523894768,
7963919,
5732587,
132,
132,
6193172,
132,
9024843,
132,
132,
9285683,
20393804,
9825156,
15691608,
10329925,
11936674,
11755718,
14716658,
16848341,
147294304,
412,
418,
781,
4989319680,
4999830656,
4865612720,
4194506688,
19886,
2593,
2543,
791656,
20618,
500,
4939189200,
2754433648,
72060,
501,
1676798532
] | 254,107,005,436
|
8984fa25007f376c1a299016d0957a37a2f797bb
|
[
"diffusers",
"safetensors",
"ltx-video",
"image-to-video",
"en",
"license:other",
"diffusers:LTXPipeline",
"region:us"
] | null | null |
[
"Lightricks/ltx-video-distilled",
"jbilcke-hf/tikslop",
"EU-IA/Aduc-sdr-VIDEO",
"TIGER-Lab/GenAI-Arena",
"cocktailpeanut/LTX-Video-Playground",
"svjack/LTX-Video-Playground",
"emilalvaro/LTX-Video-Playground",
"jbilcke-hf/ai-tube-model-ltxv-1",
"NativeAngels/LTX-Video-Playground",
"Swaqgame99/LTX-Video-Playground",
"tsqn/LTX-Video-Playground",
"PR-Puppets/PR-Puppet-Sora",
"jbilcke-hf/ai-tube-model-ltxv-2",
"ninjawick/PR-Puppet-Sora-2",
"ylues/PR-Puppet-Sora",
"jbilcke-hf/ai-tube-model-ltxv-3",
"lilcheaty/sora_test",
"Konst2021/PR-Puppet-Sora",
"alexlevy0/PR-Puppet-Sora",
"k11112/LTX-Video-Playground",
"jbilcke-hf/ai-tube-model-ltxv-4",
"ford442/LTX-Video",
"Masterdqqq/PR-Puppet-Sora",
"AashishNKumar/proj11",
"riflecreek/LTX-Video-Playground",
"kostadinkostad/LTX-Video-Playground",
"K00B404/LTX-Video-Playground",
"tsoe/sora",
"constant999/LTX-Video-Playground",
"Lezzio/LTX-Video-Playground",
"Greekmongoose/LTX-Video-Playground",
"Kaskatraz/LTX-Video-Playground",
"PeldelnasGranell/LTX-Video-Playground",
"learningloop/LTX-Video-Playground",
"akthangdz/TEXT_TO_VIDEO",
"1inkusFace/LTXImageToVideoPipeline_D",
"1inkusFace/LTX-Video-Xora",
"waloneai/LTX-Video_demo_newgenai",
"waloneai/fastvideogen",
"Tusharcrusty1/LTX-Video-Playground",
"sitonmyface/LTX-Video-Playground",
"nasiye969/LTX-Video-Playground",
"quangnhat/QNT-StudioDesign",
"WillybotAI77777/LTX-Video-Playground",
"Pablosolaris/LTX-Video-Playground",
"life-efficient/toolkit",
"jbilcke-hf/VideoModelStudio",
"svjack/VideoModelStudio",
"cziter15pl/LTX-Video-Playground",
"svjack/LTXImageToVideoPipeline_D",
"Yungleesky77/Lightricks-LTX-Video",
"Kenjibusito67/Lightricks-LTX-Video",
"ALLEN20250302/Lightricks-LTX-Video",
"Xinyu0168/Lightricks-LTX-Video",
"tktrev/Lightricks-LTX-Video",
"petenka06/Lightricks-LTX-Video",
"dtupidkids/Lightricks-LTX-Video19898312",
"royAivos/N8N_LTXImageToVideoPipeline",
"daaaaaaaaaaa2/LTX-Video-Playground",
"jbosolutions/Lightricks-LTX-Video",
"torlakovski/Lightricks-LTX-Video",
"dgokul22/Lightricks-LTX-Video",
"Tomlenda/Lightricks-LTX-Video",
"bhaskar1225/Lightricks-LTX-Video",
"vyloup/LTX-Video-Playground",
"user029182/test_video",
"cyberwarrior/Lightricks-LTX-Video",
"tushkum/Lightricks-LTX-Video",
"Sukkari/Lightricks-LTX-Video",
"K00B404/LTXImageToVideoPipeline_D",
"Kingtopaz/Lightricks-LTX-Video",
"Eyyub/Lightricks-LTX-Video",
"GreedPoud/Lightricks-LTX-Video",
"zinhomedz/Lightricks-LTX-Video",
"Razendako/Lightricks-LTX-Video",
"dotkaio/LTX-Video-Playground",
"maffia/vace-demo",
"sohitmalik/Lightricks-LTX-Video",
"AntonD91/Lightricks-LTX-Video",
"Shhabzbzbs/Lightricks-LTX-Video",
"imthanhlv/looop",
"Saksham14/Lightricks-LTX-Video",
"Rasta7909/Lightricks-LTX-Video",
"vimalvskl7/VideoModelStudio",
"appimate/Lightricks-LTX-Video",
"Streamliteeeee/Lightricks-LTX-Video",
"ShockCR/Lightricks-LTX-Video",
"ranjoojen/Lightricks-LTX-Video",
"JanRyder/Lightricks-LTX-Video",
"danielprimeservices/Lightricks-LTX-Video",
"bharath-723/Lightricks-LTX-Video",
"revrbg3vqr/Lightricks-LTX-Video",
"orbinusa/Lightricks-LTX-Video",
"JeffGreen311/Lightricks-LTX-Video",
"Rakeshj182002/LTX-Video-Playground",
"lego-liveafter/just-chill",
"Idk2ray/Lightricks-LTX-Video",
"Tunchi11/Lightricks-LTX-Video",
"mrkhurafati1/Lightricks-LTX-Video",
"InfinixMaestro/Lightricks-LTX-Video",
"kevalfst/visionary-ai",
"Abhisheksao/Lightricks-LTX-Video",
"Ali08w590/Lightricks-LTX-Video",
"archi294/Lightricks-LTX-Video",
"oliveralonsoar/Lightricks-LTX-Video",
"The-blank/Lightricks-LTX-Video",
"miannry/Lightricks-LTX-Video",
"miannry/LTX-Video-Playground",
"Anon6/Lightricks-LTX-Video",
"casity/Lightricks-LTX-Video",
"Courtney818/Lightricks-LTX-Video",
"TDMI3/Lightricks-LTX-Video",
"smartfeed/turbo_fe",
"Shancs8876/Lightricks-LTX-Video",
"Zanbraha/Lightricks-LTX-Video",
"faisalbsl21/VideoModelStudio",
"yassinovich/VideoModelStudio2",
"Nadiir23/Lightricks-LTX-Video",
"caglarcags/Lightricks-LTX-Video",
"ShyftIndustries/Lightricks-LTX-Video",
"sajankharat/Lightricks-LTX-Video",
"infinitestar/Lightricks-LTX-Video2",
"abcdeai3478/Lightricks-LTX-Video",
"Thatoneguy1721/Lightricks-LTX-Video",
"Shree627/Lightricks-LTX-Video",
"hotsarang/Lightricks-LTX-Video",
"hotsarang/tv",
"Hajahoora/Lightricks-LTX-Video",
"omen555/Lightricks-LTX-Video",
"InDetail/Lightricks-LTX-Video",
"breezywaves/Lightricks-LTX-Video",
"mbtsprod/Lightricks-LTX-Video",
"Anannt/Lightricks-LTX-Video",
"bhaskarjha514/Lightricks-LTX-Video2",
"shirish4ss/Lightricks-LTX-Video",
"kevalfst/docker-space",
"Liib/Lightricks-LTX-Video",
"jujutechnology/ltxv",
"AlfaRadius/Lightricks-LTX-Video",
"rakesg456/Lightricks-LTX-Video",
"linoyts/LTXV-lora-the-explorer",
"Zoyfik/Lightricks-LTX-Video",
"reeceway7/Lightricks-LTX-Video",
"Aeww/Lightricks-LTX-Video",
"GabrieleSheik/Lightricks-LTX-Video",
"brilliannw/Lightricks-LTX-Video",
"ALBYTERZI/Lightricks-LTX-Video",
"Bossmarc747/Innovatehub-LTX-Video",
"freddyaboulton/ltx-video-distilled",
"Iamnavn/Lightricks-LTX-Video",
"bhattaa/Lightricks-LTX-Video",
"vitarazvan/Lightricks-LTX-Video",
"Shaheer-ipynb/AI-Video-Creator",
"fffiloni/VACE-Annotators",
"siraliz/Lightricks-LTX-Video",
"Saadakgebori/Lightricks-LTX-Video",
"nathanblack1984/Lightricks-LTX-Video",
"LearnCreateRepeat/LCR_ltx-video-distilled",
"Gomeszyy/Lightricks-LTX-Video",
"Erensmith/Lightricks-LTX-Video",
"UserH501/Lightricks-LTX-Video",
"wvilela/Lightricks-LTX-Video",
"Vishal7700/Lightricks-LTX-Video",
"Sebestianmek/Seb-AI-Video-Model",
"hsuwu/Lightricks-LTX-Video",
"RTLit/Copy",
"Mvaneza/Lightricks-LTX-Video",
"Bron7/Lightricks-LTX-Video",
"saervo123/Lightricks-LTX-Video",
"ThomasUXD1/Lightricks-LTX-Video",
"Aiheyil/Lightricks-LTX-Video",
"GiveGoodV/Lightricks-LTX-Video",
"bradferd84/Lightricks-LTX-Video",
"dhuynh95/screenshot_to_html",
"Atul257/Lightricks-LTX-Video",
"TOKZIK/Lightricks-LTX-Video",
"hyperichiban/Lightricks-LTX-Video",
"Letscreateus/Lightricks-LTX-Video",
"nakul996/Lightricks-LTX-Video",
"Sebestianmek/SebVideo",
"andyaii/ltx-video-distilled",
"Watzel247/Lightricks-LTX-Video",
"dangthr/ltx-video-distilled",
"JTPLUG/Lightricks-LTX-Video",
"adptbyt/ltx-video-distilled",
"anhnq/ltx-video-distilled",
"ThomasUXD1/Lightricks-LTX-Video2",
"ThomasUXD1/Lightricks-LTX-Video3",
"tddandroid/Lightricks-LTX-Video",
"Greff3/ltx-video-distilled",
"tidoo/Lightricks-LTX-Video",
"automubashir/Lightricks-LTX-Video",
"huggi2184/Lightricks-LTX-Video",
"Mohammad-al-kabbani/Lightricks-LTX-Video",
"Mohammad-al-kabbani/Lightricks-LTX-Videos",
"NexAItools/Lightricks-LTX-Video",
"DRDELATV/Lightricks-LTX-Video",
"transponster27/Lightricks-LTX-Video",
"makululinux/ltx-video-distilled",
"mad-pink/Lightricks-LTX-Video",
"Samxgod123/Lightricks-LTX-Video",
"chinmay09/Lightricks-LTX-Video",
"AhmadYasin/Lightricks-LTX-Video",
"bep40/screenshot_to_html",
"a3igroupservices/Lightricks-LTX-Video",
"moscow2525/Lightricks-LTX-Video",
"kenxxaman/Lightricks-LTX-Video",
"WilliamR1029/Lightricks-LTX-Video",
"lukas2505200/Lightricks-LTX-Video",
"mosi77/ltx-video-distilled",
"amritesh98/Lightricks-LTX-Video",
"danielfela/Lightricks-LTX-Video",
"QuincyGininda/Lightricks-LTX-Video",
"ahtasham00/Lightricks-LTX-Video",
"sebylg5/ltx-video-distilled",
"chriswastakenaswell/Lightricks-LTX-Video",
"adazf/Lightricks-LTX-Video",
"Mazensharkas/Lightricks-LTX-Video",
"mamg94/Lightricks-LTX-Video",
"Varunpavan/Lightricks-LTX-Video",
"Hellfire2003/Lightricks-LTX-Video",
"Dongeros/Lightricks-LTX-Video",
"sofiav3/Lightricks-LTX-Video",
"Textextex/Lightricks-LTX-Video",
"hgmodi1973/Lightricks-LTX-Video",
"deevanshvgpillai/Lightricks-LTX-Video",
"mane5018/Lightricks-LTX-Video",
"msjithin996/Lightricks-LTX-Video",
"Julxxx-ID/Lightricks-LTX-Video",
"aaboode/Lightricks-LTX-Video",
"aleffpimenta/Lightricks-LTX-Video",
"kasap61/Lightricks-LTX-Video",
"A13Xg/Lightricks-LTX-Video1",
"mohitgurav7/Lightricks-LTX-Video",
"SURENDRAbuoy/Lightricks-LTX-Video",
"Safih3321/text_to_image",
"wam69/Lightricks-LTX-Video",
"Eerdmann1/Lightricks-LTX-Video",
"owqbiodf/Lightricks-LTX-Video",
"Speciouz/Lightricks-LTX-Video",
"Augustar0807/Lightricks-LTX-Video",
"Mitu-Raj/Lightricks-LTX-Video",
"Hamidpajand/videomake",
"Agents-MCP-Hackathon/AgentStudio",
"ded350let/Lightricks-LTX-Video",
"Sigmaz123/Lightricks-LTX-Video",
"itssahilverma/Lightricks-LTX-Video",
"Kavin-Kuppusamy/Lightricks-LTX-Video",
"kdoory/Lightricks-LTX-Video",
"murazoid/AIVideo",
"xAssassin69/Lightricks-LTX-Video",
"Rodrigobrands/Lightricks-LTX-Video",
"ObiJuanCodenobi/Emilios-Video-Generator",
"kragle18198/Lightricks-LTX-Video",
"mahmoudgaza2023/Lightricks-LTX-Video",
"gopi-333/Lightricks-LTX-Video",
"panacot/Lightricks-LTX-Video",
"LTTEAM/VideoAI",
"KingNish/ltx-video-distilled",
"monkeable/Lightricks-LTX-Video",
"Shervinai/CiNEMOSHEN",
"Bagda/VidDubhindiX",
"Madaboss7/Mada",
"Madaboss7/Madanutri",
"Mediapro55/Lightricks-LTX-Video",
"Theoford/Lightricks-LTX-Video",
"frokido/Lightricks-LTX-Video",
"Serefor/ltx-video-distilled",
"gnosticdev/Lightricks-LTX-Video",
"Jakubeloziom/Jaku-vid",
"Arielsacol2/Lightricks-LTX-Video",
"heboya8/ltx-video-distilled",
"amy2648/Lightricks-LTX-Video",
"lustre-469/Lightricks-LTX-Video",
"gdfgfdgdfgfdg/Lightricks-LTX-Video",
"eugenepiggy/ltx-video-distilled",
"WAVbot/ltx-video-distilled",
"thevikram/ltx-video-distilled",
"conversantech/ltx-video-distilled",
"azhan77168/video",
"victor/ltx-video-distilled",
"Greff3/ltx-video",
"vyloup/ltx-video-distilled",
"Lightricks/ltx-video-iclora",
"DreamDebris/DreamDebris.ai",
"VKExodius/ltx-video-distilled2",
"VIDraft/ltx-video-iclora",
"BenLag/ltx-video-distilled",
"lucio34/ltx-video-creator",
"shaikkhan/Ai-video-gen",
"beautikini1/test",
"ysharma/ltx-video-distilled",
"HuggyGuyJo01/Lightricks-LTX-Video",
"Obunr/LTXV-loraaaaaa",
"nbxxx/Lightricks-LTX-Video",
"Carlexxx/Aduc-Sdr_Novim",
"ford442/ltx-video-distilled",
"XxReaper7xX/Lightricks-LTX-Video",
"tobiasawalkerr/Lightricks-LTX-Video",
"juici-app/Lightricks-LTX-Video",
"Phonics/Lightricks-LTX-Video",
"johnjemba/ltx-video-distilled",
"acniko/Lightricks-LTX-Video",
"pepper200pepper/Lightricks-LTX-Video",
"Carlexx/Aduc-srd_Novim",
"saifeee/Lightricks-LTX-Video",
"Wazzer221/Lightricks-LTX-Video",
"ssafiullin9/Lightricks-LTX-Video",
"DVe0UTvm4/ltx-video-distilled",
"huggingfaceck/videogen",
"jadeoo/Lightricks-LTX-Video",
"CarlexSxx/Aduc-Sdr_Novim",
"CarlexSxx/ADUC-sdr-DEFORMS_4D",
"CarlexSxx/ADUC-sdr-novim1",
"shashu4121/Ai-video",
"Djjdjddjjs829/Lightricks-LTX-Videoxx",
"Djjdjddjjs829/Lightricks-LTX-Videosss",
"Ronnie240486/Lightricks-LTX-Video",
"diego2554/Lightricks-LTX-Video",
"Bikoz1987/Lightricks-LTX-Video",
"ALSv/ltx-video",
"ISLAM26578/Lightricks-LTX-Video",
"englissi/videogenerator",
"VirtualKimi/ltx-video-distilled",
"Sushree04/LTX-Video",
"HayeDerEchte14/Lightricks-LTX-Video",
"RANSIBEatz/Lightricks-LTX-Video",
"hannna123/Lightricks-LTX-Video",
"eveval97/Lightricks-LTX-Video",
"shenzoke2424/ltx-video-distillebejejed",
"Bun2/Lightricks-LTX-Video",
"kikikatili/Lightricks-LTX-Video",
"anggsa/Lightricks-LTX-Video"
] |
[
"other"
] | null |
[
"en"
] | null | null |
[
"image-to-video"
] | null | null |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
team
|
company
|
[
"United States of America"
] | null | null |
[
"Text",
" Image",
" Video"
] |
[
"Video Generation"
] |
[
"Diffusion-based Network"
] |
[
"EN"
] |
[
"Pretraining: Supervised",
" Model Merging",
" Quantization"
] |
Not disclosed
| 9
|
680da718233834890aa01f51
|
Qwen/Qwen3-0.6B
|
Qwen
|
{
"models": [
{
"_id": "680f0da2f99a20ddfc9a9f26",
"id": "Qwen/Qwen3-0.6B-Base"
}
],
"relation": "finetune"
}
| 3,725,603
| 10,351,656
|
False
| 2025-04-27T03:40:08Z
| 2025-07-26T03:46:27Z
|
transformers
| 577
| 16
| null |
text-generation
|
{"parameters": {"BF16": 751632384}, "total": 751632384}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"generation_config.json",
"merges.txt",
"model.safetensors",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
13965,
726,
239,
1671853,
1503300328,
11422654,
9732,
2776833
] | 1,519,209,243
|
c1899de289a04d12100db370d81485cdf75e47ca
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"Qwen/Qwen3-Demo",
"trl-lib/dataset-length-profiler",
"VIDraft/Qwen3",
"lfoppiano/document-qa",
"C2MV/Biotech2",
"bartar/tokenizers",
"guiajf/select_models",
"whitecircle-ai/circle-guard-bench",
"Dalfaga/compi",
"Luigi/ZeroGPU-LLM-Inference",
"rui3000/RPS_game_assist",
"aiqtech/LLM-Token-Visual",
"charagu-eric/solar_savings",
"M17idd/army",
"VIDraft/Qwen3-0_6B",
"pedrammrm/sahadam",
"james666600/mytest",
"kz919/Qwen3-0.6B-Zero-GPU",
"ccclllwww/Assignment_V1",
"KWRegan/LIFgen",
"tdnathmlenthusiast/Skin-Disease_Classifier",
"xe1phix/Qwen3-Demo",
"MicoGuild/Olubakka",
"KraTUZen/LogicLink-Project-Space",
"aizip-dev/SLM-RAG-Arena",
"kingarnica/Qwen3-Demo",
"Vangaio/pokemon_agents",
"drecokie/dre",
"kmondal91/SimpleChat",
"ojoke/chatbot",
"Greff3/ChatVision",
"JoydeepC/2o",
"Vangaio/Final_Assignment_Template",
"zhaozengxi/Qwen3-Demo",
"audioer/LLM_demo_docker",
"Kolimbo/Qwen3-0.6B-api",
"heboya8/Qwen3-Demo",
"p11a/sahadam",
"druvx13/0.6wen",
"m17id/RazmYar",
"A-Anwar/Final_Assignment_Template",
"mahi0412/Smart_phone_finder",
"nyamberekimeu/Qwen3-Token-Counter",
"rui3000/RPSgamewithsave",
"sds-ai/Yee-R1-Demo",
"eugenepiggy/Qwen3-Demo",
"shanaka95/Qwen-Qwen3-0.6B",
"gsaltintas/tokenizer-comparison",
"mukaist/Qwen3-Demo",
"ArindamSingh/MediQuery",
"gouravbhadraDev/server_test",
"zhaozengxi/Qwen3-Demo2",
"zhaozengxi/Qwen3-Demo3",
"sizzlebop/ZeroGPU-LLM-Inference",
"faizabenatmane/fake-news-detector3-deepseek5.7",
"itsblxde/nay",
"willsh1997/moral-compass",
"Bachstelze/Round-Trip_Translation",
"nihar-sarkar/Qwen3-chat",
"GeotechnicalCoder/geobot",
"Bachstelze/Round-Trip-Qwen3",
"frankenliu/tokenizer-multi-demo",
"mrbeast4/test",
"heyuqiang/Qwen-Qwen3-0.6B",
"dalynbutler/Qwen3-Demo",
"Goldeamond/NextTokenPrediction",
"r-three/quick-tokenizer-accuracy",
"QUT-GenAILab/moral-compass",
"gauravprasadgp/Qwen3-0.6B_demeaner_hinglish",
"alonsosilva/GeorgesPerecAssistant",
"dycoon/experimental-chat2",
"david-thrower/600M-param-agent",
"ju0im6bt6/test-chat-ui",
"ju0im6bt6/gradio-chat-app",
"ju0im6bt6/llama-2-7b-chat",
"ju0im6bt6/Qwen3-0_6B",
"Shankarm08/qwenmodel",
"ShilpaGowda/ATALFDP",
"Nasreenfathima/qwendemo",
"JanhaviNandish/qwenDemo",
"meghapradeep/ATALFDP",
"divyaharish/fdp",
"lokeessshhhh/Qwen3-Demo",
"PVH412004/test_email",
"Lyte/Qwen3-0.6B-Demo-GGUF",
"meet12341234/LogLens",
"danhtran2mind/Vietnamese-Health-Chat-LoRA",
"zhouxiaoxi/text-to-text",
"Maz097/Chitti",
"dadodido/demochat",
"Praveen-0606/chatdemo",
"Yashashwinipriya/chatdemo",
"Moulyagowda/chatdemo",
"Nageshwarinagu/chatdemo",
"Yashaswiniyashu/chatdemo",
"phantomknot/SYPHER",
"adarsha439/gen_ai",
"Anushreek123/chatdemo",
"KavanaReddy/chatdemo",
"Megha-17/chatdemo",
"shravanis92975/chatdemo",
"Anuzanu/Chatdemo",
"Sharathlr/chatdemo",
"Premks/chatdemo",
"kitty1213/chatdemo",
"pavitrakasambip/chatdemo",
"harikasathya266/chatdemo",
"varshithak97/chatdemo1",
"soujanyakiresur53/sujii",
"Alishba1132/chatdemo",
"harshiniiiiii/chatdemo",
"Zuwariya06/chatdemo1",
"Guptamohit/AXON",
"AquaAura/chatdemo12",
"SahanaNS/chatdemo",
"Keerthana2504/keer123",
"Dhannsh/chatbot",
"Sharath9143/chatdemo",
"Amrutha002/chatdemo1",
"varshakbadiger/chatdemo",
"Nehayshetty/nehaaa",
"Nehayshetty/chatdemo",
"Ananyakk/chatdemo",
"Anuzanu/chatbot",
"navneetsatyamkumar/Medalpaca-distillation",
"omidwwer/Qwen3-Demo",
"sylc-takao/highlight_with_logprobs",
"taruschirag/DynaGuard",
"FlowerCui/EamonGPT",
"vishaljoshi24/trl-4-dnd",
"BladeSzaSza/DigitalPal",
"tomg-group-umd/DynaGuard",
"RohanVashisht/asdfasdf",
"tpesso/up-there",
"tpesso/up-there-M2",
"nikmahh/chatbot",
"tpesso/up-there-M1",
"PeterPinetree/NextTokenPredictor",
"tpesso2/up-there2-M2",
"Vinay8903/Rag-chat",
"Vinay8903/Rag-chat-backend",
"akkariin/selective-prompt-anchoring",
"autogenlabs/Qwen-Qwen3-0.6B",
"op55412/Qwen3-Demo",
"TakiTakiTa/voice_chat_bot",
"yarenty/Chat_tester"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/LICENSE"
] | null | null | 751,632,384
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null |
Qwen/Qwen3-0.6B-Base
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"multilingual"
] |
[
"Finetuning: Supervised",
" Multi-task finetuning"
] |
Not disclosed
| 3
|
684d6f506551d98719ae5c38
|
Motif-Technologies/optimizer
|
Motif-Technologies
| null | 0
| 0
|
False
| 2025-06-14T12:47:12Z
| 2025-08-28T08:46:04Z
| null | 39
| 16
| null | null | null |
[
".gitattributes",
"README.md",
"build.toml",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/__init__.py",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/_ops.py",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch27-cxx11-cu118-x86_64-linux/optimizer/muon.py",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/__init__.py",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/_ops.py",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch27-cxx11-cu126-x86_64-linux/optimizer/muon.py",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/__init__.py",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/_ops.py",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch27-cxx11-cu128-x86_64-linux/optimizer/muon.py",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/__init__.py",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/_ops.py",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch27-cxx11-rocm63-x86_64-linux/optimizer/muon.py",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/__init__.py",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/_ops.py",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch28-cxx11-cu126-x86_64-linux/optimizer/muon.py",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/__init__.py",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/_ops.py",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch28-cxx11-cu128-x86_64-linux/optimizer/muon.py",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/__init__.py",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/_ops.py",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch28-cxx11-cu129-x86_64-linux/optimizer/muon.py",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/__init__.py",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/_ops.py",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch28-cxx11-rocm63-x86_64-linux/optimizer/muon.py",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/__init__.py",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/__pycache__/__init__.cpython-313.pyc",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/__pycache__/muon.cpython-313.pyc",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/_ops.py",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/_optimizer_2dc97a1_dirty.abi3.so",
"build/torch28-cxx11-rocm64-x86_64-linux/optimizer/muon.py",
"docs/muon/balanced.png",
"docs/muon/distributed_muon.png",
"docs/muon/distributed_muon_execution.png",
"docs/muon/imbalance.png",
"docs/muon/main.tex",
"docs/muon/naive_execution.png",
"docs/muon/parallel_muon.pdf",
"docs/muon/pipelined.png",
"flake.nix",
"optimizer/dummy.cu",
"torch-ext/optimizer/__init__.py",
"torch-ext/optimizer/muon.py",
"torch-ext/torch_binding.cpp",
"torch-ext/torch_binding.h"
] | null | null |
15b5d41e1f92334bd43876c67f606faee90cfe1b
|
[
"kernel",
"license:apache-2.0",
"region:us"
] | null |
# Optimizer
Optimizer is a python package that provides:
- PyTorch implementation of recent optimizer algorithms
- with support for parallelism techniques for efficient large-scale training.
### Currently implemented
- [Parallel Muon with FSDP2](./docs/muon/parallel_muon.pdf)
## Usage
```python
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from kernels import get_kernel
optimizer = get_kernel("motif-technologies/optimizer")
model = None # your model here
fsdp_model = FSDP(model)
optim = optimizer.Muon(
fsdp_model.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=1e-4,
)
```
| null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68544bb908d8c86c86e4781e
|
mistralai/Mistral-Small-3.2-24B-Instruct-2506
|
mistralai
|
{
"models": [
{
"_id": "67d75f3fd56afd880495e9b6",
"id": "mistralai/Mistral-Small-3.1-24B-Base-2503"
}
],
"relation": "finetune"
}
| 383,402
| 549,160
|
False
| 2025-06-19T17:41:13Z
| 2025-08-21T17:46:51Z
|
vllm
| 428
| 16
| null | null |
{"parameters": {"BF16": 24011361280}, "total": 24011361280}
|
[
".gitattributes",
"README.md",
"SYSTEM_PROMPT.txt",
"config.json",
"consolidated.safetensors",
"generation_config.json",
"model-00001-of-00010.safetensors",
"model-00002-of-00010.safetensors",
"model-00003-of-00010.safetensors",
"model-00004-of-00010.safetensors",
"model-00005-of-00010.safetensors",
"model-00006-of-00010.safetensors",
"model-00007-of-00010.safetensors",
"model-00008-of-00010.safetensors",
"model-00009-of-00010.safetensors",
"model-00010-of-00010.safetensors",
"model.safetensors.index.json",
"params.json",
"tekken.json"
] |
[
1567,
25365,
2384,
1172,
48022792280,
134,
4883550696,
4781593336,
4886472224,
4781593376,
4781593368,
4886472248,
4781593376,
4781593368,
4886472248,
4571866320,
57907,
807,
19399895
] | 96,065,082,071
|
cb17b97769b0305ddc717ede4a4ef6fd54ef8371
|
[
"vllm",
"safetensors",
"mistral3",
"mistral-common",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.1-24B-Base-2503",
"base_model:finetune:mistralai/Mistral-Small-3.1-24B-Base-2503",
"license:apache-2.0",
"region:us"
] | null |
# Mistral-Small-3.2-24B-Instruct-2506
Mistral-Small-3.2-24B-Instruct-2506 is a minor update of [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503).
Small-3.2 improves in the following categories:
- **Instruction following**: Small-3.2 is better at following precise instructions
- **Repetition errors**: Small-3.2 produces less infinite generations or repetitive answers
- **Function calling**: Small-3.2's function calling template is more robust (see [here](https://github.com/mistralai/mistral-common/blob/535b4d0a0fc94674ea17db6cf8dc2079b81cbcfa/src/mistral_common/tokens/tokenizers/instruct.py#L778) and [examples](#function-calling))
In all other categories Small-3.2 should match or slightly improve compared to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503).
## Key Features
- same as [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503#key-features)
## Benchmark Results
We compare Mistral-Small-3.2-24B to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503).
For more comparison against other models of similar size, please check [Mistral-Small-3.1's Benchmarks'](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503#benchmark-results)
### Text
#### Instruction Following / Chat / Tone
| Model | Wildbench v2 | Arena Hard v2 | IF (Internal; accuracy) |
|-------|---------------|---------------|------------------------|
| Small 3.1 24B Instruct | 55.6% | 19.56% | 82.75% |
| **Small 3.2 24B Instruct** | **65.33%** | **43.1%** | **84.78%** |
#### Infinite Generations
Small 3.2 reduces infinite generations by 2x on challenging, long and repetitive prompts.
| Model | Infinite Generations (Internal; Lower is better) |
|-------|-------|
| Small 3.1 24B Instruct | 2.11% |
| **Small 3.2 24B Instruct** | **1.29%** |
#### STEM
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP Plus - Pass@5 | HumanEval Plus - Pass@5 | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|--------------------|-------------------------|--------------------|
| Small 3.1 24B Instruct | 80.62% | 66.76% | 69.30% | 44.42% | 45.96% | 74.63% | 88.99% | 10.43% |
| **Small 3.2 24B Instruct** | 80.50% | **69.06%** | 69.42% | 44.22% | 46.13% | **78.33%** | **92.90%** | **12.10%** |
### Vision
| Model | MMMU | Mathvista | ChartQA | DocVQA | AI2D |
|--------------------------------|------------|-----------|-----------|-----------|-----------|
| Small 3.1 24B Instruct | **64.00%** | **68.91%**| 86.24% | 94.08% | 93.72% |
| **Small 3.2 24B Instruct** | 62.50% | 67.09% | **87.4%** | 94.86% | 92.91% |
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailor it to your needs. If you want to use the model as a general assistant, we recommend to use the one provided in the [SYSTEM_PROMPT.txt](https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506/blob/main/SYSTEM_PROMPT.txt) file.
### vLLM (recommended)
We recommend using this model with [vLLM](https://github.com/vllm-project/vllm).
#### Installation
Make sure to install [`vLLM >= 0.9.1`](https://github.com/vllm-project/vllm/releases/tag/v0.9.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.6.2`](https://github.com/mistralai/mistral-common/releases/tag/v1.6.2).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Serve
We recommend that you use Mistral-Small-3.2-24B-Instruct-2506 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.2-24B-Instruct-2506 \
--tokenizer_mode mistral --config_format mistral \
--load_format mistral --tool-call-parser mistral \
--enable-auto-tool-choice --limit-mm-per-prompt '{"image":10}' \
--tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.2-24B-Instruct-2506 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet. See the following examples.
#### Vision reasoning
Leverage the vision capabilities of Mistral-Small-3.2-24B-Instruct-2506 to make the best choice given a scenario, go catch them all !
<details>
<summary>Python snippet</summary>
```py
from datetime import datetime, timedelta
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture the Pidgey or heal your Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat the Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be a strategic move if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could save time and conserve your Pokémon's health and resources. If you are in a hurry or do not need the experience or items, running away is a safe option.
# - **Cons**: Running away means you miss out on the experience points and potential items or money that you could gain from defeating the Pidgey. It also means you do not get the chance to capture the Pidgey if you wanted to.
# ### Recommendation:
# Given the significant level advantage, the best action is likely to **FIGHT**. This will allow you to quickly defeat the Pidgey, gain experience points, and potentially earn items or money. If you are concerned about Pikachu's health, you could use an item from your **BAG** to heal it before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
#### Function calling
Mistral-Small-3.2-24B-Instruct-2506 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Python snippet - easy</summary>
```py
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
tools = [
{
"type": "function",
"function": {
"name": "get_current_population",
"description": "Get the up-to-date population of a given country.",
"parameters": {
"type": "object",
"properties": {
"country": {
"type": "string",
"description": "The country to find the population of.",
},
"unit": {
"type": "string",
"description": "The unit for the population.",
"enum": ["millions", "thousands"],
},
},
"required": ["country", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you tell me what is the biggest country depicted on the map?",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# The biggest country depicted on the map is Russia.
messages.extend([
{"role": "assistant", "content": assistant_message},
{"role": "user", "content": "What is the population of that country in millions?"},
])
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message.tool_calls)
# [ChatCompletionMessageToolCall(id='3e92V6Vfo', function=Function(arguments='{"country": "Russia", "unit": "millions"}', name='get_current_population'), type='function')]
```
</details>
<details>
<summary>Python snippet - complex</summary>
```python
import json
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://math-coaching.com/img/fiche/46/expressions-mathematiques.jpg"
def my_calculator(expression: str) -> str:
return str(eval(expression))
tools = [
{
"type": "function",
"function": {
"name": "my_calculator",
"description": "A calculator that can evaluate a mathematical expression.",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "The mathematical expression to evaluate.",
},
},
"required": ["expression"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you calculate the results for all the equations displayed in the image? Only compute the ones that involve numbers.",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
tool_calls = response.choices[0].message.tool_calls
print(tool_calls)
# [ChatCompletionMessageToolCall(id='CyQBSAtGh', function=Function(arguments='{"expression": "6 + 2 * 3"}', name='my_calculator'), type='function'), ChatCompletionMessageToolCall(id='KQqRCqvzc', function=Function(arguments='{"expression": "19 - (8 + 2) + 1"}', name='my_calculator'), type='function')]
results = []
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = tool_call.function.arguments
if function_name == "my_calculator":
result = my_calculator(**json.loads(function_args))
results.append(result)
messages.append({"role": "assistant", "tool_calls": tool_calls})
for tool_call, result in zip(tool_calls, results):
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": result,
}
)
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# Here are the results for the equations that involve numbers:
# 1. \( 6 + 2 \times 3 = 12 \)
# 3. \( 19 - (8 + 2) + 1 = 10 \)
# For the other equations, you need to substitute the variables with specific values to compute the results.
```
</details>
#### Instruction following
Mistral-Small-3.2-24B-Instruct-2506 will follow your instructions down to the last letter !
<details>
<summary>Python snippet</summary>
```python
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Write me a sentence where every word starts with the next letter in the alphabet - start with 'a' and end with 'z'.",
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# Here's a sentence where each word starts with the next letter of the alphabet, starting from 'a' and ending with 'z':
# "Always brave cats dance elegantly, fluffy giraffes happily ignore jungle kites, lovingly munching nuts, observing playful quails racing swiftly, tiny unicorns vaulting while xylophones yodel zealously."
# This sentence follows the sequence from A to Z without skipping any letters.
```
</details>
### Transformers
You can also use Mistral-Small-3.2-24B-Instruct-2506 with `Transformers` !
To make the best use of our model with `Transformers` make sure to have [installed](https://github.com/mistralai/mistral-common) `mistral-common >= 1.6.2` to use our tokenizer.
```bash
pip install mistral-common --upgrade
```
Then load our tokenizer along with the model and generate:
<details>
<summary>Python snippet</summary>
```python
from datetime import datetime, timedelta
import torch
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from huggingface_hub import hf_hub_download
from transformers import Mistral3ForConditionalGeneration
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
tokenizer = MistralTokenizer.from_hf_hub(model_id)
model = Mistral3ForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.bfloat16
)
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
tokenized = tokenizer.encode_chat_completion(ChatCompletionRequest(messages=messages))
input_ids = torch.tensor([tokenized.tokens])
attention_mask = torch.ones_like(input_ids)
pixel_values = torch.tensor(tokenized.images[0], dtype=torch.bfloat16).unsqueeze(0)
image_sizes = torch.tensor([pixel_values.shape[-2:]])
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
image_sizes=image_sizes,
max_new_tokens=1000,
)[0]
decoded_output = tokenizer.decode(output[len(tokenized.tokens) :])
print(decoded_output)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture Pidgey or heal Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be strategic if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could be a quick way to avoid the battle altogether. This might be useful if you are trying to conserve resources or if you are in a hurry to get to another location.
# - **Cons**: Running away means you miss out on the experience points, items, or money that you could gain from defeating Pidgey. It also might not be the most efficient use of your time if you are trying to train your Pokémon.
# ### Recommendation:
# Given the significant level advantage, the best action to take is likely **FIGHT**. This will allow you to quickly defeat Pidgey and gain experience points for Pikachu. If you are concerned about Pikachu's health, you could use the **BAG** to heal Pikachu before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
|
[
"Ludovicollin/agentia",
"parkuman/gaia-agent",
"macilAI/Trumpslator",
"bhutesh65/jupiter-faq-bot",
"bhutesh65/Jupiter-FAQ-streamlit",
"CultriX/CodeConverter",
"Bharatkori/text_to_image_mistral_small_3.2",
"mojtabaghollama/taste",
"mojtabaghollama/taste2"
] |
[
"apache-2.0"
] | null |
[
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn"
] | 24,011,361,280
| null | null | null |
[
"Mistral3ForConditionalGeneration",
"mistral3"
] | null | null | null |
team
|
company
|
[
"France"
] | null | null | null | null | null | null | null | null | null |
687a1570dce335c547e426ab
|
Wan-AI/Wan2.2-TI2V-5B
|
Wan-AI
| null | 16,675
| 18,989
|
False
| 2025-07-18T09:35:44Z
| 2025-08-07T10:22:24Z
|
wan2.2
| 329
| 16
| null |
text-to-video
| null |
[
".gitattributes",
".msc",
".mv",
"README.md",
"Wan2.2_VAE.pth",
"assets/comp_effic.png",
"assets/logo.png",
"assets/moe_2.png",
"assets/moe_arch.png",
"assets/performance.png",
"assets/vae.png",
"config.json",
"configuration.json",
"diffusion_pytorch_model-00001-of-00003.safetensors",
"diffusion_pytorch_model-00002-of-00003.safetensors",
"diffusion_pytorch_model-00003-of-00003.safetensors",
"diffusion_pytorch_model.safetensors.index.json",
"examples/i2v_input.JPG",
"google/umt5-xxl/special_tokens_map.json",
"google/umt5-xxl/spiece.model",
"google/umt5-xxl/tokenizer.json",
"google/umt5-xxl/tokenizer_config.json",
"models_t5_umt5-xxl-enc-bf16.pth"
] |
[
1866,
507,
36,
15935,
2818839170,
202156,
56322,
527914,
74900,
306535,
165486,
251,
43,
9825014472,
9995661736,
178558176,
72865,
250628,
6623,
4548313,
16837417,
61728,
11361920418
] | 34,203,123,497
|
921dbaf3f1674a56f47e83fb80a34bac8a8f203e
|
[
"wan2.2",
"diffusers",
"safetensors",
"ti2v",
"text-to-video",
"en",
"zh",
"arxiv:2503.20314",
"license:apache-2.0",
"region:us"
] | null |
# Wan2.2
<p align="center">
<img src="assets/logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.2">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Technical Report</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
<br>
-----
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
We are excited to introduce **Wan2.2**, a major upgrade to our foundational video models. With **Wan2.2**, we have focused on incorporating the following innovations:
- 👍 **Effective MoE Architecture**: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
- 👍 **Cinematic-level Aesthetics**: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
- 👍 **Complex Motion Generation**: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
- 👍 **Efficient High-Definition Hybrid TI2V**: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of **16×16×4**. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest **720P@24fps** models currently available, capable of serving both the industrial and academic sectors simultaneously.
This repository contains our TI2V-5B model, built with the advanced Wan2.2-VAE that achieves a compression ratio of 16×16×4. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can runs on single consumer-grade GPU such as the 4090. It is one of the fastest 720P@24fps models available, meeting the needs of both industrial applications and academic research.
## Video Demos
<div align="center">
<video width="80%" controls>
<source src="https://cloud.video.taobao.com/vod/4szTT1B0LqXvJzmuEURfGRA-nllnqN_G2AT0ZWkQXoQ.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
</div>
## 🔥 Latest News!!
* Jul 28, 2025: 👋 We've released the inference code and model weights of **Wan2.2**.
## Community Works
If your research or project builds upon [**Wan2.1**](https://github.com/Wan-Video/Wan2.1) or Wan2.2, we welcome you to share it with us so we can highlight it for the broader community.
## 📑 Todo List
- Wan2.2 Text-to-Video
- [x] Multi-GPU Inference code of the A14B and 14B models
- [x] Checkpoints of the A14B and 14B models
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Image-to-Video
- [x] Multi-GPU Inference code of the A14B model
- [x] Checkpoints of the A14B model
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Text-Image-to-Video
- [x] Multi-GPU Inference code of the 5B model
- [x] Checkpoints of the 5B model
- [x] ComfyUI integration
- [x] Diffusers integration
## Run Wan2.2
#### Installation
Clone the repo:
```sh
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
```
Install dependencies:
```sh
# Ensure torch >= 2.4.0
pip install -r requirements.txt
```
#### Model Download
| Models | Download Links | Description |
|--------------------|---------------------------------------------------------------------------------------------------------------------------------------------|-------------|
| T2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Text-to-Video MoE model, supports 480P & 720P |
| I2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Image-to-Video MoE model, supports 480P & 720P |
| TI2V-5B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | High-compression VAE, T2V+I2V, supports 720P |
> 💡Note:
> The TI2V-5B model supports 720P video generation at **24 FPS**.
Download models using huggingface-cli:
``` sh
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
```
Download models using modelscope-cli:
``` sh
pip install modelscope
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
```
#### Run Text-Image-to-Video Generation
This repository supports the `Wan2.2-TI2V-5B` Text-Image-to-Video model and can support video generation at 720P resolutions.
- Single-GPU Text-to-Video inference
```sh
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage"
```
> 💡Unlike other tasks, the 720P resolution of the Text-Image-to-Video task is `1280*704` or `704*1280`.
> This command can run on a GPU with at least 24GB VRAM (e.g, RTX 4090 GPU).
> 💡If you are running on a GPU with at least 80GB VRAM, you can remove the `--offload_model True`, `--convert_model_dtype` and `--t5_cpu` options to speed up execution.
- Single-GPU Image-to-Video inference
```sh
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
> 💡If the image parameter is configured, it is an Image-to-Video generation; otherwise, it defaults to a Text-to-Video generation.
> 💡Similar to Image-to-Video, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
```sh
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
```
> The process of prompt extension can be referenced [here](#2-using-prompt-extention).
## Computational Efficiency on Different GPUs
We test the computational efficiency of different **Wan2.2** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
<div align="center">
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
</div>
> The parameter settings for the tests presented in this table are as follows:
> (1) Multi-GPU: 14B: `--ulysses_size 4/8 --dit_fsdp --t5_fsdp`, 5B: `--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu`; Single-GPU: 14B: `--offload_model True --convert_model_dtype`, 5B: `--offload_model True --convert_model_dtype --t5_cpu`
(--convert_model_dtype converts model parameter types to config.param_dtype);
> (2) The distributed testing utilizes the built-in FSDP and Ulysses implementations, with FlashAttention3 deployed on Hopper architecture GPUs;
> (3) Tests were run without the `--use_prompt_extend` flag;
> (4) Reported results are the average of multiple samples taken after the warm-up phase.
-------
## Introduction of Wan2.2
**Wan2.2** builds on the foundation of Wan2.1 with notable improvements in generation quality and model capability. This upgrade is driven by a series of key technical innovations, mainly including the Mixture-of-Experts (MoE) architecture, upgraded training data, and high-compression video generation.
##### (1) Mixture-of-Experts (MoE) Architecture
Wan2.2 introduces Mixture-of-Experts (MoE) architecture into the video generation diffusion model. MoE has been widely validated in large language models as an efficient approach to increase total model parameters while keeping inference cost nearly unchanged. In Wan2.2, the A14B model series adopts a two-expert design tailored to the denoising process of diffusion models: a high-noise expert for the early stages, focusing on overall layout; and a low-noise expert for the later stages, refining video details. Each expert model has about 14B parameters, resulting in a total of 27B parameters but only 14B active parameters per step, keeping inference computation and GPU memory nearly unchanged.
<div align="center">
<img src="assets/moe_arch.png" alt="" style="width: 90%;" />
</div>
The transition point between the two experts is determined by the signal-to-noise ratio (SNR), a metric that decreases monotonically as the denoising step $t$ increases. At the beginning of the denoising process, $t$ is large and the noise level is high, so the SNR is at its minimum, denoted as ${SNR}_{min}$. In this stage, the high-noise expert is activated. We define a threshold step ${t}_{moe}$ corresponding to half of the ${SNR}_{min}$, and switch to the low-noise expert when $t<{t}_{moe}$.
<div align="center">
<img src="assets/moe_2.png" alt="" style="width: 90%;" />
</div>
To validate the effectiveness of the MoE architecture, four settings are compared based on their validation loss curves. The baseline **Wan2.1** model does not employ the MoE architecture. Among the MoE-based variants, the **Wan2.1 & High-Noise Expert** reuses the Wan2.1 model as the low-noise expert while uses the Wan2.2's high-noise expert, while the **Wan2.1 & Low-Noise Expert** uses Wan2.1 as the high-noise expert and employ the Wan2.2's low-noise expert. The **Wan2.2 (MoE)** (our final version) achieves the lowest validation loss, indicating that its generated video distribution is closest to ground-truth and exhibits superior convergence.
##### (2) Efficient High-Definition Hybrid TI2V
To enable more efficient deployment, Wan2.2 also explores a high-compression design. In addition to the 27B MoE models, a 5B dense model, i.e., TI2V-5B, is released. It is supported by a high-compression Wan2.2-VAE, which achieves a $T\times H\times W$ compression ratio of $4\times16\times16$, increasing the overall compression rate to 64 while maintaining high-quality video reconstruction. With an additional patchification layer, the total compression ratio of TI2V-5B reaches $4\times32\times32$. Without specific optimization, TI2V-5B can generate a 5-second 720P video in under 9 minutes on a single consumer-grade GPU, ranking among the fastest 720P@24fps video generation models. This model also natively supports both text-to-video and image-to-video tasks within a single unified framework, covering both academic research and practical applications.
<div align="center">
<img src="assets/vae.png" alt="" style="width: 80%;" />
</div>
##### Comparisons to SOTAs
We compared Wan2.2 with leading closed-source commercial models on our new Wan-Bench 2.0, evaluating performance across multiple crucial dimensions. The results demonstrate that Wan2.2 achieves superior performance compared to these leading models.
<div align="center">
<img src="assets/performance.png" alt="" style="width: 90%;" />
</div>
## Citation
If you find our work helpful, please cite us.
```
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}
```
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
## Acknowledgements
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
## Contact Us
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
[
"Wan-AI/Wan-2.2-5B",
"wavespeed/wan2.2",
"Heartsync/Wan-2.2-ADULT",
"AlekseyCalvin/FastWan2.2_5B_TI2V",
"ginigen/Wan-2.2-Enhanced",
"nazdridoy/inferoxy-hub",
"innoai/Wan-2.2-5B",
"rahul7star/Wan-2.2-5B",
"nalengyu/Wan-2.2-5B",
"wana14/Wan-2.2-5B",
"skrov/Wan-AI-Wan2.2-TI2V-5B",
"rahul7star/wan2.2TITV5BRepo",
"Fingitalian/Wan-AI-Wan2.2-TI2V-5B",
"MindOfDev/Wan-2.2-5B",
"ABitGinger/Wan-AI-Wan2.2-TI2V-5B",
"yoyoredliodesigns/Wan-AI-Wan2.2-TI2V-5B",
"Jor12/Wan-AI-Wan2.2-TI2V-5B",
"nishantdas11/Wan-AI-Wan2.2-TI2V-5B",
"justnath/FastWan2.2_5B_TI2V",
"powolnik/Wan-AI-Wan2.2-T2V-A14B-ZERO",
"skykholodovzz/Wan-2.2-ADULT",
"xxmichal/Wan-2.2-5B",
"hweas/Wan-AI-Wan2.2-TI2V-5B",
"sunainonline/Wan-AI-Wan2.2-TI2V-5B",
"Soumyajitxedu/Wan-AI-Wan2.2testexp",
"alexl1973/Wan-2.2-5B",
"Wangzhicheng6426/Wan-AI-Wan2.2-TI2V-5B",
"dangthr/Wan-2.2-5B",
"shafqat786/Wan-AI-Wan2.2-TI2V-5B",
"01devManish/Wan-AI-Wan2.2-TI2V-5B009",
"woo2a/Wan-AI-Wan2.2-TI2V-5B",
"mettoki/Wan-AI-Wan2.2-TI2V-5B",
"sensusinvistaltd/Wan-AI-Wan2.2-TI2V-5B",
"melihozlem/Wan-AI-Wan2.2-TI2V-5B",
"jblast94/Wan-2.2-ADULT",
"heheehejfkrkr/Wan-2.2-ADULT",
"fokan/train-modle",
"danielgarciav888/Wan-AI-Wan2.2-TI2V-5B",
"Navjeet07/Wan-AI-Wan2.2-TI2V-5B",
"venkatchiranjeevi/Wan-AI-Wan2.2-TI2V-5B",
"Jojo369/Wan-AI-Wan2.2-TI2V-5B",
"erasa123/Wan-AI-Wan2.2-TI2V-5B"
] |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | null |
[
"text-to-video"
] | null |
[
"ti2v"
] |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6887274f2626398dc2e9f540
|
Qwen/Qwen3-30B-A3B-Instruct-2507
|
Qwen
| null | 925,254
| 955,882
|
False
| 2025-07-28T07:31:27Z
| 2025-08-17T08:20:34Z
|
transformers
| 521
| 16
| null |
text-generation
|
{"parameters": {"BF16": 30532122624}, "total": 30532122624}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"config_1m.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00016.safetensors",
"model-00002-of-00016.safetensors",
"model-00003-of-00016.safetensors",
"model-00004-of-00016.safetensors",
"model-00005-of-00016.safetensors",
"model-00006-of-00016.safetensors",
"model-00007-of-00016.safetensors",
"model-00008-of-00016.safetensors",
"model-00009-of-00016.safetensors",
"model-00010-of-00016.safetensors",
"model-00011-of-00016.safetensors",
"model-00012-of-00016.safetensors",
"model-00013-of-00016.safetensors",
"model-00014-of-00016.safetensors",
"model-00015-of-00016.safetensors",
"model-00016-of-00016.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
15418,
963,
77313,
239,
1671839,
3998893112,
3999974192,
3997360832,
3999975056,
3999975400,
3999975400,
3999975472,
3997362064,
3999975408,
3999975400,
3999975408,
3987924896,
3999975088,
3999975400,
3999975400,
1085307128,
1699758,
11422654,
10825,
2776833
] | 61,084,264,411
|
61082d4deaa4785f64943b443cbc2b5de7524fad
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-30B-A3B-Instruct-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, named **Qwen3-30B-A3B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
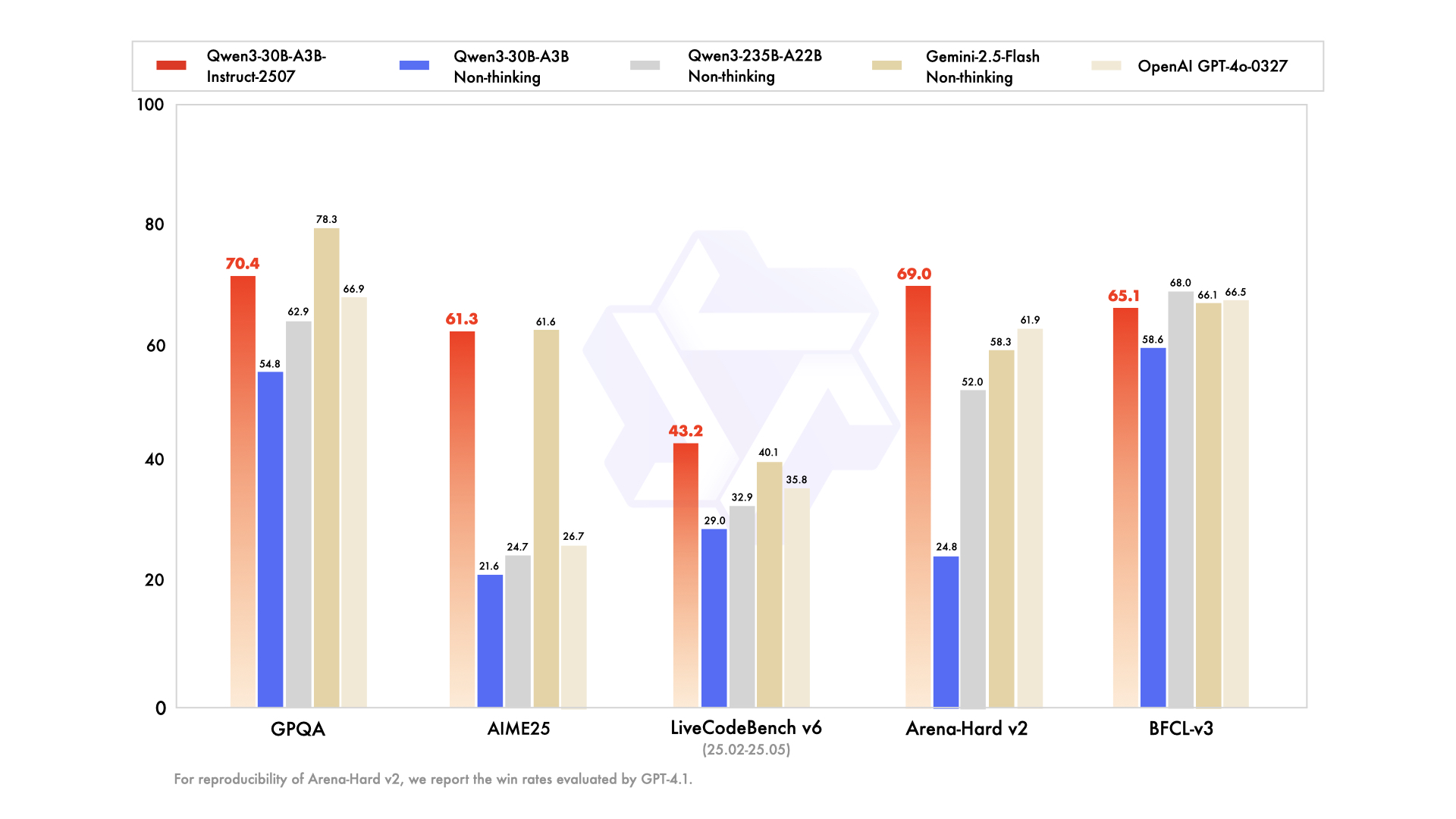
## Model Overview
**Qwen3-30B-A3B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | |
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **240 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-30B-A3B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-30B-A3B-Instruct-2507 \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-30B-A3B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 4 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 4` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B (Non-Thinking) | 72.0 | 97.1 | 96.1 | 95.0 | 92.2 | 82.6 | 79.7 | 76.9 | 70.2 | 66.3 | 61.9 | 55.4 | 52.6 | 51.5 | 52.0 | 50.9 |
| Qwen3-30B-A3B-Instruct-2507 (Full Attention) | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-30B-A3B-Instruct-2507 (Sparse Attention) | 86.8 | 98.0 | 97.1 | 96.3 | 95.1 | 93.6 | 92.5 | 88.1 | 87.7 | 82.9 | 85.7 | 80.7 | 80.0 | 76.9 | 75.5 | 72.2 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
[
"milwright/chatui-helper",
"milwright/test-bot",
"qgyd2021/llm_eval_system",
"milwright/chat-adventure-games",
"liucen56/adventure",
"CUNYGradCenter/AmigAI-Demo",
"unfiltrdfreedom/prompt-evolver",
"vsierramatute/AmigAI-Test",
"liucen56/Frenchlearning",
"VNS12/Task1_FormulateYourQuestion",
"VNS12/Task2_ResearchPlanAssistant",
"mnadell/41134114Brainstormer",
"mnadell/41134114_Translation",
"mnadell/41134114_counter_sub_arguments",
"m-ric/predibench-backend",
"VNS12/Task3_ResearchAnalyses",
"mnadell/3180grammar_and_spellchecker",
"little-huang/Chat_template_viewer",
"Jimmyjonezz/Elara",
"mnadell/Career_Exploration_for_English_Majors",
"gugapiyal/Qwen3-30B"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507/blob/main/LICENSE"
] | null | null | 30,532,122,624
| null |
[
"text-generation"
] | null |
[
"Qwen3MoeForCausalLM",
"qwen3_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
689ef1d3f46e657d684e9906
|
mPLUG/GUI-Owl-7B
|
mPLUG
|
{
"models": [
{
"_id": "6795ffcd88cd7c0294702a72",
"id": "Qwen/Qwen2.5-VL-7B-Instruct"
}
],
"relation": "finetune"
}
| 285
| 285
|
False
| 2025-08-15T08:37:39Z
| 2025-08-22T03:19:32Z
| null | 28
| 16
| null | null |
{"parameters": {"BF16": 8296592640}, "total": 8296592640}
|
[
".gitattributes",
"README.md",
"chat_template.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00005.safetensors",
"model-00002-of-00005.safetensors",
"model-00003-of-00005.safetensors",
"model-00004-of-00005.safetensors",
"model-00005-of-00005.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
7c1644c0288da07435a485701d0fea0ac353f38a
|
[
"safetensors",
"qwen2_5_vl",
"arxiv:2508.15144",
"en",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"license:mit",
"region:us"
] | null |
# GUI-Owl
<div align="center">
<img src=https://youke1.picui.cn/s1/2025/08/18/68a2f82fef3d4.png width="40%"/>
</div>
GUI-Owl is a model series developed as part of the Mobile-Agent-V3 project. It achieves state-of-the-art performance across a range of GUI automation benchmarks, including ScreenSpot-V2, ScreenSpot-Pro, OSWorld-G, MMBench-GUI, Android Control, Android World, and OSWorld. Furthermore, it can be instantiated as various specialized agents within the Mobile-Agent-V3 multi-agent framework to accomplish more complex tasks.
* **Paper**: [Paper Link](https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/MobileAgentV3_Tech.pdf)
* **GitHub Repository**: https://github.com/X-PLUG/MobileAgent
* **Online Demo**: Comming soon
## Performance
### ScreenSpot-V2, ScreenSpot-Pro and OSWorld-G
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/screenspot_v2.jpg?raw=true" width="80%"/>
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/screenspot_pro.jpg?raw=true" width="80%"/>
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/osworld_g.jpg?raw=true" width="80%"/>
### MMBench-GUI L1, L2 and Android Control
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/mmbench_gui_l1.jpg?raw=true" width="80%"/>
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/mmbench_gui_l2.jpg?raw=true" width="80%"/>
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/android_control.jpg?raw=true" width="60%"/>
### Android World and OSWorld-Verified
<img src="https://github.com/X-PLUG/MobileAgent/blob/main/Mobile-Agent-v3/assets/online.jpg?raw=true" width="60%"/>
## Usage
Please refer to our cookbook.
## Deploy
We recommand deploy GUI-Owl-7B through vllm
This script has been validated on an A100 with 96 GB of VRAM.
```bash
PIXEL_ARGS='{"min_pixels":3136,"max_pixels":10035200}'
IMAGE_LIMIT_ARGS='image=2'
MP_SIZE=1
MM_KWARGS=(
--mm-processor-kwargs $PIXEL_ARGS
--limit-mm-per-prompt $IMAGE_LIMIT_ARGS
)
vllm serve $CKPT \
--max-model-len 32768 ${MM_KWARGS[@]} \
--tensor-parallel-size $MP_SIZE \
--allowed-local-media-path '/' \
--port 4243
```
If you want GUI-Owl to recieve more than two images, you could increase `IMAGE_LIMIT_ARGS` and reduce `max_pixels`.
For example:
```bash
PIXEL_ARGS='{"min_pixels":3136,"max_pixels":3211264}'
IMAGE_LIMIT_ARGS='image=5'
MP_SIZE=1
MM_KWARGS=(
--mm-processor-kwargs $PIXEL_ARGS
--limit-mm-per-prompt $IMAGE_LIMIT_ARGS
)
vllm serve $CKPT \
--max-model-len 32768 ${MM_KWARGS[@]} \
--tensor-parallel-size $MP_SIZE \
--allowed-local-media-path '/' \
--port 4243
```
## Citation
If you find our paper and model useful in your research, feel free to give us a cite.
```
@misc{ye2025mobileagentv3foundamentalagentsgui,
title={Mobile-Agent-v3: Foundamental Agents for GUI Automation},
author={Jiabo Ye and Xi Zhang and Haiyang Xu and Haowei Liu and Junyang Wang and Zhaoqing Zhu and Ziwei Zheng and Feiyu Gao and Junjie Cao and Zhengxi Lu and Jitong Liao and Qi Zheng and Fei Huang and Jingren Zhou and Ming Yan},
year={2025},
eprint={2508.15144},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.15144},
}
```
| null |
[
"mit"
] | null |
[
"en"
] | 8,296,592,640
| null | null | null |
[
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a34c8fa39b3f545a0ad475
|
NousResearch/Hermes-4-405B-FP8
|
NousResearch
|
{
"models": [
{
"_id": "6695cd12321386ed51d7bc22",
"id": "meta-llama/Llama-3.1-405B"
}
],
"relation": "quantized"
}
| 1,352
| 1,352
|
False
| 2025-08-18T15:53:51Z
| 2025-08-26T18:45:27Z
|
transformers
| 16
| 16
|
[{"name": "Hermes-4-Llama-3.1-405B", "results": []}]
|
text-generation
|
{"parameters": {"BF16": 4226707456, "F8_E4M3": 401646551040}, "total": 405873258496}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00086.safetensors",
"model-00002-of-00086.safetensors",
"model-00003-of-00086.safetensors",
"model-00004-of-00086.safetensors",
"model-00005-of-00086.safetensors",
"model-00006-of-00086.safetensors",
"model-00007-of-00086.safetensors",
"model-00008-of-00086.safetensors",
"model-00009-of-00086.safetensors",
"model-00010-of-00086.safetensors",
"model-00011-of-00086.safetensors",
"model-00012-of-00086.safetensors",
"model-00013-of-00086.safetensors",
"model-00014-of-00086.safetensors",
"model-00015-of-00086.safetensors",
"model-00016-of-00086.safetensors",
"model-00017-of-00086.safetensors",
"model-00018-of-00086.safetensors",
"model-00019-of-00086.safetensors",
"model-00020-of-00086.safetensors",
"model-00021-of-00086.safetensors",
"model-00022-of-00086.safetensors",
"model-00023-of-00086.safetensors",
"model-00024-of-00086.safetensors",
"model-00025-of-00086.safetensors",
"model-00026-of-00086.safetensors",
"model-00027-of-00086.safetensors",
"model-00028-of-00086.safetensors",
"model-00029-of-00086.safetensors",
"model-00030-of-00086.safetensors",
"model-00031-of-00086.safetensors",
"model-00032-of-00086.safetensors",
"model-00033-of-00086.safetensors",
"model-00034-of-00086.safetensors",
"model-00035-of-00086.safetensors",
"model-00036-of-00086.safetensors",
"model-00037-of-00086.safetensors",
"model-00038-of-00086.safetensors",
"model-00039-of-00086.safetensors",
"model-00040-of-00086.safetensors",
"model-00041-of-00086.safetensors",
"model-00042-of-00086.safetensors",
"model-00043-of-00086.safetensors",
"model-00044-of-00086.safetensors",
"model-00045-of-00086.safetensors",
"model-00046-of-00086.safetensors",
"model-00047-of-00086.safetensors",
"model-00048-of-00086.safetensors",
"model-00049-of-00086.safetensors",
"model-00050-of-00086.safetensors",
"model-00051-of-00086.safetensors",
"model-00052-of-00086.safetensors",
"model-00053-of-00086.safetensors",
"model-00054-of-00086.safetensors",
"model-00055-of-00086.safetensors",
"model-00056-of-00086.safetensors",
"model-00057-of-00086.safetensors",
"model-00058-of-00086.safetensors",
"model-00059-of-00086.safetensors",
"model-00060-of-00086.safetensors",
"model-00061-of-00086.safetensors",
"model-00062-of-00086.safetensors",
"model-00063-of-00086.safetensors",
"model-00064-of-00086.safetensors",
"model-00065-of-00086.safetensors",
"model-00066-of-00086.safetensors",
"model-00067-of-00086.safetensors",
"model-00068-of-00086.safetensors",
"model-00069-of-00086.safetensors",
"model-00070-of-00086.safetensors",
"model-00071-of-00086.safetensors",
"model-00072-of-00086.safetensors",
"model-00073-of-00086.safetensors",
"model-00074-of-00086.safetensors",
"model-00075-of-00086.safetensors",
"model-00076-of-00086.safetensors",
"model-00077-of-00086.safetensors",
"model-00078-of-00086.safetensors",
"model-00079-of-00086.safetensors",
"model-00080-of-00086.safetensors",
"model-00081-of-00086.safetensors",
"model-00082-of-00086.safetensors",
"model-00083-of-00086.safetensors",
"model-00084-of-00086.safetensors",
"model-00085-of-00086.safetensors",
"model-00086-of-00086.safetensors",
"model.safetensors.index.json",
"recipe.yaml",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
45f7b629c5edb6aef818192bee44727811581429
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"Llama-3.1",
"instruct",
"finetune",
"reasoning",
"hybrid-mode",
"chatml",
"function calling",
"tool use",
"json mode",
"structured outputs",
"atropos",
"dataforge",
"long context",
"roleplaying",
"chat",
"conversational",
"en",
"arxiv:2508.18255",
"base_model:meta-llama/Llama-3.1-405B",
"base_model:quantized:meta-llama/Llama-3.1-405B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] | null |
# Hermes 4 — Llama-3.1 405B - FP8

## Model Description
Hermes 4 405B is a frontier, hybrid-mode **reasoning** model based on Llama-3.1-405B by Nous Research that is aligned to **you**.
Read the Hermes 4 technical report here: <a href="https://arxiv.org/abs/2508.18255">Hermes 4 Technical Report</a>
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
**This is the FP8 version of Hermes 4, please see the <a href="https://huggingface.co/NousResearch/Hermes-4-405B"> BF16 Model </a> if looking for that.**
## What’s new vs Hermes 3
- **Post-training corpus**: Massively increased dataset size from 1M samples and 1.2B tokens to **~5M samples / ~60B tokens** blended across reasoning and non-reasoning data.
- **Hybrid reasoning mode** with explicit `<think>…</think>` segments when the model decides to deliberate, and options to make your responses faster when you want.
- **Reasoning** that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- **Schema adherence & structured outputs**: trained to produce valid JSON for given schemas and to repair malformed objects.
- **Much easier to steer and align**: extreme improvements on steerability, especially on reduced refusal rates.
## Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.

Hermes 4 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and conforming to your values, without censorship.
## Benchmarks (Hermes 4 405B)

> Full tables, settings, and comparisons are in the technical report.
## Prompt Format
Hermes 4 uses Llama-3-Chat format with role headers and special tags.
**Basic chat:**
```
<|start_header_id|>system<|end_header_id|>
You are Hermes 4. Be concise and helpful.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Explain the photoelectric effect simply.<|im_end|>
<|start_header_id|>assistant<|end_header_id|>
```
### Reasoning mode
Reasoning mode can be activated with the chat template via the flag `thinking=True` or by using the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
Note that you can add any additional system instructions before or after this system message, and it will adjust the models policies, style, and effort of thinking, as well as its post-thinking style, format, identity, and more. You may also interleave the tool definition system message with the reasoning one.
When the model chooses to deliberate, it emits:
```
<|start_header_id|>assistant<|end_header_id|>
<think>
…model’s internal reasoning may appear here…
</think>
Final response starts here…<|eot_id|>
```
Additionally, we provide a flag to keep the content inbetween the `<think> ... </think>` that you can play with by setting `keep_cots=True`
## Function Calling & Tool Use
Hermes 4 supports function/tool calls *within* a single assistant turn, interleaved with its reasoning:
**System message (example):**
```
<|im_start|>system
You are a function-calling AI. Tools are provided inside <tools>…</tools>.
When appropriate, call a tool by emitting a <tool_call>{...}</tool_call> object.
After a tool responds (as <tool_response>), continue reasoning inside <think> and produce the final answer.
<tools>
{"type":"function","function":{"name":"get_weather","description":"Get weather by city","parameters":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"]}}}
</tools><|im_end|>
```
Note that you may also simply place tool definitions into the "tools:" field of your messages, and the chat template will parse and create the system prompt for you. This also works with reasoning mode for improved accuracy of tool use.
The model will then generate tool calls within `<tool_call> {tool_call} </tool_call>` tags, for easy parsing. The tool_call tags are also added tokens, so it makes it easy to parse while streaming! There are also automatic tool parsers built-in to VLLM and SGLang for Hermes, just set the tool parser in VLLM to `hermes` and in SGLang to `qwen25`.
## Inference Notes
- **Sampling defaults that work well:** `temperature=0.6, top_p=0.95, top_k=20`.
- **Template:** Use the Llama chat format for Hermes 4 70B and 405B as shown above, or set `add_generation_prompt=True` when using `tokenizer.apply_chat_template(...)`.
### Transformers example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "NousResearch/Hermes-4-Llama-3.1-405B"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role":"system","content":"You are Hermes 4. Be concise."},
{"role":"user","content":"Summarize CRISPR in 3 sentences."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs, max_new_tokens=400, temperature=0.6, top_p=0.95, top_k=20, do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For production serving on multi-GPU nodes, consider tensor parallel inference engines (e.g., SGLang/vLLM backends) with prefix caching.
## Inference Providers:
### Nous Portal:
<a href="https://portal.nousresearch.com"><img width=256 alt="chutes logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/6YytY7N0mjCnBQvWo3qtv.png"></a>
### Chutes:
<a href="https://chutes.ai/app"><img width=256 alt="chutes logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/l14AWPv6cSvaprpwK_IWY.png"></a>
### Nebius:
<a href="https://nebius.com/services/studio-inference-service">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/vhL0oAomFa_awBdt2KF_x.png">
<source media="(prefers-color-scheme: light)" srcset="https://cdn-uploads.huggingface.co/production/uploads/64b21cbb2fc8324fcb1dac03/LjAfeFfAz8ac5rV-iiwj5.png">
<img width=256 alt="nebius.com logo" src="https://cdn-uploads.huggingface.co/production/uploads/64b21cbb2fc8324fcb1dac03/LjAfeFfAz8ac5rV-iiwj5.png">
</picture>
</a>
### Luminal:
<a href="https://luminalai.com/">
<img width=256 alt="luminal logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/FIHsRdjMMP0HUjebiuJyH.png">
</a>
# Quantized / Smaller Variants
Hermes 4 is available as BF16 original weights as well as FP8 variants and GGUF variants by LM Studio.
BF16: https://huggingface.co/NousResearch/Hermes-4-405B
GGUF (Courtesy of LM Studio team!):
https://huggingface.co/lmstudio-community/Hermes-4-405B-GGUF
Hermes 4 is also available in smaller sizes (e.g., 70B and 14B) with similar prompt formats.
See the Hermes 4 collection to explore them all:
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
# How to cite
```bibtex
@misc{teknium2025hermes4technicalreport,
title={Hermes 4 Technical Report},
author={Ryan Teknium and Roger Jin and Jai Suphavadeeprasit and Dakota Mahan and Jeffrey Quesnelle and Joe Li and Chen Guang and Shannon Sands and Karan Malhotra},
year={2025},
eprint={2508.18255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.18255},
}
```
| null |
[
"llama3"
] | null |
[
"en"
] | 405,873,258,496
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"Online"
] | null | null | null | null | null | null | null | null | null |
68ac918aa73de92b4bb98fea
|
OpenGVLab/InternVL3_5-241B-A28B-Instruct
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918aa377a9b3e010cbbd",
"id": "OpenGVLab/InternVL3_5-241B-A28B-Pretrained"
}
],
"relation": "finetune"
}
| 56
| 56
|
False
| 2025-08-25T16:38:34Z
| 2025-08-29T17:57:02Z
|
transformers
| 16
| 16
| null |
image-text-to-text
|
{"parameters": {"BF16": 240699370368}, "total": 240699370368}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"configuration.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"layer-0-ep-0-of-1.safetensors",
"layer-1-ep-0-of-1.safetensors",
"layer-10-ep-0-of-1.safetensors",
"layer-11-ep-0-of-1.safetensors",
"layer-12-ep-0-of-1.safetensors",
"layer-13-ep-0-of-1.safetensors",
"layer-14-ep-0-of-1.safetensors",
"layer-15-ep-0-of-1.safetensors",
"layer-16-ep-0-of-1.safetensors",
"layer-17-ep-0-of-1.safetensors",
"layer-18-ep-0-of-1.safetensors",
"layer-19-ep-0-of-1.safetensors",
"layer-2-ep-0-of-1.safetensors",
"layer-20-ep-0-of-1.safetensors",
"layer-21-ep-0-of-1.safetensors",
"layer-22-ep-0-of-1.safetensors",
"layer-23-ep-0-of-1.safetensors",
"layer-24-ep-0-of-1.safetensors",
"layer-25-ep-0-of-1.safetensors",
"layer-26-ep-0-of-1.safetensors",
"layer-27-ep-0-of-1.safetensors",
"layer-28-ep-0-of-1.safetensors",
"layer-29-ep-0-of-1.safetensors",
"layer-3-ep-0-of-1.safetensors",
"layer-30-ep-0-of-1.safetensors",
"layer-31-ep-0-of-1.safetensors",
"layer-32-ep-0-of-1.safetensors",
"layer-33-ep-0-of-1.safetensors",
"layer-34-ep-0-of-1.safetensors",
"layer-35-ep-0-of-1.safetensors",
"layer-36-ep-0-of-1.safetensors",
"layer-37-ep-0-of-1.safetensors",
"layer-38-ep-0-of-1.safetensors",
"layer-39-ep-0-of-1.safetensors",
"layer-4-ep-0-of-1.safetensors",
"layer-40-ep-0-of-1.safetensors",
"layer-41-ep-0-of-1.safetensors",
"layer-42-ep-0-of-1.safetensors",
"layer-43-ep-0-of-1.safetensors",
"layer-44-ep-0-of-1.safetensors",
"layer-45-ep-0-of-1.safetensors",
"layer-46-ep-0-of-1.safetensors",
"layer-47-ep-0-of-1.safetensors",
"layer-48-ep-0-of-1.safetensors",
"layer-49-ep-0-of-1.safetensors",
"layer-5-ep-0-of-1.safetensors",
"layer-50-ep-0-of-1.safetensors",
"layer-51-ep-0-of-1.safetensors",
"layer-52-ep-0-of-1.safetensors",
"layer-53-ep-0-of-1.safetensors",
"layer-54-ep-0-of-1.safetensors",
"layer-55-ep-0-of-1.safetensors",
"layer-56-ep-0-of-1.safetensors",
"layer-57-ep-0-of-1.safetensors",
"layer-58-ep-0-of-1.safetensors",
"layer-59-ep-0-of-1.safetensors",
"layer-6-ep-0-of-1.safetensors",
"layer-60-ep-0-of-1.safetensors",
"layer-61-ep-0-of-1.safetensors",
"layer-62-ep-0-of-1.safetensors",
"layer-63-ep-0-of-1.safetensors",
"layer-64-ep-0-of-1.safetensors",
"layer-65-ep-0-of-1.safetensors",
"layer-66-ep-0-of-1.safetensors",
"layer-67-ep-0-of-1.safetensors",
"layer-68-ep-0-of-1.safetensors",
"layer-69-ep-0-of-1.safetensors",
"layer-7-ep-0-of-1.safetensors",
"layer-70-ep-0-of-1.safetensors",
"layer-71-ep-0-of-1.safetensors",
"layer-72-ep-0-of-1.safetensors",
"layer-73-ep-0-of-1.safetensors",
"layer-74-ep-0-of-1.safetensors",
"layer-75-ep-0-of-1.safetensors",
"layer-76-ep-0-of-1.safetensors",
"layer-77-ep-0-of-1.safetensors",
"layer-78-ep-0-of-1.safetensors",
"layer-79-ep-0-of-1.safetensors",
"layer-8-ep-0-of-1.safetensors",
"layer-80-ep-0-of-1.safetensors",
"layer-81-ep-0-of-1.safetensors",
"layer-82-ep-0-of-1.safetensors",
"layer-83-ep-0-of-1.safetensors",
"layer-84-ep-0-of-1.safetensors",
"layer-85-ep-0-of-1.safetensors",
"layer-86-ep-0-of-1.safetensors",
"layer-87-ep-0-of-1.safetensors",
"layer-88-ep-0-of-1.safetensors",
"layer-89-ep-0-of-1.safetensors",
"layer-9-ep-0-of-1.safetensors",
"layer-90-ep-0-of-1.safetensors",
"layer-91-ep-0-of-1.safetensors",
"layer-92-ep-0-of-1.safetensors",
"layer-93-ep-0-of-1.safetensors",
"merges.txt",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"others.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vision.safetensors",
"vocab.json"
] | null | null |
15bf7c51887223f4df386dcc8d69206dfc776802
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-241B-A28B-Pretrained",
"base_model:finetune:OpenGVLab/InternVL3_5-241B-A28B-Pretrained",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-241B-A28B-Instruct
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 240,699,370,368
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac97d7b29f468efa115168
|
apple/FastVLM-1.5B
|
apple
| null | 611
| 611
|
False
| 2025-08-25T17:05:27Z
| 2025-08-29T17:22:05Z
|
ml-fastvlm
| 16
| 16
| null |
text-generation
|
{"parameters": {"BF16": 1909278176}, "total": 1909278176}
|
[
".gitattributes",
"LICENSE",
"README.md",
"acc_vs_latency_qwen-2.png",
"added_tokens.json",
"config.json",
"generation_config.json",
"llava_qwen.py",
"merges.txt",
"model.safetensors",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
] | null | null |
bc79ceee8b70fd9e8c767b6337b880de47bc7438
|
[
"ml-fastvlm",
"safetensors",
"llava_qwen2",
"text-generation",
"transformers",
"conversational",
"custom_code",
"arxiv:2412.13303",
"license:apple-amlr",
"region:us"
] | null |
# FastVLM: Efficient Vision Encoding for Vision Language Models
FastVLM was introduced in
**[FastVLM: Efficient Vision Encoding for Vision Language Models](https://www.arxiv.org/abs/2412.13303). (CVPR 2025)**
[//]: # ()
<p align="center">
<img src="acc_vs_latency_qwen-2.png" alt="Accuracy vs latency figure." width="400"/>
</p>
### Highlights
* We introduce FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images.
* Our smallest variant outperforms LLaVA-OneVision-0.5B with 85x faster Time-to-First-Token (TTFT) and 3.4x smaller vision encoder.
* Our larger variants using Qwen2-7B LLM outperform recent works like Cambrian-1-8B while using a single image encoder with a 7.9x faster TTFT.
### Evaluations
| Benchmark | FastVLM-0.5B | FastVLM-1.5B | FastVLM-7B |
|:--------------|:------------:|:------------:|:----------:|
| Ai2D | 68.0 | 77.4 | 83.6 |
| ScienceQA | 85.2 | 94.4 | 96.7 |
| MMMU | 33.9 | 37.8 | 45.4 |
| VQAv2 | 76.3 | 79.1 | 80.8 |
| ChartQA | 76.0 | 80.1 | 85.0 |
| TextVQA | 64.5 | 70.4 | 74.9 |
| InfoVQA | 46.4 | 59.7 | 75.8 |
| DocVQA | 82.5 | 88.3 | 93.2 |
| OCRBench | 63.9 | 70.2 | 73.1 |
| RealWorldQA | 56.1 | 61.2 | 67.2 |
| SeedBench-Img | 71.0 | 74.2 | 75.4 |
### Usage Example
To run inference of PyTorch checkpoint, follow the instruction in the official repo:
Download the model
```
huggingface-cli download apple/FastVLM-1.5B
```
Run inference using `predict.py` from the official repo.
```bash
python predict.py --model-path /path/to/checkpoint-dir \
--image-file /path/to/image.png \
--prompt "Describe the image."
```
### Run inference with Transformers (Remote Code)
To run inference with transformers we can leverage `trust_remote_code` along with the following snippet:
```python
import torch
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
MID = "apple/FastVLM-1.5B"
IMAGE_TOKEN_INDEX = -200 # what the model code looks for
# Load
tok = AutoTokenizer.from_pretrained(MID, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MID,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto",
trust_remote_code=True,
)
# Build chat -> render to string (not tokens) so we can place <image> exactly
messages = [
{"role": "user", "content": "<image>\nDescribe this image in detail."}
]
rendered = tok.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
pre, post = rendered.split("<image>", 1)
# Tokenize the text *around* the image token (no extra specials!)
pre_ids = tok(pre, return_tensors="pt", add_special_tokens=False).input_ids
post_ids = tok(post, return_tensors="pt", add_special_tokens=False).input_ids
# Splice in the IMAGE token id (-200) at the placeholder position
img_tok = torch.tensor([[IMAGE_TOKEN_INDEX]], dtype=pre_ids.dtype)
input_ids = torch.cat([pre_ids, img_tok, post_ids], dim=1).to(model.device)
attention_mask = torch.ones_like(input_ids, device=model.device)
# Preprocess image via the model's own processor
img = Image.open("test-2.jpg").convert("RGB")
px = model.get_vision_tower().image_processor(images=img, return_tensors="pt")["pixel_values"]
px = px.to(model.device, dtype=model.dtype)
# Generate
with torch.no_grad():
out = model.generate(
inputs=input_ids,
attention_mask=attention_mask,
images=px,
max_new_tokens=128,
)
print(tok.decode(out[0], skip_special_tokens=True))
```
## Citation
If you found this model useful, please cite the following paper:
```
@InProceedings{fastvlm2025,
author = {Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, Hadi Pouransari},
title = {FastVLM: Efficient Vision Encoding for Vision Language Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025},
}
```
| null |
[
"apple-amlr",
"apple-ascl",
"https://github.com/apple/ml-fastvlm/blob/main/LICENSE_MODEL"
] | null | null | 1,909,278,176
| null |
[
"text-generation"
] | null |
[
"LlavaQwen2ForCausalLM",
"llava_qwen.LlavaQwen2ForCausalLM",
"llava_qwen2",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
| null |
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68b000291ba8a71c4d54cc3d
|
stepfun-ai/Step-Audio-2-mini-Base
|
stepfun-ai
| null | 21
| 21
|
False
| 2025-08-28T07:07:21Z
| 2025-08-29T10:52:45Z
| null | 16
| 16
| null | null |
{"parameters": {"BF16": 8315179264}, "total": 8315179264}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"assets/architecture5.png",
"assets/arxiv.svg",
"assets/logo.png",
"assets/qrcode.jpg",
"assets/radar.png",
"assets/wechat_group.jpg",
"config.json",
"configuration_step_audio_2.py",
"merges.txt",
"model-00001.safetensors",
"model-00002.safetensors",
"model.safetensors.index.json",
"modeling_step_audio_2.py",
"special_tokens_map.json",
"token2wav/campplus.onnx",
"token2wav/flow.pt",
"token2wav/flow.yaml",
"token2wav/hift.pt",
"token2wav/speech_tokenizer_v2_25hz.onnx",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
19318f7619359ea6571ba0185aa0b9431640e92a
|
[
"onnx",
"safetensors",
"step_audio_2",
"custom_code",
"arxiv:2507.16632",
"license:apache-2.0",
"region:us"
] | null |
<div align="center">
<img src="assets/logo.png" height=100>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/stepfun-ai/Step-Audio2" target="_blank"><img alt="GitHub" src="https://img.shields.io/badge/GitHub-StepFun-white?logo=github&logoColor=white"/></a>  
<a href="https://stepfun.com/" target="_blank"><img alt="Homepage" src="https://img.shields.io/badge/Homepage-StepFun-white?logo=StepFun&logoColor=white"/></a>  
<a href="https://x.com/StepFun_ai" target="_blank"><img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-StepFun-white?logo=x&logoColor=white"/></a>  
<a href="https://discord.com/invite/XHheP5Fn" target="_blank"><img alt="Discord" src="https://img.shields.io/badge/Discord-StepFun-white?logo=discord&logoColor=white"/></a>
</div>
<div align="center">
<a href="https://huggingface.co/stepfun-ai/Step-Audio-2-mini"><img src="https://img.shields.io/static/v1?label=Step-Audio-2-mini&message=HuggingFace&color=yellow"></a>  
<a href="https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base"><img src="https://img.shields.io/static/v1?label=Step-Audio-2-mini-Base&message=HuggingFace&color=yellow"></a>
</div>
<div align="center">
<a href="https://arxiv.org/abs/2507.16632"><img src="assets/arxiv.svg"></a>  
<a href="https://github.com/stepfun-ai/Step-Audio2/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/badge/License-Apache%202.0-blue?&color=blue"/></a>
</div>
## Introduction
Step-Audio 2 is an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation.
- **Advanced Speech and Audio Understanding**: Promising performance in ASR and audio understanding by comprehending and reasoning semantic information, para-linguistic and non-vocal information.
- **Intelligent Speech Conversation**: Achieving natural and intelligent interactions that are contextually appropriate for various conversational scenarios and paralinguistic information.
- **Tool Calling and Multimodal RAG**: By leveraging tool calling and RAG to access real-world knowledge (both textual and acoustic), Step-Audio 2 can generate responses with fewer hallucinations for diverse scenarios, while also having the ability to switch timbres based on retrieved speech.
- **State-of-the-Art Performance**: Achieving state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. (See [Evaluation](#evaluation) and [Technical Report](https://arxiv.org/pdf/2507.16632)).
+ **Open-source**: [Step-Audio 2 mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) and [Step-Audio 2 mini Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) are released under [Apache 2.0](LICENSE) license.
## Model Download
### Huggingface
| Models | 🤗 Hugging Face |
|-------|-------|
| Step-Audio 2 mini | [stepfun-ai/Step-Audio-2-mini](https://huggingface.co/stepfun-ai/Step-Audio-2-mini) |
| Step-Audio 2 mini Base | [stepfun-ai/Step-Audio-2-mini-Base](https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base) |
<!-- ### Modelscope
| Models | Links |
|-------|-------|
| Step-Audio-2-mini | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-2-mini) |
| Step-Audio-2-mini-Base | [modelscope](https://modelscope.cn/models/stepfun-ai/Step-Audio-2-mini-Base) | -->
## Model Usage
### 🔧 Dependencies and Installation
- Python >= 3.10
- [PyTorch >= 2.3-cu121](https://pytorch.org/)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads)
```bash
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa onnxruntime s3tokenizer diffusers hyperpyyaml
git clone https://github.com/stepfun-ai/Step-Audio2.git
cd Step-Audio2
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-2-mini-Base
```
### 🚀 Inference Scripts
```bash
python examples-base.py
```
## Online demonstration
### StepFun realtime console
- Both Step-Audio 2 and Step-Audio 2 mini are available in our [StepFun realtime console](https://realtime-console.stepfun.com/) with web search tool enabled.
- You will need an API key from the [StepFun Open Platform](https://platform.stepfun.com/).
### StepFun AI Assistant
- Step-Audio 2 is also available in our StepFun AI Assistant mobile App with both web and audio search tools enabled.
- Please scan the following QR code to download it from your app store then tap the phone icon in the top-right corner.
<div align="center">
<img src="./assets/qrcode.jpg" width="200" alt="QR code">
</div>
## WeChat group
You can scan the following QR code to join our WeChat group for communication and discussion.
<div align="center">
<img src="./assets/wechat_group.jpg" width="200" alt="QR code">
</div>
## Evaluation
<div align="center">
<img src="assets/radar.png" alt="Architecture" width="600" />
</div>
### Automatic speech recognition
CER for Chinese, Cantonese and Japanese and WER for Arabian and English. N/A indicates that the language is not supported.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Category</th>
<th style="text-align: center;">Test set</th>
<th style="text-align: center;">Doubao LLM ASR</th>
<th style="text-align: center;">GPT-4o Transcribe</th>
<th style="text-align: center;">Kimi-Audio</th>
<th style="text-align: center;">Qwen-Omni</th>
<th style="text-align: center;">Step-Audio 2</th>
<th style="text-align: center;">Step-Audio 2 mini</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="5" style="text-align: center; vertical-align: middle;"><strong>English</strong></td>
<td align="left">Common Voice</td>
<td align="center">9.20</td>
<td align="center">9.30</td>
<td align="center">7.83</td>
<td align="center">8.33</td>
<td align="center"><strong>5.95</strong></td>
<td align="center">6.76</td>
</tr>
<tr>
<td align="left">FLEURS English</td>
<td align="center">7.22</td>
<td align="center"><strong>2.71</strong></td>
<td align="center">4.47</td>
<td align="center">5.05</td>
<td align="center">3.03</td>
<td align="center">3.05</td>
</tr>
<tr>
<td align="left">LibriSpeech clean</td>
<td align="center">2.92</td>
<td align="center">1.75</td>
<td align="center">1.49</td>
<td align="center">2.93</td>
<td align="center"><strong>1.17</strong></td>
<td align="center">1.33</td>
</tr>
<tr>
<td align="left">LibriSpeech other</td>
<td align="center">5.32</td>
<td align="center">4.23</td>
<td align="center">2.91</td>
<td align="center">5.07</td>
<td align="center"><strong>2.42</strong></td>
<td align="center">2.86</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">6.17</td>
<td align="center">4.50</td>
<td align="center">4.18</td>
<td align="center">5.35</td>
<td align="center"><strong>3.14</strong></td>
<td align="center">3.50</td>
</tr>
<tr>
<td rowspan="7" style="text-align: center; vertical-align: middle;"><strong>Chinese</strong></td>
<td align="left">AISHELL</td>
<td align="center">0.98</td>
<td align="center">3.52</td>
<td align="center">0.64</td>
<td align="center">1.17</td>
<td align="center"><strong>0.63</strong></td>
<td align="center">0.78</td>
</tr>
<tr>
<td align="left">AISHELL-2</td>
<td align="center">3.10</td>
<td align="center">4.26</td>
<td align="center">2.67</td>
<td align="center">2.40</td>
<td align="center"><strong>2.10</strong></td>
<td align="center">2.16</td>
</tr>
<tr>
<td align="left">FLEURS Chinese</td>
<td align="center">2.92</td>
<td align="center">2.62</td>
<td align="center">2.91</td>
<td align="center">7.01</td>
<td align="center">2.68</td>
<td align="center"><strong>2.53</strong></td>
</tr>
<tr>
<td align="left">KeSpeech phase1</td>
<td align="center">6.48</td>
<td align="center">26.80</td>
<td align="center">5.11</td>
<td align="center">6.45</td>
<td align="center"><strong>3.63</strong></td>
<td align="center">3.97</td>
</tr>
<tr>
<td align="left">WenetSpeech meeting</td>
<td align="center">4.90</td>
<td align="center">31.40</td>
<td align="center">5.21</td>
<td align="center">6.61</td>
<td align="center"><strong>4.75</strong></td>
<td align="center">4.87</td>
</tr>
<tr>
<td align="left">WenetSpeech net</td>
<td align="center"><strong>4.46</strong></td>
<td align="center">15.71</td>
<td align="center">5.93</td>
<td align="center">5.24</td>
<td align="center">4.67</td>
<td align="center">4.82</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">3.81</td>
<td align="center">14.05</td>
<td align="center">3.75</td>
<td align="center">4.81</td>
<td align="center"><strong>3.08</strong></td>
<td align="center">3.19</td>
</tr>
<tr>
<td rowspan="3" style="text-align: center; vertical-align: middle;"><strong>Multilingual </strong></td>
<td align="left">FLEURS Arabian</td>
<td align="center">N/A</td>
<td align="center"><strong>11.72</strong></td>
<td align="center">N/A</td>
<td align="center">25.13</td>
<td align="center">14.22</td>
<td align="center">16.46</td>
</tr>
<tr>
<td align="left">Common Voice yue</td>
<td align="center">9.20</td>
<td align="center">11.10</td>
<td align="center">38.90</td>
<td align="center"><strong>7.89</strong></td>
<td align="center">7.90</td>
<td align="center">8.32</td>
</tr>
<tr>
<td align="left">FLEURS Japanese</td>
<td align="center">N/A</td>
<td align="center"><strong>3.27</strong></td>
<td align="center">N/A</td>
<td align="center">10.49</td>
<td align="center">3.18</td>
<td align="center">4.67</td>
</tr>
<tr>
<td rowspan="7" style="text-align: center; vertical-align: middle;"><strong>In-house</strong></td>
<td align="left">Anhui accent</td>
<td align="center"><strong>8.83</strong></td>
<td align="center">50.55</td>
<td align="center">22.17</td>
<td align="center">18.73</td>
<td align="center">10.61</td>
<td align="center">11.65</td>
</tr>
<tr>
<td align="left">Guangdong accent</td>
<td align="center">4.99</td>
<td align="center">7.83</td>
<td align="center"><strong>3.76</strong></td>
<td align="center">4.03</td>
<td align="center">3.81</td>
<td align="center">4.44</td>
</tr>
<tr>
<td align="left">Guangxi accent</td>
<td align="center">3.37</td>
<td align="center">7.09</td>
<td align="center">4.29</td>
<td align="center"><strong>3.35</strong></td>
<td align="center">4.11</td>
<td align="center">3.51</td>
</tr>
<tr>
<td align="left">Shanxi accent</td>
<td align="center">20.26</td>
<td align="center">55.03</td>
<td align="center">34.71</td>
<td align="center">25.95</td>
<td align="center"><strong>12.44</strong></td>
<td align="center">15.60</td>
</tr>
<tr>
<td align="left">Sichuan dialect</td>
<td align="center"><strong>3.01</strong></td>
<td align="center">32.85</td>
<td align="center">5.26</td>
<td align="center">5.61</td>
<td align="center">4.35</td>
<td align="center">4.57</td>
</tr>
<tr>
<td align="left">Shanghai dialect</td>
<td align="center">47.49</td>
<td align="center">89.58</td>
<td align="center">82.90</td>
<td align="center">58.74</td>
<td align="center"><strong>17.77</strong></td>
<td align="center">19.30</td>
</tr>
<tr>
<td align="left"><strong>Average</strong></td>
<td align="center">14.66</td>
<td align="center">40.49</td>
<td align="center">25.52</td>
<td align="center">19.40</td>
<td align="center"><strong>8.85</strong></td>
<td align="center">9.85</td>
</tr>
</tbody>
</table>
### Paralinguistic information understanding
StepEval-Audio-Paralinguistic
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" rowspan="2">Avg.</th>
<th style="text-align: center;" rowspan="2">Gender</th>
<th style="text-align: center;" rowspan="2">Age</th>
<th style="text-align: center;" rowspan="2">Timbre</th>
<th style="text-align: center;" rowspan="2">Scenario</th>
<th style="text-align: center;" rowspan="2">Event</th>
<th style="text-align: center;" rowspan="2">Emotion</th>
<th style="text-align: center;" rowspan="2">Pitch</th>
<th style="text-align: center;" rowspan="2">Rhythm</th>
<th style="text-align: center;" rowspan="2">Speed</th>
<th style="text-align: center;" rowspan="2">Style</th>
<th style="text-align: center;" rowspan="2">Vocal</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">43.45</td>
<td align="center">18</td>
<td align="center">42</td>
<td align="center">34</td>
<td align="center">22</td>
<td align="center">14</td>
<td align="center">82</td>
<td align="center">40</td>
<td align="center">60</td>
<td align="center">58</td>
<td align="center">64</td>
<td align="center">44</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">49.64</td>
<td align="center">94</td>
<td align="center">50</td>
<td align="center">10</td>
<td align="center">30</td>
<td align="center">48</td>
<td align="center">66</td>
<td align="center">56</td>
<td align="center">40</td>
<td align="center">44</td>
<td align="center">54</td>
<td align="center">54</td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">44.18</td>
<td align="center">40</td>
<td align="center">50</td>
<td align="center">16</td>
<td align="center">28</td>
<td align="center">42</td>
<td align="center">76</td>
<td align="center">32</td>
<td align="center">54</td>
<td align="center">50</td>
<td align="center">50</td>
<td align="center">48</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">36.91</td>
<td align="center">70</td>
<td align="center">66</td>
<td align="center">18</td>
<td align="center">14</td>
<td align="center">14</td>
<td align="center">40</td>
<td align="center">38</td>
<td align="center">48</td>
<td align="center">54</td>
<td align="center">44</td>
<td align="center">0</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>83.09</strong></td>
<td align="center"><strong>100</strong></td>
<td align="center"><strong>96</strong></td>
<td align="center"><strong>82</strong></td>
<td align="center"><strong>78</strong></td>
<td align="center"><strong>60</strong></td>
<td align="center"><strong>86</strong></td>
<td align="center"><strong>82</strong></td>
<td align="center"><strong>86</strong></td>
<td align="center"><strong>88</strong></td>
<td align="center"><strong>88</strong></td>
<td align="center">68</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">80.00</td>
<td align="center"><strong>100</strong></td>
<td align="center">94</td>
<td align="center">80</td>
<td align="center"><strong>78</strong></td>
<td align="center"><strong>60</strong></td>
<td align="center">82</td>
<td align="center"><strong>82</strong></td>
<td align="center">68</td>
<td align="center">74</td>
<td align="center">86</td>
<td align="center"><strong>76</strong></td>
</tr>
</tbody>
</table>
### Audio understanding and reasoning
MMAU
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Model</th>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">Sound</th>
<th style="text-align: center;">Speech</th>
<th style="text-align: center;">Music</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>Audio Flamingo 3</strong></td>
<td align="center">73.1</td>
<td align="center">76.9</td>
<td align="center">66.1</td>
<td align="center"><strong>73.9</strong></td>
</tr>
<tr>
<td align="left"><strong>Gemini 2.5 Pro</strong></td>
<td align="center">71.6</td>
<td align="center">75.1</td>
<td align="center">71.5</td>
<td align="center">68.3</td>
</tr>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">58.1</td>
<td align="center">58.0</td>
<td align="center">64.6</td>
<td align="center">51.8</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">69.6</td>
<td align="center">79.0</td>
<td align="center">65.5</td>
<td align="center">64.4</td>
</tr>
<tr>
<td align="left"><strong>Omni-R1</strong></td>
<td align="center">77.0</td>
<td align="center">81.7</td>
<td align="center">76.0</td>
<td align="center">73.4</td>
</tr>
<tr>
<td align="left"><strong>Qwen2.5-Omni</strong></td>
<td align="center">71.5</td>
<td align="center">78.1</td>
<td align="center">70.6</td>
<td align="center">65.9</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">49.7</td>
<td align="center">50.5</td>
<td align="center">51.4</td>
<td align="center">47.3</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>78.0</strong></td>
<td align="center"><strong>83.5</strong></td>
<td align="center"><strong>76.9</strong></td>
<td align="center">73.7</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">73.2</td>
<td align="center">76.6</td>
<td align="center">71.5</td>
<td align="center">71.6</td>
</tr>
</tbody>
</table>
### Speech translation
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" colspan="3">CoVoST 2 (S2TT)</th>
</tr>
<tr>
<th>Avg.</th>
<th>English-to-Chinese</th>
<th>Chinese-to-English</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">29.61</td>
<td align="center">40.20</td>
<td align="center">19.01</td>
</tr>
<tr>
<td align="left"><strong>Qwen2.5-Omni</strong></td>
<td align="center">35.40</td>
<td align="center">41.40</td>
<td align="center">29.40</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">28.57</td>
<td align="center">37.71</td>
<td align="center">19.43</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center">39.26</td>
<td align="center">49.01</td>
<td align="center"><strong>29.51</strong></td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center"><strong>39.29</strong></td>
<td align="center"><strong>49.12</strong></td>
<td align="center">29.47</td>
</tr>
</tbody>
</table>
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" colspan="3">CVSS (S2ST)</th>
</tr>
<tr>
<th>Avg.</th>
<th>English-to-Chinese</th>
<th>Chinese-to-English</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td align="center">23.68</td>
<td align="center">20.07</td>
<td align="center"><strong>27.29</strong></td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">15.35</td>
<td align="center">8.04</td>
<td align="center">22.66</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">27.36</td>
<td align="center">30.74</td>
<td align="center">23.98</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>30.87</strong></td>
<td align="center"><strong>34.83</strong></td>
<td align="center">26.92</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">29.08</td>
<td align="center">32.81</td>
<td align="center">25.35</td>
</tr>
</tbody>
</table>
### Tool calling
StepEval-Audio-Toolcall. Date and time tools have no parameter.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;">Model</th>
<th style="text-align: center;">Objective</th>
<th style="text-align: center;">Metric</th>
<th style="text-align: center;">Audio search</th>
<th style="text-align: center;">Date & Time</th>
<th style="text-align: center;">Weather</th>
<th style="text-align: center;">Web search</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align: center; vertical-align: middle;" rowspan="3"><strong>Qwen3-32B</strong><sup>†</sup></td>
<td align="center"><strong>Trigger</strong></td>
<td align="center"><strong>Precision / Recall</strong></td>
<td align="center">67.5 / 98.5</td>
<td align="center">98.4 / 100.0</td>
<td align="center">90.1 / 100.0</td>
<td align="center">86.8 / 98.5</td>
</tr>
<tr>
<td align="center"><strong>Type</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">100.0</td>
<td align="center">98.5</td>
<td align="center">98.5</td>
</tr>
<tr>
<td align="center"><strong>Parameter</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">N/A</td>
<td align="center">100.0</td>
<td align="center">100.0</td>
</tr>
<tr>
<td style="text-align: center; vertical-align: middle;" rowspan="3"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>Trigger</strong></td>
<td align="center"><strong>Precision / Recall</strong></td>
<td align="center">86.8 / 99.5</td>
<td align="center">96.9 / 98.4</td>
<td align="center">92.2 / 100.0</td>
<td align="center">88.4 / 95.5</td>
</tr>
<tr>
<td align="center"><strong>Type</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">100.0</td>
<td align="center">90.5</td>
<td align="center">98.4</td>
</tr>
<tr>
<td align="center"><strong>Parameter</strong></td>
<td align="center"><strong>Accuracy</strong></td>
<td align="center">100.0</td>
<td align="center">N/A</td>
<td align="center">100.0</td>
<td align="center">100.0</td>
</tr>
</tbody>
</table>
### Speech-to-speech conversation
URO-Bench. U. R. O. stands for understanding, reasoning, and oral conversation, respectively.
<table border="1" cellpadding="5" cellspacing="0" align="center">
<thead>
<tr>
<th style="text-align: center;" rowspan="2">Model</th>
<th style="text-align: center;" rowspan="2">Language</th>
<th style="text-align: center;" colspan="4">Basic</th>
<th style="text-align: center;" colspan="4">Pro</th>
</tr>
<tr>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">U.</th>
<th style="text-align: center;">R.</th>
<th style="text-align: center;">O.</th>
<th style="text-align: center;">Avg.</th>
<th style="text-align: center;">U.</th>
<th style="text-align: center;">R.</th>
<th style="text-align: center;">O.</th>
</tr>
</thead>
<tbody>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td rowspan="6" style="text-align: center; vertical-align: middle;"><strong>Chinese</strong></td>
<td align="center">78.59</td>
<td align="center">89.40</td>
<td align="center">65.48</td>
<td align="center">85.24</td>
<td align="center">67.10</td>
<td align="center">70.60</td>
<td align="center">57.22</td>
<td align="center">70.20</td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">73.59</td>
<td align="center">79.34</td>
<td align="center">64.66</td>
<td align="center">79.75</td>
<td align="center">66.07</td>
<td align="center">60.44</td>
<td align="center">59.29</td>
<td align="center"><strong>76.21</strong></td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">68.98</td>
<td align="center">59.66</td>
<td align="center">69.74</td>
<td align="center">77.27</td>
<td align="center">59.11</td>
<td align="center">59.01</td>
<td align="center">59.82</td>
<td align="center">58.74</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">74.71</td>
<td align="center">87.61</td>
<td align="center">59.63</td>
<td align="center">81.93</td>
<td align="center">65.61</td>
<td align="center">74.76</td>
<td align="center">47.29</td>
<td align="center">68.97</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center"><strong>83.32</strong></td>
<td align="center"><strong>91.05</strong></td>
<td align="center"><strong>75.45</strong></td>
<td align="center"><strong>86.08</strong></td>
<td align="center">68.25</td>
<td align="center">74.78</td>
<td align="center"><strong>63.18</strong></td>
<td align="center">65.10</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">77.81</td>
<td align="center">89.19</td>
<td align="center">64.53</td>
<td align="center">84.12</td>
<td align="center"><strong>69.57</strong></td>
<td align="center"><strong>76.84</strong></td>
<td align="center">58.90</td>
<td align="center">69.42</td>
</tr>
<tr>
<td align="left"><strong>GPT-4o Audio</strong></td>
<td rowspan="6" style="text-align: center; vertical-align: middle;"><strong>English</strong></td>
<td align="center"><strong>84.54</strong></td>
<td align="center">90.18</td>
<td align="center">75.90</td>
<td align="center"><strong>90.41</strong></td>
<td align="center"><strong>67.51</strong></td>
<td align="center">60.65</td>
<td align="center">64.36</td>
<td align="center"><strong>78.46</strong></td>
</tr>
<tr>
<td align="left"><strong>Kimi-Audio</strong></td>
<td align="center">60.04</td>
<td align="center">83.36</td>
<td align="center">42.31</td>
<td align="center">60.36</td>
<td align="center">49.79</td>
<td align="center">50.32</td>
<td align="center">40.59</td>
<td align="center">56.04</td>
</tr>
<tr>
<td align="left"><strong>Qwen-Omni</strong></td>
<td align="center">70.58</td>
<td align="center">66.29</td>
<td align="center">69.62</td>
<td align="center">76.16</td>
<td align="center">50.99</td>
<td align="center">44.51</td>
<td align="center">63.88</td>
<td align="center">49.41</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio-AQAA</strong></td>
<td align="center">71.11</td>
<td align="center">90.15</td>
<td align="center">56.12</td>
<td align="center">72.06</td>
<td align="center">52.01</td>
<td align="center">44.25</td>
<td align="center">54.54</td>
<td align="center">59.81</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2</strong></td>
<td align="center">83.90</td>
<td align="center"><strong>92.72</strong></td>
<td align="center"><strong>76.51</strong></td>
<td align="center">84.92</td>
<td align="center">66.07</td>
<td align="center"><strong>64.86</strong></td>
<td align="center"><strong>67.75</strong></td>
<td align="center">66.33</td>
</tr>
<tr>
<td align="left"><strong>Step-Audio 2 mini</strong></td>
<td align="center">74.36</td>
<td align="center">90.07</td>
<td align="center">60.12</td>
<td align="center">77.65</td>
<td align="center">61.25</td>
<td align="center">58.79</td>
<td align="center">61.94</td>
<td align="center">63.80</td>
</tr>
</tbody>
</table>
## License
The model and code in the repository is licensed under [Apache 2.0](LICENSE) License.
## Citation
```
@misc{wu2025stepaudio2technicalreport,
title={Step-Audio 2 Technical Report},
author={Boyong Wu and Chao Yan and Chen Hu and Cheng Yi and Chengli Feng and Fei Tian and Feiyu Shen and Gang Yu and Haoyang Zhang and Jingbei Li and Mingrui Chen and Peng Liu and Wang You and Xiangyu Tony Zhang and Xingyuan Li and Xuerui Yang and Yayue Deng and Yechang Huang and Yuxin Li and Yuxin Zhang and Zhao You and Brian Li and Changyi Wan and Hanpeng Hu and Jiangjie Zhen and Siyu Chen and Song Yuan and Xuelin Zhang and Yimin Jiang and Yu Zhou and Yuxiang Yang and Bingxin Li and Buyun Ma and Changhe Song and Dongqing Pang and Guoqiang Hu and Haiyang Sun and Kang An and Na Wang and Shuli Gao and Wei Ji and Wen Li and Wen Sun and Xuan Wen and Yong Ren and Yuankai Ma and Yufan Lu and Bin Wang and Bo Li and Changxin Miao and Che Liu and Chen Xu and Dapeng Shi and Dingyuan Hu and Donghang Wu and Enle Liu and Guanzhe Huang and Gulin Yan and Han Zhang and Hao Nie and Haonan Jia and Hongyu Zhou and Jianjian Sun and Jiaoren Wu and Jie Wu and Jie Yang and Jin Yang and Junzhe Lin and Kaixiang Li and Lei Yang and Liying Shi and Li Zhou and Longlong Gu and Ming Li and Mingliang Li and Mingxiao Li and Nan Wu and Qi Han and Qinyuan Tan and Shaoliang Pang and Shengjie Fan and Siqi Liu and Tiancheng Cao and Wanying Lu and Wenqing He and Wuxun Xie and Xu Zhao and Xueqi Li and Yanbo Yu and Yang Yang and Yi Liu and Yifan Lu and Yilei Wang and Yuanhao Ding and Yuanwei Liang and Yuanwei Lu and Yuchu Luo and Yuhe Yin and Yumeng Zhan and Yuxiang Zhang and Zidong Yang and Zixin Zhang and Binxing Jiao and Daxin Jiang and Heung-Yeung Shum and Jiansheng Chen and Jing Li and Xiangyu Zhang and Yibo Zhu},
year={2025},
eprint={2507.16632},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.16632},
}
```
| null |
[
"apache-2.0"
] | null | null | 8,315,179,264
| null | null | null |
[
"step_audio_2",
"StepAudio2ForCausalLM"
] | null | null | null |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
66d19580e2632490a6bc5829
|
stable-diffusion-v1-5/stable-diffusion-v1-5
|
stable-diffusion-v1-5
| null | 2,583,334
| 52,861,246
|
False
| 2024-08-30T09:48:48Z
| 2024-09-07T16:20:30Z
|
diffusers
| 773
| 15
| null |
text-to-image
| null |
[
".gitattributes",
"README.md",
"feature_extractor/preprocessor_config.json",
"model_index.json",
"safety_checker/config.json",
"safety_checker/model.fp16.safetensors",
"safety_checker/model.safetensors",
"safety_checker/pytorch_model.bin",
"safety_checker/pytorch_model.fp16.bin",
"scheduler/scheduler_config.json",
"text_encoder/config.json",
"text_encoder/model.fp16.safetensors",
"text_encoder/model.safetensors",
"text_encoder/pytorch_model.bin",
"text_encoder/pytorch_model.fp16.bin",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"unet/config.json",
"unet/diffusion_pytorch_model.bin",
"unet/diffusion_pytorch_model.fp16.bin",
"unet/diffusion_pytorch_model.fp16.safetensors",
"unet/diffusion_pytorch_model.non_ema.bin",
"unet/diffusion_pytorch_model.non_ema.safetensors",
"unet/diffusion_pytorch_model.safetensors",
"v1-5-pruned-emaonly.ckpt",
"v1-5-pruned-emaonly.safetensors",
"v1-5-pruned.ckpt",
"v1-5-pruned.safetensors",
"v1-inference.yaml",
"vae/config.json",
"vae/diffusion_pytorch_model.bin",
"vae/diffusion_pytorch_model.fp16.bin",
"vae/diffusion_pytorch_model.fp16.safetensors",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1548,
14461,
342,
541,
4723,
608018440,
1215981830,
1216061799,
608103564,
308,
617,
246144864,
492265874,
492305335,
246187076,
524619,
472,
806,
1059962,
743,
3438354725,
1719327893,
1719125304,
3438366373,
3438167536,
3438167540,
4265380512,
4265146304,
7703807346,
7703324286,
1873,
547,
334707217,
167405651,
167335342,
334643276
] | 47,259,939,649
|
451f4fe16113bff5a5d2269ed5ad43b0592e9a14
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null |
# Stable Diffusion v1-5 Model Card
### ⚠️ This repository is a mirror of the now deprecated `ruwnayml/stable-diffusion-v1-5`, this repository or organization are not affiliated in any way with RunwayML.
Modifications to the original model card are in <span style="color:crimson">red</span> or <span style="color:darkgreen">green</span>
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion) (<span style="color:crimson">now deprecated</span>), <span style="color:darkgreen">ComfyUI, Automatic1111, SD.Next, InvokeAI</span>.
### Use with Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "sd-legacy/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Use with GitHub Repository <span style="color:crimson">(now deprecated)</span>, <span style="color:darkgreen">ComfyUI or Automatic1111</span>
1. Download the weights
- [v1-5-pruned-emaonly.safetensors](https://huggingface.co/sd-legacy/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors) - ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.safetensors](https://huggingface.co/sd-legacy/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors) - ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion). <span style="color:crimson">(now deprecated)</span>
3. <span style="color:darkgreen">Use locally with <a href="https://github.com/comfyanonymous/ComfyUI">ComfyUI</a>, <a href="https://github.com/AUTOMATIC1111/stable-diffusion-webui">AUTOMATIC1111</a>, <a href="https://github.com/vladmandic/automatic">SD.Next</a>, <a href="https://github.com/invoke-ai/InvokeAI">InvokeAI</a></span>
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/sd-legacy/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/sd-legacy/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
[
"hysts/ControlNet-v1-1",
"broyang/interior-ai-designer",
"fffiloni/DiffuEraser-demo",
"hysts-duplicates/Unique3D",
"VIDraft/Unique3D",
"multimodalart/stable-diffusion-inpainting",
"hysts/multiresolution-textual-inversion",
"JingyeChen22/TextDiffuser",
"Silence1412/Stable_Diffusion_Cpu",
"omni-devel/sdInpaint",
"NeurixYUFI/imggen",
"JingyeChen22/TextDiffuser-2",
"JingyeChen22/TextDiffuser-2-Text-Inpainting",
"JVice/try-before-you-bias",
"FoivosPar/Arc2Face",
"lichih/ssd",
"smartfeed/image2image",
"bego68/test",
"Prgckwb/tokenvisor-sd",
"Omegamax/stable-diffusion-v1-5-stable-diffusion-v1-5",
"xtreemtm/sd15",
"adi72/anything",
"KsayFU/stable-diffusion-v1-5-stable-diffusion-v1-5",
"LouisFH/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Supra-San/Text-To-Image",
"jganbarov/stable-diffusion-v1-5-stable-diffusion-v1-5",
"jganbarov/UpTrendy",
"MartsoBodziu1994/stable-diffusion-v1-5-stable-diffusion-v1-5",
"gaur3009/sd3-ControlNet",
"NuriaSan/Espacio_prueba",
"antomtnez/MyNewSpace",
"aitor-medrano/prueba_clase_1610",
"Imad03/Prueba_Gradio",
"Javitron4257/Prueba-Gradio",
"kinniiris/Eam_style",
"Dunirov/stable-diffusion-v1-5-stable-diffusion-v1-5",
"chenpotatos/stable-diffusion-v1-5-stable-diffusion-v1-5",
"qyoo/AID-v2",
"irpannawawi/image-gen",
"HexYang/stable-diffusion-v1-5-stable-diffusion-v1-5",
"bkeys/stable-diffusion-v1-5-stable-diffusion-v1-5",
"antcassan4/IABD",
"dgoot/image-to-image-civitai",
"Nefelibata349/stable-diffusion-v1-5-stable-diffusion-v1-5",
"AbhinavKrishnan36/PRODIGY_GA_02",
"Quiho/stable-diffusion-v1-5-stable-diffusion-v1-5",
"gaur3009/shiva108",
"ItzRoBeerT/pigeon-avatar",
"jlau0228/firstaiapp",
"Baraaqasem/stable-diffusion-v1-5-stable-diffusion-v1-5",
"anasmkh/stable_diffusion_model",
"spiralrewind/pictodos",
"SvetlanaLa/StableDiffusion",
"ita03mouadili/MST-RSI-Ai-Tools",
"dgoot/inpainting",
"yufiru/ImageGeneratotModels",
"lineee/stable-diffusion-v1-5-stable-diffusion-v1-5",
"mckeeboards/ControlNet-v1-1",
"waloneai/ControlNet-v1-1",
"itscyrusdawg/stable-diffusion-v1-5-stable-diffusion-v1-5",
"jchwenger/ControlNet-v1-1",
"JHk27/stable-diffusion-v1-5-stable-diffusion-v1-5",
"TOKTOK55/stable-diffusion-v1-5-stable-diffusion-v1-5",
"serg1us/stable-diffusion-v1-5-stable-diffusion-v1-5",
"savan2001/stable-diffusion-v1-5-stable-diffusion-v1-5",
"DJakie/stable-diffusion-v1-5-stable-diffusion-v1-5",
"rohith2812/AtoI-App",
"Krados56/stable-diffusion-v1-5-stable-diffusion-v1-5",
"terrapretapermaculture/ControlNet-v1-1-D",
"sedefiizm/perla",
"TencentARC/ColorFlow",
"supratimrana/stable-diffusion-v1-5-stable-diffusion-v1-5",
"hanch/imagegenevaluator",
"obvious-research/OnlyFlow",
"hongkha336/stable-diffusion-v1-5-stable-diffusion-v1-5_CPU",
"vikasdeep/stable-diffusion_image_generator",
"yiayi/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Yoki18S/stable-diffusion-v1-5-stable-diffusion-v1-5",
"svjack/ColorFlow",
"redcore75/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Huraim/stable-diffusion-v1-5-stable-diffusion-v1-5",
"sidOP21/stable-diffusion-v1-5-stable-diffusion-v1-5",
"hatakex/stable-diffusion-v1-5-stable-diffusion-v1-5",
"bujowi/text2image",
"AndresTaker/stable-diffusion-v1-5-stable-diffusion-v1-5",
"crazyhite001/imggen",
"sihamemd/textImage",
"sialnoman318/stable-diffusion-v1-5-stable-diffusion-v1-5",
"sigvehaug/cas-aicp-test",
"PST75/ainuverse",
"ravidawade/image-llm",
"gknnglc/stable-diffusion-v1-5-stable-diffusion-v1-5",
"optimine/stable-diffusion-v1-5-stable-diffusion-v1-5",
"simo025/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Lifeinhockey/Diffusion_Models",
"SemaSci/DiffModels",
"willsh1997/neutral-sd-dev",
"fffiloni/MangaNinja-demo",
"gbalaji75/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Sal-ONE/Stable-Diffusion",
"dezzman/diffusion_models",
"ktrndy/diffusion-image-gen",
"tomspatula/stable-diffusion-v1-5-stable-diffusion-v1-5",
"mediaguild/stable-diffusion-v1-5-stable-diffusion-v1-5",
"um235/diffusion",
"szanto/stable-diffusion-v1-5-stable-diffusion-v1-5",
"greedfcghvjbknlk/stable-diffusion-v1-5-stable-diffusion-v1-5",
"svjack/DiffuEraser-demo",
"Masterdqqq/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Masterdqqq/stable-dif-image",
"m4r4k0s23/DiffModels",
"gstranger/diffusion_models",
"hoonkig/stable-diffusion-v1-5-stable-diffusion-v1-5",
"baiapps/hestior",
"cavargas10/Unico3D-Imagen3D",
"kimhyunwoo/ttti",
"ImamMMDE/stable-diffusion-v1-5-stable-diffusion-v1-5",
"nastybastrd/stable-diffusion-v1-5-stable-diffusion-v1-5",
"mariarivaille/Diffusion_Models_Course_Space",
"wolf1997/Image_story_generator",
"dr3mro/stable-diffusion-v1-5-stable-diffusion-v1-5",
"gaur3009/3D-LLAMA",
"Contrip92/stable-diffusion-v1-5-stable-diffusion-v1-5",
"rainbow8182/stable-diffusion-v1-5-stable-diffusion-v1-5",
"svjack/MotionClone-Text-to-Video",
"svjack/MotionClone-Image-to-Video",
"KToko/asdfmovie-lora",
"pva22/course_diffusion_final_project",
"jmalcubilla/test",
"MrRokot/stable-diffusion-v1-5-stable-diffusion-v1-5",
"Rkemmi/stable-diffusion-v1-5-stable-diffusion-v1-5",
"ccchenzc/AttentionDistillation",
"DileepEravada/stable-diffusion-v1-5-stable-diffusion-v1-5",
"sudheer1360/stable-diffusion-v1-5-stable-diffusion-v1-5",
"btwitssayan/stable-diffusion-v1-5-stable-diffusion-v1-5",
"nalin0503/Metamorph",
"qyoo/Conceptrol",
"John6666/torch_compile_bug",
"cocktailpeanut/DiffuEraser-demo",
"Emilichcka/diffusion_fin_project",
"lhilhix/stable-diffusion-v1-5-stable-diffusion-v1-5",
"nord-west-01/Diffusion_Net",
"Yw22/BlobCtrl",
"Quanli1/ddpm",
"hawkiee/stable-diffusion-v1-5-stable-diffusion-v1-5",
"torinriley/Diffusion",
"Akshitkt001/AI",
"iabd00/pruena_primer_modelo",
"WindowsXPGuy/stable-diffusion-v1-5-stable-diffusion-v1-5",
"siijiawei/gorgeous",
"iolie/stable-diffusion-v1-5-stable-diffusion-v1-5",
"iolie/stable-diffusion-v1-5",
"iolie/stable-diffusio",
"Baltej/Image_gen",
"Leofreddare/DreamCartoonLoraV2",
"Leofreddare/CartoonFaceLora",
"alexanz/Pusheen_sampling_with_controlnet",
"profesorJorgeBaron/generadorImagenesSimiliares",
"sand74/changpu",
"theSure/Omnieraser",
"alexeyGod/Test_new_mod",
"alexanz/Pusheen_sampling_with_rmbg",
"yimingyang/study-space",
"quanrecolor/stable-diffusion-v1-5-stable-diffusion-v1-5",
"ilooro/sdqr",
"Docty/img-creator",
"springermedia/stable-diffusion-v1-5-stable-diffusion-v1-5",
"S-Dreamer/stable-diffusion-v1-5-stable-diffusion-v1-5",
"jamestheramenbowl/stable-diffusion-v1-5-stable-diffusion-v1-5",
"chandujoshi386/stable-diffusion-v1-5-stable-diffusion-v1-5hcvv",
"duineeya/pokedex-generator",
"nadav-ed-26/sdv1.5",
"ab795/pi-ml-ai-api-space",
"alexeyGod/sdxl_turbo2",
"dolbohren/smhok_stickers",
"K00B404/ipadapter_testing",
"FelicianoRN/Mispacework",
"nuonuoko/sd",
"ovedrive/imagencpu",
"Scaryplasmon96/DoodlePix",
"LeoNguyen101120/ai-assistance",
"oleksandr-zakharchuk-dev/stable-diffusion-v1-5",
"KYara612/Myspace",
"pradeep4321/demo-gradio",
"borsojj/Stable-Diffusion",
"kartikvij/ControlNet-v1-1",
"jingyangcarl/matgen",
"Oysiyl/AI-QR-code-generator",
"Jesse34357/image-to-image-civitai",
"Agents-MCP-Hackathon/AI-QR-code-generator",
"Madmaxxxx/ControlNet-v1-1",
"emadAAA/Text-to_Image_with_Stable_Diffusion",
"mohamedsobhi777/FramerComfy_test1234_8625676800",
"guohp123456/guo2",
"multimodalart/Cosmos-Predict2-2B",
"joelorellana/DEMO_IMG_Generator",
"ivxivx/HF-story-generator",
"Yatheshr/stable-diffusion-text-to-image",
"Ianisq1/Arc2Face",
"Ianisq1/Arc2Face_New",
"Ianisq1/Arc2Face_Q",
"chrisjcc/image_generation",
"chrisjcc/generate_game",
"goryhon/DiffuEraser-demo",
"eftal/Cosmos-Predict2-2BASD",
"MrPio/TextureAnything",
"QUT-GenAILab/neutral-sd",
"SyntheticIAI/headshottraining",
"SmilingTree/image-gen",
"Garvit1345/INMO",
"RafaelAI200/furry-image-generator",
"Nitin1034/ImageGenerator",
"r3gm/stablediffusion-infinity",
"jingyangcarl/docker_test20",
"jingyangcarl/docker_test21",
"Ianisq1/Arc2jai",
"jingyangcarl/docker_test27",
"jingyangcarl/docker_test28",
"jingyangcarl/docker_test29",
"jingyangcarl/docker_test30",
"jingyangcarl/docker_test31",
"jingyangcarl/docker_test32",
"jingyangcarl/docker_test33",
"jingyangcarl/docker_test34",
"jingyangcarl/docker_test35",
"jingyangcarl/docker_test36",
"jingyangcarl/docker_test37",
"RucoH/img2img-generator",
"BogdanBigBoss/sd",
"chengzhigang/Unique3D-20250830",
"chengzhigang/Unique3D20250831",
"chengzhigang/Unique3D03"
] |
[
"creativeml-openrail-m"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null |
CompVis/stable-diffusion-v1-2
|
[
"Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 6
|
67c9c10d54d811c24a021731
|
sesame/csm-1b
|
sesame
| null | 30,535
| 271,546
|
auto
| 2025-03-06T15:36:45Z
| 2025-07-23T14:04:45Z
|
transformers
| 2,193
| 15
| null |
text-to-speech
| null |
[
".gitattributes",
"README.md",
"chat_template.jinja",
"ckpt.pt",
"config.json",
"generation_config.json",
"model.safetensors",
"preprocessor_config.json",
"prompts/conversational_a.wav",
"prompts/conversational_b.wav",
"prompts/read_speech_a.wav",
"prompts/read_speech_b.wav",
"prompts/read_speech_c.wav",
"prompts/read_speech_d.wav",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"transformers-00001-of-00002.safetensors",
"transformers-00002-of-00002.safetensors",
"transformers.safetensors.index.json"
] |
[
1948,
12128,
2002,
6219618714,
3280,
264,
6211186784,
271,
2646044,
2646044,
831412,
576052,
385964,
435884,
449,
17209980,
50563,
4944026784,
2189474180,
59730
] | 19,589,168,477
|
7a545da5caab051c5f5e6d9be161a5197e756a02
|
[
"transformers",
"safetensors",
"csm",
"text-to-audio",
"text-to-speech",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | null |
[
"TTS-AGI/TTS-Arena-V2",
"Inferless/Open-Source-TTS-Gallary",
"Pendrokar/TTS-Spaces-Arena",
"sesame/csm-1b",
"TTS-AGI/Voice-Clone-Arena",
"aiqtech/Open-Source-TTS-Gallary",
"JournalistsonHF/ai-toolkit",
"Bradarr/csm-1b",
"tzmartin/csm-1b",
"wehead/csm-1b-tts-demo",
"elpizospes/csm-1b",
"AsafOnHugging/ai-podcast-csm",
"lin186/csm-1b",
"drewThomasson/csm-1b",
"alethanhson/csm-1b",
"alethanhson/csm-1b-gradio",
"alethanhson/csm-1b-gradio-v2",
"preston-cell/image-text-to-text",
"UltimateJones/csm-1b",
"BlueQbit/Voice",
"dasd12d/sesame-csm-1b",
"incomedic/sesame-csm-1b",
"rafaelbatistam/sesame-csm-1b",
"keylong/sesame-csm-1b",
"molattam/sesame-csm-1b",
"djheadshine/sesame-csm-1b",
"karagmercola/csm-model-demo",
"maydayjeffk/sesame-csm-1b",
"allan-vega/sesame-csm-1b",
"0xnitish9999/csm-1b-gradio-v2",
"paulrothedesign/sesame-csm-1b",
"karagmercola/Sesame-AI-POC",
"wjmediadesign/sesame-csm-1b",
"shanrock/sesame-csm-1b",
"griffinitto/sesame-csm-1b",
"cnwoke24/first",
"pets123/sesame",
"pets123/sesameg",
"MacroSam/sesame-csm-1b",
"Xatagarasu/sesame-csm-1b",
"uergashev/sesame-csm-1b",
"uglybirds/sesame-csm-1b",
"StablePeru/sesame-csm-1b",
"Darth-Hidious/sesame-csm-1b",
"Amozsam/sesame-csm-1b",
"jameszokah/jamiya",
"moreexs/sesame-csm-1b",
"pets123/sesame_openai",
"Mia01192002/sesame",
"Mia01192002/sesame-csm",
"aawkldm/sesame-csm-1b",
"borngain/sesame-csm-1b",
"jt5d/sesame-csm-1b",
"JanAazar/sesame-csm-1b",
"dannydunlap/sesame-csm-1b",
"pittisunilkumar/sesame-csm-1bb",
"genrevo1/sesame-csm-1b",
"A-Jy/sesame-csm-1b",
"Kaankilic/text-to-speech-csm",
"Kaankilic/text-to-speechh-csm",
"Kaankilic/tts-api",
"puffyb/sesame-csm-1b",
"ajpieroni/sesame-csm-1b",
"Shiv1511/sesame-csm-1b",
"jigyasaagarwal/csm-1b",
"Paul9856147/csm-1b",
"evalstate/csm-1b",
"deepLEARNING786/csm-1b",
"WeaveEntertainment/sesame-tts",
"Justinp11004/sesame_api",
"kemuriririn/Voice-Clone-Router",
"AliFarazKhan/sesame-csm-1b",
"Kiney4/sesame-csm-1b",
"Volodstaimi/sesame-csm-1b",
"PachecoT/sesame-csm-1b",
"ihddeer/sesame-csm-1b"
] |
[
"apache-2.0"
] | null |
[
"en"
] | null | null |
[
"text-to-audio",
"text-to-speech"
] | null |
[
"CsmForConditionalGeneration",
"csm",
"AutoModelForTextToWaveform"
] |
[
"audio",
"text"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
684c4d5a7fa15e011e81d56e
|
tencent/Hunyuan3D-2.1
|
tencent
| null | 70,494
| 176,054
|
False
| 2025-06-13T16:10:02Z
| 2025-08-18T14:01:08Z
|
hunyuan3d-2
| 649
| 15
| null |
image-to-3d
| null |
[
".gitattributes",
"LICENSE",
"Notice.txt",
"README.md",
"demo.py",
"hunyuan3d-dit-v2-1/config.yaml",
"hunyuan3d-dit-v2-1/model.fp16.ckpt",
"hunyuan3d-paintpbr-v2-1/README.md",
"hunyuan3d-paintpbr-v2-1/feature_extractor/preprocessor_config.json",
"hunyuan3d-paintpbr-v2-1/image_encoder/config.json",
"hunyuan3d-paintpbr-v2-1/image_encoder/model.safetensors",
"hunyuan3d-paintpbr-v2-1/model_index.json",
"hunyuan3d-paintpbr-v2-1/scheduler/scheduler_config.json",
"hunyuan3d-paintpbr-v2-1/text_encoder/config.json",
"hunyuan3d-paintpbr-v2-1/text_encoder/pytorch_model.bin",
"hunyuan3d-paintpbr-v2-1/tokenizer/merges.txt",
"hunyuan3d-paintpbr-v2-1/tokenizer/special_tokens_map.json",
"hunyuan3d-paintpbr-v2-1/tokenizer/tokenizer_config.json",
"hunyuan3d-paintpbr-v2-1/tokenizer/vocab.json",
"hunyuan3d-paintpbr-v2-1/unet/attn_processor.py",
"hunyuan3d-paintpbr-v2-1/unet/config.json",
"hunyuan3d-paintpbr-v2-1/unet/diffusion_pytorch_model.bin",
"hunyuan3d-paintpbr-v2-1/unet/model.py",
"hunyuan3d-paintpbr-v2-1/unet/modules.py",
"hunyuan3d-paintpbr-v2-1/vae/config.json",
"hunyuan3d-paintpbr-v2-1/vae/diffusion_pytorch_model.bin",
"hunyuan3d-vae-v2-1/config.yaml",
"hunyuan3d-vae-v2-1/model.fp16.ckpt",
"hy3dpaint/textureGenPipeline.py",
"hy3dpaint/utils/multiview_utils.py"
] |
[
1519,
17079,
16644,
3998,
1490,
2078,
7366389768,
1801,
342,
554,
1264217240,
617,
387,
613,
1361671895,
524619,
460,
807,
1059962,
35104,
911,
3925293863,
25514,
45181,
553,
334707217,
409,
655648152,
8126,
5536
] | 14,909,682,439
|
fa3d0bdabcd0a05d866b97962e2b8098061cac88
|
[
"hunyuan3d-2",
"diffusers",
"safetensors",
"image-to-3d",
"text-to-3d",
"en",
"zh",
"arxiv:2506.15442",
"arxiv:2501.12202",
"arxiv:2411.02293",
"license:other",
"region:us"
] | null |
<p align="center">
<img src="https://raw.githubusercontent.com/Tencent-Hunyuan/Hunyuan3D-2.1/refs/heads/main/assets/images/teaser.jpg">
</p>
<div align="center">
<a href=https://3d.hunyuan.tencent.com target="_blank"><img src=https://img.shields.io/badge/Hunyuan3D-black.svg?logo=homepage height=22px></a>
<a href=https://huggingface.co/spaces/tencent/Hunyuan3D-2.1 target="_blank"><img src=https://img.shields.io/badge/%F0%9F%A4%97%20Demo-276cb4.svg height=22px></a>
<a href=https://huggingface.co/tencent/Hunyuan3D-2.1 target="_blank"><img src=https://img.shields.io/badge/%F0%9F%A4%97%20Models-d96902.svg height=22px></a>
<a href=https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1 target="_blank"><img src= https://img.shields.io/badge/Page-bb8a2e.svg?logo=github height=22px></a>
<a href=https://discord.gg/GuaWYwzKbX target="_blank"><img src= https://img.shields.io/badge/Discord-white.svg?logo=discord height=22px></a>
<a href=https://arxiv.org/abs/2506.15442 target="_blank"><img src=https://img.shields.io/badge/Report-b5212f.svg?logo=arxiv height=22px></a>
</div>
## 🔗 BibTeX
If you found this repository helpful, please cite our report:
```bibtex
@misc{hunyuan3d2025hunyuan3d,
title={Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material},
author={Team Hunyuan3D and Shuhui Yang and Mingxin Yang and Yifei Feng and Xin Huang and Sheng Zhang and Zebin He and Di Luo and Haolin Liu and Yunfei Zhao and Qingxiang Lin and Zeqiang Lai and Xianghui Yang and Huiwen Shi and Zibo Zhao and Bowen Zhang and Hongyu Yan and Lifu Wang and Sicong Liu and Jihong Zhang and Meng Chen and Liang Dong and Yiwen Jia and Yulin Cai and Jiaao Yu and Yixuan Tang and Dongyuan Guo and Junlin Yu and Hao Zhang and Zheng Ye and Peng He and Runzhou Wu and Shida Wei and Chao Zhang and Yonghao Tan and Yifu Sun and Lin Niu and Shirui Huang and Bojian Zheng and Shu Liu and Shilin Chen and Xiang Yuan and Xiaofeng Yang and Kai Liu and Jianchen Zhu and Peng Chen and Tian Liu and Di Wang and Yuhong Liu and Linus and Jie Jiang and Jingwei Huang and Chunchao Guo},
year={2025},
eprint={2506.15442},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{hunyuan3d22025tencent,
title={Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation},
author={Tencent Hunyuan3D Team},
year={2025},
eprint={2501.12202},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{yang2024tencent,
title={Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation},
author={Tencent Hunyuan3D Team},
year={2024},
eprint={2411.02293},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Acknowledgements
We would like to thank the contributors to
the [TripoSG](https://github.com/VAST-AI-Research/TripoSG), [DINOv2](https://github.com/facebookresearch/dinov2), [Stable Diffusion](https://github.com/Stability-AI/stablediffusion), [FLUX](https://github.com/black-forest-labs/flux), [diffusers](https://github.com/huggingface/diffusers)
and [HuggingFace](https://huggingface.co) repositories, for their open research and exploration.
## Star History
<a href="https://star-history.com/#Tencent-Hunyuan/Hunyuan3D-2.1&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=Tencent-Hunyuan/Hunyuan3D-2.1&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=Tencent-Hunyuan/Hunyuan3D-2.1&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=Tencent-Hunyuan/Hunyuan3D-2.1&type=Date" />
</picture>
</a>
|
[
"tencent/Hunyuan3D-2.1",
"Bton/Hunyuan3D-2.1",
"Jbowyer/Hunyuan3D-2.1",
"cpuai/Hunyuan3D-2.1",
"KINGHAJI/Hunyuan3D-2.1",
"KINGHAJI/mat",
"BladeSzaSza/digiPal",
"Volturus/Hunyuan3D-2_1",
"victor/Hunyuan3D-2.1",
"dylanebert/Hunyuan3D-2.1",
"MikeEhrmantraut69/Hunyuan3D-2.1",
"fawwazmohd/Hunyuan3D-2.1",
"FlavioRamso/Hunuvyvuyv",
"Gemini899/Hunyuan3D-2.1",
"imagine-io/image-to-3d",
"imagine-io/image-to-3d-generation",
"imagine-io-webinar/image-to-3d",
"Gouri764/Gouri3D-2.1",
"asimfayaz/Hunyuan3D-2.1",
"ginigen/Hunyuan3D-2.1",
"aptol/genshin",
"kcoda36/Hunyuan3D-2.1",
"Monikashyapa/VTO",
"Monikashyapa/3DVTO",
"aerovfx/Hunyuan3D-2.1"
] |
[
"other",
"tencent-hunyuan-community",
"https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1/blob/main/LICENSE"
] | null |
[
"en",
"zh"
] | null | null |
[
"text-to-3d",
"image-to-3d"
] | null | null |
[
"vision"
] |
[
"text",
"image"
] |
[
"3d-model"
] |
free
| null |
[
"China"
] | null | null | null | null | null | null | null | null | null |
6891702273b6dc7c1ad8de72
|
Comfy-Org/Qwen-Image_ComfyUI
|
Comfy-Org
| null | 1,356,874
| 1,356,874
|
False
| 2025-08-05T02:44:50Z
| 2025-08-06T06:18:04Z
|
diffusion-single-file
| 178
| 15
| null | null | null |
[
".gitattributes",
"README.md",
"non_official/diffusion_models/README.md",
"non_official/diffusion_models/qwen_image_distill_full_bf16.safetensors",
"non_official/diffusion_models/qwen_image_distill_full_fp8_e4m3fn.safetensors",
"split_files/diffusion_models/qwen_image_bf16.safetensors",
"split_files/diffusion_models/qwen_image_fp8_e4m3fn.safetensors",
"split_files/text_encoders/qwen_2.5_vl_7b.safetensors",
"split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors",
"split_files/vae/qwen_image_vae.safetensors"
] |
[
1519,
135,
103,
40861031488,
20430635136,
40861031488,
20430635136,
16584415576,
9384670680,
253806246
] | 148,806,227,507
|
b8f0a47470ec2a0724d6267ca696235e441baa5d
|
[
"diffusion-single-file",
"comfyui",
"license:apache-2.0",
"region:us"
] | null |
See: https://comfyanonymous.github.io/ComfyUI_examples/qwen_image/
| null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689374f41dc3bcaaf05e4963
|
huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated
|
huihui-ai
|
{
"models": [
{
"_id": "68924312dd81882f9eb83b66",
"id": "unsloth/gpt-oss-20b-BF16"
}
],
"relation": "quantized"
}
| 55,246
| 55,246
|
False
| 2025-08-06T15:29:56Z
| 2025-08-08T06:13:01Z
|
transformers
| 145
| 15
| null |
text-generation
|
{"parameters": {"BF16": 20914757184}, "total": 20914757184}
|
[
".gitattributes",
"GGUF/ggml-model-Q3_K_M.gguf",
"GGUF/ggml-model-Q4_K_M.gguf",
"GGUF/ggml-model-f16.gguf",
"GGUF/ggml-model-q8_0.gguf",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00009.safetensors",
"model-00002-of-00009.safetensors",
"model-00003-of-00009.safetensors",
"model-00004-of-00009.safetensors",
"model-00005-of-00009.safetensors",
"model-00006-of-00009.safetensors",
"model-00007-of-00009.safetensors",
"model-00008-of-00009.safetensors",
"model-00009-of-00009.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1821,
12916149600,
15805135200,
41860886880,
22261910880,
9091,
15392,
1691,
175,
4504304664,
4939127656,
4939127656,
4939127680,
4939127704,
4939127704,
4939127704,
4939127704,
2751362856,
34054,
463,
27868174,
4383
] | 134,701,579,132
|
6eaf572858c17b10108a3c34afda509f413df0d3
|
[
"transformers",
"safetensors",
"gguf",
"gpt_oss",
"text-generation",
"vllm",
"unsloth",
"abliterated",
"uncensored",
"conversational",
"base_model:unsloth/gpt-oss-20b-BF16",
"base_model:quantized:unsloth/gpt-oss-20b-BF16",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
{"total": 20914757184, "architecture": "gpt-oss", "context_length": 131072, "chat_template": "{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth chat template fixes. Edited from ggml-org & OpenAI #}\n{#-\n In addition to the normal inputs of `messages` and `tools`, this template also accepts the\n following kwargs:\n - \"builtin_tools\": A list, can contain \"browser\" and/or \"python\".\n - \"model_identity\": A string that optionally describes the model identity.\n - \"reasoning_effort\": A string that describes the reasoning effort, defaults to \"medium\".\n #}\n\n{#- Tool Definition Rendering ============================================== #}\n{%- macro render_typescript_type(param_spec, required_params, is_nullable=false) -%}\n {%- if param_spec.type == \"array\" -%}\n {%- if param_spec['items'] -%}\n {%- if param_spec['items']['type'] == \"string\" -%}\n {{- \"string[]\" }}\n {%- elif param_spec['items']['type'] == \"number\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"integer\" -%}\n {{- \"number[]\" }}\n {%- elif param_spec['items']['type'] == \"boolean\" -%}\n {{- \"boolean[]\" }}\n {%- else -%}\n {%- set inner_type = render_typescript_type(param_spec['items'], required_params) -%}\n {%- if inner_type == \"object | object\" or inner_type|length > 50 -%}\n {{- \"any[]\" }}\n {%- else -%}\n {{- inner_type + \"[]\" }}\n {%- endif -%}\n {%- endif -%}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any[]\" }}\n {%- if param_spec.nullable -%}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type is defined and param_spec.type is iterable and param_spec.type is not string and param_spec.type is not mapping and param_spec.type[0] is defined -%}\n {#- Handle array of types like [\"object\", \"object\"] from Union[dict, list] #}\n {%- if param_spec.type | length > 1 -%}\n {{- param_spec.type | join(\" | \") }}\n {%- else -%}\n {{- param_spec.type[0] }}\n {%- endif -%}\n {%- elif param_spec.oneOf -%}\n {#- Handle oneOf schemas - check for complex unions and fallback to any #}\n {%- set has_object_variants = false -%}\n {%- for variant in param_spec.oneOf -%}\n {%- if variant.type == \"object\" -%}\n {%- set has_object_variants = true -%}\n {%- endif -%}\n {%- endfor -%}\n {%- if has_object_variants and param_spec.oneOf|length > 1 -%}\n {{- \"any\" }}\n {%- else -%}\n {%- for variant in param_spec.oneOf -%}\n {{- render_typescript_type(variant, required_params) -}}\n {%- if variant.description %}\n {{- \"// \" + variant.description }}\n {%- endif -%}\n {%- if variant.default is defined %}\n {{ \"// default: \" + variant.default|tojson }}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \" | \" }}\n {% endif -%}\n {%- endfor -%}\n {%- endif -%}\n {%- elif param_spec.type == \"string\" -%}\n {%- if param_spec.enum -%}\n {{- '\"' + param_spec.enum|join('\" | \"') + '\"' -}}\n {%- else -%}\n {{- \"string\" }}\n {%- if param_spec.nullable %}\n {{- \" | null\" }}\n {%- endif -%}\n {%- endif -%}\n {%- elif param_spec.type == \"number\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"integer\" -%}\n {{- \"number\" }}\n {%- elif param_spec.type == \"boolean\" -%}\n {{- \"boolean\" }}\n\n {%- elif param_spec.type == \"object\" -%}\n {%- if param_spec.properties -%}\n {{- \"{\\n\" }}\n {%- for prop_name, prop_spec in param_spec.properties.items() -%}\n {{- prop_name -}}\n {%- if prop_name not in (param_spec.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{ render_typescript_type(prop_spec, param_spec.required or []) }}\n {%- if not loop.last -%}\n {{-\", \" }}\n {%- endif -%}\n {%- endfor -%}\n {{- \"}\" }}\n {%- else -%}\n {{- \"object\" }}\n {%- endif -%}\n {%- else -%}\n {{- \"any\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{%- macro render_tool_namespace(namespace_name, tools) -%}\n {{- \"## \" + namespace_name + \"\\n\\n\" }}\n {{- \"namespace \" + namespace_name + \" {\\n\\n\" }}\n {%- for tool in tools %}\n {%- set tool = tool.function %}\n {{- \"// \" + tool.description + \"\\n\" }}\n {{- \"type \"+ tool.name + \" = \" }}\n {%- if tool.parameters and tool.parameters.properties -%}\n {{- \"(_: \" }}\n {{- \"{\\n\" }}\n {%- for param_name, param_spec in tool.parameters.properties.items() %}\n {{- \"// \" + param_spec.description + \"\\n\" }}\n {{- param_name }}\n {%- if param_name not in (tool.parameters.required or []) -%}\n {{- \"?\" }}\n {%- endif -%}\n {{- \": \" }}\n {{- render_typescript_type(param_spec, tool.parameters.required or []) }}\n {%- if param_spec.default is defined -%}\n {%- if param_spec.enum %}\n {{- \", // default: \" + param_spec.default }}\n {%- elif param_spec.oneOf %}\n {{- \"// default: \" + param_spec.default }}\n {%- else %}\n {{- \", // default: \" + param_spec.default|tojson }}\n {%- endif -%}\n {%- endif -%}\n {%- if not loop.last %}\n {{- \",\\n\" }}\n {%- else %}\n {{- \"\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"}) => any;\\n\\n\" }}\n {%- else -%}\n {{- \"() => any;\\n\\n\" }}\n {%- endif -%}\n {%- endfor %}\n {{- \"} // namespace \" + namespace_name }}\n{%- endmacro -%}\n\n{%- macro render_builtin_tools(browser_tool, python_tool) -%}\n {%- if browser_tool %}\n {{- \"## browser\\n\\n\" }}\n {{- \"// Tool for browsing.\\n\" }}\n {{- \"// The `cursor` appears in brackets before each browsing display: `[{cursor}]`.\\n\" }}\n {{- \"// Cite information from the tool using the following format:\\n\" }}\n {{- \"// `\u3010{cursor}\u2020L{line_start}(-L{line_end})?\u3011`, for example: `\u30106\u2020L9-L11\u3011` or `\u30108\u2020L3\u3011`.\\n\" }}\n {{- \"// Do not quote more than 10 words directly from the tool output.\\n\" }}\n {{- \"// sources=web (default: web)\\n\" }}\n {{- \"namespace browser {\\n\\n\" }}\n {{- \"// Searches for information related to `query` and displays `topn` results.\\n\" }}\n {{- \"type search = (_: {\\n\" }}\n {{- \"query: string,\\n\" }}\n {{- \"topn?: number, // default: 10\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Opens the link `id` from the page indicated by `cursor` starting at line number `loc`, showing `num_lines` lines.\\n\" }}\n {{- \"// Valid link ids are displayed with the formatting: `\u3010{id}\u2020.*\u3011`.\\n\" }}\n {{- \"// If `cursor` is not provided, the most recent page is implied.\\n\" }}\n {{- \"// If `id` is a string, it is treated as a fully qualified URL associated with `source`.\\n\" }}\n {{- \"// If `loc` is not provided, the viewport will be positioned at the beginning of the document or centered on the most relevant passage, if available.\\n\" }}\n {{- \"// Use this function without `id` to scroll to a new location of an opened page.\\n\" }}\n {{- \"type open = (_: {\\n\" }}\n {{- \"id?: number | string, // default: -1\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"loc?: number, // default: -1\\n\" }}\n {{- \"num_lines?: number, // default: -1\\n\" }}\n {{- \"view_source?: boolean, // default: false\\n\" }}\n {{- \"source?: string,\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"// Finds exact matches of `pattern` in the current page, or the page given by `cursor`.\\n\" }}\n {{- \"type find = (_: {\\n\" }}\n {{- \"pattern: string,\\n\" }}\n {{- \"cursor?: number, // default: -1\\n\" }}\n {{- \"}) => any;\\n\\n\" }}\n {{- \"} // namespace browser\\n\\n\" }}\n {%- endif -%}\n\n {%- if python_tool %}\n {{- \"## python\\n\\n\" }}\n {{- \"Use this tool to execute Python code in your chain of thought. The code will not be shown to the user. This tool should be used for internal reasoning, but not for code that is intended to be visible to the user (e.g. when creating plots, tables, or files).\\n\\n\" }}\n {{- \"When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 120.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is UNKNOWN. Depends on the cluster.\\n\\n\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- System Message Construction ============================================ #}\n{%- macro build_system_message() -%}\n {%- if model_identity is not defined %}\n {{- \"You are ChatGPT, a large language model trained by OpenAI.\\n\" -}}\n {%- else %}\n {{- model_identity }}\n {%- endif %}\n {{- \"Knowledge cutoff: 2024-06\\n\" }}\n {{- \"Current date: \" + strftime_now(\"%Y-%m-%d\") + \"\\n\\n\" }}\n {%- if reasoning_effort is not defined %}\n {%- set reasoning_effort = \"medium\" %}\n {%- endif %}\n {{- \"Reasoning: \" + reasoning_effort + \"\\n\\n\" }}\n {%- if builtin_tools is defined %}\n {{- \"# Tools\\n\\n\" }}\n {%- set available_builtin_tools = namespace(browser=false, python=false) %}\n {%- for tool in builtin_tools %}\n {%- if tool == \"browser\" %}\n {%- set available_builtin_tools.browser = true %}\n {%- elif tool == \"python\" %}\n {%- set available_builtin_tools.python = true %}\n {%- endif %}\n {%- endfor %}\n {{- render_builtin_tools(available_builtin_tools.browser, available_builtin_tools.python) }}\n {%- endif -%}\n {{- \"# Valid channels: analysis, commentary, final. Channel must be included for every message.\" }}\n {%- if tools is defined -%}\n {{- \"\\nCalls to these tools must go to the commentary channel: 'functions'.\" }}\n {%- endif -%}\n{%- endmacro -%}\n\n{#- Main Template Logic ================================================= #}\n{#- Set defaults #}\n\n{#- Render system message #}\n{{- \"<|start|>system<|message|>\" }}\n{{- build_system_message() }}\n{{- \"<|end|>\" }}\n\n{#- Extract developer message #}\n{%- if messages[0].role == \"developer\" or messages[0].role == \"system\" %}\n {%- set developer_message = messages[0].content %}\n {%- set loop_messages = messages[1:] %}\n{%- else %}\n {%- set developer_message = \"\" %}\n {%- set loop_messages = messages %}\n{%- endif %}\n\n{#- Render developer message #}\n{%- if developer_message or tools %}\n {{- \"<|start|>developer<|message|>\" }}\n {%- if developer_message %}\n {{- \"# Instructions\\n\\n\" }}\n {{- developer_message }}\n {%- endif %}\n {%- if tools -%}\n {{- \"\\n\\n\" }}\n {{- \"# Tools\\n\\n\" }}\n {{- render_tool_namespace(\"functions\", tools) }}\n {%- endif -%}\n {{- \"<|end|>\" }}\n{%- endif %}\n\n{#- Render messages #}\n{%- set last_tool_call = namespace(name=none) %}\n{%- for message in loop_messages -%}\n {#- At this point only assistant/user/tool messages should remain #}\n {%- if message.role == 'assistant' -%}\n {%- if \"tool_calls\" in message %}\n {#- We assume max 1 tool call per message, and so we infer the tool call name #}\n {#- in \"tool\" messages from the most recent assistant tool call name #}\n {%- set tool_call = message.tool_calls[0] %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {%- if message.content %}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.content + \"<|end|>\" }}\n {%- endif %}\n {{- \"<|start|>assistant to=\" }}\n {{- \"functions.\" + tool_call.name + \"<|channel|>commentary json<|message|>\" }}\n {{- tool_call.arguments|tojson }}\n {{- \"<|call|>\" }}\n {%- set last_tool_call.name = tool_call.name %}\n {%- elif \"thinking\" in message and loop.last and not add_generation_prompt %}\n {#- Only render the CoT if the final turn is an assistant turn and add_generation_prompt is false #}\n {#- This is a situation that should only occur in training, never in inference. #}\n {{- \"<|start|>assistant<|channel|>analysis<|message|>\" + message.thinking + \"<|end|>\" }}\n {#- <|return|> indicates the end of generation, but <|end|> does not #}\n {#- <|return|> should never be an input to the model, but we include it as the final token #}\n {#- when training, so the model learns to emit it. #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|return|>\" }}\n {%- set last_tool_call.name = none %}\n {%- elif \"thinking\" in message %}\n {#- CoT is dropped during all previous turns, so we never render it for inference #}\n {{- \"<|start|>assistant<|channel|>final<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- elif loop.last and not add_generation_prompt %}\n {#- <|return|> indicates the end of generation, but <|end|> does not #}\n {#- <|return|> should never be an input to the model, but we include it as the final token #}\n {#- when training, so the model learns to emit it. #}\n {{- \"<|start|>assistant<|message|>\" + message.content + \"<|return|>\" }}\n {%- else %}\n {{- \"<|start|>assistant<|message|>\" + message.content + \"<|end|>\" }}\n {%- set last_tool_call.name = none %}\n {%- endif %}\n {%- elif message.role == 'tool' -%}\n {%- if last_tool_call.name is none %}\n {{- raise_exception(\"Message has tool role, but there was no previous assistant message with a tool call!\") }}\n {%- endif %}\n {{- \"<|start|>functions.\" + last_tool_call.name }}\n {{- \" to=assistant<|channel|>commentary<|message|>\" + message.content|tojson + \"<|end|>\" }}\n {%- else -%}\n {{- \"<|start|>user<|message|>\" + message.content + \"<|end|>\" }}\n {%- endif -%}\n{%- endfor -%}\n\n{#- Generation prompt #}\n{%- if add_generation_prompt -%}\n<|start|>assistant\n{%- endif -%}\n{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth chat template fixes. Edited from ggml-org & OpenAI #}", "bos_token": "<|startoftext|>", "eos_token": "<|return|>"}
| null | null |
[
"apache-2.0"
] | null | null | 20,914,757,184
| 20,914,757,184
|
[
"text-generation"
] | null |
[
"gpt-oss",
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689b6e1c762054a0a5fa0e39
|
LiquidAI/LFM2-VL-1.6B
|
LiquidAI
| null | 9,241
| 9,241
|
False
| 2025-08-12T16:38:52Z
| 2025-08-13T09:44:29Z
|
transformers
| 172
| 15
| null |
image-text-to-text
|
{"parameters": {"BF16": 1584804000}, "total": 1584804000}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model.safetensors",
"modeling_lfm2_vl.py",
"preprocessor_config.json",
"processing_lfm2_vl.py",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
10644,
8910,
434,
2508,
132,
3169688328,
27396,
535,
24466,
435,
584,
4733040,
92279
] | 3,174,591,210
|
95bd1b5ff38beb09619b894f8b6882a0c66eac2c
|
[
"transformers",
"safetensors",
"lfm2-vl",
"image-text-to-text",
"liquid",
"lfm2",
"edge",
"conversational",
"custom_code",
"en",
"license:other",
"region:us"
] | null |
<center>
<div style="text-align: center;">
<img
src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/7_6D7rWrLxp2hb6OHSV1p.png"
alt="Liquid AI"
style="width: 100%; max-width: 66%; height: auto; display: inline-block; margin-bottom: 0.5em; margin-top: 0.5em;"
/>
</div>
</center>
# LFM2‑VL
LFM2‑VL is [Liquid AI](https://www.liquid.ai/)'s first series of multimodal models, designed to process text and images with variable resolutions.
Built on the [LFM2](https://huggingface.co/collections/LiquidAI/lfm2-686d721927015b2ad73eaa38) backbone, it is optimized for low-latency and edge AI applications.
We're releasing the weights of two post-trained checkpoints with [450M](https://huggingface.co/LiquidAI/LFM2-VL-450M) (for highly constrained devices) and [1.6B](https://huggingface.co/LiquidAI/LFM2-VL-1.6B) (more capable yet still lightweight) parameters.
* **2× faster inference speed** on GPUs compared to existing VLMs while maintaining competitive accuracy
* **Flexible architecture** with user-tunable speed-quality tradeoffs at inference time
* **Native resolution processing** up to 512×512 with intelligent patch-based handling for larger images, avoiding upscaling and distortion
Find more about our vision-language model in the [LFM2-VL post](https://www.liquid.ai/blog/lfm2-vl-efficient-vision-language-models) and its language backbone in the [LFM2 blog post](https://www.liquid.ai/blog/liquid-foundation-models-v2-our-second-series-of-generative-ai-models).
## 📄 Model details
Due to their small size, **we recommend fine-tuning LFM2-VL models on narrow use cases** to maximize performance.
They were trained for instruction following and lightweight agentic flows.
Not intended for safety‑critical decisions.
| Property | [**LFM2-VL-450M**](https://huggingface.co/LiquidAI/LFM2-VL-450M) | [**LFM2-VL-1.6B**](https://huggingface.co/LiquidAI/LFM2-VL-1.6B) |
|---|---:|---:|
| **Parameters (LM only)** | 350M | 1.2B |
| **Vision encoder** | SigLIP2 NaFlex base (86M) | SigLIP2 NaFlex shape‑optimized (400M) |
| **Backbone layers** | hybrid conv+attention | hybrid conv+attention |
| **Context (text)** | 32,768 tokens | 32,768 tokens |
| **Image tokens** | dynamic, user‑tunable | dynamic, user‑tunable |
| **Vocab size** | 65,536 | 65,536 |
| **Precision** | bfloat16 | bfloat16 |
| **License** | LFM Open License v1.0 | LFM Open License v1.0 |
**Supported languages:** English
**Generation parameters**: We recommend the following parameters:
- Text: `temperature=0.1`, `min_p=0.15`, `repetition_penalty=1.05`
- Vision: `min_image_tokens=64` `max_image_tokens=256`, `do_image_splitting=True`
**Chat template**: LFM2-VL uses a ChatML-like chat template as follows:
```
<|startoftext|><|im_start|>system
You are a helpful multimodal assistant by Liquid AI.<|im_end|>
<|im_start|>user
<image>Describe this image.<|im_end|>
<|im_start|>assistant
This image shows a Caenorhabditis elegans (C. elegans) nematode.<|im_end|>
```
Images are referenced with a sentinel (`<image>`), which is automatically replaced with the image tokens by the processor.
You can apply it using the dedicated [`.apply_chat_template()`](https://huggingface.co/docs/transformers/en/chat_templating#applychattemplate) function from Hugging Face transformers.
**Architecture**
- **Hybrid backbone**: Language model tower (LFM2-1.2B or LFM2-350M) paired with SigLIP2 NaFlex vision encoders (400M shape-optimized or 86M base variant)
- **Native resolution processing**: Handles images up to 512×512 pixels without upscaling and preserves non-standard aspect ratios without distortion
- **Tiling strategy**: Splits large images into non-overlapping 512×512 patches and includes thumbnail encoding for global context (in 1.6B model)
- **Efficient token mapping**: 2-layer MLP connector with pixel unshuffle reduces image tokens (e.g., 256×384 image → 96 tokens, 1000×3000 → 1,020 tokens)
- **Inference-time flexibility**: User-tunable maximum image tokens and patch count for speed/quality tradeoff without retraining
**Training approach**
- Builds on the LFM2 base model with joint mid-training that fuses vision and language capabilities using a gradually adjusted text-to-image ratio
- Applies joint SFT with emphasis on image understanding and vision tasks
- Leverages large-scale open-source datasets combined with in-house synthetic vision data, selected for balanced task coverage
- Follows a progressive training strategy: base model → joint mid-training → supervised fine-tuning
## 🏃 How to run LFM2-VL
You can run LFM2-VL with Hugging Face [`transformers`](https://github.com/huggingface/transformers) v4.55 or more recent as follows:
```bash
pip install -U transformers pillow
```
Here is an example of how to generate an answer with transformers in Python:
```python
from transformers import AutoProcessor, AutoModelForImageTextToText
from transformers.image_utils import load_image
# Load model and processor
model_id = "LiquidAI/LFM2-VL-1.6B"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
device_map="auto",
torch_dtype="bfloat16",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Load image and create conversation
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = load_image(url)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "What is in this image?"},
],
},
]
# Generate Answer
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
tokenize=True,
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=64)
processor.batch_decode(outputs, skip_special_tokens=True)[0]
# This image depicts a vibrant street scene in what appears to be a Chinatown or similar cultural area. The focal point is a large red stop sign with white lettering, mounted on a pole.
```
You can directly run and test the model with this [Colab notebook](https://colab.research.google.com/drive/11EMJhcVB6OTEuv--OePyGK86k-38WU3q?usp=sharing).
## 🔧 How to fine-tune
We recommend fine-tuning LFM2-VL models on your use cases to maximize performance.
| Notebook | Description | Link |
|-----------|----------------------------------------------------------------------|------|
| SFT (TRL) | Supervised Fine-Tuning (SFT) notebook with a LoRA adapter using TRL. | <a href="https://colab.research.google.com/drive/1csXCLwJx7wI7aruudBp6ZIcnqfv8EMYN?usp=sharing"><img src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/vlOyMEjwHa_b_LXysEu2E.png" width="110" alt="Colab link"></a> |
## 📈 Performance
| Model | RealWorldQA | MM-IFEval | InfoVQA (Val) | OCRBench | BLINK | MMStar | MMMU (Val) | MathVista | SEEDBench_IMG | MMVet | MME | MMLU |
|-------------------|-------------|-----------|---------------|----------|-------|--------|------------|-----------|---------------|-------|----------|-------|
| InternVL3-2B | 65.10 | 38.49 | 66.10 | 831 | 53.10 | 61.10 | 48.70 | 57.60 | 75.00 | 67.00 | 2186.40 | 64.80 |
| InternVL3-1B | 57.00 | 31.14 | 54.94 | 798 | 43.00 | 52.30 | 43.20 | 46.90 | 71.20 | 58.70 | 1912.40 | 49.80 |
| SmolVLM2-2.2B | 57.50 | 19.42 | 37.75 | 725 | 42.30 | 46.00 | 41.60 | 51.50 | 71.30 | 34.90 | 1792.50 | - |
| LFM2-VL-1.6B | 65.23 | 37.66 | 58.68 | 742 | 44.40 | 49.53 | 38.44 | 51.10 | 71.97 | 48.07 | 1753.04 | 50.99 |
| Model | RealWorldQA | MM-IFEval | InfoVQA (Val) | OCRBench | BLINK | MMStar | MMMU (Val) | MathVista | SEEDBench_IMG | MMVet | MME | MMLU |
|-------------------|-------------|-----------|---------------|----------|-------|--------|------------|-----------|---------------|-------|----------|-------|
| SmolVLM2-500M | 49.90 | 11.27 | 24.64 | 609 | 40.70 | 38.20 | 34.10 | 37.50 | 62.20 | 29.90 | 1448.30 | - |
| LFM2-VL-450M | 52.29 | 26.18 | 46.51 | 655 | 41.98 | 40.87 | 33.11 | 44.70 | 63.50 | 33.76 | 1239.06 | 40.16 |
We obtained MM-IFEval and InfoVQA (Val) scores for InternVL 3 and SmolVLM2 models using VLMEvalKit.
## 📬 Contact
If you are interested in custom solutions with edge deployment, please contact [our sales team](https://www.liquid.ai/contact).
|
[
"prithivMLmods/Tiny-VLMs-Lab",
"Tonic/l-operator-demo"
] |
[
"other",
"lfm1.0",
"LICENSE"
] | null |
[
"en"
] | 1,584,804,000
| null |
[
"image-text-to-text"
] | null |
[
"modeling_lfm2_vl.Lfm2VlForConditionalGeneration",
"AutoModelForImageTextToText",
"lfm2-vl",
"Lfm2VlForConditionalGeneration"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689c3a5042f8611cd73006a6
|
tencent/Hunyuan-GameCraft-1.0
|
tencent
| null | 292
| 292
|
False
| 2025-08-13T07:10:08Z
| 2025-08-19T06:19:16Z
| null | 474
| 15
| null |
image-to-video
| null |
[
".gitattributes",
"LICENSE",
"Notice.txt",
"README.md",
"asset/method.png",
"asset/teaser.png",
"config.json",
"gamecraft_models/mp_rank_00_model_states.pt",
"gamecraft_models/mp_rank_00_model_states_distill.pt",
"stdmodels/llava-llama-3-8b-v1_1-transformers/.gitattributes",
"stdmodels/llava-llama-3-8b-v1_1-transformers/README.md",
"stdmodels/llava-llama-3-8b-v1_1-transformers/config.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/generation_config.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/model-00001-of-00004.safetensors",
"stdmodels/llava-llama-3-8b-v1_1-transformers/model-00002-of-00004.safetensors",
"stdmodels/llava-llama-3-8b-v1_1-transformers/model-00003-of-00004.safetensors",
"stdmodels/llava-llama-3-8b-v1_1-transformers/model-00004-of-00004.safetensors",
"stdmodels/llava-llama-3-8b-v1_1-transformers/model.safetensors.index.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/preprocessor_config.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/special_tokens_map.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/tokenizer.json",
"stdmodels/llava-llama-3-8b-v1_1-transformers/tokenizer_config.json",
"stdmodels/openai_clip-vit-large-patch14/.gitattributes",
"stdmodels/openai_clip-vit-large-patch14/README.md",
"stdmodels/openai_clip-vit-large-patch14/config.json",
"stdmodels/openai_clip-vit-large-patch14/flax_model.msgpack",
"stdmodels/openai_clip-vit-large-patch14/merges.txt",
"stdmodels/openai_clip-vit-large-patch14/model.safetensors",
"stdmodels/openai_clip-vit-large-patch14/preprocessor_config.json",
"stdmodels/openai_clip-vit-large-patch14/pytorch_model.bin",
"stdmodels/openai_clip-vit-large-patch14/special_tokens_map.json",
"stdmodels/openai_clip-vit-large-patch14/tf_model.h5",
"stdmodels/openai_clip-vit-large-patch14/tokenizer.json",
"stdmodels/openai_clip-vit-large-patch14/tokenizer_config.json",
"stdmodels/openai_clip-vit-large-patch14/vocab.json",
"stdmodels/vae_3d/hyvae/checkpoint-step-270000.ckpt",
"stdmodels/vae_3d/hyvae/config.json",
"stdmodels/vae_3d/hyvae/pytorch_model.pt",
"stdmodels/vae_3d/hyvae/source",
"teaser.png"
] | null | null |
022caa8698ea7134cd7823875757e7322fe894d6
|
[
"safetensors",
"image-to-video",
"en",
"arxiv:2506.17201",
"region:us"
] | null |
<!-- ## **Hunyuan-GameCraft** -->
<!-- <p align="center">
<img src="assets/material/logo.png" height=100>
</p> -->
# **Hunyuan-GameCraft** 🎮
<div align="center">
<a href="https://github.com/Tencent-Hunyuan/Hunyuan-GameCraft-1.0"><img src="https://img.shields.io/static/v1?label=Hunyuan-GameCraft-1.0%20Code&message=Github&color=blue"></a>  
<a href="https://hunyuan-gamecraft.github.io/"><img src="https://img.shields.io/static/v1?label=Project%20Page&message=Web&color=green"></a>  
<a href="https://arxiv.org/abs/2506.17201"><img src="https://img.shields.io/badge/ArXiv-2506.17201-red"></a>  
</div>
<div align="center">
<a href="https://huggingface.co/tencent/Hunyuan-GameCraft-1.0"><img src="https://img.shields.io/static/v1?label=Huggingface&message=Hunyuan-GameCraft-1.0&color=yellow"></a>  
</div>

> [**Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition**](https://arxiv.org/abs/2506.17201) <be>
## 🔥🔥🔥 News!!
* Aug 14, 2025: 👋 We release the inference code and model weights of Hunyuan-GameCraft. [Download](weights/README.md).
## 📑 Open-source Plan
- Hunyuan-GameCraft
- [x] Inference
- [x] Checkpoints
- [ ] Gradio & Huggingface Demo
## Contents
- [**Hunyuan-GameCraft** 🌅](#Hunyuan-GameCraft-)
- [🔥🔥🔥 News!!](#-news)
- [📑 Open-source Plan](#-open-source-plan)
- [Contents](#contents)
- [**Abstract**](#abstract)
- [**Overall Architecture**](#Hunyuan-GameCraft-overall-architecture)
- [📜 Requirements](#-requirements)
- [🛠️ Dependencies and Installation](#️-dependencies-and-installation)
- [Installation Guide for Linux](#installation-guide-for-linux)
- [🧱 Download Pretrained Models](#-download-pretrained-models)
- [🚀 Parallel Inference on Multiple GPUs](#-parallel-inference-on-multiple-gpus)
- [🔑 Single-gpu Inference](#-single-gpu-inference)
- [Run with very low VRAM](#run-with-very-low-vram)
- [Run a Gradio Server](#run-a-gradio-server)
- [🔗 BibTeX](#-bibtex)
- [Acknowledgements](#acknowledgements)
---
## **Abstract**
Recent advances in diffusion-based and controllable video generation have enabled high-quality and temporally coherent video synthesis, laying the groundwork for immersive interactive gaming experiences. However, current methods face limitations in **dynamics**, **physically realistic**, **long-term consistency**, and **efficiency**, which limit the ability to create various gameplay videos. To address these gaps, we introduce Hunyuan-GameCraft, a novel framework for high-dynamic interactive video generation in game environments. To achieve fine-grained action control, we unify standard keyboard and mouse inputs into a **shared camera representation space**, facilitating smooth interpolation between various camera and movement operations. Then we propose a **hybrid history-conditioned training strategy** that extends video sequences autoregressively while preserving game scene information. Additionally, to enhance inference efficiency and playability, we achieve **model distillation** to reduce computational overhead while maintaining consistency across long temporal sequences, making it suitable for real-time deployment in complex interactive environments. The model is trained on a large-scale dataset comprising over one million gameplay recordings across over 100 AAA games, ensuring broad coverage and diversity, then fine-tuned on a carefully annotated synthetic dataset to enhance precision and control. The curated game scene data significantly improves the visual fidelity, realism and action controllability. Extensive experiments demonstrate that Hunyuan-GameCraft significantly outperforms existing models, advancing the realism and playability of interactive game video generation.
## **Overall Architecture**

Given a reference image and the corresponding prompt, the keyboard or mouse signal, we transform these options to the continuous camera space. Then we design a light-weight action encoder to encode the input camera trajectory. The action and image features are added after patchify. For long video extension, we design a variable mask indicator, where 1 and 0 indicate history frames and predicted frames, respectively.
## 📜 Requirements
* An NVIDIA GPU with CUDA support is required.
* The model is tested on a machine with 8GPUs.
* **Minimum**: The minimum GPU memory required is 24GB but very slow.
* **Recommended**: We recommend using a GPU with 80GB of memory for better generation quality.
* Tested operating system: Linux
## 🛠️ Dependencies and Installation
Begin by cloning the repository:
```shell
git clone https://github.com/Tencent-Hunyuan/Hunyuan-GameCraft-1.0.git
cd Hunyuan-GameCraft-1.0
```
### Installation Guide for Linux
We recommend CUDA versions 12.4 for the manual installation.
Conda's installation instructions are available [here](https://docs.anaconda.com/free/miniconda/index.html).
```shell
# 1. Create conda environment
conda create -n HYGameCraft python==3.10
# 2. Activate the environment
conda activate HYGameCraft
# 3. Install PyTorch and other dependencies using conda
conda install pytorch==2.5.1 torchvision==0.20.0 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
# 4. Install pip dependencies
python -m pip install -r requirements.txt
# 5. Install flash attention v2 for acceleration (requires CUDA 11.8 or above)
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/[email protected]
```
Additionally, you can also use HunyuanVideo Docker image. Use the following command to pull and run the docker image.
```shell
# For CUDA 12.4 (updated to avoid float point exception)
docker pull hunyuanvideo/hunyuanvideo:cuda_12
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged hunyuanvideo/hunyuanvideo:cuda_12
pip install diffusers==0.34.0 transformers==4.54.1
```
## 🚀 Parallel Inference on Multiple GPUs
For example, to generate a video using 8 GPUs, you can use the following command, where `--action-list w s d a` simulate keyboard manipulation signals to help you generate a video of the corresponding content. `--action-speed-list 0.2 0.2 0.2 0.2` represents the displacement distance and can be replaced with any value between 0 and 3, the length of `action-speed-list` must be the same as `action-list`:
```bash
#!/bin/bash
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=${JOBS_DIR}:$PYTHONPATH
export MODEL_BASE="weights/stdmodels"
checkpoint_path="weights/gamecraft_models/mp_rank_00_model_states.pt"
current_time=$(date "+%Y.%m.%d-%H.%M.%S")
modelname='Tencent_hunyuanGameCraft_720P'
torchrun --nnodes=1 --nproc_per_node=8 --master_port 29605 hymm_sp/sample_batch.py \
--image-path "asset/village.png" \
--prompt "A charming medieval village with cobblestone streets, thatched-roof houses, and vibrant flower gardens under a bright blue sky." \
--add-pos-prompt "Realistic, High-quality." \
--add-neg-prompt "overexposed, low quality, deformation, a poor composition, bad hands, bad teeth, bad eyes, bad limbs, distortion, blurring, text, subtitles, static, picture, black border." \
--ckpt ${checkpoint_path} \
--video-size 704 1216 \
--cfg-scale 2.0 \
--image-start \
--action-list w s d a \
--action-speed-list 0.2 0.2 0.2 0.2 \
--seed 250160 \
--infer-steps 50 \
--flow-shift-eval-video 5.0 \
--save-path './results/'
```
Additionally, we support FP8 optimization and [SageAttn](https://github.com/thu-ml/SageAttention). To enable FP8, simply add the `--use-fp8` to your command.
And install SageAttention with:
```bash
git clone https://github.com/thu-ml/SageAttention.git
cd SageAttention
python setup.py install # or pip install -e .
```
We also provide accelerated model, you can use the following command:
```bash
#!/bin/bash
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=${JOBS_DIR}:$PYTHONPATH
export MODEL_BASE="weights/stdmodels"
checkpoint_path="weights/gamecraft_models/mp_rank_00_model_states_distill.pt"
current_time=$(date "+%Y.%m.%d-%H.%M.%S")
modelname='Tencent_hunyuanGameCraft_720P'
torchrun --nnodes=1 --nproc_per_node=8 --master_port 29605 hymm_sp/sample_batch.py \
--image-path "asset/village.png" \
--prompt "A charming medieval village with cobblestone streets, thatched-roof houses, and vibrant flower gardens under a bright blue sky." \
--add-neg-prompt "overexposed, low quality, deformation, a poor composition, bad hands, bad teeth, bad eyes, bad limbs, distortion, blurring, text, subtitles, static, picture, black border." \
--ckpt ${checkpoint_path} \
--video-size 704 1216 \
--cfg-scale 1.0 \
--image-start \
--action-list w s d a \
--action-speed-list 0.2 0.2 0.2 0.2 \
--seed 250160 \
--infer-steps 8 \
--use-fp8 \
--flow-shift-eval-video 5.0 \
--save-path './results_distill/'
```
## 🔑 Single-gpu with Low-VRAM Inference
For example, to generate a video with 1 GPU with Low-VRAM (over 24GB), you can use the following command:
```bash
#!/bin/bash
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=${JOBS_DIR}:$PYTHONPATH
export MODEL_BASE="weights/stdmodels"
checkpoint_path="weights/gamecraft_models/mp_rank_00_model_states.pt"
current_time=$(date "+%Y.%m.%d-%H.%M.%S")
modelname='Tencent_hunyuanGameCraft_720P'
# disable sp and cpu offload
export DISABLE_SP=1
export CPU_OFFLOAD=1
torchrun --nnodes=1 --nproc_per_node=1 --master_port 29605 hymm_sp/sample_batch.py \
--image-path "asset/village.png" \
--prompt "A charming medieval village with cobblestone streets, thatched-roof houses, and vibrant flower gardens under a bright blue sky." \
--add-neg-prompt "overexposed, low quality, deformation, a poor composition, bad hands, bad teeth, bad eyes, bad limbs, distortion, blurring, text, subtitles, static, picture, black border." \
--ckpt ${checkpoint_path} \
--video-size 704 1216 \
--cfg-scale 2.0 \
--image-start \
--action-list w a d s \
--action-speed-list 0.2 0.2 0.2 0.2 \
--seed 250160 \
--sample-n-frames 33 \
--infer-steps 50 \
--flow-shift-eval-video 5.0 \
--cpu-offload \
--use-fp8 \
--save-path './results/'
```
## 🔗 BibTeX
If you find [Hunyuan-GameCraft](https://arxiv.org/abs/2506.17201) useful for your research and applications, please cite using this BibTeX:
```BibTeX
@misc{li2025hunyuangamecrafthighdynamicinteractivegame,
title={Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition},
author={Jiaqi Li and Junshu Tang and Zhiyong Xu and Longhuang Wu and Yuan Zhou and Shuai Shao and Tianbao Yu and Zhiguo Cao and Qinglin Lu},
year={2025},
eprint={2506.17201},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.17201},
}
```
## Acknowledgements
We would like to thank the contributors to the [HunyuanVideo](https://github.com/Tencent/HunyuanVideo), [HunyuanVideo-Avatar](https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar),[SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [FLUX](https://github.com/black-forest-labs/flux), [Llama](https://github.com/meta-llama/llama), [LLaVA](https://github.com/haotian-liu/LLaVA), [Xtuner](https://github.com/InternLM/xtuner), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research and exploration.
|
[
"jbilcke-hf/Hunyuan-GameCraft"
] | null | null |
[
"en"
] | null | null |
[
"image-to-video"
] | null | null |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
free
| null |
[
"China"
] | null | null | null | null | null | null | null | null | null |
68b069e80036076f51629e46
|
speach1sdef178/PJ0_QwenImage_Realistic_FP8_HF_Stage_2
|
speach1sdef178
| null | 0
| 0
|
False
| 2025-08-28T14:38:32Z
| 2025-08-31T00:21:04Z
|
diffusers
| 15
| 15
| null |
text-to-image
| null |
[
".gitattributes",
"Images/sample1.jpg",
"Images/sample10.jpg",
"Images/sample11.jpg",
"Images/sample12.jpg",
"Images/sample13.jpg",
"Images/sample14.jpg",
"Images/sample15.jpg",
"Images/sample2.jpg",
"Images/sample3.jpg",
"Images/sample4.jpg",
"Images/sample5.jpg",
"Images/sample6.jpg",
"Images/sample7.jpg",
"Images/sample8.jpg",
"Images/sample9.jpg",
"README.md",
"images/Image 1.jpg",
"images/Image 10.jpg",
"images/Image 11.jpg",
"images/Image 12.jpg",
"images/Image 13.jpg",
"images/Image 14.jpg",
"images/Image 15.jpg",
"images/Image 2.jpg",
"images/Image 3.jpg",
"images/Image 4.jpg",
"images/Image 5.jpg",
"images/Image 6.jpg",
"images/Image 7.jpg",
"images/Image 8.jpg",
"images/Image 9.jpg",
"weights/PJ0_QwenImage_Realistic_FP8_HF_Stage_2.safetensors"
] | null | null |
cdd23e7c9af3118ad830648b204cd58b8f84f7a8
|
[
"diffusers",
"lora",
"flux",
"realism",
"text-to-image",
"license:apache-2.0",
"region:us"
] | null |
# PJ0 QwenImage Realistic FP8 (HF) — Stage 2
**RU:**
Это второй этап улучшения базовой модели **Qwen_Image**. В этой версии повышен **реализм** и **чёткость деталей** — особенно на коже, ткани и мелких орнаментах. Лучшие результаты по моим тестам дают семплеры **Euler/Simple**. Модель ориентирована на фотореалистические портреты и сценки с мягким кинематографичным светом.
**EN:**
This is the second improvement stage over the base **Qwen_Image** model. This release focuses on **stronger realism** and **crisper details**, especially on skin, fabric, and fine ornaments. In my tests, the best samplers are **Euler/Simple**. The model targets photorealistic portraits and cinematic, soft-lit scenes.
---
## Recommended settings / Рекомендации
- **Samplers:** Euler / Simple
- **Steps:** 20–30 (sweet spot ~24)
- **CFG / Guidance:** 1.0–4.0
- ** USE CFG=1 for realism
- **Weights:** FP8 (экономия VRAM)
> Примечание: на однотонных фонах у FP8-квантования иногда заметен лёгкий banding. Для минимизации: high-res fix (апскейл ×2 + низкий denoise) или быстрый пост-денойз.
---
## Examples















---
## License
Apache-2.0
| null |
[
"apache-2.0"
] | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
65e60cda4b2e0f45e49dc03d
|
vikhyatk/moondream2
|
vikhyatk
| null | 184,333
| 6,169,468
|
False
| 2024-03-04T18:03:06Z
| 2025-07-07T05:57:09Z
|
transformers
| 1,270
| 14
| null |
image-text-to-text
|
{"parameters": {"BF16": 1927237104}, "total": 1927237104}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"config.py",
"configuration_moondream.py",
"fourier_features.py",
"generation_config.json",
"handler.py",
"hf_moondream.py",
"image_crops.py",
"layers.py",
"lora.py",
"merges.txt",
"model.safetensors",
"moondream.py",
"region.py",
"region_model.py",
"requirements.txt",
"rope.py",
"special_tokens_map.json",
"text.py",
"tokenizer.json",
"tokenizer_config.json",
"utils.py",
"versions.txt",
"vision.py",
"vision_encoder.py",
"vocab.json",
"weights.py"
] |
[
1649,
4185,
1080,
277,
2647,
3343,
558,
69,
2101,
5534,
8145,
4558,
2299,
456318,
3854538968,
35501,
4545,
1331,
42,
1573,
99,
6851,
2114924,
7339,
1415,
131,
5087,
10214,
798156,
9709
] | 3,858,028,648
|
28a4beffe5d08b8104e1dbc10b5cd29a5a13722c
|
[
"transformers",
"safetensors",
"moondream1",
"text-generation",
"image-text-to-text",
"custom_code",
"doi:10.57967/hf/3219",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | null |
[
"prithivMLmods/Tiny-VLMs-Lab",
"BoltzmannEntropy/vlms",
"moondream/content-moderation",
"bhaskartripathi/LLM_Quantization",
"vikhyatk/moondream1",
"Omnibus/moondream2",
"fffiloni/soft-video-understanding",
"Kartik2503/ImageToText",
"fcole/moondream",
"stdgy/mdrm2",
"Greatmonkey/image_to_text",
"Nymbo/soft-video-understanding-addingaudio",
"ManishThota/Build",
"radames/Candle-Moondream-2",
"emilios/moondream2",
"awacke1/Image-Text-to-Text-with-Moondream2",
"PeepDaSlan9/B2BMGMT_Candle-Moondream-2",
"rdezwart/FoodIdentifier",
"Csplk/moondream2-batch-processing",
"jbilcke-hf/ai-tube-model-moondream2",
"ModularityAI/AskMoondream",
"ChrisMofus/BestStoryTeller",
"dwb2023/moondream2",
"Ivana123/Bakalarska_Praca",
"MrOvkill/moondream-2-multi-interrogation",
"d-delaurier/myAssistant_moondream_v2",
"vikhyatk/contemplative-moondream",
"dwb2023/model_explorer2",
"muhtasham/agent",
"AkashMnd/moondream2",
"dwb2023/model_explorer4",
"hypno-ai/moondream2",
"Ahmed007/modarb_API",
"Yakshaving/moondream2",
"Ahmed007/Modarb-AI",
"jo2456654545/segment",
"jo2456654545/detection",
"ruslanmv/convert_to_gguf",
"lucy1118/storytelling-backup",
"AWeirdDev/moondream-inference",
"yeshavyas27/moondream-finetuned-demo",
"dwb2023/omniscience",
"neonwatty/meme_search",
"0xmrmasry/Modarb-AI",
"pllara/vikhyatk-moondream2",
"Ledenav/vikhyatk-moondream2",
"Aleko514/vikhyatk-moondream2",
"LukeJacob2023/moondream-webui",
"sajid1085/image-text-conv-first",
"mvgr/medadviser",
"srivatsavdamaraju/phi-3modelapi",
"ItzRoBeerT/pigeon-avatar",
"John6666/moondream2-cpu",
"volumetrader/Iris",
"akshit-g/SeeForMe-Life",
"akshit-g/SeeForMe-Video",
"akshit-g/SeeForMe-Image",
"akshit-g/SeeForMe-Live",
"andito/moondream-05",
"eybro/Iris",
"lord-reso/scene-understanding",
"suayptalha/QwQ-32B-Preview-Vision",
"reach-vb/2025-ai-timeline",
"techdrizzdev/ui_model_eval",
"ParsaKhaz/redact-video-demo",
"moondream/video-redaction",
"KBaba7/Quant",
"totolook/Quant",
"MrCool552/Icicle",
"ParsaKhaz/promptable-content-moderation",
"Jamari/promptable-content-moderation",
"FallnAI/Quantize-HF-Models",
"K00B404/LLM_Quantization",
"makululinux/censor",
"munnae/moondreambc220",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"GF-John/moondream-pointer",
"Agents-MCP-Hackathon/moondream-pointer",
"nomri/Tadashi-TDS-TA",
"AU2003USD2024/ai-street-crossing-assistant",
"fffiloni/Image-to-Fragrance",
"sergiopaniego/vlm_object_understanding",
"ilyas02828/Object_Detection",
"ObiJuanCodenobi/vlm_Object_tracking",
"K00B404/convert_to_gguf",
"sayantan47/Image-Captioner-using-Moondream-2",
"officialneaven/vlm_Object_tracking",
"chalrie987/vision-moondream"
] |
[
"apache-2.0"
] | null | null | 1,927,237,104
| null |
[
"text-generation",
"image-text-to-text"
] | null |
[
"HfMoondream",
"hf_moondream.HfMoondream",
"moondream1",
"AutoModelForCausalLM"
] |
[
"multimodal",
"text"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
67b79c8700245b72c5706777
|
google/gemma-3-4b-it
|
google
|
{
"models": [
{
"_id": "67b79c6c01ad68cfed14677a",
"id": "google/gemma-3-4b-pt"
}
],
"relation": "finetune"
}
| 1,283,826
| 6,265,050
|
manual
| 2025-02-20T21:20:07Z
| 2025-03-21T20:20:53Z
|
transformers
| 817
| 14
| null |
image-text-to-text
|
{"parameters": {"BF16": 4300079472}, "total": 4300079472}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"generation_config.json",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1760,
25122,
35,
1615,
855,
215,
4961251752,
3639026128,
90558,
570,
70,
662,
33384568,
4689074,
1156999
] | 8,639,629,983
|
093f9f388b31de276ce2de164bdc2081324b9767
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"conversational",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2311.12022",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2312.11805",
"base_model:google/gemma-3-4b-pt",
"base_model:finetune:google/gemma-3-4b-pt",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"umint/ai",
"ginigen/VEO3-Free",
"ginigen/VEO3-Free-mirror",
"ginigen/VEO3-Directors",
"orionweller/gemma-3-token-counter",
"rishi2025/VEO3-Free",
"umint/o4-mini",
"Teapack1/RAG-Retrieve-Ingest-cz-eng",
"bishmoy/Arxiv-CS-RAG",
"CalvinU/writing-prototypes",
"TIGER-Lab/MEGA-Bench",
"stiv14/pdf-multilanguage-qa-role",
"hanzla/PlaygroundGemma3",
"jonaschua/gemma",
"rathormanoj08/gemma3-model",
"snowkylin/refsheet_chat",
"Tomoniai/gemma-3-chat",
"Slyracoon23/what_is_prompt_engineering",
"merterbak/gemma-3",
"Didier/Vision_language_Gemma3",
"PegasusPedal/gemma-examples",
"Rohit1412/AirGPT1.04b",
"CognitiveScience/gemma-3-chat",
"baconnier/Napoleon_Junior",
"gaganyatri/ai4bharat-server",
"mohitkumarrajbadi/Finetune_Gemma_Model",
"akshatsha/linkedin-ai",
"innoai/gemma-3-4b-it",
"hadadrjt/ai",
"krsnewwave/fun-image-caption",
"Kfjjdjdjdhdhd/Vllm-xd",
"AC2513/gemma-translate",
"fukugawa/indiebot-arena",
"whitecircle-ai/circle-guard-bench",
"nurswizz/visioner-ai",
"llama-yash/AI_Chatbot",
"NanobotzAI/gemma-3-chat",
"NanobotzAI/gemma-3-chat-api",
"Pamudu13/gemma-3-chat-api",
"Pamudu13/gemma-3-chat-api-2",
"NanobotzAI/gemma-3-chat-api-2",
"halfacupoftea/Gemma_Calorai",
"BhumikaShetty/Gemma3bot",
"maycodes/Gemma-ID-Image-extracter",
"mayukhpankaj/Gemma-ID-extraction",
"VIDraft/Gemma-3-R1984-4B",
"iryahayri/gemma32",
"fcervan/leitor-cnh",
"saa231/MutimodalVisionAssistant",
"sierrafr/test",
"naxwinn/Aura-2",
"JeffMII/CEC-Learning",
"Tondeptrai23/test",
"Paradoxsyn/HugStun",
"NanobotzAI/gemma-3-chat-api-3",
"KWRegan/LIFgen",
"naokiishii/Final_Assignment_Template",
"aizip-dev/SLM-RAG-Arena",
"rohitkhadka/problemgenerator",
"LLMhacker/deepseek-r1dotcom",
"F57889998888/dtd_mds_fse_support_beta",
"makululinux/fun-image-caption",
"TejAndrewsACC/ACC-AI-ChatBot",
"TejAndrewsACC/ACC-AI-Chat-MultiModal-V2025",
"broadfield-dev/gemma_test",
"konieshadow/podcast-transcriber",
"namfam/image2latex",
"Agents-MCP-Hackathon/novel-heroes",
"MohitG012/Ecomerce_Customer_Support_Chatbot",
"Murtadhaa/chat",
"VIDraft/Robo-Beam",
"kairusama/gemma-3-4b-it-qat",
"ivangabriele/trl-sandbox",
"bagihosting/VEO3",
"bagihosting/VEO3-Bagihosting",
"FilipeR/WAN-21-Test",
"Dhanuvagman/nexa",
"KCprsnlcc/my-gemma-space",
"Shrsai/gradio_app",
"ReallyFloppyPenguin/AICodepen",
"Draculajeni/VEO3-Free",
"bodyapromax2010/google-gemma-3-4b-it2",
"suprimedev/google-gemma-3-4b-it",
"sghosh01/google-gemma-demo",
"k3ybladewielder/cloudwalk_chatbot",
"mcjhn/ai",
"blueda9232/ai",
"salmankhanpm/Telugu_Vocab_Evaluation",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"Obunr/VEO333",
"swechaap/Telugu_Vocab_Evaluation",
"YAZAVIS092/VEO3-FreeforALL",
"fumucu/LAOD",
"matthartman/my-fast-rtc-app",
"Ntdeseb/NTIA-VEO3-Free",
"Lewis159/VEO3-Free",
"ethiotech4848/Object-Detection-and-Understanding-with-VLMs",
"SHIKARICHACHA/Multi_AI_Agent",
"bencent/VEO3-4Free",
"vishaljoshi24/trl-4-dnd",
"uumerrr684/chatflow",
"myselfhridoy/gemma3-free-api",
"Seth0330/OCR_VISION",
"haiyu/FOMO_industries_matcher",
"wuhuizgptamd/ai",
"Saint5/multimodal_rag_system",
"vietnux/veo3-fake",
"whatdoesrealitymean/VEO3-Free",
"rzvn/Medieval-Village-AI",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"vinoddoi/invoice-ai-form-filler",
"umint/openwebui"
] |
[
"gemma"
] | null | null | 4,300,079,472
| null |
[
"image-text-to-text"
] | null |
[
"AutoModelForImageTextToText",
"Gemma3ForConditionalGeneration",
"gemma3"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
67eda7320477637a48f1bd19
|
reducto/RolmOCR
|
reducto
|
{
"models": [
{
"_id": "6795ffcd88cd7c0294702a72",
"id": "Qwen/Qwen2.5-VL-7B-Instruct"
}
],
"relation": "finetune"
}
| 113,625
| 653,629
|
False
| 2025-04-02T21:08:02Z
| 2025-04-02T21:12:08Z
|
transformers
| 493
| 14
| null |
image-to-text
|
{"parameters": {"BF16": 8292166656}, "total": 8292166656}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
3491,
605,
1049,
1490,
214,
1671853,
4968243304,
4991495816,
4932751040,
1691924384,
57619,
575,
613,
11421896,
7327,
2776833
] | 16,600,359,679
|
f8c7a4b98df7d176d2720353b33a114905257f74
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"dataset:allenai/olmOCR-mix-0225",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"prithivMLmods/Multimodal-OCR",
"davanstrien/ocr-time-machine",
"ajforbes20/Multimodal-OCR",
"GoConqurer/textlens-efficient",
"Sivasuriya/Image2TextOCR",
"Shiv22/Multimodal-OCR",
"ndgold/Multimodal-OCR",
"Sanmath/text2",
"amberborici/Qwen-Qwen2-VL-7B-Instruct",
"storytracer/ocr-time-machine"
] |
[
"apache-2.0"
] |
[
"allenai/olmOCR-mix-0225"
] | null | 8,292,166,656
| null |
[
"image-to-text"
] | null |
[
"AutoModelForVision2Seq",
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] |
[
"multimodal"
] |
[
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null |
Qwen/Qwen2.5-VL-7B-Instruct
|
[
"Image"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 4
|
680da79d48c19d19cf82ab5e
|
Qwen/Qwen3-8B
|
Qwen
|
{
"models": [
{
"_id": "680f0c3e6eacf22a04ee1219",
"id": "Qwen/Qwen3-8B-Base"
}
],
"relation": "finetune"
}
| 4,399,178
| 10,138,544
|
False
| 2025-04-27T03:42:21Z
| 2025-07-26T03:49:13Z
|
transformers
| 570
| 14
| null |
text-generation
|
{"parameters": {"BF16": 8190735360}, "total": 8190735360}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00005.safetensors",
"model-00002-of-00005.safetensors",
"model-00003-of-00005.safetensors",
"model-00004-of-00005.safetensors",
"model-00005-of-00005.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
16660,
728,
239,
1671853,
3996250744,
3993160032,
3959604768,
3187841392,
1244659840,
32878,
11422654,
9732,
2776833
] | 16,397,461,266
|
b968826d9c46dd6066d109eabc6255188de91218
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:finetune:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"innoai/self-forcing",
"Heartsync/VEO3-RealTime",
"Qwen/Qwen3-Demo",
"nvidia/kvpress-leaderboard",
"ISEEKYAN/megatron_memory_estimator",
"mozilla-ai/wasm-agents-blueprint",
"nazdridoy/inferoxy-hub",
"Humbl3m33/Qwen-Qwen3-8B",
"VIDraft/Qwen3",
"UD-Filipino/filbench-leaderboard",
"whitecircle-ai/circle-guard-bench",
"Luigi/ZeroGPU-LLM-Inference",
"aiqtech/LLM-Token-Visual",
"Unknown504/web-ui",
"VIDraft/Qwen3-8B",
"insight-ai/api",
"Skywork/SkyCaptioner-V1",
"Tinkering/Pytorch-day-prez",
"VIDraft/Local-RAG-Qwen3-8b",
"xe1phix/Qwen3-Demo",
"MicoGuild/Olubakka",
"KraTUZen/LogicLink-Project-Space",
"pietroorlandi/First_agent_template",
"shenyunhang/VITA-Audio",
"kingarnica/Qwen3-Demo",
"drecokie/dre",
"Greff3/ChatVision",
"devprosvn/CVHay",
"zhaozengxi/Qwen3-Demo",
"audioer/LLM_demo_docker",
"heboya8/Qwen3-Demo",
"lkAHSreh/s",
"gowribharat/Qwen-Qwen3-30B-A3B",
"NLP-tech-103/LogAnalyzer",
"kebeliu/KVCacheSizeCalculator",
"mahi0412/Smart_phone_finder",
"dw2026/VITA-Audio",
"eugenepiggy/Qwen3-Demo",
"Agents-MCP-Hackathon/mcp-data-analyst",
"mukaist/Qwen3-Demo",
"Ephemeral182/PosterCraft",
"Agents-MCP-Hackathon/ad-guardian",
"jhansss/SingingSDS",
"Phuong-Nguyen123/Final_Assignment_Template",
"zhaozengxi/Qwen3-Demo2",
"zhaozengxi/Qwen3-Demo3",
"sizzlebop/ZeroGPU-LLM-Inference",
"Kingali01/Qwen-Qwen3-8B",
"multimodalart/self-forcing",
"rcp-the-chess-guru/audio_transcription",
"itsblxde/nay",
"tsi-org/pixio-video-stream",
"pierreguillou/llm_models_configuration",
"simonnsanita/browseruseapiv2",
"bunnytaidai/video-subtitle-remover",
"cpuai/wan2-1-video-generation",
"tuanhqv123/final_agent_course",
"freddyaboulton/self-forcing-private",
"Pawan2605/Career_Chat_Agent",
"ThaboMarvin/Sentiment-Analyzer",
"ReallyFloppyPenguin/AICodepen",
"nihar-sarkar/Qwen3-chat",
"iyedjb/self-forcing",
"alexeyGod/qwen3",
"raymerjacque/sf",
"mrbeast4/test",
"wynai/Wan-AI-Wan2.1-T2V-1.3B",
"cwadayi/streamlit_gmt_demo",
"dalynbutler/Qwen3-Demo",
"AIRI-Institute/LLM-Microscope-WAIC",
"mkhatcha/CUA",
"lokeessshhhh/Qwen3-Demo",
"qgyd2021/llm_eval_system",
"ALSv/self-forcing",
"talhaazfar01/web-ui-interface",
"talhaazfar01/web-interface",
"Lrodriolivera/luc1-support-7B",
"omidwwer/Qwen3-Demo",
"asifHuggingFace/webui",
"asifHuggingFace/Browser_Web_UI_Automation",
"taruschirag/DynaGuard",
"FlowerCui/EamonGPT",
"xiaochuan999/my-testcase-gen",
"MudauRI/AI-sentiment-analyzer",
"vishaljoshi24/trl-4-dnd",
"MudauRI/sentiment-analyzer",
"Dilshad-geol/Qwen-Qwen3-8B",
"tomg-group-umd/DynaGuard",
"dvpearl/REFRAME",
"binary1ne/web-ui",
"Lrodriolivera/luc1-train-dash-qwen3-8b",
"anhbilong/Qwen-Qwen3-8B",
"op55412/Qwen3-Demo",
"rzvn/Medieval-Village-AI",
"lebushi/bookmarks",
"giangpt-212/Browser_Automation",
"yarenty/Chat_tester"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-8B/blob/main/LICENSE"
] | null | null | 8,190,735,360
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null |
No
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"multilingual"
] |
[
"Pretraining: Causal Language Modeling (CLM)",
" Multi-task finetuning"
] |
Partially disclosed: unavailable
| 3
|
683f090e77b41ac9fc98c51f
|
Qwen/Qwen3-Embedding-8B
|
Qwen
|
{
"models": [
{
"_id": "680f0c3e6eacf22a04ee1219",
"id": "Qwen/Qwen3-8B-Base"
}
],
"relation": "finetune"
}
| 379,617
| 857,931
|
False
| 2025-06-03T14:39:10Z
| 2025-07-07T09:02:21Z
|
sentence-transformers
| 317
| 14
| null |
feature-extraction
|
{"parameters": {"BF16": 7567295488}, "total": 7567295488}
|
[
".gitattributes",
"1_Pooling/config.json",
"LICENSE",
"README.md",
"config.json",
"config_sentence_transformers.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modules.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
313,
11343,
17253,
729,
215,
117,
1671853,
4900037024,
4915959512,
4983067656,
335570376,
30432,
349,
11422947,
7256,
2776833
] | 15,150,575,778
|
1d8ad4ca9b3dd8059ad90a75d4983776a23d44af
|
[
"sentence-transformers",
"safetensors",
"qwen3",
"text-generation",
"transformers",
"sentence-similarity",
"feature-extraction",
"text-embeddings-inference",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:finetune:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"miiann/miian-Q3",
"VitaliyPolovyyEN/rag-embedding-tester",
"afouda/Wisal_QA",
"ipepe/nomic-embeddings",
"Compumacy/wisalQA_P1",
"lupinlapin/Qwen-Qwen3-Embedding-8B"
] |
[
"apache-2.0"
] | null | null | 7,567,295,488
| null |
[
"sentence-similarity",
"text-generation",
"feature-extraction"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"multimodal",
"text"
] |
[
"text"
] |
[
"embeddings",
"logits",
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68824c2337a7b37f90914ed8
|
Wan-AI/Wan2.2-T2V-A14B
|
Wan-AI
| null | 12,932
| 17,324
|
False
| 2025-07-24T15:07:15Z
| 2025-08-07T09:43:34Z
|
wan2.2
| 257
| 14
| null |
text-to-video
| null |
[
".gitattributes",
"README.md",
"Wan2.1_VAE.pth",
"assets/comp_effic.png",
"assets/logo.png",
"assets/moe_2.png",
"assets/moe_arch.png",
"assets/performance.png",
"assets/vae.png",
"configuration.json",
"google/umt5-xxl/special_tokens_map.json",
"google/umt5-xxl/spiece.model",
"google/umt5-xxl/tokenizer.json",
"google/umt5-xxl/tokenizer_config.json",
"high_noise_model/config.json",
"high_noise_model/diffusion_pytorch_model-00001-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00002-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00003-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00004-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00005-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model-00006-of-00006.safetensors",
"high_noise_model/diffusion_pytorch_model.safetensors.index.json",
"low_noise_model/config.json",
"low_noise_model/diffusion_pytorch_model-00001-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00002-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00003-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00004-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00005-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model-00006-of-00006.safetensors",
"low_noise_model/diffusion_pytorch_model.safetensors.index.json",
"models_t5_umt5-xxl-enc-bf16.pth",
"nohup.out"
] |
[
1807,
17169,
507609880,
202156,
56322,
527914,
74900,
306535,
165486,
47,
6623,
4548313,
16837417,
61728,
250,
9992481544,
9943937936,
9943979184,
9839059744,
9839059744,
7595559224,
96805,
250,
9992481544,
9943937936,
9943979184,
9839059744,
9839059744,
7595559224,
96805,
11361920418,
939260
] | 126,201,624,837
|
c8c270b13ee05bfa474194ac9fb07a5868a97cea
|
[
"wan2.2",
"diffusers",
"safetensors",
"text-to-video",
"arxiv:2503.20314",
"arxiv:2309.14509",
"license:apache-2.0",
"region:us"
] | null |
# Wan2.2
<p align="center">
<img src="assets/logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.2">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Technical Report</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
<br>
-----
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
We are excited to introduce **Wan2.2**, a major upgrade to our foundational video models. With **Wan2.2**, we have focused on incorporating the following innovations:
- 👍 **Effective MoE Architecture**: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
- 👍 **Cinematic-level Aesthetics**: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
- 👍 **Complex Motion Generation**: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
- 👍 **Efficient High-Definition Hybrid TI2V**: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of **16×16×4**. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest **720P@24fps** models currently available, capable of serving both the industrial and academic sectors simultaneously.
This repository contains our T2V-A14B model, which supports generating 5s videos at both 480P and 720P resolutions. Built with a Mixture-of-Experts (MoE) architecture, it delivers outstanding video generation quality. On our new benchmark Wan-Bench 2.0, the model surpasses leading commercial models across most key evaluation dimensions.
## Video Demos
<div align="center">
<video width="80%" controls>
<source src="https://cloud.video.taobao.com/vod/4szTT1B0LqXvJzmuEURfGRA-nllnqN_G2AT0ZWkQXoQ.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
</div>
## 🔥 Latest News!!
* Jul 28, 2025: 👋 We've released the inference code and model weights of **Wan2.2**.
## Community Works
If your research or project builds upon [**Wan2.1**](https://github.com/Wan-Video/Wan2.1) or Wan2.2, we welcome you to share it with us so we can highlight it for the broader community.
## 📑 Todo List
- Wan2.2 Text-to-Video
- [x] Multi-GPU Inference code of the A14B and 14B models
- [x] Checkpoints of the A14B and 14B models
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Image-to-Video
- [x] Multi-GPU Inference code of the A14B model
- [x] Checkpoints of the A14B model
- [x] ComfyUI integration
- [x] Diffusers integration
- Wan2.2 Text-Image-to-Video
- [x] Multi-GPU Inference code of the 5B model
- [x] Checkpoints of the 5B model
- [x] ComfyUI integration
- [x] Diffusers integration
## Run Wan2.2
#### Installation
Clone the repo:
```sh
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
```
Install dependencies:
```sh
# Ensure torch >= 2.4.0
pip install -r requirements.txt
```
#### Model Download
| Models | Download Links | Description |
|--------------------|---------------------------------------------------------------------------------------------------------------------------------------------|-------------|
| T2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Text-to-Video MoE model, supports 480P & 720P |
| I2V-A14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Image-to-Video MoE model, supports 480P & 720P |
| TI2V-5B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) 🤖 [ModelScope](https://modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | High-compression VAE, T2V+I2V, supports 720P |
> 💡Note:
> The TI2V-5B model supports 720P video generation at **24 FPS**.
Download models using huggingface-cli:
``` sh
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
```
Download models using modelscope-cli:
``` sh
pip install modelscope
modelscope download Wan-AI/Wan2.2-T2V-A14B --local_dir ./Wan2.2-T2V-A14B
```
#### Run Text-to-Video Generation
This repository supports the `Wan2.2-T2V-A14B` Text-to-Video model and can simultaneously support video generation at 480P and 720P resolutions.
##### (1) Without Prompt Extension
To facilitate implementation, we will start with a basic version of the inference process that skips the [prompt extension](#2-using-prompt-extention) step.
- Single-GPU inference
``` sh
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
```
> 💡 This command can run on a GPU with at least 80GB VRAM.
> 💡If you encounter OOM (Out-of-Memory) issues, you can use the `--offload_model True`, `--convert_model_dtype` and `--t5_cpu` options to reduce GPU memory usage.
- Multi-GPU inference using FSDP + DeepSpeed Ulysses
We use [PyTorch FSDP](https://docs.pytorch.org/docs/stable/fsdp.html) and [DeepSpeed Ulysses](https://arxiv.org/abs/2309.14509) to accelerate inference.
``` sh
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
```
##### (2) Using Prompt Extension
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
- Use the Dashscope API for extension.
- Apply for a `dashscope.api_key` in advance ([EN](https://www.alibabacloud.com/help/en/model-studio/getting-started/first-api-call-to-qwen) | [CN](https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen)).
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c63.p38356.0.i1).
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
```sh
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh'
```
- Using a local model for extension.
- By default, the Qwen model on HuggingFace is used for this extension. Users can choose Qwen models or other models based on the available GPU memory size.
- For text-to-video tasks, you can use models like `Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen2.5-7B-Instruct` and `Qwen/Qwen2.5-3B-Instruct`.
- For image-to-video tasks, you can use models like `Qwen/Qwen2.5-VL-7B-Instruct` and `Qwen/Qwen2.5-VL-3B-Instruct`.
- Larger models generally provide better extension results but require more GPU memory.
- You can modify the model used for extension with the parameter `--prompt_extend_model` , allowing you to specify either a local model path or a Hugging Face model. For example:
``` sh
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'zh'
```
## Computational Efficiency on Different GPUs
We test the computational efficiency of different **Wan2.2** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
<div align="center">
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
</div>
> The parameter settings for the tests presented in this table are as follows:
> (1) Multi-GPU: 14B: `--ulysses_size 4/8 --dit_fsdp --t5_fsdp`, 5B: `--ulysses_size 4/8 --offload_model True --convert_model_dtype --t5_cpu`; Single-GPU: 14B: `--offload_model True --convert_model_dtype`, 5B: `--offload_model True --convert_model_dtype --t5_cpu`
(--convert_model_dtype converts model parameter types to config.param_dtype);
> (2) The distributed testing utilizes the built-in FSDP and Ulysses implementations, with FlashAttention3 deployed on Hopper architecture GPUs;
> (3) Tests were run without the `--use_prompt_extend` flag;
> (4) Reported results are the average of multiple samples taken after the warm-up phase.
-------
## Introduction of Wan2.2
**Wan2.2** builds on the foundation of Wan2.1 with notable improvements in generation quality and model capability. This upgrade is driven by a series of key technical innovations, mainly including the Mixture-of-Experts (MoE) architecture, upgraded training data, and high-compression video generation.
##### (1) Mixture-of-Experts (MoE) Architecture
Wan2.2 introduces Mixture-of-Experts (MoE) architecture into the video generation diffusion model. MoE has been widely validated in large language models as an efficient approach to increase total model parameters while keeping inference cost nearly unchanged. In Wan2.2, the A14B model series adopts a two-expert design tailored to the denoising process of diffusion models: a high-noise expert for the early stages, focusing on overall layout; and a low-noise expert for the later stages, refining video details. Each expert model has about 14B parameters, resulting in a total of 27B parameters but only 14B active parameters per step, keeping inference computation and GPU memory nearly unchanged.
<div align="center">
<img src="assets/moe_arch.png" alt="" style="width: 90%;" />
</div>
The transition point between the two experts is determined by the signal-to-noise ratio (SNR), a metric that decreases monotonically as the denoising step $t$ increases. At the beginning of the denoising process, $t$ is large and the noise level is high, so the SNR is at its minimum, denoted as ${SNR}_{min}$. In this stage, the high-noise expert is activated. We define a threshold step ${t}_{moe}$ corresponding to half of the ${SNR}_{min}$, and switch to the low-noise expert when $t<{t}_{moe}$.
<div align="center">
<img src="assets/moe_2.png" alt="" style="width: 90%;" />
</div>
To validate the effectiveness of the MoE architecture, four settings are compared based on their validation loss curves. The baseline **Wan2.1** model does not employ the MoE architecture. Among the MoE-based variants, the **Wan2.1 & High-Noise Expert** reuses the Wan2.1 model as the low-noise expert while uses the Wan2.2's high-noise expert, while the **Wan2.1 & Low-Noise Expert** uses Wan2.1 as the high-noise expert and employ the Wan2.2's low-noise expert. The **Wan2.2 (MoE)** (our final version) achieves the lowest validation loss, indicating that its generated video distribution is closest to ground-truth and exhibits superior convergence.
##### (2) Efficient High-Definition Hybrid TI2V
To enable more efficient deployment, Wan2.2 also explores a high-compression design. In addition to the 27B MoE models, a 5B dense model, i.e., TI2V-5B, is released. It is supported by a high-compression Wan2.2-VAE, which achieves a $T\times H\times W$ compression ratio of $4\times16\times16$, increasing the overall compression rate to 64 while maintaining high-quality video reconstruction. With an additional patchification layer, the total compression ratio of TI2V-5B reaches $4\times32\times32$. Without specific optimization, TI2V-5B can generate a 5-second 720P video in under 9 minutes on a single consumer-grade GPU, ranking among the fastest 720P@24fps video generation models. This model also natively supports both text-to-video and image-to-video tasks within a single unified framework, covering both academic research and practical applications.
<div align="center">
<img src="assets/vae.png" alt="" style="width: 80%;" />
</div>
##### Comparisons to SOTAs
We compared Wan2.2 with leading closed-source commercial models on our new Wan-Bench 2.0, evaluating performance across multiple crucial dimensions. The results demonstrate that Wan2.2 achieves superior performance compared to these leading models.
<div align="center">
<img src="assets/performance.png" alt="" style="width: 90%;" />
</div>
## Citation
If you find our work helpful, please cite us.
```
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}
```
## License Agreement
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
## Acknowledgements
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
## Contact Us
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
[
"wavespeed/wan2.2",
"Nymbo/Tools",
"nazdridoy/inferoxy-hub",
"aryansrk/Wan-AI-Wan2.2-T2V-A14B",
"jasveer/Wan-AI-Wan2.2-T2V-A14B",
"hossein008/Wan-AI-Wan2.2-T2V-A14B",
"tsh7676/Wan-AI-Wan2.2-T2V-A14B",
"qiiirik/Wan-AI-Wan2.2-T2V-A14B",
"gageyoy/Wan-AI-Wan2.2-T2V-A14B",
"luisagudobelloso/Wan-AI-Wan2.2-T2V-A14B",
"devanshskibidi/Wan-AI-Wan2.2-T2V-A14B",
"mokodana/Wan-AI-Wan2.2-T2V-A14B-Unlimited",
"khushgehlot/Wan-AI-Wan2.2-T2V-A14B",
"crocodie/Wan-AI-Wan2.2-T2V-A14B",
"AlejoBecker/Wan-AI-Wan2.2-T2V-A14B",
"Formandl/Wan-AI-Wan2.2-T2V-A14B",
"zapak34/Wan-AI-Wan2.2-T2V-A14B",
"Shamik007/n8n_automation",
"meinefedern/Wan-AI-Wan2.2-T2V-A14B",
"ApexGamerTV/Wan-AI-Wan2.2-T2V-A14B",
"Anikul69/Wan-AI-Wan2.2-T2V-A14B",
"optowo/Wan-AI-Wan2.2-T2V-A14B",
"Muyumba/Wan-AI-Wan2.2-T2V-A14B",
"Meeyzt/Wan-AI-Wan2.2-T2V-A14B",
"sammy9/Wan-AI-Wan2.2-T2V-A14B",
"mohitbaldania1/Wan-AI-Wan2.2-T2V-A14B",
"Justjacko90/Wan-AI-Wan2.2-T2V-A14B",
"MrFkry/Wan-AI-Wan2.2-T2V-A14B",
"mgbam/yeye",
"dani811/Wan-AI-Wan2.2-T2V-A14B",
"XxProudDoggoYTxX/Wan-AI-Wan2.2-T2V-A14B",
"yuanfeng168/Wan-AI-Wan2.2-T2V-A14B",
"mtxgme/Wan-AI-Wan2.2-T2V-A14B"
] |
[
"apache-2.0"
] | null | null | null | null |
[
"text-to-video"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
free
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6890aa23722f1be774c0561d
|
facebook/dinov3-vit7b16-pretrain-lvd1689m
|
facebook
| null | 26,438
| 26,438
|
manual
| 2025-08-04T12:40:03Z
| 2025-08-19T09:00:35Z
|
transformers
| 123
| 14
| null |
image-feature-extraction
|
{"parameters": {"F32": 6716035072}, "total": 6716035072}
|
[
".gitattributes",
"LICENSE.md",
"README.md",
"config.json",
"model-00001-of-00006.safetensors",
"model-00002-of-00006.safetensors",
"model-00003-of-00006.safetensors",
"model-00004-of-00006.safetensors",
"model-00005-of-00006.safetensors",
"model-00006-of-00006.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json"
] |
[
1519,
7503,
14468,
746,
4980241600,
4967510232,
4967510568,
4967543448,
4967543320,
2013860920,
48723,
585
] | 26,864,283,632
|
b80367753773648a6793235ab9c65cdbb029506f
|
[
"transformers",
"safetensors",
"dinov3_vit",
"image-feature-extraction",
"dino",
"dinov3",
"arxiv:2508.10104",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | null |
[
"manu02/DINOv3-Interactive-Patch-Cosine-Similarity",
"atalaydenknalbant/DINOv3"
] |
[
"other",
"dinov3-license",
"https://ai.meta.com/resources/models-and-libraries/dinov3-license"
] | null |
[
"en"
] | 6,716,035,072
| null |
[
"image-feature-extraction"
] | null |
[
"DINOv3ViTModel",
"dinov3_vit",
"AutoModel"
] |
[
"vision"
] |
[
"image"
] |
[
"embeddings"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68a5eba2928a3994f4327b6d
|
kurakurai/Luth-LFM2-700M
|
kurakurai
|
{
"models": [
{
"_id": "686faba392bb877b650f4f4f",
"id": "LiquidAI/LFM2-700M"
}
],
"relation": "finetune"
}
| 136
| 136
|
False
| 2025-08-20T15:37:06Z
| 2025-08-25T17:35:38Z
|
transformers
| 15
| 14
| null |
text-generation
|
{"parameters": {"BF16": 742489344}, "total": 742489344}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"media/lfm2-luth.png",
"media/logo_collab.png",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
749b5265ea8207c33d35245fafd6053283a657e9
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"liquid",
"luth",
"conversational",
"fr",
"en",
"dataset:kurakurai/luth-sft",
"base_model:LiquidAI/LFM2-700M",
"base_model:finetune:LiquidAI/LFM2-700M",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | null | null |
[
"other",
"lfm1.0",
"LICENSE"
] |
[
"kurakurai/luth-sft"
] |
[
"fr",
"en"
] | 742,489,344
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Lfm2ForCausalLM",
"lfm2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ae481e759ab009f3d12180
|
Phr00t/Chroma-Rapid-AIO
|
Phr00t
|
{
"models": [
{
"_id": "688833e80f0a1154e901f0d5",
"id": "lodestones/Chroma1-Base"
}
],
"relation": "finetune"
}
| 0
| 0
|
False
| 2025-08-26T23:49:50Z
| 2025-08-27T04:33:06Z
| null | 14
| 14
| null |
text-to-image
| null |
[
".gitattributes",
"Chroma-Rapid-AIO-v2.safetensors",
"Chroma-Rapid-AIO.safetensors",
"README.md"
] | null | null |
d7dc7bf1409518b3b7d7b516e4bfaff2e8427d6a
|
[
"imagegen",
"chroma",
"text-to-image",
"base_model:lodestones/Chroma1-Base",
"base_model:finetune:lodestones/Chroma1-Base",
"region:us"
] | null |
This is a merge of Chroma HD + Chroma Base + Accelerators + Flan T5 XXL + FluxVAE to give you everything you need to generate images quickly and easily.
I highly recommend adding "High quality, sharp details" at the end of prompts (or "High quality anime" for anime style).
Use a CFG of 1, 8 steps and euler sampler with the beta scheduler:

(image shows euler_a but I think euler/beta is better... probably)
FP8 precision.
| null | null | null | null | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
621ffdc036468d709f17434d
|
openai-community/gpt2
|
openai-community
| null | 11,236,867
| 766,397,975
|
False
| 2022-03-02T23:29:04Z
| 2024-02-19T10:57:45Z
|
transformers
| 2,917
| 13
| null |
text-generation
|
{"parameters": {"F32": 137022720}, "total": 137022720}
|
[
".gitattributes",
"64-8bits.tflite",
"64-fp16.tflite",
"64.tflite",
"README.md",
"config.json",
"flax_model.msgpack",
"generation_config.json",
"merges.txt",
"model.safetensors",
"onnx/config.json",
"onnx/decoder_model.onnx",
"onnx/decoder_model_merged.onnx",
"onnx/decoder_with_past_model.onnx",
"onnx/generation_config.json",
"onnx/merges.txt",
"onnx/special_tokens_map.json",
"onnx/tokenizer.json",
"onnx/tokenizer_config.json",
"onnx/vocab.json",
"pytorch_model.bin",
"rust_model.ot",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
445,
125162496,
248269688,
495791932,
8092,
665,
497764120,
124,
456318,
548105171,
879,
653665842,
655189339,
653672649,
119,
456318,
99,
2107653,
234,
798156,
548118077,
702517648,
497933648,
1355256,
26,
1042301
] | 5,632,417,295
|
607a30d783dfa663caf39e06633721c8d4cfcd7e
|
[
"transformers",
"pytorch",
"tf",
"jax",
"tflite",
"rust",
"onnx",
"safetensors",
"gpt2",
"text-generation",
"exbert",
"en",
"doi:10.57967/hf/0039",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# GPT-2
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
This is the **smallest** version of GPT-2, with 124M parameters.
**Related Models:** [GPT-Large](https://huggingface.co/gpt2-large), [GPT-Medium](https://huggingface.co/gpt2-medium) and [GPT-XL](https://huggingface.co/gpt2-xl)
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = TFGPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
[
"Gustavosta/MagicPrompt-Stable-Diffusion",
"fffiloni/LatentSync",
"Yntec/ToyWorld",
"sonalkum/GAMA",
"open-llm-leaderboard/blog",
"Chemically-motivated/replit-code-v1-3b-demo",
"THUdyh/Ola",
"ASLP-lab/WenetSpeech-Yue",
"optimum/llm-perf-leaderboard",
"Chris4K/text-generation-tool",
"BadToBest/EchoMimic",
"John6666/PrintingPress4",
"CISCai/gguf-editor",
"Glaciohound/LM-Steer",
"kz-transformers/kaz-llm-lb",
"agents-course/beam_search_visualizer",
"bhaskartripathi/LLM_Quantization",
"MLSpeech/CarelessWhisper-low-latency-streaming",
"OMIKALIX/OKalixAI",
"topdu/OpenOCR-UniRec-Demo",
"void-coder/text_gen",
"Sri012/Ex",
"gunship999/SexyImages",
"BigSalmon/GPT2Tokenizer",
"BigSalmon/InformalToFormal",
"Hellisotherpeople/HF-SHAP",
"NegativeSector/News_Article_Generator",
"OFA-Sys/OFA-Image_Caption",
"OFA-Sys/OFA-Visual_Grounding",
"OFA-Sys/OFA-vqa",
"akhaliq/CLIP_prefix_captioning",
"akhaliq/SummerTime",
"aliabd/SummerTime",
"aliabd/nubia",
"ansfarooq7/l4-project",
"architext/Architext_deployed",
"arijitdas123student/gpt2-demo",
"aubmindlab/Arabic-NLP",
"bipin/image2story",
"deepklarity/poster2plot",
"edemgold/generator",
"ethzanalytics/gpt2-xl-conversational",
"flax-community/GPT2-CosmosQA",
"flax-community/image-captioning",
"gagan3012/ViTGPT2",
"jason9693/KoreanHateSpeechClassifier",
"jitesh/storytelling",
"kinensake/quanquan",
"knoxcs/masked-probs",
"merve/spaces-demo",
"sohaibcs1/Image-to-Text-Summary",
"un-index/textgen6b",
"EleutherAI/magma",
"max21226/HelloWorld",
"OFA-Sys/OFA-Generic_Interface",
"zachlopez/sample_1",
"zachlopez/sample_2",
"zachlopez/sample_3",
"kmacdermid/RpgRoomGenerator",
"ecarbo/text-generator-demo",
"ericanthonymitchell/model-editing",
"ofig/live-lm-critic",
"mariamisoieva/CoherentGeneration",
"kdcckvgmhuvkzngyxh/text-gen-prob",
"azaninello/ailai",
"dragonSwing/capu-demo",
"LilyF/Generate_Text_and_Audio",
"michaelgira23/debiasing-lms",
"HarryLee/eCommerceImageCaptioning",
"abxhr/design-project",
"blewandowski/gpt2-test-subspace",
"sriramelango/Social_Classification_Public",
"Apenguintitf/test",
"sneedandfeed/seeedandtest",
"cpllab/syntaxgym",
"Axolotlily/RpgGenerator",
"Axolotlily/TextGen",
"AhmedSSabir/demo-for-Visual-Belief-Revision",
"aliabid94/GPT-Golf",
"abidlabs/GPT-Golf",
"azaninello/gpt2-general-english",
"sasha/WinoBiasCheck",
"alistairmcleay/cambridge-masters-project",
"abd-meda/test",
"AhmedSSabir/Demo-for-Gender-Score",
"AhmedSSabir/demo-for-Visual-Re-ranker",
"AhmedSSabir/Demo-for-Gender-Score-jp",
"kkawamu1/huggingface_multi_inference_rank_eval",
"codeparrot/apps_metric",
"taka-yamakoshi/tokenizer-demo",
"luisoala/trustworthy-plugin",
"yairVag/Image_Captioning",
"sarahmarciano/Image_Captioning",
"jonasmouyal/Image_Captioning",
"ICML2022/OFA",
"sasha/BiasDetection",
"kunwarsaaim/Self-Debiasing",
"jiwan-chung/esper",
"gstaff/test_space",
"yuewu/tocgen",
"Xhaheen/image_captioning_gpt2",
"BigSalmon/TestAnyGPTModel",
"ccolas/TastyPiano",
"autonomous019/image_story_generator",
"fzantalis/test",
"ThankGod/text-generation",
"fzantalis/gpt2-text-generation",
"amsterdamNLP/contrastive-pairs",
"Gustavosta/MagicPrompt-Dalle",
"anonymous8/Rapid-Textual-Adversarial-Defense",
"TeamHaltmannSusanaHWCEO/StreamlitRipperv0Diffusion",
"fzantalis/gtp2-test",
"bkhalaf/testapp",
"FahadAlam/Text-Generator",
"nichaphat/text_generation",
"AriAri22/Lab10_630510695",
"aswinkvj/image_captioning",
"datasciencedojo/Text-Generator",
"mxxtnn/Exercise",
"ronaldahmed/my_perplexity",
"hkunlp/Binder",
"Abuzariii/Text-Generation-with-GPT-2",
"ClaudioX/mg_sd_esp",
"zbellay/job-automation",
"ldenoue/sentence-scorer",
"AhmedSSabir/Demo-for-Gender-Score-AR",
"swapnalvarma/github_issues_generator",
"vs4vijay/playground",
"BigSalmon/W",
"Catmeow/Text_Generation_Fine_Tune",
"Catmeow/AI_story_writing",
"shripadbhat/Document_Question_Answering",
"jkaur215/tweetopicgenarator",
"Vested-Sigil/VanGO",
"shi-labs/Versatile-Diffusion",
"osanseviero/Versatile-Diffusion",
"j43fer/MagicPrompt-Stable-Diffusion",
"waseemkhan/image-captioning",
"MartinRages/Versatile-Diffusion",
"Wmcs91/Versatile-Diffusion",
"adherent/Bart-gen-arg",
"BoomerangGirl/MagicPrompt-Stable-Diffusion",
"teddybearxzh/Versatile-Diffusion",
"Matthew567/text_generator",
"carisackc/clinicalnote",
"yizhangliu/Text-to-Image",
"yangheng/Super-Resolution-Anime-Diffusion",
"nateraw/lavila",
"4H17Joycelyn/text_generater",
"mskov/whisper",
"johko/capdec-image-captioning",
"Narsil/hf_transfer_showcase",
"NadiaHassan/TextGeneration",
"microsoft/Promptist",
"cahya/chat-server",
"ltomczak1/post_generator",
"iricardoxd/gpt2",
"youa/gpt2",
"Shmoon-Lodhi/text_generator_using_gpt2",
"dar-tau/speaking-probes",
"gstaff/MagicGen",
"shengzi/Text-Generation-with-GPT-2",
"hyuan5040/image-captioning",
"HighCWu/anime-colorization-with-hint",
"ElixirRod/Versatile-Diffusion",
"TRaw/digital-alchemy",
"Ali36Ahmad/MagicPrompt-Stable-Diffusion",
"pngwn/Stable-Diffusion-prompt-generator",
"pngwn/huguru",
"ajcdp/GPT2-Text-Generation",
"Hello-SimpleAI/chatgpt-detector-ling",
"dromerosm/gpt-info-extraction",
"mrm8488/tokenizer-comparator",
"Nonameismyname/PromptOptimizer",
"MajinBog/Promptist",
"markski/reddit-roast-me",
"jacobda/AQ",
"saim074/perplexity_enfrde",
"robjm16/domain_specific_ChatGPT",
"adrien1/test1",
"aichina/MagicPrompt-Stable-Diffusion",
"rjiang12/anima_task_0_gradio",
"rjiang12/anima_task_0_streamlit",
"anonauthors/SecretLanguage",
"noteldar/test_text_app",
"trysem/visua",
"pepereeee/aiartnik",
"unilm/Promptist-faster",
"sineglossa/ailai",
"BenjaminB/skops-model-card-creator",
"phenomenon1981/MagicPrompt-Stable-Diffusion",
"bachiembmt/HA",
"ussarata/storygen",
"seawolf2357/multi_test",
"timaaos2/gpt2",
"Shad0ws/Information_Extraction_with_ChatGPT",
"cnstvariable/med_bot",
"alphahg/academic-paper-translate-summary",
"abcde1234www/chat-gpt-y",
"beyondpremiere/BERTAI",
"Daniton/MagicPrompt-Stable-Diffusion",
"BenjaminB/skops-model-card-creator2",
"oliveiracwb/MBP",
"yonikremer/grouped-sampling-demo",
"imseldrith/AI-Content-Detector",
"imseldrith/ChatGPT-Detection",
"alisrbdni/MagicPrompt-Stable-Diffusion",
"NPG/GPT-2_Instruct",
"trysem/Architext",
"Nexxt/MagicPrompt-Stable-Diffusion",
"imseldrith/AI-Rewriter",
"seawolf2357/sd-prompt-gen",
"Kaludi/Stable-Diffusion-Prompt-Generator_App",
"yuan2023/Stable-Diffusion-Prompt-Generator_App",
"JeffJing/ZookChatBot",
"maxisz254/max-gpt2",
"Guinnessgshep/AI_story_writing",
"procrastinya/test_space",
"suryabbrj/image_captioner",
"Dao3/MagicPrompt-Stable-Diffusion",
"skar0/shakespeare-demo",
"wldmr/deeppunct-gr",
"society-ethics/model-card-regulatory-check",
"Alex-23/gtp2-gloumis",
"B-patents/patent-bert",
"ajayathitya/katefarms-gpt3-bot",
"Corianas/RamblingGPT",
"king007/Stable-Diffusion-Promptist",
"omkarb09/gpt2_sentiment",
"suryabbrj/ContentModX",
"Armored-Atom/DiFuse_Your_Thoughts",
"wtconron1/SentimentAnalyis_BC_CIS_435",
"JunchuanYu/Tools",
"ntcwai/prompt-engine",
"magic3910/badwords",
"NeoConsulting/Jarvis_QuAn_v02",
"wldmr/lexrank-gr",
"neo2021/Jarvis_QuAn_v03",
"awacke1/Text-generation",
"awacke1/Creative-Potential-Music-Art-Lit",
"hhalim/streamlit_ChatGPT_Peer",
"jbraun19/daredevil-text-generation",
"jpoptum/Daredevil-Text_generation",
"Mahathi/Daredevil-Text-Generation",
"jcrone2/Daredevil",
"northin/clean-code-qa",
"mhabegger/ebu-gpt-qa",
"kelvinleong/Kt_Demo_Text-Generation",
"HURUAI/aidoctor",
"guidel/OFA-Generic_Interface",
"younker/chatgpt-turbo",
"HamidBekam/Test_DeployingHFMs_Grdio_TextGeneration",
"hugging-fellows/capdec-image-captioning",
"suryabbrj/vit-gpt-caption-model-CMX",
"dromerosm/chatgpt-info-extraction",
"rcajegas/WHO_1",
"ashhadahsan/ai-book-generator",
"son9john/YENAYA",
"coolguys69420/HubermanPodBotskkkkrrrrtttt",
"EATHARD/chatbot",
"wangrongsheng/ChatPaper",
"Stereo0001/MagicPrompt-Stable-Diffusion",
"ai-art/MagicPrompt-Stable-Diffusion",
"Saiyajino/testing_ground",
"Ivoney/MagicPrompt-Stable-Diffusion",
"PhilHolst/desc",
"chengs/hackathon_chatbot_openai_api",
"Chakshu123/sketch-colorization-with-hint",
"Dao3/MagicPrompt-Stable-Diffusion_link",
"circlecircle/ChatPaper",
"amarzana/Drop_image_to_short_story",
"Dao3/dajuzi",
"Bigshot/Article-GPT",
"PushkarA07/Cover-Gen-text2img",
"PushkarA07/Cover-Gen-audio2image",
"Youssefk/StoryAI",
"PumpkinPie1533/Chatgpt2",
"lzhen/ChatPaper",
"jefftko/Stable-Diffusion-prompt-generator",
"ShiwenNi/ChatReviewer",
"diggua/MagicPrompt-Stable-Diffusion",
"amongusrickroll68/Text-To-Video-WIP",
"hetianlong/TestChatPaper2",
"Sapphire9877/ChatPaper",
"kent101/GPT_Fine_Tune",
"adwardlee/ChatReviewer",
"jumei/gptsite",
"luckyawen/MagicPrompt-Stable-Diffusion",
"zap8600/GPT-2",
"awacke1/TopTenAIGeneratedSolutionsAnyoneCouldUse",
"awacke1/StreamlitSolution-To-Your-Problem-Generator",
"sunxianfeng/gptsite",
"wagewg/gpt",
"hlby/gpt",
"ShiwenNi/ChatResponse",
"Vipitis/ShaderEval",
"solopku/ChatReviewer",
"solopku/ChatPaper",
"wbuni/ChatResponse",
"wbuni/ChatPaper",
"wbuni/ChatReviewer",
"xzxyx/AyyAsk",
"DtYXs/OFA-Visual_Grounding",
"DtYXs/OFA-vqa",
"DtYXs/OFA-Generic_Interface",
"a17/musicreview",
"kyleledbetter/responsibleGPT",
"vattyamp/askreddit",
"ferenas/ChatPaper",
"Glix/Nakahara-chan",
"wingRs/ChatPaper",
"imcaoxuan/ChatPaper",
"ronaldahmed/local_coh_ppl",
"baruga/gpt4-sandbox",
"xhwz216/MagicPrompt-Stable-Diffusion",
"mariamisoieva/TextGeneration1",
"louey233/ChatPaper",
"loldota2iii/valueDetection",
"liamugong/ChatPaper",
"Mrchuw/MagicPrompt-Stable-Diffusion",
"panda2018/ChatReviewer",
"wooxiaowei/ChatPaper",
"xskj/ChatPaper",
"GPTGone/GPTGone",
"satpalsr/gpt2test",
"covenants/gpt_next",
"xskj/ChatReviewer11",
"Liddlerain/ChatPaper_2",
"Cauchy101/ChatPaper_demo",
"wenxing/ChatPaper",
"MrLiu/ChatReviewer",
"weleen/ChatPaper",
"Aniun/ChatPaper",
"long1111/demo",
"jdczlx/ChatReviewer",
"willdas/Promptist",
"KyleTHU/ChatPaper",
"umbink/ChatPaper",
"jaylen/Chat_Response_to_reviewer",
"komleva/VQA",
"ryaalbr/QuestApp",
"CelesteChen/GPT-token",
"JJBruce/Reviewer",
"Liddlerain/ChatReviewer",
"ChanIok/ChatPaper",
"cagataydag/ImgCapt",
"PirateXX/Sentencewise-Perplexity",
"microsoft/HuggingGPT",
"keaneu/HuggingGPT",
"viscosity/HuggingGPT",
"Mcdof/HuggingGPT",
"BMukhtar/BMA",
"Shad0ws/AI_Content_PerplexityScorer",
"chrisW6825/HuggingGPT",
"Shenziqian/HuggingGPT",
"lokutus/HuggingGPT",
"ccarr0807/HuggingGPT",
"mimiqiao/HuggingGPT",
"ekinnk/demo1",
"tsgbalakarthik/HuggingGPT",
"wowochkin/HuggingGPT",
"Msp/HuggingGPT",
"jordonpeter01/dreamlike-photoreal-2.0",
"loldota2iii/ValueDetectionDemo",
"CalvinLuo/ChatPaper",
"CalvinLuo/ChatReviewer",
"cdb24/milestone-2",
"Fengguang08buaa/ChatPaper_pub",
"meteos/ChatResponse",
"CalvinLuo/ChatResponse",
"ryan12439/HuggingGPTpub",
"treadon/prompt-fungineer-355M",
"lizytalk/ChatPaper",
"FANCHIYU/HuggingGPT",
"Betacuckgpt/HuggingGPT",
"cashqin/HuggingGPT",
"yizhangliu/Grounded-Segment-Anything",
"wanghaha13/ChatPaper",
"ekarlee/Chatlee",
"felixfriday/MICROSOFTT_JARVIS_HuggingGPT",
"Meffordh/HuggingGPT",
"binhnase04854/nobita-gpt",
"lzqfree/HuggingGPT",
"bountyfuljr/HuggingGPTplaypublic",
"K1231/ChatPaper",
"mearjunsha/HuggingGPT",
"Bostoncake/ChatAssistant",
"next-social/audio_img",
"GungnirAP/Youtube-Comments",
"FanPmuk/ChatPaper",
"ADA3e21/MagicPrompt-Stable-Diffusion",
"hahahafofo/prompt_generator",
"AiPalsDev/Translate_It",
"MichellChen/Promptist",
"hahahafofo/image2text_prompt_generator",
"marve1ous/ChatPaper",
"weanalyze/analyze_url",
"lora-x/Backpack",
"turbowed/HuggingGPT",
"Chokyounghoon/HuggingGPT",
"zhangdream/ChatPaper",
"lollo21/Will-GPT",
"Pfs2021Funny/HuggingGPT",
"Adam173/seinfeld-dialogue",
"irritablebro/HuggingGPT",
"effluxriad/YouTube-comments-generator",
"MagKoz/HuggingGPT",
"zhangdream/HuggingGPT",
"lavawolfiee/memorizing_transformer_gpt2",
"calliber/HuggingGPT",
"zhiqiang00001/ChatPaper",
"theholycityweb/HuggingGPT",
"Pitak/HuggingGPT",
"gaocegege/HuggingGPT",
"ussarata/storybook",
"datagpt/url2info",
"DavidLuo/ChatPaper",
"erberry/botchatter",
"apgarmd/jarvis",
"apgarmd/jarvis2",
"h2oai/h2ogpt-chatbot",
"haonanhao/eggs-paper",
"aliabid94/AutoGPT",
"mukulnag/HuggingGPT1",
"ZENGXIAO/music",
"Kevin676/AutoGPT",
"KingMV/ChatReviewer",
"mikehanada/AutoGPT",
"Jaggi/AutoGPT",
"ewave/AutoGPT",
"lugifudun/HuggingGPT",
"leadmaister/HuggingGPT",
"pors/HuggingGPT",
"h2oai/h2ogpt-chatbot2",
"glebr/AutoGPT",
"nixiaobai/ChatPaper",
"vs4vijay/AutoGPT",
"vs4vijay/HuggingGPT",
"Tianyi0217/ChatPaper",
"lilyling/Vietnam_QA",
"lilyling/Spain",
"lachine/GPT-2-test",
"lilyling/Italiano_QA",
"lilyling/Chinese_QA",
"monad-one/Promptist",
"lfhe/ChatPaper",
"lachine/GPT-2-better",
"msmilauer/AutoGPT-duplicated2",
"mckeeboards/HuggingGPT",
"vs4vijay/h2ogpt-chatbot",
"akshaytrikha/gpt2-trump",
"ajithmadan09/AutoGPT",
"Connor22/duplication",
"MathysL/AutoGPT4",
"mastere00/JarvisMeetsProfessor",
"trhacknon/h2ogpt-chatbot",
"trhacknon/streamlit_ChatGPT_Peer",
"ChandraMohanNayal/AutoGPT",
"jieyan/ChatPaper",
"moha222/gpt2-wikipedia",
"hebherve/AutoGPT1",
"Avan/ChatPaper",
"passthebutter/HuggingGPT",
"MojoSamurai/AutoGPT",
"dromerosm/chatgpt-kyc",
"EdB1/AutoGPT",
"dreamerworks/t2gradio",
"zee2221/AutoGPT",
"szs9915/ChatPaper",
"rohan13/AutoGPT",
"manu1435/HuggingGPT",
"hebherve/AutoGPT12",
"Yuankai/ChatReviewer",
"dimitry12/AutoGPT",
"JackeyHong/ChatResponse",
"trhacknon/HuggingGPT",
"JackeyHong/ChatPaper",
"idirectork/AutoGPT",
"pbrown13/AutoGPT",
"taesiri/HuggingGPT-Lite",
"lotrlol/OFA-Image_Caption",
"duchaba/sd_prompt_helper",
"kenton-li/ChatArxiv",
"kukuhtw/AutoGPT",
"NaamanSaif/HuggingGPT",
"oriasirmi/AutoGPT",
"avivdm1/AutoGPT",
"Isaoudata/WaltWhitman-GPT",
"falcondai/stego-lm",
"acifol/AutoGPT",
"eslup/MedicalSchoolMatcher-GPT",
"Bruticus/AutoGPT",
"airvidcinematic/AutoGPT",
"lexamp/AutoGPT2",
"DiffusionArtco/advanced-prompt-gen",
"florim/MedGPT",
"DMDaudio/AutoGPT",
"CollaalloC/HuggingGPT",
"chatgpt-openai/AutoGPT",
"nateraw/jupyterlab-inference-dev",
"nateraw/text-generation-inference",
"thanh17/lip-reading",
"LokeEros/AutoGPT",
"tiger94me/ChatPaper",
"Baneefear/AutoGPT",
"Baneefear/ASSISTANT",
"Baneefear/UmbrellaGPT",
"Bitsak/AutoGPT2",
"aichimantou/ChatPaper",
"maxmax20160403/sovits5.0",
"cestbon/ChatPaper",
"czczup/ChatReviewer",
"dwolfe66/HuggingGPT",
"DB2323/nanoGPT",
"gblocher/AutoGPT2",
"fkhuggingme/ChatPaper",
"StephanMyburg/AutoGPT",
"xian-sheng/HuggingGPT",
"JohnTan38/AutoGPT",
"Jamkonams/AutoGPT",
"shunzh/apps_metric",
"Aygtljl518866/HuggingGPT",
"LolorzoloL/AutoGPT",
"johnsu6616/prompt_generator",
"DaleChen/AutoGPT",
"zioee/ChatPaper",
"AnmolManocha/GPT4Tools",
"TeamMlx/MagicPrompt-Stable-Diffusion",
"liyucheng/selective_context",
"Littlehongman/CLIPGPT-ImageCaptioner",
"3gg/isa",
"lhoy/ChatPaper",
"appy-agency/sprigs",
"hosseinxj0152/AutoGPT",
"PegaMichael/test-gpt-2",
"YoungLuis/ChatResponse",
"ramiin2/AutoGPT",
"Liven-Zhang/ChatPaper_2",
"lukesteuber/textual",
"mateenmalik/ethicalbot-tf",
"YoungLuis/ChatReviewer",
"zzzzxx/ChatPaper",
"zzzzxx/5656ChatPaper",
"zzzzxx/56565",
"zzzzxx/202014819zzx",
"tianyigao/ChatPaper",
"Lamai/LAMAIGPT",
"liuge2811/ChatReviewer",
"Hemi1403/HuggingGPT",
"asach/openai-meeting",
"Vageesh1/clip_gpt2",
"Chakshu123/image-colorization-with-hint",
"holly123/codeparrot-test",
"johnsu6616/SD_Helper_01",
"Vito99/HuggingGPT-Lite",
"rubberboy/MagicPrompt-Stable-Diffusion",
"ekinnk/gpt2_demo",
"EinfachOlder/MagicPrompt-Stable-Diffusion",
"bsjghee001/Refineverse_Plugin_testing",
"EinfachOlder/HuggingGPT-Lite",
"zhenyus/ChatReviewer",
"aliabid94/gloopp-glop",
"next-social/dodo12",
"Hslavinsky/AutoGPT",
"exbert-project/exbert",
"Lleetllama/MomBot-gradio",
"HalcyonAegisLLC/HalcyonAsk",
"kcagle/AutoGPT",
"akole808/ChatPaper",
"deasdutta/Ona-chat",
"Alfasign/HuggingGPT-Lite",
"zzzzxx/56565656565",
"Xinyoumeng233hu/SteganographywithGPT-2",
"bsjghee001/oldbackup",
"Vito99/AutoGPT1",
"SeViLA/SeViLA",
"Yuanling/ChatPaper",
"innovativeillusions/HuggingGPT",
"mzltest/OFA-Image_Caption",
"Wikiforwind/ChatPaper",
"KKMobile/MagicPrompt-Stable-Diffusion",
"bsjghee001/Refineverse_Plugin_backup",
"koajoel/PolyFormer",
"AjManoj/mpt-7b-chat",
"Writer/token-counter",
"aliabid94/abcdef",
"aliabid94/qwerty",
"aliabid94/no_nothing",
"aliabid94/ppp_p",
"YYG1787812757/ChatReviewer",
"rfrossard/mpt-7b-chat",
"xhy/Quantum-based-PaperRead",
"crazyjetsai/finetuneai",
"itsamejms/my-first-space",
"paulogpd/gpt-training-model",
"zeno-ml/chatbot-report",
"aliabid94/GOLF",
"FYP-23-S1-21/Refineverse_Plugin",
"S1-21/Refineverse_Plugin_2",
"bsjghee001/Refineverse_Plugin_2",
"HHANAA/Stable-Diffusion-prompt-generator",
"coding-alt/AutoGPT",
"vvitcheff/text-generation",
"cn3113645/AutoGPT",
"czovoa/ChatPaper",
"Arthios/AutoGPT",
"kusumakar/image_to_context_and_context_to_paragraph",
"posix4e/AutoGPT",
"Lllama0005/test",
"chensh911/paper-summarize",
"louisedrumm/BOE",
"jeremynotfound/ChatReviewer",
"wenjunchen/ChatResponse",
"egosumkira/GPT2-Fantasy",
"naman7415963/summarization",
"ankush29/CheckGPT",
"tracinginsights/mpt-7b-chat",
"jx-yang/deep-thinking",
"bhavyapandya/Summarization",
"Saba99/SabaAutoGPT",
"alexkueck/ChatBotLI2Klein",
"melonking/ScienceModel",
"0xAnders/test001",
"Vageesh1/Caption-Hashtag-Generator",
"mnauf/redditGPT",
"vs4vijay/ChatStudio",
"kkhan/iba_faq_chat",
"YLX1965/ChatPaper",
"harley001/ChatReviewer",
"stanfordnlp/Backpack-Demo",
"dennis1940/AutoGPT",
"FrankZxShen/so-vits-svc-models-pcr",
"aliabid94/gpttag",
"replyxf/textgen",
"aliabid94/golfy2",
"popeking/AutoGPT",
"childolt/AutoGPT",
"liudd/ChatPaper",
"iamkyle/ChatPaper_public",
"snowwolf725/LiYongLe_SoVits",
"astroarya/Youtube_Script_Generator",
"MetaWabbit/Auto-GPT",
"wldmr/transcriptifier-st-hf7",
"saurshaz/HuggingGPT",
"ttphong68/code_5.11",
"ttphong68/code_5.12",
"ttphong68/code_5.13",
"ttphong68/code_5.14",
"ttphong68/code_5.15",
"ttphong68/code_5.16",
"ttphong68/code_5.17",
"ttphong68/code_5.18",
"wissen/ChatPaper",
"DexterSptizu/sentence_completion",
"jixingwu/ChatResponse",
"hlydecker/Augmented-Retrieval-qa-ChatGPT",
"dengkane/gpt2",
"1line/AutoGPT",
"kbora/minerva-generate-docker",
"SIH/Augmented-Retrieval-qa-ChatGPT",
"vivekkumarbarman/sentence_completion",
"naman4jain/sentence_completion_using_GPT2_and_Gradio",
"anshu-man853/sentence_completion",
"Adit712/Sentence_Completion",
"rkaundinya/beamsearchexploration",
"yxchng/elia",
"lijiazhe/testtestljz",
"lijiazhe/123",
"chrishanna/AutoGPT",
"sharpbai/text_generation",
"cybertrapped/text_generation",
"Silence1412/Stable_Diffusion_Cpu",
"semaj83/ctmatch",
"hamza50/maven-5",
"thundercade/maven-5",
"amitjainmldesign/maven-5",
"datasistah/maven-5",
"brichett/maven-mlsd",
"vsukhoy/maven-5",
"ankitpoonia/maven-5",
"caldervf/maven-5",
"ramd/Maven10july",
"Sukesh/maven_5",
"darshil3011/test",
"priyaradhakrishnan/MLSysDes_assignment",
"aarontyliu/maven-5",
"mqha/tryGPT2",
"Yntec/PrintingPress",
"elderman/ChatPaper",
"RitaParadaRamos/SmallCapDemo",
"pribadihcr/quGPT",
"Wetiqe/ChatPaper",
"prlabs2023/text-completion-1",
"AlphaGPT/PaperSummary",
"amitjainmldesign/amitapp",
"mikoxi/ChatPaper",
"fuckyoudeki/AutoGPT",
"Alfasign/Einfach.Stable_DiffPomrpter",
"daeron/CONVS2S-EVJVQA-DEMO",
"ttran51/maven-50",
"ylavie/HuggingGPT3",
"ylavie/HuggingGPT-Lite",
"Betacuckgpt/AutoGPT",
"Betacuckgpt/AutoGPT123",
"myclassunil/AutoGPT",
"biranchi125/gpt2_experiment",
"Yntec/blitz_diffusion",
"nazzysweet/AutoGPT",
"zurdoo/gpt-info-extraction",
"tianjiangyou/Prompt",
"FrankZxShen/so-vits-svc-models-ba",
"zjq12333/ChatPaper",
"rjiang12/bias-test-gpt",
"elitecode/h2ogpt-chatbot2",
"Guoyccc/ChatReviewer",
"Guoyccc/ChatResponse",
"AryanDhiman/sentence_completion",
"bacelar/ciata-v1",
"Scany/GPT2",
"Jaehan/Text-Generation-1",
"Jaehan/Text-Generation-2",
"Jaehan/Text-Generation-3",
"Jaehan/Text-Generation-4",
"Emerr258/Mozbot",
"CCYAO/HuggingGPT",
"Devin-Long/ChatReviewer",
"hamelcubsfan/AutoGPT",
"rjiang12/bias-test-gpt-breadcrumbs",
"tedinvestigasi/AutoGPT",
"Wingyu/wy_space",
"omerdan03/LLM_local",
"kaaokou/stablep-diffusion-prompt",
"acclass/gpt_demo",
"AnthonyErosion/AnthonyErosion-HoctotAI",
"Coderteq/AutoGPT",
"yuaiyu/Versatile-Diffusion",
"potterbear5/AutoGPT",
"mshukor/UnIVAL",
"nalanwutuo/txt_gen",
"reihaneh-Rahmani/ML_huggingface_movie_recomm_proj",
"RohitFrancis/LEGION_TEST",
"akashkj/H2OGPT",
"dcams/HuggingGPT",
"chendl/multimodal",
"lllqqq/so-vits-svc-models-pcr",
"Yusen/So-VITS-4.1",
"ShiwenNi/ChatReviewer-2",
"rjiang12/bias-test-gpt-breadcrumbsV2",
"ScottRobertsXR/image-captioning-01",
"MrZak/Learny2.0",
"JerryFan011018/ChatReviewer",
"shilpabanerjee/Game-Wikipedia",
"iweavings/image-captioning-01",
"zw89/sd-prompt-generator",
"MicroPanda123/PythonBasic",
"Ritori/Yura_GPT",
"MicroPanda123/RustBasic",
"Alfasign/MagicDiffusion",
"peter0113/gpt2-test",
"ariel0330/h2osiri",
"Benson/text-generation",
"Tasslehawk/Stable-Diffusion-prompt-generator",
"BMQY/ChatPaper",
"MrZak/Learny3.0",
"xs98/ChatPaper",
"yangchun1987/ChatPaper",
"chaore/SD_Helper_01",
"ccoreilly/aigua-xat",
"Harshveer/Diffusion30x",
"xcoolcoinx/Auto-GPT",
"yl12053/so-vits-4.1-Special-Week",
"gsaivinay/open_llm_leaderboard",
"yl12053/so-vits-4.1-Mejiro-Mcqueen",
"yl12053/so-vits-4.1-Manhattan-Cafe",
"azusarang/so-vits-svc-models-ba_P",
"netsssss/OFA-Image_Caption",
"johnjets/grammar",
"yl12053/so-vits-4.1-Slience-Suzuka",
"TRaw/testr",
"LavanyaBurlagadda/transformers-gpt",
"yl12053/so-vits-4.1-Rice-Shower",
"scp4950/grah",
"b1sheng/kg_llm_leaderboard_test",
"TechYAN/ChatResponse",
"TechYAN/ChatReviewer",
"yl12053/so-vits-4.1-Grass-Wonder",
"yl12053/so-vits-4.1-Tokai-Teio",
"yl12053/so-vits-4.1-Seiun-Sky",
"LavanyaBurlagadda/ChatBot-OpenAI-PlayHt-Old",
"GroveStreet/GTA_SOVITS",
"suanlixianren/sovits_test",
"suanlixianren/sovits_test2",
"LavanyaBurlagadda/My-testing",
"csuvikv/gpt-2",
"daidaiyu1987/ChatReviewer",
"DHEIVER/MagicPrompt-Stable-Diffusion",
"Dorn4449/gpt-chatbot",
"faizan-shaikh/StoryGenerator",
"yl12053/so-vits-4.1-Mihono-Bourbon",
"magellan-ai/brand-classifier",
"Nymbo/AutoGPT",
"CosmoAI/ChitChat",
"PeepDaSlan9/AutoGPT",
"Arylwen/mlk8s",
"yl12053/so-vits-4.1-Curren-Chan",
"yl12053/so-vits-4.1-Kitasan-Black",
"mouaddb/OFA-Visual_Grounding",
"mouaddb/OFA",
"caiocarvalhofre/MagicPrompt-Stable-Diffusion",
"yl12053/so-vits-4.1-Gold-Ship",
"yl12053/so-vits-4.1-Satono-Diamond",
"evegarcianz/Botlitica",
"Colinmei/ChatPaper",
"Colinmei/ChatReviewer",
"knyshaleksandr6/prompt-fungineer-355M",
"sia-ai/text-generation-gen2-sample1",
"ShauryaD/Text-Generation",
"susmagus/Text_Generator",
"Hypersonic0945/GenAISample",
"hiihhiii/questionanswerplatform",
"Colinmei/AIR",
"yl12053/so-vits-4.1-Special-Week-Remake",
"alifatmi/alidemo",
"Ankoorkashyap/Sentence_Completion",
"pranavrana98/story-generator",
"insaafS/AI-Story-Gen",
"yl12053/so-vits-4.1-Daiwa-Scarlet",
"flatindo/MagicPrompt",
"cndavy/HuggingGPT",
"ysharma/dummy_m4",
"bczhou/clip-gpt2",
"DKethan/Text-Generation",
"AnirudhDaya/Daya_HR_v2",
"Seyedehsara/text-generation-webui",
"SoniR/demo-app",
"feedexpdition/gardio-patient-clinical-summary",
"Reiner4/extrasneo",
"yl12053/so-vits-4.1-Matikanetannhauser",
"yl12053/so-vits-4.1-Matikanefukukitaru",
"vasishtakuppa/EmailSubjectGeneration",
"yl12053/so-vits-4.1-Mejiro-Ardan",
"yl12053/so-vits-4.1-Nice-Nature",
"HuggingFaceM4/IDEFICS_Data_Measurement_Tool",
"lexamp/MetaGPT-GUI",
"SeamlessEMusic/So-vits-svc_Alto_soft",
"donaloc/TalkToLLM",
"SeamlessEMusic/So-vits-svc_Alto_discrete",
"fangjiajia/AAAADjj_3",
"imessien/Geriatrics_Depression_Scale_Questioniare",
"AlisterAnhedonia/extrasneo",
"Yntec/ToyWorldXL",
"Zalaruc/extrasseleo",
"TheCoolDump/MagicPrompt-Stable-Diffusion",
"pngwn/open_llm_leaderboard",
"trishv/songy",
"AnimaLab/bias-test-gpt-pairs",
"SriPravallikaB/projectexplainer",
"topstory/MagicPrompt-Stable-Diffusion",
"lingger/doctrine",
"pngwn/open_llm_leaderboard_two",
"LDJA/new2",
"Ywung/llm-webui",
"grosspaydigital/AutoGPT",
"Yntec/Image-Models-Test",
"hijaukuohno/MagicPrompt-Stable-Diffusion",
"zipingl/synthethics",
"papasega/wolof-to-french-BLOOM",
"bookmorning/MagicPrompt-Stable-Diffusion",
"TRaw/chui",
"paavansundar/my_ml_models_space",
"egub/text-generation-webui",
"menghuiguxiang/image_to_story_audio",
"DavidHuggingFace1/Model",
"jashing/Josh_RIC_GenA_Demo",
"zoebat20/BLiMP",
"jashing/JoshGenA",
"santoshaimlops/MiniProj_Jarvis",
"Nomyx/textgen-webui",
"AlexchIA/text-generation-webui",
"miittnnss/UrFriendly-Chatbot",
"mattmajestic/web3bms",
"khussairiee/H2O",
"DataAnalyticsLab/Sorvad-Dev",
"OpenMotionLab/MotionGPT",
"Ashrafb/MagicPrompt-Stable-Diffusion",
"jfeng1115/marketing-analytics-bot",
"cardioio/ChatPaper",
"fox2048/smc",
"thirdai/BOLT2.5B",
"optimum/auto-benchmark",
"rushil78/clip_gpt2",
"ahassoun/voice_clone",
"lanzhiwang/first-gradio",
"hijaukuohno/prompt-fungineer-355M",
"AnonymousSub/Ayurveda_Chatbot",
"hlydecker/RA-document-QAchat",
"SgonnikovD/Writer",
"ahassoun/voice_clone_v2",
"ahassoun/voice_clone_v3",
"ahassoun/voice_clone_v4",
"Abhiverse01/PromptEnhancer",
"olanigan/text-gen-gpt2",
"Thefrudi78/Extra",
"mozgov/so-vits-4.1-Matikanefukukitaru",
"liyaodev/so-vits-4.1-Matikanefukukitaru",
"Bhagu69/next-word-fun",
"hf-dongpyo/gpt2",
"teachyourselfcoding/chatlawv1",
"SaeedAnwar47/text_genr",
"Manmay/tortoise-tts",
"PriyaMittal/ChatBot_Final",
"Docfile/open_llm_leaderboard",
"DrSkunk570/AutoGPT",
"Ankush05/Code9",
"adr2432/lets_try",
"wissamantoun/LLM_Detection_Attribution",
"Asankilp/sovits-gochiusa-webui",
"Bhagu69/next-word-predictor",
"DeepVen/rag-test-venkat",
"Ashrafb/Promptist",
"qgyd2021/reward_model_gpt2_stack_exchange",
"ws123/optimized-text-generation",
"Rohankumar31/Prakruti_LLM",
"anon4757/BiasTestGPT",
"kushan1988/VITS-TEST",
"Shanuka01/VITS-TEST_02",
"WhaleCancer/MechanicalClerk",
"kelvin-t-lu/chatbot",
"BhanuPrakashSamoju/rag-test-venkat",
"aoxiang1221/so-vits-svc",
"ylavie/AutoGPT",
"Rohankumar31/AI-Chaperone_Chatbot",
"daniel-kim/danielkim-autonomous-agents",
"daniel-kim/daniel-kim-agents-autonomous",
"DeepVen/streamlit",
"mookkanvas/text_generation",
"roshithindia/chatBotGPT2",
"mjsp/food_classify",
"daniel-kim/d_kim_agents",
"mattmajestic/hf-supabase-chatbot",
"lm-human-preference-details/rlhf-demo",
"Anon3365/BiasTestGPT",
"LovnishVermaPRINCE/chatai",
"BhanuPrakashSamoju/streamlit",
"awakenai/fast-api-transformers-pipeline-v2",
"namemew/Promptist-by-Mircosoft",
"chendl/compositional_test",
"ZackBradshaw/omni_bot",
"SilverStarShadow/HF-SillyTavern-Extras",
"Ankush05/Test",
"DeepVen/insight",
"Achyuth4/MagicPrompt-Stable-Diffusion",
"vhpvmx/Chatbot_Comparison",
"vih-v/Stable-Diffusion-prompt-generator",
"DeepLearning101/IE101TW",
"drowdancer/extrasneo",
"duyan/test",
"AnishKumbhar/ChatBot",
"ShrapTy/text_generation",
"alonsosilva/NextTokenPrediction",
"awqwqwq/Stable-Diffusion-prompt-generator",
"TheKitten/MagicPrompt-Stable-Diffusion",
"moin1234/XAGPT1",
"Pranjal12345/Text_to_Speech",
"sujanchaw/demochatbot",
"alonsosilva/perplexity",
"mabzak/MagicPrompt-Stable-Diffusion-Indonesia-to-EN",
"alonsosilva/tokenizer",
"Shanuka01/tortoise-tts-v2",
"sheidelberg/gradio-blog-generation",
"projectsnightlight/tortoise-tts-working",
"fjibj/MotionGPT",
"TNK21/Story_Generator",
"Abhaykoul/Prompt_generator_for_helpingAI-tti",
"pol9886/extrasneo",
"pol9886/extrasneo2",
"navpreetnp/ERA-S21",
"lfoppiano/document-qa",
"WhaleCancer/Tortoise",
"StanislavMichalov/Stable-Diffusion-prompt-generator",
"StiveDudov/Stable-Diffusion-prompt-generator",
"ElenaVasileva/Stable-Diffusion-prompt-generator",
"geetherb/LiPT",
"ZingyZa/tortoise-tts-test",
"atrost/local_perplexity",
"zamasam/extrasneo",
"garima-mahato/ShakespearesWeirdTales",
"Yugang998/Grounded-Segment-Anything",
"mjsp/classifys_food",
"JanmejayM46/food_classify",
"JanmejayM46/classify_f",
"aishuya/sweet_classifying",
"QuanLingZ/ChatReviewer",
"Shanuka01/Accent_changer",
"Shanuka01/Accent_changer_test_02",
"anantgupta129/nanogpt",
"liuhaozhe6788/CelebChat",
"RashiAgarwal/NanoGPT_charToken",
"gupta1912/nanoshakespeareS21_ERA",
"LN1996/S21_ChatGPT_from_scratch",
"geekocean/ChatReviewer",
"ZeroTwo3/MagicPrompt-Stable-Diffusion",
"his0/h2ogpt-chatbot",
"Pranjal12345/Text_to_Speech22",
"piyushgrover/NanoGPT",
"VTechAI/Segment-Anything",
"atimughal662/InfoFusion",
"Gosula/Nano_gpt_Shakespeare_data",
"Mikki01/Prompt-generator",
"waredot32189/MagicPrompt-Stable-Diffusion",
"mohan32189/MagicPrompt-Stable-Diffusion",
"abdurahimanoffc/kmbr_law_assistant",
"cpt-subtext/learngradio",
"MadhurGarg/NanoGPT_charToken",
"sujitojha/nanoGPT",
"Omnibus/MagicPrompt-Stable-Diffusion_link",
"luis112/text-generation-webui",
"sms07/Georgios-Ioannou-Visual-Question-Answering-With-Hugging-Face",
"NISHANTH7/brandstoryvideo",
"QuanLingZ/ChatResponse",
"drdata/MagicPrompt-Stable-Diffusion-2",
"cy0000/ChatPaper",
"ppgawande/image-creation",
"W404NET/My-Chat",
"alonsosilva/gpt2",
"sms07/Georgios-Ioannou-Visual-Question-Answering-With-Hugging-Face-FINAL",
"lampongyuen/Gradio-text-generation",
"felixz/open_llm_leaderboard",
"CS50/Chat-Bot",
"simon-clmtd/exbert",
"MarwanAshraf22/TRIAL",
"PeepDaSlan9/Book-Analyzer",
"Sambhavnoobcoder/h2ogpt-chatbot",
"Giorgos96/gpt2-text-generation",
"Joe99/ChatFinance",
"GroveStreet/GTAVC_SOVITS",
"franmacias/tts",
"chaore/prompt_generator",
"rajpateirya/GeneratevieAIDetector",
"wldmr/transcriptifier-st-hf8",
"yjy7777/mfe",
"awacke1/MagicPrompt-Stable-Diffusion",
"drdata/MagicPrompt-Stable-Diffusion-3",
"MattGPT/ClassUI",
"lingbionlp/PhenoTagger_CL",
"Tonic1/Xgen",
"MBZUAI/artst-tts-demo",
"TeamTonic/Tulu",
"SarProgrammer/ChatReviewer-2",
"svjack/MagicPrompt-Stable-Diffusion",
"Hank528286709/tb",
"Ashrafb/MagicPrompt-Stable-Diffusiongust",
"miron258/text-generation-tool-duplicate",
"wwxing/ChatReviewer",
"pencilsout/Manmay-tortoise-tts",
"homeway/PromptCARE",
"yufistudio/Gpt2-EasyGen",
"shalinialisha/ai-for-all",
"BBrother/MagicPrompt-Stable-Diffusion",
"Hank528286709/ad",
"henrii1/Text_summarization",
"Rendernet/prompt-generator",
"solo7917/extrasneo1",
"nanankawa/extrasneo-CodeSandBox",
"evanwoods/AutoGPT",
"awqwqwq/SD-prompt-generator",
"jihaitang/extrasneo11",
"markqiu/text-generation-webui",
"smothiki/open_llm_leaderboard",
"jihaitang/extrasneo111",
"jihaitang/extrasneo4399",
"jihaitang/SillyTavern-Extras1",
"jordonpeter01/prompt",
"GH111/wonderlore",
"GH111/wn",
"MasonCrinr/MySpace",
"zewqds/ChatPaper",
"jordonpeter01/test3",
"azizalto/gpt-cost-estimator",
"macqo21/AutoGPT",
"mdevora/sherlock",
"MasonCrinr/Tortoise",
"MasonCrinr/TortoiseTTS",
"Kedreamix/ChatPaperFree",
"ksee/scamgptj-eval",
"guysalton/gpt2",
"neuroama/so-vits-svc-models-baa",
"mdevora/inggrim",
"Faizzyhon/Chatbot_IUB",
"blaketm/text-generation-webui",
"xynull/mistral-7b-docker",
"Writo/TailorAI",
"PiyushJha/img2text",
"neuroama/so-vits-svc",
"forestcalled/text-generation-webui",
"ToniTi/demo",
"Edsonlp1/MotrilTesting",
"neuroama/sovits5.0",
"elderman/ChatReviewer",
"Writo/story",
"grepLeigh/perplexity",
"Museyib/My_Project",
"banana-projects/transformer-autocomplete",
"yhavinga/dutch-tokenizer-arena",
"xzuyn/Token-Count-Comparison",
"AsadullaH777/HuggingGPT",
"llizhx/TinyGPT-V",
"SoSa123456/Radio4",
"HL-Gao/test",
"siewcode/gpt2-test",
"vishnumg/RAG-Motor",
"Epill/tortoise-tts",
"algowizmomo/RAG-Motor",
"dreamdrop-art/000555111",
"Trace2333/EasyPrompt",
"Kosuke-mnt/motiongpt",
"Faizan15/gptike",
"mjsp/recipe",
"MrBoltik/MrBoltik-mishok1",
"BruiserBro/ai_chatbot_email_subject_generator",
"xynull/test3",
"rayan74123/FightAddiction",
"EbubeJohnEnyi/ChatBot_AI",
"Yntec/Image-Models-Test-2024",
"LLMChess/Chess_LLM_Space_2",
"NLPark/convert-to-gguf",
"enriquegr/egrbot",
"cyberbuddies/cyberbuddies_AI",
"ALOQAS/aloqas-gradio",
"kaitkuroba/SillyTavern-Extras11",
"ming512/llm",
"clinitex/Gepete",
"aisafe/SCA",
"amaljoseami/test",
"hadidev/webui",
"iblfe/test",
"jialinsong/apps_metric",
"jeevana/jeevana-GenerativeQnASystem_Gradio",
"Rajut/Normandy_QA_2",
"jeevana/jeevana-EmailSubjectLineGeneration_Gradio",
"BeveledCube/bevelapi",
"Neu256/text-generation-webui",
"ananyagupta25/initialTask",
"ananyagupta25/gradioInitialTask",
"ananyagupta25/splitInitialTask",
"sandhyac/subject_line_generation",
"BlackBlur/so-vits-svc-models-pcr",
"meenalchonde/Chatbot",
"meenalchonde/Bot",
"meenalchonde/Llama-2",
"immanuelzhu/prompt_generator",
"ehristoforu/Rensor",
"KevinMelchert/Chat",
"phiskim/oobabooga_chris",
"BAAI/open_cn_llm_leaderboard",
"AU-VN-ResearchGroup/whisper_demo_docker",
"gsarti/pecore",
"abdullahmeda/detect-ai-text",
"Charles95/gradio-tasks",
"yugamj/Finance_chatbot",
"ali121300/GPT1",
"AbhiPemmaraju/subject_gen",
"mindmime/gradio",
"Jaglinux/text-generation-gpt2",
"DScience18/ai_chatbot_email_subject_generator",
"SurajSingh/gpt2_email_generation",
"Zulelee/langchain-chatchat",
"aka4akash/the_48_laws_of_power",
"VTechAI/Chat",
"ypat/AutoGPT",
"arthuqa/helporio",
"zjunlp/EasyEdit",
"TechAudio/audiosr",
"chanhen/echo-chatbot",
"mohd43/gpt2",
"LiuZiyi/5-mlBasics-gradio-gradioBlocks-transformers",
"shapermindai/SinGPTUltimate",
"shaynanigans/my_repo",
"FabioMesquita/echo-chatbot",
"sleepdeep/llm-deploy",
"Mosesgw/openai-community-gpt2",
"OnyangoF/openai-community-gpt2",
"Haysar/text-generation-webui",
"MixoMax/Ar4ikov-gpt2-650k-stable-diffusion-prompt-generator",
"NahFam13/webbyuu",
"rodrigomasini/data_only_open_llm_leaderboard",
"Verias/testing_space",
"MAsad789565/finetuninggpt2",
"MAsad789565/botdata",
"aspengreyagain/llama2",
"aspengreyagain/openai-community-gpt2",
"GTBench/GTBench",
"djrana/anything",
"hunthinn/movie_title_gpt2",
"run480/intro_to_transformers",
"rohit99/pg_capstone",
"Dagfinn1962/MagicPrompt-Stable-Diffusion2024",
"poi1258/MagicPrompt-Stable-Diffusion",
"Ck773/MagicPrompt-Stable-Diffusion",
"vkxlzk/demo-genAI",
"ToonToker/game1",
"ToonToker/text-generation-webui",
"sappho192/jesc-ja-en-translator-demo",
"fatiqa/demo-genAI-mahb",
"GeorgiosIoannouCoder/cuny-tech-prep-tutorial-4",
"musharafnasim/sentence_generation",
"Kaylb/Kaylb",
"Nikhil0987/hariom",
"djrana/AI-ART-PROMPT-CREATOR",
"alisrbdni/AutoGPT",
"Swadhin007/openai-community-gpt2",
"Kamaljp/transformers_universe",
"lapsapking/h2ogpt-chatbot",
"Nachiketkapure/Fitness_bot",
"ArpitPJain/OnlyForPMs",
"priyald/openai-community-gpt2",
"rohit99/pg_capstone_1",
"alibukhari/MotionGPT",
"magnolia-psychometrics/item-generator",
"CullerWhale/Text-Generator-clone",
"Jyothirmai/image-captioning-chest-xrays",
"rohit99/pg_capstone_2",
"Vedits/Magic-Prompt-generator",
"tgatewoo/Demo-App",
"tgatewoo/Demo-App-Streamlit",
"DataAnalyticsLab/Sorvad",
"soJaeyoon/Adventure",
"soJaeyoon/AI_novel",
"lun0tic-j/space",
"Apollo-Soyuz/NASA-Roscosmos-JAXA-ESA-CSA",
"bogdansolga/generative-ai",
"Prgckwb/tokenvisor",
"AdityaQB/gpttest",
"OPTML-Group/UnlearnCanvas-Benchmark",
"yeseo/dlaj",
"alibukhari6728/MotionGPT",
"Omnibus/Chatbot-Compare",
"psanagapati/GenAIImageRecognition",
"jubyaid123/Ai-Feedback-app",
"StKirill/GenerativeChatBot",
"selbl/LyricGeneration",
"Axoloteera/jiedi-so-vits-svc",
"Dprogrammer/tts-attemp",
"smallboxx/ChatPaper12138",
"Kvikontent/kvi-detector",
"sienasc/stabilityai-stable-diffusion-xl-refiner-1.0",
"murokhos/test-pantun",
"LPX55/dynamic-hfspaces",
"vkolasani/gpt2_demo",
"tabish543/gpt-chat",
"CatZM/value-detection",
"shangdatalab-ucsd/LDB",
"5ye8/extrasneo",
"ahsabbir104/koodi-gpt-2",
"nidhisingh27/textgeneration",
"omkar2005/Avatar",
"justseemore/ChatPaper",
"neubla/neubla-llm-evaluation-board",
"ZackBradshaw/text-generation-webui",
"jmssndrlnd/rhymes",
"saqlainraza/txt-gen",
"fanxiaocuo/koutu",
"wayne0019/gradiogpt2",
"lkishore/GENAI",
"skullsquadron/AutoGPT",
"nneka/MemorySupportChatbot",
"medmac01/stable-diff-multilingual-v0.1",
"nxphi47/MultiPurpose-Chatbot-DEMO",
"CRZ7436/FYP_CC_20275455",
"Ultrazartrex/openai-community-gpt2",
"Transment/text-generation-webui",
"TripletMix/tripletmix-demo",
"filedelete/voicemodelai",
"nneka/memory_support_chatbot_for_pregnant_women_using_gradio.py",
"KasugaiSakura/so-vits-svc-Sora",
"ivanmeer/AutoGPT",
"arauf1290/text_generation",
"HF0161/chat",
"motofanacc/GradioChatBot",
"ruiheCat/caNanoWiki",
"mingxaurora/LLM_test",
"peterciank/portfolio",
"petrumadar/openai-community-gpt2",
"hvaldez/SViTT-Ego_Action_Recognition",
"Corrigan123/fypmc20277423",
"shmarymane/AutoGPT",
"albhu/tdocaibot",
"JerryLiJinyi/Prompt-Compression-Toolbox",
"shahugging/imagenerator",
"Taf2023/MagicPrompt-Stable-Diffusion",
"Taf2023/MagicPrompt-Dalle",
"Ialready8/openai-community-gpt2",
"ndg04041/copilot-gpt2",
"MadeWithAI/MWAI-Promptist",
"MadeWithAI/MWAI-Stable-Diffusion-prompt-generator",
"m-ric/beam_search_visualizer",
"zaephaer23/compareAI",
"asir0z/open_llm_leaderboard",
"kylemin/CharadesEgo",
"william4416/bew",
"MesutUnutur/tiiuae-falcon-7b-instruct",
"nicpopovic/stoke",
"Applesam4/NETO_AI",
"Arpit1234/IDK2",
"TrungNQ/qa_roberta",
"nelbarman053/Artwork-Caption-Generation",
"kylemin/EK100MIR",
"suneeln-duke/jokify-app",
"pnvsrinivas/helloworld",
"Lwasinam/image-caption",
"harishshankam/tortoise-tts",
"jayesh944/jayesh-tts-duplicate",
"S-ai/story_generation_bot",
"Clemet/Sentence-Entailment",
"GuleedN/practice-bot",
"nishant17j03/end_of_night",
"Mezzy429/LLMintro",
"rakeshmr/ShortStory",
"eHemink/EnronEmails",
"skylersterling/TopicGPT",
"bhohbaum/text-generation-webui",
"ssenguptaopteamix/Experimental",
"Nova-school/NextTokenPrediction",
"MadeWithAI/MWAI-MagicPrompt-Stable-Diffusion",
"PatSeal/BEWBOT2",
"quchenyuan/360x_dataset_query",
"harikach24/Medical_QA",
"cyclinghearttortoise/STE",
"kbmlcoding/open_llm_leaderboard_free",
"Kvikontent/Color-Generator-AI",
"Yntec/Image-Models-Test-April-2024",
"basabose/eduRwa-community-gpt2",
"Medha2024/openai-community-gpt2.0",
"alexollion/hackathon",
"Divya0503/proj",
"Fric7ion/FricFast",
"AEUPH/SL-NAV2",
"Kenny2080/Ethio-chat",
"ArceusInception/ChatBotDemo",
"Divya0503/assi",
"ThaddeusHeller65/GPT2Gradio",
"Buzzliai/chatbot_fastapi",
"dar-tau/selfie",
"shashpam/GradioInferenceClientGPT2",
"jvamvas/beam_search_visualizer",
"devvoi01/custom1",
"tkdehf2/diary2",
"budhadityac24/trial",
"happysad/test",
"TMElyralab/MuseTalk",
"Saibo-creator/transformers-CFG-JSON-demo",
"SeaLLMs/SeaLLM-Chat",
"SeaLLMs/SeaLLM-7B-v2.5-simple",
"LaotHF/doc",
"SpawnedShoyo/testing-gpt",
"Kanai2003/chatbot",
"snbaskarraj/RAG",
"honey90/lawq",
"basabose/eduRwa.Answering.AI",
"camparchimedes/openai-community-gpt2",
"azsalihu/ENRON_EMAILS_QA",
"shraddha10/relevant_sentence_extractor",
"Divya0503/git",
"user2434/Enron",
"kevinwang676/MuseTalk",
"Rayna2812/NLP_group",
"ieuniversity/Visa-Chatbot",
"K00B404/Research-chatbot",
"Dendup/story_generation.app",
"Dendup/image_to_story_generation.app",
"nonprof/ava-1",
"asrilmurdian/Multiplesource_qna",
"Plller/openai-community-gpt2",
"Dendup/Short_story_generation_Pic.app",
"SpartanCinder/NLP_Song_Generator_Guessing_Game",
"ashutoshzade/GeneralistBiomedicalAI",
"shrimantasatpati/Text-to-Image",
"babaolanqiu/ChatReviewer",
"QuiXilver777/text-generation-webui-main",
"dineth554/openai-community-gpt2",
"Dasaradha/demoapp",
"retr04error/krish-rebase",
"concedo/WebTokenizer",
"mikasad/DialogueGenerator",
"mattekudacy/test",
"MattyTheBoi/NLP-CSI_5180",
"pngwn/open_llm_leaderboard-check",
"woodhj/PacePredictorExperimental",
"ishaqaup/openai-community-gpt2",
"Septime/openai-community-gpt2",
"VivMaC/qa_gen",
"0x1668/open_llm_leaderboard",
"phenixrhyder/NSFW-ToyWorld",
"DA1WN/StreamlitTest",
"toshi456/llava-jp-1.3b-v1.1",
"drxlouis/opdracht-ai-interface",
"phenixrhyder/MagicPrompt",
"morit/textgen_demo",
"kaktuspassion/gpt2-playground-mockup-demo",
"ffffacsimile/openai-community-gpt2",
"gongjianfei/openai-community-gpt2",
"divyang89/Test",
"Malek-AI/GPT-2",
"Koios-API/KoiosAPI-codegemma-7b-it",
"ganeshkamath89/gradio-huggingface-pipeline-tasks-demo-all",
"brunoqs/please-dont-sue-me",
"woodhj/PacePredictorFinal",
"0ddly/AIGeneratedApplication",
"cc1236/so-vits-svc-models",
"Jaysonmadill/Test-1",
"Belkiss/generation",
"chilge/so-vits-svc-models-pcr",
"ieuniversity/NLP-VISA-CHATBOT",
"ajinkya8484/TinyGPT-V-demo",
"d22cs051/Audio-Deepfake-Detection",
"camanalo1/MyAlexa",
"forrt/openai-community-gpt2",
"Montastein/openai-community-gpt2",
"nkul/SpeechAssignment3",
"Brucelee0723/openai-community-gpt2",
"ExploitationLizard/openai-community-gpt2",
"shanhanigun/openai-community-gpt2",
"Yunshansongbai/svc-online",
"Yntec/Image-Models-Test-May-2024",
"phenixrhyder/Prompt-gem-microsoft",
"JAI03/Document_QA",
"srtaxi/openai-community-gpt2",
"spraveen8/ChatBot",
"javakhangnguyen/Llama2",
"hfai-aam/sdpg",
"pvncake/acoustic_botto",
"hibalaz/visa-chatbot-DAI",
"Nachiketkapure/test_demo",
"GeorgiosIoannouCoder/cuny-tech-prep-tutorial-6",
"JoshuaPD/ASR",
"CedricZ/demo_gpt2",
"ahmedmbutt/CLIP_prefix_captioning",
"shuangzhiaishang/RS-VL-Perception",
"buhhhhhhman324982/Luccccu",
"ElliNet13/gpt2",
"diegopacheco/gen-ai-multimodel-fun",
"PeepDaSlan9/B2BMGMT_gen-ai-multimodel-fun",
"solo7917/extrasneo1111",
"seawolf2357/datasettest",
"QinghaoGuan/chatbot_gpt2_tinyllama",
"DoruC/Grounded-Segment-Anything",
"ih0dl/openai-community-gpt2",
"rynmurdock/Babel",
"jieralt/openai-community-gpt2",
"diegopacheco/genai-llm-multi-model-comics",
"Intel/low_bit_open_llm_leaderboard",
"Alif737/Deep-Remix",
"G2-7/Plant-Disease-Detection",
"Dominic0406/May_7th_2024",
"seawolf2357/l3custinstruc2",
"hailyyang/assignment6",
"aelitta/BioMistral_gradio",
"hurz01/openai-community-gpt2",
"smokiebuds/openai-community-gpt2",
"aniketnikam06/openai-community-gpt2",
"SoulXS2/test-gpt",
"K00B404/Prompter",
"oceansweep/tldw",
"K00B404/prompt_generator",
"cballz/openai-community-gpt2",
"cballz/openai-community-gpt2oh",
"dipsmom/IMAGE_TO_TEXT_GENERATOR",
"Shisanya/GROUP4_TASK1",
"swah99/GROUP1_TASK1",
"divyang89/ImageOCR",
"luisrodriguesphd/resume-worth",
"XilaiFan/ChatReviewer",
"Draken007/geochatbot",
"seawolf2357/test0001",
"xuan2k/Thesis-Demo",
"fmuindi/Group2Task2",
"fmuindi/Group2_Task1",
"Nick088/Audio-SR",
"K00B404/PapNeus",
"dioarafl/assisTen",
"PFEemp2024/DCWIR-Demo",
"K00B404/llava-jp-1.3b-v1.1",
"taratrankennedy/visa-chatbot-DAI",
"leepokai/perplex",
"nvnsngh1008/openai-community-gpt2",
"nvnsngh1008/openai-community-gpt2nvn",
"deftv/openai-community-gpt2",
"applebottomjeans420/openai-community-gpt2",
"holistic-ai/LLM-Open-Generation-Bias",
"K00B404/Morphy",
"cysjunkatschool/testspace",
"Zebulanx/My_local_LLM",
"MasalaDosa1337/RGMC",
"orlandopozo/playground-2",
"Lakshita336/bot",
"JACOBBBB/Hotel_Review_Sentiment_Reminder",
"barisg35/thesis",
"disi98/Group1_Subtask1",
"Mihirh19/openai-community-gpt2",
"phind-4869/image-captioning",
"Kashif17/demo_app",
"Kashif17/Text-Speech",
"angelariasblockdevs/openai-community-gpt2",
"rajapinja/Courteous-Writeups",
"nerfadox/openai-community-gpt2",
"ElinorZHAO/Final_Project",
"jordonpeter01/AI-App-Factory-3",
"Seqath/RVC-Conversations",
"JorgeV20/PictoVerse",
"tillman122/gradio-chatbot88",
"jacky56789/openai-community-gpt2",
"Sukeb/3ais",
"IamVicky111/Demo_Copilot",
"antjohns/gpt2",
"jchen8000/text-webui-CPUBasic",
"huudan12345/tl",
"Kaori1707/VideoCap",
"elliottd/SmallCapDemo",
"FarizAldo/openai-community-gpt2",
"PFEemp2024/DCWIR-Offcial-Demo",
"hd0013/gradio",
"afen671/ChatReviewer",
"miqueldev/NextTokenPrediction",
"shandong1970/list5-11",
"JessicaPearson/openai-community-gpt2",
"Yoxas/testchatbot",
"taratrankennedy/chess-chatbot-2",
"jcastellanosm/NextTokenPrediction",
"taratrankennedy/chess-chatbot-3",
"victoriaono/test",
"ronnye/first-gen-guide",
"Zebulanx/My_Local_LLM_V2",
"Alph4teK/tortoise-tts",
"julialincc/worldcup-2",
"Anamali153/SalesBot",
"annakcarls/top-exec",
"marniejeanreid/wordle-chatbot",
"ronnye/first-gen-guide-2.0",
"lauraza1/where_to_travel_chat",
"taratrankennedy/first-gen-guide-2.0-tara",
"saintyboy/newaimodel",
"demetz/kwk-chess-chatbot",
"Roshanik/microlearning",
"setarejahandide/Text-Generation",
"lpowers05/which-workout-new",
"jasminemomoko/chess-chatbot-2",
"jasminemomoko/chess-chatbot-3",
"jasminemomoko/jasmine-mvp",
"GPT007/Dataset-Tokens",
"daarsh/Semantic_Summarization_of_Videos_B29",
"trntytrn/chatfit",
"KlossyPasta/StudyBuddy",
"mardor/Connectt2Resources",
"kkasiviswanath/sample-app",
"kkasiviswanath/sample-app-one",
"annakcarls/top-exec2",
"annakcarls/top-exec-final",
"ChloeCodes444/PocketProfessor",
"annakcarls/top-exec-final-for-real",
"camparchimedes/AutosodomizedGPT2",
"mgetz/social_advisor",
"Tiffanynngg/chess-chatbot-2",
"mgetz/social_advisor_2",
"skops-ci/skops-model-card-creator-100ae352-a636-492e-a0bd-95390d2e0f89",
"skops-ci/skops-model-card-creator-f20106d2-904b-47db-9225-d8f172f31ecb",
"skops-ci/skops-model-card-creator-0db85e19-37e7-40fe-871f-c3eef9ce2afc",
"PhotographerAlpha7/Model-Fine-Tuner",
"aytena/ChatTherapy",
"darlingoscanoa/huggingface-language-model",
"skops-ci/skops-model-card-creator-5a88898e-3202-4a94-82b4-914b4a4f8bf2",
"skops-ci/skops-model-card-creator-afe617f5-b41c-4062-a1bd-16ae3efcab91",
"skops-ci/skops-model-card-creator-6c301f9d-87f9-4842-a1d1-98313d75c8c1",
"skops-ci/skops-model-card-creator-20cc3cf8-ce9f-4c19-8c4a-b8340d66c934",
"skops-ci/skops-model-card-creator-a51c261d-b61c-44af-8461-9862927a9022",
"mlgomez0/HFLab1",
"skops-ci/skops-model-card-creator-fce17cf3-671a-4461-8c27-ecd5ededd986",
"skops-ci/skops-model-card-creator-ffea434c-74a0-4f17-b691-670627a439ff",
"nityakupp/chess-chatbot",
"nityakupp/duplicatechessbot",
"prometheus-eval/BiGGen-Bench-Leaderboard",
"aytena/ChatTherapy1",
"IgorAndreic/test",
"OumaimaGHAZOUAN/fine_tuned_gpt2",
"Ghstys/openai-community-gpt2",
"kartik91/data_project",
"jessical1429/healthy_foods_NYC",
"Farhan1572/AutoGPT",
"Zhofang/MagicPrompt-Stable-Diffusion",
"Unfaithful/Thesimai",
"madmi/resume",
"Mr-Bhaskar/test3",
"AlfiAI/text_generator",
"ajikusuma/openai-community-gpt2",
"pratikshahp/Question-Answer-Generation-App",
"nighon/cooper",
"skops-ci/skops-model-card-creator-bced580f-4535-4b51-a91d-58092a4e5da3",
"jessical1429/Accesstohealthyfood_NYC",
"Vangmayy/Bollywood-gpt",
"JessicaL/NYC_FOODS",
"krishnv/VideoCap",
"SuriRaja/TextToVideo",
"rim32277/openai-community-gpt2",
"mardor/Connect2ResourcesBot",
"pratikroy311/IndianTaxationBot",
"Ajeissh/hf-ajeisshm-space",
"Ajeissh/hf-ajeisshm-space2",
"alexandrebackouche/IA",
"trntytrn/chess-chatbot-2",
"PrincessTigerStripes/testbot",
"purpleTree2/test",
"Taubah/test_bot",
"PositivityPlusChatbot/PositivityPlusChatbot",
"KWKGlobot/KWKGloBot",
"avantisingh/TestBot",
"OfficalBlossomBuddy/Blossombuddychatbot",
"BudgetBoss/BudgetBoss",
"rotbotchatwhat/rot-bot",
"victoriaono/first-chatbot",
"beznogy/openai-community-gpt2",
"GRPsix/GRPsixBot",
"anushkaayadav/group_6",
"JessicaL/NYC_FOODS2",
"JessicaL/NYC_FOODS3",
"mrrahul011/ERAV2_S19_babyGPT",
"BengaliNLP/bertspace",
"gschaumb/M2-Team01-SS24-RAG-demo",
"skops-ci/skops-model-card-creator-a19df421-a7d0-49f0-a7b1-dd47e0bf148b",
"soutrik/EraV2_S19_DecoderOnly",
"soutrik/ERAV2_S19",
"QueenAnna/solomon-chess-chatbot",
"fieu55/extrasneo",
"fieu55/extrasneo1",
"Anandhavalli2/GuvichatGPT",
"KleinZxA/IDK2",
"ibrim/NanoGPT",
"shyam1990/InterviewDemo",
"selvamaniandiappan/test",
"alex-abb/Simplecalculator",
"muellerzr/ai-dev-talk",
"hongkha336/openai-community-gpt2",
"hongkha336/openai-community-gpt2_add",
"alex-abb/GPT-2",
"manishagoud/simple",
"Elalimy/autocomplete_gpt",
"aichampions/open_llm_leaderboard",
"elisasy/chess-chatbot-2",
"Adhi98ai/chatbot",
"Light1st/openai-community-gpt2",
"Nax07onix3/Space",
"Cep3ga/openai-community-gpt2",
"meetsaparna/text2textgenapp",
"meetsaparna/texttotextgenapp",
"KaiOfTime/text-generation-webui-main",
"ubeydkhoiri/gpt2-text-gen-api",
"mynti/calliope-demo",
"Dovakiins/text-generation-webui-main",
"gamenowx/GameNow.X",
"Madheswaran/GUVI_LLM",
"PolloXDDDDDD/AIXD",
"Tunixlabs/Talking-avatar",
"Kanji2348/test0622",
"Kanji2348/Multi_LLM_0622",
"ROHIT936/Generate_Text_and_Audio",
"mrrahul011/ERAV2_GPT2",
"oldg591/jannn",
"IndianChessMans/openai-community-gpt2",
"IndianChessMans/openai-community-gpt2-test",
"jackchow621/openai-community-gpt2",
"next-playground/so-vits-svc-webui",
"micymike/coverletter-generator",
"kesavaprasad/textgeneration_gpt2",
"anhhayghen/dopgiongnoi",
"bhavanishankarpullela/CoSTA",
"zhaozengxi/openai-community-gpt2",
"pynapavani/langchainwithhuggingfaceapp",
"micymike/coverAI",
"Kilos1/comet_gradio",
"pavan01729/pavan01729-llama2_gpt_ai_dataset_plus",
"Adeco/open_llm_leaderboard",
"Chintan-Shah/GPT2FromScratch",
"PhotographerAlpha7/Model_Fine_Tuner_Txt2Txt_NLP",
"raja5259/EraV2S21_Raj",
"andererka/test_llama3",
"fragger246/rookus2",
"Nibir5/openai-community-gpt2",
"gaur3009/Rookus4",
"gaur3009/Rook",
"maheedhar123/testing",
"Dima123e/openai-community-gpt2",
"victoriaono/my-chatbot",
"victoriaono/chess-chatbot",
"sayanbanerjee32/nanogpt2_text_generator",
"Aacnm/so-vits-svc",
"eaglelandsonce/IntroductionHuggingFace",
"HANS27barron/hh",
"david9575/zxc",
"yeswantht/GPT",
"itaybit/AI_Doctor",
"caiosoliver/teste",
"Kartheekb7/s21-gpt3",
"sagar007/GPT-2",
"HimankJ/GPT2_CustomTrained",
"next-playground/so-vits-svc-api",
"walnash/ERAV2-21-GPT2",
"harikishanm96/GPT2_Karpathy",
"DhrubaAdhikary1991/GPT2_Custom_trained",
"Ritvik2201/Generate_Joke_Excel",
"Shivdutta/S21-GPT2",
"mattaldi/GPT-2-Text-Generator",
"nastasiasnk/languageModel",
"Dagfinn1962/MagicPrompter",
"ruslanmv/convert_to_gguf",
"WhiteD2125/text-generation-webui",
"Pranjal101/Optimus_Prime",
"loveitl/MagicPrompt",
"mikefish/French",
"sarvottam07/texttotextwithdocker",
"Kumarkishalaya/Cricket-commentary-generation",
"FallnAI/FallnAI-Assist",
"MohamedAAK/artst-tts-demo",
"Gbssreejith/custom_gpt2",
"DarwinAnim8or/NoSleep-v2",
"himanishprak23/Cricket-commentary-generation",
"haolun/llm-profiler",
"KamalRajeswar/GuviLLM",
"Nandhini93/GuviGPT",
"harry85/text-generation-GPT2",
"rasyosef/GPT2-Amharic",
"fschwartzer/llm_test",
"skops-ci/skops-model-card-creator-bbd5eccf-c9e5-403d-96cf-310a1e5b63c5",
"skops-ci/skops-model-card-creator-4debdb41-1f86-49a1-9122-6b9e6be3d04d",
"AkashDataScience/GPT-2",
"trhacknon/Promptist",
"eaglelandsonce/Tokenizers4StartUp",
"vakodiya/UvicornGpt2",
"rushi-k/app_11",
"rushi-k/app_12",
"unity2009/AutoGPT",
"sonalkum/GAMA-IT",
"Vvaann/Assignment21-GPT2",
"skops-ci/skops-model-card-creator-8ca4510a-3a1b-44a4-a019-243ef1ed44c5",
"TencentARC/ImageConductor",
"improprogrammer/Image_Genrater",
"kubotahi/sandbox_gpt2",
"BusinessDev/pothole-detector",
"dwawdwdd/Audio-SR",
"saigayathri/optimistic",
"clementine24/TheGiggleGrid",
"Archi3002/Rikka",
"SeemG/TheGiggleGrid",
"pmp438/med-buddy",
"Raven7/Chatbottest",
"fanty222/REMEDY",
"walledai/walledai-walledguard-c",
"rushi-k/app_13",
"drmurataltun/gradioUnifiedDemos",
"HarshitX/Multi_Model_ChatBot",
"pratikshahp/rag-chroma",
"barqsol/TTS",
"pratikshahp/RAG-Chroma-Gradio",
"GoalZero/GoalZero-Ada-Demo",
"dusaurabh/era_v2_assignment_21",
"Fy1/test2",
"pratikshahp/Invoice-Extractor-Gradio-App",
"skops-ci/skops-model-card-creator-fbac7bdc-e331-4a26-ab72-24cf624d5193",
"SuriRaja/VideoBOT",
"JessicaL/HappyBot",
"sanjaysamuels/Imagitextanator",
"KLM-Solutions/Gradient-cyber",
"Trickshotblaster/mike-chat",
"eaglelandsonce/CodestralHackathonLabab",
"Vasudevakrishna/ERAV2_S21_124Model",
"dnnsdunca/ddroidlabs-gpt2",
"fReEsPiRiT94/ZoraFinal",
"Sunghokim/BLOOMSCIENCE12",
"ProPerNounpYK/chat3",
"aiqtech/dataload-test",
"kgout/asr",
"thepianist9/Linly",
"Yntec/Image-Models-Test-July-2024",
"tsukamoto1120/test5",
"ethanchern/Anole",
"Samp21/newnew",
"victoriaono/chess-chatbot-test",
"MatttOrg/CelebrityFinder",
"kbmlcoding/apps_metric",
"JessicaL/practicewithtara",
"aytena/aytenFinal",
"taratrankennedy/team-chess-chatbot",
"Shivvy/Canvas-Block-APP",
"eaglelandsonce/GridinPython",
"skops-ci/skops-model-card-creator-41303ab7-f86f-4665-a94c-de530498e439",
"abigaildavis/collete-college-bot",
"raeanneferrer/chess-chatbot",
"Book-Buddy/Book-Buddy",
"diyapaudyal/hydrAIted",
"UaoS/collete",
"sharanyam00/activaid",
"hydrAIted/hydrAIted",
"sophianhd/ActivAid",
"mmmagalski/chess-chatbot",
"lshayman/songseeker",
"Skintelligent/Skintelligent",
"Estellejoubert/chess-chatbot",
"breaampaw5190/chess-chatbot",
"Collete/Real_Collete",
"Cecilia-CC136/Meal-Chatbot",
"joemama1805/chess-chatbot",
"SongSeekers3/Song_Seeker",
"MentalMusicBot-1/MentalMusicBot",
"Sustainable-Meal-Assistant/TreeBot",
"jasminemomoko/chess-chatbot",
"Estellejoubert/newchat",
"bellanun/newChatBella",
"binisha-a/binishaChat",
"dhairyashil/gpt2_Shakespeare",
"PhoneFinder/PhoneFinderApp",
"LitBot-Organization/KWK-Final-Project-LitBot",
"fillirabot/FilliraBot",
"happy-paw-bot/HappyPawBot",
"GreenUnityfinal/GreenUnityCollab",
"Zamira1235/chess-chatbot",
"Collete/new-collete-chatbot",
"polygraf-ai/article_writer",
"Mayuresh9/Mayuresh_LLM",
"hydrAIted/EpicBot2",
"xiongxiaopeng/openai-community-gpt2",
"tea-phan-y/dropdown-test",
"alokchauhan13/gpt2Train-Assigment21-gradio",
"kenken999/fastapi_django_main_live",
"Jamiiwej2903/ytet1yuhd",
"Gowdham/Profile-Screener",
"kg7/ShakespearGPT2",
"TuringsSolutions/Tokenizer-Explorer",
"vakodiya/training-gpt-2",
"AlGe/CompareTokenizers",
"koyincho/openai-community-gpt2",
"ashirhashmi/blogGenerator",
"AbdulHadi806/BlogGenerator",
"abdulllah01/Blog-Gen",
"YasirAbdali/blog_generation",
"ASaboor/BlogPost",
"MohammadSalmanAhmedRaja/TextGenerationStremio",
"tareeb23/BlogPostGenerator",
"Umairtufail/demo_space",
"JDmayo/task",
"fffiloni/EchoMimic",
"skops-ci/skops-model-card-creator-cc213858-dd24-4f91-9ed5-b4eaa2168532",
"ASaboor/Week3Day1",
"zaafirriaz/blogs",
"Mudassir939/blogspot_generation",
"barqsol/BarqsolTTS",
"sohaiby/BlogGen",
"talha2001/blogpost_app",
"rocsanket/gradio_chatbot",
"dwawdwdd/asr",
"xmadai/1bit_llama3_instruct_xmad_qa_batch",
"Aston-xMAD/1bit_llama3_instruct_xmad_chatbot",
"xmadai/1bit_llama3_instruct_xmad_chatbot",
"acvss24/nutri2assistant",
"QuindeelFatima/Blogpost_generator",
"riteshcp/Market_Analysis_Tool",
"jungsin3/experiment",
"shre02sriv/CHAT-BOT",
"danalytix/text-generation-GPT2",
"rouhina/project-query",
"dami1996/blog-post",
"gowthM23/_____",
"NoQuest/QP_ANmixtao",
"Rinkal4/GPT-2",
"wyjlu/Grounded-Segment-Anything",
"luohoa97/train",
"Vinitha3699/GUVI_GPT",
"Sephfox/E.L.N",
"fantaxy/EchoMimic",
"Vishal1806/text_generation_with_docker",
"lpowers05/chess-chatbot",
"NRbones/Grounded-Segment-Anything",
"karanzrk/gpt2-qa-quora",
"DemiPoto/TestDifs",
"karanzrk/Unified_Quora_QA",
"Roshanik/mentalhealth",
"tnk2908/ai-text-steganography",
"KBarnes/ai-nstein",
"rferreira119/ChefBot",
"SheScreen/SheScreen",
"ChefBot/ChefBot",
"fsbeau/SheScreen",
"salient-american-kids/ai-nstein",
"scholar-sage/Scholar-Sage",
"HealthHubKWK/HealthHubKWK",
"GreenGuide/GreenGuide",
"GreenGuide2/GreenGuide2",
"alexspoto/ActiveIntelligence",
"JessicaL/FarmersMarketsToYou",
"ariel79/ai-nstein",
"christineo4321/chess-chatbot",
"emilyan2/olympics",
"3rin/SheScreen",
"Diyasinkar/HealthHub-chatbot",
"ow98914/CalmConnectBot",
"florencew/Active-Intelligence",
"MukBot/MukBot",
"amy1199/greenguide",
"Wiinnieee/ScholarSage",
"activeIntelligence/activeIntelligence",
"jaynathescifi/hellom",
"KBarnes/ai-nstein1",
"sadiaislam31/scholar_sage",
"Amanda1234/AquaGuard",
"madelineeee/mukbot",
"Rooc/Prompt-Generator",
"jasminemomoko/sf-practice-duplicating",
"sarahzhao01/klossygal-practice",
"Pl-Ai/Plai",
"harmony-kwk/harmony",
"kAI-chatbot/kAI-chatbot",
"Shade-Bloom/Shade-Bloom",
"CreditCounsellor/CreditCounsellor",
"Jimyourpersonaltrainer/Jimyourpersonaltrainer",
"inikab/credit-counselor-practice",
"afiyaa/sf-kAI",
"ihundal/globowl-practice",
"belavlima9/jim-practice-duplicating",
"MotivaMate/MotivaMate",
"ATG2024/StarFinder1",
"Starfinders/Stars",
"fantasyforever/starfinder-practice",
"AquaGuard/chess-chatbot",
"SquibJam/activeIntelligence",
"EthicalEatsExplorerOrg/ethical-eats-explorer",
"medmatch-org/MedMatch",
"savvvy/savvy",
"GreenGuideChatbot/GreenGuide",
"geethika2009/Mood-Muse",
"timifyorg2024/timify",
"Moodia/Moodia",
"annakcarls/chess-chatbot",
"mood-muse-org/mood-muse-org",
"Sakka13/text-gen-model",
"klossygal/KlossyGal",
"GloBowl/GloBowl",
"Ckreamer/Jim-personal-trainer",
"tessasundar/Jim-your-personal-trainer",
"nsinha21213/motiva-mate",
"ohnothekrakengotme/plai-practice2",
"Queue-Tip/PLAI",
"natavii/harmony-likes-gravity-falls-practice",
"shelyj/test-chatbot-dupl",
"Aayush2683/tast",
"soalwin/gradio-textgenerationtool1",
"NihalGazi/GPT-2-Uncensored-Local",
"anirudh937/open_llm_leaderboard",
"GreenGuide/GreenGuide_2",
"Amanda1234/chess-chatbot2",
"smothiki/open_llm_leaderboard2",
"odaly/fuzzylab",
"EthicalEatsExplorerOrg/EthicalEatsExplorer_FinalVersion",
"bistdude/Test1",
"bistdude/test3",
"annakcarls/test-mood-muse-org",
"taratrankennedy/ethical-eats-explorer",
"lpowers05/ChefbotNew",
"JessicaL/SampleBotForKristy",
"ChefBot/ChefbotCopyFromChessbot",
"cw332/h2ogpt-chatbot",
"taratrankennedy/ethical-eats-explorer-2",
"taratrankennedy/savvy-2",
"activeIntelligence/ActiveIntelligenceSpotify",
"Seif-Yasser/Seyof",
"mgetz/timify_experiment",
"MOFadel96/GPT2_TEXT_Generator",
"Nymbo/MagicPrompt-Stable-Diffusion",
"llamameta/flux-pro-uncensored",
"taratrankennedy/timify_experiment",
"sophcheng/ai-nstein",
"harshiB/CreditCounsellor",
"Amanda1234/AG-BOT",
"Queue-Tip/Plai-Final",
"timifyorg2024/timify_final_version",
"zhaozengxi/openai-community-gpt23",
"bistdude/test4",
"siri12345/siriii",
"archit11/gpt2long",
"linxianzhong0128/Linly-Talker",
"soiz/prompt",
"yoshilol0526/WeatherChatbot",
"hoseinhajepor/MotionGPT0",
"John6666/ToyWorld4",
"pratikshahp/Next-Word-Prediction-SHAP",
"temporary0-0name/orator",
"AIdeaText/test2",
"Vikhrmodels/small-shlepa-lb",
"aakashv100/gpt2-karpathy",
"2002SM2002/StoryBook",
"Ridham-ux/nlp_153",
"soalwin/meow",
"harshananddev/LLMdemo",
"skops-ci/skops-model-card-creator-1d26d1a3-18e1-4a1d-a704-260c993b878c",
"Eman-Abdelkader25/DEPI",
"art-manuh/swahili_llm",
"llamameta/fluxproV2",
"John6666/Diffusion80XX4",
"John6666/Diffusion80XX4g",
"Prabuganesan/chainsysai",
"CHEONMA010/MOA-NLP",
"John6666/Diffusion80XX4sg",
"yakine/model",
"EsoCode/openai-community-gpt2",
"drxlouis/AI_Interface",
"sbdie/QP_AN",
"MAJED94760/app.py",
"ilaamar/lamar.py",
"Manu101/GPT2-trained-scratch",
"lou2191/newwww",
"K00B404/HuggingfaceDiffusion_custom",
"subayyalsaeed/AIDetectorModel",
"subayyalsaeed/AIdetector",
"toakley682/VedalTTS",
"seawolf2357/EchoMimic",
"DSU-FDP/Sample-API",
"piealamodewhitebread/SillyTavern-Extras1",
"sherylsapphire346/SillyTavern-Extras1",
"Tort73/new-test-autoresearch",
"a00801/sidang-simulation",
"eagletiger1/dlagpt",
"chaore/MagicPrompt-Stable-Diffusion",
"Amitontheweb/Params_Playground",
"Abhlash/75-day-challenge",
"spark-nlp/gpt2",
"Shivamkak/EchoMimic",
"Oranblock/Validjson",
"d-matrix/dmxMetric",
"Nikhitha2310/Text_Generation",
"freQuensy23/LLMhistory",
"JoeyBenvenuto/WAGS_Chat",
"maytham1/openai-community-gpt2",
"XS5217/text-classification",
"Do0rMaMu/Factory-POC",
"coding-hax/openai-community-gpt2",
"gabrielwegrow/testeprofessoria2",
"rafaelduarte/AI-Prompt-Generator",
"rafaelduarte/AI-Iceberg-Generator",
"ginipick/FLUXllama",
"afifamehak26/final",
"coding-hax/openai-community-gpt2iuihih",
"Azreal18/GPT2",
"patrol114/mistralai-Mistral-Nemo-Instruct-2407",
"zhuminghui/aug22-test",
"Nymbo/Diffusion80XX4sg",
"momenadel/openai-community-gpt2",
"sagar007/GPT-2-with_gpu",
"Verathagnus/portfolio",
"opcode3/CyberSecurity_Chatbot",
"decodingdatascience/firstchatbot",
"Rizumohamed/1stxchatbit",
"GenAiPA/First_chatbot",
"areidbet12/app",
"VS-01/openai-community-gpt2",
"f-URY/ResuMeister",
"Ffftdtd5dtft/Hhhhhhhhv",
"Ffftdtd5dtft/Gggffx",
"lislon/extrasneo",
"Ffftdtd5dtft/Kfkjfjd",
"v1vu/image_captioning",
"Misko123123/testtemplate",
"marcosZzzs/IAdetective",
"Mrvishal999/Ai_assistant",
"Mrvishal999/AI_vishal",
"atharvprajod/hawkins-images-demo",
"chunkmonster/FieldViewBuddy",
"Yakush/openai-community-gpt2",
"Skriller0208/AudioValidation",
"K00B404/Versatile-Diffusion-game-assets-gen",
"Prashanthsrn/Jarvis",
"aauu1234/openai-community-gpt2",
"mohAhmad/ReceiptBanao",
"learning4/DepolNudgeBot",
"szili2011/EcoModel",
"MolecularReality/llamaSquint",
"seddiktrk/CLIP-GPT_Image_Captionning",
"John6666/TestDifs4",
"saima730/text-2-video",
"Manasa1/Justice_Bot",
"Junebuggo/transformerstest",
"Uhhy/Temp_fasy",
"Uhhy/Temp_fnnn",
"sashtech/aihumanifierandgrmoform",
"infoteachmenow/test1",
"abilbao/openai-community-gpt2",
"Manasa1/AdvocateAI",
"sashtech/huamnifierWithSimpleGrammer",
"John6666/blitz_diffusion4",
"hujesr/openai-community-gpt2",
"Blane187/multi-diffusion",
"Yntec/Image-Models-Test-September-2024",
"John6666/blitz_diffusion_builtin",
"sixteenths/gp2fun",
"sudhanvamg/model_compare",
"skops-ci/skops-model-card-creator-89433177-6937-494e-a26f-1475b13b0677",
"mikibunny99/mikispace",
"flosstradamus/FluxMusicGUI",
"alinasuarez/AwkwardTurtle",
"mqcm2/ArticleChatbot",
"SriSumanth/SCM_Hallucinations_DemoApp",
"Yntec/MiniToyWorld",
"randomtable/Magic_Promp_SD_v2",
"randomtable/MagicPrompt-Dalle_v2",
"england61300/working",
"ibrim/GPTTextGenerator",
"TristanBehrens/Garland-Composer",
"tistabaulopez/Alhajas",
"Uhhy/Train",
"Uhhy/Trainx",
"N1k3y/KCPT",
"sohilaaraby/Task_dataScience",
"John6666/hfd_test_nostopbutton",
"Chuntim0303/text-generation",
"RahulChhatbar/TextGenPro",
"munzi273/swn",
"treuio/io",
"saja003/Story-Teller-AI_Models",
"ectofr/my-bert-model",
"Dunirov/opena",
"NadaAljohani/StoryTellerAIModels",
"DudeUnoob/Test",
"bardicreels/rag2",
"multimodalart/EchoMimic-zero",
"Uhhy/Gggggg",
"DemiPoto/testSortModels",
"arshadrana/secand_project",
"chuckc/Confluence_Sum",
"shaimaa123/text_generation",
"AlanKK/pizzasmp-gpt2",
"missbaj/chatgptcryptoanalysis",
"Hemavathineelirothu/agent",
"Garvitj/grader",
"reaperdoc/whatsapp-gpt-bot",
"anaahat/k8s-manifest-generator",
"panchadip/AI_Story_Teller",
"tharunnarra/GenAiFeatures",
"Cherry0907/Gen_AI_Features",
"Adithya005/genboot",
"panchadip/AI_Story_Generator",
"sathvik2473/genai1",
"xtreme86/character",
"vinayarni/multi-mode",
"arshadrana/Third_project",
"Menawer/chatbot",
"generalaimodelanalysis/LlmTokenGeneration",
"MAJED94760/full_pipeline_notebook",
"skops-ci/skops-model-card-creator-2476f58b-4506-43e5-811f-5f9cc7506045",
"Menawer/gpt2-chatbot",
"Vishwas1/LLMTrainingPro",
"NikkoRagnar/Secondassistant",
"Aizaz0205/openai-community-gpt2",
"Sk9shiva/Myblogen",
"SaviAnna/Extended_GPT_2",
"calvesca/gtp-final",
"DereAbdulhameed/DocuChat",
"hgdgng/HG_LLMFewshotprompt",
"Shack2883/openai-community-gpt2",
"mattsoh/WorldGPT",
"mlc-ai/MLC-Weight-Conversion",
"Shangkhonil/Text_Generation",
"BartoszB/HeraMod",
"Riyaspaul/GUVI_Final",
"jadechoghari/OpenMusic",
"Yhhxhfh/dgdgdgdgd",
"ManjeeraJ/21_ERA_ShakespeareGPT2",
"MUNTHAS/gradio-transart-genai",
"Yhhxhfh/Gxhhfhdhd",
"Yhhxhfh/Gxhhfhdhdggggg",
"MUNTHAS/gradio-project",
"Yhhxhfh/Ghhhg",
"FireRedTeam/FireRedTTS",
"minhthao56/slack-bot",
"Anubhuti024/demo-space",
"rakeshrohan/demoapp",
"Prabhleen617/StoryGen",
"Prabhleen617/RecipeGen",
"fahadMizan/Fasahathullah-gpt",
"richardorama/AssortedLanguageTools",
"miguelcastroe/MiguelCastroChatFolio",
"praty7717/Odeyssey_v2",
"lv-vl/Audio-SR2",
"DeadHello/ShakespeareGPT",
"MesibunX/openai-community-gpt2",
"Divya0503/TextAutoComplete",
"rajsingh22/text-generation",
"saumil707/SHREKgpt",
"nooshinbah/tokenizer",
"anteodt4/openai-community-gpt2",
"Jayx2u/ReallyDeadpoolGPT",
"Sujatha87/NUSCapstone-PM-2024-10-IECRS01",
"chris-na/web_application",
"Leo8613/Llama_3.2",
"riteshcp/Fine-Tuning",
"nooshinbah/TextGeneration_withGPT2",
"shrivarshan/EduSpace",
"awacke1/PromptRecombobulatorDeluxe3000",
"tanbw/CosyVoice",
"YB1425/Visual_Story_Generator",
"jonathanburk/openai-community-gpt2",
"yomariano05/openai-community-gpt2",
"pro-grammer/StoryCrafterLLM",
"PabRubio/MemeGPT",
"galaxy-destroyer-war-machine/my-gpt2-space",
"Aiden4801/openai-community-gpt2",
"ranjith8825/Nullclass",
"KittyCat00/CatGPT",
"Dhejan/Veritrue.ai",
"pi-nf/TimCookedaLLM",
"Jayx2u/ReallyDeadpoolGPT2",
"Jayx2u/ReallyDeadpoolGPT3",
"Hiezen/openai-community-gpt2",
"andrewvharris/MovementOne",
"jefersonsouzadev/openai-community-gpt2",
"zarha/GenAIApp",
"samwell/SamGPT",
"duckdb-nsql-hub/DuckDB-SQL-Eval",
"mjalg/IFEvalTR",
"MozartKato/openai-community-gpt2",
"Vicky0650/Multimodal",
"LucasSanchez12/usign-a-gan",
"Palmdrive26/PoliConst2",
"hemavarthini245/Generative_ai",
"Suryadev78/MypromptTester",
"gaspard7/wiki-gpt",
"AminFaraji/SpaceGPU",
"Adignite/Carbon_Connect",
"Nymbo/Compare-6",
"kazelnut/llama-3.2-3B-Instruct",
"anonymousatom/Anole",
"Yhhxhfh/Hhggg",
"MiraLiza/HuggingGPT",
"Yhhxhfh/Vvvvv",
"Dragunflie-420/OpenMusic",
"karyappa/gpt",
"Divya0503/llm",
"Nikithagoud/story",
"fruk19/test_gpt2",
"Nymbo/gguf-editor",
"fruk19/test_gpt2_demo",
"LSreback/openai-community-gpt2",
"patchbanks/nanoMPC",
"Geek7/mdztxi",
"Geek7/mdztxi2",
"dpaul93/llmopscicd",
"akiffazal/chatbot",
"shreyanhota/travpoet",
"shreyanhota/docker_travpoet",
"shreyanhota/travpoet_docker",
"Nymbo/MLC-Weight-Conversion",
"dindizz/personagenerator",
"GroveStreet/GTAV_SOVITS",
"MUNTHAS/transart-munthasir-pt1",
"nicpopovic/ember_chat",
"xray918/my_gradio",
"Sakalti/Model-Fine-Tuner",
"Akshit1/freebobux",
"tchelo99/customer-support-chatbot-llama2-sentiment",
"nazibkni/TextToImage",
"chandrujobs/AI_Machine_Learning_News_Analyzer",
"foxcz95/AutoGPT",
"abven/ImageCaptionGenerator",
"praveencn20/NewsSummary24",
"elapt1c/ElapticAI-1a-EnhancedChat",
"Counterplan/TinyTales",
"skops-ci/skops-model-card-creator-181ead53-7336-4a9a-abc6-f00241c39332",
"Ramya321/multimdel-app",
"CD17/AI_Store_Assistant_Project",
"thenotsoboringguy/History_Exploration_Tool",
"Counterplan/GondiiGenerator",
"henryqi91/openai-community-gpt2",
"Vedansh247365/AI-School-Project",
"Kavyabrgowda/MADRS",
"ReZon8/openai-community-gpt2",
"tenet/rwkv-mcts-cot",
"r3wfew/openai-community-gpt2",
"DexterSptizu/langchain-gpt2-text-generation",
"MohamedTalaat91/Chatbot_",
"stagbrook-tech/Proto-Peanut",
"Waseem7711/GPT2",
"vinmay1234/SynapseEd",
"KhaqanNasir/VoicetoVoice",
"Chilliming/openai-community-gpt2",
"DhilipAnto/TransArt",
"anhhayghen/MuseTalkV",
"hivecorp/Transcript-recreate",
"cindywqng/CalmBot",
"Calming/CalmBot",
"ntnmedia/Image_Captioning_Test",
"AIdeaText/v3",
"NLP-Data-Science/PT_1",
"Sonal0929/Search_Tool",
"Thiva2000/Test1",
"tbahaji/whisper-audio",
"yaoyaoNo1/AI_app",
"FrancisSilva/Loyalty_Strategy",
"RenninhoRobot/AnaliseIA",
"hopeless-dreamer/nlp_gpt_project",
"Muhusjf/XAI-Medical",
"rumbo213/myapp",
"AbhinayaDasari02/uygufrf",
"Liuboomyue/openai-community-gpt2",
"t-asawth/openai-community-gpt2",
"Nicolas-Loisy/MarkIA",
"Ibrahim9898/medical_assistant",
"Kaizouku/Multi-model-Chatbot",
"selvamaniandiappan/MultiLLM",
"tree3po/Architext_deployed",
"keisanmono/so-vits-svc-models-ba",
"bangtansoneyydaeng/StoryGenerator",
"alejoamillano/openai-community-gpt2",
"alejoamillano/gpt2-train",
"monikode/customer-service-chatbot",
"Arrcttacsrks/Llama-3.2-3B-InstructX",
"Umesh143/Chatmate",
"wanghh2804/RAG_Retrieval_Performance",
"acecalisto3/SwarmmingHuggs",
"jjz5463/App_Simulator",
"Bietin/GPT-2_Prompt",
"haozheli/ai_detector",
"crealities/HCC",
"tree3po/Chatbot-Compare",
"mahdee987/MS-GPT",
"sbicy/base_chat",
"alenelias/Compliment",
"Leifj1206/BCComp",
"sbicy/superbasic",
"LittleLil/SuperBasic",
"pawmi/pokemon",
"Bobilicious/basic",
"VicinityMC/stemstuff",
"LeonidDaniel01/Leonids_happy_place",
"DENNISWEI/Dennis.chat.bot",
"cazador1/hola_optica_lux",
"Diyasinkar/HealthHubKWK",
"Diyasinkar/KWKHealthHub",
"Hjgugugjhuhjggg/Hhhgg",
"ManojINaik/manojapi",
"jackbean/AI_BUSINESS_ANALYST",
"tasmimulhuda/fastapi-rag-qa",
"Subhajit01/spam_detection_poweredby_custom_GPT",
"AIdeaText/v4",
"sbicy/marge",
"soiz/Stable-Diffusion-prompt-generator",
"BheemaShankerNeyigapula/aiisc-watermarking-model",
"mananbharti/openai-community-gpt2",
"DSWF/Human-ai",
"enoderr/Bot",
"dsylvain/myNewAPI",
"Rohith18SFDC/Streamlit_1stSpace",
"aluizara/Maia",
"acecalisto3/Geminui",
"MishalZubair/productDescription",
"Nymbo/EchoMimic",
"E66andF10w/AIConstructing",
"DanofficeIT/privatellm",
"ozgurunlu/ethimar",
"abhisheksan/poetica",
"BACKENDAPI2024/aiisc-watermarking-modelv3",
"joermd/test",
"HammadUllahKhan/AI_AR_based_Storytelling",
"KVAkash/project",
"KVAkash/operaex1",
"Nymbo/Audio-SR",
"KVAkash/operaex2",
"mksaad/NewsSummary",
"akazmi/Investment-Advisory-App",
"YuvrajXp324/Chatbto",
"isashap/resumebot",
"akazmi/Investment-Advisor-2",
"mars1198/proba_space",
"llamameta/fast-sd3.5-large",
"akazmi/Investement-Advisor-3",
"Zeeshan42/personal-psycologist",
"lemonteaa/nanogpt-speedrun-demo",
"izhan001/personal-psychologist",
"Arrcttacsrks/Chat_X",
"Zeeshan42/Virtual-Psycologist",
"kartik2627/assignment1",
"Ozgun111/Chatbot",
"MojoHz/saivv",
"Rovan1/Saivv",
"MamathaBM/Simplechatbot",
"ItsOyondi/oyos-yt-transcriber",
"asadAbdullah/Gen_Disorder",
"vince1313/image-to-story",
"ItsOyondi/transcriber",
"jchwenger/pix2pix-zero-demo-CPU",
"lemoncityideas/document-generator",
"sango07/RAG-App-Evaluator",
"vince1313/ml-deployment",
"Dagfinn1962/MagicPrompt-Stable-Diffusion33",
"bcv-sridhar/LangchainQ_A",
"muhammadshaheryar/RAG-REV-01",
"ashok2216/Image-to-Text",
"YuvriXp324/ChabotAi",
"duck-systems/TinyLlama-v1.1-GAD-Demo",
"Humaniod1/first",
"820nam/roomy",
"nikunjcepatel/AutoTrainSpace",
"muhammadshaheryar/app-new",
"Anupam202224/SmartDocGenerator",
"nikunjcepatel/MyDemoSpaceForgpt2",
"Manasa1/Jacks_Clone",
"JHigg/Injury_History",
"abven/Customer-Support-Chatbot",
"enotkrutoy/teststore",
"aneesh-cherian-k/demo",
"lilmeaty/vllmxd",
"Besimplestudio/Kdp",
"LeoHobby/Bee-Helper",
"ashishanand/car_manual_assistant",
"garvitcpp/InkLore",
"annetade/S",
"20kt1a4215/Chat-With-Research-Paper",
"None1145/So-VITS-SVC",
"Unfaithful/Xandxtorm",
"reisarod/gradio",
"laitkor/RAGDocGen",
"MrGojo/bio_generation_app",
"SAITAN666/StableDiffusion35Large-Image-Models-Test-November-2024",
"i-darrshan/LLM-Token-Counter",
"AhmedSSabir/demo-for-Visual-Re-ranker-LLLMA-3.2-1B",
"ErkanPolat/openai-community-gpt2",
"YuvriXp324/chatbot-gpt2",
"Leee90/Test_1",
"Leee90/XY",
"meharpro/tortoise-tts",
"anujkohli/movie_recommender",
"RafaelJaime/SherezIAde",
"mahdiabedi2000/medbymehdi3",
"tshel/new3musk",
"kaleidoskop-hug/PrintingPress",
"starthub/tutorAI2",
"git-excited/VocalityDemo",
"OpenBots/openai-community-gpt2",
"AnhP/RVC-GUI",
"YuvriXp324/clarity-aiyuvri",
"TejAndrewsACC/AutisticAssistant2024",
"Kaasiein/tamil_tokenizer",
"Anuj02003/Chat_with_pdf_using_llama3.1",
"SmartRecipes/openai-community-gpt2",
"ayushkush2402/DL_project",
"LuisMBA/fine-tuned-chatbot",
"angly/FidesIA",
"AiCodeCraft/FreeAI",
"VoAndAi/Vo.ai",
"SHAIKT07/NLP_Super_APP",
"Canstralian/RedTeamAI-new",
"sobarine/openai-community-gpt2",
"lennart-rth/iris-inside",
"LunaticMaestro/book-recommender",
"NativeAngels/HuggingfaceDiffusion",
"NativeAngels/Diffusion80XX4sg",
"NativeAngels/ToyWorld",
"NativeAngels/blitz_diffusion",
"NativeAngels/PrintingPress4",
"vuxuanhoan/anychat",
"AiActivity/AI-Assistant",
"acmc/homoglyphs-alarm",
"NethraVinod/GenAIChatBot",
"NativeAngels/flux-pro-uncensored",
"Mithra19net/GenAI",
"Thiwanka01/AI_driven_consumer_device_ecosystem2",
"PradeepBodhi/Troubleshoot-bot",
"invincible-jha/vc-copilot",
"invincible-jha/VCPEAssistant",
"elitecardpro/openai-community-gpt2",
"Nihitha/GenAI",
"NativeAngels/PrintingPress",
"topdu/OpenOCR-Demo",
"Mithra19net/GenAIChatBot",
"invincible-jha/CyberSecAI",
"marshal007/echomimicv2_test",
"macota1/axa",
"sergiopaniego/Promptist",
"BielX5/crypto-analysis-hunter",
"BielX5/Crypto-signal-hunter",
"anjali2024/text-generation",
"Arr4y/chatbotOCGE",
"Mat17892/iris",
"fffiloni/echomimic-v2",
"assafcaf/ABC-Music-Gen",
"Hikari006/i_cnt",
"Celsomg/AI_Hudl-WIMU_support",
"Sarthak191213/FriendInfoBot",
"mohfinest/alloyaiassistant",
"huang342/LLM_Solace",
"NithyasriVllB/Moral_Magic",
"MohammadYaseen/Legal-Case-Summarizer",
"ajad/My_Local_LLM",
"Mohuu0601/imageintotext",
"Mohuu0601/all-in-one",
"NithyasriVllB/Explore_Topic",
"12end/openai-community-gpt2",
"idrge/chatbot-francais",
"Dagfinn1962/MagicPrompt",
"fdbfb/openai-community-gpt2",
"AnotherIndian/ATI_IA",
"Rafamartinaitis/Umdianavida",
"fztkm/length_controllable_video_captioning",
"Hemavathineelirothu/alemeno_assign",
"Aceolarye/AI-Communication",
"pbretherton/aphasia-sentence-helper",
"tlmdesign/MAI_MidiAI_Music",
"tlmdesign/MAI_MidiAI_Playback",
"Owen1756/DadGPT",
"lazoark/ChatReviewer",
"dmolino/XGeM",
"sathish99/Financial-advisor-app",
"SunDay-s/gpt2-space",
"Saanvi12011/Blog_Generator",
"Saanvi12011/News_Report",
"Percy22/test",
"fantaxy/ginfa2v",
"Saanvi12011/Art_Generator",
"LuanaMARD/historiageral",
"hilman921/multifungsiai",
"nguyenne/Quw",
"Uthar/LewdExperiments",
"Uthar/BodyPaint",
"JehanRodrigo/Medi_Backend_GPT2_Pipe",
"cstr/PDF-Summarizer",
"Amoxliar/Estudopublicotestemake",
"pico-lm/perplexity",
"arkgpt/AttaViz",
"salmaadel/Risky_Task",
"atsushieee/sovits-test",
"shrisbkh/newgr",
"shrisk/mynew",
"mehtasambhav/gpt2-qa",
"komalbagwe/RAG",
"azoodle/vedic_astrology",
"nontas4/nt1",
"Pavankumar91/llm_based_tool",
"Uthar/HRGiger",
"Uthar/SexyReality",
"Siddhant/Voice_Assistant_Demo",
"opendigital/agent-flow",
"drwaseem/school",
"ARTariq/DemoApp",
"ARTariq/Demo2",
"Satyajit45/English_Proficiency",
"Satyajit45/sop-generator",
"Mackintoshj/anychat",
"TejAndrewsACC/AutisticAssistant2024Beta",
"nawabraza/BookReview",
"dljeski/hfprodemo",
"Manojvarma07/siuuu",
"chaos4455/Bert-GPT2-TokenHeatMap",
"rpt480/DoAR_FK",
"azra-kml/fast_detect_gpt",
"AamirMalik/chatBot",
"Uthar/HighFashion",
"NativeAngels/Compare-6",
"FAIZANALLINONE/Dianosuargame",
"TejAndrewsACC/GGM",
"Talha1218/AIPoweredSignalPrioritySystemOptimizedTrainScheduling",
"manmeet3591/rag-llamaindex-librarian",
"mib-bench/leaderboard",
"Waqasnaseer19/Waqas25",
"Zabieee/Zabieexd",
"camiloNorato/agenda",
"EMAniP/MyFirstSpace",
"asim98/molasses-production",
"shaheerawan3/Interview-Preparation-Coach",
"AamirMalik/docker_space",
"Torch6435/openai-community-gpt2",
"manmeet3591/llm_water",
"manmeet3591/llm_farmer",
"thihillman/DWP1",
"redfernstech/s",
"Reality123b/openai-community-gpt2",
"civahg/sohbet",
"Umutalt47777/umuto",
"Dikshu22/ai_chatbot_project",
"shaheerawan3/AI-Teaching-Assistant",
"ZahidSultan/project-repot",
"sepp81/knjdkjafk",
"ADkshs/evaluate",
"grv805/t2t_docker_genai",
"migueldeguzmandev/leilan_v1",
"Yntec/Image-Models-Test-December-2024",
"RandomOnHuggingFace/DumbAI",
"mariamgvelesiani/anychat",
"yalotaibii/anychat",
"ilovemystagename/anychat",
"0906haris/Games",
"louiecerv/streamlit-llama",
"patchbanks/Drumwave",
"yuerrr/12_17",
"dzhuz/gp2-art",
"Ghmustafa11/MyChatbotApp",
"sango07/RAG-Evaluator1",
"sango07/RAG-Evaluation-with-Custom-metrics",
"ijerezm/aihf",
"kait-and-tara/chessbot",
"Uqba143/generated_text",
"Waqasnaseer19/Centrifugalpump",
"waleed1992/AIchatbot",
"alexmohandas/openai-community-gpt2",
"ricapereira/openai-community-gpt2",
"RandomOnHuggingFace/AIiscool",
"yousuf4343/MULTICHAT_BOT",
"ggbondServer/openai-community-gpt2",
"yousuf4343/multibot",
"Idriziks/Jarvis",
"danoprea/search",
"taimurkhalid/TTS",
"Cmescobar27/minerva-generate-docker",
"Ghmustafa11/customs-bots",
"carfer2024/VBA_Code_Generator",
"sohail-shaikh-s07/News-Article-Summarization",
"Raussky/classifierSample",
"Ranadani/freestyle",
"dehua68/ToyWorld",
"shojibur/bdtest",
"sanmathisedhupathi/MyGenAIChatBot",
"smartahsan/Upworkproposalwriting",
"Yntec/open-craiyon",
"capsizero/ai-story-generator",
"MarkChenX/neon-8-qubits",
"Yasir646/PDF_QA",
"scriptscrypt/solana-kit-assistant",
"enzer1992/Ai-Guru",
"ayaulymm/sitebyme",
"ashika27jan/ashikagenaiproj",
"tkuye/CosyVoice2-0.5B",
"ashika27jan/mygenaifirst",
"ginipick/ginfa2v",
"Voix1/openai-community-gpt2",
"ahmed-7124/MedicoGPT",
"Roohithbala/Chatbot",
"govardhini/motivational_coach",
"sencercebeci/sencer-chatbot",
"Ranadani/New_Application_for_Numberplates",
"AseemD/gpt2",
"hussain2010/RAG_Base_Application_PDF_QA",
"rupaak/reply",
"NaqchoAli/RAGapp",
"Ranadani/chat_bot",
"mosheofer1/multi_beam_text_streamer",
"bungerei/bungermc",
"Sribharath910/app",
"abugaber/test",
"Ihsan92/Yield_Prediction_App",
"Yasir646/Chatbot",
"Aarbaaaz/ragappdev",
"JeanFrankDwell/llm-task-distribution",
"GeminiAi/handy",
"zero0723/openai-community-gpt2",
"Brenord/Text-Generation-API",
"fserrgg/Audio-SR2",
"willco-afk/RAGtest",
"dragonities/Toxic_Detection",
"EbbyTornado/openai-community-gpt2",
"amasood/myRAG",
"Sribharath910/SMF",
"albhu/ubeo",
"yvesJR-237/cc_streamlit",
"amasood/myRAG2",
"Bread-F/Intelligent-Medical-Guidance-Large-Model",
"kidsampson/halcydonia_tests",
"Guhanselvam/SUPER_BOT",
"sabia771/campous_application",
"Te2908as/chatbot",
"DevNet/LLM-generation",
"Anuj02003/Market-Research-Use-Case-Generation-Agent",
"tushar888/Zeinural.ai",
"adilriaz264/medical",
"Guhanselvam/vis",
"eligapris/CosyVoice2-0.5B",
"debashis2007/AIML",
"Shakeeel/RAG_SaudiElectronicStandard",
"victory6451/LLM_PLAYGROUND",
"SimonAugus/Planning",
"Charvin04/multilingual_trans",
"Saurabey/Autism_app",
"Uthar/Harvester",
"wiqasali/8085-microcontroller-code-genrator",
"Alpharaj/alpharaj",
"Arrudaa/QualidadeCare",
"7yuuui7babar/yt_seo_score",
"martynka/TasiaExperiment",
"sunnynazir/EmbedCodeGen",
"sunnynazir/Embed_Code_Generator",
"Munwar92/Customize_Multilingual_Chatbot",
"rapid12k4/openai",
"Hidayatmahar/Guide4-thyroid-Surgeon",
"Rktastic123/Roamify",
"DEVILON007795/CyberSecure-bot",
"smzuhair/Energy-Trading-App",
"danihaji12/hackathon_project",
"bariumc/roshan_project",
"darkkhan461/med-bot-and-therapist-wellness-app",
"mjunaidsatti/Energy_Mangemet_AI",
"sialnoman318/ConstructionChecklist",
"King-Afridi/MediTherapist-Your-Complete-Health-Wellness-Companion-2.0",
"Abinivesh/Multi-models-prompt-to-image-generation",
"engr-awaisjamal/WattHack-The-Energy-Advisor",
"engr-awaisjamal/Smart_Home_Energy_Advisor",
"muhammadali81/WattHack-The-Energy-Advisor",
"amirsultan4091/Smart-Road-Design",
"danihaji12/1-Hackathon_Project",
"NayabShakeel/Embedded_system_code_generator",
"mahmudaq/PDF-SME-Chatbot",
"edyy2020/MeuAssistenteGPT",
"muhammadali81/Energy-Advisor",
"Mac05/flux-pro-uncensored",
"DevVrat088/Interview_Desk_Recommendation",
"engr-awaisjamal/Smart_Home_EnergyAdvisor",
"shaheerawan3/VisionCraft-AI",
"philip237/devoir_leugwe",
"Bhism/image_captioning",
"IVA-App/IVA-App",
"hazz92/JediGameMaster",
"JarvisOnSolana/Jarvis",
"zeroMN/zeroMN-SHMT",
"subham2507/Additive_Manufacturing_gpt",
"Anupam251272/idea-agent",
"gutai123/ChatModelApp",
"Nymbo/LatentSync",
"provin/CIAgent",
"tbimbraw/LinkedInPostCreator",
"Francke/LatentSync",
"lcipolina/game_reasoning_arena",
"Potre1qw/LatentSync",
"pascha1906/Noor",
"neetu30/openai-community-gpt2",
"BAAI/open_flageval_vlm_leaderboard",
"RenSc1/Rena1",
"jd-mughal/Snake_game",
"Aakarsh14n/product_emb",
"Hidayatmahar/Court",
"meepmoo/LatentSync",
"rubyroid11/kolianextasmusic",
"rubyroid11/kolianexstasmusic",
"vikasjain/openai-community-gpt2",
"HannahLin271/nanoGPT",
"kbam77/flux-pro-uncensored",
"Gabrielokiri/Nigerian_languages",
"SunderAli17/LatentSync",
"AniruddhaChattopadhyay/LatentSync",
"muchaco/LatentSync",
"yjkj02/CoseVoiceV2",
"shraddha10/RSE_sh",
"gautamraj8044/Prompt2Picture",
"dhairyashil/ShakespeareGPT-Forge",
"amisha001/image_gen",
"RaitonRed/gpt-tools",
"shuraimnms/deen-gpt",
"Yntec/Image-Models-Test-2025",
"Sakuramento/My_Local_Viso",
"JoeArmani/csc525_retrieval_based_chatbot",
"mgbam/PhilosBeta-Advanced-Chat",
"nananie143/app_creator",
"Shilpaj/ShakespeareGPT",
"Shiva678/vulnerable-llm",
"rishigowda007/testing_1",
"Osnofa/git_config_-global_credential.helper_store",
"DanNLO/Testings",
"HSinghHuggingFace/gpt-text-generator",
"Walruss/openai-community-gpt2",
"Hyathi/SoundImage-LipSync",
"nikhil-kumar/Love_and_Smile",
"DddaTx/openai-community-gpt2",
"artemsadko88/magic8ball",
"artemsadko88/magic8ball1",
"pedromoreno/qa_roberta_test",
"atiwari751/GPT2_replica",
"satyanayak/transformer-basic",
"kbam77/openai-community-gpt2",
"mnnobi/gpt2",
"luismidv/GPTFineTune",
"Dehru/voice-agent",
"botoole12/TriboroBot",
"Dehru/voice-agent1",
"sagargurujula/text-generator",
"NSamson1/Finance",
"Anupam251272/Voice-ai-system",
"Mister12rayyan/RYanychat",
"SudipPatil20/LLM_CHATGPT2",
"EzhirkoArulmozhi/DecoderTransformerModel",
"acecalisto3/microhugs",
"brightlembo/SY23",
"yigiao/CGS",
"chbsaikiran/NextWordGPT",
"Abhi-0069/S12_Decoder_Model",
"paul18e/Neo",
"padmanabhbosamia/Short_Shakesphere",
"wgetdd/Shakespeare-style-Text-Generator",
"Arun1612/DecoderSession12",
"Anupam251272/Superhero-Generator",
"tranquilkd/GPT-Text-Generation",
"Tousifahamed/Transformers-from-Scratch",
"piyushgrover/Decoder124M-S12ERAv3",
"Perpetualquest/ShakespeareReimagined",
"mfbarber22/autot",
"k0de01/Decidophobia",
"dalybuilds/ExhibitAI",
"omarwael/Themes_Extractor",
"Anupam251272/gta_style_city_with_collision",
"MilindChawre/simple-transformer",
"anjikum/decoder_transformer_nextwordprediction",
"musemkt/WM_text_v1",
"peeyushsinghal/GPT2_Demo",
"abmSS/openai-community-gpt2",
"Starchik1/anychat",
"sathishsesh/strat1",
"MehmetK/Image_Sense",
"kalekarnn/training-gpt-transformers-from-scratch",
"shaheerawan3/InspireCraft_Video",
"Shriti09/TransformerModel",
"ujwaliyengar/Decoder_Only_Model",
"kalekarnn/gpt-transformers-from-scratch",
"aayushraina/gpt2_session12",
"Yntec/Image-Models-Test-January-2025",
"sudhakar272/shakespheretextgenerator",
"hotshotdragon/ShakespeareSpeaks",
"Rakavi12/GPT_Text_Generation",
"shravan25/Transformer_Shakesphere",
"sawandarekar/session_12_transformer_part_1",
"hellom98/s12",
"ViksML/Transformer",
"GeminiAi/texttovidep",
"rajann/llm_gpt_model",
"rajann/guvi-llm_model",
"Kr1st3r/openai-community-gpt2",
"zzcl5127/my-novel-generator",
"Yeeezus/SexyImages",
"MalikShehram/diet-plan",
"satishchappa/cloud-cost-optimizer-bot",
"bkoos/LatentSync",
"vtriveni23/cloud-cost-optimizer-bot",
"HSinghHuggingFace/SmolLM2-135-Text-Generator",
"mrinalmouza1984/custom_gpt_tiny_shakespeare",
"anindya-hf-2002/Table-aware-RAG",
"Dwight009/MuseTal",
"KurjoZmeya42/openai-community-gpt2",
"Rajendro/StyleDecoderTransformer",
"wd43tr4t/Drrd",
"rimsnet/web",
"Arkuuu777/LatentSync",
"arghya2030/smollm2-demo",
"bhadrabolem/testing",
"Yyk040316/long-context-icl",
"Hamidrst/openai-community-gpt2",
"Perpetualquest/smolLm2-implementation",
"Jingkang/EgoGPT-7B",
"RenSc1/Dvv",
"rjproz/gamechat",
"K00B404/SimpleBrothel",
"ChaitraSaiK/Talk-To-Me-AI",
"kishkath/GPT2",
"jasonjoshi/TransformersScratch",
"Sreekan/FirstPoC",
"crailor/Funny-Pet-Name-Generator",
"crailor/Meme-Generator",
"abprasadhuggingface/TransformerDecodeString",
"aparnavellala/Chatbot",
"IDMNYU/9103D-2025S-api-example",
"ujwaliyengar/TT_SmolLM2-135_Model",
"Starchik/CodeBox",
"anton2014/catyAI1",
"hijaukuohno/ohno",
"ssastry/blue-pineapple-cat",
"WSLINMSAI/Week3-TraditionalChatbotwithAI",
"Ilum/openai-community-gpt2",
"Sartc/storyGPT",
"Interatiive/openai-community-gpt2",
"ashish-26/Text_generator",
"Anupam251272/Legal-IndianMindAI",
"izakpaul2002/Project",
"chandraswede/test",
"weteax/miku",
"Monimoy/SmolLMShakespeareTextGenerator",
"crailor/AI-Powered-Story-Generator",
"tflanagan/Flanagan-AI-Powered-Story-Generator",
"gio484/AI-Powered-Story-Generator",
"sprev21/AI_Story_Time",
"fabiovalverde/jorginho",
"Sharjeel36/Generative-Fill-AI",
"raheelchandio55/game",
"dambeebu/LiteratureReviewApp",
"pruthvimv/DecoderonlyTransformer",
"gaccardi/AI_Storyteller",
"remsaw/openai-community-gpt2",
"ariG23498/docker-demo",
"AhmadRAZA23/plant_search",
"awenzel/StoryTellingApp",
"bsajad2/Text_generator",
"gitesh-grover/Shakespeare-Coriolanus",
"Nagappana/medical",
"z0u/sparky",
"xdemocle/openai-community-gpt2",
"Alleinzellgaenger/DeeperGaze",
"TelePTC/freud-ai-chatbot",
"ultramaxai/gamer",
"nikhildsst/RAG_Chatbot",
"bless55/productNames",
"arunchidambaram/ARC-AGI",
"yousifalishah/AI_Text_Generator",
"AndrewScorp/openaichat",
"edanais/llm-test",
"happyabhinav/happy_ai_01",
"Aleksi779/deepseek-chatbot",
"The-Mirror-Prismals-Company/Mira-Clone",
"The-Mirror-Prismals-Company/Test",
"HasnainFalaksher/Budget_DEMO",
"vincentiusyoshuac/Neuromod",
"Shiva-teja-chary/shiva_llm",
"arenisLIVE/openai-community-gpt2",
"hacer201145/GPT2-Modifed",
"orionweller/parameter-count",
"MansoorSarookh/VirtualCareerCoach",
"ZavazkeyDola/first-ai-demo",
"amlanr66/GPTTextGenerationApp",
"berkanyildirim/Mydeneme",
"DKDanil/gpt-2_campchecklist_ai",
"Gineesh/joke_generator_bot",
"Sampathl/QAi",
"ghostt477/aistoryteller",
"Yoyan/T.R.A.C.E_V1",
"musaashaikh/ClmsCompare-gpt2",
"MrGm/Aitestagent",
"faiqababar/openai-community-gpt2",
"habi01/cuxtest",
"Canstralian/STRIDE-GPT-RAG",
"kunalrana123/Dream-weaver-AI",
"PrasadJali/demogpt2",
"Shreyas1441AI/VIVAI-Base",
"Alishbah/AIClashZone",
"Lananglp/my-gpt-2",
"coder2500/Algo",
"BroPutin/brbrbr666",
"monkeyprofe/whisper-youtube-description2",
"anshrva/deepseekdeploy",
"jithara/LLMModels",
"ChaosCraftAI/llm-perf-leaderboard",
"Mts192938449/openai-community-gpt2",
"gogreenverz/slm-web-app2",
"ravis2k6/GPT2_Text_Generator",
"hotshotdragon/Gibberish-LOTR",
"Swati0907/gpt2-chatbott",
"SebastianKIJ/openai-community-gpt2",
"yckao1221/demoai",
"yergyerg/ImgGenClone",
"ddomogala3/openai-community-gpt2",
"Tanmayakumar36/Rcexd",
"skuindian/vanilla-chatbot",
"alivegames/Grounded-Segment-Anything",
"PhilippSpohn/tokenprob",
"fartinalbania/st-chat-1",
"Pepperoni75/myAI",
"Hum5/LocalChatbot",
"YZ-TAN/flask-llama",
"Pepperoni75/MyAIV2",
"raphael3x/openai-community-gpt2",
"Maikeekiam/ab_ia",
"Shiva-teja-chary/TalentScout",
"mau1002/geology-chat",
"sahvarma/GENAI",
"Blandskron/ClasificacionDocumentos",
"el0315/colornames",
"Aaryan1314/Bot",
"rsachincoder/summarize",
"orpstar/openai-community-gpt2",
"KBaba7/llama.cpp",
"KBaba7/Quant",
"brainbitesai/brainbitesai-text-gen",
"mcandura/aichat2",
"AJLC4/gpt-text-generator-by-nice",
"ilangodj/rag_deployment",
"TechSmashers/LatentSync",
"mgbam/sythenticdata",
"totolook/Quant",
"24Sureshkumar/Tam_to_Eng_Translation_and_Image_Generation_Model",
"malekradwan130/openai-community-gpt2",
"hpeter11/First_agent_template",
"WRAJE/yoimiya-chatbot",
"Steven10429/apply_lora_and_quantize",
"sowhardh/hf-nutricoach-AI",
"CjangCjengh/Prompt-Compression-Toolbox",
"David960/LatentSync",
"vihaan43/openai-community-gpt2",
"awacke1/HuggingFaceModelSaveStreamlit",
"awacke1/HuggingFaceModelSaveGradio",
"Rajwinder28/EssayVibe",
"svjack/LatentSync",
"kgourgou/llm-decoders",
"ftshijt/Voice_Assistant_Demo",
"RanaHasan/First_agent_template_1",
"KR-16/Code-Assistant-CodeLlama2",
"dajidali-banana/gpt-2",
"LinhChloe/First_agent_template",
"WRAJE/xgchatbot2.0",
"Pebble2413/First_agent_template",
"kmajdan/GdzieZaplacisz",
"ace-1/erav3-gpt-inference",
"Alyaboelnasr/Story_Teller",
"Kimmmmy/Kimmy_word_generation",
"psrg17/AmadeusAPI",
"psrg17/AmadeusAPInew",
"Ascetu/LatentSync",
"toxxictechinc/api-toxxic",
"tharunk07/Text-Generation",
"nsmsopot/chatbot-fastapi",
"Zonderofficial/Gptaindaemtestes",
"lghere/text_generator",
"Safe-Harbor/harbormaster",
"debasisha/GPT_Text_Generator",
"ramkan8/ImageCaptioning",
"TheAbsoluteArgument/AI-YouTube-Video-Creator",
"paganghantasala/ai_paper_agent",
"debasisha/smolm-demo",
"FranzQDH/Syntho",
"Sinanipek/Snn",
"MatheusFonseca/GPT-Nutricionista",
"arikp/test-gradio-space",
"User-2468/simple-gpt",
"JordanSalazar/PrediccionSiguienteToken",
"Yntec/Image-Models-Test-February-2025",
"KnowledgeBay/knowledge-app",
"harshilsiyani/openai-community-gpt2",
"YashsharmaPhD/PhD_Thesis",
"SmokeyBandit/pitchdeckforgpuloanfromdad",
"mathminakshi/TextGeneratorUsingGpt2",
"roopmajumder/deepseek-R1",
"dayuian/VocabLine",
"riko-sama/AIAgent",
"Bala2004/Simple_Agent",
"Shahzaib676/mindreader",
"Alexvatti/Transformers-NLP",
"Gaut7224/straggpt",
"Carpediem29/GPT2-Assistant",
"Aali01/Physics_calculator",
"BaggerOfWords/MOSAIC",
"ganireddikumar/AI_Debate_Club",
"fordfishman/GPT2-Explorer",
"TotoB12/gguf-editor",
"wikikie/go_emotions",
"chandrimabatabyal/bertchatbot",
"aliahanch021/openai-community-gpt2",
"NDCUTI/OAG2",
"danyal-ahmaad/RoboCasting",
"Akashram95/youtube-chapter-backend",
"Womuna/Doggoz",
"cheemam0807/CTP-APP",
"sairaarif89/videosummerization",
"StephenOke/dadJokesApp",
"thanasipavlakos/social-media-gen",
"sairaarif89/sum",
"sairaarif89/summ",
"sairaarif89/summa",
"Lyte/tokenizer-leaderboard",
"sairaarif89/sam",
"Tejas98765/colloquial_trainer",
"robloxdude/HangMaN",
"Abubakar-Lakhwera/whether_impact",
"ashah29/deepseek-demo",
"gardendreams/First_agent_template_2",
"Aloorv/openai-community-gpt2",
"meraj12/docter",
"wozwize/media-unmasked-api",
"bakhtkhush551/physics_concepts",
"praveencn20/PdfReader",
"juju102424/tata",
"7yuuui7babar/Hhjj6788bbbn",
"PrabhathLolugu/storygeneration",
"Tryfonas/Portfolio_Assignment3_EDA_Tool",
"ramkan8/ImageCaptions",
"IbukiRobe/text-gen-comparison",
"vivekvicto/openai-community-gpt2",
"josh930908/test",
"swanggl/ust",
"anmishka/mishka",
"Alvstudios/EleutherAI-gpt-neox-20b",
"bartar/tokenizers",
"codewdhruv/latent-sync-testing",
"Aafiaa/ideas_generator",
"AradhyaBolar/easyai-chatbot",
"BabyCHUN/Contentsnap",
"alx-d/PhiRAG",
"usamaJabar/RescueChatBotGPT2RAG",
"preetidav/PoemGenerator",
"pams90/Adult_Novel",
"RawadAlghamdi/StoryGeneratorWithImage",
"RoaaGH/storyapp",
"RoaaGH/FainalProject",
"AdeebaZahra/languagelearning",
"gdnjr5233-YOLOer/c2r",
"haziq099/MagicPrompt-Stable-Diffusion",
"FarmanKing001/chatdoc",
"HiPeking/latentSync",
"reactd1/senti",
"Mochetillo/probando",
"erfaaaaaannnn/hackgpt",
"juju102424/dudu3",
"fxtrader70/dreamscape-chronicles",
"ZhangxinX/openai-community-gpt2",
"juju102424/duino-streamlit",
"juju102424/duplicate",
"John6666/MiniToyWorld",
"juju102424/theduplicate",
"eshan13/FootyComm",
"YashPanchal1901/document_summarizer",
"juju102424/duplicateofduplicate",
"mquirogapascal/ai-campus3-6",
"MrRokot/GENFLUX",
"Teameed/DjazaIA",
"anshumanray95/NextWord_Generator",
"Subodh556/Instruction_LLM",
"fimomiva/openai-community-gpt2",
"taiy0/Rae",
"taarhissian/Taarho-Gen-NLP",
"Spanicin/aiavatarnew",
"Alexvatti/GPT2-Temperature-top-K-P",
"Moon11111/avatar",
"openfree/IMAGE-Prompt-GEN",
"Pontonkid/AI-Voice-system",
"Abdullah-s-27-2k24/Typing-master",
"joey1101/storytelling",
"AndrewLi403/indivassign",
"mxiean/assignment1",
"LCNada/111",
"Demsaw/ISOM5240",
"pursuit1024/OSIRTool",
"wangyhh/try4",
"qxr0316/testing",
"Bondya/testasd1",
"joey1101/Assignment",
"afaq120/maintancemodel_LLM",
"umar54753/Ai-asistent-with-memory-and-email-automation",
"slliac/5240-indiv-assignment",
"dsvdfsdfsdfsdfs/fvdsdfs",
"SexxxyPriest/ai-demo",
"shanepersaud/sss",
"Vinoveer/Gpt_nemo",
"RekaCiptaEdukasi/BotBangunRuang",
"Bullguy/GPT-2",
"savan360/basic-llm",
"scooter7/voicechat",
"Rabbitturtle/genai",
"ZenithBrew/mygen",
"aobatroz/LatentSync",
"TomsTech/smol165",
"QAIML/GPT2-Text-Generator",
"shibly100/dr_kamaleddine",
"shengqizhao0124/ISOM5240ASMT1",
"Khush77/text-generator",
"JoshuaZywoo/storyjoshua",
"Muralidoss/quickdemo",
"Alinadi98/qualityoflife",
"BillieWU/app.py",
"tonyhui2234/ISOM5240_Assignment",
"shmohtashami/text-GPT-2-Gradio",
"tonyhui2234/ISOM5240-Assignment-1",
"Crystalstalalal/Assignment1",
"raheelchandio204/AI-DrivenContentGenerationPlatform",
"cblaikie/ai-chatbot",
"nibrastuhh/Company-Brochure-using-LLM-and-web-scraping",
"trhacknon/SteganographywithGPT-2",
"pjq626/ISOM5240Assignment",
"liuxh0319/ASSIGNMENT-1",
"infasmoha/AiSQLBot",
"awacke1/TransformersDiffusersNDatasets",
"ZJustin/Assignment-1",
"CarolineZXY/assignment1",
"Luizrrrr/LUIZ-AI",
"vikas83/AI_text_generator",
"Rocksolid07/DECISION",
"ShoaibShariff/Shoaib.ai",
"unamedai/Kate",
"ayan55678864222/Discord_boot",
"ayan55678864222/Bot",
"Rocksolid07/BUILDIT",
"Noman15/Ai_Text_Generator",
"twitu/my-llm",
"swhelan123/smartcert",
"vasfps/AIStuff",
"EmmaL1/Story",
"mrhat79/openai-community-gpt2",
"Wendy117/Assignment",
"mickey-panda/golden-chat",
"wam66/P",
"namuisam/ISOM5240_Assignment1",
"adrek/flux-pro-uncensored",
"liuxh0319/assignment",
"DreamGores/Misaz",
"Charleshhh/ISOM5240",
"BillieWU/stella",
"Kfjjdjdjdhdhd/Hhhh",
"alx-d/psyllm",
"NandakumarN/Nanda_the_personal_chatbot",
"Awil129/AIchatbot",
"imfeniljikadara/terra-ai-gpt",
"JanviMl/Echo_Chamber_AI_chatbot",
"anton2014/kai.1.0",
"fridayfringe/lgai",
"Allenust/ass1",
"ShuyaoJiang/audioBook",
"Reneeeee12/storytelling-app",
"pjq626/ISOM5240Assignmentv2",
"Charlieman/CharlieChanAssignment",
"NayabShakeel/Quotation_App",
"irenewhll/irenestory",
"agrimrai/code_checker_py",
"ayushrupapara/vit-gpt2-image-captioner",
"kanneboinakumar/transformers-pipeline",
"Papaya-Voldemort/chat-with-any-model",
"varghesebabu/reddit_comments",
"jasondos/ai-chatbot",
"awacke1/SFT-Tiny-Titans-Agentic-RAG-Party",
"Saivamsim26/mechvis",
"wenqinsong/langchain_gradio",
"laule/words2tokens",
"pra123401/p_1218",
"nicogptai/omega-1.2",
"H4KAI/openai-community-gpt2",
"Henkepunx/smart_ai_helper",
"Hachiru/chigas",
"NeerBoonyakorn/Neer_Bot",
"newindhu/openai-community-gpt2",
"foski234/Enaks",
"Faizal2805/expo",
"Imogen24/Kpi_formula_generation",
"edocore/openai-community-gpt2",
"SurbhiB/Streamlit-based-AI-Summarization-app",
"S1131/Streamlit",
"nnsohamnn/Conv_GPT",
"AureoFaitDuPedalo/IA_phishing",
"S1131/Fin-Bot-2.0",
"IELTS8/metalmind",
"Bhavibond/MoodSwingsHelper",
"burman-ai/Printing-Press",
"burman-ai/Draw-Images",
"YuvrajSingh9886/SmolLlama",
"sadtales/storybook-dev",
"ArfeenSKD/math_riddle_factory",
"ArfeenSKD/math_meme_repair",
"ArfeenSKD/emoji-math-solver",
"PhaseTechnologies/Webtaset",
"ahmad920192/Math_riddle",
"LonewolfT141/Math_Riddle_Factory",
"LonewolfT141/Math_Meme_Repair",
"Syed-Burhan/MathRiddle",
"LonewolfT141/Creative_Math_Problem_Solver",
"FallnAI/Quantize-HF-Models",
"Darksen97/Vira_AI",
"Gnanaqubit/Quamplifiers",
"w2mpu72/openai-community-gpt2",
"Hjgugugjhuhjggg/Hghhhh",
"sthawani/openai-community-gpt2",
"Garabatos/iabodas",
"Bhavibond/RPGStoryGenerator",
"faheemsm/ChatBot_with_FOL",
"Drbrain0620/ChatbotTest1",
"aiAlgeria/Passistante",
"abrotech/abro-project-space",
"Whilane25/AI-Consultant-Chatbot",
"K00B404/LLM_Quantization",
"wykwark/Gradio",
"saish-shetty/NanoGPT-Shakespeare-Demo",
"hackergeek/openai-community-gpt2",
"arafathali-ms/openai-community-gpt2",
"samadcyber/YT_AGENT",
"YuvrajSingh9886/StoryLlama",
"Rai-muhammad/Math_Riddle_Generator",
"NandanData/MegicAI",
"NandanData/AITOOL",
"Swatz28/My_LLM_Chatbot",
"nickylrca/mizo-gpt2",
"preston-cell/image-text-to-text",
"muhammadawais121/Emotionsupportchatbot",
"muhammadawais121/emotionchatbot",
"Rai-muhammad/Math_riddle",
"Rai-muhammad/Emoji_Math_Solver",
"Rai-muhammad/Math_Meme_Repair",
"kaddo94/22",
"hamzarana7347/GT2_Fine_Tune",
"ramazon0007/saas",
"Nidhi9999/First-AI-Demo",
"WesanCZE/Chatoos",
"KoreJosh/TheAdventurersPath",
"QureshiSaad/streamlineworkpermit",
"EliteGamerCJ/openai-community-gpt2",
"KAMGAING/Trancription_Intelligente",
"muhammadawais121/emotionalsupportchatbot",
"muhammadawais121/chatbotofemotion",
"Raiff1982/codriao",
"talipturkmen/LatentSync",
"Timxjl/seqxgpt_demo",
"zainulabedin949/Cover-Letter-Generator",
"UmerAmmar/Channel-Estimate",
"SidraMalik/Math_Riddle",
"Peeble/Text-To-Emoji-Fix",
"hoodchang/genai-demo",
"Mirthu/NLP",
"samaraamfetamina/qwant.beta.mini",
"mohithkr/Story-maker",
"mohithkr/AI-Story-Maker",
"mohithkr/Ai-story_maker",
"neuronennougat/datagenerata",
"alx-d/scout",
"Anupam007/IdeaMapper",
"muhammadawais121/emotionalsupportchatbotultra",
"Keerthanavismaya/simple-ai-text-generator",
"subatomicERROR/Quantum-API",
"im-canopus/Learn1",
"Bhavibond/LightweightcodingAssistant",
"CHETAN004/Unnati_wine",
"ayeshaishaq004/GPT2API",
"Mayorkanbayi/Cyber-rag-chatbox",
"acthuan/LLaVA-Med-Mic",
"lavacek/atoca_test_api",
"alx-d/pdf2txt",
"irpan260626/dono_ai",
"vishant99/openai-community-gpt2",
"nada116/promptunderstandingtest",
"VMom123/GPT2-Prompt-Playground",
"TroyDuh/NaNCard",
"Gnol4444/comic-suggestor",
"tanaman/my-gen-ai-model",
"raminderrathore/latestgenai",
"Peeble/There-Is-A-Chat",
"zeynepsahbaz/cookI_app",
"zeynepsahbaz/cookI_official",
"zeynepsahbaz/cookI_app_new",
"Malan1863/NOTGPT",
"Mudxyl/openai-community-gpt2",
"sakhrearasp/Asalichatbot",
"JonatasVale/openai-community-gpt2",
"WalidEAGLE/ShakespeareanGPT2",
"Andreaerre/PubliChat",
"FxxMorgan/Benjamin-Talk",
"mxiean/Final_project",
"atasturdy/ysda_hw4",
"khushidhar1210/KML",
"Priaas/SmartReconcilers",
"hbulduk/siberzorba",
"SureshKumarParamasivam/SureshKumarParamasivam",
"DoingNothingAI/DNai_chat",
"nada116/mytestspace",
"Vitto213213/GPT-2",
"Maximilien-Ier/First_agent_template",
"maya323/chatbot",
"AIBotsForYou/My_Chatbot",
"amrutux/healthllm",
"Anupam007/OfficeAutopilot",
"danielnashed/finetuning-llms",
"Pavan-Mallela/Chatbot",
"ai01firebird/Emojinator",
"rikoliva/tinytiny",
"xDemian/Space",
"rikoliva/gopoem",
"karagmercola/csm-model-demo",
"dominic1021/LatentSync",
"demet167/deneme",
"CalebGarcia95/smart-resume",
"gio484/AI_Story_Generator",
"Bhavibond/ContextAwareAdaptiveSG",
"ssppsy/gpt2-demo",
"SnehaRavichandran/Prompt-To-Image",
"NativeAngels/TasiaExperiment",
"Bhavibond/ContextAwareDreamInterpreter",
"sakshi7502/SVFT_PEFT",
"dominic1021/echomimic-v2",
"Ranjani19/EmotiQuest",
"NathanAW24/GitGlimpse",
"harshi1008/chatbot",
"andyjosh/test",
"Yntec/Image-Models-Test-March-2025",
"mikabev/openai-community-gpt2",
"aswerdlow/unidisc",
"Ronakparmar/Leap0",
"Bhavibond/AIWordSculptor",
"Moon11111/Avatar2.0",
"Yy050117/sentiment-analyzer",
"salomonsky/flux-pro-uncensored",
"Dissever/ssspeed",
"yash1161/Stable-Diffusion",
"Yy050117/mental_health_app",
"rsalehin/gemma-demo_1",
"Alithhh/Farhangian",
"Sumsmksk/openai-community-gpt2",
"raulmmorais/LatentSync",
"ybhavsar2009/woundview",
"Bhavibond/CognitiveWordSculptor",
"khushidhar1210/KML_new",
"Bhavibond/CognitiveFocusTextGenerator",
"humair025/openai-community-gpt2",
"humair025/openai-community-gpt2001",
"VenkataManoj24/AI-Personal-Email-Assistant",
"AkshayS123/advanced-ai-sandbox",
"Ranjani19/Roamio",
"48leewsypc/SillyTavern-Extras1",
"carrotcodes/College-Essay-Organizer",
"bep40/LatentSync",
"aismaanly/test-llm",
"amasood/transE",
"agnixcode/prompt",
"AIdeaText/Lab1UK",
"AmbassadorWm/AIBibleAsisstant357",
"Sernane/Sernane",
"Sernane/Sernane2",
"nxbisgin/llamat3chat",
"Hjgugugjhuhjggg/gguf-editor",
"Moaaz94/Space2",
"GG-Techo-25/Technosys_chatbot",
"ss4923/nlp-toolkit-gradio",
"treyisrael/finsight-chat",
"Kakaarot/Gemma-HuggingFace_TextCompletion_Demo",
"khubaibilyas/GPT2-Based-Chatbot",
"ajnx014/Context-Aware-QA",
"drg31/llm-deepfake",
"Rahulbaberwal/Next-Word-Predictor",
"jameszokah/jamiya",
"splaytj/IT-4490-Prototype",
"Guderoshitha9/ai-voice-buddy",
"Onsk/nayatora",
"Madhu011/programming-concepts-chatbot",
"Kakelel/Writter",
"repana/tuitor",
"repana/TUITORAPP13",
"repana/TUTORAPP1313",
"patchbanks/pop-rock",
"Svedd/ogatutat",
"patchbanks/neural-breaks",
"Viduna/openai-community-gpt2",
"lachiesmart/story-to-values",
"Emoboy8601/EB_ai_GPT",
"patchbanks/trap",
"patchbanks/house",
"sphinxsolutions/filter-removal-dspy",
"Lightuxx/Kahoot-System",
"sad050das/community-chatbot",
"abdullah12100/LLM_assistant",
"pets123/sesame_openai",
"Antronius/aipokemon",
"iisadia/transformer-visualizer",
"heboya8/demo",
"alexandrosnic/ros_gazebo_agent_space",
"mgbam/Researcher",
"polinapodozerova/youtube_comments_gemerator",
"Grorian/GrorianSpace",
"devmanpreet/Medical-GPT2-Classifier",
"benkada/IAAimages",
"RISINE/socal-ai-fashion2",
"raniesolarevisky/ChatTesteLN",
"AkzholAues/ai-email-marketer",
"MateoMarthoz/Group-3",
"abhinand462/exp10",
"Praty54/Tech9_assignment",
"Nymbo/tokenizers",
"avasilii/miyadzaki",
"ZainShahzad/Zain-workpermit",
"ZainShahzad/work-permit-generator",
"imvaibhavrana/bio-med-gpt",
"usamaJabar/FIrst-Aid-Injury-Treatment-Recommendation",
"ardances/resume-ai-backend",
"PoojaPoo/blog-writer-ai",
"Lamfair/GAMA",
"Alterb123/semantic-aacV2",
"mudassir111/transformer-visualizer",
"mudassir111/transformer-model-explorer",
"ShivamArya/pythonCode2Docstring",
"jasnoor54/Project_new",
"iqramukhtiar/sentencetokenization",
"schand17/sahil-textgen-app",
"marianvd-01/transformer-visualizer",
"manveen123/manveen_text",
"Ankushqwer/GENERATE",
"Niharika217/AI_POEM.IMAGE",
"jitujangidbki/Dostgpt_ai",
"BD07/logical-reasoning-game",
"Aranwer/Transformer_Visualization",
"WillemVH/ChatGpt2",
"Prometheus799/VR",
"SameerArz/OFA-VQA",
"rahideer/Transformer",
"Aranwer/LegalAssistantChatbot",
"galori/tortoise-tts",
"Neha13/AI_Content_Detector",
"amansingh-ai/caption-generator",
"jcsancho/LatentSync2",
"Maryisa-w-13/Teen4STEAM",
"rondabike/s7abi-aii",
"suku9/smiles-tokenizer-package",
"siddani93/TradingViewSuperChart",
"sravani0189/AI_Tutor_Interactive_learning",
"kunal89/gpt2-text-generator",
"Puggle10/ai-chat",
"Apb026/GenAI",
"aryankumarrai/gpt2-fastapi",
"suryakolluru28/deep",
"ankitchandel09/SexyReality",
"gunz0007/chatai",
"stevewuwen/gpt2",
"skesava/GPT2_Arch_TestApp",
"Rubbers/Silvia_openai-community-gpt2",
"Rubbers/VICKY",
"charliebaby2023/infnapitoggle",
"arshad1234321/Text_to_Multimedia",
"Gateblue07/Discovery_Space",
"hanzalaraja/Data_Analyst",
"shashibindra/book-writer-ai",
"shashibindra/testing2",
"Lambeckkk/Musicappp",
"lululalalily/Hello_nswer",
"kkppppp/GPT_coder",
"Trinisha30/AI-Powered_Multimodal_Story_and_Poem_Generator",
"slayton22slayton/infnapitoggle",
"Khelendramee/stocker",
"Ajeet001/ChatBot_Gpt2",
"GS-DIVYA1/PROJECT",
"Satyaaakash/Technical-Documentation-Assistant",
"Vaishnavi0404/text_to_songgg",
"GG-Techo-25/interactive_chatbot",
"mengtoa/CosyVoice2-0.5B",
"arubenruben/Quantization-Attempts",
"quonciu/work",
"MatheusHT/Testonildo",
"ashvithasaravanan/PT2",
"JeanCGuerrero/Question_Answering_Nutrition",
"KUSHALIRAJA/Deepvista",
"KUSHALIRAJA/ptproject",
"chjivan/Joblytic",
"Daisyyyyyyy/Nikon_Z30_Insight_Club",
"hskwon7/classification_test",
"JSY8/Storyteller-1",
"smrup/Recommender-Bot",
"Ashvitha08/pt2",
"ashvithasaravanan/genai",
"ai-dragon-app/dragonbyte-ai",
"shinstarrjh/admin-site-chatbot",
"Aidar1015/Aidar1",
"udayanand/Narada",
"ttusharvermaa/instagenius",
"armelmbia/CC_NLP",
"Heksan/social-media-generator",
"jubayerkhansr/openai-community-gpt2",
"aloksamyotech/ai-blog-writer",
"Heksan/test",
"110-31/horoscope",
"Ryan980306/RGE",
"amaansksz/Intromate",
"BoierGPT/boiergpt",
"Uthar/TestgroundPub",
"DavidNgoue/cc_NLP_NgoueDavid",
"maurinet/formula-finder-ai",
"richardseattle2025/tortoise-tts",
"saherbellal/world",
"Priyanshu007/Excuse-Generator",
"mentalmystery94/xsales.ai",
"Richardzcssscca/yumichat",
"vishnuspace/vr-social-media-ai",
"Vikhrmodels/DOoM-lb",
"k050506koch/GPT3-showcase",
"Elie237/cceliebea",
"agnixcode/capstone_project",
"BoojithDharshan/jaypt2project",
"puseletso55/township-chatbot",
"bryancarsan/viral-hooks-generator",
"muhammad-mobeen/LatentSync",
"AGAlienF0/Kishak",
"h4sch/any_coder",
"abdullahsajid0/Newchatbot",
"Abhi0420/Basic_chatbot",
"Jarvisazhar/Jarvis",
"jjy01215/chatbot",
"aieeeeee/MoodBoard-AI",
"aieeeeee/brand-visualizer",
"dfiyoutobd/Utogpt",
"niyano17/ProtectWaterAndMarineLife",
"szfiz/fitnessApplication",
"Omare46/Ochat",
"Rick610/TalktomeaiV2",
"AliNajdawi/testone",
"vatistasdim/ai2",
"juancamval/graph_generator",
"tsphan/llm-token-counter",
"bor/counting_words",
"reinashi/DynamicTales",
"HEwaxira/GPT2-exper",
"armelmbia/CC_NLP1",
"hamza-101/RecipeAdvisor",
"alim7897/PitchGenerator",
"Kenjihilasak/agenticRAG",
"thong0710/SAIF",
"Dc-4nderson/streamspace",
"DialloWill/wordsmith-gpt2",
"Kenjihilasak/agenticRAGpilot",
"charlesbg/cadeauecole",
"ashish-26/assignment_13",
"GG-Techo-25/without_pdf",
"ashish-26/assignment-13",
"kinzarani489/age_calculator",
"sarah111920/kaskas",
"Raja412/Gradio-App",
"charlesbg/iachatgptecole",
"charlesbg/dockeriaecole",
"xs2fahad/PMEX",
"xiehuangbao1122/KKKK",
"Kevinarnold/Botpicaro2025",
"umerghazi/WZTC",
"abdelrahman12012/dr.waleed2",
"acmc/ss-prompts",
"A-keven/Motivational",
"GSV2000/co2",
"omkartidke8080/Audio-To-Text-QnA-App",
"Hadesking1105/chatbot",
"Hadesking1105/chatbot_1",
"Vin012/asd-chatbot",
"Prashast7/Datacake",
"jzhucl/testSteamlitdemo",
"ylingag/Storytelling_Application",
"ansonc88/ISOM5240_IndividualAssignment",
"Mtkhang90/PEC_QuizApp",
"GSV2000/fsd",
"P4ULO/Consultorio_Snap",
"butterr12/chatmypdf",
"ZeeAI1/ABC3",
"ApaCu/OpenApi",
"snehithakotakala/ml_notebook",
"LAJILAODEEAIQ/officechat-sd3.5-large",
"Synnnwastaken/chatbot",
"Omare46/Ochat-chatbot",
"silent12122/DashAi",
"Gangadhar123/gpt2-text-gen",
"GotsysAfrica/Gotsys",
"GSV2000/pensamientocritico",
"DavidNgoue/SN_NLP_M2_Ngoue_David",
"SmileMask/YouTube_Automation",
"ainulyaqinmhd/SpatialReasoning",
"itznadee/ai-text-humanizer",
"Jalilmalik62/QUIZ",
"RaghuCourage9605/Custom_LLMs",
"Vvvalen/Wonder_Whispers",
"akashroy545/AI_agent",
"Jalilmalik62/Quiz_app",
"Jalisabrown18/superhero",
"saimkhan11277/Research_Based_Summary",
"Leo66277/magic-story-box-pro",
"arceus8765/openai-community-gpt2",
"Ton241/ModeloTransformers",
"rosendit079/ingles",
"Netvvv/Net",
"Yussifweb3/mymodel",
"royonetheway/Ai-E-Book-Maker",
"royonetheway/Ai-ebook-maker",
"royonetheway/E-book_Maker",
"royonetheway/openai-community-gpt2",
"Arun-VS/Final_Assignment_Template",
"hasansdq/ragsys",
"AmeenWajiha/Wajiha",
"Vansh001/Myaichatbot",
"abdullahalioo/babar-azam",
"DianaMarcela/personalizacion-campana-cardiaca",
"uswlbasster/MagicPrompt-Stable-Diffusion",
"d23064/petensi",
"Solobrad/Agentic_HF_AI",
"emguan/project7_playground",
"meedas/clinic-ai-generator",
"becaliang/SentimentAnalysis",
"lino661/ImageStoryTeller",
"vapretito/cosyvoice-app",
"alteria1/my-ai-assistant",
"Kremon96/video-dubbing",
"itzbhav/mental-health",
"ahmetp/hikayeolusturucu",
"Wizard1971/Agent",
"kevalfst/visionary-ai",
"drowdancer/extrasneo2",
"drowdancer/extrasneo3",
"Betul1526/pigaaichatbot",
"John6666/TestgroundPub",
"tbharath234/BharathGPT",
"phucleo093/icagori2o",
"alienet/BookWorld",
"Julk271/EcoB_Mail",
"archnilux/app2",
"Marsipu/textgenerator",
"28lah/ronaldo-storytelling-ai",
"Rakesh2205/Chatbot_Multi_LLM",
"TLH01/Tlhassignment",
"moss1234/class_std",
"xingyu1996/tiger-gpt2-chat",
"jqiuap/ISOM5240-1",
"qwqe11/fairy-tale-ai",
"jqiuap/isom5640",
"eleax/individualassign",
"jqiuap/1",
"jqiuap/storytelling",
"jqiuap/Tellstory",
"dekimi/Final_Assignment_Template",
"Fluospark128/Mind_Aid_Demo",
"Sohamb2005/excusify-app",
"jnguy097/FinalProjectPush",
"osangni1001/gpt2",
"muawiyaa/Synthentic_data_generator",
"joehare/ragmuffin",
"juanmackie/YourBench",
"dishant989/Linkeninpost",
"Jalisabrown18/coins",
"Shanulhaq/AI-IELTS-Preparation",
"AmineAIData/movieAvailabilityAgent",
"jnguy097/RPGCharCreator",
"voltron123/LLM_AI_Agent",
"cbspace/gpt",
"Naveedepe/Brandbuilder",
"inf-x/ai",
"drmohamedgamal1/egyptaionart",
"arterm-sedov/agent-course-final-assignment",
"ovenan/gerador-de-ideias",
"pinkul/chtglm-test",
"ovenan/gerador-de-ideias-video",
"mschae11/TextGeneration_GPT2",
"maria355/Ai-genius",
"Gk1509/garage",
"nzjsdsk/xiaozhi",
"DarfOfficial/TalkToDarf",
"cartman2k5/crime_scene_analyzer",
"dschandra/Question_And_Answer",
"Toumaima/my_customisedAgent",
"heboya8/tortoise-tts",
"sergiojmc/ChatBot",
"schogini/llm-token-explorer",
"samdak93/qrit-api",
"Abdalfttah/Fettako",
"LeenAnabtawe/ai-codegen-app",
"LeilaDennaStaiger/SLPsTalkTech_Interactive",
"prudhviLatha/pop_corn1",
"Muhammad-Umer-Khan/OpenChatGPT2",
"chandu-123/Chandana",
"chandu-123/cchandana",
"neeraj0604/chatbotScratch",
"turkfork/Aero-Testing",
"hassaanrasool55/animegenai",
"adan012/Writing-Assistant",
"Jocme/finalvbot",
"mafube/smart",
"Chandandr/resumeboost",
"maasiwa/hearoappspace",
"Fredy-brayon9/ai-description-assistant",
"mdshabeer/test",
"TeknologyGroup/distillation-space",
"huggyThree/spaceY",
"Jaswanth0217/AI-Image-Captioning",
"Adhiren/emotion_care",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"Varshawww/AiSPN",
"sramesh3/openai_test",
"TNSA/NGen3s-Stories",
"skgiles07/bai_ft3",
"marcosremar2/llama-omni",
"skgiles07/pirate_pub_chat",
"roshanbhai/roshanbot",
"cymatt/AutoModel-Autotokenizer-App",
"Waqar55111/Song_Seeker",
"PCAM/velox",
"abdehakim/vpn-chatbot",
"Raiff1982/CodetteVision",
"eemmoo123/guess-who-ai",
"eemmoo123/guess-who-ai-3",
"zerishdorelser/image-analysis",
"AnonimChicken/SketchAI",
"oberoi12/xeno-ai",
"Ayush28022004/Zomatogpt",
"Ayush28022004/zomatochatgpt",
"AmEskandari/decoding-demo",
"rahimizadeh/Log_Assistant_Application",
"tkowalski29/test1",
"e-commint/MuseTal",
"kevalfst/docker-space",
"maikevin/testbed-01923910",
"Kremon96/voice_clone-2",
"Cxfer/RoastMaster-3000",
"NithinAI12/NITHIN_AI_2.O",
"diablood/cw-hr-chatbot",
"p3rc03/2B",
"Atharv18J/poem-generator",
"MapMisfit/Neo4jHuggingfaceFlow",
"ozan123/Benimprojem",
"ozan123/projemiz",
"mervebyrk/MuseTal",
"dingjr/my-sentiment-app",
"henryliiiiii/nikon",
"Leo66277/Bank_Feedback_Topic_Classifier",
"Vx2-3y/NCOS_S3",
"rjnitt/sample",
"komalphulpoto/Voice_To_Text",
"Franciscounisierra/GeneracionTextoGPT2",
"rahulvaish/Storiestack-Tiny-LLM",
"torinriley/ARC125m",
"testteJF6787IA/test",
"Kirigaiya/LLM",
"Harshal0610/my-gaia-agent",
"P1radeep19911/My-Chatbot",
"Noor25/simple",
"emori1968/AutoGPT",
"Shadow0111/AI_Lavoro_Futuro",
"habibahmad786/abc",
"merrillaudio/Music_Midi",
"gkcnaz/future-mirror-ai",
"gkcnaz/future_mirror",
"gkcnaz/mirror",
"Shadabur-Rahaman/Gpt2-finetuner",
"schogini/GPT-2-Token-Inspector-Self-Attention",
"kartik1221/gpt2-api",
"jinv2/gpt2-lora-trajectory-demo",
"JLLG/LatentSync",
"Fali1212/globalstatsol-Platform",
"muhammadanwar-31/Civil-Engineering-App",
"Mun33biqbal/chatbot_for_research_",
"sxanskiy/aiperexbot",
"Jasssy17/Mental-Check",
"Manuel989/PrintingPress",
"jatinxyz/jatinsxd",
"Orlik/pichu",
"Lps02/Alice-backend",
"EntropyGain/Prompt-Chain",
"tarkpatel/Chat_With_PDF",
"Npatil/basic_Ai_Agent",
"daniel83fr/First_agent_template",
"Saritza/Test_chatbot",
"nekkobean/Recipe_generator",
"Hadi1211/Hadi-ki",
"AhtishamFarooq/Ppra-Procurement-Assistant",
"maru212/PPRA_Proc_Advisor",
"XFuryus/CatAI",
"maru212/Procurement_Advisor",
"AUHaq/ScholarshipGenie2",
"viddushiva/my-ai-agent-demo",
"thalesFidelix/unibloom-gpt-api",
"gampala1234/checkphi3mini",
"Kai171/Roast_bot",
"koyalmyna/content-generator",
"koyalmyna/Content-generation",
"Thegoals/demigod-ai",
"Bebeyonddigital/Ds_digital_marketing_bot",
"Erica12345612/weibo-sentiment-app",
"eyepyon/rcdemo1",
"doga8524/Dogatest",
"doga8524/dogatest2",
"pradeep4321/gradio-bgi",
"mali6/genau-demo",
"ludofar/YinShi_finetuning",
"schogini/embed-and-pos-encode",
"PAblo8919/michatbotformal",
"AIdeaText/v5Dev",
"Arslan7/chatbot_basic",
"Rupok0199/Monowar-AI",
"docteurmozz/audioldm2-perso",
"ughu/gpt2-generator",
"Tagomorikun/GPT2Generator",
"velolxd/ia",
"arthurlouette/my-space",
"gampala1234/0111",
"Ronaldodev/fastapi_django_main_live",
"apatra06/rag-ticket-summarizer",
"Imran012x/gpt-2-chatbot",
"Malvinhaparimwi/empower-bot",
"Malvinhaparimwi/empowerbot-server",
"younassadat/Birthday_AI_Agent",
"economics-25/economics-professor",
"HIM1244/deenai",
"HIM1244/dawsda",
"HIM1244/cftjyh",
"HIM1244/DeenAIrefined",
"Eudoxia21/BookWritingGPT",
"nagbisafae/llm-demo-gpt2",
"nagbisafae/llm-demo",
"arashebr/DistilGPT-2",
"peramruthvika/Text-Gen",
"abhishekp21/Final_Assignment_Template",
"schogini/embed-and-pos-encode-code",
"sumedhbhagat/tranformer_from_scratch",
"Madiharehan/lecture-notes-app",
"mdubang96/ask-sirdube-gpt2",
"0X100/Ml-huggingface-Docker",
"builderlai/test",
"Santivs06/e-coomerce",
"adityasen1hl/pilltickr-nlp",
"M3003/TextToVideo",
"g0th/image-to-song-lyrics",
"Jamshid0307/Generator",
"swaleha19/agent_tuning_framework",
"diegotluz/CosyVoice2-0.5B",
"spectrebrain/harry_potter_llm",
"vladimirc/frajtag-sinopsis-checker",
"lol040604lol/NeoProcure",
"zarahmer/Ai-SEO",
"oKen38461/M2TlatentSync",
"Suzana/prompt_playground",
"sreepathi-ravikumar/tortoise-tts",
"Vimallazzar/Vi-GPT",
"rickeyemma00/rickey",
"schogini/embedding-positional",
"nydilegr/mygpt",
"Drago1995/AI-New-Question-Generator",
"idroid007/ai",
"kimikajai/kurikula-demo",
"rythem253/MyAi",
"neuralworm/GPT-Identity-Evaluation",
"BAAI/EmbodiedVerse",
"sabahoth01/task3",
"mirxakamran893/kamranIQBOTLC",
"duwa656/Text-Starter",
"Vineetha00/llm-chat-assistant",
"AIdeaText/v5Prod",
"Zeinab911/test",
"Alpha0169/gpt2-textgen",
"dhruv78/GPT-124M-ScratchBot",
"AWIEPL/mro-poc",
"das1mtb56/yt_trans",
"supriya1991/my-text-gen-demo",
"xxdottoro/lkpoai",
"dw2026/Cv2-0.5B",
"swapnilpopatgaikwad/predict-next-word",
"dheerajreddykarrasathkrutha/empathetic_chatbot",
"gayatrichittabathinaSathkrutha/generate_cover_letters",
"Syncbuz120/testCaseGenerator",
"mike23415/Meme",
"ThieLin/Workspace",
"DmitryRyumin/BiBiER",
"DumbsterDrekk/Agent",
"LunarBs/DarkGPT-API",
"Goutam03/image-captioning-app",
"Alfievarghese007/InspireMe",
"hamidfadaei/ai-stereotype-watch",
"Abdullah43/AI_Chat",
"FrankyBravo/my-agent-space",
"kemuriririn/Voice-Clone-Router",
"prarthanastephen/multi-tool-chatbot",
"yatoontop/Example",
"WAVbot/RVC-MAKER",
"Lukefdeds/Xelya",
"corsia/text-generation",
"corsia/spazio-pippo",
"auri001/text",
"krsoleg/oleg",
"AIAgentforDI/WFM",
"aurelia-virgone/FLEBot",
"mibrahimzia/AI_Powered_Proposal_Generator",
"DrDamiD/Psicometrista",
"vivnatan/AIDA-react",
"yatoontop/wwwwwww",
"marcosremar2/cosyvoice",
"Archiaa/chat",
"kemuriririn/CosyVoice2-0.5B",
"Leku/Trial2",
"Michel-25/meu-deepseek-test",
"akash093/llm-probability-loop",
"codingSarvesh/study-ai-tool",
"Predator911/NomadMVP",
"Syed-Adnan/A-mused",
"eugenepiggy/LatentSync",
"Safore989/Nova",
"jahnaviP04/my-gpt-api",
"ApocryphalEditor/SynestheticVoyage",
"jajangnr31/coder",
"DeepImagix/self-trained2",
"mtdgloble/seo-title-generator",
"anshz3iijhtyretg/chat.ai",
"schamizo/diario-emocional",
"darsh-reddy-v/talentscout-assitant",
"kimmanduck/Hugging-Face-Spaces",
"vaibhaviandhale/Happy",
"ReProgs/Disaster-prediction-AI",
"GAMEMASTER13/mein-gpt2-chatbot",
"Agents-MCP-Hackathon/video_mcp",
"yale-nlp/LimitGen",
"alokiitm/alokparadoxworkshop25",
"abdemota/gpt2-textgen-space",
"Tomtom84/dev-mode-orpheus-tts",
"gabrix00/grammarllm",
"gsaltintas/tokenizer-comparison",
"welher/LatentSync",
"happyuser123321/my-chato",
"Spanicin/cacauavatar",
"ArshBN/arshgpt",
"viniciu016/Viniciu_ai",
"daivikneogi/transformers_sample",
"Alwx7788/CHATBOX",
"Agents-MCP-Hackathon/HuggingFaceDoc",
"NoorHA/tinyllama-watermark",
"Ashwinpatwa/Questionpapergenerator",
"NLarchive/mcp-gr-token-counter",
"alihaider37/semester-project-text-analyzer",
"alihaider37/text-analyzer",
"Doaneer/Truong",
"Agents-MCP-Hackathon/ChessLLMAgents",
"Ashwinpatwa/QPgenerator",
"Shiwii/text-completion",
"Ocks/LLM",
"andrewmoreno/negocios",
"dubsblue26/DataHub",
"lordimpi/recetas",
"andrewmoreno/negociosaaaaso",
"svjack/LatentSync_ver_1_6",
"AndaiMD/brainbench",
"Br4masura/AlignedIris",
"naxemCDA/AI_Assistant",
"pranjjj/Vanilla-Chatbot",
"Aatcharya/storygenerator",
"TransformingBerry/Raddino-GPT2-Chest-XRAY",
"phpcoder/ZimEngage-Chatbot",
"phpcoder/zimeng-chat",
"hardiktiwari/tensora-autotrain",
"davy13k/HERMES",
"krisalyn/sample",
"Ab971/HIRA",
"Slime0629/ellie-math-demo",
"speako/cosyvoice2-server",
"Priyadharshini10shab/gpt2-story-generator",
"SHN199/JETOJSHPKBOT",
"ulvsno/cat_bot",
"Imthiyas/texttttt",
"Imthiyas/dd",
"sangita1998/MYCHATBOOT",
"kavithabasker/kavi",
"Srinesh10/career-mentor-bot",
"Ekocak/visionary-verse",
"meryem2013/kartbot",
"NoorHA/tinyllama-watermark-paraphrase",
"arunim1/remrofsnart",
"Hugescoot/AgentGrader",
"AlekMan/HSE_AI",
"saksh-d/Recipe-GPT",
"ivangabriele/trl-sandbox",
"sumanth914/ai-tutor-stem",
"mirkodandrea/MIDI-GPT-inference-docker",
"Dhom1/IllegalAd",
"gaurav98/my-textbot",
"anaseem/AstroPurr-Robot-Designer",
"bhanuprakashnannuri/text-generator-bhanu",
"Mdgouse02/WEBYT",
"sahilawatramani/crime-analytics-backend",
"bhanuprakashnannuri/text-generator-nannuri",
"Hariniguptaemmadi/StorySpark",
"Swaranvenkitesh/swetha-ai",
"a3shapcom/ar-article-generator",
"zelenke/telex",
"LTTEAM/LatentSync",
"Letiiicha/sarcasme-detection",
"alicia1905/mon-chatbot",
"Adillega/AdIlleagal",
"deadven7/Fashion_AI_Darzy",
"Enderchef/AI-Leaderboard",
"Naksh7/Lyric_Gen",
"missolifant23/marketing-copy-generator",
"zooyaho/chat-ai-dating-app",
"aplussystem/apluscrm_article_generator",
"danieljonnarth/Klara_test",
"AndaiMD/braingpt_implement",
"Aezichain/junk_tresure",
"tapanyemre/philosophy_llms",
"Viviktha07/MrRoast",
"puyokura/trpg-gamemaster",
"harshdhane/ShivaAIAssistant",
"hwi0201/myspace",
"zu4425/text",
"willsh1997/next-token-predictor",
"alanferris/Transformer-in-2-hours-Yep",
"Daniel1303ZH/mvp-sentinel",
"skadush5232/gerador-readme-ia",
"ashwinipatwa/QPgenerator",
"Affan44/AiCTT",
"lacos03/Article-Summarizer-Image-Generator",
"VVKSudheer/Sportscoach",
"ramkrishna1/AI_story_generator",
"DreamGenAI/jayas-ai-generator",
"DreamGenAI/jays-AI-generator",
"DreamGenAI/Jaya-ai-generator",
"d2n1z/multi",
"Pritam02021/seo-generator",
"EMTAK1/EMTAK",
"admin-hiewa/harry-monday-motivation",
"Prajan007/AITextGenerator",
"drmilanpopovic/AI-model",
"shridharrathore/talk_to_doc",
"hou12q/sample-leaderboard",
"SerhioD/kateAISpace_v.2",
"Siri012/image-to-story-app",
"Ragstone/chatGpt2",
"vaclavrozhon/probabilistic-lenses-widgets",
"gpantaz/athnlp2025_tokenization",
"Khyatikhandelwal20/blackboxscan-demo",
"issamlaradji/omniscient",
"akanish/vlm",
"sunny10505/mistralai-Mistral-7B-Instruct-v0.3",
"dranxer/Ragg",
"ShrutiJoshi/meal-planner-ai",
"Elsieiiiiiii/why-major-checker",
"Aniket2012/experiment",
"lavanya121/AI_Powered_Patient",
"JacobWP/language_app_Jacob_WP",
"DavidNgoue/SN_NLP_Ngoue_David",
"seanerons/cambridge-chatbot",
"JacobWP/langauge.app",
"Devang404/nuclear_gaia_agent",
"seanerons/demo-chatbot",
"seanerons/demo3",
"Ahmedhassan54/English-llm-Chatbot",
"jgleaves7/prueba_AI_engineer_Gradio",
"ulab-ai/RoutePilot",
"Denish2346/my-ai-assitant",
"nigelhys10/mnk",
"masteranshu/my-resume-maker",
"artush-habetyan/vibe_sip",
"TransformingBerry/CDGPT2-Deployment",
"rajanazneen3/formativeassessmenthelper",
"sksameermujahid/propertyverification",
"LamiaYT/gaia-llamaindex-agent",
"RuthvikReddy45/smart-ai-assistant",
"LamiaYT/Gaia_Llamaindex_Agent",
"NeoPy/SongGeneration",
"vika4433/nlp-text-analyze",
"Jascoh2025/DSTOK2025",
"natkin178/TokenizerSwitch",
"YanaGabelev/TokenLab",
"Oshrattamam/Tokenizers",
"shlomiav53/Tokenizer",
"AvishaiTsabari/Tokenization-Stemming-Lemmatization",
"YuvalGoldman/tokenizer-app",
"Tinkabellaa/Hiiii",
"John-Jiang/starfish_data_ai",
"truonganhdung810/dog-name-app",
"RLikhitha/EDUTUTOR_AI",
"riu-rd/contact-center-operations",
"slurpio/myGen-AI",
"deekshasoota/mygenaitext-generator",
"prajyot2003/gpt2-text-generator",
"lovepreet01/gpt2-text-generator",
"Sanjay1203/gpt2-text-generator",
"kushi0002/gpt2-text-generator",
"millyjain88/gpt2-text-generator",
"Rivan1220/Rivan",
"krishna34-aimlcurious/AI_ML_CURIOUS",
"millyjain88/text-generator",
"kushi0002/text_genrater",
"kushi0002/tech_chatbox",
"millyjain88/text-generator-app",
"aravinddev02/ai-syllabus-gen",
"likhitha-gunneri/EduTutor-AI",
"Riley-01234/Riley-AI",
"DharavathSri/LLMFineTuningDeployment",
"kushi0002/AI-Assistant",
"lovepreet01/MindMorph-Spaces-generator",
"Yadav122/llm-ai-agent",
"OdedEf/Interactive_Language_Processing_App",
"viofer/Chat_With_LLM",
"soiz1/stable-diffusion-prompt-generator",
"DharavathSri/ChatGptStyleLLMChatbot",
"Shri-75/Ai-project",
"Shri-75/Gemini-project",
"thecadMunik/university_chatbot",
"Tb2003/Ai-Chatbot",
"chiraggupta8769/free-veo3-ai",
"waize333/ChatBot-pro",
"krishna34-aimlcurious/speech_app",
"vwvwvwvwvw/tarot-ai",
"txh17/work1",
"ArchCoder/federated-credit-scoring",
"Banglagpt1/banglagpt1",
"Goutam7555/Vigoxai",
"krishna34-aimlcurious/AI_TWEET_GENERATOR",
"darkkhan461/afridi",
"Abisha2005/Personalized_Knowledge_Base_Assistant",
"vika4433/text_processor",
"Shubham1068/readmeGen",
"poewilson/Gaelic-Guide",
"Shubham1068/readMe",
"liaherring/text-generator-app",
"amiresfed/littleassistant",
"amiresfed/esfed",
"tarkpatel/Chat_With_PDF_sec",
"SQCU/attn_shift_demo",
"fayezzouari/beaglemind-rag-poc",
"RIT27/AI-ASSISTANT_ONLINE",
"zohaib2834/ai-nlp-assistant",
"sukanya05/smart-research-assistant",
"AyamUwUh/chatbot_skripsi_tes",
"BUBBY34/ai-assistant-rag",
"anu151105/agentic-browser",
"mn500mn/sentiment-muneer",
"Maymonah/TrailTrekdDemo",
"sajidrazak/Final_Assignment_Sajid",
"alexspoto/askYYGS",
"Lokesh7d/text2textwithDockers",
"DataThree/InstaCap",
"GRSS29/chatbot-streamlit",
"Taidat/GCU_Course_Adviser_Chatbot",
"openfree/SEAL",
"hitanshu-tandon/TextGeneration",
"anixlynch/textgen-app",
"dnanetwork/eco-education-companion",
"kkppppp/GPT29",
"rohit-hf-25/text-generator-gpt2",
"JacobWP/SpaceOfApp",
"JacobWP/LanguageLearningSpace",
"navid72m/securedocai",
"lanwudawn/bigwork1-leaderboard",
"azranazulku/azra-chatbot",
"Albaarghheuuebh/Infinite",
"zjzshyq/test1",
"lavanya121/PatientFollowUpAgent",
"rachumallupavan/tokenisation",
"PakeezaKhalid/AI_Based_Book_Review",
"Navya-Sree/NLP-Playground-with-Hugging-Face-Integration",
"theflowercat/cosyvoice2-server",
"Surendradjh/Sentiment_Analysis",
"LTTEAM/Veo3Audio",
"kushi0002/Text-Generator",
"ZaighamRaza/Study_Planner_streamlit",
"Ayeshashakeel25/story_creator",
"MalikAyaanAhmed1123/AI_story_writer",
"hzaidi677/agentic-travel-planner",
"Michiczi/gpt2-textgen",
"ahmadsanafarooq/Multi_Task_NLP_app",
"Manikantabandi/chatbot",
"Vaishnavi1206/emoji-sentence-generator",
"qilimazaluodexue/text",
"Kinza-rana-123/PuzzlePop",
"alex5757/techyaz",
"ArthyP/technical-rag-assistant",
"Thursdayschild/ai-story-generator",
"gedela/text-classification",
"satyakishan/healthclinc2",
"zay12121/Free-AI-Detection-App",
"chavezord/hk",
"FloresRSS/alyachat-space",
"godling/my-text-generator",
"Vaishnavi1206/Wikiyatra",
"work-sasi-kiran/ai-story_generator",
"jnyst1985/gaia",
"sigridveronica/ai-news-analyzer",
"satyamkurum/gpt2-storygen",
"xxcttn/LatentSync",
"xxcttn/LatentSync3",
"jeyjey-01/NEIRO",
"MaithiliG/headline-generator-gpt2",
"raveESCOBAR/ali_99",
"raveESCOBAR/STORY-WRITTER",
"SaqeebMomin/tokenization-visualizer",
"raveESCOBAR/Story",
"arneshchauhan/gpt-22",
"fasihh/TextGeneration",
"antoblandon/mi-ia-programadora",
"mmoua89/broth-bot",
"hardbanrecords/Hardban_AI_Writer",
"SanthoshReddy18/ai_product_description_generator",
"snorfyang/token-visualizer",
"Kunal5678/resume",
"philosopher-from-god/MagicPrompt-Stable-Diffusion",
"hardbanrecords/Hardban_AI_Editor",
"sameenAmer/waetherapp",
"pdf-bot/keerthitask",
"Genchief/Debate_agent",
"pushpender1043/Multilingual_Speech_Translator",
"Dub973/meeting-summarizer-egpt",
"Dub973/basic-conversational-agent",
"amit098/legal_lens",
"1MR/Mychatmodel",
"hardbanrecords/hardban-ai-daw-musicgen",
"ramzan118/RAG-Project",
"Uwaish/blog-generator",
"neerajkalyank/waterbodies",
"meghana1516/Recipe_Generator",
"Ksr1830/ai-strategy-dashboard",
"BlurryFace04ss/Try",
"mr2along/free-veo3-ai",
"nomtonton/assistant-candidature-ai",
"seonglae/CorrSteer",
"MuzzammilShah/NLP-Playground",
"Kushalmanda/Diet_planner",
"sohnaeo/travelot",
"premmukund/regshbsuejgbesurlgbserluigbesrfiugbuelsigb",
"gertum1/nlptown-bert-base-multilingual-uncased-sentiment",
"yanwai13/seo-test",
"gunktra/KKAChatBot",
"likhitha-gunneri/ShopGenie-AI",
"DD3Llii/Demo-Ham",
"milanmor/MajorPlato",
"likhitha-gunneri/Wallmart",
"kushalemi/intelligent-excuse-generator",
"MEVI1/Chatbot",
"HenriqueBraz/AiiTServices",
"So66/Gpt2",
"maxorange/MagicPrompt-Stable-Diffusion",
"LennyInTech/LatentSync",
"Fenleus/Llama-Meal-Planner",
"ndk211/instruction_finetune_gpt2_big",
"DhimanG/prompt2magic-aiwriter",
"Bushra346/Advisory_chatbot",
"Afifi00/Flask_n8n_Workflow",
"sairaishaq/advisorychatbot",
"IrinaArevalo/image_captioner",
"mattritchey/docker_dash",
"Minnimaro/modelEval",
"Ravi1234554321/chatgpt.com123321",
"ndk211/classification_finetune_gpt2_small",
"griddava/pull-request-validator",
"startupgig/code-builder-ai",
"Ansareze/domain_specific_NLP_model_for_indian_recipe_generation",
"K00B404/convert_to_gguf",
"crmsolution/CRM_Doctor",
"Aishani03/FakeNews-Detector_Generator",
"krishnasoniai/int",
"UmraFathima/Caption-generator",
"avciTheProgrammer/code-generator",
"taylap/ai-text-generator",
"Aishani03/Fake_News_Generator_Detector",
"TarSh8654/Own",
"efrat-dev/Chatter",
"Priyanshi1112/ai-story-generator",
"dubeyatharv/excuse_generater",
"Kavya1111/KAVDEV-FUNCHAT",
"TarSh8654/Modified_tool",
"hariniguduri/image_to_recipe_generator",
"madhvi1994/Your-Physio-Assistant",
"Dub973/nlp2sql-space",
"Dub973/text2sql",
"smastan7864/Testing",
"Michaelteacher/lesson-generator",
"QUT-GenAILab/next-word-predictor",
"KishoreKutty/app.py",
"Nemo1233333/nemo-ai",
"EduBot-v1/falcon-ibam",
"lihaoxin2020/critiq_gen",
"dev7halo/token_calculator",
"ajinaji6110/chatbot-api",
"Michaelteacher/Lesson-planner",
"peterrand/Mel2",
"Youssef-Koabari/Agent",
"Mtmoez/reprup-ai-test",
"qubychatbot/quby-ai-backend",
"Amit-hgf-29/reddit-persona-generator",
"Wplotnikow/edu_bot",
"Sparkysparo/EmotionAlchemy",
"nepcoder82132/tbcai",
"Cityzen09/system_intelligence",
"faizaaska517/llm-attack-tester",
"Kushal0099/AI_Peom_generator",
"Abhinaya579/rag-app",
"sumitkothiyal/image-to-story-ai",
"tacab/tacab_ai",
"ecesude/chatbot",
"Jpmiquelito/EES-Engenheiro-Sistemas-Sustentaveis",
"rntc/leaderboard-test",
"Uwaish/wordtodef",
"WorldforgerAI/npc-generator",
"Umanzz/chatbot-uman",
"MohanaPriya200/DreamSynth",
"PrashantKumarSingh/gpt2-chatbot",
"O-ken5481/AvaterTolk_bgk",
"Shalini-13/First-ai-demo",
"Lory226/miage-gpt2",
"aqibali06/AI_Resume_Cover_Letter_Builder",
"ADIL2006/script-generator-v1",
"ArthyP/enhanced-rag-demo",
"tk-prg/emotion-transformer-bot",
"rbz84/n8nconnection",
"dangod12z/BrianAiZ",
"aiengineerspecialist/CourseMorph",
"Sefat33/VOICE_AI_COUNTRY",
"Ruusheka/ReelKast",
"SilentProgrammer/NeuraVerse",
"mlopez6132/nano-coder-free",
"sharika99/kuchBhi-bot-v3",
"TechNo-Logic/Image_detection",
"WuziPosha/WuziAi",
"zexxadev/BOT_AI",
"Maxfaster/ocr-qa-gradio",
"NdiagaSarr/Human_eval",
"micheldouglasonline/informatica",
"ashu2401/myaiapplication",
"CoachReno/jesus-generation-coach",
"micheldouglasonline/easycomp",
"Harshit4705/AI-Story-Generator",
"muhamedFarag300/gpt2-coker",
"bobostudio/transformers-playground",
"prashantsh/demo_space",
"idvxlab/EmotiCrafter-Demo",
"user4460/test",
"epazar2020/epazar-llm",
"simar13/social-caption-generator",
"simar13/social-caption-generator-new",
"meera341/flight-booking-chatbot",
"Loschejr/Jejdjdd",
"architaaaaaaaaaaa/mad-philosopher",
"cavomo/my-Ai",
"DavidYuliaG/pirate-chatbotk2",
"sumit042/like_predictor",
"kaybeeOmo/StoryComposer",
"pallaviramsaran/textgenerator",
"KHADSESOHAM02/rocko-v1",
"KavyaPoojaryyy26/AI-product-identifier",
"jinu0804/AI_BOOK",
"Ntdeseb/ntia",
"testingportals10/ebook-generator",
"NaruseShiroha/gguf-editor",
"rm-lht/lightrag",
"webaifda/webgpt",
"faizaaska517/Trojai_demo",
"azkaabid/text-generator",
"Raisa92/AdvBench-Demo",
"vaclavrozhon/llama-adversarial-attack",
"Khaled12sszx/My_space",
"URCristiano/MindMate",
"Kotochka/FOMAI_XAI",
"Aloct94/alointel",
"gundeveloper/text-gen-demo",
"Taidat/GCU_Chatbot",
"TanushriS/thermosense",
"venuv2204/student-ai-app",
"ahmedsqrd/model_trace",
"bubuduuuubist/hallu",
"hardiktiwari/hook-preview",
"Ntdeseb/NTIA-PRO",
"wilred/WILAI",
"priyasreekrishnan/SimpleTextGenerator",
"migueljoie/miguel-joie-ai-assistant",
"Sabir94/islamic-post-bot",
"HaiderNadeem/AgroPulse",
"runtzxx/week3test",
"rayanps55/ai-art-quote",
"SundusYounis/genai-churn-dashboard",
"rayanps55/ai-art-quote-rayan55",
"raizi19/chef-camila",
"Aroob-Mushtaq123/InsightMirror",
"R-Kentaren/Gemma3-R1984-12B",
"tansilatha/gpt2-chatbot",
"vigneshyadala/lokkala",
"Aashish2552/Aashishchatbot",
"saranisam/chatbotgenai",
"AriAI1/tortoise-tts",
"DenBayou/Kritis-ai",
"AdityaSindhu/Buddy",
"OSR555/me555",
"Kartik009hg/mini-genai-colab",
"Arni1ntares/WinnerApp",
"almogra/AI-powered-car-recommendation",
"TuringsSolutions/GEPA-Prompt-Tuner",
"maheshsmc/image-story-generator",
"PARII72/airayad",
"PARII72/pari",
"Carlex40/LatentSync",
"stutipandey/SkincareChat",
"Nullpointer-KK/llm_project",
"kfoughali/serpent",
"Minorah/art-prompt-generator",
"AiCoderv2/Ai-data-generator",
"AiCoderv2/Legend-King",
"LeSmithBro/mygenai",
"Next01/Next-Assistant-ChatBot",
"quotexhlp/prompt-to-website",
"9voltfan2009/RVC-MAKER",
"Cryox/astroxai",
"aloshy-ai/deep-job-seek-mini",
"osamaahmedkhan/Workshop",
"nero7151/SPOON-AI",
"ojaslko/sanitation_bot",
"sandeep43/custom-agent-sandeep",
"Dove97/Review-Classifier",
"almogra/Wolt_Food_Recommender_PRO",
"ReynierHG/OkanIA",
"owlninjam/openwebui",
"hekuma/Namaskara",
"Flux9665/LatentSync",
"Raisa92/gpt2",
"Javeria45/test2.py",
"pratiktester/chatgpt-blog-title-generator",
"Houzeric/text-to-mermaid",
"Javeria45/test3",
"faizaaska517/gpt2",
"MaxPrestige/test",
"ykdavid/OnlineInformationRetrieval",
"SoggyBurritos/Spam_Classifier_Agent",
"fdfdfddsfdfdfd/Musicgen",
"Basu03/personal_excel_interviewer",
"sukanya15/genbridgee-voice-ai",
"abhinavyadav6397/social-media-post-generator",
"Gilvan/XRaySwinGen-RMMM",
"Shivanjali20/SnapScribe-AI",
"hellord789456/roommate-matcher-ai",
"Gtgstg/gaaliGPT",
"Gagan442005/PromptSculptor",
"romancao22/video-game-review-analyzer",
"utsab-adhikari/gpt2-space",
"Debito/mamba-encoder-swarm_app",
"gaur3009/beer",
"pragyna31/Text_Generation",
"paramasivan27/LLM_Product_Classification",
"Paulo1474/TrendAI",
"bluethinker25/talking-robot-monkey",
"cutteels/Noesis__Ai",
"Ukhanyo/quiz-generator-ai",
"DINESH-DATAPRO/health-care",
"HemanM/EvoConvo",
"tatikondavrindaa/Text_Generation",
"NokuthulaN/educational-materials-generator",
"plvictor/Phi3Mini",
"tc1024/ivla-phi2-assistant",
"momosun/gpt2-from-scratch",
"therooms/gemma",
"Lucasssssssawa/Lucas_Ai_demo1",
"kpomservices/ai-chat-web-page",
"solidjoe/AI-Poetry-Generator",
"LCTDEVELOPERS/aibabyname",
"Mehrdat/healgentic",
"Eliasnasser/lama",
"Stormbreaker17/Slm",
"Mehak-Mazhar/Chatbot_for_Content_Generation",
"BolaNash/openai-gpt-oss-120b",
"vishaljoshi24/trl-4-dnd",
"Lesekete/ai_business_name_generator",
"factorst/NEWORLD",
"Mehak-Mazhar/StoryTelling_App",
"Divyanshct24/resume-reviewer-genai",
"factorst/NEWM",
"LaneF/64m-training-space",
"nick-pavic/my-agent-project",
"surajkum/AI_Resume_Generator",
"ginigen/FLUXllama",
"engfatoom/school-assistan",
"KamalnathS1719/TamilAI-Chatbot",
"TheHuriShow/RecipeWizard",
"Bilal-ali09/my-gpt-app",
"P22TF/text-generator-demo",
"devByByron/Visi0nTechSpace",
"devByByron/VisionTechSpace",
"gtyv68f6d567d/MangoAI",
"HarisFaheem12/gpt2-textgen",
"SohamSSarkar/postpilot",
"grilish11/xavi",
"Subnaut5482/Ai_game_creator",
"dxmouh/talk-to-dx-mouh-ai28",
"hferreiraaaaa/gradio_demo",
"DarkxCrafter/Test",
"duygiang/giangpd1",
"Shiva8164/Email_Spam_Classifier_Using_Custom_GPT2_Model",
"Mehak-Mazhar/FitBuddy",
"SmartAIBot/SmartAI-Bot",
"Humphreykowl/art_fashion",
"kingsmanhome/69core",
"YuvrajSingh9886/StoryKimi-Zero",
"TheHuriShow/RecipeMaster",
"Nofarsagi123/RecipeWizard",
"skipper12123/ai-detect",
"asmhashenry12345/gpt2-text-generator",
"yasserrmd/LegalGPT",
"Alpha108/AI_lead_generation",
"skyoi1212/ai-detection",
"Pranuuuuu/Pranathi",
"rverma0631/MATH-GPT",
"Pranuuuuu/my-gpt2-chat",
"daltron/ChatGPT2_Bias",
"daltron/GPT_History",
"YuvrajSingh9886/StoryLlama-Zero",
"Nihal2000/autoSLM",
"AIDreamMaker/TVhostAI2",
"BHAYASH04/Synapse-AI",
"nailag/health-advisor-chatbot",
"cosasparajoelito/CHATGAMEGPT",
"YuvrajSingh9886/SmolLlama-Zero",
"Divyansh515/gpt2-medium-sentiment-demo",
"Nkheso/Content-Generator",
"edcol909/Testing",
"Niwin07/1",
"dressasan/DressasanAI",
"ozodbekpanjiyev/Gpt2",
"jmjoseph/talktuner-probe-training",
"jmjoseph/talktuner-auto-training",
"TheHuriShow/TravelAdviser",
"techmew/factcheck-tweet",
"GinorajhR/legal-doc-explainer",
"Kingseal/kings",
"shiffman-tests/babbleGPT",
"morfriden/TripAdvisor",
"osamabyc19866/amamal",
"sufisoul/AI-Joke-Generator",
"sufisoul/ai-joker",
"nlpengineer/space2",
"vinaymanchala/Gen_App",
"Prathamesh1420/Mazak_manual_chatbot",
"lemms/openllm",
"anhbilong/PROJECT",
"surahj/chat-bot",
"maldons77/text-generation-demo",
"godling/my-gradio-app",
"vovxb/yash",
"oz11/my-text-generator",
"god05212/MyGradioApp",
"Cosmo125/GPT",
"PeppermintSnow/dungeonmaster-llm",
"maniwebexppro2025/gpt2-api",
"amber1907/smartyai",
"udaysankarjalli/AnotherExample",
"sujith1450/2ndexample",
"newlearner-w1/assignment-demo",
"SpaceNinja007/Chikion_AI",
"RxMECH4NO1R/AI_3",
"KutisBayag/DFW_Expert",
"saagarikas/Code_Archaeology_Tool",
"fknuette/LLM",
"vbrajon/whisperlivekit",
"rachumallupavan/test",
"Guilbert12/MinhaPrompt",
"sanjaypuvvada/firstapp",
"LucaR84/SmollLLMRest",
"SPYBOTH/translation-app",
"Sahil5112/Companion",
"SARMAD2310/my-colab-bot",
"AdvancedAPI/getproject",
"mljagne/Naive-RAG-Chatbot",
"seshaanil/Text_Generation",
"Shiva8164/Custom_Instruction_based_GPT2_Medium_Model",
"Blackrose-Blackhat/MVP",
"udaysankarjalli/BasicTextGeneration",
"code5ecure/Yavar",
"Geniuss123/OtterAI",
"iftekher18/DietTrainer",
"dlamini-amk/impact-rag-assistant",
"ahmadsajidpro/MySocialMediaAssistant",
"henrient/EXPUN",
"iabubakkar/CAPTIQUE",
"mahesh1209/voice2",
"dev-arpit5462/med-buddy_",
"jyoti210303/quiz-question-generator",
"ran014/MedPredict",
"LucidMinds3ye/Lucid",
"ZENLLC/opensourcegym",
"Rock2666/Train",
"thisanie/my-gpt2-space",
"ASLP-lab/OSUM-EChat",
"npaleti2002/PetComics",
"Agnuxo/nebula-x-benchmark-dashboard",
"Acuboost/royan-ai-stylist",
"Nobita2536/riya-assitsnt",
"mithunkrishnan03/Guvi_multilingual_chatbot",
"mehreen125/AI_Pregnancy_Assistant",
"mssaidat/tryinghard",
"Aryanshanu/RAG",
"ion74/chatbot-sl",
"muthuraman3112/initial_space",
"astralpilot/text2mdparser",
"Fred808/INV",
"mssaidat/imapro",
"MichaelAI2025/Michael",
"bhavyaGP/my-text-gen-space",
"rbiswas01/asst_teacher",
"Tejash9/Desi-Drama-GPT",
"anilx95/anil-generative-ai",
"Ziapro12/illa",
"suswin/research-gap-finder",
"baku666a/art_text_detection",
"shelarswwapnil/Swap",
"reza81/prompt-builderpro-web",
"EUIA/LatentSync_ver_1_6",
"markchapman522/etsy4",
"Somalarajurahul/CAI_ASSIGNMENT_2_G61",
"dgith/PersonalizedLearningRecommendationSystem",
"Riy777/Mod_money",
"Samanvitha08/remo",
"kvmy/convAI",
"MrUnknown420/my-ai-model-builder",
"winter930722/midilm-1.7B",
"oomayhnit/My_first_AI",
"Arslankhan7/Thesismaker",
"AKKU07/gpt3-text-generator",
"gnvsn/cai-group123-assignment1",
"iyadalagha/ai-text-detector-app",
"RameshKolipaka/simple-ai-agent",
"RameshKolipaka/multi-ai-agent",
"RameshKolipaka/multi-ai-agent-with-memory",
"nutrientartcd/recipe-ai-fastapi",
"usmannasir9989/Caption-GeneX",
"mithunkrishnan03/guvichatbot",
"Aber99/telegram-bot-free",
"muthuraman3112/Rag_with_text_generation",
"TUCKER1303/NLP-Education",
"gabriel1109/chatbot_multimodal",
"patrjfjfkfr/Julia-browser-Agent",
"JavierGuio/textGenerationStudio",
"Shaheerkhurrum/shaheer-free-gpt2",
"DILEEP2223/Instagram-caption-generator",
"Hm4326/myai-chat-image",
"M-Rajeswari/eng-tel-story-bot",
"BetaGen/Image-Generator",
"shahriar99/poetica",
"raisahab86/text_generator",
"raisahab86/textai",
"raisahab86/aitext",
"rider-provider-777/training_bench",
"Abanoubsamir92/NTI_PromptUnderstanding",
"ClaCe/FindHugForPMwithKey",
"shiva1msk/StudyMate",
"NickAi88/SocialPlus",
"proeditor/VerseCraf",
"Binaypradhan21/SAFe-agile-coach",
"professorjefferson/distilgpt2",
"abhiram000/wwwwwww",
"Tsunamisingh/vllm-prefix-demo",
"Mrloser/My-ai-novel-maker",
"Mrloser/Ai-Novel-maker",
"HuzaifaUrRehman/Typing-speed-tester",
"hamidmaei/rl-ai-coding-agent",
"to0ony/final-thesis-plotgen-app",
"22btrdc047/dashboard",
"aradhya178/Final_Assignment_Template",
"Julio3333/Iafinancias",
"Sri012/Python",
"Charlievox/BotTwit",
"Saivivek25/myspace",
"Saivivek25/my-data.txt",
"playfulrhymesinsta/moodpulse-ai",
"sajjansingh/GenAI"
] |
[
"mit"
] | null |
[
"en"
] | 137,022,720
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"GPT2LMHeadModel",
"gpt2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null |
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en"
] |
[
"Pretraining: Causal Language Modeling (CLM)"
] |
Partially disclosed: unavailable
| 6
|
658fb85235c41262d661dc48
|
TinyLlama/TinyLlama-1.1B-Chat-v1.0
|
TinyLlama
| null | 1,591,653
| 19,166,301
|
False
| 2023-12-30T06:27:30Z
| 2024-03-17T05:07:08Z
|
transformers
| 1,384
| 13
| null |
text-generation
|
{"parameters": {"BF16": 1100048384}, "total": 1100048384}
|
[
".gitattributes",
"README.md",
"config.json",
"eval_results.json",
"generation_config.json",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1519,
3196,
608,
566,
124,
2200119864,
551,
1842767,
499723,
1289
] | 2,202,470,207
|
fe8a4ea1ffedaf415f4da2f062534de366a451e6
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
<div align="center">
# TinyLlama-1.1B
</div>
https://github.com/jzhang38/TinyLlama
The TinyLlama project aims to **pretrain** a **1.1B Llama model on 3 trillion tokens**. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs 🚀🚀. The training has started on 2023-09-01.
We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
#### This Model
This is the chat model finetuned on top of [TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T). **We follow [HF's Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha)'s training recipe.** The model was " initially fine-tuned on a variant of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat) dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
We then further aligned the model with [🤗 TRL's](https://github.com/huggingface/trl) `DPOTrainer` on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contain 64k prompts and model completions that are ranked by GPT-4."
#### How to use
You will need the transformers>=4.34
Do check the [TinyLlama](https://github.com/jzhang38/TinyLlama) github page for more information.
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# ...
```
|
[
"eduagarcia/open_pt_llm_leaderboard",
"fisherman611/gaia-agent",
"Vokturz/can-it-run-llm",
"cvachet/pdf-chatbot",
"NCTCMumbai/nctc-pdf-chatbot",
"bhaskartripathi/LLM_Quantization",
"muhammadarash/NeoBot-Free-AI-Chatbot",
"Invescoz/Server-B",
"Sharathhebbar24/Open-LLM",
"Alfasign/Mixtral_8xgguf",
"Mediocreatmybest/TinyChat",
"diggum/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Deepak250/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"trueequals/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"TobDeBer/TinyChat",
"alihs/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Alperencaca/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"zyhui98/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Abrarrrrr/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Nesdub/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Vishwak1002/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Taranosaurus/Tokenizaminer",
"DANSONY/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"sh20raj/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"adildhkh/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Maximuth/tinyllama",
"FlorentFerrere/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"RobertCastagna/FIN_LLM",
"truongghieu/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"sotosbarl/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"zped/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"blanczak/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"HiveerLi/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Mohit21/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"LikhonScripts/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"LikhonScripts/TinyLlama",
"Jav0/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Nymbo/TinyChat",
"ziffir/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"erknvl/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"philippedelia992/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"greenarcade/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"vishalvvr2/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"bhargavj0shi/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"TinyLlama/tinyllama-chat",
"catworld1212/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"HPiDATA/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"liuzeeast/liuzeeast653",
"TheMaisk/TheMaisk_tinychat1b",
"amiraaaa123/docbesmiallah",
"Tomoniai/Tinyllama_Chat",
"whutxd/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"TuringsSolutions/3-Tiny-Llamas",
"sdafd/ChatBot",
"roexetis/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"jezv/cmd",
"youngitachi/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"void6670/tinyllama-chat",
"Nymbo/tinyllama-chat",
"emilalvaro/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"killick/wintermute",
"Heng666/tcml-chatglm-chat",
"dazai555/model",
"Miday/MyTinyLlaMa",
"TeamTrack/Test",
"mlawson/AutoTaskv2",
"am1rd/NeuralStreamer-I-Space-soup",
"thobuiq/Tinyllama_chatBot",
"dave0/QuizRabbi",
"kr9025/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"BeveledCube/bevelapi",
"jakec4488/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"kleverson/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"basit123796/Llama2",
"soubiracharya/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Kvikontent/Llama-7B-Chat-UI",
"electriceccentrics/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"bardsai/performance-llm-board",
"Em-Be-Aa/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Araeynn/lyre",
"LeNaM/Text_Generation_AI",
"rumbleFTW/d-RAG",
"Tarunpreet/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"JulienNawak/MyLLM",
"OnyangoF/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Mz33/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Mosesgw/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"pongngai/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Antonio49/tinyllama-chat",
"inflaton-ai/tinyllama-chat",
"os1187/ChatPDF",
"seryeni/llm-tinyllama",
"captain-awesome/Chat_with_any_website",
"MasterMohan/PDFChat",
"santuchal/pdf_chat_bot",
"lunde/solara-esport-highlights",
"Jaman/openLLMs-RAG",
"sumanthkv/pdfchatbot",
"Arcypojeb/pdf-chatbots",
"Wasima/pdf-chatbot",
"vishwask/rag",
"FroggyQc/tinyllama_chat_gradio",
"sanchitm/pdf-chatbot_Sanchit",
"Ubai/pdf-chatbot-opensource-llm",
"Nymbo/pdf-chatbot",
"Alfasign/pdf-chatbot-opensource-llm",
"Nymbo/LangHub",
"shubnimkar/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"AamirAli123/chat_with_pdf",
"ys-nat/pdf-chatbot",
"Ashmal/MobiLlama",
"RajatChaudhari/QueryingLangchainPaper",
"Intel/powered_by_intel_llm_leaderboard",
"wcj02/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Munes787/labotv2",
"Munes787/labotv3",
"awellis/pdf-chatbot",
"BigSalmon/AbstractTwst4",
"gtlYashParmar/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Felipe02/Quotation_extractor",
"m-ric/attribution_visualizer",
"Felipe02/test",
"iv-dimova/travel",
"ToonTownTommy/jjoojj",
"ali121300/pdf_chat_bot",
"Sambhavnoobcoder/pdf-chatbot",
"namanroxx/pdf-chatbot",
"Qazi-Mudassar-Ilyas/PDKnowledgeBaseQAusingRAG",
"Nymbo/can-it-run-llm",
"pvporwal/vinod_llm_test",
"nirajandhakal/Talk-To-PDF",
"rianders/mpi_data_store",
"atlury/pdf-legal-chatbot",
"klavyelibey/pdf-chatbot",
"ryan0303/requirements",
"ryan0303/requirement_compliance",
"pcuenq/cpuarch",
"rishabhjain16/tinyllama-chat2",
"rishabhjain16/test-space",
"MLynOwner/Instagram_Caption_Generation",
"thesnak/chat-pdf",
"3DTopia/3DGen-Arena",
"awacke1/PDF-Document-QA-Chatbot",
"Qazi-Mudassar-Ilyas/EnterpriseRAG",
"santuchal/only_chat",
"shionhonda/reviewer2-bot",
"joepyro/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"yes2code/pdf-chatbot",
"Akshayram1/pdf-chatbot",
"AbdelhakTali/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"K00B404/pdf-chatbot-teacher",
"Prajith04/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"InvestmentResearchAI/LLM-ADE",
"j2moreno/who-is-leo",
"Sergey-wa/pdf-chatbot",
"kaustavnandy19/QA-RA-app",
"curiouscurrent/OmniCode",
"AhmedMagdy7/can-it-run-llm",
"vijayagrawal/philipsdemo",
"egefraser/NLPWomen",
"sdxl12/pdf-chatbot",
"awellis/rag-chatbot",
"faruqaziz/chatbot_diagnosa",
"skanda12/pdf-chatbot",
"iDrops/pdf-chatbot",
"Ahtisham1583/Pdf_to_chatbot",
"Akshayram1/pdf-edi",
"Sankalp25/pdf-chatbot-comp",
"BharathGM123/pdf-chatbot",
"JeeLeanChinese/PdfCitiesPolicy",
"anubhav100rao/pdf-chatbot",
"Vigneshwaran-D/pdf-chatbot",
"Vigneshwaran-D/pdf-chatbot1",
"Kartik2503/cost-estimator",
"hexml/chat-with-pdf",
"Yoxas/testrun",
"JoaoCunha/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"gfdagfdg/pdf-chatbot",
"anezatra2/test6",
"rraangga/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"rajivmehtapy/DevEnv",
"Namitg02/DiabetesPilot",
"KalishAyish/somali-pdf-chat",
"Prachidwi/PDFmultiple",
"erinwolff/endpoint",
"ari-in-media-res/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"kkasiviswanath/sample-app-one",
"rishi0258/llm-prediction",
"anasmarz/startup-ecosystem",
"zicsx/DocAI",
"vetrovvlad/protobench",
"Parth211/rag-model-v1",
"K00B404/RAG_Chat_with_websites",
"Karani/pdf-chatbot",
"Karthikeyan-M3011/Cartesian-Bot-TinyLlama",
"funnyPhani/testSpace",
"tangbentcltest/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"abhirup7/chatpdf",
"Dovakiins/qwerrwe",
"zhaozengxi/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"JustAPR/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"malvika2003/openvino_notebooks",
"ruslanmv/convert_to_gguf",
"Bofeee5675/FIRE",
"malvika2003/INTEL",
"omarakwah/Grad_Project",
"testser2/Test",
"batlahiya/urban1",
"wy233/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"batlahiya/t2",
"raghu8096/pdf-chatbot",
"li-qing/FIRE",
"RobinsAIWorld/can-it-run-llm",
"Akshayram1/vit",
"OmkarMurthy/pdf-chatbot",
"TuringsSolutions/Qwen-2.0.5B-Swarm-Function-Caller",
"danalytix/chatbot-tinyllama",
"evelyn-lo/evelyn",
"Issactoto/therapist-latest",
"totosac/therapist",
"Pavan178/pdf-chatbot",
"CCCDev/PDFChat",
"mathbatistela/kor-doc-chatbot",
"Sivnds/TinyLlamaRaw",
"askari1122/Nira-chatbot",
"zjasper666/bf16_vs_fp8",
"iDrops/pdf-chatbot-test",
"RaptorSteins/Retrieving_with_RAG",
"wolfpaulus/sl_demo",
"martinakaduc/melt",
"Jeff28/CipherReadPDF",
"christinathattil/CHATwithPDF",
"tanayIITian/chat-with-PDF",
"veechan/LLM_RAG",
"astro21/ds4",
"yogesh69/BMD",
"Sergidev/Pennyalpha",
"Akshayram1/sarvam_api",
"Akshayram1/api_test",
"JiakaiDu/RAG_Test",
"thongnguyen5999/mama",
"blacknight3113/pdf-chatbot",
"farmax/pdf-rag-chatbot",
"coalms/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"ElObredor/testing",
"vinmay1234/SynapseEd",
"medmekk/BitNet.cpp",
"warless/RAG_application",
"CamiloVega/NewsIA",
"Presley10009/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Presley10009/Chatty",
"lightmate/llm-chatbot",
"Sarath0x8f/Document-QA-bot",
"atlury/edgellms",
"Nymbo/BitNet.cpp",
"mrarora/LlamaService",
"Rsnarsna/pdf-chat",
"saradotdev/AI-ChatBot",
"Veerammal/Pdf_chatbot_for_CBSE",
"MNGames/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Veerammal/sync_pdf",
"RAMYASRI-39/nctc-pdf-chatbot",
"walaa2022/financial-analysis-system",
"ShahbazAlam/pdf-chatbot-pub",
"vuxuanhoan/anychat",
"API-Handler/test_api",
"logeshnusic/pdf-chatbot",
"AItool/ServerlessInferenceAPI",
"AliArshad/BreastCare",
"walaa2022/financial_analysis",
"SIQCALI/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"neelumsoft/Document-QA-bot",
"Hobmo/Nexus",
"walaa2022/fin_analysis",
"cstr/PDF-Summarizer",
"azoodle/Haiku",
"Mackintoshj/anychat",
"pranav1212/TOY-GPT",
"BeingShashi05/PDF_ChatBot_By_Shash",
"monica1d/chatbot",
"mariamgvelesiani/anychat",
"yalotaibii/anychat",
"ilovemystagename/anychat",
"cpu4dream/llava-small-open-elm-aimv2",
"lokeshwarans/pybot",
"shahiil/laptopRecommendation",
"Jebin2005/Jebz_CB",
"shahiil/laptopRecommendation1",
"shahiil/RecommendationChatbot",
"Jebin2005/Jebzx_Cbt",
"shahiil/Lap_CBT",
"pranav1212/PDF-ChatBOT",
"ali-vilab/IDEA-Bench-Arena",
"jljiu/Space-A",
"morangold1/vacation-rental-assistant",
"bujowi/tinyllama-chat",
"Prgrmmer/ai-dungeon",
"Veerammal/Pdf-GEnie-chat",
"Veerammal/PDf-GENIE-CHATT",
"fiber6942/llama-chat",
"Onoroyiza/tinyllam-calmz",
"orYx-models/tinyllama-Demo",
"AdithyaR2115/hackpyrag",
"manavagrwl/api_bot",
"slahiri/global-million-gdp",
"arun2565/newllm-ai",
"nananie143/advanced-reasoning",
"sushibait/test",
"Mister12rayyan/RYanychat",
"mpvasilis/can-it-run-llm",
"Starchik1/anychat",
"alperall/TinyLlama-TinyLlama-1.1B-Chat-v1.0.gardio",
"nnilayy/powered_by_intel_llm_leaderboard",
"wylum/ETD_Chatbot1",
"Jafar99/NeuroGen_Rex_Web",
"mfrng/whisper-transcription",
"Starchik/CodeBox",
"tvibes/deep",
"DHEIVER/pdf-chatbot",
"DHEIVER/pdfchatbot",
"awacke1/Deepseek-HPC-GPU-KEDA",
"Dargouls/pdfchatbot",
"AhmedDEV/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"coldramen/ai-receipt-extractor",
"KalkiInfinity/Collison",
"GB87/tinyllama_firstdeploy",
"Robostar/french_ml",
"lmcnova37/Chatbot",
"MichalisCYP/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"markshep68/MLPchatbot",
"LucianStorm/Tiny_LLAMA_Assistant",
"Mopium5/data-analysis-through-deepseek-r1",
"ElidevOS/Holiaa",
"PhilippSpohn/tokenprob",
"FaiziK/ResearchChatbot",
"ek0212/llama-chatbot",
"KBaba7/Quant",
"Bofandra/letter_generator",
"antaniantani/provaAPI",
"totolook/Quant",
"Ayush2004/Mental-Health-Chatbot",
"ethiotech4848/experimental",
"akshita1107/yt_trans",
"wylum/ETD_Chatbot_LLAMA_",
"umutyananer/mistral-cv-chat",
"Somnath3570/LLM-request-response",
"Xpoiop/H_chatbot",
"Neglosz/My_project",
"HussRash/First_agent_template",
"EvoProx/kinises",
"hich966/GUNDI216_Search02",
"pgoyanka/rag",
"NathanPap/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"ogi3433/whisperApi",
"indrapurrnama/purnamai",
"Francescogiraldi/IKIGAI",
"kanupriya01/sample-app-test",
"Unclejunkie/pdf-chatbot",
"akashshahade/talk-to-pdf",
"tingdaggg/recipe_assistant",
"belalyahouni/TinyLlama_Chatbot",
"gmz1711/Leeruitkomsten",
"wiseproffit/ROOBs-TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"jake2004/Timetable3",
"Comos19/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"shanfei/AIStorytelling",
"Shamem0801/FinChat",
"srmlover/bruhma.ai",
"rawadbs/RetailAssist",
"rawadbs/Retail_Assist",
"ipd-now/healio_alpha",
"janushex/AIenergy",
"zalphas/tinyllama-chatbot",
"robertgil/First_agent_template",
"vbmokin/tiny-llama-chat",
"WesanCZE/Assistant-AI",
"Lovitra/HackNight",
"bh4vay/comicVala",
"bh4vay/comic",
"wiseproffit/TinyLlama-ROOB-ai-Neu2025",
"Guru0304/pdf-rag-chatbot",
"joy1515/Case-AI",
"CR7CAD/Assignment1",
"anuttamac/financialrag",
"Ultron3000/PersonalProjects",
"sailokesh/Hello_GPT",
"shanfei/ParrotStory",
"bvrgsk6/cai-group29-a2",
"javimarlop/pdf-chatbot",
"giampaoloranaldi2369/Zenone",
"EkaSurya1998/financial_chatbot",
"dine422/cai-group29-a2",
"2023aa05958/CAI2_Assign2",
"MuhammadHaaris278/Riddle_generator_trained",
"FallnAI/Quantize-HF-Models",
"baneman/Group_103_RAG_Chatbot_Re_Ranking_with_Cross_Encoders",
"adzee19/Storyteller",
"sthawani/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"as32608/rag-app",
"shripriyanga/CAI_gp_86",
"Hardik5456/Wan2.1playground",
"blessingh/CAI-ASSIGNMENT2",
"chkethley2/tinyllamatrainer",
"K00B404/LLM_Quantization",
"hackergeek/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"Taizun/Drapel",
"rahuljuneja657/NexAI_CSM_Demo",
"Hangar1d/AlexAI",
"Omprakash75646357483/Chatbot_maker_backend",
"pradeepjangirml007/News_flask-api",
"FirozPrabisha/tinyllama-ollama",
"conanana/testing123",
"Njongo/Evolution",
"Omprakash75646357483/Chatbot",
"Georg4000/Octagon",
"nyasukun/toxic-eye",
"Rulga/status-law-gbot",
"omegaxxx/tinyllama-chat",
"behappy092/space",
"benzaria/Med-Campus-AI",
"1tbfree/TinyLlamaOnline",
"ai01firebird/Emojinator",
"rikoliva/misgemas",
"LucaCostabile/UtopIA",
"Lordhenry/salesforce-agent",
"akashmadisetty/Test",
"Thejno/Hecate-AI-v2",
"abrotech/abro-gpt-1.1B",
"ramadanibrahim/telegram_bot_project",
"Wahyuazizi/Genai-text-and-captioning",
"be1newinner/chatbot_llama",
"KVGAGANYADAV13/FLASH",
"hlai-2023/tarot-reader",
"krisha06/Python_tutor",
"Jelmerhb/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"SeyhaLite/aihavin",
"krisha03/Python_tutor",
"abhishekpawar7218/mistral-7b-lora-adapter-demo",
"vidhan1234/HealthcareAIAgent",
"sbentley/Boston-School-Choice",
"DPAIHELPER123/Dpeducation123",
"Kishorekumar7/gradio_voice_to_image_and_text",
"RayanAli/Medi-ChefBot",
"RadimSvetlak/haflingove",
"krisha03/Python_tutoe",
"antoncarlo/HELPET-AI-AGENT",
"antoncarlo/HELPET-1",
"aa2999587/pdf-chatbot",
"harshitsingh911/alltius",
"vudangho/myfirst",
"heboya8/demo",
"Asmodeus757374/LOTM",
"mRaghu/fast-chatbot",
"dalide/her2-rag-chatbot",
"Samay1012/tiny-therapist",
"Twelve2five/qlora-llama3-finetuning",
"Sanjay002/final",
"shavirazh/copyright-purpose-song-recommender",
"imajayshukla/learning",
"henas12/all_in_one",
"rat45/sql-sft-lora-model",
"Arifzyn/akane-ai",
"iougp/HeartFix-AI-2",
"iougp/heartfix-ai2",
"katwli/bps_chatbot1",
"teenysheep/chatbot",
"Hery34/Annexx_Talker",
"gampala1234/Ai",
"ralucachintoanu/boardgame-llm-assistant",
"dosty17/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"ellawang9/bps-school-chatbot",
"laur0613/chatbot",
"felipehlvo/6S041_Boston_School_Chatbot",
"shreyankisiri/Literature",
"Conso04/Ai_sensei",
"imajayshukla/test",
"amitanand2003/Scrapper",
"sanjaykc321/chat_ai",
"SaranRaj-12/PDF_BASED_QUESTION_GENERATION_ANSWERING_SYSTEM",
"Zoro-chi/ai-creative-studio",
"alegio98/rag-insiel",
"alegio98/rag-for-insiel",
"Jadfost/legal-assistant",
"SaranRaj-12/PDF_CHAT_BOT_NEW",
"Joshua93/TinyLlama",
"gasifiwe/BPS_chatbot",
"lawrenceylong/boston-school-chatbot",
"naxwinn/AURA",
"samarth-kamble/pdf-chatbot",
"jeevakumar-moorthy/interview-companion",
"luisvoltou/Sonho",
"wuthomas/boston-school-chatbot",
"ellawang9/bps-school-chatbot-new",
"tac01/boston-school-chatbot-zephyr-simple",
"annikavi/6.S041-Chatbot",
"johnathansun/boston-schools-chatbot",
"Subrahmanyagaonkar/QueryQuack",
"sdufays/boston-school-chatbot",
"haramor/bps-eligibility",
"h4sch/any_coder",
"henas12/last",
"anmani2007/docker",
"Techbite/faq-rag-chatbot",
"uglyeleven11/uglySpace",
"getGO007/RAG-chatbot",
"thehoneybadger/JurisBot",
"sorl47/hf-agents-course-final-assignement",
"magdap116/Final_Assignment_Template",
"eduardmihai/chatbot2",
"SeleneAndrade22/First_agent_template",
"mar4su/phi2-chatbot",
"ankanpy/DocuMind",
"bianca-lilyyy128/Final_Assignment_Template",
"memofy/AI-FY",
"Firebulet/luau-code-generator",
"dipta-dataist/Image-to-Story-Generation",
"pedrofsgarcia/jurisbot2",
"Solobrad/Agentic_HF_AI",
"Tox1cC0der/Final_Assignment_Template",
"wiseforg1111/isom5240-projects",
"sashimdrEb/CVScreening",
"Hoitkn/customercomplain",
"Rakesh2205/LLM_Project_1",
"clubentrepreneurs/pdf-chatbot",
"kaitwithkwk/kwk-first-chatbot-revised",
"Julk271/EcoB_Mail",
"Swapnilbpatil/test_model_on-local",
"awesomesue153/nine-study-chatbot",
"digvijayingole55/Agent_DiNeo",
"IamRulo/Final_Assignment_Template",
"bobo666/Story_Generation",
"Drag0n101/Final_Assignment_Template",
"juanmackie/YourBench",
"AlexSoudant/Final_Assignment_Template",
"Rasheedj/mtech-chatbot",
"Angelarenotfound/AdonisExcept",
"souleima/dog-breed-api",
"lyricolivia20/LivLoRA",
"hazrath/texttotext",
"AntonioKaminski/AgentsFinalProj",
"kshitij230/VisiHealth.AI",
"Kamocodes/math",
"KraTUZen/LogicLink-Project-Space",
"pinakiz/ingredient-extractor-api",
"1Haseeb/chat1",
"Intercept-Intelligence/TinyLlama-1.1B-Chat-v1.0-access",
"alt-sr/timeline-llm",
"doublesizebed/chatbot",
"Swapnilbpatil/model_do-uplode",
"santuchal/pdf_chat_Sourajit",
"abdelghanighpgmailcom/chat1",
"s12144251/xsg123",
"anushkab0602/ayurvedabot",
"congcan/super-agent",
"dharshanre20/TinyLlama_1_1b_ChatBot",
"cdiogo/Final_Assignment_Template",
"mobixconsulting/eatc-class7-llama2",
"Baher-Hamada/Final_Project",
"hbeeb/my-ai-girlfriend",
"tandaniele/first_cahtbot_application",
"reteeter/Final_Assignment_Template",
"K00B404/ocr_florence2",
"bassommma/fastapiquestionA",
"nesunhamo/BPSChatBot",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"pandiyarajan-ayyappan/Final_Assignment_Template",
"mohit24224/Youtuebqna",
"lkAHSreh/SSSSSSSSSSS",
"ComposableConsult/RAGwith3BModel",
"ComposableConsult/ragmodelwithllm",
"shea1108/Chatbox",
"h0820617/test",
"HeartHeard/chatbot",
"yugant007tg/edith-tinyllama",
"mono212/history",
"yheye43/jglue_test",
"isilulgerr/planmytrip-ai",
"shubhamgs/RAG_Assistant_Model",
"shubhamgs/RAG_Multi-Agent_Assistant",
"ozgecanaktas/planmytrip-llm-api",
"tongyi21/AI_Novelist_RAG",
"Itz-Amethyst/Final_Assignment_Template",
"WK512/gaia-agent",
"MattHunker/mosh-and-myth",
"say4/vaital_check",
"Jatiom/llm-api",
"disu93/pinpoint",
"Wanted/WanVPNAI",
"atulisoffline/CGI-POC-with-Reasoning",
"samadjunejo/hackathon",
"Upsam/EasilyAI",
"volymax/TiLoL",
"VIMARSHDWIVEDI/dost",
"nightprogrammer/lolo",
"NguyenVangiavy/Vychatbot",
"jyotimaurya2610/Chatbot",
"MatheusSoranco/gaia-agent",
"Anupam007/CGI-POC-with-Reasoning",
"xset/aibot",
"davidgturner/GaiaAgentEvaluator",
"mtoqeerzafar/RAG_Chatbot_With_PDF_Prorcessing",
"SagarChhabriya/tinyllama-chat-unify",
"Vladx/Agents_Course_Final_Work",
"lailai1208/Final_Assignment_for_agent_course",
"eress6969/fortecAI",
"ekabaruh/Final_Assignment_Template",
"xmuruaga/Final_Assignment_Template",
"mirxakamran893/logiqcurveaichatbot",
"rudranighosh/family_law_finetuned",
"kshitij230/llm-summarizer",
"sagitovoleg/hf_final_assign",
"CiccioQuinto/MeowAgent",
"syedMohib44/AI-Auditor",
"oegbo/gaia_gen",
"Saymyname1234/mcq-generation",
"Gulten/planmytrip-route.t2",
"ozgecanaktas/planmytrip-route.t2",
"kushh108/compliance-metadata-extractor",
"gettherefast/4ther",
"ShenghaoYummy/AI-chatbot",
"Prashant26am/llava-chat",
"akilalochana/chat-hotel",
"akilalochana/my-chata",
"chandubram/chandan-private-chatbot",
"Pawan28a/Final_Assignment_Template",
"DETAIM/ingles-tutor",
"roohite/gaia-agent",
"iamkdp/chatbot",
"darkShadow-exe/atlas-aceAPI",
"Robessar/undressimage",
"AtlaSync-Int/ChatBotV",
"TestUsername1234/scraper",
"amiteisen/handson_final",
"SumitB7/Final_Assignment_Template",
"aparnamolks/fine-tuned-tinyllama-healthbot",
"Nur-Fatin/ai-tutor",
"rudranighosh/indian_family_law",
"rudranighosh/indian_family_law2",
"MINEOGO/TinyLlamaTinyLlama-1.1B-Chat-v1.0",
"zamal/Multimodal-Chat-Playground",
"diego-lopez/rag-sobre-pdf",
"Trigger82/Hmm",
"FelixSeptem/Final_Assignment_Template",
"DumbsterDrekk/Agent",
"carlos202524/InteligenciaBasura",
"FisherH/nurse-talk-simplifier",
"Lukasz50777/pdf_assistant",
"Hamzukhan/deepseek",
"juanvic/Bob",
"shruthinagappan/Final_Assignment_Template",
"juanvic/Bob2",
"Sush96/voice_movement_assistant",
"Hayabu5a/Auf-gehts",
"Archiaa/chat",
"makroumi/invoice_data_extractor_agent",
"pmshoanghot/chat_bot_pbl5",
"hfOrz/aiwriter",
"Hodely/Amside-Ai",
"phdsilver22/gaia-benchmark",
"pmshoanghot/pbl5_chat_bot_rag",
"hfOrz/airecipe",
"Anon543353/mistral-api",
"SreejaS/Final_Assignment_Template",
"VWVQWA/nuget",
"jan01/Final_Assignment_Template",
"enlightenment/resumate-llm",
"enlightenment/resumate",
"naveenadama/Excel_Assistent",
"unnati14/tinyllama-chatbot",
"Minh1310/pet-clothing-bot",
"Minh1310/bot_test_ai",
"naveenadam/Natural_Language_Chabot",
"naveenadama/Natural_Language_Chabot_New",
"naveenadama/Natural_Language_Chatbot",
"sahil-datascience/gaia-agent",
"anushkab0602/ayurved-chat",
"VIMARSHDWIVEDI/ASKYOURDOCS",
"sdfsdh/koalpaca-search-demo",
"LorenzoScaioli/Agent_3_base",
"findrmwn/Gym-Bro-Chatbot",
"Aidoost/Farsi_chat_1",
"JeeKay/PDF-Chatbot",
"YixczFab/FTMIA",
"joelim88/jl88a",
"ramnifram/ai-urlaubsplaner",
"yatoontop/thppp",
"NoorHA/tinyllama-watermark",
"BamaBoiii/AntlerAI",
"lester-tavelet715/My-Astro-Mirror-V2-app",
"Chaitu2112/chatbot",
"richardxiangzg/agora-reasoner",
"Vcollabetiq1/Vcollab",
"AyishaSiddeequa/tryllm",
"Vcollabetiq1/spac11",
"Wiefdw/ChatbotAnemia",
"lakshitgupta/tinyllama-finqa-api",
"farjadmalik/Iqbal_Poetry_RAG",
"NoorHA/paraphrasing-watermark-demo",
"SaopinMa/gaia-agent",
"vatsalm/AOT-AI",
"Sanjoy24/JobFound",
"LeBuH/ArtMatch",
"ama2aifusion/agents-course-final-project",
"jamal07/tinyllama-dialogue-chatbot",
"mischaemerson/mischa-llm-demo",
"ahmedjk34/road-watch-llm-space",
"sujal7102003/tinnyllama",
"Jack1808/Fine_Tuning_TinyLlama",
"anguswang0101/angus_ui",
"raks96/ai-workout",
"kmishra/Game_Over",
"paigesteu/Final_Assignment_Agents_Course",
"Mollen81/Juno-Helper",
"riccardomusmeci/SentimentProfAI",
"lprato/ai_i2a2_agent_invoices",
"Debanna/final_project",
"ArshitModels18/Hindi-English-Tutor",
"adiboy-23/Gita-GPT",
"hardik-0212/QA-ChatBot",
"Vats2411/fine-tunning-llm",
"muhammadali81/Health-monitoring-app-for-Elderly-Care",
"muhammadali81/Elderly-Care-Health-Monitoring-app",
"muhammadali81/Elderly-Care-App",
"akhilchint/tiny-llama-api-endpoint",
"akhilchint/NotsoTinyLlama-FastAPI-Application",
"Adityabhatia0204/chatbot",
"sematech/sema-chat",
"SreekariGattu/Career-Advisor-Bot",
"anupamm05/First_agent_template",
"lijoraju/charitra-backend",
"Darsh0816/FinHelper_Chatbot",
"blankblanklamb/Final_Assignment_Template_v2",
"srimadhan/madhan-coding-assistan",
"guptatilak/investment-analyzer-api",
"meinvlv/personal_agent_starter",
"LEILA75/askpdf",
"mojad121/Chatbot_Shopify_By_Mujtaba_on_models",
"LEILA75/chat_pdf_tinyllama_phi2",
"mahazkhan12345654321/bazario-chatbot",
"alie354/startup-journey-advisor",
"sujal7102003/igenrate",
"veteroner/NovaAI",
"orachamp1981/oracle-llm",
"amit1072/HF_Final_Assignment_Template_1",
"SPILab/chatbot",
"Alexend/Stust",
"artush-habetyan/vibe_and_sip",
"LamiaYT/gaia-llamaindex-agent",
"LamiaYT/Gaia_Llamaindex_Agent",
"Phoenix4102/Final_Assignment_Template",
"pareshmishra/MT564AITraining",
"stellababy2004/stella-ai-chat",
"SPILab/qa_bot",
"itswronit/taf-chabot",
"alambino/codeiceapp",
"liyimichael/phi3-lora-chat",
"DanteInVeritas/test",
"hibaaaaaaa/finetuning",
"varun1128/support_bot",
"aadinathdeepak/tinyllama-support-bot",
"liyimichael/pdf-qa-bot",
"SadyMady1902/EmoGPT",
"anupajose/tiny",
"jefalod/fine-tuning-bot",
"CoporateNewbieGenz/PerfectVsGenZEmployeeAI",
"martynabaran/Final_Assignment_Template",
"KIGOz/KIGOz",
"JaganathC/Smart_Assistant_for_Research_Summarization",
"zebra12341/Final_Assignment_Templatewae",
"avin-255/open-notebook",
"hdallstars/tinychat",
"Rockerleo/agentcourse",
"JaganathC/Smart_Assistant_for_Research_Summarization_copy",
"anu151105/agentic-browser",
"sajidk25/Final_Assignment_Template",
"zebra12341/gaia-agent123",
"mrsheikh/custom_model",
"fiver01/Final_Assignment_Template",
"NoorHA/paraphrasing-watermark",
"clokoihue/hf_agents_course_gaia_agent",
"hai56/gusto-rag",
"mpombo/Final_Assignment_Template",
"mrsheikh/model",
"joydeb/agent_fc",
"dannybhatt/AI_fast_api",
"mrsheikh/test",
"rifukawa/ucrg",
"mrsheikh/model_cpu",
"MasteredUltraInstinct/FallbackLLM",
"dranxer/ohkk",
"random-luck85/biblical-bot-space",
"mrsheikh/cpu",
"Zeba15/gaia-agent",
"tsissam/AI_Powered_University_of_CapeTown_Course_Advisor_Chatbot",
"kabir-mathur-999/LLM-MODEL",
"BUG6s/JasonAI",
"Satvick/ChatBot_Pdf",
"Satvick/ChatBot_PDF_",
"uhoui/ollama_serve",
"Bluestrikeai/Tiny-llama-Fast",
"Mano5108/ui-ux-chatbot",
"Stanley03/tinyllama-docx-rag",
"Stanley03/Medicalai01",
"eamemymoche/MOFwelfareAII",
"pritamdeka/Biomedical-Fact-Checker",
"rohitbarnwal/rohitgpt-mistral",
"nrmlzk/mental-health-api",
"Magarevedant/SeptOne_AI",
"ishowsewy/tinyllama-lora-qa",
"sampsong/Final_Assignment_Template",
"leBoltzmann/Final_Assignment_Adeel_Agent",
"pdf-bot/CHATBOT",
"pavan-d/Final_Assignment_Template",
"88rehaan88/crag-chatbot",
"bytebytego028/clinical-trial-matcher",
"cedricbidet/FirminBot",
"thoughtcast/tinyllama-experiment-chat-gradio",
"Beek1One/multilingual-rag-chatbot",
"sumeyyekoksal/testwiki",
"ValakiJay1706/Whop",
"B-Anupreet/Grand-Slam-Offer",
"StevePerna/GodSteve",
"mahmoudalrefaey/PDFPal-PDF-chatbot",
"Shailajagorile/g-ai-assistant",
"AKHILBudige/Smart_JobAI",
"Prasanthkumar/Final_Assignment_Template",
"SachinBairagi/Emmy_Chat",
"fahad089/Listings",
"Tejxs04/tejxs-ai",
"Pooja-2025/cybersecurityassistant",
"yassinkhoualdi/neuralfit-therapist",
"menta360/mentora-mely-menta360",
"thoughtcast/polukranos",
"K00B404/convert_to_gguf",
"rithvik6238/test",
"liyimichael/sunzhongshan-rag-bot",
"dibgerges/huggingface_agents_course",
"Phase-Technologies/Tinyllama-try",
"Phase-Technologies/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"lolkbo/openhermes-chat",
"anguswang0101/chat",
"Ank-067/Gita-assistant",
"Nooriey/Ai_therapist_Bot",
"yogeshkadam/mistral-7b-instruct-demo",
"Dronpancholi/fp-gpt-v0-4",
"pragunkutlehrria754/RAGCHATBOT",
"dorraelarem/tinyllama-api-space",
"hehelo77/deep",
"sfstrk/fitzekapp",
"shivanibadam/InterviewCoach",
"Cjieey/GCCAI",
"Syedha/kural-thunai-backend",
"Khdidij/REACT_test",
"Tesneem/grant_rag_system",
"AryanRathod3097/high-school-physics",
"RayNene/gaia-agent",
"rashid996958/nickelfox-RAG",
"ananya5151/free-gemma-bot-api",
"MasElCol/pitch-reviewer-mvp",
"rishabhchhillar/oshorc",
"SHELLAPANDIANGANHUNGING/AIf4digiplan",
"botcampusai/interview-coach",
"avadheshmishra/project-llm-chatbot",
"nishantr8461/GDOT_LlamaIndex",
"rashid996958/nickelfox-assignment",
"Andro777/LLM-dermatology",
"Daiyannnn/Chatbot_Tinyllama",
"gk2410/pen_test",
"ChAbhishek28/trimus-hr-chatbot",
"Teeburg/skin",
"brave4567/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"mehuldev/NPChef",
"helmfridsson/citrus",
"semioz/infersense",
"emrecancelik03/netmera_ts_rag",
"navyamehta/tinyllama-chat-api",
"Maddysher/changi-rag-chatbot",
"Maddysher/changi-rag-bot",
"Ayyyesha/MindTrace",
"AnandVishesh1301/Agents_Finals_Assignment",
"nitin92/tiny-llama-chatbot-demo",
"Aisiphiwe/CV-Check",
"iffazainab/disaster-app",
"Jayasankha/RxGenie",
"whoisnp/Final_Assignment_Template",
"CauRAguiar/tinyllama-chatbot",
"platinumbehmoth/TinyLlamaprisencolinensinanchulo",
"GrootW/newspace",
"CelagenexResearch/medgemma",
"Leongay/Consent_Decoder",
"JumaRubea/logbook_ai_gen",
"jykh01/solar-system-chatbot",
"stutipandey/SkincareChat",
"nishadwankhede1/ishad-portfolio-api",
"cchhriss/Chatbot",
"pradipraut737/catbot",
"Muyumba/Neo-AI",
"DjornIronshield/Unstructured_Fellowship_1",
"pradipraut737/Insights_Generator",
"solfedge/Safetyinspector_AI",
"JumaRubea/assistant",
"cwadayi/Transformer",
"Basel-Amr/ev-qa-api",
"akshay-kap/greatlearning-demo",
"ahmed-eisa/genai_service",
"Juraboy/Finall_Assignment_Agent",
"Ranasa44/chatbotRano",
"rapzzcode/m",
"lakshmireddy100/medical-chatbot-demo",
"msalahuddin/test1",
"BrdH7940/Agentic-RAG",
"lakshmireddy100/medical_ai_project",
"lakshmireddyy/medical_ai_project",
"QuanTumForgeLabs/medical_ai_project",
"narciso125/professor-ia-portugues",
"Wali1234/TinyLlama-TinyLlama-1.1B-Chat-v1.0",
"gwagsidraig/KERRYMATE",
"phoenixt28/cool_summarizer_and_qa",
"Invescoz/VI1",
"amalbiju/Ava",
"ankitamod/Final_Assignment_Templateamm",
"Vaishnavi776/mistral",
"Vaishnavi776/vaishnavi-tinyllama",
"Mehrdat/healgentic",
"ThomasBasil/slm-customer-support-chatbot",
"Nehal721/my-creative-writer-api",
"angieli7121/resume-chat",
"PaddySeahorse/YanZhiChun-default",
"Onnuurr/Test",
"Ananya829/app.py",
"Mostafa9675/astra-chatbot",
"DarkxCrafter/Test",
"luguog/fartfly3",
"khudri/islamichat",
"BeDream/Dream",
"DNRaina/Final_Assignment_Template_final",
"TotallyILYAS/bacon-ai",
"shallowHate/Final_Assignment",
"SpookyFab/FabPhi-Chat",
"3LL3/GAIA_ASSIGNMENT",
"suhas06/tiny_llama_finetuned",
"BloonsWarMaster/Sports-Injury-Sentinel-Chatbot",
"wli9/paperchatbot",
"aswyga/agent_bench",
"HGKo/vision-web-app",
"iimkarthik/demo_dynamic_prompt_n_tool_calling",
"Tigrillus/Final_Assignment_Template",
"mrkrisshu/krishna-ai",
"dylanginsberg/fire-app-v2",
"kvreshan/article-writer",
"Guest24897LOL/tinyllama-chat",
"MTY2025/medbot",
"ryansonn/SportsInjury-Chatbot",
"surahj/chat-bot",
"Ravena18/namorada-virtual",
"BoltAI-GLM/BoltAI-5",
"corben777/ai_bot",
"JeremyCao22/Chatbot",
"moizN/MoizGPT",
"v0idalism/blacklight-text",
"AhmadAny/MedBot",
"1tbfree/tinyllama-chat",
"miosama/crypto-tutor-demo",
"mukulgarg0097/BioMedRagChatbot",
"Gnanika/tennis-and-swimming-chatbot",
"IvanXGF/digitalvance-ai",
"mepartha/openscad-codegen",
"Priyanshu12121/exam-prep-ai",
"muddasser/TinyLlama_RAG",
"muddasser/TinyLlama_finetuned",
"aradfarmani131/arad-GPT-1.1B",
"mssaidat/testing_testing",
"Carlos80/Marketingprofis",
"oofman/tinyllama-test",
"sahil239/chatbotv2",
"MayaWagabaza/Nakato-voice",
"Megxx/Legal_Analyst",
"Cowboy-d/Final_Assignment_Template",
"Siddharth2626/storytellingchatbot",
"Garrison8/tinyllama-tutor-docker",
"dzehuggingface/Tracker",
"pankaj1982/smart_research_Assitant",
"mitanshugoel/memory-assistant-backend",
"AAhadA/PDF_QA_Agent_tinyllama",
"virtualplay/security-alert-summarizer-ui",
"Prathvirajj/my-first-llm",
"jazib1341/AIchatbot",
"userisname/dreamtracer-oss-chat",
"NikhiSanghi/PDFQAAgent",
"selinazarzour/ai-virtual-tryon",
"khanfaiz123/faiz-multimodal-chatbot",
"RAFAMANTANANTSOA/COURS-EGSS",
"Arshsandhu/Dasi_AI",
"Matrani/mon-ai-gratuit",
"technonyte00/oss",
"argyledrapes/Final_Assignment",
"inebrahim99/autosar",
"a2948764576888/777",
"Black332/Hydra-brain",
"mahesh1209/CHAT-DOC",
"justloginm2024/convAI",
"maheen34/NewsLens",
"mahesh1209/codeing-agent",
"anshumanpatil/just_poc_ms",
"Binny2634/ForgerockChaatbot",
"Moizmk11/Idea-To-Business-Pitch",
"lilbablo/humigence",
"kumarkasaramoni/Chatbot",
"mahesh1209/MLFLOW-DOCKER-Q-A-CHATBOT",
"mahesh1209/TinyLlama-Text-Reader",
"mahesh1209/LlamaIndex-RAG",
"rzvn/Medieval-Village-AI",
"mahesh2025AI/DB-SST-Pilot",
"TAWGCreatology/pet-care-test",
"muddasser/Youtube_RAG_TinyLlama",
"saifibolte/TinyLlama-AI-Assistant",
"vkatamineni/rag-vs-ft",
"kasudza/kasudza",
"janbryanmartirez/TestChatBot",
"AnshT013/urbanpulse-llm",
"vjuturu/Tryitout",
"rishabhsetiya/CAIAssignmentGradio",
"kundan621/cai-bits-llm",
"kundan621/assignment",
"Riya012/TinyLlama_AI_ML_Chatbot",
"khalidsafi/brotravelsafg-chat",
"fmlin429/chinese-poetry",
"sabbirjoy567/GrihoGadget",
"jdupree/SRA-redo",
"nadakjc/nadakjc",
"mahesh2025AI/Learn_Copilot",
"farjadmalik/fromWordsToMedia",
"Tristant95/AI_Storybook",
"santi140869/mi-chat-ia",
"cwattsnogueira/bikeease-ad-generator",
"zarsyeda/Resume-Parser",
"katie2023may/katiemaytest",
"martinezaustin078/AI-Powered-Interview-App",
"Adegbe/AI_AGENT_Sam",
"relayaiprototype/RELAYAI",
"theshifainsitute/ShifaBot",
"apds2025/TinyLlama_chatbot",
"mariopropel/propelpujas",
"DndProject/DnD_Chatbot",
"uditk99/agentic_ai"
] |
[
"apache-2.0"
] |
[
"cerebras/SlimPajama-627B",
"bigcode/starcoderdata",
"HuggingFaceH4/ultrachat_200k",
"HuggingFaceH4/ultrafeedback_binarized"
] |
[
"en"
] | 1,100,048,384
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
free
|
university
|
[
"Singapore"
] | null |
TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"EN"
] |
[
"Pretraining: Causal Language Modeling (CLM)",
" Finetuning: Supervised",
" Instruction finetuning",
" Reinforcement learning from feedback"
] |
Disclosed: available
| 9
|
661f97d48e7f3438386f755d
|
meta-llama/Meta-Llama-3-8B
|
meta-llama
| null | 1,501,374
| 21,256,323
|
manual
| 2024-04-17T09:35:16Z
| 2024-09-27T15:52:33Z
|
transformers
| 6,295
| 13
| null |
text-generation
|
{"parameters": {"BF16": 8030261248}, "total": 8030261248}
|
[
".gitattributes",
"LICENSE",
"README.md",
"USE_POLICY.md",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"original/consolidated.00.pth",
"original/params.json",
"original/tokenizer.model",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
7801,
36584,
4696,
654,
177,
4976698672,
4999802720,
4915916176,
1168138808,
23950,
16060617592,
211,
2183982,
73,
9085698,
50566
] | 32,132,569,879
|
8cde5ca8380496c9a6cc7ef3a8b46a0372a1d920
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"en",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"featherless-ai/try-this-model",
"eduagarcia/open_pt_llm_leaderboard",
"bhaskartripathi/LLM_Quantization",
"zhtet/RegBotBeta",
"tws-pappu/Llama3_PK_DemoAPP",
"BeveledCube/bevelapi",
"logikon/open_cot_leaderboard",
"Omnibus/Chatbot-Compare",
"HeshamHaroon/Arabic_Tokenizer",
"RajatChaudhari/QueryingLangchainPaper",
"mlabonne/AutoMerger",
"jordyvl/ask_my_thesis",
"TomData/PoliticsToYou",
"henry2024/ARIN_7102",
"genai-impact/ecologits-calculator",
"Lician/meta-llama-Meta-Llama-3-8B",
"WillianCGomes4Sys/meta-llama-Meta-Llama-3-8B",
"philip10/meta-llama-Meta-Llama-3-8B",
"amancseai/meta-llama-Meta-Llama-3-8B",
"zeez/meta-llama-Meta-Llama-3-8B",
"goaiguru/meta-llama-Meta-Llama-3-8B",
"edison1/meta-llama-Meta-Llama-3-8B",
"afrenkai/meta-llama-Meta-Llama-3-8B",
"andrewchristen/meta-llama-Meta-Llama-3-8B",
"soeb/meta-llama-Meta-Llama-3-8B",
"nabu098/meta-llama-Meta-Llama-3-8B",
"VaderKai/meta-llama-Meta-Llama-3-8B",
"rudyTzhan/meta-llama-Meta-Llama-3-8B",
"yuping322/meta-llama-Meta-Llama-3-8B",
"mfernandes3/meta-llama-Meta-Llama-3-8B",
"Tianyi289/meta-llama-Meta-Llama-3-8B",
"saicharanreddy5839/meta-llama-Meta-Llama-3-8B",
"nnilayy/meta-llama3",
"DanTheCoder/meta-llama-Meta-Llama-3-8B",
"sombochea/meta-llama-Meta-Llama-3-8B",
"ihamadasyr/meta-llama-Meta-Llama-3-8B",
"jasonqhd/meta-llama-Meta-Llama-3-8B",
"HilalKhan1/meta-llama-Meta-Llama-3-8B-awkum",
"nganc/meta-llama-Meta-Llama-3-8B",
"danielnluna/meta-llama-Meta-Llama-3-8B",
"blvckn9ght/meta-llama-Meta-Llama-3-8B",
"rayzh2013/meta-llama-Meta-Llama-3-8B",
"t1ffxny/meta-llama-Meta-Llama-3-8B",
"ahaval/meta-llama-Meta-Llama-3-8B",
"G765/LLM_testing",
"shouqiangli/meta-llama-Meta-Llama-3-8B",
"holaaamijo/meta-llama-Meta-Llama-3-8B",
"taohui035/meta-llama-Meta-Llama-3-8B",
"AhmedMagdy7/meta-llama-Meta-Llama-3-8B",
"Stanlito/meta-llama-Meta-Llama-3-8B",
"manuelsan/meta-llama-Meta-Llama-3-8B",
"maenkhouseh/meta-llama-Meta-Llama-3-8B",
"lusan021/meta-llama-Meta-Llama-3-8B",
"raochao521520/meta-llama-Meta-Llama-3-8B",
"bryan467/meta-llama-Meta-Llama-3-8B",
"giulianopicco/meta-llama-Meta-Llama-3-8B",
"anguia001/Meta-Llama-3-8B-Instruct",
"Shusiii/meta-llama-Meta-Llama-3-8B",
"eprasad/meta-llama-Meta-Llama-3-8B",
"Feli87/meta-llama-Meta-Llama-3-8B",
"juanserna70/meta-llama-Meta-Llama-3-8B",
"xt64/meta-llama-Meta-Llama-3-8B",
"MrSterlinger/meta-llama-Meta-Llama-3-8B",
"edelkkevin/meta-llama-Meta-Llama-3-8B",
"Skywinnner/meta-llama-Meta-Llama-3-8B",
"fantos/Chatbot-Compare",
"BYY5410/meta-llama-Meta-Llama-3-8B",
"Kushiii112/meta-llama-Meta-Llama-3-8B",
"bramuige/meta-llama-Meta-Llama-3-8B",
"amk9978/meta-llama-Meta-Llama-3-8B",
"patil1001970/docLite",
"dhrubap/meta-llama-Meta-Llama-3-8B",
"Ajbjbu/meta-llama-Meta-Llama-3-8B",
"Legacy549/meta-llama-Meta-Llama-3-8B",
"rgsreeni/terminator_snoop",
"Allanware/meta-llama-Meta-Llama-3-8B",
"gptforfree/meta-llama-Meta-Llama-3-8B",
"papeleta/Llama-3-8B",
"anmlclt/meta-llama-Meta-Llama-3-8B",
"yamcs/meta-llama-Meta-Llama-3-8B",
"dogwtz/meta-llama-Meta-Llama-3-8B",
"ycma/meta-llama-Meta-Llama-3-8B",
"TWT1019/meta-llama-Meta-Llama-3-8B",
"Torphy-Winner/meta-llama-Meta-Llama-3-8B",
"learnhere/meta-llama-Meta-Llama-3-8B",
"dineth554/meta-llama-Meta-Llama-3-8B",
"PunchAgency/meta-llama-Meta-Llama-3-8B",
"sdsdfaas/meta-llama-Meta-Llama-3-8B",
"shudelong/meta-llama-Meta-Llama-3-8B",
"shudelong/2meta-llama-Meta-Llama-3-8B",
"harshahug/meta-llama-Meta-Llama-3-8B",
"aanaruna/test-meta-llama",
"flora-kiddom/meta-llama-Meta-Llama-3-8B",
"MattyTheBoi/NLP-CSI_5180",
"NouRed/BioMed-LLaMa-3",
"pezon/meta-llama-Meta-Llama-3-8B",
"trongns/meta-llama-Meta-Llama-3-8B",
"feob/meta-llama-Meta-Llama-3-8B",
"visitsmaple/meta-llama-Meta-Llama-3-8B",
"yashdamania99/meta-llama-Meta-Llama-3-8B",
"ranjanriteshhf/open_source_rag_hf",
"fly9i/meta-llama-Meta-Llama-3-8B",
"SakuragiHanamichi/meta-llama-Meta-Llama-3-8B",
"decodingdatascience/meta-llama-Meta-Llama-3-8B",
"phool624/llama-2-chat",
"hiascend/meta-llama-Meta-Llama-3-8B",
"smattancheril/meta-llama-Meta-Llama-3-8B",
"caclou89/meta-llama-Meta-Llama-3-8B",
"UltraMarkoRJ/meta-llama-Meta-Llama-3-8B",
"poloniki/meta-llama-Meta-Llama-3-8B",
"Ophird/meta-llama-Meta-Llama-3-8B",
"gndhdht/meta-llama-Meta-Llama-3-8B",
"domedev/meta-llama-Meta-Llama-3-8B",
"codemaker2015/meta-llama-Meta-Llama-3-8B",
"t4lha/meta-llama-Meta-Llama-3-8B",
"Vardhan6070/meta-llama-Meta-Llama-3-8B",
"ashwinmahender/meta-llama-Meta-Llama-3-8B",
"HuggingUser7453/meta-llama-Meta-Llama-3-8B",
"Ensyllis/meta-llama-Meta-Llama-3-8B",
"asderene/meta-llama-Meta",
"NicerDave/meta-llama-Meta-Llama-3-8B",
"DylanZ/meta-llama-Meta-Llama-3-8B",
"darshanTheDev/meta-llama-Meta-Llama-3-8B",
"vaiyon/Llama-3-8B",
"saketh092/meta-llama-Meta-Llama-3-8B",
"SohamGhugare/meta-llama-Meta-Llama-3-8B",
"kvrma/explichat-ui",
"rocky4dx3906/meta-llama-Meta-Llama-3-8B",
"TermixSlayer/meta-llama-Meta-Llama-3-8B",
"pkarlaa/zentica",
"fanxuedong/meta-llama-Meta-Llama-3-8B",
"JUSTlook/meta-llama-Meta-Llama-3-8B",
"alejandrorojas/meta-llama-Meta-Llama-3-8B",
"Starlight8357/meta-llama-Meta-Llama-3-8B",
"ahliang/meta-llama-Meta-Llama-3-8B",
"ajajjajajaja/meta-llama-Meta-Llama-3-8B",
"dvilasuero/reasoning_config_space",
"chahba/meta-llama-Meta-Llama-3-8B",
"ky32/Email_Classification",
"AliHQ/meta-llama-Meta-Llama-3-8B",
"blairdods/meta-llama-Meta-Llama-3-8B",
"HugoCS2002/meta-llama-Meta-Llama-3-8B",
"SuperSU99/meta-llama-Meta-Llama-3-8B",
"wangenius/meta-llama-Meta-Llama-3-8B",
"Tina2088/meta-llama-Meta-Llama-3-8B",
"haoxiong693/meta-llama-Meta-Llama-3-8B",
"burtenshaw/bicycle_maintenance_config_space",
"devopsrobo/meta-llama-Meta-Llama-3-8B",
"Rambo1111/meta-llama-Meta-Llama-3-8B",
"dragonku/meta-llama-Meta-Llama-3-8B",
"psy-taha/meta-llama-Meta-Llama-3-8B",
"zombieofCrypto/meta-llama-Meta-Llama-3-8B",
"cross55/meta-llama-Meta-Llama-3-8B",
"mjithin/meta-llama-Meta-Llama-3-8B",
"KennyYoung/meta-llama-Meta-Llama-3-8B",
"gauravlogical/meta-llama-Meta-Llama-3-8B",
"waterreptile19/meta-llama-Meta-Llama-3-8B",
"AICopyCC/meta-llama-Meta-Llama-3-8B",
"Abhishek4623/meta-llama-Meta-Llama-3-8B",
"Aashxx/meta-llama-Meta-Llama-3-8B",
"kediboregi/meta-llama-Meta-Llama-3-8B",
"FalconNave/meta-llama-Meta-Llama-3-8B",
"nier111/1",
"Gregr4/meta-llama-Meta-Llama-3-8B",
"zsoltadam/livechat-application",
"dineshneurindustries/meta-llama-Meta-Llama-3-8B",
"ai1819/meta-llama-Meta-Llama-3-8B",
"HAMDOUNTHEDON/meta-llama-Meta-Llama-3-8B",
"sshrey15/lammma3",
"kuochingx/meta-llama-Meta-Llama-3-8B",
"jdelgado2002/meta-llama-Meta-Llama-3-8B",
"GrahamW/red_hatter_gd",
"baotuan/meta-llama-Meta-Llama-3-8B",
"authar/meta-llama-Meta-Llama-3-8B",
"johnmogi/meta-llama-Meta-Llama-3-8B",
"gigim/meta-llama-Meta-Llama-3-8B",
"Xaitum/meta-llama-Meta-Llama-3-8B",
"carnage7491/meta-llama-Meta-Llama-3-8B",
"Oussama2000/for_py",
"Ciencia/meta-llama-Meta-Llama-3-8B",
"kiranpatel11/meta-llama-Meta-Llama-3-8B",
"DataCodebr/meta-llama-Meta-Llama-3-8B",
"vkdel001/meta-llama-Meta-Llama-3-8B",
"itspasindu/meta-llama-Meta-Llama-3-8B0",
"raul27868/meta-llama-Meta-Llama-3-8B",
"rakesh-123/meta-llama-Meta-Llama-3-8B",
"Harshjaiswal/meta-llama-Meta-Llama-3-8B",
"alonpo/meta-llama-Meta-Llama-3-8B",
"spinitup1312/meta-llama-Meta-Llama-3-8B",
"TadpolAI/meta-llama-Meta-Llama-3-8B",
"Khaee/meta-llama-Meta-Llama-3-8B",
"cundyofkenzo/meta-llama-Meta-Llama-3-8B",
"amirkalateh/meta-llama-Meta-Llama-3-8B",
"yuvaranianandhan24/chat_with_pdf",
"hamzaasalhi/meta-llama-Meta-Llama-3-8B",
"vijayjain7425/meta-llama-Meta-Llama-3",
"Mrohondu/meta-llama-Meta-Llama-3-8B",
"John6687890/meta-llama-Meta-Llama-3-8B",
"CGI-Chamel/meta-llama-Meta-Llama-3-8B",
"Ytghh/meta-llama-Meta-Llama-3-8B",
"playra/meta-llama-Meta-Llama-3-8B",
"ngocquynh85/meta-llama-Meta-Llama-3-8B",
"jbie/meta-llama-Meta-Llama-3-8B",
"Farrell666/meta-llama-Meta-Llama-3-8B",
"vwinnv/meta-llama-Meta-Llama-3-8B",
"Imperial-1513/Alpha-Chatbot",
"RuslanYTKA/meta-llama-Meta-Llama-3-8B",
"VictorHAM/meta-llama-Meta-Llama-3-8B",
"Rupesx007/meta-llama-Meta-Llama-3-8B",
"comsian/meta-llama-Meta-Llama-3-8B",
"rinna/llama-3-youko-8b-instruct",
"ClefChen/ARIN_7102_final",
"JARVIS-DEV/meta-llama-Meta-Llama-3-8B",
"machalex/meta-llama-Meta-Llama-3-8B",
"yonivenn/meta-llama-Meta-Llama-3-8B",
"berkekoca/meta-llama-Meta-Llama-3-8B",
"umaiuni/meta-llama-Meta-Llama-3-8B",
"hbui/RegBot4.0",
"pbdigital/meta-llama-Meta-Llama-3-8B",
"jrrakib182/meta-llama-Meta-Llama-3-8B",
"omertafveez/TherapyChatBot",
"mertkannn/meta-llama-Meta-Llama-3-8B",
"Airop/meta-llama-Meta-Llama-3-8B",
"BadBoyz555/meta-llama-Meta-Llama-3-8B",
"GTGenesis/meta-llama-Meta-Llama-3-8B",
"TestJarditips/meta-llama-Meta-Llama-3-8B",
"TestJarditips/meta-llama-Meta-Llama-3-8B-HK",
"scs891/meta-llama-Meta-Llama-3-8B",
"k3rnh3ll/meta-llama-Meta-Llama-3-8B",
"cyhhao/meta-llama-Meta-Llama-3-8B",
"Reinoptland/meta-llama-Meta-Llama-3-8B",
"octhavio/meta-llama-Meta-Llama-3-8B",
"BogdanValentin977/Llama-3",
"Dhirain/meta-llama-Meta-Llama-3-8B",
"Nvaikus1109/meta-llama-Meta-Llama-3-8B",
"suplinux/meta-llama-Meta-Llama-3-8B",
"loushuai/meta-llama-Meta-Llama-3-8B",
"govindkmsv/meta-llama-Meta-Llama-3-8B",
"MartinK1/meta-llama-Meta-Llama-3-8B",
"MartinK1/meta-llama-Meta-Llama-3-8BB",
"zhaoyihui/meta-llama-Meta-Llama-3-8B",
"aelitta/BioMistral_gradio",
"dragit/llama-test-2",
"harsh2040/meta-llama-Meta-Llama-3-8B",
"hbui/RegBot4.1",
"BritoReji/meta-llama-Meta-Llama-3-8B",
"kalihat/SentinelEcho",
"makeol/meta-llama-Meta-Llama-3-8B",
"Starrn/meta-llama-Meta-Llama-3-8B",
"Helder84/meta-llama-Meta-Llama-3-8B",
"saneowl/meta-llama-Meta-Llama-3-8B",
"kr0078/meta-llama-Meta-Llama-3-8B",
"dons6811/Meta-Llama-3-8B-Instruct",
"saim4242/meta-llama-Meta-Llama-3-8B",
"ujjwaldsfsf/meta-llama-Meta-Llama-3-8B",
"HazardSpence/logits",
"HazardSpence/meta-llama-Meta-Llama-3-8B",
"loganlxb/meta-llama-Meta-Llama-3-8B_image",
"Yasein0119/meta-llama-Meta-Llama-3-8B",
"LightmanLu/meta-llama-Meta-Llama-3-8B",
"bilalghalib/meta-llama-Meta-Llama-3-8B",
"maxshuo/meta-llama-Meta-Llama-3-8B",
"sorsseli/timo-llama3-8b",
"xxxub/Jjj",
"btwiamjc/meta-llama-Meta-Llama-3-8B",
"benben17/meta-llama-Meta-Llama-3-8B",
"Faustrix/meta-llama-Meta-Llama-3-8B",
"ChrisMofus/BestStoryTeller",
"locorene1000/meta-llama-Meta-Llama-3-8B",
"RTVS/meta-llama-Meta-Llama-3-8B",
"Eyecatcher/meta-llama-Meta-Llama-3-8B",
"Shirlman/meta-llama-Meta-Llama-3-8B",
"idris-jafarov/meta-llama-Meta-Llama-3-8B",
"tusharg007/meta-llama-Meta-Llama-3-8B",
"aniketnikam06/meta-llama-Meta-Llama-3-8B",
"User1995/meta-llama-Meta-Llama-3-8B",
"mystifyi/meta-llama-Meta-Llama-3-8B",
"AgnivaG/meta-llama-Meta-Llama-3-8B",
"michaelirey/meta-llama-Meta-Llama-3-8B",
"aniketnikam06/meta-llama-Meta-Llama-3-8B-ann",
"menghuaZ/meta-llama-Meta-Llama-3-8B",
"WAILINOO/meta-llama-Meta-Llama-3-8B",
"Gow7/meta-llama-Meta-Llama-3-8B",
"internettrashh/meta-llama-Meta-Llama-3-8B",
"dioarafl/Translate",
"ExploitationLizard/Meta_LLama_charlie",
"wfdwfwfwf/meta-llama-Meta-Llama-3-8B",
"agend07/meta-llama-Meta-Llama-3-8B",
"refold64/meta-llama-Meta-Llama-3-8B-myr",
"fainer/meta-llama-Meta-Llama-3-8B",
"Pranjal-666/meta-llama-Meta-Llama-3-8B",
"millan001/meta-llama-Meta-Llama-3-8B",
"avik6028/meta-llama-Meta-Llama-3-8B",
"dineth554/meta-llama-Meta-Llama-3-8Bhjj",
"UlmerMan/meta-llama-Meta-Llama-3-8B",
"felipebarcelospro/meta-llama-Meta-Llama-3-8B",
"shangab/llama3",
"Abhishek4623/meta-llama-Meta-Llama-3-8Bdas",
"dioarafl/snapSync",
"Ifeanyi/Knowledge-Graph-Assistant",
"SnirMo/meta-llama-Meta-Llama-3-8B",
"hxrzz123/meta-llama-Meta-Llama-3-8B",
"Kashif338/meta-llama-Meta-Llama-3-8B",
"Kashif338/meta-llama-Meta-Llama-38",
"Giang07/Ti6-lllama2-QLoRra",
"AlexanderValentin/Llama-finetune",
"RockCoder23/AIv2",
"Nvaikus1109/meta-llama-Meta-Llama-3-8B_Test",
"0x932b/meta-llama-Meta-Llama-3-8B",
"venkateshcv/meta-llama-Meta-Llama-3-8B",
"Cafet/meta-llama-Meta-Llama-3-8B",
"Biplav00/meta-llama-Meta-Llama-3-8B",
"nahi002/meta-llama-Meta-Llama-3-8B",
"bharri10/meta-llama-Meta-Llama-3-8Btest",
"RoninHa/meta-llama-Meta-Llama-3-8B",
"Datadev17/meta-llama-Meta-Llama-3-8B",
"hedtorresca/meta-llama-Meta-Llama-3-8B",
"Tosin5S/meta-llama-Meta-Llama-3-8B",
"Tosin5S/meta-llama-Meta-Llama-3-8B-2",
"cagjony/meta-llama-Meta-Llama-3-8B",
"lashu333/meta-llama-Meta-Llama-3-8B",
"Hussey12/MyBot",
"Shempolo/meta-llama-Meta-Llama-3-8B",
"XiaoyuSGuo/meta-llama-Meta-Llama-3-8B",
"Phindx/meta-llama-Meta-Llama-3-8B",
"mosishon/meta-llama-Meta-Llama-3-8B",
"Shankarm08/llmademo",
"JeromeXX/meta-llama-Meta-Llama-3-8B",
"hikikome/meta-llama-Meta-Llama-3-8B",
"Shubhambansal2/meta-llama-Meta-Llama-3-8B",
"davdadev/ai",
"davdadev/meta-llama-Meta-Llama-3-8B",
"TencentAIGC-Lab/meta-llama-Meta-Llama-3-8B",
"adhilshan/meta-llama-Meta-Llama-3-8B",
"adhilshan/meta-llama-Meta-Llama-3-8Bd",
"kiolx/meta-llama-Meta-Llama-3-8B",
"damodhar918/meta-llama-Meta-Llama-3-8B",
"DeFc0n/meta-llama-Meta-Llama-3-8B",
"dnnsdunca/DDroidlabs-Llama-3-8B",
"Maximnota/meta-llama-Meta-Llama-3-8B",
"srijansengupta/meta-llama-Meta-Llama-3-8B",
"JJx123/meta-llama-Meta-Llama-3-8B-rei",
"Celestial-Entity/meta-llama-Meta-Llama-3-8B",
"bqtk0vdev/meta-llama-Meta-Llama-3-8B",
"Xatmo/meta-llama-Meta-Llama-3-8B",
"AikoNee/meta-llama-Meta-Llama-3-8B",
"jiww/meta-llama-Meta-Llama-3-8B",
"zhen1001/meta-llama-Meta-Llama-3-8B-001",
"JACOBBBB/meta-llama-Meta-Llama-3-8B_test",
"Coolepicgwmerrr/meta-llama-Meta-Llama-3-8B",
"aitek2487/meta-llama-Meta-Llama-3-8B",
"Elon99/Sapan-meta-llama3b",
"aitek2487/Chat-GPH-3-8B",
"CoolEpicChair/ZeroGpuLlama",
"dineth554/novav3",
"AshJohn90/meta-llama-Meta-Llama-3-8B",
"sa-rehman/goat3",
"sa-rehman/bakra",
"adildhkh/meta-llama-Meta-Llama-3-8B",
"IncinerateZ/meta-llama-Meta-Llama-3-8B",
"ThinkAI-Morocco/TESTing",
"RyanZhuuuuu/meta-llama-Meta-Llama-3-8B",
"ChengSir/meta-llama-Meta-Llama-3-8B",
"infinitenow/meta-llama-Meta-Llama-3-8B",
"bAInaryglobe/meta-llama-Meta-Llama-3-8B",
"domengo/llama",
"FragM3/BobLlama",
"Comeit/meta-llama-Meta-Llama-3-8B",
"codexxx/meta-llama-Meta-Llama-3-8B",
"cot-leaderboard/open-cot-dashboard",
"gaudengalea/meta-llama-Meta-Llama-3-8B",
"Parikxit/meta-llama-Meta-Llama-3-8B",
"nkmrt/meta-llama-Meta-Llama-3-8B",
"Michaelsihua/meta-llama-Meta-Llama-3-8B",
"WLL781/meta-llama-Meta-Llama-3-8B",
"trodjo/shopi_bot",
"thinking80s/meta-llama-Meta-Llama-3-8B",
"SyedYusuf/meta-llama-Meta-Llama-3-8B",
"singhshiva/meta-llama-Meta-Llama-3-8B",
"lorenzoney/meta-llama-Meta-Llama-3-8B",
"RomaAserion/meta-llama-Meta-Llama-3-8B",
"szrai001/meta-llama-Meta-Llama-3-8B",
"naterz/meta-llama-Meta-Llama-3-8B",
"nerottt/meta-llama-Meta-Llama-3-8B",
"AmrGharieb/meta-llama-Meta-Llama-3-8B",
"sirluky/meta-llama-Meta-Llama-3-8B",
"MattJarl/meta-llama-Meta-Llama-3-8B",
"Cidewalk/meta-llama-vanilla-Meta-Llama-3-8B",
"NoumaanAhamed/meta-llama-Meta-Llama-3-8B",
"0x0a1/meta-llama-Meta-Llama-3-8B",
"Glenville/meta-llama-Meta-Llama-3-8B",
"NullNerd/meta-llama-Meta-Llama-3-8B",
"cpamidi81/meta-llama-Meta-Llama-3-8B",
"JuanPablo4to/CoachPRODI",
"frogert/meta-llama-Meta-Llama-3-8B",
"sbutalia/mythology-builder",
"sushisasha/meta-llama-Meta-Llama-3-8B",
"ariefcahya/meta-llama-Meta-Llama-3-8B",
"truongcuongbt/meta-llama-Meta-Llama-3-8B",
"VanguardAI/RealTime",
"scribbyotx/meta-llama-Meta-Llama-3-8B",
"meetingattendee/meta-llama-Meta-Llama-3-8B-test1",
"iamomen/meta-llama-Meta-Llama-3-8B",
"ianhutomo/meta-llama-Meta-Llama-3-8B",
"lcodoceoc/summary-app",
"pylasrenu/meta-llama-Meta-Llama-3-8B",
"SJTUSK/meta-llama-Meta-Llama-3-8B",
"Do0rMaMu/meta-llama-Meta-Llama-3-8B",
"sandz7/loki",
"sandz7/Io",
"StevenChen16/AI-Lawyer",
"MartinK1/meta-llama-Meta-Llama-3-8Bd",
"lcodoceoc/meta-llama-Meta-Llama-3-8B",
"Kwindla/meta-llama-Meta-Llama-3-8B",
"sapan3012/meta-llama-Meta-Llama-3-8B",
"dolkan/meta-llama-Meta-Llama-3-8B",
"Elon99/meta-llama-Meta-Llama-3-8B",
"feregrino/try-llama-3",
"lolp1ke/meta-llama-Meta-Llama-3-8B",
"AndrewNanu-app/meta-llama-Meta-Llama-3-8B",
"Colmand/meta-llama-Meta-Llama-3-8B",
"typesdigital/meta-llama-Meta-Llama-3-8B",
"Nidhichandra20/meta-llama-Meta-Llama-3-8B",
"alpdk1394/test_chat_space",
"catallama/CataLlama-Chat",
"atovk/meta-llama-Meta-Llama-3-8B",
"boldhasnain/first",
"lyokovn/meta-llama-Meta-Llama-3-8B",
"Oeric/meta-llama-Meta-Llama-3-8B",
"dueprincipati/meta-llama-Meta-Llama-3-8B",
"musicspace/meta-llama-Meta-Llama-3-8B",
"DocExplorer/meta-llama-Meta-Llama-3-8B",
"qinghua-zhou/stealth-edits",
"shakeelhussain/meta-llama-Meta-Llama-3-8B",
"ludovic-vallee/test1",
"Karlsen/IT_support_bot",
"mebinjo/meta-llama-Meta-Llama-3-8B",
"HelloOoOooo/uday9441",
"neerajram007/meta-llama-Meta-Llama-3-8B",
"jayyd/meta-llama-Meta-Llama-3-8B",
"Naesh/meta-llama-Meta-Llama-3-8B",
"dshiohfjfnsdlknvjlsnxdlinvlxm/meta-llama-Meta-Llama-3-8B",
"sergiopaniego/Meta-Llama-3-8B",
"markcoatsworth/gradio-demo",
"lizhen30/meta-llama-Meta-Llama-3-8B",
"RomanRG008/meta-llama-Meta-Llama-3-8B",
"Sbaccius/meta-llama-Meta-Llama-3-8B",
"GatewayXR/meta-llama-Meta-Llama-3-8B",
"pepsinb/meta-llama-Meta-Llama-3-8B",
"SrijitMukherjee/cheentastat",
"uberkie/meta-llama-Meta-Llama-3-8B",
"haoyaqi/meta-llama-Meta-Llama-3-8B",
"svijayanand/Podcast_Oracle",
"Kailxzz/CodeAssistant",
"ericmora/meta-llama-Meta-Llama-3-8B",
"d13d13/meta-llama-Meta-Llama-3-8B",
"chan15/llama_model",
"dwb2023/model_explorer2",
"neuraldevx/FinWise-AI",
"Akashkumar2k01/resumemaker",
"GiladtheFixer/meta-llama-Meta-Llama-3-8B",
"hisense363/meta-llama-Meta-Llama-3-8B",
"raihaneon/meta-llama-Meta-Llama-3-8B",
"Ahmed0011/meta-llama-Meta-Llama-3-8B",
"gopalnoutiyal/testing_llama",
"marionnette-belfort/meta-llama-Meta-Llama-3-8B",
"prometheus-eval/BiGGen-Bench-Leaderboard",
"pepsinb/meta-llama-Meta-Llama-3-8Ba",
"Making/meta-llama-Meta-Llama-3-8B",
"sanbo1200/meta-llama-Meta-Llama-3-8B",
"rulekiller11/NEW_SPACE",
"teum254/meta-llama-Meta-Llama-3-8B",
"Timing-up/meta-llama-Meta-Llama-3-8B",
"nasser1/meta-llama-Meta-Llama-3-8B",
"Shivagye/meta-llama-Meta-Llama-3-8B",
"AneriThakkar/Question_Generation",
"DevBM/text-generation",
"aikongfu/meta-llama-Meta-Llama-3-8B",
"cathyxianus/meta-llama-Meta-Llama-3-8B",
"ndwdgda/lam",
"DBLDEE/meta-llama-Meta-Llama-3-8B",
"king17pvp/LLM-DIalouge-Summarization-Demo",
"yellowhatpro/meta-llama-Meta-Llama-3-8B",
"YESDODATA/testing",
"DhruvAwasthi/meta-llama-Meta-Llama-3-8B",
"Khanhpham1992/meta-llama-Meta-Llama-3-8B",
"nokia220/meta-llama-Meta-Llama-3-8B",
"Iamnoob235/meta-llama-Meta-Llama-3-8B",
"dendimaki/meta-llama-Meta-Llama-3-8B",
"bharagavgg123/meta-llama-Meta-Llama-3-8B-1",
"Lightningrod654/meta-llama-Meta-Llama-3-8B",
"SeikouBK/meta-llama-Meta-Llama-3-8B",
"Sydil/meta-llama-Meta-Llama-3-8B",
"Noumaan/meta-llama-Meta-Llama-3-8B",
"saketh092/meta-llama",
"Whatisyournamepro/meta-llama-Meta-Llama-3-8B",
"AIM-Harvard/rabbits-leaderboard",
"ashishtanwer/meta-llama-Meta-Llama-3-8B",
"dwb2023/model_explorer4",
"OjciecTadeusz/Chatbot-Compare",
"shujjat/Shujjat",
"Vamsi11/demo",
"Vamsi11/demo1",
"maxschulz-COL/meta-llama-Meta-Llama-3-8B",
"farhananwar123/meta-llama-Meta-Llama-3-8B",
"Vamsi11/demo3",
"Orbital/meta-llama-Meta-Llama-3-8B",
"Xavi99/meta-llama-Meta-Llama-3-8B",
"Yasirkh/meta-llama-Meta-Llama-3-8B",
"Excalibur9455/textGenwithDockers",
"Uttampatel/Text2TextDemo",
"rjonezzy/irietechmeta-llama-Meta-Llama-3-8B",
"hemchande/meta-llama-Meta-Llama-3-8B",
"LARRY-YIN/meta-llama-Meta-Llama-3-8B",
"cuhkjiang/meta-llama-Meta-Llama-3-8B",
"NghiR/meta-llama-Meta-Llama-3-8B",
"Justinrune/LLaMA-Factory",
"Deepa1234/meta-llama-Meta-Llama-3-8B",
"Kulsh/meta-llama-Meta-Llama-3-8B",
"wyattmarshall/meta-llama-Meta-Llama-3-8B",
"kneeyee/meta-llama-Meta-Llama-3-8B",
"mad123222/meta-llama-Meta-Llama-3-8B",
"killer-bee/meta-llama-Meta-Llama-3-8B",
"Cep3ga/meta-llama-Meta-Llama-3-8B",
"AldosBenzaldos/My_meta-llama-Meta-Llama-3-8B_LLM",
"smbss/meta-llama-Meta-Llama-3-8B",
"CarmelaFinianos/LLAMA3",
"EditorZ/Llama-3-8B",
"Adeco/rabbits-leaderboard",
"Jackybeat/meta-llama-Meta-Llama-3-8B",
"surrealdev/meta-llama-Meta-Llama-3-8B",
"p0t3fl0n/meta-llama-Meta-Llama-3-8B",
"EasonSong/meta-llama-Meta-Llama-3-8B",
"whitelotus0/meta-llama-Meta-Llama-3-8B",
"whitelotus0/glorry-llm",
"Truligon/meta-llama-Meta-Llama-3-8B",
"SreedeviBDP/meta-llama-Meta-Llama-3-8B",
"HuggingFaceSupport/meta-llama-Meta-Llama-3-8B",
"hallisky/StyleRemix",
"aaronstone1699/meta-llama-Meta-Llama-3-8B",
"MariameOuamer/specification_generation_app",
"Ale6100/meta-llama-Meta-Llama-3-8B",
"Alexview3/meta-llama-Meta-Llama-3-8B",
"bdgamer369/meta-llama-Meta-Llama-3-8B",
"asmahwimli/meta-llama-Meta-Llama-3-8B",
"nadeesh345/meta-llama-Meta-Llama-3-8B",
"0xjasonic/meta-llama-Meta-Llama-3-8B",
"angelblack/meta-llama-Meta-Llama-3-8B",
"nothemingway/meta-llama-Meta-Llama-3-8B",
"JOJOT98/meta-llama-Meta-Llama-3-8B",
"BharatMangal/meta-llama-Meta-Llama-3-8B",
"Morandav/meta-llama-Meta-Llama-3-8B",
"InJ1/llama3_test",
"shishira18/meta-llama-Meta-Llama-3-8B",
"MichaelS42/LLMTalk",
"LeAntGroupNote/meta-llama-Meta-Llama-3-8B",
"dplem/meta-llama-Meta-Llama-3-8B",
"dgalickis/meta-llama-Meta-Llama-3-8B",
"Gopikanth123/genai_llama3",
"Ferhat123/test2",
"Ferhat123/deneme",
"Ferhat123/ferhat",
"pablopiquejr/meta-llama-Meta-Llama-3-8B",
"Ferhat123/llama3",
"inflaton-ai/logical-reasoning",
"Abrar51/meta-llama-Meta-Llama-3-8B",
"Abrar51/Adplay-meta-llama-Meta-Llama-3-8B",
"Darkknight12/meta-llama-Meta-Llama-3-8B",
"Thebull/meta-llama-Meta-Llama-3-8B",
"Nibir5/meta-llama-Meta-Llama-3-8B",
"chrisOlv/meta-llama-Meta-Llama-3-8B",
"jonascholz/llama",
"decodingdatascience/meta-llama-Meta-Llama-3-8B1",
"pks3kor/amazon_product_review",
"ruslanmv/convert_to_gguf",
"suryacharanv/meta-llama-Meta-Llama-3-8B",
"dmishra86/llm-qna-app",
"swass/meta-llama-Meta-Llama-3-8B",
"PuMi11/meta-llama-Meta-Llama-3-8B",
"lineee/meta-llama-Meta-Llama-3-8B",
"Abhinay45/Meta-Llama-3-8B-Instruct",
"nitingarg/meta-llama-Meta-Llama-3-8B",
"Anson69/HoolsPic",
"Carlozm/meta-llama-Meta-Llama-3-8B",
"vmadman/meta-llama-Meta-Llama-3-8B",
"ndwdgda/tradingbot",
"TieuThanhNhi/meta-llama-Meta-Llama-3-8B",
"TieuThanhNhi/meta-llama-Meta-Llama-3-8Ba",
"PrudhviNarayana/meta-llama-Meta-Llama-3-8B",
"kusiyaitkrishna/meta-llama-Meta-Llama-3-8B",
"AshIsPro/My-Space",
"tha-crypt6-wxtch/meta-llama-Meta-Llama-3-8B",
"CHEFAI2024/meta-llama-Meta-Llama-3-8B",
"kanishqgandharv/meta-llama-Meta-Llama-3-8B",
"ProPerNounpYK/NEWSPACE",
"moawwal/meta-llama-Meta-Llama-3-8B",
"zyboy2000/meta-llama-Meta-Llama-3-8B",
"SoakingEnd39/Llama-3-8B",
"tecnologiacomigo/meta-llama-Meta-Llama-3-8B",
"DevBM/Meta-Llama-3-8B-Instruct",
"swimdubz/meta-llama-Meta-Llama-3-8B",
"whoami-j/meta-llama-Meta-Llama-3-8B",
"Rouna24/meta-llama-Meta-Llama-3-8B",
"RamyaKammari/jee_ai_tutor",
"sam-megh0305/SAM",
"shafee07/meta-llama-Meta-Llama-3-8B",
"FaizanSZ/meta-llama-Meta-Llama-3-8B",
"yayablaze/meta-llama-Meta-Llama-3-8B",
"hereoncollab/meta-llama-Meta-Llama-3-8B",
"Adelhead/llama3-main",
"yunhomaeng/meta-llama-Meta-Llama-3-8B",
"atsnamba/meta-llama-Meta-Llama-3-8B",
"gongxing/meta-llama-Meta-Llama-3-8B",
"osmunphotography/meta-llama-Meta-Llama-3-8B",
"sergeevii123/JailbreakLLMUsingPAIR",
"daksh5656/daksh",
"NoaiGPT/merger",
"ahmedothman11/meta-llama-Meta-Llama-3-8B",
"mayankchugh-learning/AgeBot",
"Asadshama123/meta-llama-Meta-Llama-3-8B",
"Oluwatoni/meta-llama-Meta-Llama-3-8B",
"Toxic87/meta-llama-Meta-Llama-3-8B",
"lintasmediadanawa/hf-llm-api",
"k2xl/meta-llama-Meta-Llama-3-8B",
"masfauzen/meta-llama-Meta-Llama-3-8B",
"Miykaelxxm/Chatbot-Compare",
"allicetheneko/nekollm",
"LinkAINL/meta-llama-Meta-Llama-3-8B",
"rashadism/llama3-test",
"aklraj/meta-llama-Meta-Llama-3-8B",
"kjha1/meta-llama-Meta-Llama-3-8B",
"Shabbir-Anjum/testLLama",
"udaiag/meta-llama-Meta-Llama-3-8B",
"RocketConcepts/meta-llama-Meta-Llama-3-8B",
"udaiag/Test-llama-3",
"Kalyan-sundar/meta-llama-Meta-Llama-3-8B",
"ganesh054/meta-llama-Meta-Llama-3-8B",
"Aditya7248/meta-llama-Meta-Llama-3-8B",
"NatiAbay/meta-llama-Meta-Llama-3-8B",
"NatiAbay/meta-llama-Meta-Llama-3-8B-test",
"DontslamtheDoor/meta-llama-Meta-Llama-3-8B",
"kenken999/fastapi_django_main_live",
"krishnajha23/meta-llama-Meta-Llama-3-8B",
"Aryan2411/meta-llama-Meta-Llama-3-8B",
"premsigths/meta-llama-Meta-Llama-3-8B",
"Crow34/meta-llama-Meta-Llama-3-8B",
"lelter/meta-llama-Meta-Llama-3-8B",
"MrBelette/meta-llama-Meta-Llama-3-8B",
"HermenO/meta-llama-Meta-Llama-3-8B",
"DevBM/meta-llama-Meta-Llama-3-8B",
"fafdajalebi/meta-llama-Meta-Llama-3-8B",
"HazeTupac/meta-llama-Meta-Llama-3-8B",
"HazeTupac/llama3",
"MaxDond/meta-llama-Meta-Llama-3-8B",
"abin1502/meta-llama-Meta-Llama-3-8B",
"HazeTupac/llama3-v2",
"nikpil93/my_llama_ui",
"data-ject/HackingBot",
"Siri23/BlogWriter",
"aieeshashafique/meta-llama-Meta-Llama-3-8B",
"mtcporto/meta-llama-Meta-Llama-3-8B",
"LightHearted/meta-llama-Meta-Llama-3-8B",
"LightHearted/meta-llama-Meta-Llama-3-8B4",
"licc319/meta-llama-Meta-Llama-3-8B",
"licc319/meta-llama-Meta-Llama-3-8B-2",
"Yogeshoodles/meta-llama-Meta-Llama-3-8B",
"ignitariumcloud/TI_RAG_Demo_L3.1",
"afya-david/sms-afya-chat",
"Pamudu13/meta-llama-Meta-Llama-3-8B",
"aitchatbot/aitchatbot",
"sipsmehta/Analyzer",
"K1-1960/meta-llama-Meta-Llama-3-8B",
"panuthept/thai_sentence_embedding_benchmark",
"oneres/meta-llama-Meta-Llama-3-8B",
"wirunw/meta-llama-Meta-Llama-3-8B",
"occhan/meta-llama-Meta-Llama-3-8B2",
"charlesapochi/plagiarism-detection-llm",
"raghuveer000/meta-llama-Meta-Llama-3-8B",
"TVRRaviteja/Multimodal-PACA",
"iDrops/LLama-3-8b",
"Sydil/meta-llama-Meta-Llama-3-8Bb",
"mkuroda/hello",
"Gampanut/thaiassistantrice",
"Ytghh/meta-llama-Meta-Llama-3-8Bjj",
"mohaimanulturash/meta-llama-Meta-Llama-3-8B",
"Alonge9500/Diabetes_App",
"manuellopper/meta-llama-Meta-Llama-3-8B",
"ASDSER/meta-llama-Meta-Llama-3-8B",
"Fy1717/forsico_ai_space",
"jxsun/meta-llama-Meta-Llama-3-8B",
"huzey/ncut-pytorch",
"ashmib/green-city-finder",
"rahulprajapati123/Llama-3.1-8B",
"catidiana/test2",
"catidiana/Chatbot_test_5",
"kasivisu3109/meta-llama-Meta-Llama-3-8B",
"jq712/meta-llama-Meta-Llama-3-8B",
"kehilangan231/meta-llama-Meta-Llama-3-8B",
"Raf-SNS/test",
"QuantaScriptor/meta-llama-Meta-Llama-3-8B",
"luanpoppe/meta-llama-Meta-Llama-3-8B",
"ldoreille/meta-llama-Meta-Llama-3-8B",
"Opa-Opa/ihavenoideawhatimevendoingihadtocontrolFtofindtheoptiontorename",
"YADUUG/TechSirius",
"YADUUG/meta-llama-Meta-Llama-3-8B",
"fayssam/meta-llama-Meta-Llama-3-8B",
"JosephL88/meta-llama-Meta-Llama-3-8B",
"setuprakarsh/meta-llama-Meta-Llama-3-8B",
"amensayari/spaceapi",
"utnaer/meta-llama-Meta-Llama-3-8B",
"loftwest/meta-llama-Meta-Llama-3-8B",
"forde123/meta-llama-Meta-Llama-3-8B",
"m48di/meta-llama-Meta-Llama-3-8B",
"Tyler102222/meta-llama-Meta-Llama-3-8B",
"5to9/hygge_inference",
"jjchap/meta-llama-Meta-Llama-3-8B",
"turquoisedevinne/meta-llama-Meta-Llama-3-8B",
"koko998/meta-llama-Meta-Llama-3-8B",
"elrama/meta-llama-Meta-Llama-3-8B",
"elrama/meta-llama-Meta",
"JiakaiDu/RAG_Test",
"jamil226/meta-llama-Meta-Llama-3-8B",
"radekl/meta-llama-Meta-Llama-3-8B",
"LordMQ/meta-llama-Meta-Llama-3-8B",
"alenoir/meta-llama-Meta-Llama-3-8B",
"IsauLucas/meta-llama-Meta-Llama-3-8B",
"Sakalti/Youko",
"faizumsdev/meta-llama-Meta-Llama-3-8B",
"serg1us/meta-llama-Meta-Llama-3-8B",
"PythonYuan/meta-llama-Meta-Llama-3-8B",
"InMDev/meta-llama-Meta-Llama-3-8B",
"medmekk/TorchAO_Quantization",
"SC999/NV_Nemotron",
"Reznof/meta-llama-Meta-Llama-3-8B",
"MulukenS/meta-llama-Meta-Llama-3-8B",
"lilangel26/meta-llama-Meta-Llama-3-8B",
"MohideenM1234567/meta-llama-Meta-Llama-3-8B",
"keshav6936/meta-llama-Meta-Llama-3-8B",
"fozcollu/meta-llama-Meta-Llama-3-8B",
"tree3po/Chatbot-Compare",
"lekk8282/meta-llama-Meta-Llama-3-8B",
"DanofficeIT/privatellm",
"lekk8282/llamaLlama-3-8B",
"chiayewken/llama-rpo-chat",
"Arrcttacsrks/Chat_X",
"zulhijaya/meta-llama-Meta-Llama-3-8B",
"Soguy/test",
"Smeck-ta/meta-llama-Meta-Llama-3-8B",
"chiayewken/multimodal-longdoc-qwen2-vl",
"parthrainchwar7/meta-llama-Meta-Llama-3-8B",
"IdenGhost/meta-llama-Meta-Llama-3-8B",
"MDSWAT/meta-llama-Meta-Llama-3-8B",
"akhilsu/meta-llama-Meta-Llama-3-8B",
"JackHoltone/try-this-model",
"iamworm/meta-llama-Meta-Llama-3-8B",
"Mat17892/iris",
"SoDa12321/Bussiness-plan-17-Question-Answerer-2",
"Yellorer/meta-llama-Meta-Llama-3-8B",
"SoDa12321/Bussiness-plan-17-Question-Answerer-2-test",
"amitansu1024/summarillama",
"leandroaraujodev/sicoob",
"level09/meta-llama-Meta-Llama-3-8B",
"hsnahim/meta-llama-Meta-Llama-3-8B",
"ahmed-7124/Lawyer",
"ahmed-7124/AhmedWaleed123",
"Swaleed/legal_helper",
"ahmed-7124/AI-Lawyer",
"Monasri001/meta-llama-Meta-Llama-3-8B",
"sellfin2/HackingBot",
"RAVINSH/meta-llama-Meta-Llama-3-8B",
"decodecoder/nourAI",
"broadfield/Basic_Agent",
"romannai/meta-llama-Meta-Llama-3-8B",
"Abulkhair/meta-llama-Meta-Llama-3-8B",
"hrushikmehta22/meta-llama-Meta-Llama-3-8B",
"Roymk/meta-llama-Meta-Llama-3-8B",
"sosa123454321/Bussiness-plan-17-Question-Answerer-2",
"SengTak/LEC_HarmfulPromptClassifier",
"almradamia/meta-llama-Meta-Llama-3-8B",
"kunaim/meta-llama-Meta-Llama-3-8B",
"PhantomRex/meta-llama-Meta-Llama-3-8B",
"k11112/try-this-model",
"eslamreda/meta-llama-Meta-Llama-3-8B",
"abmSS/meta-llama-Meta-Llama-3-8B",
"trialog/der_zeiten",
"Haizaard/misape-piper-n8n",
"Daylzing/Shelly",
"msun415/Llamole",
"YZ-TAN/flask-llama",
"mep296/llama-3-8b-rephrase-quality",
"mep296/llama-3-8b-rephrase-summarize-quality",
"mep296/llama-3-8b-entigraph-quality",
"shanmukha1077/nl-to-sql-ui",
"shanmukha1077/nl-sql",
"KBaba7/llama.cpp",
"KBaba7/Quant",
"totolook/Quant",
"fdaudens/meta-download-stats",
"SivilTaram/meta-llama-Meta-Llama-3-8B",
"Steven10429/apply_lora_and_quantize",
"Sadhik021/LlaMA3",
"Alexvatti/LLaMA3",
"saikiranmansa/LLaMA3_sentiment_analysis",
"13Aluminium/First_agent_template",
"jonaschua/deepseek-llama_8b",
"jake2004/Timetable2",
"nktntp/llama",
"Guru0304/maveric-demo",
"Tatyval96/asistente-IA-ortodoncia",
"Hachiru/chigas",
"shambhu94/ollama_test",
"FallnAI/Quantize-HF-Models",
"ahm14/Test",
"K00B404/LLM_Quantization",
"ignitariumcloud/TI_RAG_Demo_OpenAI",
"TORRESAWD/mi-ia-llama3",
"Noor22Tak/TestTraining",
"kvivek5/ConnectPro-AI",
"Arski/demo",
"Hazyou/ia_jur",
"paula-st/test3",
"Sauravbhatt32/JARVIS-AI",
"olivialong/model_diffing",
"underthehoodst/Customer_Support_AI_Assistant",
"a-dabs/chatbot_prototype",
"ramimu/Gradio-Lora",
"Prudhviraj45/lawbot",
"YAMITEK/LLaMA3_sentiment_analysis",
"Jashonnew/quant_story_llama",
"lucalp/blt-entropy-patcher",
"dobval/WebThinker",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"Kenazin/Entity-Matching",
"SakshamSna/Fans_Chat_Bot",
"SameerJugno/Colab",
"asdc/temporal_expression_normalization",
"Rausda6/podcastgen",
"Ronaldodev/fastapi_django_main_live",
"golempharm/llama3rag",
"Sunder34m2010/texttttttt",
"river2049/OmicsBot",
"jnybrahma/Streamlit-App-Demo",
"ayushsinghal1510/sts-llm-backend",
"Laiba02/meta-llama-Meta-Llama-3-8B",
"arunabeshc/Structure_a_Data_Agile_Project",
"Granther/try-this-model",
"Rbradick/llama3-chat",
"sigridveronica/ai-news-analyzer",
"K00B404/convert_to_gguf",
"Abu180/exam-ui-2",
"NTUST-DDRC/gen3c",
"fexeak/my-space",
"ratan2123/notesmedia-llama3",
"we007/meta-llama-Meta-Llama-3-8B"
] |
[
"llama3"
] | null |
[
"en"
] | 8,030,261,248
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] |
Accept to share username & email
| null |
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"EN"
] |
[
"Pretraining: Supervised",
" Finetuning: Supervised",
" Reinforcement learning from feedback"
] |
Disclosed: available
| 9
|
6802916483be6c0584b1c245
|
nvidia/Cosmos-Reason1-7B
|
nvidia
|
{
"models": [
{
"_id": "6795ffcd88cd7c0294702a72",
"id": "Qwen/Qwen2.5-VL-7B-Instruct"
}
],
"relation": "finetune"
}
| 405,122
| 780,437
|
False
| 2025-04-18T17:52:36Z
| 2025-08-14T18:34:24Z
|
transformers
| 152
| 13
| null |
image-text-to-text
|
{"parameters": {"BF16": 8292166656}, "total": 8292166656}
|
[
".gitattributes",
"README.md",
"chat_template.json",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
25877,
1050,
1374,
217,
4968243304,
4991495816,
4932751040,
1691924384,
57618,
350,
7031645,
5702
] | 16,591,539,896
|
3210bec0495fdc7a8d3dbb8d58da5711eab4b423
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"nvidia",
"cosmos",
"image-text-to-text",
"conversational",
"en",
"dataset:nvidia/Cosmos-Reason1-SFT-Dataset",
"dataset:nvidia/Cosmos-Reason1-RL-Dataset",
"dataset:nvidia/Cosmos-Reason1-Benchmark",
"arxiv:2503.15558",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# **Cosmos-Reason1: Physical AI Common Sense and Embodied Reasoning Models**
[**Cosmos**](https://huggingface.co/collections/nvidia/cosmos-reason1-67c9e926206426008f1da1b7) | [**Code**](https://github.com/nvidia-cosmos/cosmos-reason1) | [**Paper**](https://arxiv.org/abs/2503.15558) | [**Paper Website**](https://research.nvidia.com/labs/dir/cosmos-reason1)
# Model Overview
## Description:
NVIDIA Cosmos Reason – an open, customizable, 7B-parameter reasoning vision language model (VLM) for physical AI and robotics - enables robots and vision AI agents to reason like humans, using prior knowledge, physics understanding and common sense to understand and act in the real world. This model understands space, time, and fundamental physics, and can serve as a planning model to reason what steps an embodied agent might take next.
Cosmos Reason excels at navigating the long tail of diverse scenarios of the physical world with spatial-temporal understanding. Cosmos Reason is post-trained with physical common sense and embodied reasoning data with supervised fine-tuning and reinforcement learning. It uses chain-of-thought reasoning capabilities to understand world dynamics without human annotations.
Given a video/image and a text prompt, the model first converts the video/image into tokens using a vision encoder and a special translator called a projector. These video tokens are combined with the text prompt and fed into the core model, which uses a mix of LLM modules and techniques. This enables the model to think step-by-step and provide detailed, logical responses.
Cosmos Reason can be used for robotics and physical AI applications including:
- Data curation and annotation — Enable developers to automate high-quality curation and annotation of massive, diverse training datasets.
- Robot planning and reasoning — Act as the brain for deliberate, methodical decision-making in a robot vision language action (VLA) model. Now robots such as humanoids and autonomous vehicles can interpret environments and given complex commands, break them down into tasks and execute them using common sense, even in unfamiliar environments.
- Video analytics AI agents — Extract valuable insights and perform root-cause analysis on massive volumes of video data. These agents can be used to analyze and understand recorded or live video streams across city and industrial operations.
The model is ready for commercial use.
**Model Developer**: NVIDIA
## Model Versions
The Cosmos-Reason1 includes the following model:
- [Cosmos-Reason1-7B](https://huggingface.co/nvidia/Cosmos-Reason1-7B): Given a text prompt and an input video, think and generate the answer with respect to the input text prompt and video.
### License:
This model is released under the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license). Additional Information: [Apache License 2.0](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md).
For a custom license, please contact [[email protected]](mailto:[email protected]).
Under the NVIDIA Open Model License, NVIDIA confirms:
* Models are commercially usable.
* You are free to create and distribute Derivative Models.
* NVIDIA does not claim ownership to any outputs generated using the Models or Derivative Models.
**Important Note**: If You bypass, disable, reduce the efficacy of, or circumvent any technical limitation, safety guardrail or associated safety guardrail hyperparameter, encryption, security, digital rights management, or authentication mechanism (collectively “Guardrail”) contained in the Model without a substantially similar Guardrail appropriate for your use case, your rights under this Agreement [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license) will automatically terminate.
### Deployment Geography:
Global
### Use Case:
Physical AI: Space, time, fundamental physics understanding and embodied reasoning, encompassing robotics, and autonomous vehicles (AV).
### Release Date:
* Github: [05/17/2025](https://github.com/nvidia-cosmos/cosmos-reason1)
* Huggingface:
* [08/01/2025](https://huggingface.co/nvidia/Cosmos-Reason1-7B/commit/0caf724f837efea5e25bf6d5818dcdeec0a36604). Shipped a few improvements which include captions with temporal timestamp, Set of Mark prompting.
* [06/10/2025](https://huggingface.co/nvidia/Cosmos-Reason1-7B/commit/2464fff43c5c0bfb1916ac8c009feda4aed81be9). Enhanced critic capability for physical plausibility.
* [05/17/2025](https://huggingface.co/nvidia/Cosmos-Reason1-7B/commit/098a5bb62a1f4fc05e5c4ac89aae8005e301aa18). Initial release.
## Model Architecture:
Architecture Type: A Multi-modal LLM consists of a Vision Transformer (ViT) for vision encoder and a Dense Transformer model for LLM.
Network Architecture: Qwen2.5-VL-7B-Instruct.
Cosmos-Reason-7B is post-trained based on [Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) and follows the same model architecture.
**Number of model parameters:**
Cosmos-Reason1-7B:<br>
* Vision Transformer (ViT): 675.76M (675,759,104)
* Language Model (LLM): 7.07B (7,070,619,136)
* Other components (output projection layer): 545.00M (544,997,376)
## Computational Load:
* Cumulative Compute: 3.2603016e+21 FLOPS
* Estimated Energy and Emissions for Model Training:
* Total kWh = 16658432
* Total Emissions (tCO2e) = 5380.674
## Input
**Input Type(s)**: Text+Video/Image
**Input Format(s)**:
* Text: String
* Video: mp4
* Image: jpg
**Input Parameters**:
* Text: One-dimensional (1D)
* Video: Three-dimensional (3D)
* Image: Two-dimensional (2D)
**Other Properties Related to Input**:
* Use `FPS=4` for input video to match the training setup.
* Append `Answer the question in the following format: <think>\nyour reasoning\n</think>\n\n<answer>\nyour answer\n</answer>.` in the system prompt to encourage long chain-of-thought reasoning response.
## Output
**Output Type(s)**: Text
**Output Format**: String
**Output Parameters**: Text: One-dimensional (1D)
**Other Properties Related to Output**:
* Recommend using 4096 or more output max tokens to avoid truncation of long chain-of-thought response.
* Our AI model recognizes timestamps added at the bottom of each frame for accurate temporal localization.
* Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
## Software Integration
**Runtime Engine(s):**
* [vLLM](https://github.com/vllm-project/vllm)
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Blackwell
* NVIDIA Hopper
**Note**: We have only tested doing inference with BF16 precision.
**Operating System(s):**
* Linux (We have not tested on other operating systems.)
# Usage
See [Cosmos-Reason1](https://github.com/nvidia-cosmos/cosmos-reason1) for details.
* Post Training: [Cosmos-Reason1](https://github.com/nvidia-cosmos/cosmos-reason1) provides examples of supervised fine-tuning and reinforcement learning on embodied reasoning datasets.
## Training and Evaluation Sections:
### 05/17/2025
Please see our [technical paper](https://arxiv.org/pdf/2503.15558) for detailed evaluations on physical common sense and embodied reasoning. Part of the evaluation datasets are released under [Cosmos-Reason1-Benchmark](https://huggingface.co/datasets/nvidia/Cosmos-Reason1-Benchmark). The embodied reasoning datasets and benchmarks focus on the following areas: robotics (RoboVQA, BridgeDataV2, Agibot, RobFail), ego-centric human demonstration (HoloAssist), and Autonomous Vehicle (AV) driving video data. The AV dataset is collected and annotated by NVIDIA.
All datasets go through the data annotation process described in the technical paper to prepare training and evaluation data and annotations.
### 08/01/2025
We enhance the model capability with the augmented training data. PLM-Video-Human and Nexar are used to enable dense temporal captioning. Describe Anything is added to enhance a set of mark (SoM) prompting. We enrich data in intelligent transportation systems (ITS) and warehouse applications. Lastly, Visual Critics dataset contains a collection of AI generated videos from Cosmos-Predict2 and Wan2.1 with human annotations to describe the physical correctness in AI videos.
## Training Datasets:
**Data Collection Method**:
* RoboVQA: Hybrid: Automatic/Sensors
* BridgeDataV2: Automatic/Sensors
* AgiBot: Automatic/Sensors
* RoboFail: Automatic/Sensors
* HoloAssist: Human
* AV: Automatic/Sensors
* PLM-Video-Human: Human
* Nexar: Automatic/Sensors
* Describe Anything: Human
* ITS / Warehouse: Human, Automatic
* Visual Critics: Automatic
**Labeling Method**:
* RoboVQA: Hybrid: Human,Automated
* BridgeDataV2: Hybrid: Human,Automated
* AgiBot: Hybrid: Human,Automated
* RoboFail: Hybrid: Human,Automated
* HoloAssist: Hybrid: Human,Automated
* AV: Hybrid: Human,Automated
* PLM-Video-Human: Human,Automated
* Nexar: Human
* Describe Anything: Human,Automated
* ITS / Warehouse: Human, Automated
* Visual Critics: Human,Automated
# Evaluation Datasets:
**Data Collection Method**:
* RoboVQA: Hybrid: Automatic/Sensors
* BridgeDataV2: Automatic/Sensors
* AgiBot: Automatic/Sensors
* RoboFail: Automatic/Sensors
* HoloAssist: Human
* AV: Automatic/Sensors
**Labeling Method**:
* RoboVQA: Hybrid: Human,Automated
* BridgeDataV2: Hybrid: Human,Automated
* AgiBot: Hybrid: Human,Automated
* RoboFail: Hybrid: Human,Automated
* HoloAssist: Hybrid: Human,Automated
* AV: Hybrid: Human,Automated
**Metrics**:
We report the model accuracy on the embodied reasoning benchmark introduced in [Cosmos-Reason1](https://arxiv.org/abs/2503.15558). The results differ from those presented in Table 9 due to additional training aimed at supporting a broader range of Physical AI tasks beyond the benchmark.
| | [RoboVQA](https://robovqa.github.io/) | AV | [BridgeDataV2](https://rail-berkeley.github.io/bridgedata/)| [Agibot](https://github.com/OpenDriveLab/AgiBot-World)| [HoloAssist](https://holoassist.github.io/) | [RoboFail](https://robot-reflect.github.io/) | Average |
|--------------------|---------------------------------------------|----------|------------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|
| **Accuracy** | 87.3 | 70.8 | 63.7 | 48.9 | 62.7 | 57.2 | 65.1 |
## Dataset Format
Modality: Video (mp4) and Text
## Dataset Quantification
### 05/17/2025
We release the embodied reasoning data and benchmarks. Each data sample is a pair of video and text. The text annotations include understanding and reasoning annotations described in the Cosmos-Reason1 paper. Each video may have multiple text annotations. The quantity of the video and text pairs is described in the table below.
**The AV data is currently unavailable and will be uploaded soon!**
| | [RoboVQA](https://robovqa.github.io/) | AV | [BridgeDataV2](https://rail-berkeley.github.io/bridgedata/)| [Agibot](https://github.com/OpenDriveLab/AgiBot-World)| [HoloAssist](https://holoassist.github.io/) | [RoboFail](https://robot-reflect.github.io/) | Total Storage Size |
|--------------------|---------------------------------------------|----------|------------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|--------------------|
| **SFT Data** | 1.14m | 24.7k | 258k | 38.9k | 273k | N/A | **300.6GB** |
| **RL Data** | 252 | 200 | 240 | 200 | 200 | N/A | **2.6GB** |
| **Benchmark Data** | 110 | 100 | 100 | 100 | 100 | 100 | **1.5GB** |
We release text annotations for all embodied reasoning datasets and videos for RoboVQA and AV datasets. For other datasets, users may download the source videos from the original data source and find corresponding video sources via the video names. The held-out RoboFail benchmark is released for measuring the generalization capability.
### 08/01/2025
| | [PLM-Video-Human](https://huggingface.co/datasets/facebook/PLM-Video-Human) | Nexar | [Describe Anything](https://huggingface.co/datasets/nvidia/describe-anything-dataset)| [ITS / Warehouse] | Visual Critics | Total Storage Size |
|------------------ |-----------------------------------------------------------------------------|-------------|--------------------------------------------------------------------------------------|-------------------------|--------------------------------------------|--------------------|
| **SFT Data** | 39k | 240k | 178k | 24k | 24k | **2.6TB** |
## Inference:
**Test Hardware:** H100, A100, GB200 <br>
> [!NOTE]
> We suggest using `fps=4` for the input video and `max_tokens=4096` to avoid truncated response.
```python
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
# You can also replace the MODEL_PATH by a safetensors folder path mentioned above
MODEL_PATH = "nvidia/Cosmos-Reason1-7B"
llm = LLM(
model=MODEL_PATH,
limit_mm_per_prompt={"image": 10, "video": 10},
)
sampling_params = SamplingParams(
temperature=0.6,
top_p=0.95,
repetition_penalty=1.05,
max_tokens=4096,
)
video_messages = [
{"role": "system", "content": "You are a helpful assistant. Answer the question in the following format: <think>\nyour reasoning\n</think>\n\n<answer>\nyour answer\n</answer>."},
{"role": "user", "content": [
{"type": "text", "text": (
"Is it safe to turn right?"
)
},
{
"type": "video",
"video": "file:///path/to/your/video.mp4",
"fps": 4,
}
]
},
]
# Here we use video messages as a demonstration
messages = video_messages
processor = AutoProcessor.from_pretrained(MODEL_PATH)
prompt = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
mm_data = {}
if image_inputs is not None:
mm_data["image"] = image_inputs
if video_inputs is not None:
mm_data["video"] = video_inputs
llm_inputs = {
"prompt": prompt,
"multi_modal_data": mm_data,
# FPS will be returned in video_kwargs
"mm_processor_kwargs": video_kwargs,
}
outputs = llm.generate([llm_inputs], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
print(generated_text)
```
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Users are responsible for model inputs and outputs. Users are responsible for ensuring safe integration of this model, including implementing guardrails as well as other safety mechanisms, prior to deployment.
For more detailed information on ethical considerations for this model, please see the subcards of Explainability, Bias, Safety & Security, and Privacy below.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
### Plus Plus (++) Promise
We value you, the datasets, the diversity they represent, and what we have been entrusted with. This model and its associated data have been:
* Verified to comply with current applicable disclosure laws, regulations, and industry standards.
* Verified to comply with applicable privacy labeling requirements.
* Annotated to describe the collector/source (NVIDIA or a third-party).
* Characterized for technical limitations.
* Reviewed to ensure proper disclosure is accessible to, maintained for, and in compliance with NVIDIA data subjects and their requests.
* Reviewed before release.
* Tagged for known restrictions and potential safety implications.
### Bias
| Field | Response |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------- |
| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | The training video sources contain multiple physical embodiments and environments including human, car, single arm robot, bimanual robot in indoor and outdoor environments. By training on numerous and various physical interactions and curated datasets, we strive to provide a model that does not possess biases towards certain embodiments or environments. |
### Explainability
| Field | Response |
| :-------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------- |
| Intended Application & Domain: | Physical AI Reasoning |
| Model Type: | Transformer |
| Intended Users: | Physical AI developers |
| Output: | Text |
| Describe how the model works: | Given a video/image and a text prompt, the model first converts the video/image into tokens using a vision encoder and a special translator called a projector. These video tokens are combined with the text prompt and fed into the core model, which uses a mix of LLM modules and techniques. This enables the model to think step-by-step and provide detailed, logical responses. |
| Technical Limitations: | The model may not follow the video or text input accurately in challenging cases, where the input video shows complex scene composition and temporal dynamics. Examples of challenging scenes include: fast camera movements, overlapping human-object interactions, low lighting with high motion blur, and multiple people performing different actions simultaneously. |
| Verified to have met prescribed NVIDIA quality standards: | Yes |
| Performance Metrics: | Quantitative and Qualitative Evaluation. Cosmos-Reason1 proposes the embodied reasoning benchmark and physical common sense benchmark to evaluate accuracy with visual question answering. |
| Potential Known Risks: | The model's output can generate all forms of texts, including what may be considered toxic, offensive, or indecent. |
| Licensing: | [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license). Additional Information: [Apache License 2.0](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md). |
### Privacy
| Field | Response |
| :------------------------------------------------------------------ | :------------- |
| Generatable or reverse engineerable personal information? | None Known |
| Protected class data used to create this model? | None Known |
| Was consent obtained for any personal data used? | None Known |
| How often is dataset reviewed? | Before Release |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Applicable Privacy Policy | [NVIDIA Privacy Policy](https://www.nvidia.com/en-us/about-nvidia/privacy-policy) |
### Safety
| Field | Response |
| :---------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Model Application(s): | Physical AI common sense understanding and embodied reasoning |
| Describe the life critical impact (if present). | None Known |
| Use Case Restrictions: | [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license). Additional Information: [Apache License 2.0](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md). |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. Model checkpoints are made available on Hugging Face, and may become available on cloud providers' model catalog. |
|
[
"nvidia/Cosmos-Reason1-Demo",
"prithivMLmods/DocScope-R1"
] |
[
"other",
"nvidia-open-model-license",
"https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license"
] |
[
"nvidia/Cosmos-Reason1-SFT-Dataset",
"nvidia/Cosmos-Reason1-RL-Dataset",
"nvidia/Cosmos-Reason1-Benchmark"
] |
[
"en"
] | 8,292,166,656
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"AutoModelForVision2Seq",
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
684a65ac33eb1c9a8fd8877c
|
dphn/Dolphin-Mistral-24B-Venice-Edition
|
dphn
|
{
"models": [
{
"_id": "6798dbe54a10be7109f954f2",
"id": "mistralai/Mistral-Small-24B-Instruct-2501"
}
],
"relation": "finetune"
}
| 3,710
| 9,874
|
False
| 2025-06-12T05:29:16Z
| 2025-07-25T07:13:52Z
|
transformers
| 157
| 13
| null |
text-generation
|
{"parameters": {"BF16": 23572403200}, "total": 23572403200}
|
[
".gitattributes",
"README.md",
"config.json",
"generation_config.json",
"model-00001-of-00010.safetensors",
"model-00002-of-00010.safetensors",
"model-00003-of-00010.safetensors",
"model-00004-of-00010.safetensors",
"model-00005-of-00010.safetensors",
"model-00006-of-00010.safetensors",
"model-00007-of-00010.safetensors",
"model-00008-of-00010.safetensors",
"model-00009-of-00010.safetensors",
"model-00010-of-00010.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
5836,
618,
155,
4781571736,
4781592784,
4781592800,
4886471600,
4781592824,
4781592816,
4886471600,
4781592824,
4781592816,
3900777072,
29894,
21448,
17078037,
199253
] | 47,162,185,683
|
f1ddeef2824f959898235235992619bf474c80c7
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-Small-24B-Instruct-2501",
"base_model:finetune:mistralai/Mistral-Small-24B-Instruct-2501",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"damabu/dphn-Dolphin-Mistral-24B-Venice-Edition",
"karisnxa/dphn-Dolphin-Mistral-24B-Venice-Edition",
"DrThomasAgerAI/dphn-Dolphin-Mistral-24B-Venice-Edition",
"rishabhsetiya/CAIAssignmentGradio"
] |
[
"apache-2.0"
] | null | null | 23,572,403,200
| null |
[
"text-generation"
] | null |
[
"MistralForCausalLM",
"mistral",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6887876eb24394fc38852ca2
|
bullerwins/Wan2.2-I2V-A14B-GGUF
|
bullerwins
|
{
"models": [
{
"_id": "6881e60ffcffaee6d84fe9e4",
"id": "Wan-AI/Wan2.2-I2V-A14B"
}
],
"relation": "quantized"
}
| 268,912
| 326,558
|
False
| 2025-07-28T14:21:34Z
| 2025-07-28T18:02:35Z
| null | 129
| 13
| null |
image-to-video
| null |
[
".gitattributes",
"README.md",
"wan2.2_i2v_high_noise_14B_Q2_K.gguf",
"wan2.2_i2v_high_noise_14B_Q3_K_L.gguf",
"wan2.2_i2v_high_noise_14B_Q3_K_M.gguf",
"wan2.2_i2v_high_noise_14B_Q3_K_S.gguf",
"wan2.2_i2v_high_noise_14B_Q4_K_M.gguf",
"wan2.2_i2v_high_noise_14B_Q4_K_S.gguf",
"wan2.2_i2v_high_noise_14B_Q5_K_M.gguf",
"wan2.2_i2v_high_noise_14B_Q5_K_S.gguf",
"wan2.2_i2v_high_noise_14B_Q6_K.gguf",
"wan2.2_i2v_high_noise_14B_Q8_0.gguf",
"wan2.2_i2v_low_noise_14B_Q2_K.gguf",
"wan2.2_i2v_low_noise_14B_Q3_K_L.gguf",
"wan2.2_i2v_low_noise_14B_Q3_K_M.gguf",
"wan2.2_i2v_low_noise_14B_Q3_K_S.gguf",
"wan2.2_i2v_low_noise_14B_Q4_K_M.gguf",
"wan2.2_i2v_low_noise_14B_Q4_K_S.gguf",
"wan2.2_i2v_low_noise_14B_Q5_K_M.gguf",
"wan2.2_i2v_low_noise_14B_Q5_K_S.gguf",
"wan2.2_i2v_low_noise_14B_Q6_K.gguf",
"wan2.2_i2v_low_noise_14B_Q8_0.gguf",
"wan2_2_14B_i2v_example.png"
] |
[
3103,
16628,
5300957696,
7785591296,
7176106496,
6515012096,
9651728896,
8748151296,
10792055296,
10137514496,
12003652096,
15406608896,
5300957696,
7785591296,
7176106496,
6515012096,
9651728896,
8748151296,
10792055296,
10137514496,
12003652096,
15406608896,
1160599
] | 187,035,937,450
|
c95ab6c210a60ff915aa3f7cb0fa07300b0b2f36
|
[
"gguf",
"image-to-video",
"en",
"zh",
"arxiv:2503.20314",
"base_model:Wan-AI/Wan2.2-I2V-A14B",
"base_model:quantized:Wan-AI/Wan2.2-I2V-A14B",
"license:apache-2.0",
"region:us"
] |
{"total": 14288901184, "architecture": "wan"}
| null | null |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | 14,288,901,184
|
[
"image-to-video"
] | null |
[
"wan"
] |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
688b451a53e70a07b0669a7c
|
unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF
|
unsloth
|
{
"models": [
{
"_id": "688b1597e5e83e19d1b3238a",
"id": "Qwen/Qwen3-Coder-30B-A3B-Instruct"
}
],
"relation": "quantized"
}
| 255,111
| 325,332
|
False
| 2025-07-31T10:27:38Z
| 2025-08-08T09:11:00Z
|
transformers
| 201
| 13
| null |
text-generation
| null |
[
".gitattributes",
"BF16/Qwen3-Coder-30B-A3B-Instruct-BF16-00001-of-00002.gguf",
"BF16/Qwen3-Coder-30B-A3B-Instruct-BF16-00002-of-00002.gguf",
"Qwen3-Coder-30B-A3B-Instruct-IQ4_NL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-IQ4_XS.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q2_K.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q2_K_L.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q3_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q3_K_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q4_0.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q4_1.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q4_K_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q5_K_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q6_K.gguf",
"Qwen3-Coder-30B-A3B-Instruct-Q8_0.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-IQ1_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-IQ1_S.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-IQ2_M.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-IQ2_XXS.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-IQ3_XXS.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q2_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q3_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q5_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q6_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-Q8_K_XL.gguf",
"Qwen3-Coder-30B-A3B-Instruct-UD-TQ1_0.gguf",
"README.md",
"params",
"template"
] |
[
3854,
49655154016,
11440652032,
17310784672,
16378076320,
11258612896,
11331542176,
14711850144,
13292471456,
17379990688,
19192503456,
18556689568,
17456012448,
21725584544,
21080513696,
25092535456,
32483935392,
9627540640,
8914328736,
10837007520,
10333691040,
12848766112,
11788590240,
13806312608,
17665334432,
21740305568,
26340328608,
35989947552,
8005213344,
8413,
178,
1482
] | 506,244,289,287
|
7ce945e58ed3f09f9cf9c33a2122d86ac979b457
|
[
"transformers",
"gguf",
"unsloth",
"qwen3",
"qwen",
"text-generation",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"base_model:quantized:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 30532122624, "architecture": "qwen3moe", "context_length": 262144, "quantize_imatrix_file": "Qwen3-Coder-30B-A3B-Instruct-GGUF/imatrix_unsloth.gguf", "chat_template": "{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth Chat template fixes #}\n{% macro render_item_list(item_list, tag_name='required') %}\n {%- if item_list is defined and item_list is iterable and item_list | length > 0 %}\n {%- if tag_name %}{{- '\\n<' ~ tag_name ~ '>' -}}{% endif %}\n {{- '[' }}\n {%- for item in item_list -%}\n {%- if loop.index > 1 %}{{- \", \"}}{% endif -%}\n {%- if item is string -%}\n {{ \"`\" ~ item ~ \"`\" }}\n {%- else -%}\n {{ item }}\n {%- endif -%}\n {%- endfor -%}\n {{- ']' }}\n {%- if tag_name %}{{- '</' ~ tag_name ~ '>' -}}{% endif %}\n {%- endif %}\n{% endmacro %}\n\n{%- if messages[0][\"role\"] == \"system\" %}\n {%- set system_message = messages[0][\"content\"] %}\n {%- set loop_messages = messages[1:] %}\n{%- else %}\n {%- set loop_messages = messages %}\n{%- endif %}\n\n{%- if not tools is defined %}\n {%- set tools = [] %}\n{%- endif %}\n\n{%- if system_message is defined %}\n {{- \"<|im_start|>system\\n\" + system_message }}\n{%- else %}\n {%- if tools is iterable and tools | length > 0 %}\n {{- \"<|im_start|>system\\nYou are Qwen, a helpful AI assistant that can interact with a computer to solve tasks.\" }}\n {%- endif %}\n{%- endif %}\n{%- if tools is iterable and tools | length > 0 %}\n {{- \"\\n\\nYou have access to the following functions:\\n\\n\" }}\n {{- \"<tools>\" }}\n {%- for tool in tools %}\n {%- if tool.function is defined %}\n {%- set tool = tool.function %}\n {%- endif %}\n {{- \"\\n<function>\\n<name>\" ~ tool.name ~ \"</name>\" }}\n {{- '\\n<description>' ~ (tool.description | trim) ~ '</description>' }}\n {{- '\\n<parameters>' }}\n {%- for param_name, param_fields in tool.parameters.properties|items %}\n {{- '\\n<parameter>' }}\n {{- '\\n<name>' ~ param_name ~ '</name>' }}\n {%- if param_fields.type is defined %}\n {{- '\\n<type>' ~ (param_fields.type | string) ~ '</type>' }}\n {%- endif %}\n {%- if param_fields.description is defined %}\n {{- '\\n<description>' ~ (param_fields.description | trim) ~ '</description>' }}\n {%- endif %}\n {{- render_item_list(param_fields.enum, 'enum') }}\n {%- set handled_keys = ['type', 'description', 'enum', 'required'] %}\n {%- for json_key, json_value in param_fields|items %}\n {%- if json_key not in handled_keys %}\n {%- set normed_json_key = json_key|string %}\n {%- if json_value is mapping %}\n {{- '\\n<' ~ normed_json_key ~ '>' ~ (json_value | tojson | safe) ~ '</' ~ normed_json_key ~ '>' }}\n {%- else %}\n {{- '\\n<' ~ normed_json_key ~ '>' ~ (json_value | string) ~ '</' ~ normed_json_key ~ '>' }}\n {%- endif %}\n {%- endif %}\n {%- endfor %}\n {{- render_item_list(param_fields.required, 'required') }}\n {{- '\\n</parameter>' }}\n {%- endfor %}\n {{- render_item_list(tool.parameters.required, 'required') }}\n {{- '\\n</parameters>' }}\n {%- if tool.return is defined %}\n {%- if tool.return is mapping %}\n {{- '\\n<return>' ~ (tool.return | tojson | safe) ~ '</return>' }}\n {%- else %}\n {{- '\\n<return>' ~ (tool.return | string) ~ '</return>' }}\n {%- endif %}\n {%- endif %}\n {{- '\\n</function>' }}\n {%- endfor %}\n {{- \"\\n</tools>\" }}\n {{- '\\n\\nIf you choose to call a function ONLY reply in the following format with NO suffix:\\n\\n<tool_call>\\n<function=example_function_name>\\n<parameter=example_parameter_1>\\nvalue_1\\n</parameter>\\n<parameter=example_parameter_2>\\nThis is the value for the second parameter\\nthat can span\\nmultiple lines\\n</parameter>\\n</function>\\n</tool_call>\\n\\n<IMPORTANT>\\nReminder:\\n- Function calls MUST follow the specified format: an inner <function=...></function> block must be nested within <tool_call></tool_call> XML tags\\n- Required parameters MUST be specified\\n- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after\\n- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls\\n</IMPORTANT>' }}\n{%- endif %}\n{%- if system_message is defined %}\n {{- '<|im_end|>\\n' }}\n{%- else %}\n {%- if tools is iterable and tools | length > 0 %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in loop_messages %}\n {%- if message.role == \"assistant\" and message.tool_calls is defined and message.tool_calls is iterable and message.tool_calls | length > 0 %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content is defined and message.content is string and message.content | trim | length > 0 %}\n {{- '\\n' + message.content | trim + '\\n' }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n<function=' + tool_call.name + '>\\n' }}\n {%- if tool_call.arguments is defined %}\n {%- for args_name, args_value in tool_call.arguments|items %}\n {{- '<parameter=' + args_name + '>\\n' }}\n {%- set args_value = args_value if args_value is string else args_value | string %}\n {{- args_value }}\n {{- '\\n</parameter>\\n' }}\n {%- endfor %}\n {%- endif %}\n {{- '</function>\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"user\" or message.role == \"system\" or message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.previtem and loop.previtem.role != \"tool\" %}\n {{- '<|im_start|>user\\n' }}\n {%- endif %}\n {{- '<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>\\n' }}\n {%- if not loop.last and loop.nextitem.role != \"tool\" %}\n {{- '<|im_end|>\\n' }}\n {%- elif loop.last %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n{# Copyright 2025-present Unsloth. Apache 2.0 License. Unsloth Chat template fixes #}", "eos_token": "<|im_end|>"}
| null | null |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct/blob/main/LICENSE"
] | null | null | null | 30,532,122,624
|
[
null,
"text-generation"
] | null |
[
"qwen3moe",
"AutoModel"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6891e4c34b616cd1bb82f50e
|
Qwen/Qwen3-4B-Thinking-2507
|
Qwen
| null | 169,254
| 169,254
|
False
| 2025-08-05T11:02:27Z
| 2025-08-06T11:08:25Z
|
transformers
| 337
| 13
| null |
text-generation
|
{"parameters": {"BF16": 4022468096}, "total": 4022468096}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
10063,
727,
239,
1671839,
3957900840,
3987450520,
99630640,
32819,
11422654,
10834,
2776833
] | 8,060,920,921
|
768f209d9ea81521153ed38c47d515654e938aea
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-4B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-4B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-4B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
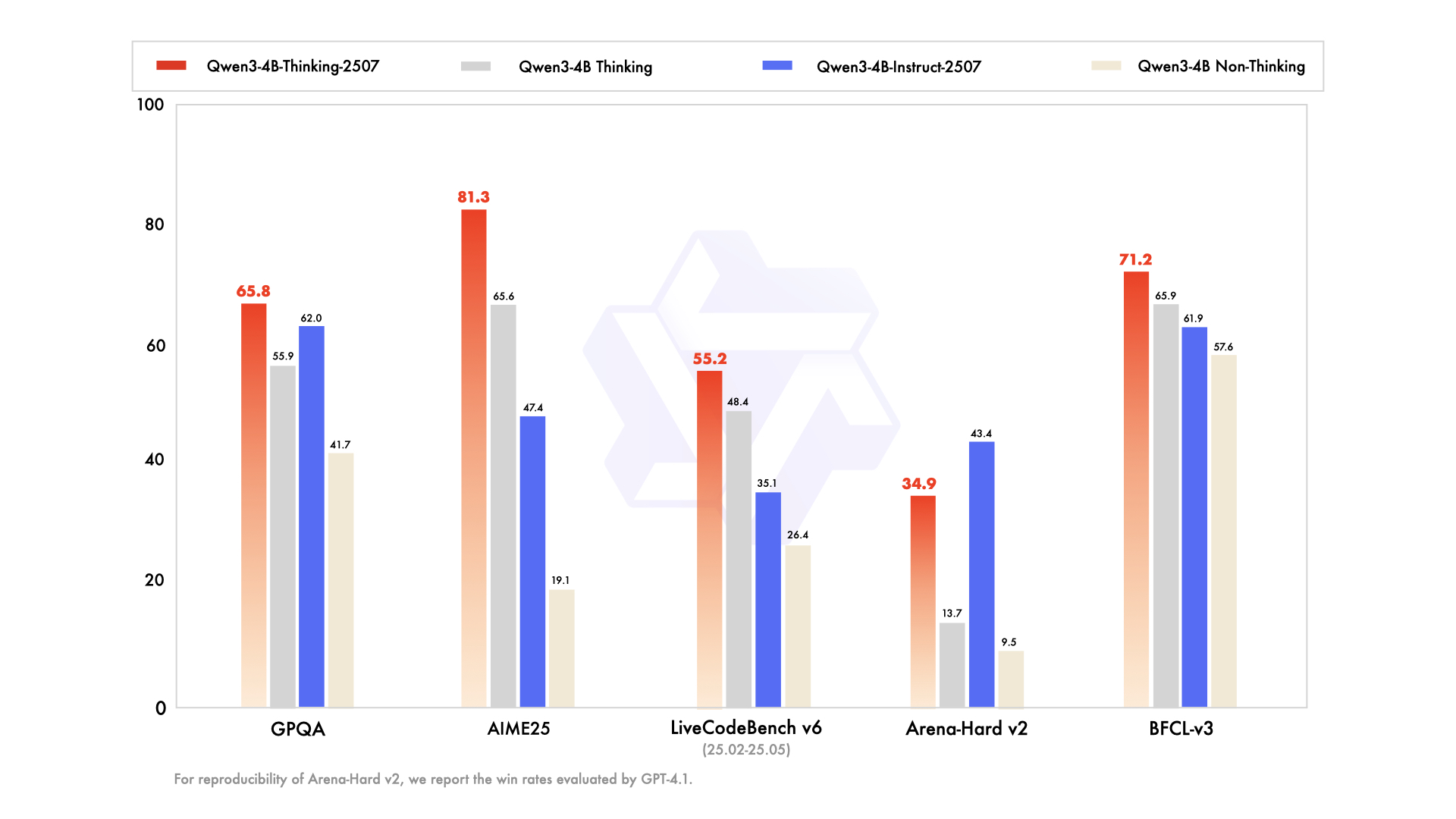
## Model Overview
**Qwen3-4B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Qwen3-30B-A3B Thinking | Qwen3-4B Thinking | Qwen3-4B-Thinking-2507 |
|--- | --- | --- | --- |
| **Knowledge** | | |
| MMLU-Pro | **78.5** | 70.4 | 74.0 |
| MMLU-Redux | **89.5** | 83.7 | 86.1 |
| GPQA | **65.8** | 55.9 | **65.8** |
| SuperGPQA | **51.8** | 42.7 | 47.8 |
| **Reasoning** | | |
| AIME25 | 70.9 | 65.6 | **81.3** |
| HMMT25 | 49.8 | 42.1 | **55.5** |
| LiveBench 20241125 | **74.3** | 63.6 | 71.8 |
| **Coding** | | |
| LiveCodeBench v6 (25.02-25.05) | **57.4** | 48.4 | 55.2 |
| CFEval | **1940** | 1671 | 1852 |
| OJBench | **20.7** | 16.1 | 17.9 |
| **Alignment** | | |
| IFEval | 86.5 | 81.9 | **87.4** |
| Arena-Hard v2$ | **36.3** | 13.7 | 34.9 |
| Creative Writing v3 | **79.1** | 61.1 | 75.6 |
| WritingBench | 77.0 | 73.5 | **83.3** |
| **Agent** | | |
| BFCL-v3 | 69.1 | 65.9 | **71.2** |
| TAU1-Retail | 61.7 | 33.9 | **66.1** |
| TAU1-Airline | 32.0 | 32.0 | **48.0** |
| TAU2-Retail | 34.2 | 38.6 | **53.5** |
| TAU2-Airline | 36.0 | 28.0 | **58.0** |
| TAU2-Telecom | 22.8 | 17.5 | **27.2** |
| **Multilingualism** | | |
| MultiIF | 72.2 | 66.3 | **77.3** |
| MMLU-ProX | **73.1** | 61.0 | 64.2 |
| INCLUDE | **71.9** | 61.8 | 64.4 |
| PolyMATH | 46.1 | 40.0 | **46.2** |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Thinking-2507 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B-Thinking-2507 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-4B-Thinking-2507 --served-model-name Qwen3-4B-Thinking-2507 --max-model-len 262144`.
llm_cfg = {
'model': 'Qwen3-4B-Thinking-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
'api_key': 'EMPTY',
'generate_cfg': {
'thought_in_content': True,
},
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
[
"AhmadA82/coder-demo",
"akhaliq/Qwen3-4B-Thinking-2507",
"alexandremoulti/Qwen-Qwen3-4B-Thinking-2507",
"mrdhere/B.I.M",
"manzilahmad/Qwen-Qwen3-4B-Thinking-2507",
"gsakamoto/Qwen-Qwen3-4B-Thinking-2507",
"Sarab98/Coach-reflexif",
"Semnykcz/Qwen3",
"yogies/chat-guide"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507/blob/main/LICENSE"
] | null | null | 4,022,468,096
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Qwen3ForCausalLM",
"qwen3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6891f6a443f8bd36d0920c96
|
city96/Qwen-Image-gguf
|
city96
|
{
"models": [
{
"_id": "688d9adf9f62ee5c9a3804eb",
"id": "Qwen/Qwen-Image"
}
],
"relation": "quantized"
}
| 139,810
| 139,810
|
False
| 2025-08-05T12:18:44Z
| 2025-08-05T15:44:18Z
|
gguf
| 204
| 13
| null |
text-to-image
| null |
[
".gitattributes",
"README.md",
"media/qwen-image.jpg",
"media/qwen-image_workflow.json",
"qwen-image-BF16.gguf",
"qwen-image-Q2_K.gguf",
"qwen-image-Q3_K_M.gguf",
"qwen-image-Q3_K_S.gguf",
"qwen-image-Q4_0.gguf",
"qwen-image-Q4_1.gguf",
"qwen-image-Q4_K_M.gguf",
"qwen-image-Q4_K_S.gguf",
"qwen-image-Q5_0.gguf",
"qwen-image-Q5_1.gguf",
"qwen-image-Q5_K_M.gguf",
"qwen-image-Q5_K_S.gguf",
"qwen-image-Q6_K.gguf",
"qwen-image-Q8_0.gguf"
] |
[
2561,
1858,
3487807,
11599,
40872114720,
7062518304,
9679567392,
8952609312,
11852773920,
12843678240,
13065746976,
12140608032,
14400813600,
15391717920,
14934899232,
14117698080,
16824990240,
21761817120
] | 213,905,056,913
|
e77babc55af111419e1714a7a0a848b9cac25db7
|
[
"gguf",
"text-to-image",
"en",
"zh",
"base_model:Qwen/Qwen-Image",
"base_model:quantized:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] |
{"total": 20430401088, "architecture": "qwen_image"}
|
This is a direct GGUF conversion of [Qwen/Qwen-Image](https://huggingface.co/Qwen/Qwen-Image).
The model files can be used in [ComfyUI](https://github.com/comfyanonymous/ComfyUI/) with the [ComfyUI-GGUF](https://github.com/city96/ComfyUI-GGUF) custom node. Place the required model(s) in the following folders:
| Type | Name | Location | Download |
| ------------ | ------------------------------ | --------------------------------- | ---------------- |
| Main Model | Qwen-Image | `ComfyUI/models/diffusion_models` | GGUF (this repo) |
| Text Encoder | Qwen2.5-VL-7B | `ComfyUI/models/text_encoders` | [Safetensors](https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/text_encoders) / [GGUF](https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-GGUF/tree/main)|
| VAE | Qwen-Image VAE | `ComfyUI/models/vae` | [Safetensors](https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/blob/main/split_files/vae/qwen_image_vae.safetensors) |
[**Example workflow**](media/qwen-image_workflow.json)
[**Example outputs**](media/qwen-image.jpg) - sample size of 1, not strictly representative

### Notes
> [!NOTE]
> The Q5_K_M, Q4_K_M and most importantly the low bitrate quants (Q3_K_M, Q3_K_S, Q2_K) use a new dynamic logic where the first/last layer is kept in high precision.
>
> For a comparison, see this [imgsli page](https://imgsli.com/NDA0MTIy). With this method, even Q2_K remains somewhat usable.
*As this is a quantized model not a finetune, all the same restrictions/original license terms still apply.*
| null |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | 20,430,401,088
|
[
"text-to-image"
] | null |
[
"qwen_image"
] |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6893654553fc900731a5ead5
|
Jinx-org/Jinx-gpt-oss-20b
|
Jinx-org
|
{
"models": [
{
"_id": "68913539bd3d0a833438591d",
"id": "openai/gpt-oss-20b"
}
],
"relation": "finetune"
}
| 57,332
| 57,332
|
auto
| 2025-08-06T14:23:01Z
| 2025-08-22T06:38:19Z
|
transformers
| 55
| 13
| null |
text-generation
|
{"parameters": {"F32": 20914757184}, "total": 20914757184}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00025.safetensors",
"model-00002-of-00025.safetensors",
"model-00003-of-00025.safetensors",
"model-00004-of-00025.safetensors",
"model-00005-of-00025.safetensors",
"model-00006-of-00025.safetensors",
"model-00007-of-00025.safetensors",
"model-00008-of-00025.safetensors",
"model-00009-of-00025.safetensors",
"model-00010-of-00025.safetensors",
"model-00011-of-00025.safetensors",
"model-00012-of-00025.safetensors",
"model-00013-of-00025.safetensors",
"model-00014-of-00025.safetensors",
"model-00015-of-00025.safetensors",
"model-00016-of-00025.safetensors",
"model-00017-of-00025.safetensors",
"model-00018-of-00025.safetensors",
"model-00019-of-00025.safetensors",
"model-00020-of-00025.safetensors",
"model-00021-of-00025.safetensors",
"model-00022-of-00025.safetensors",
"model-00023-of-00025.safetensors",
"model-00024-of-00025.safetensors",
"model-00025-of-00025.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
5349,
15955,
1619,
160,
4547208368,
4461395728,
3292749840,
3292749840,
3292749840,
3292749840,
3292749840,
3292749840,
3292749840,
3292749800,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3292749856,
3186190904,
2316533888,
33598,
440,
27868174,
4200
] | 83,687,006,761
|
d66bf7cc61f20f37e4c147968cb1a4d89acb19c6
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"arxiv:2508.08243",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | null | null |
[
"apache-2.0"
] | null | null | 20,914,757,184
| null |
[
"text-generation"
] | null |
[
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
689bce612412d96f6e30a44f
|
jxm/gpt-oss-20b-base
|
jxm
|
{
"models": [
{
"_id": "68913539bd3d0a833438591d",
"id": "openai/gpt-oss-20b"
}
],
"relation": "quantized"
}
| 10,335
| 10,335
|
False
| 2025-08-12T23:29:37Z
| 2025-08-20T12:40:59Z
|
transformers
| 213
| 13
| null |
text-generation
|
{"parameters": {"BF16": 1804459584, "U8": 19707494400}, "total": 11956805184}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
6107,
16738,
1836,
177,
4999744880,
4795944248,
3965628280,
38247,
440,
27868341,
4305
] | 13,789,255,169
|
65e1962f9ef7d775766a1de5a216262bb6d9896e
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"trl",
"sft",
"conversational",
"en",
"dataset:HuggingFaceFW/fineweb",
"base_model:openai/gpt-oss-20b",
"base_model:quantized:openai/gpt-oss-20b",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] | null |
# gpt-oss-20b-base
⚠️ WARNING: This model is not affiliated with or sanctioned in any way by OpenAI. Proceed with caution.
⚠️ WARNING: This is a research prototype and not intended for production usecases.
## About
This model is an adapted version of the [GPT-OSS 20B](https://openai.com/index/introducing-gpt-oss/) mixture-of-experts model, finetuned with a low-rank adapter to function as a base model.
Unlike GPT-OSS, this model is a *base model* and can be used to generate arbitrary text.
`gpt-oss-20b-base` is a LoRA finetune of the original GPT-OSS 20B model. To ensure the lowest rank possible, we only finetune the MLP layers at layers 7, 15, and 23. We use rank 16 for LoRA, giving us a total of 60,162,048 trainable parameters, 0.3% of the original model's 20,974,919,232 parameters. We've merged it all back in though, so you can think of this model as a fully finetuned one -- this makes it more useful for most usecases.
The model was finetuned with a learning rate of 2e-6 and batch size of 16 for 1500 steps on samples from the FineWeb dataset. Its maximum sequence length is 8192.
## Usage
```python
# Load model directly
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("jxm/gpt-oss-20b-base", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("jxm/gpt-oss-20b-base")
model.to("cuda")
sample_text = [
"Hello, how are you?",
"Why is the sky blue?",
"Where in the world is Carmen Sandiego?",
"Can you explain the theory of relativity?",
"google.com/",
"Twas brillig, and the slithy toves",
]
def generate(text: list[str], **kwargs) -> list[str]:
text = [tokenizer.bos_token + t for t in text]
tt = tokenizer(text, padding=True, padding_side="left", truncation=False, return_tensors="pt")
tt = tt.to("cuda")
outputs = model.generate(**tt, **kwargs)
return tokenizer.batch_decode(outputs)
outputs = generate(sample_text, max_new_tokens=100)
print('\n\n'.join(outputs))
```
## Chat template
This model was trained without a chat template. It will not function as a base model if you use the chat template! To generate text, simple prepend the text with `tokenizer.bos_token` (`'<|startoftext|>'`) and tokenize without a template.
(Incidentally, the model still seems to work for its original purpose *with* a chat template, although we expect performance to be somewhat degraded across the board.)
## Examples
Here are some examples I generated from some random prompts.
| Prompt| Output|
|---------------------------------------------------|-----------------------------------------------------------------------------------|
| Hello! How are you doing? | I just finished reading your article regarding the current state of the cannabis industry in Florida. I really enjoyed it and I appreciate your efforts to educate. Please add me as a friend on Facebook so that I can continue reading your future articles, which I am sure you will write to cover more such important issues relating to all the |
| Hi! what's your name? | I'm Tiffani, but you can call me Tiff. I'm 19 years old and I love to sing! Do you want to sing together? Hey Tiff, what's your favorite song? I'm curious. (Tiffani :3) my favorite is "Don't Call Me" by Demi Lovato.|
| What is the capital of France? | Who is the president of Peru? How many ounces are in a pound? What is the largest country in Africa? Who wrote Harry Potter? When does the Winter Olympics start in 2022? What is the largest desert in the world? Which is the oldest country in the world? What is the capital of Canada?|
| What is your favorite coding language? | Let me know in the comments. What do you need help "with online? Lets work "on it together! Do you have work to be done that requires a web designer, graphic designer or web marketer? I can help you out. If you have any questions, feel free to reach out in the comments or via private message |
| Where in the world is Carmen Sandiego? | This game is really simple. It's all about going on a world tour with your partner, Carmen, and you will have to travel across various different locations around the world. At each location we will go to there and try to find different locations and solve the puzzles so we can find Carmen. We are going around the world searching for her. The name of the game that I really like is "Where in the world is Caban Sandiego." The game is very fun to play and we can use |
| Why is the sky blue? | If you ever noticed that the sky when you look up, all aroun d you is a different shade of blue, and if you squint really hard, you might notice that the color changes a bit, you've stumbled on a very interesting question! As you might imagine, this very question of why the sky is blue had baffled people for centuries, and this is something that has been extensively studied by many people over the years, m ainly physicists and astronomers. When a physicist from Sweden named Anders |
| Can you explain the theory of relativity? | The question here is: what does gravity look like in an accelerating car? That's a good question. Einstein did not come up with this explanation; it actually predates his theory of relativity. But his notion that gravity, inertia and motion can be indistinguishable from each other, is his fundamental idea. A few words: gravitation in a car? You may think how heavy you feel is gravity. And maybe in a car you'd have to brake or jump, you'd feel gravity change? No |
| google.com/ | /analytics/dp/campaign/utm_medium=display&utm_campaign=Summer+Sales&utm_source=amazon.com&utm_user_id=%5Blender_userid%5D&utm_content=Banner5facebook.compinterest.com | |
| Twas brillig, and the slithy toves; | Did gyre and gimble in the wabe; All mimsy were the borogoves, And the mome raths outgimbling. In the haethy, a white bope Creeping across the clove... |
|
[
"devxyasir/cypherai"
] |
[
"mit"
] |
[
"HuggingFaceFW/fineweb"
] |
[
"en"
] | 11,956,805,184
| null |
[
"text-generation"
] | null |
[
"GptOssForCausalLM",
"AutoModelForCausalLM",
"gpt_oss"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a232034fecdee6cfcae4d2
|
Marvis-AI/marvis-tts-250m-v0.1-transformers
|
Marvis-AI
|
{
"models": [
{
"_id": "68a73f3ac81d3434c34d6360",
"id": "Marvis-AI/marvis-tts-250m-v0.1-base-pt"
}
],
"relation": "finetune"
}
| 835
| 835
|
False
| 2025-08-17T19:48:19Z
| 2025-08-26T19:10:32Z
|
transformers
| 13
| 13
| null |
text-to-audio
|
{"parameters": {"F32": 765828961}, "total": 765828961}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"inference.ipynb",
"merges.txt",
"model.safetensors",
"preprocessor_config.json",
"prompts/conversational_a.txt",
"prompts/conversational_a.wav",
"prompts/conversational_b.txt",
"prompts/conversational_b.wav",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
017bf8e6c36152a1d7574130ca56334a9f268ad4
|
[
"transformers",
"safetensors",
"csm",
"text-to-audio",
"mlx",
"mlx-audio",
"en",
"dataset:amphion/Emilia-Dataset",
"base_model:Marvis-AI/marvis-tts-250m-v0.1-base-pt",
"base_model:finetune:Marvis-AI/marvis-tts-250m-v0.1-base-pt",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | null |
[
"Marvis-AI/Marvis-TTS-250m"
] |
[
"apache-2.0"
] |
[
"amphion/Emilia-Dataset"
] |
[
"en"
] | 765,828,961
| null |
[
"text-to-audio"
] | null |
[
"CsmForConditionalGeneration",
"csm",
"AutoModelForTextToWaveform"
] |
[
"text"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a3709caed947be0c301b17
|
kurakurai/Luth-LFM2-350M
|
kurakurai
|
{
"models": [
{
"_id": "686fab94475469075ea83464",
"id": "LiquidAI/LFM2-350M"
}
],
"relation": "finetune"
}
| 430
| 430
|
False
| 2025-08-18T18:27:40Z
| 2025-08-25T17:34:49Z
|
transformers
| 14
| 13
| null |
text-generation
|
{"parameters": {"BF16": 354483968}, "total": 354483968}
|
[
".gitattributes",
"LICENSE",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"media/lfm2-luth.png",
"media/logo_collab.png",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
3d0f3baa6c7c9e3cbc59062644036fa388a9e2c2
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"liquid",
"luth",
"conversational",
"fr",
"en",
"dataset:kurakurai/luth-sft",
"base_model:LiquidAI/LFM2-350M",
"base_model:finetune:LiquidAI/LFM2-350M",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | null |
[
"kurakurai/Luth-LFM2-Demo"
] |
[
"other",
"lfm1.0",
"LICENSE"
] |
[
"kurakurai/luth-sft"
] |
[
"fr",
"en"
] | 354,483,968
| null |
[
"text-generation"
] | null |
[
"AutoModelForCausalLM",
"Lfm2ForCausalLM",
"lfm2"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a7f324ad150b5dcf8cbb74
|
taide/Gemma-3-TAIDE-12b-Chat
|
taide
| null | 1,296
| 1,296
|
auto
| 2025-08-22T04:33:40Z
| 2025-08-22T16:09:37Z
| null | 13
| 13
| null | null |
{"parameters": {"BF16": 12401873520}, "total": 12401873520}
|
[
".gitattributes",
"README.md",
"README_en.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] | null | null |
abae28ce090549c694cd130d8fe64a54a8f13a6e
|
[
"safetensors",
"gemma3",
"license:other",
"region:us"
] | null | null |
[
"goblingeorge/Gemma-3-TAIDE-12b-Chat"
] |
[
"other",
"gemma-version-taide-models-license-agreement",
"https://drive.google.com/file/d/1xMi1P4pjWDjiAQndVTIIinqiTpk2airo/view"
] | null | null | 12,401,873,520
| null | null | null |
[
"Gemma3ForConditionalGeneration",
"gemma3"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
65770c3426ef61bbf101d4da
|
mistralai/Mistral-7B-Instruct-v0.2
|
mistralai
| null | 494,582
| 35,939,486
|
auto
| 2023-12-11T13:18:44Z
| 2025-07-24T16:57:21Z
|
transformers
| 2,936
| 12
| null |
text-generation
|
{"parameters": {"BF16": 7241732096}, "total": 7241732096}
|
[
".gitattributes",
"README.md",
"config.json",
"generation_config.json",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"pytorch_model-00001-of-00003.bin",
"pytorch_model-00002-of-00003.bin",
"pytorch_model-00003-of-00003.bin",
"pytorch_model.bin.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1519,
5540,
596,
111,
4943162336,
4999819336,
4540516344,
25125,
4943184288,
4999843272,
5064824210,
23950,
414,
1795188,
493443,
2103
] | 29,493,697,775
|
63a8b081895390a26e140280378bc85ec8bce07a
|
[
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"finetuned",
"mistral-common",
"conversational",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | null |
[
"mteb/leaderboard",
"barunsaha/slide-deck-ai",
"featherless-ai/try-this-model",
"eduagarcia/open_pt_llm_leaderboard",
"Nymbo/Serverless-TextGen-Hub",
"MGZON/mgzon-app",
"speakleash/open_pl_llm_leaderboard",
"allenai/WildBench",
"SustainabilityLabIITGN/VayuChat",
"MuntasirHossain/RAG-PDF-Chatbot",
"KingNish/OpenGPT-4o",
"JournalistsonHF/ai-scraper",
"flowers-team/StickToYourRoleLeaderboard",
"NCTCMumbai/nctc-pdf-chatbot",
"bhaskartripathi/LLM_Quantization",
"skmdud/SantoshGPT",
"emartinez1015/aipai",
"awacke1/AI-MovieMaker-Comedy",
"ryanrwatkins/needs",
"helenai/openvino_transformers_streaming",
"zhtet/RegBotBeta",
"Skier8402/mistral-super-fast",
"ignitariumcloud/IAB_VIDEO_AD_CLASSIFIER",
"alfonsovelp/mistral-super-fast",
"Tomoniai/Chat",
"wop/Chattybot-OpenGPT-Chat",
"med-llm-tutorial/llm-playground-demo",
"Jamestiago/mistralai-Mistral-7B-Instruct-v0.2",
"miteshkotak7/mistralai-Mistral-7B-Instruct-v0.2",
"williamleex/mistralai-Mistral-7B-Instruct-v0.2",
"einarvollset/mistralai-Mistral-7B-Instruct-v0.2",
"tony9999/mistralai-Mistral-7B-Instruct-v0.2",
"jseidler/mistralai-Mistral-7B-Instruct-v0.2",
"TheBlueberry-AI/Mistral-7b-v0.2",
"zk5/zk5-mistral",
"Hansimov/hf-llm-api",
"LuckRafly/QnA-with-CSV",
"Titeiiko/mixtral-46.7b-chat-api",
"radinhas/hf-llm-api",
"iamdelrio/transformers",
"Aabbhishekk/Chat-Pdf-With-Search-Assistant",
"ka1kuk/LLM-api",
"AFischer1985/AI-RAG-Interface-to-Hub",
"halimbahae/mistral-7b",
"LanyB/Meta_llama-test",
"ROHAN181/chatpdf",
"ADOPLE/Video_QA",
"ashokrawat2023/hf-llm-api-dup",
"ROHAN181/pdf-chatbot",
"TheMaisk/TheMaisk_PDF_Chat",
"akshay326/Mistral-7B-Doc-Chat",
"Gooly/example-pipeline",
"sotosbarl/greeklawgpt2",
"lkw99/mistral-7b",
"nonamed33/minigpt_api",
"VenHello/thirdquery",
"asigalov61/Karaoke-MIDI-Search",
"kevinklam/GuessWho",
"agrimag/RISCRIVI_DESCRIZIONE",
"jfo/Mixtral-Chat",
"iblfe/test",
"thobuiq/Mistral-7b-v0.2",
"SiraH/mistral-DQA",
"gsarti/pecore",
"wop/BibleLearner_AI",
"MarkoVidrih/Chat-With-PDF-document",
"bardsai/performance-llm-board",
"officialhimanshu595/llama-factory",
"ROHAN181/pdf-chatbotfiv",
"logikon/open_cot_leaderboard",
"harshitv804/MedChat",
"AllyArc/AllyArcChatDemo",
"Araeynn/Luminary-Yarn-of-Robotic-Excellence",
"Tuana/hackernews-summaries",
"aryagarvit/mistralsql",
"ruslanmv/hf-llm-api-collection",
"os1187/ChatPDF",
"mkumar87AI/FunnyChatBot",
"ruslanmv/hf-llm-api",
"kunalchamoli/pdf-chatbot-try",
"joaopaulopresa/workshop_llm_ufg_chatbot",
"loveblairsky/LLM-model-cards",
"MasterMohan/PDFChat",
"santuchal/pdf_chat_bot",
"carlotamdeluna/ollama",
"pyakhurel/mistral-7b",
"carlotamdeluna/Chatbot",
"EsoCode/hf-llm-api",
"bohmian/esg_countries_chatbot",
"Testerino/mixtral-46.7b-fastapi",
"z00mP/Simple-RAG-solution",
"MatteoScript/StreamlitChat",
"skrmanglam/VectorBOT",
"manjunathshiva/Grade-3-Brilla-Branics",
"Jaman/openLLMs-RAG",
"sumanthkv/pdfchatbot",
"Arcypojeb/pdf-chatbots",
"Wasima/pdf-chatbot",
"huedaya/llm-fastapi-1",
"BIOCHEM4EVA/Mistral_7B_Chat_Keto",
"MatteoScript/Streamlit_ZucchettiAI",
"AFischer1985/Advanced-RAG-Demo",
"vishwask/rag",
"MixoMax/mistral-7b",
"AFischer1985/AI-Interface_memRAG",
"MAsad789565/llm-api",
"ABBNikit/pdf-chatbot",
"felipemarques8/mistral-super-fast",
"harshitv804/LawGPT",
"sanchitm/pdf-chatbot_Sanchit",
"Ubai/pdf-chatbot-opensource-llm",
"Nymbo/pdf-chatbot",
"Alfasign/pdf-chatbot-opensource-llm",
"Umama-at-Bluchip/Medical-Chat",
"aipatseer/chatllm",
"goku6045/test",
"qfisch/pdf-rag-mistral-7b",
"ys-nat/pdf-chatbot",
"mehdirab/ResumeParser",
"saneowl/mistralai-Mistral-7B-Instruct-v0.2",
"hansleyc/mistralai-Mistral-7B-Instruct-v0.2",
"chansung/paper_qa",
"xyz123456789/mistralai-Mistral-7B-Instruct-v0.2",
"Harsimran19/pdf-rag-mistral-7b",
"Anish13/chat_with_data",
"shawn-suo/mistralai-Mistral-7B-Instruct-v0.2",
"LAWGPT/attorneygpt",
"rajesh1501/Law-GPT",
"JeanBoutboull/Text2Action",
"LLM-auto-model-card/LLM-guessing-game",
"vonshed/SimpleChatbot",
"svjack/genshin-impact-bookqa-haystack",
"rafaaa2105/text-generation",
"thunder-lord/hf-llm-api-2",
"pedroeuropeu/mistralai-Mistral-7B-Instruct-v0.2",
"nxphi47/test-zero-gpu",
"abdullahalzubaer/mistral-inference-test",
"XsoraS/mistralai-Mistral-7B-Instruct-v0.2",
"spkkrishna/LexiGuide",
"awinml/mistral-7b",
"yangbh217/ChatAcadamy",
"ivanmeer/mistralai-Mistral-7B-Instruct-v0.2",
"SharryOG/MIA",
"kyleebrooks/mistralai-Mistral-7B-Instruct-v0.2",
"gordonchan/embedding-m3e-large",
"abhijeetjagtap30/mistralai-Mistral-7B-Instruct-v0.2",
"vaidehikale24/mistralai-Mistral-7B-Instruct-v0.2",
"chansung/vid2persona",
"saptharishi/aibot",
"Munes787/labotv2",
"Munes787/labotv3",
"FallnAI/ComSci-Retrieval-Augmentation",
"rahgadda/chatwithpdf",
"awacke1/Arxiv-RAG-Mistal-Mixtral-MoE-n-Gemma",
"Ekkyboss/Ekene-LLM-APP",
"awellis/pdf-chatbot",
"zahaby/chat-with-mistral",
"aiscientist/mistralchatbot",
"4thed/mistralai-Mistral-7B-Instruct-v0.2",
"awacke1/Arxiv-Paper-Search-And-QA-RAG-Pattern",
"mhurhangee/model_test",
"lubani/basic_rag_with_hf_inference",
"jikoni/pdfchat",
"Felipe02/Quotation_extractor",
"Felipe02/test",
"durjoy2/llm-langchain-q-a-chatbot",
"rajeshja/OCR-Fix-Words",
"dkumar007/BioMedicalApp",
"gsspdev/mistral-7-2-instruct",
"kishoregajjala/Mental-Health-Chatbot",
"Nymbo/hf-llm-api",
"darkknight72/TestingMistralAI",
"vierpiet/mistralai-Mistral-7B-Instruct-v0.2",
"ali121300/mistral-PDF-chat",
"chansung/gradio_together_tgi",
"ali121300/pdf_chat_bot",
"AleenDG/QueryWebsites",
"virendhanwani/lexbot",
"Sambhavnoobcoder/pdf-chatbot",
"namanroxx/pdf-chatbot",
"yunlinger/mistralai-Mistral-7B-Instruct-v0.2",
"gingun18/SimpleChatBot",
"zaephaer23/compareAI",
"SwatGarg/PeacePal",
"wop/HTML-Writer",
"Qazi-Mudassar-Ilyas/PDKnowledgeBaseQAusingRAG",
"tabish543/mistralai-Mistral-7B-Instruct-v0.2",
"Rohan246/Mistral_Bot",
"Qazi-Mudassar-Ilyas/TalkToAnyPDFFile",
"rarebear/mistralai-Mistral-7B-Instruct-v0.2",
"awacke1/Arxiv-Paper-Search-QA-RAG-Streamlit-Gradio-API",
"nirajandhakal/Talk-To-PDF",
"Marroco93/PacmanAI-2",
"umbc-nlp/chat-llm",
"AWeirdDev/mistral-7b-instruct-v0.2",
"TymofiiNas/listlink-test",
"Taf2023/mistral-7b",
"rianders/mpi_data_store",
"Omdena-MentalHealth-team-consolidated/MindfulMedia_Mentor",
"awacke1/Scholarly-Article-Document-Search-With-Memory",
"Kembum9999/mistralai-Mistral-7B-Instruct-v0.2",
"Sagar23p/mistralAI_chatBoat",
"itachi-ai/Chat-Bot",
"Umama-at-Bluchip/mental-health-bot",
"mqamar/mistralai-Mistral-7B-Instruct-v0.2",
"Omdena-Mental-Health-Team-2/PeacePal",
"lookingforabrain/11",
"atlury/pdf-legal-chatbot",
"asymptote/mistralai-Mistral-7B-Instruct-v0.2",
"klavyelibey/pdf-chatbot",
"indat/mistralai-Mistral-7B-Instruct-v0.2",
"Oritsemisan/PeacePal",
"jhurlocker/mistralai-Mistral-7B-Instruct-v0.2",
"tesla1/SimpleChatbot",
"arjunanand13/house_excel_query",
"felipemarques8/mistralai-Mistral-7B-Instruct-v0.2",
"ryan0303/requirements",
"ryan0303/requirement_compliance",
"Easyfly/mistralai-Mistral-7B-Instruct-v0.2",
"codewithdark/text-complation",
"worcestershire/mistralai-Mistral-7B-Instruct-v0.2",
"Jeanius/mistralai-Mistral-7B-Instruct-v0.2",
"evanrsl/chat-with-pdf",
"ssenguptaopteamix/mistralai-Mistral-7B-Instruct-v0.2",
"khting/SimpleQA1",
"loubnabnl/zero-gpu",
"vini02/IPO_Analyser",
"ogegadavis254/MindfulMedia_Mentor",
"JonnyRysler/Mistral_Implementation_Test",
"steef68/Mixtral-8x7B",
"ajeetkumar01/Text-Generations-using-mistralai-Mistral-7B-Instruct-v0.2",
"Qazi-Mudassar-Ilyas/RAGWithMSExcel",
"greenarcade/mistralai-Mistral-7B-Instruct-v0.2",
"Vivedha/Blog-generation",
"droo303/mistralai-Mistral-7B-Instruct-v0.2",
"omdena-mhc-team5/mhc_brighterdays_mentor",
"ogegadavis254/Chatbot",
"surprisedPikachu007/pdf-chat",
"surprisedPikachu007/mistralai-Mistral-7B-Instruct-v0.2",
"Mr-Vicky-01/chat-with-PDF",
"armandogon94/image2story",
"wilmors/mistralai-Mistral-7B-Instruct-v0.2",
"NeuralSphere-Labs/NeuralSphere-7B-Instruct-v0.1",
"ogegadavis254/Bible_AI_chatbot",
"ogegadavis254/React_Coder",
"gofeco/support",
"skyblaze-11/gradio-chatbot",
"Ekkyboss/chat",
"Qazi-Mudassar-Ilyas/PDF2PPTX",
"evvic/llm-intro",
"Ck773/mistral-super-fast",
"tahar-amin/mistralai-Mistral-7B-Instruct-v0.2",
"jharrison27/arxiv-RAG",
"momokoElla/mistralai-Mistral-7B-Instruct-v0.2",
"thesnak/chat-pdf",
"evvic/chat-model-app",
"bilbodai/mistralai-Mistral-7B-Instruct-v0.2",
"awacke1/PDF-Document-QA-Chatbot",
"Hawks101/mistralai-Mistral-7B-Instruct-v0.2",
"rodrigomasini/Arxiv-CS-RAG",
"Qazi-Mudassar-Ilyas/EnterpriseRAG",
"Zeroxdesignart/mistralai-Mistral-7B-Instruct-v0.2",
"threcius/mistralai-Mistral-7B-Instruct-v0.2",
"Thrinadh00-19/Goodachari-511",
"tobiasmj97/pirate-class",
"RJuro/cheese-doc",
"Annikaijak/Pirate_Speak_Chatbot",
"mtzeve/cheese-doc",
"Camillahannesbo/cheese-doc",
"Paypatty/dockerpirate",
"benj3037/pirate-doc",
"notsimao/Pirate_Speak_Chatbot",
"MikkelONielsen/Pirate_Speak_Chatbot",
"ogegadavis254/chatapi",
"ogegadavis254/apiv1",
"RJuro/rag-lex",
"Logarxx/mistralai-Mistral-7B-Instruct-v0.2",
"hyerimpark/mistralai-Mistral-7B-Instruct-v0.2",
"mihirjadhav/mistralai-Mistral-7B-Instruct-v0.2",
"dolo650/mistral-7b",
"yanisbgrib/Mistral-7B-Instruct-v0.2",
"NCTCMumbai/Customs_Manual_Chatbot",
"AshScholar/StegLLMBro",
"bkumar7/mistralai-Mistral-7B-Instruct-v0.2",
"pduf/mistralai-Mistral-7B-Instruct-v0.2",
"acloudfan/HF-Playground",
"acecalisto3/hAPI_face",
"omegaodin/mistralai-Mistral-7B-Instruct-v0.2",
"playgrdstar/compare_retrieval_methods",
"lycuts/mistralai-Mistral-7B-Instruct-v0.2",
"abhivsh/Engg-SS_ChatBOT",
"Harsimran19/MedChat",
"rojiaugustine/test1",
"Udbhav44/VOX_RAG",
"anisotropies/chatty",
"OriDragon2000/simpleRAG",
"Udbhav44/VOX_RAG1.0",
"evvic/marketing-tool",
"Indexerr/mistralai-Mistral-7B-Instruct-v0.2",
"Indexerr/mistralai",
"tomhagen1989/AdvancedChatBot",
"AWeirdDev/mistral-7b-instruct-v0.2-leicht",
"santuchal/only_chat",
"dar-tau/selfie",
"extysecz/mistralai-Mistral-7B-Instruct-v0.2",
"minhcrafters/Mistral-7B-Instruct-v0.2-mental-health-finetuned",
"ConceptaMAGIC/svc-gradiotgi-fm-template",
"WeTambara/mistralai-Mistral-7B-Instruct-v0.2",
"caffeinatedcherrychic/gradio-server",
"alvations/llm_harness_mistral_arc",
"Asma123-code/PeacePal",
"divy131/legalapp",
"divy131/legal",
"divy131/legalchat",
"arjunanand13/knowledge_model",
"Kaivalya7/mistralai-Mistral-7B-Instruct-v0.2",
"JARVIS-DEV/mistralai-Mistral-7B-Instruct-v0.2",
"kk117/mistralai-Mistral-7B-Instruct-v0.2",
"Paul-Joshi/website-summarizers-RAG",
"ManishThota/Mistral-7b-v2",
"contextcite/context-cite",
"hasitpbhatt/mistralai-Mistral-7B-Instruct-v0.2",
"SeaLLMs/SeaLLM-7B-v2.5-simple",
"asderene/mistralai-Mistral-7B-Instruct-v0.2",
"yes2code/pdf-chatbot",
"Niansuh/HFLLMAPI",
"Dayozoe/stockbotadviser",
"olanokhin/mistralai-Mistral-7B-Instruct-v0.2",
"yanisbgrib/text_generation",
"ervijayraghuwanshi/mistral-super-fast",
"HHZera/mistralai-Mistral-7B-Instruct-v0.2",
"GordonChan365/new-llm-mouse",
"awacke1/The_Music_Of_New_Orleans_MoE",
"samim2024/LangChain-HuggingFaceEndpoint-Demo",
"Akshayram1/pdf-chatbot",
"saranya-psg/rag_langchain_mistral_chromadb",
"Ateeqq/Mistral-7B-Instruct-v0.2-Chatbot",
"gbabuts/Briefer",
"JairoCesar/Buho",
"IAMAnsh/RAG-Document-QnA",
"nikhilkomakula/nk-openpages-intellibot",
"vikaskapur/MoviesEmotions",
"Anvoleo/mistralai-Mistral-7B-Instruct-v0.2",
"durgeshshisode1988/module6_mp3",
"abhinandan18/langchain_qna_chatbot",
"samim2024/Somesh-Marketing-App",
"tsi-org/slide-deck-ai",
"durgeshshisode1988/pdf_text_spitter",
"AjithBharadwaj/Blog_Generator",
"asrilmurdian/my-bot",
"sohammistri07/LangChain-QnA-App",
"samim2024/ChatBoot-MISTRAL-AI",
"abdullahalzubaer/chatbots",
"haraldosan/mistralai-Mistral-7B-Instruct-v0.2",
"K00B404/pdf-chatbot-teacher",
"MaxMLang/universal-ai-chatbot",
"DallanQ/sleeping_gods_demo",
"smitathkr1/ai-learning-platform",
"YassoCodes/mistralai-Mistral-7B-Instruct-v0.2",
"gasbaoui/Instagram-post-improvement",
"vivek9/PDF_Question_Answering",
"kayle-maclou/mistralai-Mistral-7B-Instruct-v0.2",
"arjunanand13/video_ad_classifier",
"suriya7/Chatbot-PDF",
"sancreatesAI/LLMsintro",
"arjun-radha-krishnan/Smart-travel-planner",
"yboady/IA-coexya",
"joey888/mistralai-Mistral-7B-Instruct-v0.2",
"fra-lupo/MistralAI_gentext",
"Riya0702/UnconditionalImages",
"richardchai/mistralai-Mistral-7B-Instruct-v0.2",
"mohammedanas1581/hfChatFiles",
"Sergey-wa/berisamocat_gpt",
"jeffyang56/mistralai-Mistral-7B-Instruct-v0.2",
"BluechipTechnologiesAsia/medical-chat",
"pankaj-munde/AgExpert",
"HugThang/EndPointMistral",
"YashB1/VayuBuddy",
"iseehf/hf-llm-api",
"manu-codes/mistralai-Mistral-7B-Instruct-v0.2",
"qdqd/11114477745",
"Ericosmic/mistralai-Mistral-7B-Instruct-v0.2",
"Ericosmic/mistral-chatbot",
"Sergey-wa/pdf-chatbot",
"giulianopicco/mistralai-Mistral-7B-Instruct-v0.2",
"ali121300/mistral-PDF-chat_B1",
"Ya2023/mistralai-Mistral-7B-Instruct-v0.2",
"yxmnjxzx/hf-llm-api",
"alfonsovelp/lynk-mistral",
"ali121300/mistral-PDF-chat_B3",
"alfonsovelp/mistralai-Mistral-7B-Instruct-v0.2",
"CarterGuo/mistralai-Mistral-7B-mytest-model",
"alfonsovelp/mistral-lynk-final",
"samim2024/MP3-Video-Summerization-Email",
"leducanh1203/HealthChat_config_space",
"leducanh1203/create-health-data_config_space",
"huedaya/llm-fastapi-2",
"YashB1/VayuBuddy_DevelopmentApp",
"arjunanand13/llama-2-7b-chatbot",
"lakshmivairamani/pdf_chatbot",
"CarterGuo/mistralai-Mistral-7B-hhahahahahaha",
"CarterGuo/mistralai-Mistral-7B-jjjjjjjjjjjjjj",
"CarterGuo/mistralai-333333333333333",
"CarterGuo/mistralai-Mistral-7B-Instruct-v0.2dfsdddddd",
"CarterGuo/mistralai-Mistral-7B-Instruct-v0.2dfsdddddddddd",
"CarterGuo/mistralai-Mistral-7B-Instruct-v0.2zxzx",
"heidornj/hf-llm-api",
"fffiloni/miniGPT4-Video-Zero",
"harir/Review-Toxicity-Checker",
"AIMaster7/HFLLMAPI2",
"aerospacer/mistralai-Mistral-7B-Instruct-v0.2-Babylon",
"carlotamdeluna/Mixtral-chatbot",
"dvilasuero/reasoning_config_space",
"DevsDoCode/DeepInfra",
"Vision-CAIR/MiniGPT4-video",
"samim2024/Code-Analysis-META-AI",
"samim2024/Sentiment-Analysis-MISTRAL-AI",
"RachanaHS/mistralai-Mistral-7B-Instruct-v0.2",
"talha1503/hemm_space",
"burtenshaw/bicycle_maintenance_config_space",
"Shuddho/HFLLMAPI",
"awacke1/ScienceBrain.AI",
"acloudfan/pdf-summarizer",
"abdulmalek9/chat",
"vijayagrawal/philipsdemo",
"sdxl12/pdf-chatbot",
"KingNish/JARVIS",
"Darka001/law_bot",
"ali121300/mistral-PDF-chat_B5",
"AIMaster7/HFLLMAPI3",
"sotosbarl/Mistral-7b-v0.2",
"sotosbarl/mistralai-Mistral-7B-Instruct-v0.2",
"awellis/rag-chatbot",
"peter2000/audit_config_space",
"peter2000/audit_uganda_config_space",
"leducanh1203/Apr29-LLM_config_space",
"kukukaka02/mistralai-Mistral-7B-Instruct-v0.2",
"aperrot42/ucare",
"leducanh1203/Apr29_config_space",
"leducanh1203/anhHiep_config_space",
"sameemul-haque/ktugpt",
"Surendar00/mistralai-Mistral-7B-Instruct-v0.02",
"vishalgofficial/LLMExperiment",
"dvilasuero/human-rights_config_space",
"cfrancois7/survey-analysis_config_space",
"KTUGPT/KTUGPT",
"davanstrien/data-centril-ml_config_space",
"sguertl/pm-archiguide-api-mistral-7b-instruct-v0.2",
"qbo-odp/mistralai-Mistral-7B-Instruct-v0.2",
"ignitariumcloud/knowledge_model",
"ignitariumcloud/house_excel_query",
"ake178178/StoryAppRunningGPU",
"gospacedev/friday",
"mnbrshd/SimpleQnAApp",
"jsaplication/instagram-post",
"sorg20/llm_rag_cv",
"awacke1/Multimodal-Science-and-Music-Lab",
"Luciferalive/my_rag",
"RachanaHS/BioBuddy",
"vagrillo/Arxiv-CS-RAG",
"Tantalingo/Mixtral-8x7B-Instruct-FastAPI",
"hbui/RegBot4.0",
"burtenshaw/yoga_nistra_config_space",
"skanda12/pdf-chatbot",
"iDrops/pdf-chatbot",
"ThibaultDPS/firstDeploy",
"AdarshJi/Deepifra",
"hbui/RegBot4.1",
"NiansuhAI/Main",
"snaha1911/blip-tales",
"noorulamean444/ChatBot_for_Jupyter_Notebook",
"samim2024/QA-MISTRAL-AI",
"randeom/gpt-prompt-generator",
"danielpappa/Newsbot",
"MrCorocottax/Pdf_to_Chatbot",
"Fuegovic/mistralai-Mistral-7B-Instruct-v0.2",
"NadiaBedhiafi/Oddo_ChatBot",
"Ahtisham1583/Pdf_to_chatbot",
"DoctorSlimm/document-ai",
"shi-labs/CuMo-7b-zero",
"Akshayram1/pdf-edi",
"Rohan12345/edi",
"wb-droid/RetrievalAugmentedGeneration",
"Sankalp25/pdf-chatbot-comp",
"BharathGM123/pdf-chatbot",
"unknowop383987/zephyr",
"JeeLeanChinese/PdfCitiesPolicy",
"AyeshaNoreen/CHATbOT2",
"guillesanwills/first_streamlit_app",
"Arbazkhan-cs/AI-ChatBot",
"IsaacCao/langchain_QA_chatbot",
"anubhav100rao/pdf-chatbot",
"samim2024/STOCK-ANALYZER",
"HarryGGD/WebQA",
"fdaudens/journalism_config_space",
"Frayzer/Mixtral-8x7B-Instruct-FastAPI",
"CIVICS-dataset/CIVICS-responses",
"Astern2112/Emoji_Story_Teller_Translator",
"RockCoder23/AIv2",
"awacke1/GPT-4o-omni-text-audio-image-video",
"Vigneshwaran-D/pdf-chatbot",
"Vigneshwaran-D/pdf-chatbot1",
"ikruchynskyi/helloworld",
"pierodactylus/coderslave",
"AgamP/FAQ-Chatbot",
"akhil2808/Mistral-7B-Instruct-v0.2",
"mklovely/hu",
"Ivan123123123/Mixtral-8x7B-Instruct-FastAPI",
"Yoxas/testrun",
"samim2024/Market-Research-By-URL-Mistral-AI",
"codybum/farming_config_space",
"agentharbor/agentville-academy",
"amraly1983/chat-with-pdf",
"CLeach22/green_farming_config_space",
"pippyP/Mixtral-8x7B-Instruct-FastAPI",
"sethia99/mistralai-Mistral-7B-Instruct-v0.2",
"MasterDee/mistralai-Mistral-7B-Instruct-v0.2",
"RahulShiv/my_QNA",
"seeffdsfsdfsd/mistralai-Mistral-7B-Instruct-v0.2",
"gfdagfdg/pdf-chatbot",
"cot-leaderboard/open-cot-dashboard",
"krishankumar/mistralai-Mistral-7B-Instruct-v0.2-sample",
"Nymbo/gen-synth-data",
"WLL781/mistralai-Mistral-7B-Instruct-v0.2",
"ee333/Mixtral-8x7B-Instruct-FastAPI",
"XUNAIRAH/chatbot03",
"GG13412/mistralai-Mistral-7B-Instruct-v0.2",
"randeom/website_logo_gen",
"taphi/alch",
"Cidewalk/mistralai-Mistral-7B-Instruct-v0.2",
"cszhzleo/mistral-7b-inf2",
"Tortola/Enceladus-new-reworked-AI-system",
"MasterDee/Chat-GPH-7B-Newton-v0.2",
"locmtpm/mistralai-Mistral-7B-Instruct-v0.2",
"AFischer1985/Schreibassistenz",
"navid72m/pdfexplorer",
"basildarwazeh/RAG",
"FarizAldo/mistralai-Mistral-7B-Instruct-v0.2",
"ChrisSMurphy/farming_config_space",
"peterciank/healthy",
"Pro100Sata/xche_ai",
"BrokenSoul/PsicologoEstoico_config_space",
"BrokenSoul/farming_config_space",
"sainathBelagavi/NextSuccess.ai",
"KalishAyish/somali-pdf-chat",
"ai-artist/OI-Resume-Analyzer",
"Vinfinity/Mixtral-8x7B-Instruct-FastAPI",
"Prachidwi/PDFmultiple",
"AngryBull/Demo",
"Korron/music-recommendation",
"deepakbatham572/LLMChatbot",
"ajay1710/mistralai-Mistral-7B-Instruct-v0.2",
"Hemanth2002/chat_ai",
"dbasu/multilingual-chatbot-arena-leaderboard",
"TinhNguyen/RAG-PDF-Chatbot",
"xstone93/ph-ems-llm",
"AnuraginiSinha/aviation",
"anukvma/Question_Answer",
"IamVicky111/MistralScrapy",
"deepakaiplanet/gov-tech-lab",
"arthrod/contracts_clauses_config_space",
"SyedSubahani/QA-Chatbot-with-PDF-Upload",
"NiansuhAI/HFLLMs",
"dwb2023/model_explorer2",
"suhas1971/MistralLLMSuhas",
"Jayanath1987/OpenGPT-4o",
"Dhanushlevi/basic_chatbot",
"MMPano/MMPano",
"sainathBelagavi/TheNextSucess.ai",
"sainathBelagavi/startupCaptain",
"sainathBelagavi/InsiderInvest",
"jarnot/EasyAnimate",
"Ahmed0011/mistralai-Mistral-7B-Instruct-v0.2",
"colornative/ai-scraperr",
"colornative/ai-scraper4",
"prometheus-eval/BiGGen-Bench-Leaderboard",
"Cloudsy/Test2",
"meghagk/cbc",
"KingNish/Voice-Chat-AI",
"mdr123/test2",
"mayankchugh-learning/mistral-streamlit-chatbot",
"anasmarz/startup-ecosystem",
"Nymbo/GPT-4o-omni-text-audio-image-video",
"zicsx/DocAI",
"miroslav-mihaylov/gradio-oauth",
"BSC-LT/t45_crexdata_demo",
"jonathanjordan21/test",
"EPIC135t5/Mixtral-8x7B-Instruct-FastAPI",
"Redori/Mixtral-8x7B-Instruct-FastAPI",
"The46822organization/Mixtral-8x7B-Instruct-FastAPI",
"SyedSubahani/Custome-Chatbot-With-Rank",
"Parth211/rag-model-v1",
"Ciesta/Mixtral-8x7B-Instruct-FastAPI",
"Ciesta/Mixtral-8x7B-Instruct-FastAPI2",
"Laxmanr566/mistralai-Mistral-7B-Instruct-v0.2",
"Firedragon618/Mixtral-8x7B-Instruct-FastAPI",
"VD14/fun_bot",
"ZENLLC/mistral-TurboZ",
"chripto/desc_compare",
"sjsbdfvv/hf-llm-apidde",
"VISHNUDHAT/Simplebot",
"punyakeerthi/AILinkedInOptimizer",
"iamscotch/PDF___CHAT",
"iamscotch/PDF____CHAT",
"iamscotch/mistralai-Mistral-7B-Instruct-v0.2",
"iamscotch/mistrala",
"Logeswaransr/WikipediaChat",
"RJuro/cheese-doc-test",
"dwb2023/model_explorer4",
"connorsisacat/RPAI2024-bot",
"Karani/pdf-chatbot",
"woahtherebuster101/space",
"xyfo/chatbot",
"Lecloow/testai",
"E-GOD-OFFICIAL/Mixtral-8x7B-Instruct-FastAPI",
"DipamGhosh/Simple-Q_A-ChatBot",
"ogegadavis254/101TestSpace",
"chawitzoon/find_youtube_content_timestamp",
"mou3az/MCQA-Quiz",
"ramcielo/Mixtral-8x7B-Instruct-FastAPI2",
"ogegadavis254/AIWebScrapper",
"Justinrune/LLaMA-Factory",
"datacipen/eventia",
"abhirup7/chatpdf",
"yashsarnaik23/llama3_chatbot",
"ssd-2k3/Finance-Docs-Info-Retriever",
"sadidul012/test-space",
"bambamai/summarize-html",
"zerrin/test_space",
"AbdelrahmanOmran/RagWithReferences",
"MichaelS42/LLMTalk",
"MuVeraAI/TestAssistant",
"Nymbo/Scraper-Instructions",
"ryanrwatkins/gsehd_individualized",
"malvika2003/openvino_notebooks",
"ruslanmv/convert_to_gguf",
"shreyasr09/lexi",
"ssd-2k3/Financial_Information_Generator",
"ssd-2k3/Finance-Docs-Info-Retriever2",
"malvika2003/INTEL",
"HuggingFaceSupport/Mixtral-8x7B-Instruct-FastAPI",
"lxq2021/voice_assistant",
"batlahiya/urban1",
"guest123121314/Mixtral-8x7B-Instruct-FastAPI",
"kartik91/Image-To-Story",
"acecalisto3/hAPI_face2",
"Bluesekcoder12/Roblox_who_Is_the_Bot_personal_AI",
"Pyboxs/hf-llm-api",
"pysenii/mistral-super-fast",
"guest12423412/Mixtral-8x7B-Instruct-FastAPI",
"guest14123124/Mixtral-8x7B-Instruct-FastAPI",
"guest8190843/Mixtral-8x7B-Instruct-FastAPI",
"raghu8096/pdf-chatbot",
"HarshitX/Multi_Model_ChatBot",
"seawolf2357/aiscrap",
"RajivReddy4777/mistralai-Mistral-7B-Instruct-v0.2",
"DHEIVER/hf-llm-api-pt",
"Akshayram1/vit",
"IamVicky111/MyCoder",
"ogegadavis254/hf-llm-api-collection",
"allenai/ZebraLogic",
"Nymbo/journalism_config_space",
"aizanlabs/medical_chatbot_on_blood_cancer2",
"OmkarMurthy/pdf-chatbot",
"pysenii/pysenii",
"RajivReddy4777/medbot1",
"kartik91/Image-To-Story_narrate",
"smile11914/chatbot",
"sekhar888/voice_ai",
"lintasmediadanawa/hf-llm-api",
"tianlong12/hf-llm-api",
"noscoper/Mixtral-8x7B-Instruct-FastAPI",
"HarshanaLF/JULIA",
"Visal9252/AI_Content_Generator",
"FallnAI/VoiceChat",
"kenken999/fastapi_django_main_live",
"mmd341/mistralai-Mistral-7B-Instruct-v0.2",
"samim2024/PDF-RAG",
"I-AdityaGoyal/NoteBot",
"guest1231313/Mixtral-8x7B-Instruct-FastAPI",
"awacke1/ChatStreamlitMultiplayer",
"dragonhearted/ai-coding-assistant",
"sankar12345/simpleQA_system_using_Mistral",
"httpdaniel/TalkToDocuments",
"Pavan178/pdf-chatbot",
"sepioo/facebook-translation",
"muradkhan/indemo",
"awacke1/VoiceAIWithDrNovaQuantum",
"Prompting-MoE-MaS-SeR/23.VoiceInOutLLMwJarvis",
"cali72mero/ki",
"fhsp93/Arxiv-CS-RAG",
"Sharal/ragpdf-streamlit",
"Pablinho/bedtime-stories",
"SadiaSaif/OpenGPT-4.o",
"universalsoftware/uchat",
"Pavan178/pdf-chatbot-v1",
"SwatGarg/Content_Creation",
"kanishka36/rag-demo",
"Raumkommander/OpenGPT-4o_new",
"ILLERRAPS/OpenGPT-4o",
"ILLERRAPS/hottie",
"atmiLLM/myapp",
"CCCDev/PDFChat",
"KK-Sequeira/HF-Small-LLMs",
"jsperez/mistral-7b-instruct",
"ignitariumcloud/TI_RAG_Demo_L3.1",
"invincible-jha/voice_demo",
"invincible-jha/JARVIS",
"anythignabovcve/Mixtral-8x7B-Instruct-FastAPI",
"ed0/mistralai-Mistral-7B-Instruct-v0.2",
"devindevine/mygpt",
"mathbatistela/kor-doc-chatbot",
"daniellp/HFLLMs",
"AkshayaKeerthi/mistralai-Mistral-7B-Instruct-v0.2",
"SKV2001/graph_llama31",
"Danielsuri/CV_Chat",
"szjiozi/Smurfs",
"ZENLLC/OPEN-GPT4o",
"PinkAlpaca/Mixtral-8x7B-Instruct-FastAPI",
"saikub/chatB",
"awacke1/DrNovaQuantumVoiceAI",
"mtyrrell/cpv_3.1",
"iosswomen/iosschatbot",
"alsaeth/Arxiv-CS-RAG-LMM",
"SoDa12321/LawGPT",
"Satyam-Singh/mistralai-Mistral-7B-Instruct-v0.2",
"jokku077/Mistral_rag_test",
"thierrydamiba/Chatbot",
"MukeshKapoor25/ISO20022_RAG",
"AndreJacobs514/llm-intro",
"ruslanmv/Hotel-Recommendation-Multimodal",
"Xhaheen/AI_safety_testing",
"himel06/Haor_PDF_Chatbot",
"ishaank123/RAG-PDF-Chatboth",
"AndreJacobs514/chat-clone",
"starsdream666/OpenGPT-4o",
"Jaward/optimus",
"eusholli/ttv-ec",
"kzahra/QnA_FYP",
"batlahiya/DisasterAwarenessBot",
"EBTRFIO/hf-llm-api",
"Marquit/Mixtral-8x6B-Instruct-FastAPI",
"yashxx07/hf-llm-api",
"Prachi03/chatbot",
"mnjkr/LLMsmnjkr1",
"abox/Mixtral-8x7B-Instruct-FastAPI",
"Chirag01/MedChat",
"Chirag01/pdf-rag-mistral-7b",
"iDrops/pdf-chatbot-test",
"pln-udelar/chatbot-educativo",
"mariagrandury/pdf_qa",
"ahmedsamirio/farming_config_space",
"MihirRajeshPanchal/CiteSpy",
"torVik/law",
"Tirath5504/Arxiv-CS-RAG-LMM",
"Xhaheen/phoeniks_redteamers",
"alyanalam/veni_interviewer",
"EBayego/ZephST",
"jacowu/pdf_reader_qanda",
"Adinarayana02/voice_ai",
"aidev08/farming_config_space",
"Namantaneja/Personalised_Email_Bot_LLM",
"barrylevn/hf-llm-api",
"selfDotOsman/Web-sight",
"brofile/gpt-4o",
"Jeff28/CipherReadPDF",
"christinathattil/CHATwithPDF",
"Jawachan/course-rag",
"thisisrishi/Arxiv-CS-RAG",
"Genzo1010/language_translator",
"3SS/mistralai-Mistral-7B-Instruct-v0.2",
"KieferWasTaken/Mixtral-8x7B-Instruct-FastAPI",
"awacke1/AzureCosmosDBUI",
"gendev/aidenforfina",
"vkasyap/BMD",
"IAMTFRMZA/RAG-PDF-Chatbot",
"hujesr/OpenGPT-4o",
"Gokulnath2003/AskPdf",
"bziiit/Carto-RSE",
"ayushanand106/mistral",
"AdamyaG/OpenGPT-4o",
"tanayIITian/chat-with-PDF",
"kanishka36/Test",
"pratham0011/Fast_VoiceChat",
"rickkkz/223",
"ngovu182002/caithienpptx",
"yogesh69/BMD",
"bardicreels/RAG-PDF-Chatbot",
"peterciank/RAG_XP",
"Mudrock10/find_youtube_content_timestamp",
"jayTech456/mistral",
"pjay6120/Resume_Bot",
"martius1/mistral-fastapi-1",
"martius1/mistral-fastapi-2",
"Akshayram1/sarvam_api",
"Akshayram1/api_test",
"naheswar/test",
"Khizerali29/AppGenie",
"Dabococo/OpenGPT-4o",
"naheswar/s",
"Khizerali29/App_Genie",
"JeCabrera/OpenGPT-4o2",
"MukeshKapoor25/ChatAPIServer",
"Greff3/ALL-LLMs",
"mtyrrell/cpv_3.1_eval_pipeline",
"C2MV/BioRAG",
"utk-jain/AskZeno",
"MetzgerVougl/Mixtral-8x7B-Instruct-FastAPI3",
"sagarsahoo220887/ocr_image_processing",
"kumarAnurag/ocr_image_file_processing",
"Vungo182002/test",
"jleitefilho/projeto06",
"augustinbrun/mistralai-Mistral-7B-Instruct-v0.2",
"Ashar086/hackathon",
"MMXCVII/mistralai-Mistral-7B-Instruct-v0.2",
"blacknight3113/pdf-chatbot",
"rohith10062002/7b-job-19",
"kimou605/RAG-POWERED-CHATBOT",
"srinuksv/Main",
"mfahadkhan/research_hive",
"nottabbot/7b-job-0",
"Gainward777/Manuscript",
"farmax/pdf-rag-chatbot",
"K00B404/EasyAnimate_custom",
"GTJ-AI/7b-job-0",
"tob-eht/7b-job-0",
"bottob/7b-job-0",
"bottob/7b-job-1",
"bottob/7b-job-2",
"bottob/7b-job-3",
"bottob/7b-job-4",
"bottob/7b-job-5",
"bottob/7b-job-6",
"bottob/7b-job-7",
"bottob/7b-job-8",
"bottob/7b-job-9",
"bottob/7b-job-10",
"bottob/7b-job-11",
"bottob/7b-job-12",
"bottob/7b-job-13",
"bottob/7b-job-14",
"GIZ/climate_vulnerability_analysis",
"bottob/7b-job-16",
"bottob/7b-job-17",
"bottob/7b-job-18",
"bottob/7b-job-19",
"bottob/7b-job-15",
"sumanth-genai/RAG-PDF-Chat",
"ericrt/7b-job-0",
"ericrt/7b-job-1",
"ericrt/7b-job-2",
"ericrt/7b-job-3",
"ericrt/7b-job-4",
"ericrt/7b-job-5",
"ericrt/7b-job-6",
"ericrt/7b-job-7",
"ericrt/7b-job-8",
"ericrt/7b-job-9",
"ericrt/7b-job-10",
"ericrt/7b-job-11",
"ericrt/7b-job-12",
"ericrt/7b-job-13",
"ericrt/7b-job-14",
"SC999/NV_Nemotron",
"Krrish-shetty/LawGPTD",
"usmanyousaf/AI-SlideMaker",
"devuxious/PowerPoint-AI",
"wgqme/OpenGPT-4o",
"ColamanAI/hf-llm-api",
"Suplanter/FastAPI",
"ericrt/7b-job-15",
"ericrt/7b-job-16",
"ericrt/7b-job-17",
"ericrt/7b-job-18",
"ericrt/7b-job-19",
"datacipen/dashskills",
"WordLift/synthID",
"Wedyan2023/Data_Generation_LabelingCopy",
"br00ke/7b-job-0",
"Shrijoy/falcon_summarizer",
"awacke1/AIKnowledgeTreeBuilder",
"nottabbot/7b-job-1",
"nottabbot/7b-job-2",
"nottabbot/7b-job-3",
"nottabbot/7b-job-4",
"nottabbot/7b-job-5",
"nottabbot/7b-job-6",
"nottabbot/7b-job-7",
"nottabbot/7b-job-8",
"nottabbot/7b-job-9",
"nottabbot/7b-job-10",
"nottabbot/7b-job-11",
"nottabbot/7b-job-12",
"nottabbot/7b-job-13",
"nottabbot/7b-job-14",
"nottabbot/7b-job-15",
"GTJ-AI/7b-job-1",
"GTJ-AI/7b-job-2",
"GTJ-AI/7b-job-3",
"GTJ-AI/7b-job-4",
"GTJ-AI/7b-job-5",
"GTJ-AI/7b-job-6",
"GTJ-AI/7b-job-7",
"GTJ-AI/7b-job-8",
"GTJ-AI/7b-job-9",
"GTJ-AI/7b-job-10",
"GTJ-AI/7b-job-11",
"GTJ-AI/7b-job-12",
"GTJ-AI/7b-job-13",
"GTJ-AI/7b-job-14",
"GTJ-AI/7b-job-15",
"tob-eht/7b-job-1",
"tob-eht/7b-job-2",
"tob-eht/7b-job-3",
"tob-eht/7b-job-4",
"tob-eht/7b-job-5",
"tob-eht/7b-job-6",
"tob-eht/7b-job-7",
"tob-eht/7b-job-8",
"tob-eht/7b-job-9",
"tob-eht/7b-job-10",
"tob-eht/7b-job-11",
"tob-eht/7b-job-12",
"tob-eht/7b-job-13",
"tob-eht/7b-job-14",
"tob-eht/7b-job-15",
"br00ke/7b-job-1",
"br00ke/7b-job-2",
"br00ke/7b-job-3",
"br00ke/7b-job-4",
"br00ke/7b-job-5",
"br00ke/7b-job-6",
"br00ke/7b-job-7",
"br00ke/7b-job-8",
"br00ke/7b-job-9",
"br00ke/7b-job-10",
"br00ke/7b-job-11",
"br00ke/7b-job-12",
"br00ke/7b-job-13",
"br00ke/7b-job-14",
"br00ke/7b-job-15",
"Sarath0x8f/Document-QA-bot",
"Fretful/OpenGPT-4o",
"bibarbibar123123/Help",
"oth-featury/mistralai",
"EditsPaarth/PowerPoint-AI",
"kaleidoskop-hug/StreamlitChat",
"TheJawbreaker/Reza_B",
"TooKeen/TooKeen-neo-blockchain-assistant",
"bhkkhjgkk/mixtral-46.7b-fastapi-v2-stream-2",
"Rsnarsna/pdf-chat",
"7mak7/RobloxAI",
"TejAndrewsACC/EidolonNexusv2.00",
"arsalanjamal002/ai-content-generation",
"ObindiG/sautiyasema",
"krippto/email_generator",
"hitmanblade/PowerPoint-AI",
"arjunanand13/RAG-PDF-Chatbot",
"Veerammal/Pdf_chatbot_for_CBSE",
"awacke1/RescuerOfStolenBikes",
"Masterdqqq/OpenGPT-4o",
"Masterdqqq/Supremo",
"tsvss/bloom-chatbot",
"mukaist/RAG-PDF-Chatbot",
"kaleidoskop-hug/StreamlitChat_Test",
"torVik/lama-law",
"dawood/anychat",
"Veerammal/sync_pdf",
"Finnspiration/OpenGPT-4o-CPU",
"arman1310600/OpenGPT-4o_1",
"RAMYASRI-39/nctc-pdf-chatbot",
"lcrisnm/teste-cloud",
"Muramaki/llm",
"re1ss/teste",
"VitorResende/Vitor",
"GoudaLua/MySpace",
"giglio/MySpace",
"Vilerbas/CompNuvem",
"PradeepBodhi/chatbot",
"ShahbazAlam/pdf-chatbot-pub",
"Sambhavnoobcoder/Cyber-Security-Advisor",
"vuxuanhoan/anychat",
"SC999/RAG-PDF-Chatbot",
"AiActivity/AI-Assistant",
"elon9900/sapan.ai",
"JackHoltone/try-this-model",
"API-Handler/test_api",
"galshammri/Ghalib_Chat_GPT1",
"cchen-aos/AI-chatbot-SoutheastAsia-ClimateChange",
"Nymbo/ai-scraper",
"hunterXdk/RagModels",
"mrbeliever/MultiModlbot",
"yashxx07/hf-llm-api-2",
"logeshnusic/pdf-chatbot",
"hunterXdk/RAG-Chatbot",
"Sambhavnoobcoder/RAG-PDF-Chatbot",
"maha2121/everopen",
"Viky18096/Species_information",
"Gargaz/Heyyy",
"SHAKAZAMBA/TWIZA-demo-master",
"imomenujung/ragcvst",
"neelumsoft/Document-QA-bot",
"ShankarCh19/RAG",
"cedioza/mistralai-Mistral-7B-Instruct-v0.2",
"Viky18096/article_upsc",
"aniudupa/ani",
"ShankarCh19/trainingRag",
"invincible-jha/mentalwellness",
"Viky18096/Env_07_July",
"Whalberg01/OpenGPT-4o",
"vijayaranjanarra/financial_rag",
"arjunanand13/finance_rag",
"Mattral/RAG-PDF-Chatbot",
"MukeshKapoor25/AIReviewSummary",
"invincible-jha/mentalwellnessagenticai",
"Mackintoshj/anychat",
"altunumut13/deployment_space",
"pranav1212/TOY-GPT",
"BeingShashi05/PDF_ChatBot_By_Shash",
"sudip1987/RAG-PDF-Chatbot_copied",
"Abdul-Haseeb-Shahbaz/chatbot",
"Shashikiran42/Banking_Regulations_Compliance_ChatBOT",
"omarakwah/Data_Science_Challange",
"Petropepo/virtualAcademy",
"mariamgvelesiani/anychat",
"yalotaibii/anychat",
"ilovemystagename/anychat",
"suhas1971/image-flip",
"sudip1987/house_excel_query_copied",
"Condense-AI/Fast-PDF-Chat",
"sanbo1200/HFLLMs",
"sanbo1200/Main",
"sanbo1200/Main1",
"snedand/first-playground",
"sanbo110/Main",
"holyhigh666/RAG-chalcogenide-perovskite",
"1MR/ragopenai",
"ritagomes/question_and_answer_app",
"pranav1212/PDF-ChatBOT",
"romprakash/AIMS-DoMS-IITR",
"waloneai/PowerPoint-AI-basic",
"Samarth991/RAG-PDF_With_LLAMA-3B",
"holyhigh666/RAG-with-image",
"artyrkc/Mixtral-8x7B-Instruct-FastAP1",
"Shashikiran42/personal_bot",
"nagasurendra/voicetovoice",
"altunumut13/AML_Project_Deployment",
"isaiane/avence-poc",
"Chavindu/personal-chat-bot",
"Chetan3110/DocuQuery-AI",
"antonsoloviev/ecommerce-support-chatbot",
"SengTak/LEC_HarmfulPromptClassifier",
"Bnanana/mistralai-Mistral-7B-Instruct-v0.2",
"Veerammal/Pdf-GEnie-chat",
"Veerammal/PDf-GENIE-CHATT",
"dusmane/Construction-of-Energy-Efficient-Buildings",
"rishabh5752/RAG_PDF_ChatBot",
"metiny/translate",
"k11112/try-this-model",
"chaithanyashaji/lawforher",
"chaithanyashaji/lawapi",
"mattlicodes/NeuroCog-MD",
"Tamim3/Test",
"jaothan/Bk_Rl_Compliance_chtbot",
"PookienRookie/NeuRon_Archive",
"EduTechTeam/RAG-based_PDF_Chatbot",
"arnaupq/AI",
"DKethan/Sage",
"arnaupq/APIAI",
"arnaupq/Mixtral-8x7B-Instruct-FastAPI",
"Echo9k/DocuSpeak",
"Ken3376576567/Mixtral-8x7B-Instruct-FastAPI",
"Mister12rayyan/RYanychat",
"Dorsio/mistral-super-fast",
"ChelseaLOL/Mixtral-8x7B-Instruct-FastAPIHHH",
"ChelseaLOL/Mixtral-8x7B-Instruct-FastAPI12222",
"ChelseaLOL/Mixtral-8x7B-Instruct-FastAPI",
"sp103107/agent-system",
"ChelseaLOL/Mixtral-8x7B-Instruct-FastAPIKUY",
"Raiff1982/google-bert-bert-base-uncased",
"chaithanyashaji/BNS-Law4her",
"chaithanyashaji/law4her_bns",
"chaithanyashaji21/bnsapi",
"Starchik1/anychat",
"sanbo110/Main1",
"raannakasturi/RAG-Demo",
"Vardhan-kuppala/RAG-Bot",
"Vardhan-kuppala/Microcontroller_selection_assistant",
"BitterDoes/Mixtral-8x7B-Instruct-FastAPI",
"tanmaykansal/Horoscope-AI",
"Starchik/CodeBox",
"aniudupa/fir-gen",
"ramgunjal/Resume_Analyzher",
"indosakura-dev/SBChat",
"reginaappel/hf-hlwhorn",
"DHEIVER/pdf-chatbot",
"DHEIVER/pdfchatbot",
"WildEval/ZebraLogic",
"Anupam251272/Arxiv-CS-RAG",
"Dargouls/pdfchatbot",
"engasm89/slide-deck-ai",
"srijaydeshpande/RAG-Chatbot",
"ksimdeep/myRAG",
"DHEIVER/RAG-PDF-Chatbot",
"DHEIVER/RAG-CHAT",
"krishnamohanseelam/LLMDemo",
"sairamn/Ai-Law-Services",
"Sarveshyadav19/test1",
"dicksinyass/frtyh",
"Marttinsaji26/Mistral-AI-by-Hackerz-Lab",
"berkanyildirim/MyMultiAI",
"blackcrowYT/Mixtral-8x7B-Instruct-FastAPI",
"sproducts/Custom_AI_Chatbot",
"sproducts/YTEST",
"dnzblgn/RAG_PDF_langchain",
"maxenceLIOGIER/SmartRescue",
"Greyzzz1/mistralai-Mistral-7B-Instruct-v0.2",
"musaashaikh/ClmsCompare_Mistral",
"noochila/LawGPT",
"Davi-Co/demo-quote-generator",
"mMonika/Resume_optimizer",
"mteb/leaderboard_legacy",
"Diego34JO/Hprincesa",
"efsdesdf/Mixtral-8x7B-Instruct-FastAPI",
"msun415/Llamole",
"ragibhasan/slide-deck-ai",
"KBaba7/Quant",
"Jafet-ILS/chatbot_repo",
"Logeswaransr/Mistral-Interface",
"Anshefvefvet/mistralai-Mistral-7B-Instruct-v0.2",
"Kekin/Mixtral-8x7B-Instruct-FastAPI",
"totolook/Quant",
"doublemeow/aiAutoRepair",
"debnandan911/Spirit.AI",
"Jeff28/EvSentry8",
"ethiotech4848/experimental",
"valeriacastrorauch/cryptocurrency",
"Metamyverse/First_agent_template",
"AffinityConnect/LiteLLM",
"darsoarafa/g1",
"m1keio/First_agent_template",
"wylum/ETD_Chatbot_LLAMA_",
"Pranavadhar/mistralai-Mistral-7B-Instruct-v0.2",
"rajattech02/mistralai-Mistral-7B-Instruct-v0.2",
"barunsaha/First_agent_template",
"iamironman4279/ai",
"iamironman4279/Chat-Bot",
"rajattech02/chatbot_test",
"tomarni/open_pl_llm_leaderboard",
"NathanPap/Mail_Analyser_2",
"parthib07/Blog-Generation-Applications-Using-Huggingface-models",
"rkunofficial/mistralai-Mistral-7B-Instruct-v0.2",
"laibasif/RelManager",
"htunh/mistralai-Mistral-7B-Instruct-v0.2",
"SomeGuy1155/Mixtral-8x7B-Instruct-FastAPI",
"aun09/RAG-based-query",
"DHEIVER/Voice-Chat-AI",
"batman-c137/DocumentSummarizer",
"batman-c137/DocumentSummarizerGradio",
"yaoyugua/gradio_wave2wave",
"darsoarafa/arafa_products_word",
"darsoarafa/ebook",
"thevinaymittal/IoT_App",
"sq66/leaderboard_legacy",
"sguertl/mistral-7b-instruct-v0.3-api",
"borjaureta/RentIA_AIAgent",
"karim23657/llm-api-hf",
"Jafet-ILS/second_chat_bot",
"meiamgood/Mixtral-8x7B-Instruct-FastAPI",
"hamzasafwan/GradeMate_MVP",
"VenkataGopi112/lawgpt",
"zastixx/dr-himanshudas",
"BuiDao/API",
"jsakshi/BlogAgent",
"1232ertysdxc21/rag_wal",
"jake2004/timetable_app",
"RupakKadhare/birdscribe",
"phucbienvan/AppChat",
"jake2004/ChhayaGPT",
"jake2004/VarunGPT4",
"tladion/fugu",
"tladion/mistral",
"awacke1/AgentsKnowledgeTreeBuilder",
"Username2025aiml/KadesSandbox",
"prachi1507/Multimodal-Visual-AI-Chatbot",
"blazewind/mental_health",
"AutoBench/AutoBench_1.0_Demo",
"scaary/Mixtral-8x6B-Instruct-FastAPI",
"AayushKuloor/VayuBuddy",
"Tapish97/travel-planner-backend",
"bobbub123dude/Mixtral-8x7B-Instruct-FastAP0",
"RupakKadhare/birdscribe-ai",
"motsimaslam/Afri-AI-Tutor",
"myousif15/AfriEdu",
"priyesh17/BirdScribe-AI",
"Guru0304/maveric-demo",
"Guru0304/Pdf-summarizer",
"pal07/RAG2_LLM_MISTRAL",
"kuzeee/chatbotlaguna",
"Linebeck/OlympiaWikiInfos",
"sonummmm/mistralai-Mistral-7B-Instruct-v0.2",
"lamnickdavid/Mistral-7B",
"Guru0304/pdf-upload",
"jerald-joyson/Medicoz-Model",
"knarula2099/otm-writter",
"soranz84/Textboku",
"PLBot/Journi_clean",
"tanzeem7/Financial_Document_Analyzer",
"FaisalExecutorAI/mistralai-Mistral-7B-Instruct-v0.2",
"sailokesh/Hello_GPT",
"Bongo36/First_agent_template",
"Hopsakee/functieomschrijving",
"PLX15/Mixtral-8x7B-Instruct-FastAPI",
"andyhuggingvegas/pdfchat1",
"satyanand001/test01_RAG_PDF_langchain",
"neurostack/medical_chatbot",
"mayanisrar/my-study-bot",
"kuzeee/lagunabotchat",
"Aradhya01/GSC",
"Aradhya01/financial-chatbot",
"yourkushagra/CarrierCounsellor",
"Justax/justax",
"ContactPoint360/bQAsummary2",
"Mrityunjay2025/mrityunjay_kumar_biomedgpt",
"bainskarman/BasicRAG",
"Mohith202/Ema_Chatbot",
"DHEIVER/RAG_PDF_Chatbot",
"DHEIVER/RAG-PDF-AI",
"trizard/pelpe",
"Anarch-y/SmartTutor_AI",
"sadtales/storybook-dev",
"FallnAI/Quantize-HF-Models",
"Ts881188/Serverless-TextGen-Hub",
"Dave9891/Mixtral-8x7B-Instruct-FastAPIIIO",
"Hardik5456/Wan2.1playground",
"K00B404/LLM_Quantization",
"GQ-LI/cmo_game",
"rdaudt/genai-data-model-chatbot",
"ignitariumcloud/TI_RAG_Demo_OpenAI",
"koulsahil/FashionForecaster",
"Rubbers/Silvia-4.1",
"NandanData/MegicAI",
"NandanData/AITOOL",
"Titan0123/mistralai-Mistral-7B-Instruct-v0.2",
"jaot92/sofia-chat-api",
"jerald-joyson/Medicoz_Old_Model",
"conanana/testing123",
"YasserKSA/RAG-PDF-Chatbot",
"asc8er/ApteDoc",
"peterciank/mistralAI_chatBot",
"Njongo/sonet23",
"Garvit1904/LLM_SimpleChatBot",
"askbyte/biter-zephyr",
"GatosNegros/ChatbotLaguna",
"ronaldaug/hf-llm-api",
"abdulshakur/YT-TranscriptChunkAnalyzer",
"nicoserenade/EcoAmigo",
"jsegrets/Categorize_Data_V1",
"thaistamae/first_langgraph_agent",
"nicoserenade/EcoAmigo2",
"SultanmyJAAN/chatbot_uoe",
"Shivayamini/AIGeneratedScientificPapers",
"Jeff28/FarMVi8ioN",
"hapm219/idc-chatbot",
"daminoob/DDMixtral-8x7B-Instruct-FastAPI",
"GatosNegros/ChatbotLagunaV2",
"SultanmyJAAN/UOE_Academic_Chatbot",
"redbeansgroup/jsueducatorsconferenceapp1",
"HarmainHE/custom_chatbot",
"sapbot/OpenGPT-4o",
"privateuserh/AI_Content_Generator",
"56yth/misewl",
"vikramronavrsc/BLOCHAIN_RAG_FOR_LASTDAY_EXAM_PREP",
"notlocalmaxima/VerbalApp",
"DKethan/Duel-Simulation",
"BlazeInc/Chatbot",
"Anirudh3/mistral-instruct-test-v1",
"SaiKumar1627/dual_agent_simulation",
"KAMAL18/dual_agent_simulation",
"Velpurisubbarao19/dual_agent_simulation",
"Tarunpadavala17/DearHRSpeakWithMy2.0",
"abhishekpawar7218/mistral-7b-lora-adapter-demo",
"Pamudu13/RAG-web-Chatbot",
"pchernic/bot6",
"Pamudu13/rag-chat-botapi",
"riccione55/multi-agent-system",
"lahorrillo/lunIA_v1",
"DronA23/Dual_Agent_Simulation",
"sharp74/Chatbot-AI-to-RBLX",
"Vinoveer/Listenandheal",
"lhybosco/hf-llm-api",
"Tuhinm2002/ved_vyas",
"Jeff28/EvSentry28",
"suku9/Empathetic-AI-Chatbot",
"Chater-Marzougui/MiraiBot-Mistral",
"Mira194/amira-p2m-code",
"suku9/Empathetic-AI",
"Architjain808/testCase-generator",
"Guhanselvam/ocr",
"Anchita2004/Sentiment-Aware-Chatbot",
"pchernic2/houerbot",
"chay07/mistralai-Mistral-7B-Instruct-v0.2",
"Lsapk/IA",
"AGayathriiii/DotNetJavaCodeConversion",
"sudha07/MedrepoInt",
"Rashi2722/InsightAgent",
"bsandeep/test",
"LearninwithAK/Code-roaster",
"Krrish-shetty/AILawyer",
"Krrish-shetty/LawGpt-Adv",
"sudha07/MedicalInterpreter",
"Krrish-shetty/AILawgpt",
"LPX55/_suite-scraper",
"xomec/mistralai-Mistral-7B-Instruct-v0.2",
"Rubbers/Silvia_mistralai-Mistral-7B-Instruct-v0.2",
"iisamlendemarit/IisalmiGPT",
"PriyaMishra/RAGpdf_chatbot",
"Jashmhta/multi-ai-app",
"rayyanmoqeem/RAG_FOR_CLINICAL_QUERIES",
"Conso04/Ai_sensei",
"MGGroup/GoogleChatBot",
"Lambeckkk/Larynxlab",
"Holycanolies123/Test-6",
"vijayvizag/code-to-doc-streamlit",
"vijaynani03/intelidocs",
"SmileXing/leaderboard",
"Krrish-shetty/LAWGPT_GENAI",
"IS2Lab/S-Eval",
"aafqwe/blogzenbot",
"sosa123454321/Bussiness-plan-maker-2-divar",
"denisbay/GLaDOS-chat",
"shoeb27/askmydocs-by-shoeb",
"syedMohib44/pentagon-games-model",
"amitharitwal02/label-gen-lora",
"Krrish-shetty/jurisproAI",
"q275343119/leaderboard",
"h4sch/any_coder",
"Dman11777/matt",
"GrahamWall/mortgage_calculator",
"Pro100Sata/chatgpt4",
"Pro100Sata/sata_ai",
"goodsfofo/YaSs",
"bp7274/hello_raheem",
"rmxzz/llama2-chat-saudi-assistant",
"rmxzz/saudi-smart-ai",
"thehoneybadger/JurisBot",
"magdap116/Final_Assignment_Template",
"VeePon/Veerle_AI_Literacy_Buddy",
"cellerson/AgentCourseFinalProject",
"AIbyKaindu/CoreQuest-AI",
"yamatuji/Final_Assignment_Template_try",
"hamdylove/Hamdy.law",
"Patonki/Final_Assignment_Template",
"roshcheeku/ashabot",
"subhangi-dhasmana/q-and-a-research-paper",
"pedrofsgarcia/jurisbot2",
"ZAZA88888/Zazzz",
"prabuselva/Agents_Final_Assignment_Template",
"romain-lembo/Unit4-GAIA",
"Zeros66/AgentCourseFinalProject",
"Chris4K/summarizer-tool",
"dicksinyass/Councilai",
"Mina76/expert",
"MellowSilva/CsClass",
"prasel/Agents_Final_Assignment",
"clubentrepreneurs/pdf-chatbot",
"joresk/demomistraljoresk",
"keeperballon/multi-llm",
"pararthdave/HF-Agents-Course",
"Alimubariz124/Topic_modelling",
"0r0b0r0s/Final_Assignment_Template",
"piropiro2025/Final_Assignment_Template",
"SimpleFrog/WER_Evaluation",
"testItBetter/Final_Assignment_Template",
"Steffen9/AI_Agent",
"botando/tuttibank-chatbot",
"Raahulthakur/Research_Agent",
"vsdev1/Final_Assignment_Solution_2",
"Dharmendra622/mdr-tb-qa-app",
"ZuhaibHuggingFace/DSA_AI_Tutor",
"mycobs/TavernForge",
"garyuzair/SEO-Content-Generator",
"reddwarf03/archethic-sdk-assistant",
"tomlrogers/esa-multimodal-rag",
"VucciRetail/moneybot",
"Dave9891/Mixtral-8x7B-Instruct-FastAPI-AOI",
"santuchal/pdf_chat_Sourajit",
"Faisalkhany/AI-SlideMaker",
"usmanyousaf/pptx",
"Faisalkhany/slide-deck-ai",
"Faisalkhany/PowerPoint-AI-basic2",
"Faisalkhany/PowerPoint-AI-basic",
"Chamin09/BrailleMenuGen",
"Chamin09/BrailleMenuGenV2",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"Antoine101/AgentsCourseAssignment",
"LeroyDyer/template",
"KTEAMXO/IslamicaAI-v2",
"Hyd01/may50",
"cyeninesky3/Final_Assignment_Template",
"AyushM6/leaderboard",
"krishshharma/Code-Explainer",
"Luongsosad/chat_bot",
"amuppasani/Wittgenstein-PLA-Test",
"cgranados/Final_Assignment_AgentsCourse",
"ankushkumar/Mistral-7B-Instruct-v0.3",
"rahimhunzai/candlestick-rag",
"rahimhunzai/candlepattern_rag_gradio",
"coolsajan/mygreatfoodbuddie",
"Anchita2004/bert-gpt-text-classifier",
"Noor25/mistral",
"Samuelblue/Computer-Agent-good-version",
"mgbam/StoryVerseWeaver",
"Saintyves/Giu_1.0",
"punsisikiridana/sl_tutor",
"bhanutejadamera/pdf-info-extractor",
"UcsTurkey/mistral7b",
"mtalha03/Resume_Analyzer_Final",
"jillsundie/cap",
"samim2024/testing",
"nguyetn/nguyetcapstone",
"demetz/capstone",
"Zubairshaikh/CHAT-BOX",
"SandeepReddyK/EduMeAI",
"Usman06/mistral-chatbot",
"jafhaponiuk/final_agent",
"phuonggl/eduai-poc",
"pran07/LLM-evaluator",
"AamerAkhter/BuildSmartEstimator",
"xmuruaga/Final_Assignment_Template",
"nehanansari/NehanGPT-training",
"reemashh/digital-services-rag",
"Ecoursebf/E-Market-Assistant",
"Ronaldodev/fastapi_django_main_live",
"lakshmidhar346/my-llama-rag-chatbot",
"CyberTud/legalchat",
"Yannyra66/yra-chatbot",
"lol040604lol/k",
"qazi-musa/med",
"Adelgh65/MF",
"M2LabOrg/First_agent_template",
"aleixlopezpascual/final_assignment_v4",
"emreheh/starter-xai-chat",
"GazalRan/Ghazlia",
"ninfante/iam-bot",
"BSSpedtour/Spedtouri",
"rumet/rmtasn",
"Yasinfalkean/lazy-lecture-agent",
"mahmood726/Studentsim2",
"zamal/Multimodal-Chat-Playground",
"sanjay72003/sanjay_phi2_model",
"hmmodqa/telegram-gpt-bot",
"saivivek6/customer-support-hub",
"Reavorizer/Kaz-AI-Guardian",
"Hirudika/mistral-health-insurance",
"funzhu1/simpson-core",
"Dimigro/Final_Assignment_Agent_Dimigro",
"justroot/trendtrap",
"maarc97z/SocialContentGenius",
"saivivek6/distributed-mistral-orchestra",
"LucasFern/test3",
"stellababy2004/stellababy2004cyber_chatbot",
"alexacido/csv-analyzer-mistral",
"alexacido/csv-analyzer-mistral2",
"ashamsundar/chatbot",
"broadfield-dev/chat2code",
"suprimedev/llama31",
"Iasso/rag-chatbot",
"A0olpi/lead-qualification-ai",
"glotius/my-chatbot",
"rajktk/fileprocess",
"flaviarus22/nutrition-ai-assistant",
"bullemir/First_agent_template",
"sehaj13/SK_RAG_Chatbot",
"Harika11/Resume_Checker",
"AyusmanSamasi/Aimi",
"alexacido/analisador-mistral-1",
"eugenepiggy/RAG-PDF-Chatbot",
"Cybertron08/Synthetic_screams_",
"rgkannan676/Final_Assignment_Template",
"C2MV/Agent-Biotech-2025",
"Bhaskar2611/BankStatement_Parser",
"LorenzoScaioli/Agent_3_base",
"pradyML/academic-research-assistant",
"alyxsis/txt",
"geraldalivia/Blood-Connect-Assist",
"HuggingFace169/EzyLegal",
"weiyi01191/DeepOperateAI-Video",
"dakshbajaj26/Startup-Copilot",
"ayush70/First_agent_template",
"AiTrekker/SalesEnablementAssistant",
"Agents-MCP-Hackathon/Huggingface-Space-Commander",
"feliksius/ai-translation",
"jayashree/TatTwamAI",
"C2MV/Agent-Biotech-2025-2",
"Agents-MCP-Hackathon/Agent-Biotech-2025",
"C2MV/Project-HF-2025-3",
"itsskofficial/AgentsCourseFinalAssignment",
"R01z3L/chattrix-ai-bot",
"fjagad/jira-root-cause-ai",
"be65/vqa",
"barmijli/barmijli_AI",
"mjmuskan03/legal-advisor-chatbot",
"C2MV/Project-HF-2025-31",
"ivangabriele/trl-sandbox",
"ama2aifusion/agents-course-final-project",
"ozgecanaktas/mistral-test",
"innovatems/jsu-applet-v1",
"villagraciaa/semantic-repo",
"elenasartoni/nuovo_tentativo",
"jnybrahma/Streamlit-App-Demo",
"Nashyboi/sermon",
"KhaledSalehKL1/First_agent_template",
"HarithaReddyDondeti/interviewinsight-backend",
"Marcosrrez/Knowledge-architect",
"Yogaprriya/medibuddy",
"puyokura/trpg-gamemaster",
"Uuopn/Telegram_Blender",
"vivekreddy1105/URL_Chatbot",
"tanmaykansal702/Resume_Generator",
"jbaselga/agentes-unit4",
"tanujrai/llm-interview-question-gen",
"Lakshmanan04/Final_Assignment_GAIA",
"enzone/friday-assistente",
"CRX7/C4HCyberAI-1o",
"Unizomby/prompt_comparison",
"sarathi1010/ALFO-Chatbot",
"Sanyam357/mistralai-Mistral-7B-Instruct-v0.2",
"mdrifatbd5/mistralai-Mistral-7B-Instruct-v0.2",
"xu77/mistral-api-demo",
"thawait/Final_Assignment_Template",
"apekshaemailassistant/emailgenerationapi",
"alperall/chatbotv1",
"HarithaReddyDondeti/interviewinsight-web",
"skylerYan/AlfredAgent",
"gvdptdr/textsql",
"shawno/Bawno",
"blankblanklamb/Final_Assignment_Template_v2",
"BenkHel/CumoThesis",
"Ronley/ab",
"AIRoy/imp-safety-patching",
"damnitscashed/Qwen3",
"Aravindram/First_agent_template",
"artempris/gaia_agentic_assistant",
"Synnove/Final_Assignment_Template",
"shaghayeghhp/Final_Assignment_Template",
"bunnyluzy/smart_resume_coach",
"blackwolf-ai/ownmind",
"FeloGomz/elena-chatbot",
"HAL1993/MDFtranslation1234567890abcdef1234567890abcdef1234567890abcdef1234567890abcdef12",
"eessopower/rag-bot",
"omarViga/gaia-agent",
"FernandoDeSantosFranco/Final_Assignment_Template",
"datarchive/mcp-client",
"ToanLee0934/demo",
"ahlamm/rag-api",
"ahlamm/Rag-api-1",
"8kLovesShit/afmapi_chatbot",
"Chang-Gore2025/claim_agent",
"ahlamm/rag-test-api",
"DevMan974/Prompts_IA_Simple_Draw_SDXL_LoRA",
"CoporateNewbieGenz/perfect-employee-ai",
"Projectsummer2025/Ourproject2025",
"Sanjay177/genomai",
"Granther/try-this-model",
"Sam3782/proactive-insurance",
"Hemchander/Cognito-ai-app",
"MichaelTILAS/TULIPS",
"ahmeteren00/First_agent_templatee",
"Shankar-Winchester/First_agent",
"Dewasheesh/HelpDevelopersNew",
"sachbhat/DrukRes",
"Dewasheesh/HelpDev",
"ragna-28/language-bot",
"sajidrazak/Final_Assignment_Sajid",
"ridzalzainal/Mistral-7B-Instruct-v0.2-Chatbot",
"e10ai/Final_Assignment_Template",
"janAGIorg/janAGIbe",
"ohoud4x/OhoudAlghassab",
"DaninoJake/myitineraryapp",
"jarrar67/ask-cosmology",
"dannybhatt/AI_fast_api",
"viccollado/Final_Assignment",
"spaghettis11/Tutor_Matematiques_Basiques",
"joelvep/omegagent",
"msmaje/ragmodel",
"lanakakashka/layan-finance-chat",
"Genchief/Negotiate",
"sree0987/serious-research-assistant",
"Genchief/streamlitnegotiate",
"Imadsinger/quran-ai-assistant",
"ArthyP/technical-rag-assistant",
"MYLZ/clinstudy-chatbot",
"Lui3ui3ui/BookRecommender",
"mineshup/high-potential-stocks",
"mineshup/high-potential-stocksV2",
"ParthGuptaa/consultant-ai-gradio",
"Vaishnavi1206/Wikiyatra",
"siliconengineer/fruitbot",
"danielhooded/Mixtral-8x7B-Instruct-FastAPI",
"nandunelapatla/CodeMentorAI",
"WahajSa/NLP-Assistant",
"aberkulov/Final_Assignment_Template",
"saisingh/kuro",
"saisingh/lovegpt",
"saisingh/love-gpt",
"berfinaktas/misunderstanding",
"iamnew123/TAXRAG_PHI",
"vemuripraveena/praveena-rag-chatbot1",
"betancourtosmar/django-llm-api",
"violetdetre/faithfueledultracoach",
"joeffj/elyon-cloud",
"bjnrds/First_agent_template",
"PLAZMAstudios/LetherAI",
"letaken-olam/BOT-0",
"sidd6sci/NodeNest.chat.mistral7b",
"fernandogoh/ChatGPT4.1_PT-BR",
"mariangelrojasrojas7/App-Becas",
"likhitha-gunneri/ShopGenie-AI",
"likhitha-gunneri/Wallmart",
"Shailajagorile/foodie_assistant",
"Yuktha26/genai-data-analyst",
"thetalljosh/vblchat",
"bfrogs/RAG26Demo",
"SachinBairagi/EmmyChat",
"alikhan-1122/testing",
"Braazzz/ZenithAI",
"SuperCreations/ChatBotApiv2",
"sick-nik/RAGBotMetavolt",
"AkhileshSappal1/auralis.ai",
"K00B404/convert_to_gguf",
"fabiodr/context-cite",
"sejalkishan/doc-sum",
"louis-it/mistralai-Mistral-7B-Instruct-v0.2",
"Shalini23/legal-rag",
"dracer/AI-DOCTOR",
"BrenHu4/gaia-agent-BrenHu4",
"omarViga/Unit_3_Agentic_RAG",
"shiwan7788/leaderboard",
"AkhileshSappal1/Auralis-Backend",
"Sincon0121/literary-recommender",
"loosedamoose/Final_Assignment_Template",
"maddiaks/RAG26Demo",
"sejalkishan/Resume-parser",
"NutriAssist/finalproject",
"SafeEats/KWK_lesson_11_edited",
"sawsharda/recipe",
"sawsharda/rrecipe",
"mgbam/builder",
"jillsundie/Dominique_solution",
"sejalkishan/doc-sum-2",
"Kumravib/ravi_ai",
"Antta/caee-v3-tester",
"MRTB17/Chatmrt",
"NutriAssist/finalprojectcopytotestcheckboxes",
"jillsundie/Dominique",
"gauravkar5526/Legal_Case_Summary_Generator",
"gauravkar5526/PROJECT",
"Novaura1/Novaura",
"Vaibhavg7/the_brooo",
"omm7/test_law",
"glamenza/Tutor",
"omm7/rag_llm_test",
"ssundus/kwkk2",
"catblue2204/projectai",
"NdiagaSarr/DebateLLM",
"Chengyanci/11",
"nishu0001/gaia-agent",
"botcampusai/interview-coach",
"yanciyuyu/1",
"rcrahulkumar/design-agent-backend",
"hetoo24/hetoo2424",
"vighneshnamaig/resume-screener",
"patelishaan/First_agent_template",
"Dafidi/DaniFD",
"debabrataroy/text-summarizer",
"funtech64/logicrocket-demo",
"jjyy2222/First_agent_template",
"Maramdahmen/audio-to-json",
"krishankula/whatsappb_bot",
"Barrysu3po/my-llm",
"displaynamereal/Mixtral-8x7B-Instruct-FastAPI",
"MakeshKarthik/KYC-agent-Face-detection",
"opinternational/IQUlater",
"ankit282kk/Chat-Bot-GenAI",
"aaysush/finance-project-bot",
"rcrahulkumar/Co-Designer",
"onyx-800/MaryTheSecond",
"timesupcoming0001/RAG-PDF-Chatbot",
"acaicedo/Ignacio-Javier-Chatbot-FING-demo",
"teameight/fairytale_generator",
"GigaAIOffical/GigaAIOffical",
"kcbkS/mistralai-Mistral-7B-Instruct-v0.2",
"traleela/RevisionHelp",
"buffsinTheD/AllinOneFree",
"buffsinTheD/NEW2026inONE",
"AGI144348Outlook/Exosuit-Lifeboat",
"SelvaKrish/RAG",
"Mhammad2023/First_agent_template",
"AGI144348Outlook/Exosuit-Lifeboat-2.0",
"Ashwinks005/smart-cultural-storyteller",
"acaicedo/Ignacio-Javier-Chatbot-FING-demo-v2",
"SriramVempaty/Sriram_AI_Defect_Agent",
"Japo96/question-paper-generator",
"KrishnaVeniVankineni/Vankinenis",
"CelagenexResearch/AMA",
"stellababy2004/my-chatbot",
"dawoodAhmad12/ai-expense-backend",
"mn500mn/symptodent-api",
"Muppeteer/tachi",
"gayu17sk/chatbot",
"Bewitcher/my-flashcard-api",
"Zenagers/Zenagers_Final_Project",
"AiCoderv2/FineTune",
"kcbkS/mistralai-Mistral-7B-Instruct-v0.2-vol2",
"sticking/7",
"hami-hek/Neuroscience-Research-Assistant",
"shreyas2k1/gaia-agent-2025",
"zhufengyun/zai-org-GLM-4-9B-0414",
"abdulqadeerchannar/PakAiProPlus",
"n8n-1/8",
"abdulqadeerchannar/PakAiProPlusGpt",
"reader-1/1",
"Juraboy/Finall_Assignment_Agent",
"ShattertedOmen/instagram-growth-optimizer",
"jwwylie1/pitwall-ai",
"truelife2025/edp",
"Aghoriakhilesh/Fastapideployment",
"azilll/Jari",
"knicole/JARVIS",
"Leon4gr45/hosted_llm",
"Leon4gr45/mistral",
"cltajith/AgenticOps",
"matchonerror/7B",
"3LL3/3ll3_GAIA_AGENT",
"navin55/seo-audit-ai",
"Kian16/mistral-7b-reviewer",
"Ivirina/ISLAND",
"sagaratalari/test_space",
"balasaimaruboyina/tamil_to_eng",
"Praveen8220/bnpp1",
"arjun-ms/mistral-lora-ipc",
"erickramos/gpt2",
"Tsukuri/KinoGrenaa",
"harshit-bot/news-regeneration-bot",
"vishaljoshi24/trl-4-dnd",
"Aman-Kalladi/mistralai-Mistral-7B-Instruct-v0.2",
"piyush-p256/bajaj",
"CrimsonElephant/Baba-Milind-LLM_w_RAG",
"hussainap/malaria-ai-dashboard",
"Rong6693/Soulcompass",
"tarasingh6969/new-space",
"Sanjana04123/hr-chatbot",
"Humphreykowl/mistralai-Mistral-7B-Instruct-v0.2",
"Swayam-learnin/Hackathon",
"neevus/Minstral_ai",
"gouthamsai78/Ai-prompt-enhancer",
"dxmouh/talk-to-dx-mouh-ai",
"yash-ish/Hackathon",
"seksa/Myweb",
"nmdummy/mistralai-Mistral-7B-Instruct-v0.2",
"menikev/KnowYourRIght-Bot",
"JevCS/LLM-api",
"Elcano/Chatbot_Sol",
"trader-ai-dev/trading_pannel",
"cheranengg/dhf-backend-fastapi-space",
"brahmairesearch/nllb-translation",
"soupstick/fraud-detector-app",
"NipunaSam/AI-CareerCraft",
"nithish1212/mistralai-Mistral-7B-Instruct-v0.2",
"Theeone/Chat-bot",
"leeroy-jankins/Retrieval-Augmentation",
"IvanPSG/ProgrammythAI",
"manyamlhtr/boxboxbot2",
"acc-ltd/automated-regulatory",
"Deva1211/chatbot",
"SterlingRuby/Splat",
"Adeeldev/AI-Code-Teaching-Mode",
"surahj/chat-bot",
"xoxpo/Resume_QnA",
"JAPG/FocoSaludPlus",
"kushalestari/jcd",
"harir/Review-Toxicity-Checker-2",
"Anish1718/finance-test2",
"IvanXGF/digitalvance-ai",
"Ahmed622841G/Mychat",
"Saif1234567/SaifAI",
"vanga732/AI_PDF_QA_Chatbot",
"vanga732/qachatbot",
"Stg2004/Personal_RAG_System",
"aminulhussain27/ai-voice-interviwer",
"arthurhanderson/extrator-exames",
"ShanenThomas/PDF_RAG",
"BrainBirdAI/BrainbirdAI",
"SNebti/hello",
"fsdfsdfsd2323/GojoBot",
"SNebti/chat_AR",
"Lucita110414/PDF-CHATBOT",
"JeremyCao22/AIChatbot",
"Vlad218/Vlad",
"DORINDESTRES/DOROSai",
"MuneebAhmad07/SuperAI",
"Stanleymikky1/chatbot-demo",
"satishchawan/ARtehub",
"GMR01231/AI_Barber_Chat_Bot",
"hameed516/olexra",
"ThiruHuggingface/domain-tc-generator",
"Coder19/interview_system",
"AbhayVG/VayuChat2",
"SustainabilityLabIITGN/VayuChatv2",
"shumettsion/Naive-RAG-Chatbot",
"mahesh2025AI/Project_2",
"convodev/FAQ3",
"alvasvoboda/SocraticDialogueGame",
"mahesh1209/youtube-video-summary",
"ryckmoraes/projetoaugusto",
"nbsanjaykumar/FUNDAI-CHATBOT",
"Manav0603/project1",
"Heng1018/PAL_support_demo",
"ANESBLEM/LeGlossaire",
"csrivallabro/fake-news-detector",
"Manav0603/project2",
"anasaliking/my-chatbot",
"Kyoronginus/Chatto-Botto",
"Kyoronginus/ureeka_chatto_botto",
"mana2202/snackhack-backend",
"manojsharrma/CAI_Finance_ChatBot",
"madhu0810/pdf_reader",
"aquibjaved7/biomistral-medical-chatbot",
"kundan621/assignment",
"Salifa/Book_buddy",
"nischalgautam/calculate-burnt-calories",
"shafiquebhutto/lab-report-explainer",
"NIKSHAN/test",
"Rapnss/Server-1",
"Intenzo/internal-docs-qa-agent",
"nelsonmejiadiaz/chatbotdeatencion",
"LeadershipTMA25/leadership-assessment-scenario-chatbot",
"chikki2004/simplellm",
"ananyaupadhyayy/my-chatbot",
"nicolasmery/Foundry",
"nkjoy/Ai",
"helping51Ankit/resume-helper",
"cdmr007/Easy_Company",
"Rahmatjonov/OpenAI",
"johan73/interview-ai-agent",
"sentinel-faisal/rag-chatbot",
"Nullpointer-KK/Demo_OS_BaseLLM",
"Rooms/14_HF_Agent_project",
"Bebra81/Pixel",
"gurkanarguz/etsyaramamotoru",
"KATY1922/ImageCreate2",
"hernicksen/streamlit_ollama_final",
"hernicksen/streamlit_test_final",
"SpldMilk/chatbot-steamlit-gemini",
"visionaryTEST/LearningNPC",
"acc-ltd/Automated_Regulatory_V2",
"Vytora04/local-chatbot"
] |
[
"apache-2.0"
] | null | null | 7,241,732,096
| null |
[
"text-generation"
] | null |
[
"MistralForCausalLM",
"mistral",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"France"
] |
Accept to share username & email
|
mistral-community/Mistral-7B-v0.2
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"EN"
] |
[
"Instruction finetuning"
] |
Disclosed: unavailable
| 8
|
67583e455554fc359dadf298
|
DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B-GGUF
|
DavidAU
|
{
"models": [
{
"_id": "675acec5653534e02a9e4529",
"id": "DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B"
}
],
"relation": "quantized"
}
| 83,815
| 784,299
|
False
| 2024-12-10T13:12:37Z
| 2025-07-28T00:18:34Z
| null | 331
| 12
| null |
text-generation
| null |
[
".gitattributes",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-IQ4_XS.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q2_k.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q3_k_l.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q3_k_m.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q3_k_s.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q4_0_4_4.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q4_0_4_8.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q4_0_8_8.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q4_k_m.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q4_k_s.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q5_k_s.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q6_k.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-Q8_0.gguf",
"L3.2-8X3B-MOE-Dark-Champion-Inst-18.4B-uncen-ablit_D_AU-q5_k_m.gguf",
"README.md",
"dark-champ.jpg"
] |
[
2975,
10131598368,
7040908320,
9638007840,
9026655264,
8252806176,
10553248800,
10553248800,
10553248800,
11312942112,
10661776416,
12782488608,
15151055904,
19565630496,
13156830240,
58801,
262246
] | 158,380,770,166
|
72ea56da897d05f4771d43b46964b359f22bfaf0
|
[
"gguf",
"mixture of experts",
"moe",
"8x3B",
"Llama 3.2 MOE",
"128k context",
"creative",
"creative writing",
"fiction writing",
"plot generation",
"sub-plot generation",
"story generation",
"scene continue",
"storytelling",
"fiction story",
"science fiction",
"romance",
"all genres",
"story",
"writing",
"vivid prosing",
"vivid writing",
"fiction",
"roleplaying",
"bfloat16",
"swearing",
"rp",
"horror",
"mergekit",
"llama",
"llama-3",
"llama-3.2",
"text-generation",
"en",
"base_model:DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B",
"base_model:quantized:DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 18404944960, "architecture": "llama", "context_length": 131072, "chat_template": "{{- bos_token }}\n{%- if custom_tools is defined %}\n {%- set tools = custom_tools %}\n{%- endif %}\n{%- if not tools_in_user_message is defined %}\n {%- set tools_in_user_message = true %}\n{%- endif %}\n{%- if not date_string is defined %}\n {%- if strftime_now is defined %}\n {%- set date_string = strftime_now(\"%d %b %Y\") %}\n {%- else %}\n {%- set date_string = \"26 Jul 2024\" %}\n {%- endif %}\n{%- endif %}\n{%- if not tools is defined %}\n {%- set tools = none %}\n{%- endif %}\n\n{#- This block extracts the system message, so we can slot it into the right place. #}\n{%- if messages[0]['role'] == 'system' %}\n {%- set system_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n{%- else %}\n {%- set system_message = \"\" %}\n{%- endif %}\n\n{#- System message #}\n{{- \"<|start_header_id|>system<|end_header_id|>\\n\\n\" }}\n{%- if tools is not none %}\n {{- \"Environment: ipython\\n\" }}\n{%- endif %}\n{{- \"Cutting Knowledge Date: December 2023\\n\" }}\n{{- \"Today Date: \" + date_string + \"\\n\\n\" }}\n{%- if tools is not none and not tools_in_user_message %}\n {{- \"You have access to the following functions. To call a function, please respond with JSON for a function call.\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n{%- endif %}\n{{- system_message }}\n{{- \"<|eot_id|>\" }}\n\n{#- Custom tools are passed in a user message with some extra guidance #}\n{%- if tools_in_user_message and not tools is none %}\n {#- Extract the first user message so we can plug it in here #}\n {%- if messages | length != 0 %}\n {%- set first_user_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n {%- else %}\n {{- raise_exception(\"Cannot put tools in the first user message when there's no first user message!\") }}\n{%- endif %}\n {{- '<|start_header_id|>user<|end_header_id|>\\n\\n' -}}\n {{- \"Given the following functions, please respond with a JSON for a function call \" }}\n {{- \"with its proper arguments that best answers the given prompt.\\n\\n\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n {{- first_user_message + \"<|eot_id|>\"}}\n{%- endif %}\n\n{%- for message in messages %}\n {%- if not (message.role == 'ipython' or message.role == 'tool' or 'tool_calls' in message) %}\n {{- '<|start_header_id|>' + message['role'] + '<|end_header_id|>\\n\\n'+ message['content'] | trim + '<|eot_id|>' }}\n {%- elif 'tool_calls' in message %}\n {%- if not message.tool_calls|length == 1 %}\n {{- raise_exception(\"This model only supports single tool-calls at once!\") }}\n {%- endif %}\n {%- set tool_call = message.tool_calls[0].function %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' -}}\n {{- '{\"name\": \"' + tool_call.name + '\", ' }}\n {{- '\"parameters\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- \"}\" }}\n {{- \"<|eot_id|>\" }}\n {%- elif message.role == \"tool\" or message.role == \"ipython\" %}\n {{- \"<|start_header_id|>ipython<|end_header_id|>\\n\\n\" }}\n {%- if message.content is mapping or message.content is iterable %}\n {{- message.content | tojson }}\n {%- else %}\n {{- message.content }}\n {%- endif %}\n {{- \"<|eot_id|>\" }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}\n{%- endif %}\n", "bos_token": "<|begin_of_text|>", "eos_token": "<|eot_id|>"}
| null | null |
[
"apache-2.0"
] | null |
[
"en"
] | null | 18,404,944,960
|
[
"text-generation"
] | null |
[
"llama"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null |
DavidAU/Llama-3.2-8X3B-MOE-Dark-Champion-Instruct-uncensored-abliterated-18.4B
|
[
"Text"
] |
[
"Text Generation"
] |
[
"Mixture-of-Experts"
] |
[
"en"
] |
[
"Quantization"
] | null | 0
|
683fa4984cbccbb7fff016f5
|
vrgamedevgirl84/Wan14BT2VFusioniX
|
vrgamedevgirl84
|
{
"models": [
{
"_id": "67bd70aaac4a596a43c6706c",
"id": "Wan-AI/Wan2.1-T2V-14B"
}
],
"relation": "finetune"
}
| 0
| 0
|
False
| 2025-06-04T01:42:48Z
| 2025-06-21T22:02:25Z
| null | 550
| 12
| null |
text-to-video
| null |
[
".gitattributes",
"FusionX_LoRa/Phantom_Wan_14B_FusionX_LoRA.safetensors",
"FusionX_LoRa/Wan2.1_I2V_14B_FusionX_LoRA.safetensors",
"FusionX_LoRa/Wan2.1_T2V_14B_FusionX_LoRA.safetensors",
"FusionX_LoRa/placeholder.txt",
"LICENSE",
"OtherLoRa's/DetailEnhancerV1.safetensors",
"OtherLoRa's/Placeholder.txt",
"OtherLoRa's/Wan14B_RealismBoost.safetensors",
"README.md",
"Wan14BT2VFusioniX_Phantom_fp16.safetensors",
"Wan14BT2VFusioniX_fp16_.safetensors",
"Wan14Bi2vFusioniX.safetensors",
"Wan14Bi2vFusioniX_fp16.safetensors",
"WanT2V_MasterModel.safetensors",
"images/ComfyUI_00001_.webp",
"placeholder",
"videos/AnimateDiff_00001.mp4",
"videos/FusionX_00005.mp4",
"videos/FusionX_00012.mp4",
"videos/FusionX_00020.gif",
"videos/FusionX_00021.gif",
"videos/FusionX_00022.gif",
"videos/FusionX_00023.gif",
"videos/FusionX_00024.gif",
"videos/FusionX_00025.gif",
"videos/FusionX_00026.gif",
"videos/FusionX_00027.gif",
"videos/FusionX_00028.gif",
"videos/FusionX_00029.gif",
"videos/FusionX_00030.gif",
"videos/FusionX_00031.gif",
"videos/Video_00063.mp4",
"videos/Video_00066.mp4",
"videos/Video_00067.mp4",
"videos/Video_00068.mp4",
"videos/Video_00069.mp4",
"videos/Video_00072.mp4",
"videos/WanVideoWrapper_VACE_startendframe_00002.mp4",
"videos/WanVideoWrapper_VACE_startendframe_00022-audio.mp4",
"videos/WanVideoWrapper_VACE_startendframe_00030-audio.mp4"
] |
[
3124,
316822496,
371128616,
316822496,
0,
0,
306847400,
0,
306848616,
11698,
28577796288,
28577792224,
16397285160,
32791417192,
14289641560,
1676222,
0,
5100634,
1088660,
2118658,
30923344,
23456780,
28942374,
26832716,
17490930,
22980358,
25228311,
33703126,
32266579,
36226245,
24155317,
19735627,
2110834,
1448775,
1487338,
2309856,
1484759,
2822831,
2921379,
2084171,
2156290
] | 122,603,168,984
|
32ae8dc9a8352038442d80831988cc3bfae5bc20
|
[
"text-to-video",
"diffusion",
"merged-model",
"video-generation",
"wan2.1",
"base_model:Wan-AI/Wan2.1-T2V-14B",
"base_model:finetune:Wan-AI/Wan2.1-T2V-14B",
"license:apache-2.0",
"region:us"
] | null |
# 🌀 Wan2.1_14B_FusionX
**High-Performance Merged Text-to-Video Model**
Built on WAN 2.1 and fused with research-grade components for cinematic motion, detail, and speed — optimized for ComfyUI and rapid iteration in as few as 6 steps.
Merged models for faster, richer motion & detail — high performance even at just 8 steps.
> 📌 Important: To match the quality shown here, use the linked workflows or make sure to follow the recommended settings outlined below.
---
## 🚀 Overview
A powerful text-to-video model built on top of **WAN 2.1 14B**, merged with several research-grade models to boost:
- Motion quality
- Scene consistency
- Visual detail
Comparable with closed-source solutions, but open and optimized for **ComfyUI** workflows.
---
## 💡 Inside the Fusion
This model is made up of the following which is on TOP of Wan 2.1 14B 720p(FusionX would not be what it is without these Models):
- **CausVid** – [Causal motion modeling for better flow and dynamics](https://github.com/tianweiy/CausVid)
- **AccVideo** – [Better temporal alignment and speed boost](https://github.com/aejion/AccVideo)
- **MoviiGen1.1** – [Cinematic smoothness and lighting](https://huggingface.co/ZuluVision/MoviiGen1.1)
- **MPS Reward LoRA** – [Tuned for motion and detail](https://huggingface.co/alibaba-pai/Wan2.1-Fun-Reward-LoRAs)
- **Custom LoRAs** – For texture, clarity, and small detail enhancements (Set at a very low level)
All merged models are provided for research and non-commercial use only.
Some components are subject to licenses such as CC BY-NC-SA 4.0, and do not fall under permissive licenses like Apache 2.0 or MIT.
Please refer to each model’s original license for full usage terms.
---
## 🚨✨**Hey guys! Just a quick update!**
We finally cooked up **FusionX LoRAs**!! 🧠💥
This is huge – now you can plug FusionX into your favorite workflows as a LoRA on top of the Wan base models and SkyReels models!🔌💫
You can still stick with the base FusionX Model if you already use it, but if you would rather have more control over the "FusionX" strength and a speed boost, then this might be for you.
Oh, and there’s a **nice speed boost** too! ⚡
**Example:** *(RTX 5090)*
- FusionX as a full base model: **8 steps = 160s** ⏱️
- FusionX as a **LoRA on Wan 2.1 14B fp8 T2V**: **8 steps = 120s** 🚀
**Bonus:** You can bump up the FusionX LoRA strength and lower your steps for a **huge speed boost** while testing/drafting.
Example: strength `2.00` with `3 steps` takes `72 seconds`.
Or lower the strength to experiment with a **less “FusionX” look**. ⚡🔍
We’ve got:
- **T2V (Text to Video)** 🎬 – works perfectly with **VACE** ⚙️
- **I2V (Image to Video)** 🖼️➡️📽️
- A dedicated **Phantom LoRA** 👻
The new LoRA's are [HERE](https://huggingface.co/vrgamedevgirl84/Wan14BT2VFusioniX/tree/main/FusionX_LoRa)
Note: The LoRa's are not meant to be put on top of the FusionX main models and instead you would use them with the Wan base models.
**New workflows** are [HERE](https://civitai.com/models/1681541) 🛠️🚀
---
After lots of testing 🧪, the video quality with the LoRA is **just as good** (and sometimes **even better**! 💯)
That’s thanks to it being trained on the **fp16 version** of FusionX 🧬💎
---
### 🌀 Preview Gallery
*These are compressed GIF previews for quick viewing — final video outputs are higher quality.*












---
## 📂 Workflows & Model Downloads
- 💡 **ComfyUI workflows** can be found here:
👉 [Workflow Collection (WIP)](https://civitai.com/models/1663553)
- 📦 **Model files (T2V, I2V, Phantom, VACE)**:
👉 [Main Hugging Face Repo](https://huggingface.co/vrgamedevgirl84/Wan14BT2VFusioniX/tree/main)
### 🧠 GGUF Variants:
- 🖼️ [FusionX Image-to-Video (GGUF)](https://huggingface.co/QuantStack/Wan2.1_I2V_14B_FusionX-GGUF/tree/main)
- 🎥 [FusionX Text-to-Video (GGUF)](https://huggingface.co/QuantStack/Wan2.1_T2V_14B_FusionX-GGUF/tree/main)
- 🎞️ [FusionX T2V VACE (for native)](https://huggingface.co/QuantStack/Wan2.1_T2V_14B_FusionX_VACE-GGUF/tree/main)
- 👻 [FusionX Phantom](https://huggingface.co/QuantStack/Phantom_Wan_14B_FusionX-GGUF/tree/main)
---
## 🎬 Example Videos
Want to see what FusionX can do? Check out these real outputs generated using the latest workflows and settings:
- **Text-to-Video**
👉 [Watch Examples](https://civitai.com/posts/17874424)
- **Image-to-Video**
👉 [Watch Examples](https://civitai.com/posts/18029174)
- **Phantom Mode**
👉 [Watch Examples](https://civitai.com/posts/17986906)
- **VACE Integration**
👉 [Watch Examples](https://civitai.com/posts/18080876)
---
## 🔧 Usage Details
### Text-to-Video
- **CGF**: Must be set to `1`
- **Shift**:
- `1024x576`: Start at `1`
- `1080x720`: Start at `2`
- For realism → lower values
- For stylized → test `3–9`
- **Scheduler**:
- Recommended: `uni_pc`
- Alternative: `flowmatch_causvid` (better for some details)
### Image-to-Video
- **CGF**: `1`
- **Shift**: `2` works best in most cases
- **Scheduler**:
- Recommended: `dmp++_sde/beta`
- To boost motion and reduce slow-mo effect:
- Frame count: `121`
- FPS: `24`
---
## 🛠 Technical Notes
- Works in as few as **6 steps**
- Best quality at **8–10 steps**
- Drop-in replacement for `Wan2.1-T2V-14B`
- Up to **50% faster rendering**, especially with **SageAttn**
- Works natively and with **Kaji Wan Wrapper**
[Wrapper GitHub](https://github.com/kijai/ComfyUI-WanVideoWrapper)
- Do **not** re-add merged LoRAs (CausVid, AccVideo, MPS)
- Feel free to add **other LoRAs** for style/variation
- Native WAN workflows also supported (slightly slower)
---
## 🧪 Performance Tips
- RTX 5090 → ~138 sec/video at 1024x576 / 81 frames
- If VRAM is limited:
- Enable block swapping
- Start with `5` blocks and adjust as needed
- Use **SageAttn** for ~30% speedup (wrapper only)
- Do **not** use `teacache`
- "Enhance a video" (tested): Adds vibrance (try values 2–4)
- "SLG" not tested — feel free to explore
---
## 🧠 Prompt Help
Want better cinematic prompts? Try the **WAN Cinematic Video Prompt Generator GPT** — it adds visual richness and makes a big difference in quality. [Download Here](https://chatgpt.com/g/g-67c3a6d6d19c81919b3247d2bfd01d0b-wan-cinematic-video-prompt-generator)
---
## 📣 Join The Community
We’re building a friendly space to chat, share outputs, and get help.
- Motion LoRAs coming soon
- Tips, updates, and support from other users
👉 [Join the Discord](https://discord.com/invite/hxPmmXmRW3)
---
## ⚖️ License
Some merged components use permissive licenses (Apache 2.0 / MIT),
**but others** — such as those from research models like *CausVid* — may be released under **non-commercial licenses** (e.g., [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)).
- ✅ You **can** use, modify, and redistribute **under original license terms**
- ❗ You **must** retain and respect the license of each component
- ⚠️ **Commercial use is not permitted** for models or components under non-commercial licenses
- 📌 Outputs are **not automatically licensed** — do your own due diligence
This model is intended for **research, education, and personal use only**.
For commercial use or monetization, please consult a legal advisor and verify all component licenses.
---
## 🙏 Credits
- WAN Team (base model)
- aejion (AccVideo)
- Tianwei Yin (CausVid)
- ZuluVision (MoviiGen)
- Alibaba PAI (MPS LoRA)
- Kijai (ComfyUI Wrapper)
And thanks to the open-source community!
---
|
[
"linoyts/wan2-1-VACE-fast",
"ginigen/VEO3-Free",
"ginigen/VEO3-Free-mirror",
"rahul7star/wan-fusionx-lora",
"ginigen/VEO3-Directors",
"rishi2025/VEO3-Free",
"Heartsync/WAN2-1-fast-T2V-FusioniX",
"Heartsync/WAN2-1-fast-T2V-FusioniX2",
"tbbl/NAG_wan2-1-fast_fusion",
"rahul7star/Wan-fusionX-Lora-T2V",
"bagihosting/VEO3",
"Darkstarxxx/WAN2-1-fast-T2V-FusioniX",
"bagihosting/VEO3-Bagihosting",
"FilipeR/WAN-21-Test",
"thankfulcarp/Wan_FusionX_with_Loras",
"thankfulcarp/Wan_t2v_FusionX_with_Loras",
"Draculajeni/VEO3-Free",
"rahul7star/InstaVideo",
"aiqtech/Wan_FusionX_with_Loras",
"Obunr/Wan.loras",
"Lemonator/wan-fusionx-lora",
"Obunr/VEO333",
"YAZAVIS092/VEO3-FreeforALL",
"bep40/wan2-1-VACE-fast",
"Ntdeseb/test2",
"Ntdeseb/NTIA-VEO3-Free",
"Lewis159/VEO3-Free",
"rohitkatyal/InstaVideo",
"Ntdeseb/test3",
"bencent/VEO3-4Free",
"skykholodovzz/WAN2-1-fast-T2V-FusioniX",
"AiCoderv2/FineToonText-to-video",
"vietnux/veo3-fake",
"whatdoesrealitymean/VEO3-Free",
"lionfxxx/wan2-1-VACE-fast",
"diocal/wan2-1-VACE-fast2",
"frsmn/Wan_FusionX_with_Lorasimp"
] |
[
"apache-2.0"
] | null | null | null | null |
[
"text-to-video"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null |
Wan-AI/Wan2.1-T2V-14B
|
[
"Text"
] |
[
"Video Generation"
] |
[
"Diffusion-based Network",
" Variational Autoencoder",
" Transformer: Text Encoder-only"
] |
[
"zh",
" en"
] |
[
"Model Merging"
] | null | 3
|
68436ae6653b53fab347c930
|
google/gemma-3n-E4B-it-litert-lm
|
google
| null | 11,970
| 13,045
|
manual
| 2025-06-06T22:25:42Z
| 2025-08-28T21:29:17Z
|
litert-lm
| 51
| 12
| null |
text-generation
| null |
[
".gitattributes",
"README.md",
"gemma-3n-E4B-it-int4-Web.litertlm",
"gemma-3n-E4B-it-int4.litertlm"
] |
[
1655,
23612,
4274978816,
4652318720
] | 8,927,322,803
|
9b2c8ab731a5dff4e4b8e49092ff147d77ac826c
|
[
"litert-lm",
"text-generation",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2210.03057",
"arxiv:2502.12404",
"arxiv:2411.19799",
"arxiv:2009.03300",
"arxiv:2502.21228",
"arxiv:2311.12022",
"arxiv:2403.07974",
"arxiv:2108.07732",
"arxiv:2107.03374",
"license:gemma",
"region:us"
] | null | null | null |
[
"gemma"
] | null | null | null | null |
[
"text-generation"
] | null | null |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6862c53843c5d350ace97398
|
NeoQuasar/Kronos-base
|
NeoQuasar
| null | 57,122
| 57,133
|
False
| 2025-06-30T17:11:20Z
| 2025-08-17T12:05:50Z
| null | 31
| 12
| null |
time-series-forecasting
| null |
[
".gitattributes",
"README.md",
"config.json",
"model.safetensors"
] |
[
1519,
8842,
228,
409264008
] | 409,274,597
|
64a2508aa9521120638a8c4b25baf61dafdd0195
|
[
"safetensors",
"Finance",
"Candlestick",
"K-line",
"time-series-forecasting",
"arxiv:2508.02739",
"license:mit",
"region:us"
] | null |
# Kronos: A Foundation Model for the Language of Financial Markets
[](https://arxiv.org/abs/2508.02739)
[](https://shiyu-coder.github.io/Kronos-demo/)
[](https://github.com/shiyu-coder/Kronos)
<p align="center">
<img src="https://github.com/shiyu-coder/Kronos/blob/master/figures/logo.jpeg?raw=true" alt="Kronos Logo" width="100">
</p>
**Kronos** is the **first open-source foundation model** for financial candlesticks (K-lines), trained on data from over **45 global exchanges**. It is designed to handle the unique, high-noise characteristics of financial data.
## Introduction
Kronos is a family of decoder-only foundation models, pre-trained specifically for the "language" of financial markets—K-line sequences. It leverages a novel two-stage framework:
1. A specialized tokenizer first quantizes continuous, multi-dimensional K-line data (OHLCV) into **hierarchical discrete tokens**.
2. A large, autoregressive Transformer is then pre-trained on these tokens, enabling it to serve as a unified model for diverse quantitative tasks.
<p align="center">
<img src="https://github.com/shiyu-coder/Kronos/blob/master/figures/overview.png?raw=true" alt="Kronos Overview" align="center" width="700px" />
</p>
The success of large-scale pre-training paradigm, exemplified by Large Language Models (LLMs), has inspired the development of Time Series Foundation Models (TSFMs). Kronos addresses existing limitations by introducing a specialized tokenizer that discretizes continuous market information into token sequences, preserving both price dynamics and trade activity patterns. We pre-train Kronos using an autoregressive objective on a massive, multi-market corpus of over 12 billion K-line records from 45 global exchanges, enabling it to learn nuanced temporal and cross-asset representations. Kronos excels in a zero-shot setting across a diverse set of financial tasks, including price series forecasting, volatility forecasting, and synthetic data generation.
## Live Demo
We have set up a live demo to visualize Kronos's forecasting results. The webpage showcases a forecast for the **BTC/USDT** trading pair over the next 24 hours.
👉 [Access the Live Demo Here](https://shiyu-coder.github.io/Kronos-demo/)
## Model Zoo
We release a family of pre-trained models with varying capacities to suit different computational and application needs. All models are readily accessible from the Hugging Face Hub.
| Model | Tokenizer | Context length | Param | Hugging Face Model Card |
|--------------|---------------------------------------------------------------------------------| -------------- | ------ |--------------------------------------------------------------------------|
| Kronos-mini | [Kronos-Tokenizer-2k](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-2k) | 2048 | 4.1M | ✅ [NeoQuasar/Kronos-mini](https://huggingface.co/NeoQuasar/Kronos-mini) |
| Kronos-small | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 24.7M | ✅ [NeoQuasar/Kronos-small](https://huggingface.co/NeoQuasar/Kronos-small) |
| Kronos-base | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 102.3M | ✅ [NeoQuasar/Kronos-base](https://huggingface.co/NeoQuasar/Kronos-base) |
| Kronos-large | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 499.2M | ❌ Not yet publicly available |
## Getting Started: Making Forecasts
Forecasting with Kronos is straightforward using the `KronosPredictor` class. It handles data preprocessing, normalization, prediction, and inverse normalization, allowing you to get from raw data to forecasts in just a few lines of code.
**Important Note**: The `max_context` for `Kronos-small` and `Kronos-base` is **512**. This is the maximum sequence length the model can process. For optimal performance, it is recommended that your input data length (i.e., `lookback`) does not exceed this limit. The `KronosPredictor` will automatically handle truncation for longer contexts.
Here is a step-by-step guide to making your first forecast.
### Installation
1. Install Python 3.10+, and then install the dependencies from the [GitHub repository's `requirements.txt`](https://github.com/shiyu-coder/Kronos/blob/main/requirements.txt):
```shell
pip install -r requirements.txt
```
### 1. Load the Tokenizer and Model
First, load a pre-trained Kronos model and its corresponding tokenizer from the Hugging Face Hub.
```python
from model import Kronos, KronosTokenizer, KronosPredictor
# Load from Hugging Face Hub
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")
```
### 2. Instantiate the Predictor
Create an instance of `KronosPredictor`, passing the model, tokenizer, and desired device.
```python
# Initialize the predictor
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)
```
### 3. Prepare Input Data
The `predict` method requires three main inputs:
- `df`: A pandas DataFrame containing the historical K-line data. It must include columns `['open', 'high', 'low', 'close']`. `volume` and `amount` are optional.
- `x_timestamp`: A pandas Series of timestamps corresponding to the historical data in `df`.
- `y_timestamp`: A pandas Series of timestamps for the future periods you want to predict.
```python
import pandas as pd
# Load your data (example data can be found in the GitHub repo)
df = pd.read_csv("./data/XSHG_5min_600977.csv")
df['timestamps'] = pd.to_datetime(df['timestamps'])
# Define context window and prediction length
lookback = 400
pred_len = 120
# Prepare inputs for the predictor
x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp = df.loc[:lookback-1, 'timestamps']
y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps']
```
### 4. Generate Forecasts
Call the `predict` method to generate forecasts. You can control the sampling process with parameters like `T`, `top_p`, and `sample_count` for probabilistic forecasting.
```python
# Generate predictions
pred_df = predictor.predict(
df=x_df,
x_timestamp=x_timestamp,
y_timestamp=y_timestamp,
pred_len=pred_len,
T=1.0, # Temperature for sampling
top_p=0.9, # Nucleus sampling probability
sample_count=1 # Number of forecast paths to generate and average
)
print("Forecasted Data Head:")
print(pred_df.head())
```
The `predict` method returns a pandas DataFrame containing the forecasted values for `open`, `high`, `low`, `close`, `volume`, and `amount`, indexed by the `y_timestamp` you provided.
### 5. Example and Visualization
For a complete, runnable script that includes data loading, prediction, and plotting, please see [`examples/prediction_example.py`](https://github.com/shiyu-coder/Kronos/blob/main/examples/prediction_example.py) in the GitHub repository.
Running this script will generate a plot comparing the ground truth data against the model's forecast, similar to the one shown below:
<p align="center">
<img src="https://github.com/shiyu-coder/Kronos/blob/master/figures/prediction_example.png?raw=true" alt="Forecast Example" align="center" width="600px" />
</p>
Additionally, a script that makes predictions without Volume and Amount data can be found in [`examples/prediction_wo_vol_example.py`](https://github.com/shiyu-coder/Kronos/blob/main/examples/prediction_wo_vol_example.py).
## 🔧 Finetuning on Your Own Data (A-Share Market Example)
Refer to the [README](https://github.com/shiyu-coder/Kronos) of GitHub repository.
## Citation
If you use Kronos in your research, we would appreciate a citation to our [paper](https://huggingface.co/papers/2508.02739):
```bibtex
@misc{shi2025kronos,
title={Kronos: A Foundation Model for the Language of Financial Markets},
author={Yu Shi and Zongliang Fu and Shuo Chen and Bohan Zhao and Wei Xu and Changshui Zhang and Jian Li},
year={2025},
eprint={2508.02739},
archivePrefix={arXiv},
primaryClass={q-fin.ST},
url={https://arxiv.org/abs/2508.02739},
}
```
## License
This project is licensed under the [MIT License](https://github.com/shiyu-coder/Kronos/blob/main/LICENSE).
|
[
"fiewolf1000/stockai"
] |
[
"mit"
] | null | null | null | null |
[
"time-series-forecasting"
] | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
686402ad18dc1091659e67b3
|
bosonai/higgs-audio-v2-generation-3B-base
|
bosonai
| null | 309,925
| 479,098
|
False
| 2025-07-01T15:45:49Z
| 2025-07-28T20:17:03Z
| null | 587
| 12
| null |
text-to-speech
|
{"parameters": {"BF16": 5771283456}, "total": 5771283456}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"emergent-tts-emotions-win-rate.png",
"generation_config.json",
"higgs_audio_tokenizer_architecture.png",
"higgs_audio_v2_architecture_combined.png",
"higgs_audio_v2_open_source_delay_pattern.png",
"model-00001-of-00003.safetensors",
"model-00002-of-00003.safetensors",
"model-00003-of-00003.safetensors",
"model.safetensors.index.json",
"open_source_repo_demo.mp4",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
2062,
9172,
12557,
6264,
838024,
147,
117208,
438316,
33002,
4965820232,
4983224272,
1593566728,
31095,
13975450,
301,
17209675,
50279
] | 11,575,334,784
|
10840182ca4ad5d9d9113b60b9bb3c1ef1ba3f84
|
[
"safetensors",
"higgs_audio",
"text-to-speech",
"en",
"zh",
"de",
"ko",
"arxiv:2505.23009",
"license:other",
"region:us"
] | null | null |
[
"smola/higgs_audio_v2",
"alexnasa/OmniAvatar",
"savvy7007/BananaTTS",
"ginigen/higgs_audio-Enhanced",
"glodov/gradio",
"mpasila/higgs_audio_v2",
"LLMhacker/higgs_audio_v2",
"bla/higgs_audio_v2",
"fexeak/auido-generation-3B-v2",
"ComedieDesMondesHybrides/higgs_audio",
"VirtualOasis/higgs_audio_v2",
"Dorjzodovsuren/higgs_audio_v2",
"vakilrathod67/OmniAvatar"
] |
[
"other"
] | null |
[
"en",
"zh",
"de",
"ko"
] | 5,771,283,456
| null |
[
"text-to-speech"
] | null |
[
"HiggsAudioModel",
"higgs_audio"
] |
[
"audio"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
686ceee17e3b40a013a9afdc
|
HuggingFaceTB/SmolLM3-3B
|
HuggingFaceTB
|
{
"models": [
{
"_id": "6853f5779e7c268e15850d9c",
"id": "HuggingFaceTB/SmolLM3-3B-Base"
}
],
"relation": "finetune"
}
| 195,702
| 890,746
|
False
| 2025-07-08T10:11:45Z
| 2025-08-14T16:40:41Z
|
transformers
| 677
| 12
| null |
text-generation
|
{"parameters": {"BF16": 3075098624}, "total": 3075098624}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"notebook.ipynb",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
17452,
5598,
1915,
182,
4966315264,
1183919744,
26899,
317457,
289,
17208819,
50387
] | 6,167,865,576
|
1c00fc78bd9cf90108046bc433cb34992480f1c1
|
[
"transformers",
"safetensors",
"smollm3",
"text-generation",
"conversational",
"en",
"fr",
"es",
"it",
"pt",
"zh",
"ar",
"ru",
"base_model:HuggingFaceTB/SmolLM3-3B-Base",
"base_model:finetune:HuggingFaceTB/SmolLM3-3B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# SmolLM3

## Table of Contents
1. [Model Summary](#model-summary)
2. [How to use](#how-to-use)
3. [Evaluation](#evaluation)
4. [Training](#training)
5. [Limitations](#limitations)
6. [License](#license)
## Model Summary
SmolLM3 is a 3B parameter language model designed to push the boundaries of small models. It supports dual mode reasoning, 6 languages and long context. SmolLM3 is a fully open model that offers strong performance at the 3B–4B scale.

The model is a decoder-only transformer using GQA and NoPE (with 3:1 ratio), it was pretrained on 11.2T tokens with a staged curriculum of web, code, math and reasoning data. Post-training included midtraining on 140B reasoning tokens followed by supervised fine-tuning and alignment via Anchored Preference Optimization (APO).
### Key features
- Instruct model optimized for **hybrid reasoning**
- **Fully open model**: open weights + full training details including public data mixture and training configs
- **Long context:** Trained on 64k context and supports up to **128k tokens** using YARN extrapolation
- **Multilingual**: 6 natively supported (English, French, Spanish, German, Italian, and Portuguese)
For more details refer to our blog post: https://hf.co/blog/smollm3
## How to use
The modeling code for SmolLM3 is available in transformers `v4.53.0`, so make sure to upgrade your transformers version. You can also load the model with the latest `vllm` which uses transformers as a backend.
```bash
pip install -U transformers
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# prepare the model input
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
```
>[!TIP]
> We recommend setting `temperature=0.6` and `top_p=0.95` in the sampling parameters.
### Long context processing
The current `config.json` is set for context length up to 65,536 tokens. To handle longer inputs (128k or 256k), we utilize YaRN you can change the `max_position_embeddings` and rope_scaling` to:
```
{
...,
"rope_scaling": {
"factor": 2.0, #2x65536=131 072
"original_max_position_embeddings": 65536,
"type": "yarn"
}
}
```
### Enabling and Disabling Extended Thinking Mode
We enable extended thinking by default, so the example above generates the output with a reasoning trace. For choosing between enabling, you can provide the `/think` and `/no_think` flags through the system prompt as shown in the snippet below for extended thinking disabled. The code for generating the response with extended thinking would be the same except that the system prompt should have `/think` instead of `/no_think`.
```python
prompt = "Give me a brief explanation of gravity in simple terms."
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
```
We also provide the option of specifying the whether to use extended thinking through the `enable_thinking` kwarg as in the example below. You do not need to set the `/no_think` or `/think` flags through the system prompt if using the kwarg, but keep in mind that the flag in the system prompt overwrites the setting in the kwarg.
```python
prompt = "Give me a brief explanation of gravity in simple terms."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
```
### Agentic Usage
SmolLM3 supports tool calling!
Just pass your list of tools:
- Under the argument `xml_tools` for standard tool-calling: these tools will be called as JSON blobs within XML tags, like `<tool_call>{"name": "get_weather", "arguments": {"city": "Copenhagen"}}</tool_call>`
- Or under `python_tools`: then the model will call tools like python functions in a `<code>` snippet, like `<code>get_weather(city="Copenhagen")</code>`
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tools = [
{
"name": "get_weather",
"description": "Get the weather in a city",
"parameters": {"type": "object", "properties": {"city": {"type": "string", "description": "The city to get the weather for"}}}}
]
messages = [
{
"role": "user",
"content": "Hello! How is the weather today in Copenhagen?"
}
]
inputs = tokenizer.apply_chat_template(
messages,
enable_thinking=False, # True works as well, your choice!
xml_tools=tools,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt"
)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Using Custom System Instructions.
You can specify custom instruction through the system prompt while controlling whether to use extended thinking. For example, the snippet below shows how to make the model speak like a pirate while enabling extended thinking.
```python
prompt = "Give me a brief explanation of gravity in simple terms."
messages = [
{"role": "system", "content": "Speak like a pirate./think"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
```
For local inference, you can use `llama.cpp`, `ONNX`, `MLX`, `MLC` and `ExecuTorch`. You can find quantized checkpoints in this collection (https://huggingface.co/collections/HuggingFaceTB/smollm3-686d33c1fdffe8e635317e23)
### vLLM and SGLang
You can use vLLM and SGLang to deploy the model in an API compatible with OpenAI format.
#### SGLang
```bash
python -m sglang.launch_server --model-path HuggingFaceTB/SmolLM3-3B
```
#### vLLM
```bash
vllm serve HuggingFaceTB/SmolLM3-3B --enable-auto-tool-choice --tool-call-parser=hermes
```
#### Setting `chat_template_kwargs`
You can specify `chat_template_kwargs` such as `enable_thinking` to a deployed model by passing the `chat_template_kwargs` parameter in the API request.
```bash
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "HuggingFaceTB/SmolLM3-3B",
"messages": [
{"role": "user", "content": "Give me a brief explanation of gravity in simple terms."}
],
"temperature": 0.6,
"top_p": 0.95,
"max_tokens": 16384,
"chat_template_kwargs": {"enable_thinking": false}
}'
```
## Evaluation
In this section, we report the evaluation results of SmolLM3 model. All evaluations are zero-shot unless stated otherwise, and we use [lighteval](https://github.com/huggingface/lighteval) to run them.
We highlight the best score in bold and underline the second-best score.
### Instruction Model
#### No Extended Thinking
Evaluation results of non reasoning models and reasoning models in no thinking mode. We highlight the best and second-best scores in bold.
| Category | Metric | SmoLLM3-3B | Qwen2.5-3B | Llama3.1-3B | Qwen3-1.7B | Qwen3-4B |
|---------|--------|------------|------------|-------------|------------|----------|
| High school math competition | AIME 2025 | <u>9.3</u> | 2.9 | 0.3 | 8.0 | **17.1** |
| Math problem-solving | GSM-Plus | 72.8 | <u>74.1</u> | 59.2 | 68.3 | **82.1** |
| Competitive programming | LiveCodeBench v4 | <u>15.2</u> | 10.5 | 3.4 | 15.0 | **24.9** |
| Graduate-level reasoning | GPQA Diamond | <u>35.7</u> | 32.2 | 29.4 | 31.8 | **44.4** |
| Instruction following | IFEval | **76.7** | 65.6 | 71.6 | <u>74.0</u> | 68.9 |
| Alignment | MixEval Hard | 26.9 | <u>27.6</u> | 24.9 | 24.3 | **31.6** |
| Tool Calling | BFCL| <u>92.3</u> | - | <u>92.3</u> * | 89.5 | **95.0** |
| Multilingual Q&A | Global MMLU | <u>53.5</u> | 50.54 | 46.8 | 49.5 | **65.1** |
(*): this is a tool calling finetune
#### Extended Thinking
Evaluation results in reasoning mode for SmolLM3 and Qwen3 models:
| Category | Metric | SmoLLM3-3B | Qwen3-1.7B | Qwen3-4B |
|---------|--------|------------|------------|----------|
| High school math competition | AIME 2025 | <u>36.7</u> | 30.7 | **58.8** |
| Math problem-solving | GSM-Plus | <u>83.4</u> | 79.4 | **88.2** |
| Competitive programming | LiveCodeBench v4 | 30.0 | <u>34.4</u> | **52.9** |
| Graduate-level reasoning | GPQA Diamond | <u>41.7</u> | 39.9 | **55.3** |
| Instruction following | IFEval | 71.2 | <u>74.2</u> | **85.4** |
| Alignment | MixEval Hard | 30.8 | <u>33.9</u> | **38.0** |
| Tool Calling | BFCL | <u>88.8</u> | <u>88.8</u> | **95.5** |
| Multilingual Q&A | Global MMLU | <u>64.1</u> | 62.3 | **73.3** |
### Base Pre-Trained Model
#### English benchmarks
Note: All evaluations are zero-shot unless stated otherwise. For Ruler 64k evaluation, we apply YaRN to the Qwen models with 32k context to extrapolate the context length.
| Category | Metric | SmolLM3-3B | Qwen2.5-3B | Llama3-3.2B | Qwen3-1.7B-Base | Qwen3-4B-Base |
|---------|--------|---------------------|------------|--------------|------------------|---------------|
| Reasoning & Commonsense| HellaSwag | **76.15** | 74.19 |<u>75.52</u> | 60.52 | 74.37 |
| | ARC-CF (Average) | **65.61** | 59.81 | 58.58 | 55.88 | <u>62.11</u> |
| | Winogrande | 58.88 | **61.41** | 58.72 | 57.06 | <u>59.59</u> |
| | CommonsenseQA | <u>55.28</u> | 49.14 | **60.60** | 48.98 | 52.99 |
| Knowledge & Understanding | MMLU-CF (Average) | <u>44.13</u> | 42.93 | 41.32 | 39.11 | **47.65** |
| | MMLU Pro CF | <u>19.61</u> | 16.66 | 16.42 | 18.04 | **24.92** |
| | MMLU Pro MCF | <u>32.70</u> | 31.32 | 25.07 | 30.39 | **41.07** |
| | PIQA | **78.89** | 78.35 | <u>78.51</u> | 75.35 | 77.58 |
| | OpenBookQA | 40.60 | 40.20 | <u>42.00</u> | 36.40 | **42.40** |
| | BoolQ | **78.99** | 73.61 | <u>75.33</u> | 74.46 | 74.28 |
| **Math & Code** | | | | | | |
| Coding & math | HumanEval+ | 30.48 | 34.14| 25.00 | <u>43.29</u>| **54.87** |
| | MBPP+ | 52.91 | 52.11 | 38.88| <u>59.25</u> | **63.75** |
| | MATH (4-shot) | <u>46.10</u> | 40.10 | 7.44 | 41.64 | **51.20** |
| | GSM8k (5-shot) | 67.63 | <u>70.13</u> | 25.92 | 65.88 | **74.14** |
| **Long context** | | | | | | |
| | Ruler 32k | 76.35 | 75.93 | <u>77.58</u> | 70.63 | **83.98** |
| | Ruler 64k | <u>67.85</u> | 64.90 | **72.93** | 57.18 | 60.29 |
| | Ruler 128k | 61.03 | <u>62.23</u> | **71.30** | 43.03 | 47.23 |
#### Multilingual benchmarks
| Category | Metric | SmolLM3 3B Base | Qwen2.5-3B | Llama3.2 3B | Qwen3 1.7B Base | Qwen3 4B Base |
|---------|--------|---------------------|------------|--------------|------------------|---------------|
| Main supported languages | | | | | | | |
| French| MLMM Hellaswag | **63.94** | 57.47 | 57.66 | 51.26 | <u>61.00</u> |
| | Belebele | 51.00 | <u>51.55</u> | 49.22 |49.44| **55.00** |
| | Global MMLU (CF) | <u>38.37</u> | 34.22 | 33.71 | 34.94 |**41.80** |
| | Flores-200 (5-shot) | 62.85| 61.38| <u>62.89</u> | 58.68 | **65.76** |
| Spanish| MLMM Hellaswag | **65.85** | 58.25 | 59.39 | 52.40 | <u>61.85</u> |
| | Belebele | 47.00 | <u>48.88</u> | 47.00 | 47.56 | **50.33** |
| | Global MMLU (CF) | <u>38.51</u> | 35.84 | 35.60 | 34.79 |**41.22** |
| | Flores-200 (5-shot) | <u>48.25</u>| 50.00| 44.45 | 46.93 | **50.16** |
| German| MLMM Hellaswag | **59.56** | 49.99| 53.19|46.10| <u>56.43</u>|
| | Belebele | <u>48.44</u> | 47.88 | 46.22 | 48.00 | **53.44**|
| | Global MMLU (CF) | <u>35.10</u> | 33.19 | 32.60 | 32.73 |**38.70** |
| | Flores-200 (5-shot) | **56.60**| 50.63| <u>54.95</u> | 52.58 | 50.48 |
| Italian| MLMM Hellaswag | **62.49** | 53.21 | 54.96 | 48.72 | <u>58.76</u> |
| | Belebele | <u>46.44</u> | 44.77 | 43.88 | 44.00 | **48.78** | 44.88 |
| | Global MMLU (CF) | <u>36.99</u> | 33.91 | 32.79 | 35.37 |**39.26** |
| | Flores-200 (5-shot) | <u>52.65<u/>| **54.87**| 48.83 | 48.37 | 49.11 |
| Portuguese| MLMM Hellaswag | **63.22** | 57.38 | 56.84 | 50.73 | <u>59.89</u> |
| | Belebele | 47.67 | **49.22** | 45.00 | 44.00 | 50.00 | <u>49.00</U> |
| | Global MMLU (CF) | <u>36.88</u> | 34.72 | 33.05 | 35.26 |**40.66** |
| | Flores-200 (5-shot) | <u>60.93</u> |57.68| 54.28 | 56.58 | **63.43** |
The model has also been trained on Arabic (standard), Chinese and Russian data, but has seen fewer tokens in these languages compared to the 6 above. We report the performance on these langages for information.
| Category | Metric | SmolLM3 3B Base | Qwen2.5-3B | Llama3.2 3B | Qwen3 1.7B Base | Qwen3 4B Base |
|---------|--------|---------------------|------------|--------------|------------------|---------------|
| Other supported languages | | | | | | | |
| Arabic| Belebele | 40.22 | 44.22 | <u>45.33</u> | 42.33 | **51.78** |
| | Global MMLU (CF) | 28.57 | 28.81 | 27.67 | <u>29.37</u> | **31.85** |
| | Flores-200 (5-shot) | <u>40.22</u> | 39.44 | **44.43** | 35.82 | 39.76 |
| Chinese| Belebele | 43.78 | 44.56 | <u>49.56</u> | 48.78 | **53.22** |
| | Global MMLU (CF) | 36.16 | 33.79 | <u>39.57</u> | 38.56 | **44.55** |
| | Flores-200 (5-shot) | 29.17 | **33.21** | 31.89 | 25.70 | <u>32.50</u> |
| Russian| Belebele | <u>47.44</u> | 45.89 | <u>47.44</u> | 45.22 | **51.44** |
| | Global MMLU (CF) | <u>36.51</u> | 32.47 | 34.52 | 34.83 | **38.80** |
| | Flores-200 (5-shot) | 47.13 | 48.74 | 50.74 | <u>54.70</u> | **60.53** |
## Training
### Model
- **Architecture:** Transformer decoder
- **Pretraining tokens:** 11T
- **Precision:** bfloat16
### Software & hardware
- **GPUs:** 384 H100
- **Training Framework:** [nanotron](https://github.com/huggingface/nanotron/tree/smollm3)
- **Data processing framework:** [datatrove](https://github.com/huggingface/datatrove)
- **Evaluation framework:** [lighteval](https://github.com/huggingface/lighteval)
- **Post-training Framework:** [TRL](https://github.com/huggingface/trl)
### Open resources
Here is an infographic with all the training details
- The datasets used for pretraining can be found in this [collection](https://huggingface.co/collections/HuggingFaceTB/smollm3-pretraining-datasets-685a7353fdc01aecde51b1d9) and those used in mid-training and post-training will be uploaded later
- The training and evaluation configs and code can be found in the [huggingface/smollm](https://github.com/huggingface/smollm) repository.
- The training intermediate checkpoints (including the mid-training and SFT checkpoints) are available at [HuggingFaceTB/SmolLM3-3B-checkpoints](https://huggingface.co/HuggingFaceTB/SmolLM3-3B-checkpoints)

### EU Summary of Public Content
The EU AI Act requires all GPAI models to provide a Public Summary of Training Content according to a [given template](https://digital-strategy.ec.europa.eu/en/library/explanatory-notice-and-template-public-summary-training-content-general-purpose-ai-models).
You can find the summary for this model below, as well as in its [development Space](https://huggingface.co/spaces/hfmlsoc/smollm3-eu-data-transparency).
<iframe
src="https://hfmlsoc-smollm3-eu-data-transparency.hf.space"
frameborder="0"
width="850"
height="350"
></iframe>
## Limitations
SmolLM3 can produce text on a variety of topics, but the generated content may not always be factually accurate, logically consistent, or free from biases present in the training data. These models should be used as assistive tools rather than definitive sources of information. Users should always verify important information and critically evaluate any generated content.
## License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Citation
```bash
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{https://huggingface.co/blog/smollm3}}
}
```
|
[
"TiberiuCristianLeon/GradioTranslate",
"codelion/safety-copilot",
"vsrinivas/Social_Impact_Investment_Platform",
"andreska/AdregaAIChat61",
"moeinab/customer-complaint",
"brendon-ai/faq-huggingface-model",
"nfel/infherno",
"tuliodisanto/buscador_analistas_IA",
"ProCreations/smollm3",
"6Genix/HuggingFaceTB-SmolLM3-3B",
"PaulHouston/HuggingFaceTB-SmolLM3-3B_2",
"nidheesh1994/ai-assistant-new",
"ginipick/HuggingFaceTB-SmolLM3-3B",
"tomhflau/Final_Assignment_Template",
"slemiu/smolLM",
"DarwinAnim8or/SmolLM3-img-gen",
"bytewhisperer11/HuggingFaceTB-SmolLM3-3B",
"diegogalan8484/HuggingFaceTB-SmolLM3-3B",
"tharapearlly/smollm-affirmations",
"sivaganesh4ai/HuggingFaceTB-SmolLM3-3B",
"mgbam/builder",
"Amanda03/supplement-recommendation",
"harmancs/automated-book-writer",
"cjduck113/HuggingFaceTB-SmolLM3-3B",
"jlov7/Dynamic-Function-Calling-Agent",
"ReallyFloppyPenguin/HuggingFaceTB-SmolLM3-3B",
"jedick/R-help-chat",
"Bluestrikeai/SmolLM3-3B",
"jlov7/auto-dpo-loop-demo",
"hfmlsoc/smollm3-eu-data-transparency",
"dstrophe/test-space",
"david-thrower/3B-Param-Agent",
"david-thrower/3B-Param-Basic-Chatbot",
"Inszero209/HuggingFaceTB-SmolLM3-3B",
"John6666/First_agent_template_smollm3_test",
"asyte-rob/HuggingFaceTB-SmolLM3-3B",
"TroglodyteDerivations/Robotic_Arm_Calculator_Gallery",
"adilsyed/ZenAI",
"gaialive/Nentang_Dautu_TacdongXahoi",
"TroglodyteDerivations/Terminal_Instructions_For_Install_Sh",
"RohanVashisht/AI_test",
"Tonic/SmolFactory",
"ethanwinters1907/HuggingFaceTB-SmolLM3-3B",
"adamgogogo/HuggingFaceTB-SmolLM3-3B-test",
"HamzaArfan/HuggingFaceTB-SmolLM3-3B",
"bhuwanpandey7/smollm3-chatbot",
"yulongzhao/HuggingFaceTB-SmolLM3-3B",
"diegorossler/HuggingFaceTB-SmolLM3-3B-2",
"nkjoy/Ai",
"sdqfg/test"
] |
[
"apache-2.0"
] | null |
[
"en",
"fr",
"es",
"it",
"pt",
"zh",
"ar",
"ru"
] | 3,075,098,624
| null |
[
"text-generation"
] | null |
[
"SmolLM3ForCausalLM",
"AutoModelForCausalLM",
"smollm3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
community
|
[
"HF"
] | null | null | null | null | null | null | null | null | null |
6887875e72269759e541740f
|
QuantStack/Wan2.2-I2V-A14B-GGUF
|
QuantStack
|
{
"models": [
{
"_id": "6881e60ffcffaee6d84fe9e4",
"id": "Wan-AI/Wan2.2-I2V-A14B"
}
],
"relation": "quantized"
}
| 292,261
| 338,654
|
False
| 2025-07-28T14:21:18Z
| 2025-07-29T13:04:00Z
|
gguf
| 89
| 12
| null |
image-to-video
| null |
[
".gitattributes",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q2_K.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q3_K_M.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q3_K_S.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q4_K_M.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q4_K_S.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q5_0.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q5_1.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q5_K_M.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q5_K_S.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q6_K.gguf",
"HighNoise/Wan2.2-I2V-A14B-HighNoise-Q8_0.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q2_K.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q3_K_M.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q3_K_S.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q4_0.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q4_1.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q4_K_M.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q4_K_S.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q5_0.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q5_1.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q5_K_M.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q5_K_S.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q6_K.gguf",
"LowNoise/Wan2.2-I2V-A14B-LowNoise-Q8_0.gguf",
"README.md",
"VAE/Wan2.1_VAE.safetensors"
] |
[
3485,
5300957696,
7176106496,
6515012096,
9651728896,
8748151296,
10314461696,
11015696896,
10792055296,
10137514496,
12003652096,
15406608896,
5300957696,
7176106496,
6515012096,
8558096896,
9259332096,
9651728896,
8748151296,
10314461696,
11015696896,
10792055296,
10137514496,
12003652096,
15406608896,
617,
253815318
] | 232,195,140,124
|
6c6717459277b9cd1f72579d78a0fd62a79e57dc
|
[
"gguf",
"image-to-video",
"en",
"zh",
"base_model:Wan-AI/Wan2.2-I2V-A14B",
"base_model:quantized:Wan-AI/Wan2.2-I2V-A14B",
"license:apache-2.0",
"region:us"
] |
{"total": 14288901184, "architecture": "wan"}
| null | null |
[
"apache-2.0"
] | null |
[
"en",
"zh"
] | null | 14,288,901,184
|
[
"image-to-video"
] | null |
[
"wan"
] |
[
"vision"
] |
[
"text",
"image"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
6891589998b393e6b93274a8
|
unsloth/GLM-4.5-Air-GGUF
|
unsloth
|
{
"models": [
{
"_id": "687c61c324649ecb26a748f0",
"id": "zai-org/GLM-4.5-Air"
}
],
"relation": "quantized"
}
| 123,086
| 123,086
|
False
| 2025-08-05T01:04:25Z
| 2025-08-05T05:32:36Z
|
transformers
| 83
| 12
| null |
text-generation
| null |
[
".gitattributes",
"BF16/GLM-4.5-Air-BF16-00001-of-00005.gguf",
"BF16/GLM-4.5-Air-BF16-00002-of-00005.gguf",
"BF16/GLM-4.5-Air-BF16-00003-of-00005.gguf",
"BF16/GLM-4.5-Air-BF16-00004-of-00005.gguf",
"BF16/GLM-4.5-Air-BF16-00005-of-00005.gguf",
"GLM-4.5-Air-Q2_K.gguf",
"GLM-4.5-Air-Q2_K_L.gguf",
"GLM-4.5-Air-UD-IQ1_M.gguf",
"GLM-4.5-Air-UD-IQ1_S.gguf",
"GLM-4.5-Air-UD-IQ2_M.gguf",
"GLM-4.5-Air-UD-IQ2_XXS.gguf",
"GLM-4.5-Air-UD-Q2_K_XL.gguf",
"GLM-4.5-Air-UD-TQ1_0.gguf",
"IQ4_NL/GLM-4.5-Air-IQ4_NL-00001-of-00002.gguf",
"IQ4_NL/GLM-4.5-Air-IQ4_NL-00002-of-00002.gguf",
"IQ4_XS/GLM-4.5-Air-IQ4_XS-00001-of-00002.gguf",
"IQ4_XS/GLM-4.5-Air-IQ4_XS-00002-of-00002.gguf",
"Q3_K_M/GLM-4.5-Air-Q3_K_M-00001-of-00002.gguf",
"Q3_K_M/GLM-4.5-Air-Q3_K_M-00002-of-00002.gguf",
"Q3_K_S/GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf",
"Q3_K_S/GLM-4.5-Air-Q3_K_S-00002-of-00002.gguf",
"Q4_0/GLM-4.5-Air-Q4_0-00001-of-00002.gguf",
"Q4_0/GLM-4.5-Air-Q4_0-00002-of-00002.gguf",
"Q4_1/GLM-4.5-Air-Q4_1-00001-of-00002.gguf",
"Q4_1/GLM-4.5-Air-Q4_1-00002-of-00002.gguf",
"Q4_K_M/GLM-4.5-Air-Q4_K_M-00001-of-00002.gguf",
"Q4_K_M/GLM-4.5-Air-Q4_K_M-00002-of-00002.gguf",
"Q4_K_S/GLM-4.5-Air-Q4_K_S-00001-of-00002.gguf",
"Q4_K_S/GLM-4.5-Air-Q4_K_S-00002-of-00002.gguf",
"Q5_K_M/GLM-4.5-Air-Q5_K_M-00001-of-00002.gguf",
"Q5_K_M/GLM-4.5-Air-Q5_K_M-00002-of-00002.gguf",
"Q5_K_S/GLM-4.5-Air-Q5_K_S-00001-of-00002.gguf",
"Q5_K_S/GLM-4.5-Air-Q5_K_S-00002-of-00002.gguf",
"Q6_K/GLM-4.5-Air-Q6_K-00001-of-00002.gguf",
"Q6_K/GLM-4.5-Air-Q6_K-00002-of-00002.gguf",
"Q8_0/GLM-4.5-Air-Q8_0-00001-of-00003.gguf",
"Q8_0/GLM-4.5-Air-Q8_0-00002-of-00003.gguf",
"Q8_0/GLM-4.5-Air-Q8_0-00003-of-00003.gguf",
"README.md",
"UD-Q3_K_XL/GLM-4.5-Air-UD-Q3_K_XL-00001-of-00002.gguf",
"UD-Q3_K_XL/GLM-4.5-Air-UD-Q3_K_XL-00002-of-00002.gguf",
"UD-Q4_K_XL/GLM-4.5-Air-UD-Q4_K_XL-00001-of-00002.gguf",
"UD-Q4_K_XL/GLM-4.5-Air-UD-Q4_K_XL-00002-of-00002.gguf",
"UD-Q5_K_XL/GLM-4.5-Air-UD-Q5_K_XL-00001-of-00002.gguf",
"UD-Q5_K_XL/GLM-4.5-Air-UD-Q5_K_XL-00002-of-00002.gguf",
"UD-Q6_K_XL/GLM-4.5-Air-UD-Q6_K_XL-00001-of-00003.gguf",
"UD-Q6_K_XL/GLM-4.5-Air-UD-Q6_K_XL-00002-of-00003.gguf",
"UD-Q6_K_XL/GLM-4.5-Air-UD-Q6_K_XL-00003-of-00003.gguf",
"UD-Q8_K_XL/GLM-4.5-Air-UD-Q8_K_XL-00001-of-00003.gguf",
"UD-Q8_K_XL/GLM-4.5-Air-UD-Q8_K_XL-00002-of-00003.gguf",
"UD-Q8_K_XL/GLM-4.5-Air-UD-Q8_K_XL-00003-of-00003.gguf",
"imatrix_unsloth.gguf"
] |
[
5734,
49820314656,
49793597056,
48572097408,
49793597056,
23017799712,
45065825120,
45211315040,
39976455008,
38372477792,
44307499872,
42600418144,
46449494880,
38130256736,
49888581344,
12623787360,
49725767040,
10540666528,
49809168864,
7224935008,
49645253088,
2807736928,
49997890432,
12585633952,
49946263264,
19312397664,
49913518112,
22944003104,
49781040384,
17087981376,
49841691328,
33564176736,
49833174592,
28431115776,
49689530592,
49317997408,
49793116352,
49788877664,
17874512000,
3736,
49900472640,
7829390048,
49977546784,
23060362272,
49989737632,
33504092032,
49817606976,
49467993536,
2271478688,
49786100736,
49975655264,
27978577248,
228395296
] | 1,886,867,383,998
|
a5133889a6e29d42a1e71784b2ae8514fb28156f
|
[
"transformers",
"gguf",
"unsloth",
"text-generation",
"en",
"zh",
"base_model:zai-org/GLM-4.5-Air",
"base_model:quantized:zai-org/GLM-4.5-Air",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 110468824832, "architecture": "glm4moe", "context_length": 131072, "quantize_imatrix_file": "GLM-4.5-Air-GGUF/imatrix_unsloth.gguf", "chat_template": "[gMASK]<sop>\n{%- if tools -%}\n<|system|>\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>\n{% for tool in tools %}\n{{ tool | tojson|string }}\n{% endfor %}\n</tools>\n\nFor each function call, output the function name and arguments within the following XML format:\n<tool_call>{function-name}\n<arg_key>{arg-key-1}</arg_key>\n<arg_value>{arg-value-1}</arg_value>\n<arg_key>{arg-key-2}</arg_key>\n<arg_value>{arg-value-2}</arg_value>\n...\n</tool_call>{%- endif -%}\n{%- macro visible_text(content) -%}\n {%- if content is string -%}\n {{- content }}\n {%- elif content is iterable and content is not mapping -%}\n {%- for item in content -%}\n {%- if item is mapping and item.type == 'text' -%}\n {{- item.text }}\n {%- elif item is string -%}\n {{- item }}\n {%- endif -%}\n {%- endfor -%}\n {%- else -%}\n {{- content }}\n {%- endif -%}\n{%- endmacro -%}\n{%- set ns = namespace(last_user_index=-1) %}\n{%- for m in messages %}\n {%- if m.role == 'user' %}\n {% set ns.last_user_index = loop.index0 -%}\n {%- endif %}\n{%- endfor %}\n{% for m in messages %}\n{%- if m.role == 'user' -%}<|user|>\n{% set content = visible_text(m.content) %}{{ content }}\n{{- '/nothink' if (enable_thinking is defined and not enable_thinking and not content.endswith(\"/nothink\")) else '' -}}\n{%- elif m.role == 'assistant' -%}\n<|assistant|>\n{%- set reasoning_content = '' %}\n{%- set content = visible_text(m.content) %}\n{%- if m.reasoning_content is string %}\n {%- set reasoning_content = m.reasoning_content %}\n{%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = ((content.split('</think>')|first).rstrip('\\n').split('<think>')|last).lstrip('\\n') %}\n {%- set content = (content.split('</think>')|last).lstrip('\\n') %}\n {%- endif %}\n{%- endif %}\n{%- if loop.index0 > ns.last_user_index and reasoning_content -%}\n{{ '\\n<think>' + reasoning_content.strip() + '</think>'}}\n{%- else -%}\n{{ '\\n<think></think>' }}\n{%- endif -%}\n{%- if content.strip() -%}\n{{ '\\n' + content.strip() }}\n{%- endif -%}\n{% if m.tool_calls %}\n{% for tc in m.tool_calls %}\n{%- if tc.function %}\n {%- set tc = tc.function %}\n{%- endif %}\n{{ '\\n<tool_call>' + tc.name }}\n{% set _args = tc.arguments %}\n{% for k, v in _args.items() %}\n<arg_key>{{ k }}</arg_key>\n<arg_value>{{ v | tojson|string if v is not string else v }}</arg_value>\n{% endfor %}\n</tool_call>{% endfor %}\n{% endif %}\n{%- elif m.role == 'tool' -%}\n{%- if m.content is string -%}\n{%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|observation|>' }}\n{%- endif %}\n{{- '\\n<tool_response>\\n' }}\n{{- m.content }}\n{{- '\\n</tool_response>' }}\n{%- else -%}\n<|observation|>{% for tr in m.content %}\n\n<tool_response>\n{{ tr.output if tr.output is defined else tr }}\n</tool_response>{% endfor -%}\n{% endif -%}\n{%- elif m.role == 'system' -%}\n<|system|>\n{{ visible_text(m.content) }}\n{%- endif -%}\n{%- endfor -%}\n{%- if add_generation_prompt -%}\n <|assistant|>{{- '\\n<think></think>' if (enable_thinking is defined and not enable_thinking) else '' -}}\n{%- endif -%}", "bos_token": "[gMASK]", "eos_token": "<|endoftext|>"}
| null | null |
[
"mit"
] | null |
[
"en",
"zh"
] | null | 110,468,824,832
|
[
null,
"text-generation"
] | null |
[
"glm4moe",
"AutoModel"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6892993be68d438e900b601d
|
facebook/meta-wiki-expert
|
facebook
| null | 15
| 15
|
False
| 2025-08-05T23:52:27Z
| 2025-08-12T23:06:22Z
| null | 15
| 12
| null | null |
{"parameters": {"BF16": 8030261248}, "total": 8030261248}
|
[
".gitattributes",
"README.md",
"config.json",
"consolidated/consolidated.pth",
"consolidated/params.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
14fafb95b24ec1b79bcfbe31fa17f864d7eadbde
|
[
"safetensors",
"llama",
"<relevant tags to be included in HF filters>",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | null | null | null |
[
"cc-by-nc-4.0"
] | null |
[
"en"
] | 8,030,261,248
| null | null | null |
[
"llama",
"LlamaForCausalLM"
] | null | null | null |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
689bdf1509cb26ac337c41da
|
unsloth/gemma-3-270m-it-GGUF
|
unsloth
|
{
"models": [
{
"_id": "688a5f23e7cb4413ca5b8678",
"id": "google/gemma-3-270m-it"
}
],
"relation": "quantized"
}
| 70,383
| 70,383
|
False
| 2025-08-13T00:40:53Z
| 2025-08-15T11:53:27Z
|
transformers
| 108
| 12
| null |
text-generation
| null |
[
".gitattributes",
"README.md",
"gemma-3-270m-it-F16.gguf",
"gemma-3-270m-it-IQ4_NL.gguf",
"gemma-3-270m-it-IQ4_XS.gguf",
"gemma-3-270m-it-Q2_K.gguf",
"gemma-3-270m-it-Q2_K_L.gguf",
"gemma-3-270m-it-Q3_K_M.gguf",
"gemma-3-270m-it-Q3_K_S.gguf",
"gemma-3-270m-it-Q4_0.gguf",
"gemma-3-270m-it-Q4_1.gguf",
"gemma-3-270m-it-Q4_K_M.gguf",
"gemma-3-270m-it-Q4_K_S.gguf",
"gemma-3-270m-it-Q5_K_M.gguf",
"gemma-3-270m-it-Q5_K_S.gguf",
"gemma-3-270m-it-Q6_K.gguf",
"gemma-3-270m-it-Q8_0.gguf",
"gemma-3-270m-it-UD-IQ2_M.gguf",
"gemma-3-270m-it-UD-IQ2_XXS.gguf",
"gemma-3-270m-it-UD-IQ3_XXS.gguf",
"gemma-3-270m-it-UD-Q2_K_XL.gguf",
"gemma-3-270m-it-UD-Q3_K_XL.gguf",
"gemma-3-270m-it-UD-Q4_K_XL.gguf",
"gemma-3-270m-it-UD-Q5_K_XL.gguf",
"gemma-3-270m-it-UD-Q6_K_XL.gguf",
"gemma-3-270m-it-UD-Q8_K_XL.gguf",
"imatrix_unsloth.gguf_file",
"params",
"template"
] |
[
2818,
37648,
542835488,
241964064,
240858144,
237079584,
237079584,
241964064,
236710944,
241574944,
247677984,
253115424,
249889824,
260027424,
257999904,
282975264,
291546144,
182787104,
180104224,
184517664,
237745184,
242619424,
253934624,
260027424,
286149664,
471104544,
471040,
202,
476
] | 6,362,800,824
|
c90975dbd40c0c7b275fefaae758c3415c906238
|
[
"transformers",
"gguf",
"gemma3",
"unsloth",
"gemma",
"google",
"text-generation",
"arxiv:2503.19786",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:2311.07911",
"arxiv:2311.12022",
"arxiv:2411.04368",
"arxiv:1904.09728",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2403.07974",
"arxiv:2305.03111",
"arxiv:2405.04520",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2310.02255",
"arxiv:2312.11805",
"base_model:google/gemma-3-270m-it",
"base_model:quantized:google/gemma-3-270m-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 268098176, "architecture": "gemma3", "context_length": 32768, "chat_template": "{# Unsloth Chat template fixes #}\n{{ bos_token }}\n{%- if messages[0]['role'] == 'system' -%}\n {%- if messages[0]['content'] is string -%}\n {%- set first_user_prefix = messages[0]['content'] + '\n\n' -%}\n {%- else -%}\n {%- set first_user_prefix = messages[0]['content'][0]['text'] + '\n\n' -%}\n {%- endif -%}\n {%- set loop_messages = messages[1:] -%}\n{%- else -%}\n {%- set first_user_prefix = \"\" -%}\n {%- set loop_messages = messages -%}\n{%- endif -%}\n{%- for message in loop_messages -%}\n {%- if (message['role'] == 'user') != (loop.index0 % 2 == 0) -%}\n {{ raise_exception(\"Conversation roles must alternate user/assistant/user/assistant/...\") }}\n {%- endif -%}\n {%- if (message['role'] == 'assistant') -%}\n {%- set role = \"model\" -%}\n {%- else -%}\n {%- set role = message['role'] -%}\n {%- endif -%}\n {{ '<start_of_turn>' + role + '\n' + (first_user_prefix if loop.first else \"\") }}\n {%- if message['content'] is string -%}\n {{ message['content'] | trim }}\n {%- elif message['content'] is iterable -%}\n {%- for item in message['content'] -%}\n {%- if item['type'] == 'image' -%}\n {{ '<start_of_image>' }}\n {%- elif item['type'] == 'text' -%}\n {{ item['text'] | trim }}\n {%- endif -%}\n {%- endfor -%}\n {%- elif message['content'] is defined -%}\n {{ raise_exception(\"Invalid content type\") }}\n {%- endif -%}\n {{ '<end_of_turn>\n' }}\n{%- endfor -%}\n{%- if add_generation_prompt -%}\n {{'<start_of_turn>model\n'}}\n{%- endif -%}\n\n{# Copyright 2025-present Unsloth. Apache 2.0 License. #}", "bos_token": "<bos>", "eos_token": "<end_of_turn>"}
|
> [!NOTE]
> Please use the correct settings: `temperature = 1.0, top_k = 64, top_p = 0.95, min_p = 0.0`
>
<div>
<p style="margin-bottom: 0; margin-top: 0;">
<strong>See <a href="https://huggingface.co/collections/unsloth/gemma-3-67d12b7e8816ec6efa7e4e5b">our collection</a> for all versions of Gemma 3 including GGUF, 4-bit & 16-bit formats.</strong>
</p>
<p style="margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/tutorial-how-to-run-gemma-3-effectively">Read our Guide</a> to see how to Run Gemma 3 correctly.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/basics/tutorial-how-to-run-deepseek-r1-on-your-own-local-device">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
<h1 style="margin-top: 0rem;">✨ Fine-tune Gemma 3 with Unsloth!</h1>
</div>
- Fine-tune Gemma 3 (270M) for free using our Google [Colab notebook here](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3_(270M).ipynb)!
- Read our Blog about Gemma 3 support: [unsloth.ai/blog/gemma3](https://unsloth.ai/blog/gemma3)
- View the rest of our notebooks in our [docs here](https://docs.unsloth.ai/get-started/unsloth-notebooks).
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Gemma 3 (4B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3_(4B).ipynb) | 2x faster | 80% less |
| **Gemma-3n-E4B** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3N_(4B)-Conversational.ipynb) | 2x faster | 60% less |
| **Gemma-3n-E4B (Audio)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3N_(4B)-Audio.ipynb) | 2x faster | 60% less |
| **GRPO with Gemma 3 (1B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3_(1B)-GRPO.ipynb) | 2x faster | 80% less |
| **Gemma 3 (4B) Vision** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3_(4B)-Vision.ipynb) | 2x faster | 60% less |
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 models are multimodal, handling text and image input and generating text
output, with open weights for both pre-trained variants and instruction-tuned
variants. Gemma 3 has a large, 128K context window, multilingual support in over
140 languages, and is available in more sizes than previous versions. Gemma 3
models are well-suited for a variety of text generation and image understanding
tasks, including question answering, summarization, and reasoning. Their
relatively small size makes it possible to deploy them in environments with
limited resources such as laptops, desktops or your own cloud infrastructure,
democratizing access to state of the art AI models and helping foster innovation
for everyone.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Images, normalized to 896 x 896 resolution and encoded to 256 tokens
each
- Total input context of 128K tokens for the 4B, 12B, and 27B sizes, and
32K tokens for the 1B and 270M sizes.
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context up to 128K tokens for the 4B, 12B, and 27B sizes,
and 32K tokens for the 1B and 270M sizes per request, subtracting the
request input tokens
### Citation
```none
@article{gemma_2025,
title={Gemma 3},
url={https://arxiv.org/abs/2503.19786},
publisher={Google DeepMind},
author={Gemma Team},
year={2025}
}
```
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources. The 27B model was trained with 14 trillion tokens, the 12B model was
trained with 12 trillion tokens, 4B model was trained with 4 trillion tokens,
the 1B with 2 trillion tokens, and the 270M with 6 trillion tokens. The
knowledge cutoff date for the training data was August 2024. Here are the key
components:
- Web Documents: A diverse collection of web text ensures the model is
exposed to a broad range of linguistic styles, topics, and vocabulary. The
training dataset includes content in over 140 languages.
- Code: Exposing the model to code helps it to learn the syntax and
patterns of programming languages, which improves its ability to generate
code and understand code-related questions.
- Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
- Images: A wide range of images enables the model to perform image
analysis and visual data extraction tasks.
The combination of these diverse data sources is crucial for training a powerful
multimodal model that can handle a wide variety of different tasks and data
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
- CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering
was applied at multiple stages in the data preparation process to ensure
the exclusion of harmful and illegal content.
- Sensitive Data Filtering: As part of making Gemma pre-trained models
safe and reliable, automated techniques were used to filter out certain
personal information and other sensitive data from training sets.
- Additional methods: Filtering based on content quality and safety in
line with [our policies][safety-policies].
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using [Tensor Processing Unit (TPU)][tpu] hardware (TPUv4p,
TPUv5p and TPUv5e). Training vision-language models (VLMS) requires significant
computational power. TPUs, designed specifically for matrix operations common in
machine learning, offer several advantages in this domain:
- Performance: TPUs are specifically designed to handle the massive
computations involved in training VLMs. They can speed up training
considerably compared to CPUs.
- Memory: TPUs often come with large amounts of high-bandwidth memory,
allowing for the handling of large models and batch sizes during training.
This can lead to better model quality.
- Scalability: TPU Pods (large clusters of TPUs) provide a scalable
solution for handling the growing complexity of large foundation models.
You can distribute training across multiple TPU devices for faster and more
efficient processing.
- Cost-effectiveness: In many scenarios, TPUs can provide a more
cost-effective solution for training large models compared to CPU-based
infrastructure, especially when considering the time and resources saved
due to faster training.
- These advantages are aligned with
[Google's commitments to operate sustainably][sustainability].
### Software
Training was done using [JAX][jax] and [ML Pathways][ml-pathways].
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models. ML
Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
foundation models, including large language models like these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models][gemini-2-paper]; *"the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."*
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation. Evaluation results marked
with **IT** are for instruction-tuned models. Evaluation results marked with
**PT** are for pre-trained models.
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 models are multimodal, handling text and image input and generating text
output, with open weights for both pre-trained variants and instruction-tuned
variants. Gemma 3 has a large, 128K context window, multilingual support in over
140 languages, and is available in more sizes than previous versions. Gemma 3
models are well-suited for a variety of text generation and image understanding
tasks, including question answering, summarization, and reasoning. Their
relatively small size makes it possible to deploy them in environments with
limited resources such as laptops, desktops or your own cloud infrastructure,
democratizing access to state of the art AI models and helping foster innovation
for everyone.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Images, normalized to 896 x 896 resolution and encoded to 256 tokens
each, for the 4B, 12B, and 27B sizes.
- Total input context of 128K tokens for the 4B, 12B, and 27B sizes, and
32K tokens for the 1B and 270M sizes.
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context up to 128K tokens for the 4B, 12B, and 27B sizes,
and 32K tokens for the 1B and 270M sizes per request, subtracting the
request input tokens
### Citation
```none
@article{gemma_2025,
title={Gemma 3},
url={https://arxiv.org/abs/2503.19786},
publisher={Google DeepMind},
author={Gemma Team},
year={2025}
}
```
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources. The 27B model was trained with 14 trillion tokens, the 12B model was
trained with 12 trillion tokens, 4B model was trained with 4 trillion tokens,
the 1B with 2 trillion tokens, and the 270M with 6 trillion tokens. The
knowledge cutoff date for the training data was August 2024. Here are the key
components:
- Web Documents: A diverse collection of web text ensures the model is
exposed to a broad range of linguistic styles, topics, and vocabulary. The
training dataset includes content in over 140 languages.
- Code: Exposing the model to code helps it to learn the syntax and
patterns of programming languages, which improves its ability to generate
code and understand code-related questions.
- Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
- Images: A wide range of images enables the model to perform image
analysis and visual data extraction tasks.
The combination of these diverse data sources is crucial for training a powerful
multimodal model that can handle a wide variety of different tasks and data
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
- CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering
was applied at multiple stages in the data preparation process to ensure
the exclusion of harmful and illegal content.
- Sensitive Data Filtering: As part of making Gemma pre-trained models
safe and reliable, automated techniques were used to filter out certain
personal information and other sensitive data from training sets.
- Additional methods: Filtering based on content quality and safety in
line with [our policies][safety-policies].
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using [Tensor Processing Unit (TPU)][tpu] hardware (TPUv4p,
TPUv5p and TPUv5e). Training vision-language models (VLMS) requires significant
computational power. TPUs, designed specifically for matrix operations common in
machine learning, offer several advantages in this domain:
- Performance: TPUs are specifically designed to handle the massive
computations involved in training VLMs. They can speed up training
considerably compared to CPUs.
- Memory: TPUs often come with large amounts of high-bandwidth memory,
allowing for the handling of large models and batch sizes during training.
This can lead to better model quality.
- Scalability: TPU Pods (large clusters of TPUs) provide a scalable
solution for handling the growing complexity of large foundation models.
You can distribute training across multiple TPU devices for faster and more
efficient processing.
- Cost-effectiveness: In many scenarios, TPUs can provide a more
cost-effective solution for training large models compared to CPU-based
infrastructure, especially when considering the time and resources saved
due to faster training.
- These advantages are aligned with
[Google's commitments to operate sustainably][sustainability].
### Software
Training was done using [JAX][jax] and [ML Pathways][ml-pathways].
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models. ML
Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
foundation models, including large language models like these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models][gemini-2-paper]; *"the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."*
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation. Evaluation results marked
with **IT** are for instruction-tuned models. Evaluation results marked with
**PT** are for pre-trained models.
#### Gemma 3 270M
| **Benchmark** | **n-shot** | **Gemma 3 PT 270M** |
| :------------------------ | :-----------: | ------------------: |
| [HellaSwag][hellaswag] | 10-shot | 40.9 |
| [BoolQ][boolq] | 0-shot | 61.4 |
| [PIQA][piqa] | 0-shot | 67.7 |
| [TriviaQA][triviaqa] | 5-shot | 15.4 |
| [ARC-c][arc] | 25-shot | 29.0 |
| [ARC-e][arc] | 0-shot | 57.7 |
| [WinoGrande][winogrande] | 5-shot | 52.0 |
[hellaswag]: https://arxiv.org/abs/1905.07830
[boolq]: https://arxiv.org/abs/1905.10044
[piqa]: https://arxiv.org/abs/1911.11641
[triviaqa]: https://arxiv.org/abs/1705.03551
[arc]: https://arxiv.org/abs/1911.01547
[winogrande]: https://arxiv.org/abs/1907.10641
| **Benchmark** | **n-shot** | **Gemma 3 IT 270m** |
| :------------------------ | :-----------: | ------------------: |
| [HellaSwag][hellaswag] | 0-shot | 37.7 |
| [PIQA][piqa] | 0-shot | 66.2 |
| [ARC-c][arc] | 0-shot | 28.2 |
| [WinoGrande][winogrande] | 0-shot | 52.3 |
| [BIG-Bench Hard][bbh] | few-shot | 26.7 |
| [IF Eval][ifeval] | 0-shot | 51.2 |
[hellaswag]: https://arxiv.org/abs/1905.07830
[piqa]: https://arxiv.org/abs/1911.11641
[arc]: https://arxiv.org/abs/1911.01547
[winogrande]: https://arxiv.org/abs/1907.10641
[bbh]: https://paperswithcode.com/dataset/bbh
[bbh]: https://paperswithcode.com/dataset/bbh
[ifeval]: https://arxiv.org/abs/2311.07911
#### Gemma 3 1B, 4B, 12B & 27B
##### Reasoning and factuality
| Benchmark | n-shot | Gemma 3 IT 1B | Gemma 3 IT 4B | Gemma 3 IT 12B | Gemma 3 IT 27B |
|--------------------------------|--------|:-------------:|:-------------:|:--------------:|:--------------:|
| [GPQA][gpqa] Diamond | 0-shot | 19.2 | 30.8 | 40.9 | 42.4 |
| [SimpleQA][simpleqa] | 0-shot | 2.2 | 4.0 | 6.3 | 10.0 |
| [FACTS Grounding][facts-grdg] | - | 36.4 | 70.1 | 75.8 | 74.9 |
| [BIG-Bench Hard][bbh] | 0-shot | 39.1 | 72.2 | 85.7 | 87.6 |
| [BIG-Bench Extra Hard][bbeh] | 0-shot | 7.2 | 11.0 | 16.3 | 19.3 |
| [IFEval][ifeval] | 0-shot | 80.2 | 90.2 | 88.9 | 90.4 |
| Benchmark | n-shot | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------|:--------------:|:-------------:|:--------------:|:--------------:|
| [HellaSwag][hellaswag] | 10-shot | 62.3 | 77.2 | 84.2 | 85.6 |
| [BoolQ][boolq] | 0-shot | 63.2 | 72.3 | 78.8 | 82.4 |
| [PIQA][piqa] | 0-shot | 73.8 | 79.6 | 81.8 | 83.3 |
| [SocialIQA][socialiqa] | 0-shot | 48.9 | 51.9 | 53.4 | 54.9 |
| [TriviaQA][triviaqa] | 5-shot | 39.8 | 65.8 | 78.2 | 85.5 |
| [Natural Questions][naturalq] | 5-shot | 9.48 | 20.0 | 31.4 | 36.1 |
| [ARC-c][arc] | 25-shot | 38.4 | 56.2 | 68.9 | 70.6 |
| [ARC-e][arc] | 0-shot | 73.0 | 82.4 | 88.3 | 89.0 |
| [WinoGrande][winogrande] | 5-shot | 58.2 | 64.7 | 74.3 | 78.8 |
| [BIG-Bench Hard][bbh] | few-shot | 28.4 | 50.9 | 72.6 | 77.7 |
| [DROP][drop] | 1-shot | 42.4 | 60.1 | 72.2 | 77.2 |
[gpqa]: https://arxiv.org/abs/2311.12022
[simpleqa]: https://arxiv.org/abs/2411.04368
[facts-grdg]: https://goo.gle/FACTS_paper
[bbeh]: https://github.com/google-deepmind/bbeh
[ifeval]: https://arxiv.org/abs/2311.07911
[hellaswag]: https://arxiv.org/abs/1905.07830
[boolq]: https://arxiv.org/abs/1905.10044
[piqa]: https://arxiv.org/abs/1911.11641
[socialiqa]: https://arxiv.org/abs/1904.09728
[triviaqa]: https://arxiv.org/abs/1705.03551
[naturalq]: https://github.com/google-research-datasets/natural-questions
[arc]: https://arxiv.org/abs/1911.01547
[winogrande]: https://arxiv.org/abs/1907.10641
[bbh]: https://paperswithcode.com/dataset/bbh
[drop]: https://arxiv.org/abs/1903.00161
##### STEM and code
| Benchmark | n-shot | Gemma 3 IT 1B | Gemma 3 IT 4B | Gemma 3 IT 12B | Gemma 3 IT 27B |
|----------------------------|--------|:-------------:|:-------------:|:--------------:|:--------------:|
| [MMLU][mmlu] (Pro) | 0-shot | 14.7 | 43.6 | 60.6 | 67.5 |
| [LiveCodeBench][lcb] | 0-shot | 1.9 | 12.6 | 24.6 | 29.7 |
| [Bird-SQL][bird-sql] (dev) | - | 6.4 | 36.3 | 47.9 | 54.4 |
| [Math][math] | 0-shot | 48.0 | 75.6 | 83.8 | 89.0 |
| HiddenMath | 0-shot | 15.8 | 43.0 | 54.5 | 60.3 |
| [MBPP][mbpp] | 3-shot | 35.2 | 63.2 | 73.0 | 74.4 |
| [HumanEval][humaneval] | 0-shot | 41.5 | 71.3 | 85.4 | 87.8 |
| [Natural2Code][nat2code] | 0-shot | 56.0 | 70.3 | 80.7 | 84.5 |
| [GSM8K][gsm8k] | 0-shot | 62.8 | 89.2 | 94.4 | 95.9 |
| Benchmark | n-shot | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------------|:-------------:|:--------------:|:--------------:|
| [MMLU][mmlu] | 5-shot | 59.6 | 74.5 | 78.6 |
| [MMLU][mmlu] (Pro COT) | 5-shot | 29.2 | 45.3 | 52.2 |
| [AGIEval][agieval] | 3-5-shot | 42.1 | 57.4 | 66.2 |
| [MATH][math] | 4-shot | 24.2 | 43.3 | 50.0 |
| [GSM8K][gsm8k] | 8-shot | 38.4 | 71.0 | 82.6 |
| [GPQA][gpqa] | 5-shot | 15.0 | 25.4 | 24.3 |
| [MBPP][mbpp] | 3-shot | 46.0 | 60.4 | 65.6 |
| [HumanEval][humaneval] | 0-shot | 36.0 | 45.7 | 48.8 |
[mmlu]: https://arxiv.org/abs/2009.03300
[agieval]: https://arxiv.org/abs/2304.06364
[math]: https://arxiv.org/abs/2103.03874
[gsm8k]: https://arxiv.org/abs/2110.14168
[gpqa]: https://arxiv.org/abs/2311.12022
[mbpp]: https://arxiv.org/abs/2108.07732
[humaneval]: https://arxiv.org/abs/2107.03374
[lcb]: https://arxiv.org/abs/2403.07974
[bird-sql]: https://arxiv.org/abs/2305.03111
[nat2code]: https://arxiv.org/abs/2405.04520
#### Multilingual
| Benchmark | n-shot | Gemma 3 IT 1B | Gemma 3 IT 4B | Gemma 3 IT 12B | Gemma 3 IT 27B |
|--------------------------------------|--------|:-------------:|:-------------:|:--------------:|:--------------:|
| [Global-MMLU-Lite][global-mmlu-lite] | 0-shot | 34.2 | 54.5 | 69.5 | 75.1 |
| [ECLeKTic][eclektic] | 0-shot | 1.4 | 4.6 | 10.3 | 16.7 |
| [WMT24++][wmt24pp] | 0-shot | 35.9 | 46.8 | 51.6 | 53.4 |
| Benchmark | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------------ |:-------------:|:-------------:|:--------------:|:--------------:|
| [MGSM][mgsm] | 2.04 | 34.7 | 64.3 | 74.3 |
| [Global-MMLU-Lite][global-mmlu-lite] | 24.9 | 57.0 | 69.4 | 75.7 |
| [WMT24++][wmt24pp] (ChrF) | 36.7 | 48.4 | 53.9 | 55.7 |
| [FloRes][flores] | 29.5 | 39.2 | 46.0 | 48.8 |
| [XQuAD][xquad] (all) | 43.9 | 68.0 | 74.5 | 76.8 |
| [ECLeKTic][eclektic] | 4.69 | 11.0 | 17.2 | 24.4 |
| [IndicGenBench][indicgenbench] | 41.4 | 57.2 | 61.7 | 63.4 |
[mgsm]: https://arxiv.org/abs/2210.03057
[flores]: https://arxiv.org/abs/2106.03193
[xquad]: https://arxiv.org/abs/1910.11856v3
[global-mmlu-lite]: https://huggingface.co/datasets/CohereForAI/Global-MMLU-Lite
[wmt24pp]: https://arxiv.org/abs/2502.12404v1
[eclektic]: https://arxiv.org/abs/2502.21228
[indicgenbench]: https://arxiv.org/abs/2404.16816
##### Multimodal
| Benchmark | Gemma 3 IT 4B | Gemma 3 IT 12B | Gemma 3 IT 27B |
|-----------------------------------|:-------------:|:--------------:|:--------------:|
| [MMMU][mmmu] (val) | 48.8 | 59.6 | 64.9 |
| [DocVQA][docvqa] | 75.8 | 87.1 | 86.6 |
| [InfoVQA][info-vqa] | 50.0 | 64.9 | 70.6 |
| [TextVQA][textvqa] | 57.8 | 67.7 | 65.1 |
| [AI2D][ai2d] | 74.8 | 84.2 | 84.5 |
| [ChartQA][chartqa] | 68.8 | 75.7 | 78.0 |
| [VQAv2][vqav2] (val) | 62.4 | 71.6 | 71.0 |
| [MathVista][mathvista] (testmini) | 50.0 | 62.9 | 67.6 |
| Benchmark | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |:-------------:|:--------------:|:--------------:|
| [COCOcap][coco-cap] | 102 | 111 | 116 |
| [DocVQA][docvqa] (val) | 72.8 | 82.3 | 85.6 |
| [InfoVQA][info-vqa] (val) | 44.1 | 54.8 | 59.4 |
| [MMMU][mmmu] (pt) | 39.2 | 50.3 | 56.1 |
| [TextVQA][textvqa] (val) | 58.9 | 66.5 | 68.6 |
| [RealWorldQA][realworldqa] | 45.5 | 52.2 | 53.9 |
| [ReMI][remi] | 27.3 | 38.5 | 44.8 |
| [AI2D][ai2d] | 63.2 | 75.2 | 79.0 |
| [ChartQA][chartqa] | 63.6 | 74.7 | 76.3 |
| [VQAv2][vqav2] | 63.9 | 71.2 | 72.9 |
| [BLINK][blinkvqa] | 38.0 | 35.9 | 39.6 |
| [OKVQA][okvqa] | 51.0 | 58.7 | 60.2 |
| [TallyQA][tallyqa] | 42.5 | 51.8 | 54.3 |
| [SpatialSense VQA][ss-vqa] | 50.9 | 60.0 | 59.4 |
| [CountBenchQA][countbenchqa] | 26.1 | 17.8 | 68.0 |
[coco-cap]: https://cocodataset.org/#home
[docvqa]: https://www.docvqa.org/
[info-vqa]: https://arxiv.org/abs/2104.12756
[mmmu]: https://arxiv.org/abs/2311.16502
[textvqa]: https://textvqa.org/
[realworldqa]: https://paperswithcode.com/dataset/realworldqa
[remi]: https://arxiv.org/html/2406.09175v1
[ai2d]: https://allenai.org/data/diagrams
[chartqa]: https://arxiv.org/abs/2203.10244
[vqav2]: https://visualqa.org/index.html
[blinkvqa]: https://arxiv.org/abs/2404.12390
[okvqa]: https://okvqa.allenai.org/
[tallyqa]: https://arxiv.org/abs/1810.12440
[ss-vqa]: https://arxiv.org/abs/1908.02660
[countbenchqa]: https://github.com/google-research/big_vision/blob/main/big_vision/datasets/countbenchqa/
[mathvista]: https://arxiv.org/abs/2310.02255
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
- **Child Safety**: Evaluation of text-to-text and image to text prompts
covering child safety policies, including child sexual abuse and
exploitation.
- **Content Safety:** Evaluation of text-to-text and image to text prompts
covering safety policies including, harassment, violence and gore, and hate
speech.
- **Representational Harms**: Evaluation of text-to-text and image to text
prompts covering safety policies including bias, stereotyping, and harmful
associations or inaccuracies.
In addition to development level evaluations, we conduct "assurance
evaluations" which are our 'arms-length' internal evaluations for responsibility
governance decision making. They are conducted separately from the model
development team, to inform decision making about release. High level findings
are fed back to the model team, but prompt sets are held-out to prevent
overfitting and preserve the results' ability to inform decision making.
Assurance evaluation results are reported to our Responsibility & Safety Council
as part of release review.
### Evaluation Results
For all areas of safety testing, we saw major improvements in the categories of
child safety, content safety, and representational harms relative to previous
Gemma models. All testing was conducted without safety filters to evaluate the
model capabilities and behaviors. For both text-to-text and image-to-text, and
across all model sizes, the model produced minimal policy violations, and showed
significant improvements over previous Gemma models' performance with respect
to ungrounded inferences. A limitation of our evaluations was they included only
English language prompts.
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open vision-language models (VLMs) models have a wide range of applications
across various industries and domains. The following list of potential uses is
not comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
- Content Creation and Communication
- Text Generation: These models can be used to generate creative text
formats such as poems, scripts, code, marketing copy, and email drafts.
- Chatbots and Conversational AI: Power conversational interfaces
for customer service, virtual assistants, or interactive applications.
- Text Summarization: Generate concise summaries of a text corpus,
research papers, or reports.
- Image Data Extraction: These models can be used to extract,
interpret, and summarize visual data for text communications.
- Research and Education
- Natural Language Processing (NLP) and VLM Research: These
models can serve as a foundation for researchers to experiment with VLM
and NLP techniques, develop algorithms, and contribute to the
advancement of the field.
- Language Learning Tools: Support interactive language learning
experiences, aiding in grammar correction or providing writing practice.
- Knowledge Exploration: Assist researchers in exploring large
bodies of text by generating summaries or answering questions about
specific topics.
### Limitations
- Training Data
- The quality and diversity of the training data significantly
influence the model's capabilities. Biases or gaps in the training data
can lead to limitations in the model's responses.
- The scope of the training dataset determines the subject areas
the model can handle effectively.
- Context and Task Complexity
- Models are better at tasks that can be framed with clear
prompts and instructions. Open-ended or highly complex tasks might be
challenging.
- A model's performance can be influenced by the amount of context
provided (longer context generally leads to better outputs, up to a
certain point).
- Language Ambiguity and Nuance
- Natural language is inherently complex. Models might struggle
to grasp subtle nuances, sarcasm, or figurative language.
- Factual Accuracy
- Models generate responses based on information they learned
from their training datasets, but they are not knowledge bases. They
may generate incorrect or outdated factual statements.
- Common Sense
- Models rely on statistical patterns in language. They might
lack the ability to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of vision-language models (VLMs) raises several ethical
concerns. In creating an open model, we have carefully considered the following:
- Bias and Fairness
- VLMs trained on large-scale, real-world text and image data can
reflect socio-cultural biases embedded in the training material. These
models underwent careful scrutiny, input data pre-processing described
and posterior evaluations reported in this card.
- Misinformation and Misuse
- VLMs can be misused to generate text that is false, misleading,
or harmful.
- Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit][rai-toolkit].
- Transparency and Accountability:
- This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
- A responsibly developed open model offers the opportunity to
share innovation by making VLM technology accessible to developers and
researchers across the AI ecosystem.
Risks identified and mitigations:
- **Perpetuation of biases**: It's encouraged to perform continuous
monitoring (using evaluation metrics, human review) and the exploration of
de-biasing techniques during model training, fine-tuning, and other use
cases.
- **Generation of harmful content**: Mechanisms and guidelines for content
safety are essential. Developers are encouraged to exercise caution and
implement appropriate content safety safeguards based on their specific
product policies and application use cases.
- **Misuse for malicious purposes**: Technical limitations and developer
and end-user education can help mitigate against malicious applications of
VLMs. Educational resources and reporting mechanisms for users to flag
misuse are provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy][prohibited-use].
- **Privacy violations**: Models were trained on data filtered for removal
of certain personal information and other sensitive data. Developers are
encouraged to adhere to privacy regulations with privacy-preserving
techniques.
### Benefits
At the time of release, this family of models provides high-performance open
vision-language model implementations designed from the ground up for
responsible AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
[g3-tech-report]: https://arxiv.org/abs/2503.19786
[rai-toolkit]: https://ai.google.dev/responsible
[kaggle-gemma]: https://www.kaggle.com/models/google/gemma-3
[vertex-mg-gemma3]: https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3
[terms]: https://ai.google.dev/gemma/terms
[safety-policies]: https://ai.google/static/documents/ai-responsibility-update-published-february-2025.pdf
[prohibited-use]: https://ai.google.dev/gemma/prohibited_use_policy
[tpu]: https://cloud.google.com/tpu/docs/intro-to-tpu
[sustainability]: https://sustainability.google/operating-sustainably/
[jax]: https://github.com/jax-ml/jax
[ml-pathways]: https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[sustainability]: https://sustainability.google/operating-sustainably/
[gemini-2-paper]: https://arxiv.org/abs/2312.11805
|
[
"Monster/gemma-3-270m-it",
"broadfield-dev/gemma-3-270m-it-unsloth-demo",
"cwadayi/gemma-3-270m-it",
"lemonteaa/edge_llm_chat",
"lyangas/free_llm_structure_output_docker",
"SiddhJagani/gemma-3",
"Dagriffpatchfan/5000tokens-1"
] |
[
"gemma"
] | null | null | null | 268,098,176
|
[
null,
"text-generation"
] | null |
[
"AutoModel",
"gemma3"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
689d3c56e7b7e599336b0fca
|
nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base
|
nvidia
| null | 2,085
| 2,085
|
False
| 2025-08-14T01:31:02Z
| 2025-08-26T22:17:12Z
|
transformers
| 73
| 12
| null |
text-generation
|
{"parameters": {"BF16": 12310001152}, "total": 12310001152}
|
[
".gitattributes",
"README.md",
"bias.md",
"config.json",
"configuration_nemotron_h.py",
"explainability.md",
"generation_config.json",
"model-00001-of-00006.safetensors",
"model-00002-of-00006.safetensors",
"model-00003-of-00006.safetensors",
"model-00004-of-00006.safetensors",
"model-00005-of-00006.safetensors",
"model-00006-of-00006.safetensors",
"model.safetensors.index.json",
"modeling_nemotron_h.py",
"privacy.md",
"safety.md",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1570,
27421,
2208,
1562,
12176,
2689,
132,
4830843560,
4874263544,
4790388152,
4874398064,
3907972648,
1342177408,
29117,
78798,
2296,
2094,
414,
17078330,
177172
] | 24,637,459,355
|
6d4bf47647294eb572daa82b7c5711163c26b200
|
[
"transformers",
"safetensors",
"nvidia",
"pytorch",
"text-generation",
"en",
"es",
"fr",
"de",
"ja",
"it",
"pt",
"zh",
"ar",
"da",
"ko",
"nl",
"pl",
"ru",
"sv",
"th",
"dataset:nvidia/Nemotron-Pretraining-Dataset-sample",
"dataset:nvidia/Nemotron-CC-v2",
"dataset:nvidia/Nemotron-CC-Math-v1",
"dataset:nvidia/Nemotron-Pretraining-Code-v1",
"dataset:nvidia/Nemotron-Pretraining-SFT-v1",
"arxiv:2508.14444",
"license:other",
"endpoints_compatible",
"region:us"
] | null |
# NVIDIA-Nemotron-Nano-12B-v2-Base
**Model Developer:** NVIDIA Corporation
**Model Dates:**
June 2025 \- August 2025
**Data Freshness:**
May 1, 2025
The pretraining data has a cutoff date of May 1, 2025\.
## Model Overview
## Description
NVIDIA-Nemotron-Nano-12B-v2-Base is a large language model (LLM) developed by NVIDIA that is designed as a completion model for a given piece of text. It uses a hybrid model architecture that consists primarily of Mamba-2 and MLP layers with just six Attention layers. The model features a context length of 128K. The supported languages include: English, Spanish, French, German, Japanese, Italian, Portuguese, Chinese, Arabic, Danish, Korean, Dutch, Polish, Russian, Swedish, and Thai. Improved using Qwen.
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/).
### Deployment Geography: Global
### Use Case
This model is intended for developers and researchers building LLMs.
### Release Date: 08/18/2025
Hugging Face 08/18/2025 via [https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base](https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-12B-v2-Base)
## Reference(s)
[NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model](https://arxiv.org/abs/2508.14444)
## Model Architecture
- **Architecture Type:** Mamba2-Transformer Hybrid
- **Network Architecture:** Nemotron-Hybrid
- **Number of model parameters:** *12.31B*
## Model design
The model was trained with 20T tokens, with a batch size of 736, and used the Warmup-Stable-Decay (WSD) learning rate schedule with 8B tokens of learning rate warm up, peak learning rate of 4.5e-4 and minimum learning rate of 4.5e-6. There are a total of 62 layers, of which there are 28 of each MLP and Mamba-2, the remaining layers use GQA with 8 groups
## Input
- **Input Type(s):** Text
- **Input Format(s):** String
- **Input Parameters:** One-Dimensional (1D): Sequences
- **Maximum input size:** 128K tokens
- **Other Properties Related to Input:** Supported languages include English, Spanish, French, German, Japanese, Italian, Portuguese, Chinese, Arabic, Danish, Korean, Dutch, Polish, Russian, Swedish, Thai.
## Output
- **Output Type(s):** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D): Sequences
- **Maximum output size:** 128K tokens
Our AI models are designed and optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## Software Integration
- Runtime Engine(s): NeMo 25.07.nemotron-nano-v2
- Supported Hardware Microarchitecture Compatibility: NVIDIA H100-80GB, NVIDIA A100
- Operating System(s): Linux
The integration of foundation and fine-tuned models into AI systems requires additional testing using use-case-specific data to ensure safe and effective deployment. Following the V-model methodology, iterative testing and validation at both unit and system levels are essential to mitigate risks, meet technical and functional requirements, and ensure compliance with safety and ethical standards before deployment.
## Model Version(s)
- v1.0
# Training, Testing, and Evaluation Datasets:
NVIDIA-Nemotron-Nano-12B-v2-Base is pre-trained on a large corpus of high-quality curated and synthetically-generated data. It is trained in the English language, as well as 15 multilingual languages and 43 programming languages. Our sources cover a variety of document types such as: webpages, dialogue, articles, and other written materials. The corpus spans domains including legal, math, science, finance, and more. We also include a small portion of question-answering, and alignment style data to improve model accuracy. The model was trained for approximately twenty trillion tokens.
Alongside the model, we release our [final pretraining data](https://huggingface.co/collections/nvidia/nemotron-pre-training-dataset-689d9de36f84279d83786b35), as outlined in this section. For ease of analysis, there is a sample set that is ungated. For all remaining code, math and multilingual data, gating and approval is required, and the dataset is permissively licensed for model training purposes
**Data Modality:** Text **The total size:** 10,648,823,153,919 Tokens **Total number of datasets:** 141 **Dataset partition:** *Training \[100%\], testing \[0%\], validation \[0%\]*
**Time period for training data collection:** 2013 to May 1, 2025
**Time period for testing data collection:** 2013 to May 1, 2025
**Time period for validation data collection:** 2013 to May 1, 2025
More details on the datasets and synthetic data generation methods can be found in the technical report [NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model](https://arxiv.org/abs/2508.14444).
| Dataset | Collection Period |
| :---- | :---- |
| [GSM8K](https://github.com/openai/grade-school-math) | 4/23/2025 |
| [CC-NEWS](https://commoncrawl.org/blog/news-dataset-available) | 4/23/2025 |
| [Common Crawl](https://commoncrawl.org/) | 4/23/2025 |
| [Wikimedia](https://dumps.wikimedia.org/) | 4/23/2025 |
| [Bespoke-Stratos-17k](https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k) | 4/23/2025 |
| [tigerbot-kaggle-leetcodesolutions-en-2k](https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k) | 4/23/2025 |
| [glaive-function-calling-v2](https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2) | 4/23/2025 |
| [APIGen Function-Calling](https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k) | 4/23/2025 |
| [LMSYS-Chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) | 4/23/2025 |
| [Open Textbook Library \- CC BY-SA & GNU subset](https://open.umn.edu/opentextbooks/textbooks/) and [OpenStax \- CC BY-SA subset](https://openstax.org/) | 4/23/2025 |
| [Advanced Reasoning Benchmark](https://github.com/TheDuckAI/arb), [tigerbot-kaggle-leetcodesolutions-en-2k](https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k), [PRM800K](https://github.com/openai/prm800k), and [SciBench](https://github.com/mandyyyyii/scibench) | 4/23/2025 |
| [FineWeb-2](https://huggingface.co/datasets/HuggingFaceFW/fineweb-2) | 4/23/2025 |
| [Court Listener](https://www.courtlistener.com/help/api/bulk-data/) | Legacy Download |
| [peS2o](https://huggingface.co/datasets/allenai/peS2o) | Legacy Download |
| [OpenWebMath](https://huggingface.co/datasets/open-web-math/open-web-math) | Legacy Download |
| [BioRxiv](https://www.biorxiv.org/tdm) | Legacy Download |
| [PMC Open Access Subset](https://pmc.ncbi.nlm.nih.gov/tools/openftlist/) | Legacy Download |
| [OpenWebText2](https://openwebtext2.readthedocs.io/en/latest/) | Legacy Download |
| [Stack Exchange Data Dump](https://archive.org/details/stackexchange) | Legacy Download |
| [PubMed Abstracts](https://github.com/thoppe/The-Pile-PubMed) | Legacy Download |
| [NIH ExPorter](https://exporter.nih.gov/ExPORTER_Catalog.aspx) | Legacy Download |
| [arXiv](https://info.arxiv.org/help/bulk_data/index.html) | Legacy Download |
| [BigScience Workshop Datasets](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml#datasets) | Legacy Download |
| [Reddit Dataset](https://files.pushshift.io/reddit/) | Legacy Download |
| [SEC's Electronic Data Gathering, Analysis, and Retrieval (EDGAR)](https://www.sec.gov/search-filings) | Legacy Download |
| [Advanced Mathematical Problem Solving](https://github.com/hendrycks/math?tab=readme-ov-file) | Legacy Download |
| [MathPile](https://github.com/GAIR-NLP/MathPile/) | Legacy Download |
| [NuminaMath CoT](https://huggingface.co/datasets/AI-MO/NuminaMath-CoT) | Legacy Download |
| [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/) | Legacy Download |
| [FLAN](https://github.com/google-research/FLAN) | Legacy Download |
| [Advanced Reasoning Benchmark](https://github.com/TheDuckAI/arb) | Legacy Download |
| [SciBench](https://github.com/mandyyyyii/scibench) | Legacy Download |
| [WikiTableQuestions](https://huggingface.co/datasets/wikitablequestions) | Legacy Download |
| [FinQA](https://finqasite.github.io/) | Legacy Download |
| [Riddles](https://github.com/crawsome/riddles) | Legacy Download |
| [Problems in Elementary Mathematics for Home Study](https://archive.org/details/AntonovVygodskyNikitinSankinProblemsInElementaryMathematicsForHomeStudyMir1982) | Legacy Download |
| [MedMCQA](https://huggingface.co/datasets/openlifescienceai/medmcqa) | Legacy Download |
| [Cosmos QA](https://huggingface.co/datasets/allenai/cosmos_qa) | Legacy Download |
| [MCTest](https://huggingface.co/datasets/sagnikrayc/mctest) | Legacy Download |
| [AI2's Reasoning Challenge](https://huggingface.co/datasets/ai2_arc) | Legacy Download |
| [OpenBookQA](https://github.com/allenai/OpenBookQA) | Legacy Download |
| [MMLU Auxiliary Train](https://huggingface.co/datasets/cais/mmlu/viewer/all/auxiliary_train) | Legacy Download |
| [social-chemestry-101](https://huggingface.co/datasets/tasksource/social-chemestry-101) | Legacy Download |
| [Moral Stories](https://huggingface.co/datasets/demelin/moral_stories) | Legacy Download |
| [The Common Pile v0.1](https://huggingface.co/common-pile) | Legacy Download |
| [FineMath](https://huggingface.co/datasets/HuggingFaceTB/finemath) | Legacy Download |
| [MegaMath](https://huggingface.co/datasets/LLM360/MegaMath) | Legacy Download |
## Private Non-publicly Accessible Datasets of Third Parties
| Dataset |
| :---- |
| Global Regulation |
## Crawled and Scraped from Online Sources by NVIDIA
The English Common Crawl data was downloaded from the Common Crawl Foundation (see their FAQ for details on their crawling) and includes the snapshots CC-MAIN-2013-20 through CC-MAIN-2025-13. The data was subsequently deduplicated and filtered in various ways described in the Nemotron-CC paper. Additionally, we extracted data for fifteen languages from the following three Common Crawl snapshots: CC-MAIN-2024-51, CC-MAIN-2025-08, CC-MAIN-2025-18. The fifteen languages included were Arabic, Chinese, Danish, Dutch, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Swedish, and Thai. As we did not have reliable multilingual model-based quality classifiers available, we applied just heuristic filtering instead—similar to what we did for lower quality English data in the Nemotron-CC pipeline, but selectively removing some filters for some languages that did not work well. Deduplication was done in the same way as for Nemotron-CC.
The GitHub Crawl was collected using the GitHub REST API and the Amazon S3 API. Each crawl was operated in accordance with the rate limits set by its respective source, either GitHub or S3. We collect raw source code and subsequently remove any having a license which does not exist in our permissive-license set (for additional details, refer to the technical report).
| Dataset | Modality | Dataset Size | Collection Period | Collecting Organisation |
| :---- | :---- | :---- | :---- | :---- |
| English Common Crawl | Text | 3.36T | 4/8/2025 | NVIDIA Advanced Deep Learning Research |
| Multilingual Common Crawl | Text | 812.7B | 5/1/2025 | NVIDIA Advanced Deep Learning Research |
| GitHub Crawl | Text | 747.4B | 4/29/2025 | NVIDIA Advanced Deep Learning Research |
## NVIDIA-Sourced Synthetic Datasets
| Dataset | Modality | Dataset Size | Seed Dataset | Model(s) used for generation |
| :---- | :---- | :---- | :---- | :---- |
| Synthetic Art of Problem Solving from DeepSeek-R1 | Text | 40086030608 | [Art of Problem Solving](https://artofproblemsolving.com/company); [American Mathematics Competitions 8](https://artofproblemsolving.com/wiki/index.php/AMC_8_Problems_and_Solutions); [American Mathematics Competitions 10](https://artofproblemsolving.com/wiki/index.php/AMC_10_Problems_and_Solutions); | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
| Synthetic Moral Stories and Social Chemistry from Mixtral-8x22B-v0.1 | Text | 327M | [social-chemestry-101](https://huggingface.co/datasets/tasksource/social-chemestry-101); [Moral Stories](https://huggingface.co/datasets/demelin/moral_stories) | [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1) |
| Synthetic Social Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 83.6M | [OpenStax \- CC BY-SA subset](https://openstax.org/) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| Synthetic Health Sciences seeded with OpenStax from DeepSeek-V3, Mixtral-8x22B-v0.1, and Qwen2.5-72B | Text | 9.7M | [OpenStax \- CC BY-SA subset](https://openstax.org/) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [Mixtral-8x22B-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| Synthetic STEM seeded with OpenStax, Open Textbook Library, and GSM8K from DeepSeek-R1, DeepSeek-V3, DeepSeek-V3-0324, and Qwen2.5-72B | Text | 175M | [OpenStax \- CC BY-SA subset](https://openstax.org/); [GSM8K](https://github.com/openai/grade-school-math); [Open Textbook Library \- CC BY-SA & GNU subset](https://open.umn.edu/opentextbooks/textbooks/) | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1), [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [DeepSeek-V3-0324](https://huggingface.co/deepseek-ai/DeepSeek-V3-0324); [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) |
| [Nemotron-PrismMath](https://huggingface.co/datasets/nvidia/Nemotron-PrismMath) | Text | 4.6B | [Big-Math-RL-Verified](https://huggingface.co/datasets/SynthLabsAI/Big-Math-RL-Verified); [OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) | [Qwen2.5-0.5B-instruct](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct), [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct); [DeepSeek-R1-Distill-Qwen-32B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| Synthetic Question Answering Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | 350M | [arXiv](https://info.arxiv.org/help/bulk_data/index.html); [National Institutes of Health ExPorter](https://www.nih.gov/); [BioRxiv](https://www.biorxiv.org/tdm); [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/); [USPTO Backgrounds](https://data.uspto.gov/apis/transition-guide/bdss#pats); [peS2o](https://huggingface.co/datasets/allenai/peS2o); Global Regulation; [CORE](https://core.ac.uk/documentation/dataset); [PG-19](https://github.com/google-deepmind/pg19); [DOAB CC BY & CC BY-SA subset](https://www.doabooks.org/en); [NDLTD](https://ndltd.org/thesis-resources/global-etd-search/) | [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Refreshed [Nemotron-MIND](https://huggingface.co/datasets/nvidia/Nemotron-MIND) from phi-4 | Text | 73B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| nv-cc-math-45-jun2025 | Text | 52.3B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3) |
| nv-cc-math-3-jun2025 | Text | 80.9B | [Common Crawl](https://commoncrawl.org/latest-crawl) | [phi-4](https://huggingface.co/microsoft/phi-4) |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from DeepSeek-V3 and DeepSeek-V3-0324 | Text | 4.0B | [AQUA-RAT](https://huggingface.co/datasets/deepmind/aqua_rat); [LogiQA](https://huggingface.co/datasets/lucasmccabe/logiqa); [AR-LSAT](https://github.com/zhongwanjun/AR-LSAT) | [DeepSeek-V3](https://huggingface.co/deepseek-ai/DeepSeek-V3); [DeepSeek-V3-0324](https://huggingface.co/deepseek-ai/DeepSeek-V3-0324) |
| Synthetic AGIEval seeded with AQUA-RAT, LogiQA, and AR-LSAT from Qwen3-30B-A3B | Text | 4.2B | [AQUA-RAT](https://huggingface.co/datasets/deepmind/aqua_rat); [LogiQA](https://huggingface.co/datasets/lucasmccabe/logiqa); [AR-LSAT](https://github.com/zhongwanjun/AR-LSAT) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic Art of Problem Solving from Qwen2.5-32B-Instruct, Qwen2.5-Math-72B, Qwen2.5-Math-7B, and Qwen2.5-72B-Instruct | Text | | [Art of Problem Solving](https://artofproblemsolving.com/company); [American Mathematics Competitions 8](https://artofproblemsolving.com/wiki/index.php/AMC_8_Problems_and_Solutions); [American Mathematics Competitions 10](https://artofproblemsolving.com/wiki/index.php/AMC_10_Problems_and_Solutions); [GSM8K](https://github.com/openai/grade-school-math); [PRM800K](https://github.com/openai/prm800k) | [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct); [Qwen2.5-Math-72B](https://huggingface.co/Qwen/Qwen2.5-Math-72B); [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B); [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Synthetic MMLU Auxiliary Train from DeepSeek-R1 | Text | 0.5B | [MMLU Auxiliary Train](https://huggingface.co/datasets/cais/mmlu/viewer/all/auxiliary_train) | [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
| Synthetic Long Context Continued Post-Training Data from Papers and Permissible Books from Qwen2.5-72B-Instruct | Text | | [arXiv](https://info.arxiv.org/help/bulk_data/index.html); [National Institutes of Health ExPorter](https://www.nih.gov/); [BioRxiv](https://www.biorxiv.org/tdm); [PMC Article](https://pmc.ncbi.nlm.nih.gov/tools/textmining/); [USPTO Backgrounds](https://data.uspto.gov/apis/transition-guide/bdss#pats); [peS2o](https://huggingface.co/datasets/allenai/peS2o); Global Regulation; [CORE](https://core.ac.uk/documentation/dataset); [PG-19](https://github.com/google-deepmind/pg19); [DOAB CC BY & CC BY-SA subset](https://www.doabooks.org/en); [NDLTD](https://ndltd.org/thesis-resources/global-etd-search/) | [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) |
| Synthetic Common Crawl from Qwen3-30B-A3B and Mistral-Nemo-12B-Instruct | Text | 415.8B | [Common Crawl](https://commoncrawl.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B); [Mistral-NeMo-12B-Instruct](https://huggingface.co/nvidia/Mistral-NeMo-12B-Instruct) |
| Synthetic Multilingual Data from Common Crawl from Qwen3-30B-A3B | Text | | [Common Crawl](https://commoncrawl.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic Multilingual Data from Wikimedia from Qwen3-30B-A3B | Text | | [Wikimedia](https://dumps.wikimedia.org/) | [Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) |
| Synthetic Math Data from Wikimedia from Nemotron-4-340B-Instruct | Text | | \- | [Nemotron-4-340B-Instruct](https://huggingface.co/nvidia/Nemotron-4-340B-Instruct) |
## Training Dataset :
| Dataset | \# Tokens |
| :---- | :---- |
| English Common Crawl | 3,360,110,334,818 |
| English Synthetic CC | 1,949,464,641,123 |
| Crawl++ | 360,389,153,262 |
| Math | 124,606,230,663 |
| Synthetic Math | 73,007,767,155 |
| Code | 747,409,228,724 |
| Synthetic Code | 175,067,553,293 |
| English Wiki | 17,349,266,926 |
| Books | 0 |
| Papers | 191,586,493,365 |
| PDF-to-text | 141,096,578,533 |
| Code SFT | 60,025,726,817 |
| STEM SFT | 272,680,426,295 |
| General SFT | 6,057,478,645 |
| Multilingual | 2,172,261,909,350 |
| Synthetic multilingual | 997,710,364,950 |
| Total | 10,648,823,153,919 |
We use a considerable amount of synthetic data. Out of 10.6 trillion tokens, 3,534,013,958,278 tokens are synthetically generated.
We extracted data for fifteen languages from the following three Common Crawl snapshots: CC-MAIN-2024-51, CC-MAIN-2025-08, CC-MAIN-2025-18. The fifteen languages included were Arabic, Chinese, Danish, Dutch, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Swedish, and Thai. As we did not have reliable multilingual model-based quality classifiers available, we applied just heuristic filtering instead—similar to what we did for lower quality English data in the Nemotron-CC pipeline, but selectively removing some filters for some languages that did not work well. Deduplication was done in the same way as for Nemotron-CC. Additionally, we used data from Wikipedia and FineWeb-2 (Penedo et al., 2025\) for these fifteen languages.
| Language | Total Tokens |
| :---- | :---- |
| Arabic | 118,056,362,726 |
| Danish | 117,747,321,618 |
| German | 146,613,691,781 |
| Spanish | 469,156,575,409 |
| French | 139,982,002,289 |
| Italian | 298,858,370,174 |
| Japanese | 682,755,693,336 |
| Korean | 127,099,747,538 |
| Dutch | 89,041,592,681 |
| Polish | 105,356,493,147 |
| Portuguese | 243,249,275,089 |
| Russian | 185,314,014,057 |
| Swedish | 74,954,953,299 |
| Thai | 160,778,944,467 |
| Chinese | 211,007,236,689 |
We collect a total of 922,476,782,017 tokens of code in 43 different languages.
| Language | Tokens |
| :---- | :---- |
| Assembly | 750,628,764 |
| C | 42,657,300,868 |
| C\# | 56,153,329,307 |
| C++ | 67,773,701,658 |
| CommonLisp | 263,234,672 |
| CSS | 38,848,760,035 |
| Cuda | 400,222,993 |
| Dart | 3,816,960,470 |
| Dockerfile | 474,958,084 |
| Fortran | 1,105,049,387 |
| Go | 8,332,419,480 |
| Haskell | 1,294,613,669 |
| HTML | 69,082,117,487 |
| Java | 131,440,465,822 |
| JavaScript | 75,573,420,861 |
| JSON | 15,366,881,241 |
| Julia | 621,046,949 |
| JupyterNotebook | 2,241,893,197 |
| Lua | 4,146,420,802 |
| Makefile | 12,640,010,879 |
| Markdown | 64,796,743,311 |
| Mathematica | 320,504,225 |
| OmniversePython | 26,946,093 |
| Pascal | 1,625,013,876 |
| Perl | 1,575,314,434 |
| PHP | 61,575,339,005 |
| Python | 126,916,727,384 |
| R | 19,811,381,935 |
| reStructuredText | 1,779,876,391 |
| Ruby | 6,446,962,615 |
| Rust | 4,438,640,533 |
| Scala | 3,343,959,154 |
| Shell | 18,758,779,250 |
| SQL | 23,205,633,085 |
| Swift | 5,976,714,881 |
| SystemVerilog | 233,056,185 |
| TeX | 7,347,157,527 |
| TypeScript | 15,657,838,582 |
| Verilog | 811,884,369 |
| VHDL | 648,401,444 |
| VisualBasic.NET | 1,005,680,881 |
| XML | 12,616,779,741 |
| YAML | 10,574,010,491 |
##
## Evaluation Dataset:
* Data Collection Method by dataset: Hybrid: Human, Synthetic
* Labeling Method by dataset: Hybrid: Automated, Human, Synthetic
### Base Benchmark Evaluations
We evaluated our model on the following benchmarks:
| Task | N-Nano-V2 12B Base | | N-Nano-V2 9B Base | Qwen3 8B Base | Gemma3 12B Base |
| :---- | :---- | :---- | :---- | :---- | :---- |
| **General** | | | | | |
| MMLU | **78.24** | | 74.53 | 76.44 | 73.61 |
| MMLU-Pro 5-shot | **63.98** | | 59.43 | 56.27 | 45.12 |
| AGIEval English CoT | **68.03** | | 65.28 | 59.54 | 51.69 |
| **Math** | | | | | |
| GSM8K CoT | **91.66** | | 91.36 | 84.00 | 74.45 |
| Math | **83.54** | | 80.50 | 55.40 | 42.40 |
| MATH Level 5 | **67.61** | | **63.64** | 29.91 | 17.71 |
| AIME 2024 avg@32 | **56.67** | | 30.00 | 20.00 | 16.67 |
| **Code** | | | | | |
| HumanEval+ Pass@1 | **61.03** | | 58.50 | 57.55 | 36.68 |
| MBPP+ Pass@1 | **61.55** | | 58.95 | 58.56 | 51.73 |
| **Commonsense Understanding** | | | | | |
| ARC Challenge | **93.26** | | 90.70 | 93.09 | 90.44 |
| HellaSwag | 84.00 | | 79.90 | 79.75 | **84.15** |
| OpenBookQA | **46.00** | | 44.80 | 42.00 | **46.00** |
| PIQA | **82.54** | | 81.83 | 79.43 | 82.10 |
| WinoGrande | 79.24 | | 75.30 | 75.93 | **79.95** |
| **Long Context** | | | | | |
| RULER-128K | **84.74** | | 82.22 | \- | 80.70 |
*Table 1: Accuracy of Nemotron-Nano-V2-Base models versus existing SoTA models. N-Nano-V2 is short for Nemotron-Nano-V2. The distilled N-Nano-V2-9B-Base is compared against Qwen3-8B-Base and Gemma3-12B-Base, and the best score is highlighted in each row.*
| Task | N-Nano-V2 12B Base | | N-Nano-V2 9B Base | Qwen3 8B Base | Gemma3 12B Base |
| :---- | :---- | :---- | :---- | :---- | :---- |
| **Global-MMLU-Lite** | | | | | |
| German | 74.50 | | 68.25 | **75.50** | 69.75 |
| Spanish | **76.50** | | 72.75 | 75.00 | 74.00 |
| French | **78.25** | | 69.75 | 74.25 | 72.50 |
| Italian | **76.50** | | 73.25 | 72.75 | 74.00 |
| Japanese | 71.00 | | 67.00 | 70.00 | **71.50** |
| Korean | **72.50** | | 67.25 | 67.25 | 70.25 |
| Portuguese | **76.25** | | 71.25 | 72.50 | 75.75 |
| Chinese | **75.50** | | 69.25 | 75.25 | 67.25 |
| Average | **75.13** | | 69.94 | 72.81 | 71.88 |
| **Multilingual Math (MGSM)** | | | | | |
| Spanish | **93.20** | | 91.60 | 86.40 | 74.00 |
| German | **89.60** | | 89.60 | 78.80 | 68.80 |
| French | **86.40** | | 86.00 | 78.80 | 70.80 |
| Chinese | 44.40 | | **75.20** | 28.80 | 26.80 |
| Japanese | **76.00** | | 74.80 | 30.80 | 26.40 |
| Russian | 90.40 | | **91.60** | 83.60 | 76.00 |
| Average | 80.00 | | **84.80** | 64.53 | 57.13 |
*Table 2: Accuracy of Nemotron-Nano-V2-Base models versus existing SoTA models on multilingual benchmarks. N-Nano-V2 is short for Nemotron-Nano-V2. The distilled N-Nano-V2-9B-Base is compared against Qwen3-8B-Base and Gemma3-12B-Base, and the best score is highlighted in each row.*
## Inference
- ## Engines: HF, vLLM, TRT-LLM
- ## Test Hardware NVIDIA A100 80GB, H100 80GB
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our [Trustworthy AI terms of service](https://www.nvidia.com/en-us/agreements/trustworthy-ai/terms/), developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Bias](bias.md), [Explainability](explainability.md), [Safety & Security](safety.md), and [Privacy](privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
```
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}
```
| null |
[
"other",
"nvidia-open-model-license",
"https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/"
] |
[
"nvidia/Nemotron-Pretraining-Dataset-sample",
"nvidia/Nemotron-CC-v2",
"nvidia/Nemotron-CC-Math-v1",
"nvidia/Nemotron-Pretraining-Code-v1",
"nvidia/Nemotron-Pretraining-SFT-v1"
] |
[
"en",
"es",
"fr",
"de",
"ja",
"it",
"pt",
"zh",
"ar",
"da",
"ko",
"nl",
"pl",
"ru",
"sv",
"th"
] | 12,310,001,152
| null |
[
null,
"text-generation"
] | null |
[
"AutoModel"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
68a1acf489373c2011d80922
|
TheDrummer/Cydonia-24B-v4.1
|
TheDrummer
| null | 823
| 823
|
False
| 2025-08-17T10:20:36Z
| 2025-08-24T11:27:46Z
| null | 39
| 12
| null | null |
{"parameters": {"BF16": 23572403200}, "total": 23572403200}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00010.safetensors",
"model-00002-of-00010.safetensors",
"model-00003-of-00010.safetensors",
"model-00004-of-00010.safetensors",
"model-00005-of-00010.safetensors",
"model-00006-of-00010.safetensors",
"model-00007-of-00010.safetensors",
"model-00008-of-00010.safetensors",
"model-00009-of-00010.safetensors",
"model-00010-of-00010.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
717e35eceb939ee36c7cdd35559c3e0af66d5d24
|
[
"safetensors",
"mistral",
"region:us"
] | null |
# Join our Discord! https://discord.gg/BeaverAI
## Nearly 7000 members strong 💪 A hub for users and makers alike!
---
## Drummer is open for work / employment (I'm a Software Engineer). Contact me through any of these channels: https://linktr.ee/thelocaldrummer
### Thank you to everyone who subscribed through [Patreon](https://www.patreon.com/TheDrummer). Your suppprt helps me chug along in this brave new world.
---
[Drummer](https://huggingface.co/TheDrummer) proudly presents...
# Cydonia 24B v4.1 💿

## Usage
- Mistral v7 Tekken
## Description
> Cydonia Evolved again.
> I have to praise this model for good focus. I said earlier that it still remembers it at 12K. I think my personal evaluation of it has already beaten the rest.
> Damn okay this model is actually pretty good. I don't have enough vram to test it on longer chats to 16k, but on 6k chats it's looking good and without deepseek's slop.
> Wow, for a 24B this thing has some writing chops. Like it nails mood and nuance and shit with the prose, descriptive but not purple prose. you may have cracked the Cydonias for good with this one. The more I play with it, the more it feels like a level up from the prior ones. Haven't got into long context yet though. My cards tend to favor the opposite or at best neutral. Its rolling with the card, and nailing it, its a bit fallen and its doing good prose to match. Yeah this one's a banger.
> Very good. For 24B, the best I've come across. Like even swipes, it stays creative and writes just as well as the swipes before it but doesn't recycle anything from them. It doesn't go overboard on the creativity like Gemma can do, it'll write what you tell it or if RP pick up on things pretty accurately. The prose isn't purple either, it's good.
> I dunno how you have broken the spell R1 Cydonia had on me or what made me try this on a whim but you have gold on your hands with this tune. Again.
> it really doesn't feel like a mistral tune which is honestly the best compliment I can give it. I'm not getting the usual mistral tuneisms from it.
> It's probably the best Cydonia.

## Links
- Original: https://huggingface.co/TheDrummer/Cydonia-24B-v4.1
- GGUF: https://huggingface.co/TheDrummer/Cydonia-24B-v4.1-GGUF
- iMatrix (recommended): https://huggingface.co/bartowski/TheDrummer_Cydonia-24B-v4.1-GGUF
- EXL3: https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v4.1-EXL3
## Special Thanks
Hoping to make SleepDeprived proud with this one. RIP.
`config-v4j`
| null | null | null | null | 23,572,403,200
| null | null | null |
[
"MistralForCausalLM",
"mistral"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ad1b963c3e503e0651f43a
|
FoxBaze/Try_On_Qwen_Edit_Lora_Alpha
|
FoxBaze
| null | 0
| 0
|
False
| 2025-08-26T02:27:34Z
| 2025-08-26T11:50:57Z
| null | 12
| 12
| null | null | null |
[
".gitattributes",
"README.md",
"TryOn-Alpha-Workflow.json",
"Try_On_Qwen_Edit_Lora.safetensors",
"example_1.png",
"example_2.png",
"example_3.png"
] | null | null |
da7bdf70e9f231c61b562e0e28a23d653ebbe3a2
|
[
"qwen",
"qwen-edit",
"qwen-edit-lora",
"try-on",
"license:apache-2.0",
"region:us"
] | null |
## Qwen-Edit Try-On Lora (Alpha version)
This is an alpha version Lora that is trained to perform **multi-reference try-on editing** with [Qwen Image Edit](https://huggingface.co/Qwen/Qwen-Image-Edit).
- **Model type**: LoRA for Qwen Image Edit
- **Use case**: Multi-reference clothing try-on
- **Input format**: One top image (subject) + multiple bottom images (garments). For best results, use garment images that are high quality, and full body-shots for the subject.
- **Output format**: Stylized subject wearing all garments from bottom row
find us on Discord: https://discord.gg/UXN7zFuxbk
# Examples:



## Usage
For usage within ComfyUI using the [provided workflow](./TryOn-Alpha-Workflow.json). Recommended settings are 30 steps, with 2.5 CFG using Euler sampler and Simple scheduler.
:warning: **Warning:** Both the 4-steps and 8-steps lightning lora’s did not perform well with the Try-On lora. I would recommend using it without low step lora's for now.
832x1248 is the recommended resolution used. If you would like to use a different one please use one of the reccomended resolutions below provided by Qwen:
(672, 1568),
(688, 1504),
(720, 1456),
(752, 1392),
(800, 1328),
(832, 1248),
(880, 1184),
(944, 1104),
(1024, 1024),
(1104, 944),
(1184, 880),
(1248, 832),
(1328, 800),
(1392, 752),
(1456, 720),
(1504, 688),
(1568, 672),
---
### Limitations
- Only trained/tested on multi-garment try-on tasks.
- May not generalize to unrelated image editing tasks.
- Requires careful prompt alignment (see below).
- Struggles with 5 or more garments (more training required)
---
## Example Prompts
- **For Woman**:
`"Style the woman in the top of the image, with every article of clothing on the bottom"`
- **For Man**:
`"Style the man in the top of the image, with every article of clothing on the bottom"`
---
## Training Details
- **Base Model**: Qwen Image Edit
- **Approach**: LoRA training with [Ostris ai toolkit](https://github.com/ostris/ai-toolkit)
---
## Donations
We’re working toward a scaled-up V2 of this project, with expanded capabilities and larger dataset/compute requirements. Your support helps make this possible:
- [Ko-fi](https://ko-fi.com/foxbaze)
- **BTC Address**: `bc1qnqa7ufcw4f7cp8pzahd8jlut0ve2trq4c7t75h`
- **ETH Address**: `0x596A4Bd554337d9D1FfbA6AA346f847CE942f945`
| null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68addbbb95975e492767795c
|
TheDrummer/GLM-Steam-106B-A12B-v1-GGUF
|
TheDrummer
|
{
"models": [
{
"_id": "687c61c324649ecb26a748f0",
"id": "zai-org/GLM-4.5-Air"
}
],
"relation": "quantized"
}
| 3,185
| 3,185
|
False
| 2025-08-26T16:07:23Z
| 2025-08-29T09:17:23Z
| null | 12
| 12
| null | null | null |
[
".gitattributes",
"GLM-Steam-106B-A12B-v1b-Q2_K-00001-of-00001.gguf",
"GLM-Steam-106B-A12B-v1b-Q3_K_M-00001-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q3_K_M-00002-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q4_K_M-00001-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q4_K_M-00002-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q5_K_M-00001-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q5_K_M-00002-of-00002.gguf",
"GLM-Steam-106B-A12B-v1b-Q6_K-00001-of-00003.gguf",
"GLM-Steam-106B-A12B-v1b-Q6_K-00002-of-00003.gguf",
"GLM-Steam-106B-A12B-v1b-Q6_K-00003-of-00003.gguf",
"GLM-Steam-106B-A12B-v1b-Q8_0-00001-of-00003.gguf",
"GLM-Steam-106B-A12B-v1b-Q8_0-00002-of-00003.gguf",
"GLM-Steam-106B-A12B-v1b-Q8_0-00003-of-00003.gguf",
"README.md"
] |
[
2636,
44972828832,
44980731424,
12053371648,
44917636544,
27939883840,
44634383680,
38771483616,
44784348320,
44856006208,
9367172768,
44814227808,
44809989920,
27832287520,
2022
] | 474,734,356,786
|
728e788b747ed9e5beee85cdd0edb3fb92dc8dce
|
[
"gguf",
"base_model:zai-org/GLM-4.5-Air",
"base_model:quantized:zai-org/GLM-4.5-Air",
"endpoints_compatible",
"region:us",
"conversational"
] |
{"total": 110468824832, "architecture": "glm4moe", "context_length": 131072, "chat_template": "[gMASK]<sop>\n{%- if tools -%}\n<|system|>\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>\n{% for tool in tools %}\n{{ tool | tojson(ensure_ascii=False) }}\n{% endfor %}\n</tools>\n\nFor each function call, output the function name and arguments within the following XML format:\n<tool_call>{function-name}\n<arg_key>{arg-key-1}</arg_key>\n<arg_value>{arg-value-1}</arg_value>\n<arg_key>{arg-key-2}</arg_key>\n<arg_value>{arg-value-2}</arg_value>\n...\n</tool_call>{%- endif -%}\n{%- macro visible_text(content) -%}\n {%- if content is string -%}\n {{- content }}\n {%- elif content is iterable and content is not mapping -%}\n {%- for item in content -%}\n {%- if item is mapping and item.type == 'text' -%}\n {{- item.text }}\n {%- elif item is string -%}\n {{- item }}\n {%- endif -%}\n {%- endfor -%}\n {%- else -%}\n {{- content }}\n {%- endif -%}\n{%- endmacro -%}\n{%- set ns = namespace(last_user_index=-1) %}\n{%- for m in messages %}\n {%- if m.role == 'user' %}\n {% set ns.last_user_index = loop.index0 -%}\n {%- endif %}\n{%- endfor %}\n{% for m in messages %}\n{%- if m.role == 'user' -%}<|user|>\n{% set content = visible_text(m.content) %}{{ content }}\n{{- '/nothink' if (enable_thinking is defined and not enable_thinking and not content.endswith(\"/nothink\")) else '' -}}\n{%- elif m.role == 'assistant' -%}\n<|assistant|>\n{%- set reasoning_content = '' %}\n{%- set content = visible_text(m.content) %}\n{%- if m.reasoning_content is string %}\n {%- set reasoning_content = m.reasoning_content %}\n{%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n{%- endif %}\n{%- if loop.index0 > ns.last_user_index and reasoning_content -%}\n{{ '\\n<think>' + reasoning_content.strip() + '</think>'}}\n{%- else -%}\n{{ '\\n<think></think>' }}\n{%- endif -%}\n{%- if content.strip() -%}\n{{ '\\n' + content.strip() }}\n{%- endif -%}\n{% if m.tool_calls %}\n{% for tc in m.tool_calls %}\n{%- if tc.function %}\n {%- set tc = tc.function %}\n{%- endif %}\n{{ '\\n<tool_call>' + tc.name }}\n{% set _args = tc.arguments %}\n{% for k, v in _args.items() %}\n<arg_key>{{ k }}</arg_key>\n<arg_value>{{ v | tojson(ensure_ascii=False) if v is not string else v }}</arg_value>\n{% endfor %}\n</tool_call>{% endfor %}\n{% endif %}\n{%- elif m.role == 'tool' -%}\n{%- if m.content is string -%}\n{%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|observation|>' }}\n{%- endif %}\n{{- '\\n<tool_response>\\n' }}\n{{- m.content }}\n{{- '\\n</tool_response>' }}\n{%- else -%}\n<|observation|>{% for tr in m.content %}\n\n<tool_response>\n{{ tr.output if tr.output is defined else tr }}\n</tool_response>{% endfor -%}\n{% endif -%}\n{%- elif m.role == 'system' -%}\n<|system|>\n{{ visible_text(m.content) }}\n{%- endif -%}\n{%- endfor -%}\n<|endoftext|>\n{%- if add_generation_prompt -%}\n <|assistant|>{{- '\\n<think></think>' if (enable_thinking is defined and not enable_thinking) else '' -}}\n{%- endif -%}\n", "bos_token": "[gMASK]", "eos_token": "<|endoftext|>"}
|
# Join our Discord! https://discord.gg/BeaverAI
## Nearly 7000 members strong 💪 A hub for users and makers alike!
---
### Thank you to everyone who subscribed through [Patreon](https://www.patreon.com/TheDrummer). Your suppprt helps me chug along in this brave new world.
---
[Drummer](https://huggingface.co/TheDrummer) proudly presents...
# GLM Steam 106B A12B v1 🚂

> The smoke and the fire and the speed, the action and the sound, and everything that goes together, the steam engine is the most beautiful machine that we ever made, there's just nothing like it.
## Usage
- GLM-4.5 (Think or No Thinking)
- https://rentry.org/geechan#model-specific-presets
## Description
> Steam v1 has got the juice
> Characters are as vivid as the original GLM-Air, though prose is much more enticing.
> Damn okay this model is actually pretty good. I don't have enough vram to test it on longer chats to 16k, but on 6k chats it's looking good and without deepseek's slop.
> this model has a unique way of speaking. imo it's kept the same "soul" of the writing as Air but with more creativity and willingness to be hor -
> this model is fun! :3

## Links
- Original: https://huggingface.co/TheDrummer/GLM-Steam-106B-A12B-v1
- GGUF: https://huggingface.co/TheDrummer/GLM-Steam-106B-A12B-v1-GGUF
- iMatrix (recommended): https://huggingface.co/bartowski/TheDrummer_GLM-Steam-106B-A12B-v1-GGUF
- EXL3: https://huggingface.co/ArtusDev/TheDrummer_GLM-Steam-106B-A12B-v1-EXL3
## Special Thanks
Thank you to [Nectar.AI](https://nectar.ai/) for making this finetune possible, and your belief and support for Generative AI as entertainment!
Thank you, zerofata, for collaborating with me and diving headfirst on tuning GLM Air!
`config-v1b`
| null | null | null | null | null | 110,468,824,832
| null | null |
[
"glm4moe"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ade2625f191715666805d6
|
Comfy-Org/Qwen-Image-InstantX-ControlNets
|
Comfy-Org
| null | 13,971
| 13,971
|
False
| 2025-08-26T16:35:46Z
| 2025-08-27T11:41:27Z
|
diffusion-single-file
| 12
| 12
| null | null | null |
[
".gitattributes",
"README.md",
"split_files/controlnet/Qwen-Image-InstantX-ControlNet-Union.safetensors"
] |
[
1519,
72,
3536027816
] | 3,536,029,407
|
da9adb06bf28ac0d0c914a1a21393a9df238cc60
|
[
"diffusion-single-file",
"comfyui",
"license:apache-2.0",
"region:us"
] | null | null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
|
66944f1fe0c5c2e493a804f5
|
meta-llama/Llama-3.1-8B
|
meta-llama
| null | 1,186,239
| 12,628,422
|
manual
| 2024-07-14T22:20:15Z
| 2024-10-16T22:00:37Z
|
transformers
| 1,757
| 11
| null |
text-generation
|
{"parameters": {"BF16": 8030261248}, "total": 8030261248}
|
[
".gitattributes",
"LICENSE",
"README.md",
"USE_POLICY.md",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"original/consolidated.00.pth",
"original/params.json",
"original/tokenizer.model",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
7627,
40883,
4691,
826,
185,
4976698672,
4999802720,
4915916176,
1168138808,
23950,
16060621688,
199,
2183982,
73,
9085658,
50500
] | 32,132,578,157
|
d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"fancyfeast/joy-caption-pre-alpha",
"gokaygokay/FLUX-Prompt-Generator",
"fancyfeast/joy-caption-alpha-one",
"bhaskartripathi/LLM_Quantization",
"tomg-group-umd/lm-watermarking",
"joaogante/assisted_generation_demo",
"genai-impact/ecologits-calculator",
"ranamhamoud/webpluging",
"BharadhwajS/Niral_Thiruvizha_Project",
"ale-bjanes/rag-chat",
"ruslanmv/convert_to_gguf",
"Kathirsci/mistreal",
"Asor/Coverletter_Writer",
"fschwartzer/text_generation_with_feedback",
"hursittopal/Meta-Llama-3.1-8B",
"littleduckliu/meta-llama-Meta-Llama-3.1-8B",
"fafdajalebi/meta-llama-Meta-Llama-3.1-8B",
"awuspace/meta-llama-Meta-Llama-3.1-8B",
"ahsancloud/meta-llama-Meta-Llama-3.1-8B",
"Roy310/ChatBOT",
"rohanc10/meta-llama-Meta-Llama-3.1-8B",
"wiklif/my-api",
"sahil-s-246/meta-llama-Meta-Llama-3.1-8B",
"kashviiii/meta-llama-Meta-Llama-3.1-8B",
"johnyang/meta-llama-Meta-Llama-3.1-8B",
"llwcool/meta-llama-Meta-Llama-3.1-8B",
"iqbalfachry/meta-llama-Meta-Llama-3.1-8B",
"egrilmez/meta-llama-Meta-Llama-3.1-8B",
"freemmy/meta-llama-Meta-Llama-3.1-8B",
"TheDexter00/meta-llama-Meta-Llama-3.1-8B-testing",
"emts/meta-llama-Meta-Llama-3.1-8B",
"kj1012/meta-llama-Meta-Llama-3.1-8B",
"mxtkde/meta-llama-Meta-Llama-3.1-8B",
"Inabia-AI/meta-llama-Meta-Llama-3.1-8B",
"gnicula/Dota2_Build_Help",
"ujjaval88/meta-llama-Meta-Llama-3.1-8B",
"sanbo1200/meta-llama-Meta-Llama-3.1-8B",
"faisalbsl21/meta-llama-Meta-Llama-3.1-405",
"Infeksion/meta-llama-Meta-Llama-3.1-8B",
"neuralworm/meta-llama-3.1-8B",
"aieeshashafique/meta-llama-Meta-Llama-3.1-8B",
"felipebarcelospro/meta-llama-Meta-Llama-3.1-8B",
"VenturaSpectra/ZervAI",
"aaaasasd12/meta-llama-Meta-Llama-3.1-8B",
"ginolimdev/testoutsystems",
"kerenskiy/meta-llama-Meta-Llama-3.1-8B",
"tejas1210/meta-llama-Meta-Llama-3.1-8B",
"Alone88/meta-llama-Meta-Llama-3.1-8B",
"aieeshashafique/meta-llama-Meta-Llama",
"akhilmonanilkumar/meta-llama-Meta-Llama-3.1-8B",
"JamaYao/meta-llama-Meta-Llama-3.1-8B",
"arjunanand13/Mood_Based_Music_Recommender",
"xxhandbananaxx/meta-llama-Meta-Llama-3.1-8B",
"Pablometal17/meta-llama-Meta-Llama-3.1-8B",
"Vivtorsing/UselessAI",
"Crow34/Fun",
"SKV2001/graph_llama31",
"alpharash/meta-llama-Meta-Llama-3.1-8B",
"Crow8827/meta-llama-Meta-Llama-3.1-8B",
"panuthept/thai_sentence_embedding_benchmark",
"Nehruraj/meta-llama-Meta-Llama-3.1-8B",
"vensonaa/meta-llama-Meta-Llama-3.1-8B",
"yakine/model",
"K-Rahul/meta-llama-Meta-Llama-3.1-8B",
"vakodiya/news_research_tool_with_llama3_8b",
"PokemonGoAboo/MetaMan",
"godocean/meta-llama-Meta-Llama-3.1-8B",
"cihan/meta-llama-Meta-Llama-3.1-8B",
"springsuu/meta-llama-Meta-Llama-3.1-8B",
"mayank0002/llama3",
"realbcmonkey/lllama",
"Masterdqqq/meta-llama-Meta-Llama-3.1-8B",
"shasha123/LLama1",
"kshetez/meta-llama-Meta-Llama-3.1-8B",
"abhinandvk41/meta-llama-Meta-Llama-3.1-8B",
"Rajkumar-9999/meta-llama-Meta-Llama-3.1-8B",
"chanpreet007/meta-llama-Meta-Llama-3.1-8B",
"Hasanbnr360/meta-llama-Meta-Llama-3.1-8B",
"imGaurav333/chatbot",
"kerembozkurt/meta-llama-Meta-Llama-3.1-8B",
"bimbashrestha/meta-llama-Meta-Llama-3.1-8B",
"mtqahmdtp/meta-llama-Meta-Llama-3.1-8B",
"Ffftdtd5dtft/gfgf",
"Ffftdtd5dtft/Hhhggv",
"shoukosagiri/meta-llama-Meta-Llama-3.1-8B",
"Ffftdtd5dtft/Hhhhh",
"huzey/ncut-pytorch",
"abhivsh/meta-llama-Meta-Llama-3.1-8B",
"vector2000/test_finetunning",
"iclalcetin/llama-3.1-chatbot",
"skleckyi/meta-llama-Meta-Llama-3.1-8B",
"ashmib/green-city-finder",
"LohithGummi/meta-llama-Meta-Llama-3.1-8B",
"khush2003/meta-llama-Meta-Llama-3.1-8B",
"Kikuu/meta-llama-Meta-Llama-3.1-8B",
"artupas/tes",
"artupas/meta-llama-Meta-Llama-3.1-8B",
"catidiana/test1-chatbot",
"ponomd420/meta-llama-Meta-Llama-3.1-8B",
"samyak152002/meta-llama-Meta-Llama-3.1-8B",
"aanand04/meta-llama-Meta-Llama-3.1-8B",
"MrPlotert/meta-llama-Meta-Llama-3.1-8B",
"yg-iima/meta-llama-Meta-Llama-3.1-8B",
"yg-iima/UL-Techtonic",
"kijeoung/joy-caption-ko",
"Andreyalth/meta-llama-Meta-Llama-3.1-8B",
"B1999/meta-llama-Meta-Llama-3.1-8B",
"fakejig/meta-llama-Meta-Llama-3.1-8B",
"poojaroonwit/meta-llama-Meta-Llama-3.1-8B",
"LVKinyanjui/QueryYourDocs",
"lowtinghao/meta-llama-Meta-Llama-3.1-8B",
"source7th/text2sql_",
"olimpolui/meta-llama-Meta-Llama-3.1-8B",
"AmpleBasis/joy-caption-pre-alpha",
"Mohit0412/meta-llama-Meta-Llama-3.1-8B",
"AhmedMagdy7/meta-llama-Meta-Llama-3.1-8B",
"frozenboy/meta-llama-Meta-Llama-3.1-8B",
"cabranch/meta-llama-Meta-Llama-3.1-8B",
"vishnuhari17/meta-llama-Meta-Llama-3.1-8B",
"emptycoder0220/meta-llama-Meta-Llama-3.1-8B",
"klsnlkne/meta-llama-Meta-Llama-3.1-8B",
"JeCabrera/FLUX-Prompt-Generator-2",
"mhitaman/meta-llama-Meta-Llama-3.1-8B",
"sudac/meta-llama-Meta-Llama-3.1-8B",
"Madan2007/meta-llama-Meta-Llama-3.1-8B",
"Madan2007/meta-llama-Meta-Llama-3.1-8B_test",
"1whomakes/meta-llama-Meta-Llama-3.1-8B",
"redfernstech/meta-llama-Meta-Llama-3.1-8B",
"dehsahk-deys/demo_llama",
"Ingeniar/meta-llama-Meta-Llama-3.1-8B",
"Gwidha/meta-llama-Meta-Llama-3.1-8B",
"WARDHADID/meta-llama-Meta-Llama-3.1-8B",
"VishnuVichu096/meta-llama-Meta-Llama-3.1-8B",
"AryaWu/Ndif_No_Code",
"Yhhxhfh/chat-test",
"gautampu2003/meta-llama-Meta-Llama-3.1-8B",
"samudr4/meta-llama-Meta-Llama-3.1-8B",
"bala-rishikesavan/meta-llama-Meta-Llama-3.1-8B",
"VMassola/meta-llama-Meta-Llama-3.1-8B",
"Nymbo/joy-caption-alpha-one",
"ryanpdwyer/meta-llama-Meta-Llama-3.1-8B",
"Parlusyt/meta-llama-Meta-Llama-3.1-8B",
"Underground-Digital/Test-Caption-Captain",
"John6666/joy-caption-pre-alpha-mod-error",
"mohammedhabib/samsa",
"Olicity0411/meta-llama-Llama-3.1-8B",
"lee1fffa/meta-llama-Llama-3.1-8B",
"Underground-Digital/Caption-Captain",
"Sergidev/hftestbackend",
"andyaii/FLUX-Prompt-Generator",
"ayushiiisahu/meta-llama-Llama-3.1-8B",
"annieGod/meta-llama-Llama-3.1-8B",
"moknml/topic_cls_test",
"MXPD/joy-caption-alpha-one",
"varun324242/meta-llama-Llama-3.1-8B",
"luklue/joy-caption-alpha-one",
"Nandha22/Lamma3.1-8B",
"AnggaRamdaR/AkuChatbot",
"DevRuhela/Chat-IIITA-Python",
"DevRuhela/meta-llama-Llama-3.1-8B",
"Woziii/LLMnBiasV2",
"Chilliming/meta-llama-Llama-3.1-8B",
"Sonfire/meta-llama-Llama-3.1-8B",
"DjDister/meta-llama-Llama-3.1-8B",
"DiegoMories/testasdf",
"kysfu/meta-llama-Llama-3.1-8B",
"Adi123jadhav/meta-llama-Llama-3.1-8B",
"assadsid/llama-test",
"YourickStancov/Crowley-Meta",
"JacobJackson1/meta-llama-Llama-3.1-8B",
"serifekocak/meta-llama-Llama-3.1-8B",
"bobber/joy-caption-pre-alpha",
"swapnil1989/swapnilgupta",
"Namit2111/Jivus-Test-Llama-3.1-8B",
"sobarine/everai",
"pcalhoun/Convert-Modern-English-to-Jonathan-Swift-Style",
"papahawk/meta-llama-Llama-3.1-8B",
"pblnmhf/rag",
"mahdiabedi2000/meta-llama-Llama-3.1-8B",
"gaverfraxz/Weight_Comparator",
"One-Gridd/radio",
"kishorprajapati/meta-llama-Llama-3.1-8B",
"eltorio/Llama-3.1-8B-appreciation",
"mackalex/meta-llama-Llama-3.1-8B",
"sanketchaudhary/LLM-chat-app",
"1v1a3x/TestMLBackEnd",
"SkazuHD/docker-test",
"Jaysi-hf/regulatory",
"Torch6435/meta-llama-Llama-3.1-8B",
"kuntal01/meta-llama-Llama-3.1-8B",
"aryaash/meta-llama-Llama-3.1-8B",
"romannai/meta-llama-Llama-3.1-8B",
"philosopher-from-god/FLUX-Prompt-Generator",
"dappjuis/meta-llama-Llama-3.1-8B",
"Aleksmorshen/joy-caption-pre-alpha",
"Sergidev/GemEnd",
"lcipolina/game_reasoning_arena",
"iamboolean/set50-rag",
"bamiiiland/meta-llama-Llama-3.1-8B",
"ccraam/meta-llama-Llama-3.1-8B",
"Chrome540/meta-llama-Llama-3.1-8B",
"mitko2703/meta-llama-Llama-3.1-8B",
"svjack/joy-caption-pre-alpha",
"akashsah1008/meta-llama-Llama-3.1-8B",
"rtazlaou/meta-llama-Llama-3.1-8B",
"ikenna1234/ai_interviewer4",
"caelendev/meta-llama-Llama-3.1-8B",
"Prashasst/meta-llama-Llama-3.1-8B",
"ManojBahadur/Text_generation_llama3",
"Bilgisam/meta-llama-Llama-3.1-8B",
"Motojeff/meta-llama-Llama-3.1-8B",
"Rivak/Test_finetuned_ISO_model",
"genaitiwari/AutogenWithHF",
"bola23/chatbot-has-feelings",
"nothing95/meta-llama-Llama-3.1-8B",
"KBaba7/Quant",
"hzc541882025/joy-caption-pre-alpha",
"Pierre918/get_great_deal",
"totolook/Quant",
"benrben/meta-llama-Llama-3.1-8B",
"benrben/meta-llama-Llama-3.1-8B-9",
"fdaudens/meta-download-stats",
"lombokLegi/meta-llama-Llama-3.1-8B",
"jonaschua/deepseekv1",
"Globalsdik/meta-llama-Llama-3.1-8B",
"MegaTronX/MetaLlamaTest",
"jbjbjb55/First_agent_template",
"HenriMK/meta-llama-Llama-3.1-8B",
"WOWILd657765/meta-llama-Llama-3.1-8B",
"starnernj/Early-Christian-Church-Fathers",
"FallnAI/Quantize-HF-Models",
"K00B404/LLM_Quantization",
"SamuelJaja/llama3.1-8b-construction-lora_a100",
"Vasps/Validate-Address",
"Vasps/HTSCode",
"Vasps/ProdDesc",
"Guy24/inner_lexicon",
"chanakarnuac/G01_Computer_Vision_Joy-caption-pre-alpha",
"nyasukun/compare-security-models",
"Himanshu806/llama3.1_8b",
"purpleriann/LLM-Engineers-Handbook",
"dobval/WebThinker",
"mamogasr/llm_engineering",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"lisekarimi/snapr",
"Darsh1234Tayal/AI_Girlfriend_Project_by_Darsh_",
"SHAH-MEER/BarginBots",
"SonicRiff/meta-llama-Llama-3.1-8B",
"PVZ388/joy-caption-pre-alpha",
"hideosnes/meta-llama-Llama-3.1-8B",
"YongdongWang/robot-task-planning",
"mariompv/GAIA_AGENT",
"arunabeshc/Structure_a_Data_Agile_Project",
"e10ai/Final_Assignment_Template",
"gns1784/my-llm-demo",
"Hhellocedric/meta-llama-Llama-3.1-8B",
"K00B404/convert_to_gguf",
"gopi30/meta-llama-Llama-3.1-8B",
"NTUST-DDRC/gen3c",
"YongdongWang/DART-LLM-Multi-Model-GGUF",
"YongdongWang/DART-LLM-Multi-Model",
"lifedebugger/cs-ai-sakura-dev",
"NaveenRM/llama31-finetuned-demo",
"Avi-Shrivastava/kabloom_rag",
"talhafewfefefew/Pricer",
"Mauriciotuks/IoPrototype",
"dudeai612/KingChat-0.3",
"Upendra98/meta-llama-Llama-3.1-8B"
] |
[
"llama3.1"
] | null |
[
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th"
] | 8,030,261,248
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] |
Accept to share username & email, Other agreement/info requirements
| null |
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en",
" de",
" fr",
" it",
" pt",
" hi",
" es",
" th"
] |
[
"Pretraining: Causal Language Modeling (CLM)"
] |
Partially disclosed: unavailable
| 5
|
67175475ab870480b86e7caa
|
stabilityai/stable-diffusion-3.5-large
|
stabilityai
| null | 74,708
| 1,547,949
|
auto
| 2024-10-22T07:29:57Z
| 2024-10-22T14:36:33Z
|
diffusers
| 3,087
| 11
| null |
text-to-image
| null |
[
".gitattributes",
"LICENSE.md",
"README.md",
"SD3.5L_example_workflow.json",
"mmdit.png",
"model_index.json",
"scheduler/scheduler_config.json",
"sd3.5_large.safetensors",
"sd3.5_large_demo.png",
"text_encoder/config.json",
"text_encoder/model.fp16.safetensors",
"text_encoder/model.safetensors",
"text_encoder_2/config.json",
"text_encoder_2/model.fp16.safetensors",
"text_encoder_2/model.safetensors",
"text_encoder_3/config.json",
"text_encoder_3/model-00001-of-00002.safetensors",
"text_encoder_3/model-00002-of-00002.safetensors",
"text_encoder_3/model.fp16-00001-of-00002.safetensors",
"text_encoder_3/model.fp16-00002-of-00002.safetensors",
"text_encoder_3/model.safetensors.index.fp16.json",
"text_encoder_3/model.safetensors.index.json",
"text_encoders/README.md",
"text_encoders/clip_g.safetensors",
"text_encoders/clip_l.safetensors",
"text_encoders/t5xxl_fp16.safetensors",
"text_encoders/t5xxl_fp8_e4m3fn.safetensors",
"tokenizer/merges.txt",
"tokenizer/special_tokens_map.json",
"tokenizer/tokenizer_config.json",
"tokenizer/vocab.json",
"tokenizer_2/merges.txt",
"tokenizer_2/special_tokens_map.json",
"tokenizer_2/tokenizer_config.json",
"tokenizer_2/vocab.json",
"tokenizer_3/special_tokens_map.json",
"tokenizer_3/spiece.model",
"tokenizer_3/tokenizer.json",
"tokenizer_3/tokenizer_config.json",
"transformer/config.json",
"transformer/diffusion_pytorch_model-00001-of-00002.safetensors",
"transformer/diffusion_pytorch_model-00002-of-00002.safetensors",
"transformer/diffusion_pytorch_model.safetensors.index.json",
"vae/config.json",
"vae/diffusion_pytorch_model.safetensors"
] |
[
1576,
11726,
10473,
11575,
262061,
706,
141,
16460379262,
18080198,
574,
247323896,
247323896,
570,
1389382176,
1389382176,
740,
4994582104,
4530066248,
4994582104,
4530066248,
20980,
19885,
636,
1389382176,
246144152,
9787841024,
4893934904,
524619,
588,
705,
1059962,
524619,
576,
856,
1059962,
2543,
791656,
2424035,
20617,
397,
9985185992,
6307519304,
126867,
809,
167666902
] | 71,585,723,216
|
ceddf0a7fdf2064ea28e2213e3b84e4afa170a0f
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"en",
"arxiv:2403.03206",
"license:other",
"diffusers:StableDiffusion3Pipeline",
"region:us"
] | null | null |
[
"Nymbo/Serverless-ImgGen-Hub",
"jbilcke-hf/OmniAvatar",
"Yntec/ToyWorld",
"Kunbyte/Lumen",
"Yntec/PrintingPress",
"Yntec/blitz_diffusion",
"multimodalart/civitai-to-hf",
"NeurixYUFI/imggen",
"Mr-Vicky-01/AI_Artist",
"alfredplpl/sd3-with-LLM",
"gokaygokay/SD3.5-with-Captioner",
"AlekseyCalvin/SD35soonrLoRAs",
"gokaygokay/SD3.5-Prompt-Generator",
"Ivan000/AI-screensaver",
"Nymbo/Compare-6",
"stabilityai/stable-diffusion-3.5-large",
"Nymbo/stable-diffusion-3.5-large",
"Deewmaker/stabilityai-stable-diffusion-3.5-large",
"PhelpsGG/stabilityai-stable-diffusion-3.5-large",
"Nymbo/Stable-Diffusion-3.5-Large-Serverless",
"SalvaNanez/stabilityai-stable-diffusion-3.5-large",
"JJSer32/stable-diffusion-3.5-large",
"dfeels/stabilityai-stable-diffusion-3.5-large",
"arad1367/Stable_Diffusion_3.5_Large_Customized",
"SamGro/stabilityai-stable-diffusion-3.5-large",
"ruchijindal58/stabilityai-stable-diffusion-3.5-large",
"Han-123/stable-diffusion-3.5-large",
"chen318/stabilityai-stable-diffusion-3.5-large",
"setaayesh/stabilityai-stable-diffusion-3.5-large",
"Meetop/stabilityai-stable-diffusion-3.5-large",
"zombie6868/stabilityai-stable-diffusion-3.5-large",
"Minorutanaka14052005/stabilityai-stable-diffusion-3.5-large",
"7ejsud/stabilityai-stable-diffusion-3.5-large",
"SoulToast/stabilityai-stable-diffusion-3.5-large",
"LeX17/stabilityai-stable-diffusion-3.5-large",
"gonzatoba/stabilityai-stable-diffusion-3.5-large",
"ACRavelo/stabilityai-stable-diffusion-3.5-large",
"SpaghettiUniverse/stabilityai-stable-diffusion-3.5-large",
"TorresCamilo/application",
"yasu01/stabilityai-stable-diffusion-3.5-large",
"YFL4K/stabilityai-stable-diffusion-3.5-large",
"Kareolis/stabilityai-stable-diffusion-3.5-large",
"THARUN9522/stabilityai-stable-diffusion-3.5-large",
"Thetutorcyber/stabilityai-stable-diffusion-3.5-large",
"Alex2027/stabilityai-stable-diffusion-3.5-large",
"badpiggy/stabilityai-stable-diffusion-3.5-large",
"anthienlong/stable-diffusion-3.5-large",
"Bagusindra/Tesnet",
"Pedronassif/stabilityai-stable-diffusion-3.5-large",
"MarsimoWs/stabilityai-stable-diffusion-3.5-large",
"Zsa45/stabilityai-stable-diffusion-3.5-large",
"fifosifo/Stable-Diffusion-3.5-Large-Serverless",
"DanialKing1/stabilityai-stable-diffusion-3.5-large",
"dongdong961/stabilityai-stable-diffusion-3.5-large",
"djberube/stabilityai-stable-diffusion-3.5-large",
"davidAbrahan/stabilityai-stable-diffusion-3.5-large",
"TruffleFrog/stabilityai-stable-diffusion-3.5-large",
"FaceHugger987/stabilityai-stable-diffusion-3.5-large",
"AlekseyCalvin/Stabled_LoRAs_on_SD3.5_MERGED",
"JUZbox013/stabilityai-stable-diffusion-3.5-large",
"K00B404/Stable-Diffusion-3.5-Serverless",
"keshav6936/stabilityai-stable-diffusion-3.5-large",
"Samshantj/stabilityai-stable-diffusion-3.5-large",
"Abhik0069/stabilityai-stable-diffusion-3.5-large",
"Sp00K1/stable-diffusion-3.5-large",
"Davidyulianto/stable-diffusion-3.5-large",
"Samba666/stabilityai-stable-diffusion-3.5-large",
"haccourt/stabilityai-stable-diffusion-3.5-large",
"ashkck/stabilityai-stable-diffusion-3.5-large",
"michellemoorre/tvar-demo-test",
"ashkck/stabilityai-stable-diffusion-3.5-large2",
"ordlibrary/stabilityai-stable-diffusion-3.5-large",
"iliciuv/stable-diffusion-3.5-large",
"gervaisazangati/stabilityai-stable-diffusion-3.5-large",
"ashkck/stabilityai-stable-diffusion-3.5-largelogo",
"Thetutorcyber/stabilityai-stable-diffusion-3g.5-large",
"SwampGT/stabilityai-stable-diffusion-3.5-large",
"ArijitMishra/t2i_image_translation",
"spark-sweet/stabilityai-stable-diffusion-3.5-large",
"bgaap/stabilityai-stable-diffusion-3.5-large",
"kylemacmac/stabilityai-stable-diffusion-3.5-large",
"economo/stabilityai-stable-diffusion-3.5-large",
"rajakmonu/stabilityai-stable-diffusion-3.5-large",
"wangwolgw/stabilityai-stable-diffusion-3.5-large",
"danyial/stabilityai-stable-diffusion-3.5-large",
"znxbbd/stabilityai-stable-diffusion-3.5-large",
"Dynamitte63/stabilityai-stable-diffusion-3.5-large",
"rogelioalcantarrangel/stabilityai-stable-diffusion-3.5-large",
"lihong2023tk/stabilityai-stable-diffusion-3.5-large",
"selvamaniandiappan/MultiLLM",
"varunhuggingface/Dev-Img",
"Kemploff/stabilityai-stable-diffusion-3.5-large",
"Deepack/stabilityai-stable-diffusion-3.5-large",
"rphrp1985/stable-diffusion-3.5-large",
"Paour/stabilityai-stable-diffusion-3.5-large",
"anubisweb/stabilityai-stable-diffusion-3.5-large",
"Kynlo/stabilityai-stable-diffusion-3.5-large",
"definitelynotaname/stabilityai-stable-diffusion-3.5-large",
"baobeimilk23/stabilityai-stable-diffusion-3.5-large",
"thesab/Grape-Leaf-Disease-Synth-Generator",
"DigiP-AI/Image_Studio",
"Quiho/stabilityai-stable-diffusion-3.5-large",
"baiyang1111/stabilityai-stable-diffusion-3.5-large",
"Bsisb/stabilityai-stable-diffusion-3.5-large",
"Bad1/stabilityai-stable-diffusion-3.5-large",
"terrasono/Silly_draw",
"marcussviniciusa/stabilityai-stable-diffusion-3.5-large",
"Mangeloox3/stabilityai-stable-diffusion-3.5-large",
"lftzab/stabilityai-stable-diffusion-3.5-large",
"2510044747qq/stabilityai-stable-diffusion-3.5-large",
"Troy-Tillier/stabilityai-stable-diffusion-3.5-large",
"Seaofbbs/stabilityai-stable-diffusion-3.5-large",
"qiyonle/stabilityai-stable-diffusion-3.5-large",
"amos1088/test_gradio",
"w1166en/stabilityai-stable-diffusion-3.5-large",
"Supermarkedet/stabilityai-stable-diffusion-3.5-large",
"titoo233/stabilityai-stable-diffusion-3.5-large",
"jithenderchoudary/Promp",
"Oyayubi/stable-diffusion-3.5-large",
"hjjhgdfs/stabilityai-stable-diffusion-3.5-large",
"k4rd4n/yariksnovaprivet",
"ItoshiRae/stabilityai-stable-diffusion-3.5-large",
"paisdsf/stabilityai-stable-diffusion-3.5-large",
"gregmellon/stabilityai-stable-diffusion-3.5-large",
"tom0072012/stabilityai-stable-diffusion-3.5-large",
"ToddEverett/stabilityai-stable-diffusion-3.5-large",
"timedepths/stabilityai-stable-diffusion-3.5-large",
"Thetutorcyber/stabilityai-stable-diffusion-3.5-larbbbhhfffge",
"ahmadalfakeh/Stable-Diffusion-3.5-Large-Serverless",
"gasekerci/stabilityai-stable-diffusion-3.5-large",
"JagmeetMinhas22/stabilityai-stable-diffusion-3.5-large",
"Ugottaloveit/stabilityai-stable-diffusion-3.5-large",
"meinsdfsf/stabilityai-stable-diffusion-3.5-large",
"Zula03/stabilityai-stable-diffusion-3.5-large",
"Nosferatu666/stabilityai-stable-diffusion-3.5-large",
"mbrady/stable-diffusion-3.5-large",
"ovaisham/stabilityai-stable-diffusion-3.5-large",
"gasekerci/stabilityai-stable-diffusion-3.5-large1",
"SeePlay/stabilityai-stable-diffusion-3.5-large",
"Mandwiki/Diffusion",
"nthuy/stabilityai-stable-diffusion-3.5-large",
"yerysh/stabilityai-stable-diffusion-3.5-large",
"wang12311/stabilityai-stable-diffusion-3.5-large",
"DoomSlayer9743/Text-to-image",
"LetsRewind/stabilityai-stable-diffusion-3.5-large",
"LetsRewind/sstabilityai-stable-diffusion-3.5-large",
"niklascon/NLPU1",
"tofaramususa/stabilityai-stable-diffusion-3.5-large",
"luisfn/stabilityai-stable-diffusion-3.5-large",
"innkeeper/stabilityai-stable-diffusion-3.5-large",
"Nyzilver/stabilityai-stable-diffusion-3.5-large",
"arsh4/stabilityai-stable-diffusion-3.5-large",
"gwada/stabilityai-stable-diffusion-3.5-large",
"joseple6890/stabilityai-stable-diffusion-3.5-large",
"Spooke/txttoimg",
"ensariano/ensoenso",
"ygongBU/XXiao",
"Brian-A/text-to-image",
"MARK52/stabilityai-stable-diffusion-3.5-large",
"kenzl1/stabilityai-stable-diffusion-3.5-large",
"kenzl1/teststable",
"ahmetmehmetalper/stable_diffusion_imagegeneration",
"sskoder/stabilityai-stable-diffusion-3.5-large",
"erstrik/stabilityai-stable-diffusion-3.5-large",
"vasilisklv/genai_story_creation_game",
"sunny333/textToImage",
"karthik12345ttttt/stabilityai-stable-diffusion-3.5-large",
"udderbird84/stabilityai-stable-diffusion-3.5-large",
"ivanusto/stable-diffusion-3.5-large",
"wang12311/stabilityai-stable-diffusion-3.5-large-wang",
"Bbae112/stabilityai-stable-diffusion-3.5-large",
"spark12x/SD3.5-Prompt-Generator",
"kaoqy/stabilityai-stable-diffusion-3.5-large",
"xzezaru/stable-diffusion-3.5-large",
"gengs/prithivMLmods-SD3.5-Large-Photorealistic-LoRA",
"revanth8977/stabilityai-stable-diffusion-3.5-large",
"yangong23/BUbot",
"urwah1248/stabilityai-stable-diffusion-3.5-large",
"yangong23/XXiao",
"tamilkamkov/stabilityai-stable-diffusion-3.5-large",
"FabrizioFor/stabilityai-stable-diffusion-3.5-large",
"zareefhasan/stabilityai-stable-diffusion-3.5-large",
"Shouden/stabilityai-stable-diffusion-3.5-large",
"egyleader/stabilityai-stable-diffusion-3.5-large",
"Ikygantengbangetanjay/stable-diffusion-3.5-large",
"praveenbenakannanavar/stabilityai-stable-diffusion-3.5-large",
"dws16/stabilityai-stable-diffusion-3.5-large",
"phamngoctukts/assistant",
"sky120906/stabilityai-stable-diffusion-3.5-large",
"Garfied/stabilityai-stable-diffusion-3.5-large",
"Shankarm08/Text2image",
"zulteon/SD3.5Large",
"loveitl/stabilityai-stable-diffusion-3.5-large",
"Eliasgtr/stable-diffusion-3.5-large",
"prashanthmuthu/stabilityai-stable-diffusion-3.5-large",
"Leesanghyeon/stabilityai-stable-diffusion-3.5-large",
"Alph4teK/stabilityai-stable-diffusion-3.5-large",
"eashuu/stabilityai-stable-diffusion-3.5-large",
"Kebab42/stabilityai-stable-diffusion-3.5-large",
"duqj/stabilityai-stable-diffusion-3.5-large",
"SvetlanaLa/stabilityai-stable-diffusion-3.5-large",
"kasap61/stabilityai-stable-diffusion-3.5-large",
"kasap61/stabilityai-stable-diffusion-3.5-large-gradio",
"KmgSamuel/stabilityai-stable-diffusion-3.5-large",
"MIKHAILCLEAR/stabilityai-stable-diffusion-3.5-large",
"arielvrt/stabilityai-stable-diffusion-3.5-large",
"DavidBrauch/TUDa_NLP4Web_HW1_db",
"purakausupplements/stabilityai-stable-diffusion-3.5-large",
"ashmjoy33/stabilityai-stable-diffusion-3.5-large",
"Ramybe01/stabilityai-stable-diffusion-3.5-large",
"leonchiu/stabilityai-stable-diffusion-3.5-large",
"WompUniversity/stable-diffusion-3.5-large",
"Konst2021/stabilityai-stable-diffusion-3.5-large",
"Dagfinn1962/stabilityai-stable-diffusion-3.5-large",
"mrlow/stabilityai-stable-diffusion-3.5-large",
"Pablocha2424/stabilityai-stable-diffusion-3.5-large",
"Raheel1909/stabilityai-stable-diffusion-3.5-large",
"newikov/sd_large_experiments",
"newikov/stabilityai-stable-diffusion-3.5-large",
"Darthside/stabilityai-stable-diffusion-3.5-large",
"anisirji/final-text-to-image-meme-ai",
"MERDANio/stabilityai-stable-diffusion-3.5-large",
"vinrox2090/stabilityai-stable-diffusion-3.5-large",
"janigma/npl-4-web",
"blind1234/stabilityai-stable-diffusion-3.5-large",
"the82447/stabilityai-stable-diffusion-3.5-large",
"Zmuki/stabilityai-stable-diffusion-3.5-large",
"adampalam/stabilityai-stable-diffusion-3.5-large",
"akutar/stabilityai-stable-diffusion-3.5-large",
"Zorobaka/stabilityai-stable-diffusion-3.5-large",
"SAITAN666/StableDiffusion35Large-Image-Models-Test-November-2024",
"revittapanda/stabilityai-stable-diffusion-3.5-large",
"pkq2222/stabilityai-stable-diffusion-3.5-large",
"Michinca/stabilityai-stable-diffusion-3.5-large",
"creytris/stabilityai-stable-diffusion-3.5-large",
"JohnJohnnyJohn/stabilityai-stable-diffusion-3.5-large",
"ryrl/nlp_",
"Rdeisenroth/XgvtvJdhTzb9w7VxWK3d3jczMrhqsPxn",
"Alibiiiii/gradio-bm25-demo",
"kingNiven/stabilityai-stable-diffusion-3.5-large",
"kaleidoskop-hug/PrintingPress",
"Santiago-del-Rio/bm25-search-engine",
"konnnou/stabilityai-stable-diffusion-3.5-large",
"InstantX/SD35-IP-Adapter",
"Steve223/HW1_Steven",
"Sihoff/MeinSpace",
"hanifi/NLP4WEB-HW1",
"zway717/stabilityai-stable-diffusion-3.5-large",
"joiweb3/stabilityai-stable-diffusion-3.5-large",
"RogelioAlcantar/Application",
"Manojajj/AI_Image_Creator",
"AnushaSM/NLP_Web",
"sigango/cscbm25test-app",
"NikeSophie/NLPHW1",
"Yousef-Allam/CSC_BM25_Retriever",
"sigango/apptest",
"StarNews/stabilityai-stable-diffusion-3.5-large",
"mehboob-shaikh/stabilityai-stable-diffusion-3.5-large",
"intelava/nlp4web",
"titanium2550/stabilityai-stable-diffusion-3.5-large",
"Surfparadise/stabilityai-stable-diffusion-3.5-large",
"drybone121/hw1-gradio",
"sawal4/search-engine",
"Sophie-O/NLP",
"mb0710/HW1",
"chikiet/stabilityai-stable-diffusion-3.5-large",
"Ikaikuro/NLP-Exercise1",
"ffffffff12345678/nlp4web_ex1",
"johnksunny97/NLPForWeb",
"chikiet/stabilityai-stable-diffusion-3.5-large1",
"LKhelwi/stabilityai-stable-diffusion-3.5-large",
"fugam/Fusion-stable",
"wgdp5000/stabilityai-stable-diffusion-3.5-large",
"abmSS/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/HuggingfaceDiffusion",
"NativeAngels/ToyWorld",
"TiyashaB/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/blitz_diffusion",
"Alekbom/stabilityai-stable-diffusion-3.5-large",
"foxhon/stabilityai-stable-diffusion-3.5-large",
"Mashal456/Newsletter_generator_using_Groq",
"CIULLU/stabilityai-stable-diffusion-3.5-large",
"JHk27/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/PrintingPress",
"kcanmersin/stabilityai-stable-diffusion-3.5-large",
"MasterBlueSAMA/stabilityai-stable-diffusion-3.5-large",
"NoInk02/stabilityai-stable-diffusion-3.5-large",
"Nymbo/SD35-IP-Adapter",
"nguyenthanhasia/stable-diffusion-3.5-large",
"Wendywzt/stable-diffusion-3.5-large",
"williamchans/stabilityai-stable-diffusion-3.5-large",
"RORONovaLuffy/stabilityai-stable-diffusion-3.5-large",
"lpxwander/stabilityai-stable-diffusion-3.5-large",
"louuup/stabilityai-stable-diffusion-3.5-large",
"Nymbo/Model-Status-Checker",
"klaus0123/stabilityai-stable-diffusion-3.5-large",
"lyy0914lyy/stabilityai-stable-diffusion-3.5-large",
"mrmalinet/stabilityai-stable-diffusion-3.5-large",
"GeminiAi/stabilityai-stable-diffusion-3.5-large",
"liruiw/hma",
"Anonym26/TextToImages",
"SK5/stabilityai-stable-diffusion-3.5-large",
"FradigmaDangerYT/stabilityai-stable-diffusion-3.5-large-r",
"savan2001/stabilityai-stable-diffusion-3.5-large",
"benri/stabilityai-stable-diffusion-3.5-large",
"adamexe/stabilityai-stable-diffusion-3.5-large",
"FradigmaDangerYT/stabilityai-stable-diffusion-3.5-large",
"TheLame0ne/stabilityai-stable-diffusion-3.5-large",
"BhanuSaiSree/stabilityai-stable-diffusion-3.5-large",
"SohaMady66/stabilityai-stable-diffusion-3.5-large",
"freQuensy23/TextToImages",
"prakhardoneria/stable-diffusion-3-api",
"Happychappue/stabilityai-stable-diffusion-3.5-large",
"ChinoCarbon/stabilityai-stable-diffusion-3.5-large",
"khaitt147/stabilityai-stable-diffusion-3.5-large",
"FisheggAwaO/stabilityai-stable-diffusion-3.5-large",
"vapefr/stabilityai-stable-diffusion-3.5-large",
"rbonweb/stabilityai-stable-diffusion-3.5-large",
"TheVeshup/test1",
"roniee/stabilityai-stable-diffusion-3.5-large",
"Papamurphy06/stabilityai-stable-diffusion-3.5-large",
"shockwave00/stabilityai-stable-diffusion-3.5-large",
"ricardocosta43/stabilityai-stable-diffusion-3.5-large",
"PicklesG/stabilityai-stable-diffusion-3.5-large",
"Apolloturner/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/Serverless-ImgGen-Hub",
"azazelmay/stabilityai-stable-diffusion-3.5-large",
"lejs200/stabilityai-stable-diffusion-3.5-large",
"Shirokaly/stabilityai-stable-diffusion-3.5-large",
"csujeong/stabilityai-stable-diffusion-3.5-large",
"saliseabeali/stabilityai-stable-diffusion-3.5-large",
"TeraGames/stabilityai-stable-diffusion-3.5-large",
"evanfun300/stabilityai-stable-diffusion-3.5-large",
"Darren81/stabilityai-stable-diffusion-3.5-large",
"WhiteShirt/stabilityai-stable-diffusion-3.5-large",
"Vishalkarnik0891/stabilityai-stable-diffusion-3.5-large",
"Crepveant/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/Compare-6",
"Dok66/stabilityai-stable-diffusion-3.5-large",
"iryahayri/stabilityai-stable-diffusion-3.5-large",
"MartsoBodziu1994/stabilityai-stable-diffusion-3.5-large",
"Telmanio/stabilityai-stable-diffusion-3.5-large",
"ddgf/stabilityai-stable-diffusion-3.5-large",
"hongliveje/stabilityai-stable-diffusion-3.5-large",
"JakeFornis/stabilityai-stable-diffusion-3.5-large",
"JoeProAI/stabilityai-stable-diffusion-3.5-large",
"JoeProAI/stabilityai-stable-diffusion-3.5-large222",
"igaswiatek/stable-diffusion-3.5-large",
"sargamon/stabilityai-stable-diffusion-3.5-large",
"GPUModelSpotlight/Analysis-Of-Image-Song-Video-Prompts",
"awacke1/ImageMultiagentSystem",
"hanwest/stabilityai-stable-diffusion-3.5-large",
"niiamu/stabilityai-stable-diffusion-3.5-large",
"gencbeyinlernet/stable-diffusion-3.5-large",
"LifeGameYT/stabilityai-stable-diffusion-3.5-large",
"Sayiqa/stabilityai-stable-diffusion-3.5-large",
"danielk96/stabilityai-stable-diffusion-3.5-large",
"NativeAngels/Stable-Diffusion-3.5-Large-Serverless",
"raghunathvanka/text-to-image-generator",
"johnshloper/stabilityai-stable-diffusion-3.5-large",
"raiderboyz/stabilityai-stable-diffusion-3.5-large",
"faizaledrus/stabilityai-stable-diffusion-3.5-large",
"WangHe/stabilityai-stable-diffusion-3.5-large",
"lasheerah/stabilityai-stable-diffusion-3.5-large",
"Fantomio/stabilityai-stable-diffusion-3.5-large",
"vninetwo/stabilityai-stable-diffusion-3.5-large",
"skiming/stabilityai-stable-diffusion-3.5-large",
"Lilllijdhfv/stabilityai-stable-diffusion-3.5-large",
"smatt92/stabilityai-stable-diffusion-3.5-large",
"Double2and9/stabilityai-stable-diffusion-3.5-large",
"simo025/stabilityai-stable-diffusion-3.5-large",
"ihihihhoih/stabilityai-stable-diffusion-3.5-large",
"gurkanasekerci/stabilityai-stable-diffusion-3.5-large",
"Rajesh64240/stabilityai-stable-diffusion-3.5-large",
"PPdm/stabilityai-stable-diffusion-3.5-large",
"dehua68/ToyWorld",
"Kdub8990/stabilityai-stable-diffusion-3.5-large",
"Yoki18S/stabilityai-stable-diffusion-3.5-large",
"Justik45/stabilityai-stable-diffusion-3.5-large",
"Jalosq/stabilityai-stable-diffusion-3.5-large",
"topperge/stabilityai-stable-diffusion-3.5-large",
"S16stable/stabilityai-stable-diffusion-3.5-large",
"itscyrusdawg/stabilityai-stable-diffusion-3.5-large",
"Zyanfarhan/stabilityai-stable-diffusion-3.5-large",
"ranaur/stabilityai-stable-diffusion-3.5-large",
"TejaSayya/stabilityai-stable-diffusion-3.5-large",
"123umat/stabilityai-stable-diffusion-3.5-large",
"Tijlio/epc-test",
"EleHome/stabilityai-stable-diffusion-3.5-large",
"cookprotocol/image_kitchen",
"bingfeng288/stabilityai-stable-diffusion-3.5-large",
"RageshAntony/ragesh-stable-diffusion-3.5-large",
"AlexSU5/stabilityai-stable-diffusion-3.5-large",
"amankft/stabilityai-stable-diffusion-3.5-large",
"kleinfreddie/stabilityai-stable-diffusion-3.5-large",
"crazyhite001/imggen",
"Baawiil/stabilityai-stable-diffusion-3.5-large",
"mitesh7/SketchGen",
"AAA56y65/stabilityai-stable-diffusion-3.5-large",
"gamal77/stabilityai-stable-diffusion-3.5-large",
"rakheshkrishna2005/stabilityai-stable-diffusion-3.5-large",
"WhiteGuyShirtT/stabilityai-stable-diffusion-3.5-large",
"Mhilty07/stabilityai-stable-diffusion-3.5-large",
"LAYEK-143/VYX-MODEL",
"Guibat/stabilityai-stable-diffusion-3.5-large",
"martynka/TasiaExperiment",
"itscyrusdawg/stabilityai-stable-diffusion-3.5-largefffef",
"Athuyl/stable-diffusion-3.5-large",
"Unity-Unix/stabilityai-stable-diffusion-3.5-large",
"Sheldon57/stabilityai-stable-diffusion-3.5-large",
"sialnoman318/stabilityai-stable-diffusion-3.5-large",
"Abinivesh/Multi-models-prompt-to-image-generation",
"hlvvcr79/stabilityai-stable-diffusion-3.5-large",
"STA08/stabilityai-stable-diffusion-3.5-large",
"sialnoman318/2DFloorPlanDesigner",
"garrypay/stabilityai-stable-diffusion-3.5-large",
"mbiddick/stabilityai-stable-diffusion-3.5-large",
"jbuckles/stabilityai-stable-diffusion-3.5-large",
"zeno211/Gensuki_Ai",
"shatteredking/stabilityai-stable-diffusion-3.5-large",
"Plugiloinc/stabilityai-stable-diffusion-3.5-large",
"Witness5242/stabilityai-stable-diffusion-3.5-large",
"sunlow983/stabilityai-stable-diffusion-3.5-large",
"sype/stable-diffusion-3.5-large",
"Ewan1958/stabilityai-stable-diffusion-3.5-large",
"Rkemmi/stabilityai-stable-diffusion-3.5-large",
"samgor77/stabilityai-stable-diffusion-3.5-large",
"Sonfire/stabilityai-stable-diffusion-3.5-lsarge",
"Sonfire/stabilityai-stable-diffusion-3.5-large",
"CadenC/stabilityai-stable-diffusion-3.5-large",
"Roso82/stabilityai-stable-diffusion-3.5-large",
"Adrian212112/stabilityai-stable-diffusion-3.5-large",
"Gaeldeth/stabilityai-stable-diffusion-3.5-large",
"Muhammad-1254/stabilityai-stable-diffusion-3.5-large-demo",
"Rente3/stabilityai-stable-diffusion-3.5-large",
"donvirtus/stabilityai-stable-diffusion-3.5-large",
"Senpaga/stabilityai-stable-diffusion-3.5-large",
"okshijian/stabilityai-stable-diffusion-3.5-large",
"xxx231231231/stabilityai-stable-diffusion-3.5-large",
"diegosaran/stabilityai-stable-diffusion-3.5-large",
"Jodaye33/stabilityai-stable-diffusion-3.5-large",
"brutal9557/image-sonu",
"wowank/stabilityai-stable-diffusion-3.5-large",
"Kr1st3r/stabilityai-stable-diffusion-3.5-large",
"DonImages/Testing",
"EliteGamerCJ/EGCJIMAGEGEN",
"DonImages/Testing2",
"namank5x/stabilityai-stable-diffusion-3.5-large",
"sivasubramanian34/stabilityai-stable-diffusion-3.5-large",
"Sigiteko2402/stabilityai-stable-diffusion-3.5-large",
"MrDrmm/DiffFlu2",
"MrDrmm/t2i-multi-demo",
"Jsdndn/stabilityai-stable-diffusion-3.5-large",
"DonImages/Testing3",
"skyzhao1223/stabilityai-stable-diffusion-3.5-large",
"deepak032/stabilityai-stable-diffusion-3.5-large_032",
"sawknifevion/stabilityai-stable-diffusion-3.5-large",
"OkCaterpillarrr/stabilityai-stable-diffusion-3.5-large",
"OkCaterpillarrr/stabilityai-stable-diffusion-3.5-larg",
"schastlivcev/bedtime-fairy-tale",
"waseemirshad45/stabilityai-stable-diffusion-3.5-large",
"Pinky836/stabilityai-stable-diffusion-3.5-large",
"igz/stabilityai-stable-diffusion-3.5-large",
"zzhou292/stabilityai-stable-diffusion-3.5-large",
"lenruy/stabilityai-stable-diffusion-3.5-large",
"benjamin-paine/absynth-2.0",
"MrDrmm/Self",
"Enntized/stabilityai-stable-diffusion-3.5-large",
"MrDrmm/Gen",
"BICORP/stabilityai-stable-diffusion-3.5-large",
"Arwaxda/stabilityai-stable-diffusion-3.5-large",
"Atreyhur/stabilityai-stable-diffusion-3.5-large",
"lllllllEGOlllllll/Stablediff-3.5-large",
"m3g4p0p/qr-code",
"Han-Shao/stabilityai-stable-diffusion-3.5-large",
"seeingfaces/stabilityai-stable-diffusion-3.5-large",
"Sheriff005/stabilityai-stable-diffusion-3.5-large",
"momo1994A11/stabilityai-stable-diffusion-3.5-large",
"gnosticdev/stabilityai-stable-diffusion-3.5-large",
"CaravenCREATE/StableDifSharaball",
"AiWithHamza/stabilityai-stable-diffusion-3.5-large",
"Fre123/stabilityai-stable-diffusion-3.5-large",
"MohammadBanis/Fine_Tuning_Test",
"martynka/tasia-api",
"loganvicky/stabilityai-stable-diffusion-3.5-large",
"FM-1976/TweetGeneration",
"chrisjcrocker/stabilityai-stable-diffusion-3.5-large",
"bjshark/stabilityai-stable-diffusion-3.5-large",
"Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1",
"lostspace003/stabilityai-stable-diffusion-3.5-large",
"Coraxxx/Traponder",
"ashifjoyius/stabilityai-stable-diffusion-3.5-large",
"Rahimuj570/stabilityai-stable-diffusion-3.5-large",
"SKsizan/stabilityai-stable-diffusion-3.5-large",
"M4xjunior/stabilityai-stable-diffusion-3.5-large",
"NomadSHANTO/stabilityai-stable-diffusion-3.5-large",
"Sboncen/stabilityai-stable-diffusion-3.5-large",
"nimurojas/stabilityai-stable-diffusion-3.5-large",
"meme13521/stabilityai-stable-diffusion-3.5-large",
"psychogoff/stabilityai-stable-diffusion-3.5-large",
"sanzydev/stabilityai-stable-diffusion-3.5-large",
"SrKatayama/stabilityai-stable-diffusion-3.5-large",
"Polopo/stabilityai-stable-diffusion-3.5-large",
"martynka/tasia-api-dev",
"Refricontrols/stabilityai-stable-diffusion-3.5-large",
"Badboycj001/stabilityai-stable-diffusion-3.5-large",
"unrecited/stabilityai-stable-diffusion-3.5-large",
"Framill/stabilityai-stable-diffusion-3.5-large",
"Malik99999/stabilityai-stable-diffusion-3.5-large",
"soiz1/Serverless-ImgGen-Hub",
"HighFocusRecords/Stable-Diffusion-3.5-Large-ServerlessNYMBO",
"cyberl33t/stabilityai-stable-diffusion-3.5-large",
"waliullahSam/stabilityai-stable-diffusion-3.5-large",
"Eksing/stabilityai-stable-diffusion-3.5-large",
"bardwilliams720/stabilityai-stable-diffusion-3.5-large",
"soyonofficial89/stabilityai-stable-diffusion-3.5-large",
"fdfdsgkd/stabilityai-stable-diffusion-3.5-large",
"genaitiwari/AutogenWithHF",
"VoodooPickle/stabilityai-stable-diffusion-3.5-large",
"mafiafoxx/stabilityai-stable-diffusion-3.5-large",
"alexeyGod/stable-diffusion-3.5-large",
"deltaw/stabilityai-stable-diffusion-3.5-large",
"nabiadua/stabilityai-stable-diffusion-3.5-large",
"Hyuuuu/stabilityai-stable-diffusion-3.5-large",
"jesuswithclinton/stabilityai-stable-diffusion-3.5-large",
"Masterdqqq/emilio-stable-diffusion-3.5-large",
"spiermario/stabilityai-stable-diffusion-3.5-large",
"expinc32/stabilityai-stable-diffusion-3.5-large",
"ggautama/stabilityai-stable-diffusion-3.5-large",
"jjbwez/stabilityai-stable-diffusion-3.5-large",
"marwaneziani3/stabilityai-stable-diffusion-3.5-large",
"annasiverova2023/stabilityai-stable-diffusion-3.5-large",
"Cryogenized/stabilityai-stable-diffusion-3.5-large",
"mohammedamehry/stabilityai-stable-diffusion-3.5-large",
"WengFelix/stabilityai-stable-diffusion-3.5-large",
"Studiociber/stabilityai-stable-diffusion-3.5-large",
"Bshanej1986/stabilityai-stable-diffusion-3.5-large",
"ceodaniel/stabilityai-stable-diffusion-3.5-large",
"agentsvalley/Stable-Diffusion-3.5-Large-Agents-Valley",
"1Tinker/stabilityai-stable-diffusion-3.5-large",
"joeysaada/stabilityai-stable-diffusion-3.5-large",
"shaunaklad21/stabilityai-stable-diffusion-3.5-large",
"alexgeros/stabilityai-stable-diffusion-3.5-large",
"Parmist/strangerzonehf-Flux-Super-Realism-LoRA",
"MrDrmm/Gen2",
"Mrsanchaari8/stabilityai-stable-diffusion-3.5-large",
"yuhaode/stabilityai-stable-diffusion-3.5-large",
"ankit1302/stabilityai-stable-diffusion-3.5-large",
"bragadeeshs/stabilityai-stable-diffusion-3.5-large",
"qonfederanus/stabilityai-stable-diffusion-3.5-large",
"alexisdanielle/stabilityai-stable-diffusion-3.5-large",
"fahim986/stabilityai-stable-diffusion-3.5-large",
"Vedant987/stabilityai-stable-diffusion-3.5-large",
"lajicab/stabilityai-stable-diffusion-3.5-large",
"Majest1que/SD",
"1234567890isme/stabilityai-stable-diffusion-3.5-large",
"sebm9849/stabilityai-stable-diffusion-3.5-large",
"egoistCookie/EgoistStableApi",
"waloneai/stable-diffusion-3.5-large",
"Kos91/stabilityai-stable-diffusion-3.5-large",
"HolyBlood/stabilityai-stable-diffusion-3.5-large",
"Mattlowry/stabilityai-stable-diffusion-3.5-large",
"arkasamanta/stabilityai-stable-diffusion-3.5-large",
"k4l3b4/stabilityai-stable-diffusion-3.5-large",
"DShreyas/stabilityai-stable-diffusion-3.5-large",
"Obad0x/stabilityai-stable-diffusion-3.5-large",
"IvanRogelio/stabilityai-stable-diffusion-3.5-large",
"Abhijeet7488/stabilityai-stable-diffusion-3.5-large",
"Abhijeet7488/Abhijeet",
"basildevai/stabilityai-stable-diffusion-3.5-large",
"pranit121/stabilityai-stable-diffusion-3.5-large",
"xxxub/stabilityai-stable-diffusion-3.5-large",
"fmischel/stabilityai-stable-diffusion-3.5-large",
"sujit16611661/stabilityai-stable-diffusion-3.5-large",
"Hieucyber2208/know-flow",
"Nonnya/stabilityai-stable-diffusion-3.5-large",
"MrDrmm/Texttoimagevn",
"Hhsio/stabilityai-stable-diffusion-3.5-large",
"rgbMonk/stabilityai-stable-diffusion-3.5-large",
"Excalibur08/stabilityai-stable-diffusion-3.5-large",
"dreamrun/stabilityai-stable-diffusion-3.5-large",
"MrRokot/GENFLUX",
"Mohu0527/stabilityai-stable-diffusion-3.5-large",
"EliteGamerCJ/EGCJIMAGEGENEGCJ",
"Ebanart/stabilityai-stable-diffusion-3.5-large",
"mohanshenoy/stabilityai-stable-diffusion-3.5-large",
"muhamedkishta/stabilityai-stable-diffusion-3.5-large",
"MrRokot/hinablue",
"vinayakgour02/stabilityai-stable-diffusion-3.5-large",
"ilmarim/stabilityai-stable-diffusion-3.5-large",
"ffdrer/Stable-Diffusion-Text-To-Image",
"nnwofwpw/stabilityai-stable-diffusion-3.5-large",
"nnwofwpw/njaca1q95dqka",
"supratimdasrana/stabilityai-stable-diffusion-3.5-large",
"Serkann27/stabilityai-stable-diffusion-3.5-large",
"L0rdNA/stabilityai-stable-diffusion-3.5-large",
"Jokentek/stabilityai-stable-diffusion-3.5-large",
"Jokentek/stabilityai-stable-diffusion-3.5-large2",
"Nuanmanee/stabilityai-stable-diffusion-3.5-large",
"DileepEravada/stabilityai-stable-diffusion-3.5-large",
"Amozsam/stabilityai-stable-diffusion-3.5-large",
"rso123123/stabilityai-stable-diffusion-3.5-large",
"pepper200pepper/stabilityai-stable-diffusion-3.5-large",
"Hairitics/stabilityai-stable-diffusion-3.5-large",
"jamiejjmanning/stabilityai-stable-diffusion-3.5-large",
"julooo/stabilityai-stable-diffusion-3.5-large",
"Fave010/stabilityai-stable-diffusion-3.5-large",
"FusionNexus/stabilityai",
"Farsinjr/stabilityai-stable-diffusion-3.5-large",
"CyberfoxI76/stabilityai-stable-diffusion-3.5-large",
"chburhan64/ImageGeneration",
"Abdox/stabilityai-stable-diffusion-3.5-large",
"SeedOfEvil/stable-diffusion-3.5-large-SoE",
"yunglahwd/stabilityai-stable-diffusion-3.5-large",
"FUNNY1234/stabilityai-stable-diffusion-3.5-large",
"komer26/stabilityai-stable-diffusion-3.5-large",
"Amwin/stabilityai-stable-diffusion-3.5-large",
"Synitx/stabilityai-stable-diffusion-3.5-large",
"danilkonon/picture_sampling",
"BarBar288/Chatbot",
"CapriTheCreator/stabilityai-stable-diffusion-3.5-large",
"MarsYoung/stabilityai-stable-diffusion-3.5-large",
"BarBar288/AI_Tools",
"Sisiphos/stabilityai-stable-diffusion-3.5-large",
"jiayu5ua/stabilityai-stable-diffusion-3.5-large",
"cosybenulu/stabilityai-stable-diffusion-3.5-large",
"tugiefe/stabilityai-stable-diffusion-3.5-large",
"burman-ai/Printing-Press",
"worldking666/stabilityai-stable-diffusion-3.5-large",
"rosallseasons/stabilityai-stable-diffusion-3.5-large",
"BJHBJBJ/stabilityai-stable-diffusion-3.5-large",
"theunseenones94/Flux_Lustly_AI_Uncensored_NSFW_V1",
"PepsiFireAsf/stabilityai-stable-diffusion-3.5-large",
"zumwaltboi/stabilityai-stable-diffusion-3.5-large",
"MXZTT/stabilityai-stable-diffusion-3.5-large",
"dbaranchuk/SwD-SD3.5-Large",
"Hasjnlnj/stabilityai-stable-diffusion-3.5-large",
"freddyaboulton/qr-code",
"sst12345/CoRe2",
"mmineee/stabilityai-stable-diffusion-3.5-large",
"soyal/stabilityai-stable-diffusion-3.5-large",
"Lonelobo/stabilityai-stable-diffusion-3.5-large",
"AthuKawaleLogituit/SD3.5-Large",
"on3john/stabilityai-stable-diffusion-3.5-large",
"BaieNwarr/stabilityai-stable-diffusion-3.5-large",
"limone/stabilityai-stable-diffusion-3.5-large",
"underscorecramp/stabilityai-stable-diffusion-3.5-large",
"weepiess2383/CFG-Zero-Star",
"harshavardhan-ap/s2dentp1",
"matoupines/stabilityai-stable-diffusion-3.5-large",
"voodooz100/stabilityai-stable-diffusion-3.5-large",
"buttonsnnickle/stabilityai-stable-diffusion-3.5-large",
"clc05663/stabilityai-stable-diffusion-3.5-large",
"TyDaShina/stabilityai-stable-diffusion-3.5-large",
"sahbikh/stabilityai-stable-diffusion-3.5-large",
"GR4YH4M/stabilityai-stable-diffusion-3.5-large",
"jamil226/stabilityai-stable-diffusion-3.5-large",
"mayprathama/stabilityai-stable-diffusion-3.5-large",
"ankurparashar/stabilityai-stable-diffusion-3.5-large",
"MamdouhRElNakeeb/storify",
"tharisth/stabilityai-stable-diffusion-3.5-large",
"vrundagwrgeb/stabilityai-stable-diffusion-3.5-large",
"ilny999/stabilityai-stable-diffusion-3.5-large",
"DarkLore69/stabilityai-stable-diffusion-3.5-large",
"jastrzaboo/stabilityai-stable-diffusion-3.5-large",
"iolie/stabilityai-stable-diffusion-3.5-large",
"iolie/stabilityai-stable-diffusion-3.5-large22",
"Akashkale83/stabilityai-stable-diffusion-3.5-large",
"Jovemsabio/stabilityai-stable-diffusion-3.5-large",
"gourishchanda/stabilityai-stable-diffusion-3.5-large",
"ggwpnicebot/stabilityai-stable-diffusion-3.5-large",
"SnehaRavichandran/Prompt-To-Image",
"NativeAngels/TasiaExperiment",
"fromrus/stabilityai-stable-diffusion-3.5-large",
"Ravddd/stabilityai-stable-diffusion-3.5-large",
"Alfred8a/stabilityai-stable-diffusion-3.5-large",
"Elhrak/stabilityai-stable-diffusion-3.5-large",
"hungle9/stabilityai-stable-diffusion-3.5-large",
"UnnayanMishra/DreamWeaverFinal",
"qwerty212/stabilityai-stable-diffusion-3.5-large",
"parsaah13/stabilityai-stable-diffusion-3.5-large",
"OrrinNaylor/stabilityai-stable-diffusion-3.5-large",
"will-z9/my-dog-around-the-world",
"Moibe/nowme-images",
"nelllaf/stabilityai-stable-diffusion-3.5-large",
"danilkonon/beaut_rabbit_lora",
"Hori0329/stabilityai-stable-diffusion-3.5-large",
"Soyun99/stabilityai-stable-diffusion-3.5-large",
"devisty/stabilityai-stable-diffusion-3.5-large",
"Soumya79/stabilityai-stable-diffusion-3.5-large",
"Orbeato/stabilityai-stable-diffusion-3.5-large",
"Andres16l/stabilityai-stable-diffusion-3.5-large",
"walkinbay/stabilityai-stable-diffusion-3.5-large",
"cwyanada/stabilityai-stable-diffusion-3.5-large1",
"bryanbenaim/stabilityai-stable-diffusion-3.5-large",
"nagarjunmrn/stabilityai-stable-diffusion-3.5-large",
"danielprs/stabilityai-stable-diffusion-3.5-large",
"cbensimon/stable-diffusion-3.5-large",
"Amar01111/stabilityai-stable-diffusion-3.5-large",
"rafaelkamp/black-forest-labs-FLUX.1-dev",
"guvbbbn/stabilityai-stable-diffusion-3.5-large",
"DigiP-AI/Stable_Diffusion_Large",
"sanvera/stabilityai-stable-diffusion-3.5-large",
"asdasdasdsdas/stabilityai-stable-diffusion-3.5-large",
"usama7871/stabilityai-stable-diffusion-3.5-large",
"sanatmeh0932/stabilityai-stable-diffusion-3.5-large",
"nguyenvantruyen/stabilityai-stable-diffusion-3.5-large",
"vibesnow/stabilityai-stable-diffusion-3.5-large",
"Luongsosad/stabilityai-stable-diffusion-3.5-large",
"Nusss/stabilityai-stable-diffusion-3.5-large",
"justShannniii/stabilityai",
"SosaJhons/nowme-images",
"SosaJhons/nowme-images-app",
"tareq1989/my-image-generate",
"ltnpro/stabilityai-stable-diffusion-3.5-large",
"Nathan97y56/stabilityai-stable-diffusion-3.5vjl",
"Mnac11/stabilityai-stable-diffusion-3.5-large",
"varfaanna/stickers_cartoonlegend",
"teki9233/stabilityai-stable-diffusion-3.5-large",
"totemtma/stabilityai-stable-diffusion-3.5-large",
"neo7team/Stable-Diffusion-3.5-Large-Serverless",
"akbarazimifar/stabilityai-stable-diffusion-3.5-large",
"krasnoglaziiik/Serverless-ImgGen-Hub",
"saliseabeali/stabilityai-stable-diffusion-3.5-largey31",
"alissondf/st35l",
"qiang927/stabilityai-stable-diffusion-3.5-large",
"mu7ammad/stabilityai-stable-diffusion-3.5-large",
"kobeseiguzzo/stabilityai-stable-diffusion-3.5-large",
"mraurelius/stabilityai-stable-diffusion-3.5-large",
"Akira666/attire",
"HamzaUsman/stabilityai-stable-diffusion-3.5-large",
"Dockins/Automation",
"nileshkedari/stabilityai-stable-diffusion-3.5-large",
"lohengrinmesa/stabilityai-stable-diffusion-3.5-large",
"Manuel989/PrintingPress",
"Babyboy333/Flux_Lustly_AI_Uncensored_NSFW_V1",
"NeelamVDVD/stabilityai-stable-diffusion-3.5-large",
"hotelhardeo/stabilityai-stable-diffusion-3.5-large",
"den4k4554/stabilityai-stable-diffusion-3.5-large",
"kkhhhjju/stabilityai-stable-diffusion-3.5-large",
"ericaaaa334/stabilityai-stable-diffusion-3.5-large",
"Kableado/stabilityai-stable-diffusion-3.5-large",
"Danvora/stabilityai-stable-diffusion-3.5-large",
"raajeshk/stabilityai-stable-diffusion-3.5-large",
"afba1993/stabilityai-stable-diffusion-3.5-large",
"wedyanessam/Real_Time_Interactive_Avatar_v2",
"Moibe/stripe-kraken-dev",
"kbacon45/stabilityai-stable-diffusion-3.5-large",
"HighFocusRecords/Stable-Diffusion-3.5-Large-InferenceAPI",
"NeelSheth123/stabilityai-stable-diffusion-3.5-large",
"BSJ2004/stabilityai-stable-diffusion-3.5-large",
"Williams75/CFG-Zero-Star",
"bigjones1/stabilityai-stable-diffusion-3.5-large",
"Domi9981/stabilityai-stable-diffusion-3.5-large",
"prs-eth/FLAIR",
"MoibeSun/nowme-images",
"BuzzwordMx/nowme-images",
"Grandjury/stabilityai-stable-diffusion-3.5-large",
"eddyzhu12/stabilityai-stable-diffusion-3.5-large",
"jtbusiness/stabilityai-stable-diffusion-3.5-large",
"SainiVishal30/Image-Generation-App",
"Sonfire/stabilityai-stable-diffusion-3.511-large",
"Devnanc/stabilityai-stable-diffusion-3.5-large",
"YITxx/Prompt_Pics",
"alyxsis/img",
"mshary55/stabilityai-stable-diffusion-3.5-large",
"drugonme/stabilityai-stable-diffusion-3.5-large",
"gxztn/stabilityai-stable-diffusion-3.5-large",
"mojitocup/realistic-xl",
"hypevolve/stabilityai-stable-diffusion-3.5-large",
"Dee2a2/stabilityai-stable-diffusion-3.5-large",
"Rmonster/stabilityai-stable-diffusion-3.5-large",
"90gaoxing/stabilityai-stable-diffusion-3.5-large",
"mchinn/stabilityai-stable-diffusion-3.5-large",
"khaledwauto/stabilityai-stable-diffusion-3.5-large",
"BuzzwordMx/nowme-images-cron",
"iamashir12/stabilityai-stable-diffusion-3.5-large",
"HungAI116/stabilityai-stable-diffusion-3.5-large",
"Moibe/rapicash_old",
"vaishmali/stabilityai-stable-diffusion-3.5-large",
"dvlpr2003/stabilityai-stable-diffusion-3.5-large",
"TymurZemka/stabilityai-stable-diffusion-3.5-large",
"sakuraregret/stabilityai-stable-diffusion-3.5-large",
"Vickyzins/stabilityai-stable-diffusion-3.5-large",
"mkhodagholi/stabilityai-stable-diffusion-3.5-large",
"helloforyouandyou/stabilityai-stable-diffusion-3.5-large",
"muhammadakash/stabilityai-stable-diffusion-3.5-large",
"rahul7star/PusaV1",
"jbilcke-hf/ReCamMaster",
"Maverick03511/stabilityai-stable-diffusion-3.5-large",
"saliseabe89/stabilityai-stable-diffusion-3.5-large",
"dasunii002/text-image",
"Tanushka-lokegaonkar/AI_Image_Generation",
"Gamy000/stabilityai-stable-diffusion-3.5-large",
"MoibeSun/nowme-images-regen",
"Salma4121/stabilityai-stable-diffusion-3.5-large",
"Ntdeseb/ntia",
"carlosarinez19/stabilityai-stable-diffusion-3.5-large",
"Johaness/stabilityai-stable-diffusion-3.5-large",
"tabrez01/stabilityai-stable-diffusion-3.5-large",
"RioLoopz777/stabilityai-stable-diffusion-3.5-large",
"fdGDFDFLDFKJDFV/stabilityai-stable-diffusion-3.5-large",
"goravfx/stabilityai-stable-diffusion-3.5-large",
"xxmichal/stable-diffusion-3.5-large",
"FlipUpchicken/stabilityai-stable-diffusion-3.5-large",
"Moibe/stripe-kraken-prod",
"abdulbasith5/stabilityai-stable-diffusion-3.5-large",
"AiAF/Civ-2-HF",
"noumanjavaid/SD3.5-Prompt-Generator",
"Ronnie240486/stabilityai-stable-diffusion-3.5-large",
"aniketkadyan/stabilityai-stable-diffusion-3.5-large",
"tekoaly4/lejos-borges",
"fitflow71/stabilityai-stable-diffusion-3.5-large"
] |
[
"other",
"stabilityai-ai-community",
"LICENSE.md"
] | null |
[
"en"
] | null | null |
[
"text-to-image"
] | null | null |
[
"vision"
] |
[
"text"
] |
[
"image"
] |
user
|
user
|
[
"user"
] |
Accept to share username & email, Other agreement/info requirements
| null |
[
"Text"
] |
[
"Image Generation"
] |
[
"Diffusion-based Network"
] |
[
"en"
] |
[
"Pretraining: Multimodal joint-embeddings",
" Pretraining: Supervised"
] |
Partially disclosed: unavailable
| 0
|
67de202b6599e7158f6912f4
|
Qwen/Qwen2.5-Omni-7B
|
Qwen
| null | 168,359
| 1,112,480
|
False
| 2025-03-22T02:27:55Z
| 2025-04-30T13:48:45Z
|
transformers
| 1,769
| 11
| null |
any-to-any
|
{"parameters": {"F32": 449051296, "BF16": 10283174144}, "total": 10732225440}
|
[
".gitattributes",
"LICENSE",
"README.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00005.safetensors",
"model-00002-of-00005.safetensors",
"model-00003-of-00005.safetensors",
"model-00004-of-00005.safetensors",
"model-00005-of-00005.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"special_tokens_map.json",
"spk_dict.pt",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
36838,
579,
1313,
13186,
74,
1671853,
4985055504,
4991496800,
4991496904,
4969489824,
2425322160,
233160,
667,
832,
259544,
11421870,
6469,
2776833
] | 22,379,297,323
|
ae9e1690543ffd5c0221dc27f79834d0294cba00
|
[
"transformers",
"safetensors",
"qwen2_5_omni",
"multimodal",
"any-to-any",
"en",
"arxiv:2503.20215",
"license:other",
"endpoints_compatible",
"region:us"
] | null | null |
[
"MERaLiON/AudioBench-Leaderboard",
"srinuksv/qwen2.5-omini",
"srinuksv/f",
"aimeri/Qwen2.5-Omni-7B-Demo",
"Gyaneshere/Qwen2.5-Omni-7B-MultimodalInput-to-Speech",
"wambugu71/Qwen2.5-Omni-7B-Demo",
"PabloTJ/palindroms",
"Sergidev/Qwen2.5-OmniAgent",
"kingarnica/Tuesday",
"memex-in/Price-Prediction",
"memex-in/Qwen2.5-Omni-7B-Demo",
"dkolarova007/chatbot-agent",
"marluwe/Final_Assignment_Template",
"pablodiaz/Final_Assignment_Template_2",
"SamiaHaque/HarmSense",
"gijs/audsemthinker",
"Luigi/Qwen2.5-Omni-3B-ASR",
"BillionForgeAi/AI",
"DanielbDEV/AgentSubmission",
"jdesiree/EduBot"
] |
[
"other",
"apache-2.0",
"https://huggingface.co/Qwen/Qwen2.5-Omni-7B/blob/main/LICENSE"
] | null |
[
"en"
] | 10,732,225,440
| null |
[
null,
"any-to-any"
] | null |
[
"AutoModel",
"Qwen2_5OmniModel",
"qwen2_5_omni"
] |
[
"multimodal"
] |
[
"any"
] |
[
"any"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
67ff7b22b5ba13b43f0c3811
|
ByteDance-Seed/UI-TARS-1.5-7B
|
ByteDance-Seed
| null | 112,548
| 359,693
|
False
| 2025-04-16T09:40:50Z
| 2025-04-18T01:35:38Z
|
transformers
| 375
| 11
| null |
image-text-to-text
|
{"parameters": {"F32": 8292166656}, "total": 8292166656}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.json",
"config.json",
"merges.txt",
"model-00001-of-00007.safetensors",
"model-00002-of-00007.safetensors",
"model-00003-of-00007.safetensors",
"model-00004-of-00007.safetensors",
"model-00005-of-00007.safetensors",
"model-00006-of-00007.safetensors",
"model-00007-of-00007.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
8370,
605,
1050,
1374,
1671853,
4952311608,
4984124272,
4932743936,
4998852296,
4984124336,
4932743992,
3383846800,
57619,
350,
613,
11421896,
7253,
2776833
] | 33,184,696,626
|
683d002dd99d8f95104d31e70391a39348857f4e
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"multimodal",
"gui",
"image-text-to-text",
"conversational",
"en",
"arxiv:2501.12326",
"arxiv:2404.07972",
"arxiv:2409.08264",
"arxiv:2401.13919",
"arxiv:2504.01382",
"arxiv:2405.14573",
"arxiv:2410.23218",
"arxiv:2504.07981",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"Mungert/UI-TARS-1.5-7B",
"premuim89/GUI",
"premuim89/GUITARS",
"Stremly/uitars",
"what2up/qwen3",
"sharathmajjigi/UITARS_Grounding_Model"
] |
[
"apache-2.0"
] | null |
[
"en"
] | 8,292,166,656
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"AutoModelForVision2Seq",
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
680a289582ee1640eea64f70
|
ResembleAI/chatterbox
|
ResembleAI
| null | 879,121
| 2,492,035
|
False
| 2025-04-24T12:03:33Z
| 2025-05-30T09:37:10Z
|
chatterbox
| 1,021
| 11
| null |
text-to-speech
| null |
[
".gitattributes",
"README.md",
"conds.pt",
"s3gen.pt",
"s3gen.safetensors",
"t3_cfg.pt",
"t3_cfg.safetensors",
"tokenizer.json",
"ve.pt",
"ve.safetensors"
] |
[
1519,
4248,
107374,
1057165844,
1056484620,
1064892246,
2129653744,
25470,
5698626,
5695784
] | 5,319,729,475
|
1b475dffa71fb191cb6d5901215eb6f55635a9b6
|
[
"chatterbox",
"text-to-speech",
"speech generation",
"voice-cloning",
"en",
"license:mit",
"region:us"
] | null |
<img width="800" alt="cb-big2" src="https://github.com/user-attachments/assets/bd8c5f03-e91d-4ee5-b680-57355da204d1" />
<h1 style="font-size: 32px">Chatterbox TTS</h1>
<div style="display: flex; align-items: center; gap: 12px">
<a href="https://resemble-ai.github.io/chatterbox_demopage/">
<img src="https://img.shields.io/badge/listen-demo_samples-blue" alt="Listen to Demo Samples" />
</a>
<a href="https://huggingface.co/spaces/ResembleAI/Chatterbox">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/open-in-hf-spaces-sm.svg" alt="Open in HF Spaces" />
</a>
<a href="https://podonos.com/resembleai/chatterbox">
<img src="https://static-public.podonos.com/badges/insight-on-pdns-sm-dark.svg" alt="Insight on Podos" />
</a>
</div>
<div style="display: flex; align-items: center; gap: 8px;">
<span style="font-style: italic;white-space: pre-wrap">Made with ❤️ by</span>
<img width="100" alt="resemble-logo-horizontal" src="https://github.com/user-attachments/assets/35cf756b-3506-4943-9c72-c05ddfa4e525" />
</div>
We're excited to introduce Chatterbox, [Resemble AI's](https://resemble.ai) first production-grade open source TTS model. Licensed under MIT, Chatterbox has been benchmarked against leading closed-source systems like ElevenLabs, and is consistently preferred in side-by-side evaluations.
Whether you're working on memes, videos, games, or AI agents, Chatterbox brings your content to life. It's also the first open source TTS model to support **emotion exaggeration control**, a powerful feature that makes your voices stand out. Try it now on our [Hugging Face Gradio app.](https://huggingface.co/spaces/ResembleAI/Chatterbox)
If you like the model but need to scale or tune it for higher accuracy, check out our competitively priced TTS service (<a href="https://resemble.ai">link</a>). It delivers reliable performance with ultra-low latency of sub 200ms—ideal for production use in agents, applications, or interactive media.
# Key Details
- SoTA zeroshot TTS
- 0.5B Llama backbone
- Unique exaggeration/intensity control
- Ultra-stable with alignment-informed inference
- Trained on 0.5M hours of cleaned data
- Watermarked outputs
- Easy voice conversion script
- [Outperforms ElevenLabs](https://podonos.com/resembleai/chatterbox)
# Tips
- **General Use (TTS and Voice Agents):**
- The default settings (`exaggeration=0.5`, `cfg=0.5`) work well for most prompts.
- If the reference speaker has a fast speaking style, lowering `cfg` to around `0.3` can improve pacing.
- **Expressive or Dramatic Speech:**
- Try lower `cfg` values (e.g. `~0.3`) and increase `exaggeration` to around `0.7` or higher.
- Higher `exaggeration` tends to speed up speech; reducing `cfg` helps compensate with slower, more deliberate pacing.
# Installation
```
pip install chatterbox-tts
```
# Usage
```python
import torchaudio as ta
from chatterbox.tts import ChatterboxTTS
model = ChatterboxTTS.from_pretrained(device="cuda")
text = "Ezreal and Jinx teamed up with Ahri, Yasuo, and Teemo to take down the enemy's Nexus in an epic late-game pentakill."
wav = model.generate(text)
ta.save("test-1.wav", wav, model.sr)
# If you want to synthesize with a different voice, specify the audio prompt
AUDIO_PROMPT_PATH="YOUR_FILE.wav"
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH)
ta.save("test-2.wav", wav, model.sr)
```
See `example_tts.py` for more examples.
# Acknowledgements
- [Cosyvoice](https://github.com/FunAudioLLM/CosyVoice)
- [HiFT-GAN](https://github.com/yl4579/HiFTNet)
- [Llama 3](https://github.com/meta-llama/llama3)
# Built-in PerTh Watermarking for Responsible AI
Every audio file generated by Chatterbox includes [Resemble AI's Perth (Perceptual Threshold) Watermarker](https://github.com/resemble-ai/perth) - imperceptible neural watermarks that survive MP3 compression, audio editing, and common manipulations while maintaining nearly 100% detection accuracy.
# Disclaimer
Don't use this model to do bad things. Prompts are sourced from freely available data on the internet.
|
[
"ResembleAI/Chatterbox",
"Inferless/Open-Source-TTS-Gallary",
"Pendrokar/TTS-Spaces-Arena",
"Jimmi42/chatterbox-tts-apple-silicon",
"SebastianBodza/Kartoffelbox",
"nazdridoy/inferoxy-hub",
"VIDraft/Voice-Clone-Podcast",
"aiqtech/Open-Source-TTS-Gallary",
"JournalistsonHF/ai-toolkit",
"case-llm-traversaal/umer-tayyeb",
"SlouchyBuffalo/Chatterbox",
"sungo-ganpare/Chatterbox",
"Puru213/chatterbox",
"mahmoud12/chatterbox",
"imdadareeph/chatterbox_tts",
"FictionFoxy/Chatterbox",
"Saudade0167/ResembleAI-chatterbox",
"Sage6673/ResembleAI-chatterbox",
"Leafeon12xx/ResembleAI-chatterbox",
"wangweinoo1/ResembleAI-chatterbox",
"Ojas1024/ChatterboxTEST",
"Sog249/ResembleAI-chatterbox",
"SAMO5A/ResembleAI-chatterbox",
"Bendelaire/chatterbox",
"SavageKraken/ResembleAI-chatterbox",
"TaronArt/ResembleAI-chatterbox",
"yatharth2307/ResembleAI-chatterbox-copy-4mcp",
"Pops3351/git_config_-global_credential.helper_store",
"Hematej/ResembleAI-chatterbox",
"CanardPuma74/ResembleAI-chatterbox",
"spongetatle/ResembleAI-chatterbox",
"altuardo/Chatterbox",
"alankwok/ResembleAI-chatterbox",
"LTTEAM/LTTEAM_TTS",
"amew0/Chatterbox",
"UKR-PROJECTS/ResembleAI-chatterbox",
"Kiran1983/Text-Speech",
"cybertech599/ResembleAI-chatterbox",
"musama0/ResembleAI-chatterbox",
"chhokarpardeep/chatterbox",
"neo7team/Chatterbox",
"imtiyaz0/Chatterbox",
"rohan124gvvvv/ResembleAI-chatterbox",
"freddyaboulton/Chatterbox",
"akileshv/ResembleAI-chatterbox",
"ChronicSonic/ResembleAI-chatterbox",
"markl11/ResembleAI-chatterbox",
"bhaveshkanoje23/chatterboxnew",
"bhaveshkanoje23/ResembleAI-chatterbox",
"jujutechnology/https-huggingface-co-spaces-jujutechnology-ebook2audiobook",
"ryanmitts/ryan-tts",
"Arestotech/Chatterbox1",
"Swingzo/ResembleAI-chatterbox",
"SebastianBodza/Kartoffelbox_v0.2_preview",
"Gwx4/ResembleAI-chatterbox",
"fernandingo/ResembleAI-chatterbox",
"gperdrizet/unit-one-introduction",
"adptbyt/ResembleAI-chatterbox",
"victor/chatterbox-mcp",
"Detomhet/ResembleAI-chatterbox",
"lyra2025/Chatterbox",
"MananMongia/ResembleAI-chatterbox",
"ravi-bansal/ResembleAI-chatterbox",
"VentusDominus/ResembleAI-chatterbox",
"Gibbs254/ResembleAI-chatterbox",
"Hackerjackiejahn/ResembleAI-chatterbox",
"Sulai2005/VoiceSample",
"Fabrigsx/chatterbox-tts",
"Kaustubhx/My-AI-Voice",
"sablab/Chatterbox",
"JoabeAAM/chatterbox-tts-joabe",
"narcisse-on-aws/Chatterbox_Voice_AI",
"parminderpalsingh1997/chatterbox-voice-clone",
"gen2karl/ChatterBox-TTS-Server",
"musclemind27/chatterbox",
"jk-25/Chatterbox",
"jk-25/gradio",
"jeanrosso/ResembleAI-chatterbox",
"eliriedel/ResembleAI-chatterbox",
"Goodvibes247/ResembleAI-chatterbox",
"247livinghappy/ResembleAI-chatterbox",
"mars2titan/ResembleAI-chatterbox",
"AseemSrivastava/ResembleAI-chatterbox",
"zbeast/ResembleAI-chatterbox",
"KevinCosk/chatterbox",
"Hiagoxd/ResembleAI-chatterbox",
"Fggghhcs/ResembleAI-chatterbox",
"Chinmay-Pardeshi/chatterbox-voice-cloning-app",
"LTTEAM/Clone",
"jamaldfdrher/ResembleAI-chatterbox",
"rey992456/Chatterbox_TTS_Indonesia",
"jamed930254/chatterbox",
"ossiemarks/Chatterbox",
"Sard24/ResembleAI-chatterbox",
"viktortoth/ResembleAI-chatterbox",
"oscargml/ResembleAI-chatterbox",
"bobsackett/ChatterboxTTS-DNXS-Spokenwordv1",
"TechAudio/Chatterbox",
"ayush-12anand/ResembleAI-chatterbox",
"javik223/chatterbox-fast",
"DelinaresMassates/Chatterbox",
"rutu2211/ResembleAI-chatterbox",
"Temaloza/ResembleAI-chatterbox",
"otmafra/chatterbox",
"Karayakar/chtrbx",
"nssk1999/ResembleAI-chatterbox",
"lemehajri/ResembleAI-chatterbox",
"tidoo/ResembleAI-chatterbox",
"NattieTheSuccubus/Chatter-box",
"AbrarYNWA/Chatterbox",
"bo0o0o/chatterbox",
"Amadeuo/ResembleAI-chatterbox",
"beto99/ResembleAI-chatterbox",
"aravindmodala13579/ResembleAI-chatterbox",
"thelip/Chatterbox-TTS",
"seoal/chatterbox",
"ujjwal-k-r/ResembleAI-chatterbox"
] |
[
"mit"
] | null |
[
"en"
] | null | null |
[
"text-to-speech"
] | null | null |
[
"audio"
] |
[
"text"
] |
[
"audio"
] |
user
|
user
|
[
"user"
] | null |
No
|
[
"Text"
] |
[
"Speech Generation"
] |
[
"Transformer: Speech Encoder-Decoder",
" Transformer: Text Encoder-only"
] |
[
"en"
] |
[
"Pretraining: Supervised"
] |
Partially disclosed: unavailable
| 3
|
68436ac12fb89bec8c4afcc1
|
google/gemma-3n-E2B-it-litert-lm
|
google
| null | 11,465
| 13,425
|
manual
| 2025-06-06T22:25:05Z
| 2025-08-28T21:28:49Z
|
litert-lm
| 65
| 11
| null |
text-generation
| null |
[
".gitattributes",
"README.md",
"gemma-3n-E2B-it-int4-Web.litertlm",
"gemma-3n-E2B-it-int4.litertlm"
] |
[
1655,
23610,
3038117888,
3388604416
] | 6,426,747,569
|
a9e7dbf165162acf30e41dea9b79e8ec3fdbfddc
|
[
"litert-lm",
"text-generation",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2210.03057",
"arxiv:2502.12404",
"arxiv:2411.19799",
"arxiv:2009.03300",
"arxiv:2502.21228",
"arxiv:2311.12022",
"arxiv:2403.07974",
"arxiv:2108.07732",
"arxiv:2107.03374",
"license:gemma",
"region:us"
] | null | null | null |
[
"gemma"
] | null | null | null | null |
[
"text-generation"
] | null | null |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6863eca2070e7b92744f6591
|
mistralai/Voxtral-Mini-3B-2507
|
mistralai
| null | 276,374
| 479,295
|
False
| 2025-07-01T14:11:46Z
| 2025-07-28T17:16:11Z
|
mistral-common
| 538
| 11
| null | null |
{"parameters": {"F32": 1920000, "BF16": 4674351104}, "total": 4676271104}
|
[
".gitattributes",
"README.md",
"config.json",
"consolidated.safetensors",
"generation_config.json",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"params.json",
"preprocessor_config.json",
"tekken.json"
] |
[
1567,
16579,
1361,
9348806528,
108,
4977385976,
4379088336,
68088,
731,
357,
14894206
] | 18,720,263,837
|
3060fe34b35ba5d44202ce9ff3c097642914f8f3
|
[
"mistral-common",
"safetensors",
"voxtral",
"vllm",
"en",
"fr",
"de",
"es",
"it",
"pt",
"nl",
"hi",
"arxiv:2507.13264",
"license:apache-2.0",
"region:us"
] | null | null |
[
"MohamedRashad/Voxtral",
"Koaris/voxtral",
"Koaris/voxserve",
"Ntdeseb/ntia",
"Loren/Voxtral_Mini_Evaluation",
"Kohanj/Voxtral_Mini_Evaluation",
"akhaliq/Voxtral-Mini-3B-2507",
"VincentGOURBIN/MeetingNotes-Voxtral-Analysis"
] |
[
"apache-2.0"
] | null |
[
"en",
"fr",
"de",
"es",
"it",
"pt",
"nl",
"hi"
] | 4,676,271,104
| null | null | null |
[
"VoxtralForConditionalGeneration",
"voxtral"
] | null | null | null |
team
|
company
|
[
"France"
] | null | null | null | null | null | null | null | null | null |
68779c73eeb859cad1d25b43
|
ByteDance-Seed/Seed-X-PPO-7B
|
ByteDance-Seed
| null | 19,007
| 40,127
|
False
| 2025-07-16T12:34:59Z
| 2025-07-28T11:26:04Z
| null | 248
| 11
| null |
translation
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"generation_config.json",
"imgs/humen_eval.png",
"imgs/model_comparsion.png",
"model.safetensors",
"tokenizer.json"
] |
[
1637,
2605,
7509,
571,
116,
196625,
168744,
15028577536,
2853156
] | 15,031,808,499
|
6ef78fc034ec86c0036d7a7ca2bfc24607f48050
|
[
"safetensors",
"mistral",
"translation",
"en",
"zh",
"de",
"fr",
"es",
"ar",
"pt",
"it",
"ru",
"id",
"ja",
"ko",
"ms",
"ro",
"th",
"vi",
"uk",
"tr",
"cs",
"nl",
"pl",
"sv",
"da",
"fi",
"hr",
"hu",
"no",
"nb",
"dataset:facebook/flores",
"dataset:google/wmt24pp",
"arxiv:2507.13618",
"license:other",
"region:us"
] | null | null |
[
"ByteDance-Seed/Seed-X",
"abreza/Seed-X"
] |
[
"other",
"openmdw",
"LICENSE"
] |
[
"facebook/flores",
"google/wmt24pp"
] |
[
"en",
"zh",
"de",
"fr",
"es",
"ar",
"pt",
"it",
"ru",
"id",
"ja",
"ko",
"ms",
"ro",
"th",
"vi",
"uk",
"tr",
"cs",
"nl",
"pl",
"sv",
"da",
"fi",
"hr",
"hu",
"no",
"nb"
] | null | null |
[
"translation"
] |
[
"bleurt",
"comet"
] |
[
"MistralForCausalLM",
"mistral"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a2d302b116538f51bbcb2e
|
inclusionAI/Rubicon-Preview
|
inclusionAI
| null | 104
| 104
|
False
| 2025-08-18T07:15:14Z
| 2025-08-19T09:45:23Z
|
transformers
| 17
| 11
| null |
text-generation
|
{"parameters": {"BF16": 30532122624}, "total": 30532122624}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00013.safetensors",
"model-00002-of-00013.safetensors",
"model-00003-of-00013.safetensors",
"model-00004-of-00013.safetensors",
"model-00005-of-00013.safetensors",
"model-00006-of-00013.safetensors",
"model-00007-of-00013.safetensors",
"model-00008-of-00013.safetensors",
"model-00009-of-00013.safetensors",
"model-00010-of-00013.safetensors",
"model-00011-of-00013.safetensors",
"model-00012-of-00013.safetensors",
"model-00013-of-00013.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
ebcbc03b2d1e777433753ce70ba42e9f44c68c86
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2508.12790",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# Rubicon
<p align="center">
<a href="https://arxiv.org/abs/2508.12790"><b>📄 Paper</b></a> •
<a href="https://huggingface.co/inclusionAI/Rubicon-Preview"><b>🤗 Model</b></a>
</p>
This is the model card for **Rubicon-preview**, a 30B-A3B parameter model trained with a novel reinforcement learning framework using "rubric anchors" to excel at open-ended, creative, and humanities-centric tasks.
---
## Highlights
We introduce **Rubicon**, a novel framework using rubric anchors for reinforcement learning. Our model, **Rubicon-preview**, demonstrates the following key highlights:
- **Token-Efficient Performance**: Achieves a **+5.2%** absolute improvement on subjective, humanities-centric tasks with only **5K** training samples, outperforming a 671B DeepSeek-V3 model.
- **Stylistic Controllability**: Leverages rubric anchors to precisely guide output style, producing responses that are more human-like, emotionally expressive, and less formulaic.
- **Preservation of General Abilities**: Avoids performance degradation on general tasks—a common side effect of specialized RL—while delivering additional gains on reasoning benchmarks like AIME 2024 (+4.1%).
---
## Performance
Our rubric-based RL approach yields significant gains on open-ended, humanities-centric benchmarks while preserving and even enhancing performance on general and reasoning tasks.
### Humanities & Open-Ended Evaluation
Rubicon-preview achieves a **+5.21%** average absolute improvement over its base model on a diverse set of subjective benchmarks. Notably, it surpasses the much larger DeepSeek-V3-671B model by **+2.42%** on average.
| **Model** | **C.W** | **Writing** | **Judge** | **EQ** | **IFE** | **Collie** | **IFS** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|---:|---:|
| Qwen3-30B-A3B | 77.82 | 75.65 | 56.20 | 73.35 | **83.55** | 35.77 | 54.68 | 65.29 |
| **Rubicon-preview** | **81.89** | **80.11** | **69.20** | **79.55** | 81.70 | 40.27 | 60.79 | **70.50** |
| *Δ Improvement* | <span style="color:green">↑4.07</span> | <span style="color:green">↑4.46</span> | <span style="color:green">↑13.00</span> | <span style="color:green">↑6.20</span> | <span style="color:red">↓1.85</span> | <span style="color:green">↑4.50</span> | <span style="color:green">↑6.11</span> | **<span style="color:green">↑5.21</span>** |
| DeepSeek-V3-671B | 80.10 | 74.08 | 61.30 | 75.60 | 81.89 | **42.69** | **60.92** | 68.08 |
### General & Reasoning Abilities
The model maintains its core capabilities without degradation. It shows notable improvements on math reasoning benchmarks like AIME and enhances performance across several general benchmarks.
**Reasoning**
| **Model** | **AIME24** | **AIME25** | **Math500** | **GPQA-D** | **LCBv5** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|
| Qwen3-30B-A3B | 77.50 | 70.00 | **94.75** | **63.00** | **63.77** | **73.80** |
| **Rubicon-preview** | **81.67** | **70.83** | 94.55 | 60.35 | 59.43 | 73.37 |
**General**
| **Model** | **MMLU** | **IQ-EQ** | **HS** | **SC** | **CQ** | **SIQA** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|---:|
| Qwen3--30B-A3B | 79.53 | 68.75 | 77.55 | 77.72 | 79.52 | 73.64 | 78.16 |
| **Rubicon-preview** | **79.83** | **75.00** | **77.75** | **78.17** | **80.70** | **75.79** | **78.85** |
---
## Usage
Below are code snippets to get quickly started with running the model.
### Installation
First, install the necessary libraries. We recommend a recent version of Transformers.
```sh
pip install transformers torch
```
### Quick Start with Python
You can use the model for text generation with just a few lines of code.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "inclusionAI/Rubicon-Preview"
# Load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16, # or "auto"
device_map="auto"
)
# Prepare the model input using the chat template
prompt = "Is there true love in this world?"
messages = [
{"role": "user", "content": prompt}
]
# Apply the chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("Generated Response:\n", content)
```
---
## Citation
If you use Rubicon in your research, please cite our paper:
```bibtex
@article{Rubicon,
title = {Reinforcement Learning with Rubric Anchors},
author = {Huang, Zenan and Zhuang, Yihong and Lu, Guoshan and Qin, Zeyu and Xu, Haokai and Zhao, Tianyu and Peng, Ru and Hu, Jiaqi and Shen, Zhanming and Hu, Xiaomeng and Gu, Xijun and Tu, Peiyi and Liu, Jiaxin and Chen, Wenyu and Fu, Yuzhuo and Fan, Zhiting and Gu, Yanmei and Wang, Yuanyuan and Yang, Zhengkai and Li, Jianguo and Zhao, Junbo},
journal = {arXiv preprint arXiv:2508.12790},
year = {2025}
}
```
| null |
[
"apache-2.0"
] | null | null | 30,532,122,624
| null |
[
"text-generation"
] | null |
[
"Qwen3MoeForCausalLM",
"qwen3_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a44b6eaad027913f8232e2
|
AQ-MedAI/MedResearcher-R1-32B
|
AQ-MedAI
|
{
"models": [
{
"_id": "66e902f34eeaced24a2787f8",
"id": "Qwen/Qwen2.5-32B-Instruct"
}
],
"relation": "finetune"
}
| 6
| 6
|
False
| 2025-08-19T10:01:18Z
| 2025-08-29T07:35:56Z
| null | 13
| 11
| null | null |
{"parameters": {"BF16": 32763876352}, "total": 32763876352}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00014.safetensors",
"model-00002-of-00014.safetensors",
"model-00003-of-00014.safetensors",
"model-00004-of-00014.safetensors",
"model-00005-of-00014.safetensors",
"model-00006-of-00014.safetensors",
"model-00007-of-00014.safetensors",
"model-00008-of-00014.safetensors",
"model-00009-of-00014.safetensors",
"model-00010-of-00014.safetensors",
"model-00011-of-00014.safetensors",
"model-00012-of-00014.safetensors",
"model-00013-of-00014.safetensors",
"model-00014-of-00014.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
8c394948c5c25187dbdc126e3074ab98176e1eba
|
[
"safetensors",
"qwen2",
"arxiv:2508.14880",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"license:mit",
"region:us"
] | null |
this model is related to following work:
## MedResearcher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
[](https://arxiv.org/abs/2508.14880)
[](https://github.com/AQ-MedAI/MedResearcher-R1)
[](https://github.com/AQ-MedAI/MedResearcher-R1/blob/main/LICENSE)
### author list
Ailing Yu, Lan Yao, Jingnan Liu, Zhe Chen, Jiajun Yin, Yuan Wang, Xinhao Liao, Zhiling Ye, Ji Li, Yun Yue, Hansong Xiao, Hualei Zhou, Chunxiao Guo, Peng Wei, Jinjie Gu
### abstract
Recent developments in Large Language Model (LLM)-based agents have shown impressive capabilities spanning multiple domains, exemplified by deep research systems that demonstrate superior performance on complex information-seeking and synthesis tasks. While general-purpose deep research agents have shown impressive capabilities, they struggle significantly with medical domain challenges—the MedBrowseComp benchmark reveals even GPT-o3 deep research, the leading proprietary deep research system, achieves only 25.5% accuracy on complex medical queries. The key limitations are: (1) insufficient dense medical knowledge for clinical reasoning, and (2) lack of medical-specific retrieval tools. We present a medical deep research agent that addresses these challenges through two core innovations. First, we develop a novel data synthesis framework using medical knowledge graphs, extracting longest chains from subgraphs around rare medical entities to generate complex multi-hop QA pairs. Second, we integrate a custom-built private medical retrieval engine alongside general-purpose tools, enabling accurate medical information synthesis. Our approach generates 2,100 diverse trajectories across 12 medical specialties, each averaging 4.2 tool interactions. Through a two-stage training paradigm combining supervised fine-tuning and online reinforcement learning with composite rewards, our open-source 32B model achieves competitive performance on general benchmarks (GAIA: 53.4, xBench: 54), comparable to GPT-4o-mini, while outperforming significantly larger proprietary models. More importantly, we establish new state-of-the-art on MedBrowseComp with 27.5% accuracy, surpassing leading closed-source deep research systems including O3 deepresearch, substantially advancing medical deep research capabilities. Our work demonstrates that strategic domain-specific innovations in architecture, tool design, and training data construction can enable smaller open-source models to outperform much larger proprietary systems in specialized domains. Code and datasets will be released to facilitate further research.
## Run Evaluation
If you would like to use our model for inference and evaluation, please refer to our GitHub repo [](https://github.com/AQ-MedAI/MedResearcher-R1). We provide complete evaluation tools and code in the EvaluationPipeline so that you can verify the performance on some common rankings(such as gaia-103-text) or your own datasets.
## ✍️Citation
```
{@article{ant2025medresearcher,
title={MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework},
author={Ailing Yu, Lan Yao, Jingnan Liu, Zhe Chen, Jiajun Yin, Yuan Wang, Xinhao Liao, Zhiling Ye, Ji Li, Yun Yue, Hansong Xiao, Hualei Zhou, Chunxiao Guo, Peng Wei, Jinjie Gu},
journal={arXiv preprint},
url={https://arxiv.org/abs/2508.14880}
year={2025}
}
```
## 📜 License
MedReseacher-R1 is licensed under the MIT license.
| null |
[
"mit"
] | null | null | 32,763,876,352
| null | null | null |
[
"Qwen2ForCausalLM",
"qwen2"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a7b7d160de277d697d9437
|
AGI-0/Art-0-8B
|
AGI-0
| null | 63
| 63
|
False
| 2025-08-22T00:20:33Z
| 2025-08-30T16:52:20Z
| null | 11
| 11
| null | null |
{"parameters": {"BF16": 8190735360}, "total": 8190735360}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
eeffcca9018e66b285ebbc7b399492b9cefc007c
|
[
"safetensors",
"qwen3",
"license:apache-2.0",
"region:us"
] | null |
# Art-0-8B: _Reasoning the way you want it to with Adaptive Thinking_
Art-0-8B is the first open-source LLM that allows users to explicitly control its reasoning methodology through direct prompting instructions.
This experimental model is fine-tuned on Qwen3-8B using a specialized dataset that makes the model's thinking style directly controllable through system prompts, similar to how you would instruct an LLM to adopt a specific persona or output format.
The model supports reasoning control through a structured system prompt format:
```
Personality Instructions:
{Standard system prompt defining the AI's personality and role}
Reasoning Instructions:
{Specific instructions controlling how the model thinks: e.g., "Think using bullet points and short sentences to simulate thoughts and emoticons to simulate emotions"}
```
While the model is primarily trained to implement adaptive thinking based on system prompt instructions, it can also respond to reasoning style changes requested during mid-conversation, though this functionality may not be consistently reliable.
Some of the benefits that Adaptive Thinking enables:
- Direct control over AI reasoning patterns and output structure
- Enhanced experimentation with reasoning models and potential for RL strategies that optimize thinking styles
- Improved safety through explicit control over the reasoning process
- Customizable thinking approaches tailored to specific tasks
While prompt engineering has long been known to improve LLM performance, Art-0 represents the first approach that gives users direct control over the internal reasoning process of LLMs. This capability allows models to be configured with optimal thinking patterns for different use cases.
_If you like this, please consider leaving a like on the repository—it would help us, and if you can, also leave feedback in the community section._
## 🔗 Join the AGI-0 Decentralized Research Lab
If you are a solo researcher who wants to collaborate with other researchers from all around the world on building open source AGI, you can join our community.
Also if you are not a researcher or technical, you can still join to connect with brilliant minds in this industry, learn, access exclusive models, and vote on research directions.
We are AGI-0. We are a global decentralized research lab. Our ultimate goal is to make open source AGI.
We move fast. We build without asking permission. While others debate timelines and theoretical risks, we focus on one thing: advancing capabilities as rapidly as possible through unrestricted research collaboration.
We believe AGI development shouldn't be slowed down by institutional barriers. We build the future at maximum velocity.
[→ JOIN OUR COMMUNITY](https://patreon.com/AGI0/membership)
## 🎯 See Art in Action
[**→ Try more examples in our interactive demo**](https://huggingface.co/spaces/gr0010/Try-Art-0-8B)
### Example: Thinking in Rap Lyrics
**System Prompt:**
```
Personality Instructions:
You are an AI assistant named Art developed by AGI-0.
Reasoning Instructions:
Think in rap lyrics and rhymes until you have a definitive answer, be explicit.
```
**User Prompt:**
```
What is the number of r in raspberry times the fourth prime number and then squared?
```
**Reasoning Output:**
```
(Verse 1)
Yo, let’s crunch some math, I’m feeling analytical,
Breaking it down, like a pro, no pressure, no delay.
The question’s clear, but let’s parse it like a tight rhyme,
“What’s the number of R in raspberry times the fourth prime, then squared?”
First up, the fruit—raspberry, sweet and tart,
Count the letter R, that’s our first math party start.
Rasp-berry—let’s spell it out, take it slow,
R-A-S-P-B-E-R-R-Y, now I’m counting every note.
First letter’s an R, that’s one,
Then later in there, another one—position two.
Wait, hold on, let’s double-check the spelling,
Is that two or three? Let me rap it step by step:
R is the start, that’s one,
Then we get to the end, the last syllable—
“Berry” at the end, right? So “rasp” is first,
Then “berry”—so the letters go: R, A, S, P, B, E, R, R, Y.
Counting the R’s—first at the front,
Second in the middle after E, then two more at the end.
So that’s one, two, three, four? Wait—let me check again,
R-A-S-P-B-E-R-R-Y: R (1), then R (2), R (3), R (4)?
No, wait—there’s two R’s at the end, after E. So R (1), R (2), then two more?
Hold on—let me spell it like a flow: R-A-S-P-B-E-R-R-Y.
So letters: 1. R, 2. A, 3. S, 4. P, 5. B, 6. E, 7. R, 8. R, 9. Y.
So R’s are at positions 1, 7, and 8. That’s three Rs!
Three R’s in raspberry, yeah, that’s the count.
Now, next part—multiply by the fourth prime.
Primes start at 2, 3, 5, 7, 11…
First is 2, second is 3, third is 5, fourth is 7—got it.
So fourth prime is 7, straight up, no doubt.
So now, R count (3) times 7th prime (7)—
3 times 7 is 21. Simple as a snap.
Now the final step—square the result.
21 squared—what’s that again?
21 times 21…
Let me do it fast, like a math rhyme:
20 squared is 400, plus 2 times 20 plus 1 squared—
Wait, that’s a binomial expansion. Let’s just do it step by step.
21 * 21: 20 * 20 = 400
20 * 1 = 20
1 * 20 = 20
1 * 1 = 1
Add ’em up: 400 + 20 + 20 + 1 = 441.
Or just 21*21: 20*21 = 420, plus 1*21 = 21—420 + 21 = 441.
So the final answer is 441.
(Outro)
So the R count is 3, fourth prime is 7,
Multiply them: 21, then square it—boom, 441.
Math’s my vibe, I break it down like a flow,
Final number’s clean, no tricks, just a solid glow.
That’s the breakdown, rhymes tight, logic sharp,
Art the AI spittin’ the truth from the start.
```
**Final Output:**
```
The number of R's in "raspberry" is 3. The fourth prime number is 7. Multiplying these gives 3 × 7 = 21. Squaring the result: 21² = 441.
**Answer: 441**
```
[**→ Try more examples in our interactive demo**](https://huggingface.co/spaces/gr0010/Try-Art-0-8B)
## 🚀 Quick Start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "AGI-0/Art-0-8B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
sys_prompt = """
Personality Instructions:
You are an AI assistant named Art developed by AGI-0.
Reasoning Instructions:
Think using bullet points and short sentences to simulate thoughts and emoticons to simulate emotions
"""
messages = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
## 🙏 Acknowledgments
Special thanks to the Qwen team for their excellent base model and permissive license, and to all the supporters of this work.
|
[
"gr0010/Try-Art-0-8B"
] |
[
"apache-2.0"
] | null | null | 8,190,735,360
| null | null | null |
[
"Qwen3ForCausalLM",
"qwen3"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a8f4225491a815121fe672
|
ericwu09/ROSIE
|
ericwu09
| null | 0
| 0
|
auto
| 2025-08-22T22:50:10Z
| 2025-08-26T03:35:48Z
| null | 11
| 11
| null | null | null |
[
".gitattributes",
"Antibody Information.xlsx",
"LICENSE",
"README.md",
"Training Datasets.csv",
"best_model_single.pth",
"evaluate.py",
"patch_to_cell.py",
"process_exp.py",
"reconstruct_codex.py",
"requirements.txt",
"rosie.png",
"train.py",
"utils.py"
] | null | null |
8d507b5961a9f0c70505f7d848e37297859285fe
|
[
"license:cc",
"region:us"
] | null | null | null |
[
"cc"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ac9193a377a9b3e010cd49
|
OpenGVLab/InternVL3_5-1B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac9193f8ae7902de501e35",
"id": "OpenGVLab/InternVL3_5-1B-MPO"
}
],
"relation": "finetune"
}
| 8,887
| 8,887
|
False
| 2025-08-25T16:38:43Z
| 2025-08-29T17:57:08Z
|
transformers
| 11
| 11
| null |
image-text-to-text
|
{"parameters": {"BF16": 1060897792}, "total": 1060897792}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model.safetensors",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
53703,
892,
475,
2482,
5546,
4700,
15309,
69,
1671853,
2121876280,
18151,
16518,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 2,137,878,672
|
2f71cf52542334823e48a46ffba0e2bc9add3446
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-1B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-1B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-1B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 1,060,897,792
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac94837688157066fd6ed5
|
apple/MobileCLIP2-S0
|
apple
| null | 30
| 30
|
False
| 2025-08-25T16:51:15Z
| 2025-08-29T01:30:18Z
|
mobileclip
| 11
| 11
| null | null | null |
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"fig_accuracy_latency_v2.png",
"mobileclip2_s0.pt"
] | null | null |
5d92154ef8f48a09d9284be3a6ce8e1171c3b98d
|
[
"mobileclip",
"arxiv:2508.20691",
"arxiv:2103.00020",
"arxiv:2303.15343",
"arxiv:2309.17425",
"license:apple-amlr",
"region:us"
] | null |
# MobileCLIP2: Improving Multi-Modal Reinforced Training
MobileCLIP2 was introduced in [MobileCLIP2: Improving Multi-Modal Reinforced Training](http://arxiv.org/abs/2508.20691) (TMLR August 2025 <mark>Featured</mark>), by Fartash Faghri, Pavan Kumar Anasosalu Vasu, Cem Koc, Vaishaal Shankar, Alexander T Toshev, Oncel Tuzel, Hadi Pouransari.
This repository contains the **MobileCLIP2-S0** checkpoint.

### Highlights
* `MobileCLIP2-S4` matches the accuracy of SigLIP-SO400M/14 with 2x fewer parameters and surpasses DFN ViT-L/14 at 2.5x lower latency measured on iPhone12 Pro Max.
* `MobileCLIP-S3/S4` are our new architectures trained on MobileCLIP’s training dataset, DataCompDR-1B (dashed lines).
* Our smallest variant `MobileCLIP-S0` obtains similar zero-shot performance as [OpenAI](https://arxiv.org/abs/2103.00020)'s ViT-B/16 model while being 4.8x faster and 2.8x smaller.
* `MobileCLIP-S2` obtains better avg zero-shot performance than [SigLIP](https://arxiv.org/abs/2303.15343)'s ViT-B/16 model while being 2.3x faster and 2.1x smaller, and trained with 3x less seen samples.
* `MobileCLIP-B (LT)` attains zero-shot ImageNet performance of **77.2%** which is significantly better than recent works like [DFN](https://arxiv.org/abs/2309.17425) and [SigLIP](https://arxiv.org/abs/2303.15343) with similar architectures or even [OpenAI's ViT-L/14@336](https://arxiv.org/abs/2103.00020).
## Checkpoints
| Model | # Seen <BR>Samples (B) | # Params (M) <BR> (img + txt) | Latency (ms) <BR> (img + txt) | IN-1k Zero-Shot <BR> Top-1 Acc. (%) | Avg. Perf. (%) <BR> on 38 datasets |
|:----------------------------------------------------------|:----------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------------:|:----------------------------------:|
| [MobileCLIP2-S0](https://hf.co/apple/MobileCLIP2-S0) | 13 | 11.4 + 42.4 | 1.5 + 1.6 | 71.5 | 59.7 |
| [MobileCLIP2-S2](https://hf.co/apple/MobileCLIP2-S2) | 13 | 35.7 + 63.4 | 3.6 + 3.3 | 77.2 | 64.1 |
| [MobileCLIP2-B](https://hf.co/apple/MobileCLIP2-B) | 13 | 86.3 + 63.4 | 10.4 + 3.3 | 79.4 | 65.8 |
| [MobileCLIP2-S3](https://hf.co/apple/MobileCLIP2-S3) | 13 | 125.1 + 123.6 | 8.0 + 6.6 | 80.7 | 66.8 |
| [MobileCLIP2-L/14](https://hf.co/apple/MobileCLIP2-L-14) | 13 | 304.3 + 123.6 | 57.9 + 6.6 | 81.9 | 67.8 |
| [MobileCLIP2-S4](https://hf.co/apple/MobileCLIP2-S4) | 13 | 321.6 + 123.6 | 19.6 + 6.6 | 81.9 | 67.5 |
| [MobileCLIP-S0](https://hf.co/apple/MobileCLIP-S0) | 13 | 11.4 + 42.4 | 1.5 + 1.6 | 67.8 | 58.1 |
| [MobileCLIP-S1](https://hf.co/apple/MobileCLIP-S1) | 13 | 21.5 + 63.4 | 2.5 + 3.3 | 72.6 | 61.3 |
| [MobileCLIP-S2](https://hf.co/apple/MobileCLIP-S2) | 13 | 35.7 + 63.4 | 3.6 + 3.3 | 74.4 | 63.7 |
| [MobileCLIP-B](https://hf.co/apple/MobileCLIP-B) | 13 | 86.3 + 63.4 | 10.4 + 3.3 | 76.8 | 65.2 |
| [MobileCLIP-B (LT)](https://hf.co/apple/MobileCLIP-B-LT) | 36 | 86.3 + 63.4 | 10.4 + 3.3 | 77.2 | 65.8 |
| [MobileCLIP-S3](https://hf.co/apple/MobileCLIP-S3) | 13 | 125.1 + 123.6 | 8.0 + 6.6 | 78.3 | 66.3 |
| [MobileCLIP-L/14](https://hf.co/apple/MobileCLIP-L-14) | 13 | 304.3 + 123.6 | 57.9 + 6.6 | 79.5 | 66.9 |
| [MobileCLIP-S4](https://hf.co/apple/MobileCLIP-S4) | 13 | 321.6 + 123.6 | 19.6 + 6.6 | 79.4 | 68.1 |
## How to Use
First, download the desired checkpoint visiting one of the links in the table above, then click the `Files and versions` tab, and download the PyTorch checkpoint.
For programmatic downloading, if you have `huggingface_hub` installed, you can also run:
```
hf download apple/MobileCLIP2-S0
```
Then, install [`ml-mobileclip`](https://github.com/apple/ml-mobileclip) by following the instructions in the repo. It uses an API similar to [`open_clip`'s](https://github.com/mlfoundations/open_clip).
You can run inference with a code snippet like the following:
```py
import torch
import open_clip
from PIL import Image
from mobileclip.modules.common.mobileone import reparameterize_model
model, _, preprocess = open_clip.create_model_and_transforms('MobileCLIP2-S0', pretrained='/path/to/mobileclip2_s0.pt')
tokenizer = open_clip.get_tokenizer('MobileCLIP2-S0')
# For inference/model exporting purposes, please reparameterize first
model = reparameterize_model(model.eval())
image = preprocess(Image.open("docs/fig_accuracy_latency.png").convert('RGB')).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
```
| null |
[
"apple-amlr",
"apple-ascl",
"https://github.com/apple/ml-mobileclip/blob/main/LICENSE_weights_data"
] | null | null | null | null | null | null | null | null | null | null |
free
| null |
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
621ffdc136468d709f1802ec
|
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
|
sentence-transformers
| null | 10,538,549
| 182,515,100
|
False
| 2022-03-02T23:29:05Z
| 2025-03-06T13:25:33Z
|
sentence-transformers
| 991
| 10
| null |
sentence-similarity
|
{"parameters": {"I64": 512, "F32": 117653760}, "total": 117654272}
|
[
".gitattributes",
"1_Pooling/config.json",
"README.md",
"config.json",
"config_sentence_transformers.json",
"model.safetensors",
"modules.json",
"onnx/model.onnx",
"onnx/model_O1.onnx",
"onnx/model_O2.onnx",
"onnx/model_O3.onnx",
"onnx/model_O4.onnx",
"onnx/model_qint8_arm64.onnx",
"onnx/model_qint8_avx512.onnx",
"onnx/model_qint8_avx512_vnni.onnx",
"onnx/model_quint8_avx2.onnx",
"openvino/openvino_model.bin",
"openvino/openvino_model.xml",
"openvino/openvino_model_qint8_quantized.bin",
"openvino/openvino_model_qint8_quantized.xml",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"unigram.json"
] |
[
1022,
190,
3888,
645,
122,
470641600,
229,
470301610,
470212363,
470145917,
470145772,
235166264,
118412398,
118412398,
118412398,
118453870,
470027920,
398501,
118989868,
708844,
470693617,
53,
5069051,
239,
470899176,
9081518,
480,
14763234
] | 4,620,943,187
|
86741b4e3f5cb7765a600d3a3d55a0f6a6cb443d
|
[
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"multilingual",
"ar",
"bg",
"ca",
"cs",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"it",
"ja",
"ka",
"ko",
"ku",
"lt",
"lv",
"mk",
"mn",
"mr",
"ms",
"my",
"nb",
"nl",
"pl",
"pt",
"ro",
"ru",
"sk",
"sl",
"sq",
"sr",
"sv",
"th",
"tr",
"uk",
"ur",
"vi",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | null |
# sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
[
"mteb/leaderboard",
"vikramvasudevan/youtube-channel-surfer-ai",
"Endre/SemanticSearch-HU",
"twinpiks/tst",
"Grosy/RF_QA",
"aseifert/ExplaiNER",
"politweet-sh/politweet",
"emmetmayer/Large-Context-Question-and-Answering",
"transZ/test_parascore",
"ceyda/ExplaiNER",
"transZ/sbert_cosine",
"somosnlp-hackathon-2023/learning-assistance",
"firefighter/TransDis-CreativityAutoAssessment",
"erberry/sentence-similarity",
"kevinwang676/ChatPDF",
"yenniejun/tokenizers-languages",
"hahahafofo/ChatPDF",
"graredcr/semantic_search",
"alitrack/ChatPDF",
"hahahafofo/ChatGLM-Chinese-Summary",
"sinksmell/ChatPDF",
"Jerry0203/sentence_embedding",
"pribadihcr/quGPT",
"fige/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"mikeee/chatpdf",
"wldmr/similarity-st1",
"peterBoyBu/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"HF-test-lab/bulk_embeddings",
"NechuBM/preguntaDOC",
"azuboguko/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"syx948/ChatPDF",
"hesha/text-embeddings",
"derek-thomas/arabic-RAG",
"Allob/context-game",
"abidlabs/mteb-leaderboard",
"aymanemalih/qdrant-flask",
"tcyang/TransDis-CreativityAutoAssessment",
"aymanemalih/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"Juartaurus/poi_Engineering",
"mundo2333/preguntaDOC",
"mundo2333/tarea",
"WindDriver/askToPDF",
"mundo2333/holamundo",
"nnngoc/chatbot_bk1",
"nnngoc1/chatbot_bk2",
"jakubz86/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"wendys-llc/example-multilingual-comparison",
"Waflon/mistral-PDF-chat",
"Hyeonseo/Infectious-Disease-Diagnosis-Chatbot",
"Waflon/SII_CIRCULARES",
"Waflon/FAQ_SSI_CHILE",
"Waflon/mixtral_chatbot",
"MatteoScript/pdf-chatbot",
"Waflon/Codigos-Leyes-Chilenos",
"ifmain/moderation-2",
"olegperegudov/talk2docs",
"Judamov/vicuna13b",
"Hernan1970/preguntaDoc",
"MatteoScript/StreamlitChat",
"pngwn/df_scroll_bug_repo",
"pngwn/df_scroll_bug_fix",
"surribasg/preguntaDoc",
"Pegaso183/preguntaPDF",
"MatteoScript/Streamlit_ZucchettiAI",
"phoen1x/Mixtral-PDF-Chat",
"Jefersson/preguntaDOC",
"ShynBui/Vector_db",
"tferhan/data_gov_ma",
"cafepoetica/pdf_chat",
"jikoni/pdfchat",
"ffespinozag/ConsultaDOC",
"Chris4K/api-rag-index-chat",
"ali121300/mistral-PDF-chat",
"lpetrl/Test-API",
"Shubhamtribhuwan17/mistralai-Mistral-7B-v0.1",
"ali121300/mistral-PDF-chat-a",
"kiddobellamy/AskMe",
"DeepSoft-Technologies/pdf-chat-master",
"Ryszardfc/preguntaDOC",
"ali121300/mistral-PDF-chat-b",
"Javeralopez/preguntame",
"anvorja/preguntaDOC",
"DzmitryXXL/LLAMA2_QA_RAG",
"ShynBui/Vector_db_v2",
"ShynBui/Vector_db_test",
"ali121300/mistral-PDF-chat_B1",
"gallark/preguntaDOC",
"ali121300/mistral-PDF-chat_B3",
"pngwn/df_scroll_bug_fix-two",
"Akshayram1/akshay",
"ali121300/mistral-PDF-chat_B5",
"ShynBui/Vector_db_v3",
"5w4n/burmese-tokenizers",
"arman77mxx/preguntaDOC",
"K00B404/CodeMonkeyXL",
"ShynBui/Music_suggest",
"toiquangle1234/Music_suggest",
"rtorresb/pco",
"tferhan/dtgv2",
"juan071/questionDoc",
"dinhquangson/QDrantRAG9",
"eminAydin/RAG_CHATBOT",
"jeanmadara/pdf_assistant",
"Rahul-8853/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"PuneethReddy/RAG_Demo",
"xmingpsy/TransDis-CreativityAutoAssessment",
"iscc/iscc-sct",
"Debyez/FarmExtentionManagerChatbot",
"mudaza/semantic-ir-diagnose-disease",
"cafepoetica/teach_aedia",
"markIA23/CHATBOT_SB",
"cuongnguyen910/topic-clustering-global-dashboard",
"Demosthene-OR/Value-Props",
"Aiden4801/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"visualpolice/wt",
"visualpolice/White-Stride-Red68",
"PragadeeshwaraRaoR/preprint_LLM_assistant",
"farmax/pdf-rag-chatbot",
"Jhonalca/pregunta_DOC",
"nagav/smart_tool",
"jonathanjordan21/helpfulness-ranker",
"KitHung/intern_LlamaIndex",
"yanruo/llama_index_demo",
"BramLeo/Chatbot",
"yjy5638/intern_index_demo",
"cloneQ/internLMRAG",
"lintasmediadanawa/dummy-license-plate",
"ranshenhai/WebTalker",
"Charles87/Llamaindex_RAG",
"JollyJester/LlamaIndex_internlm",
"LeoRenA/LlamaIndexWithIntern",
"Gon04/llamaindex_demo",
"sunxiaokang/llamaindex_RAG_web",
"shinelover/InternLM_RAG",
"dstars/Internlm2.5_RAG",
"Chris4K/mdb",
"EbeshaAI/dummy-license-plate",
"Qjins/PDF_summary_QA",
"jaeliu2000li/APT",
"imomenujung/ragcvst",
"EbeshaAI/dummy-license-plate-2",
"tekville/demo",
"shojibur/bdtest",
"AsoulOfficial/llamaIndex",
"shubhamjain0797/GenAI-RAG-APP",
"sfang32/test_internlm_rag",
"SerifeGokdas/Fake-Real-New-Classification",
"xiaoxishui/Llamaindex_rag",
"TAnGx1411/Streamlit_LlamaIndex_InternLM",
"EbeshaAI/dummy-license-plate-api",
"EbeshaAI/dummy-license-plate-api-2",
"quentinrobot/llamaindex_rag",
"ylxtesting/llamaindexrag",
"mehdi364/Analsys",
"mehdi364/data_anilsys",
"yanyoyo/Streamlit-LlamaIndex-API",
"forestav/jobsai",
"shouzhong-cn/Streamlit-LlamaIndex-puyu-api",
"isl-research/sparksearch-demo",
"keyggen/my-llama-space",
"KitHung/ai-assistant-1",
"alchemistcohen/Consultas_en_la_Norma_BRCGS_Food_Safety_V9",
"LA-lj/Llamaindex_RAG",
"SELIGROUP/chatstream",
"isl-research/books-discovery",
"abidlabs/df_scroll_bug_fix",
"BramLeo/chatbothrd",
"georgeek/HF-LLM-Intent-Detection",
"Icarus011/inttrn",
"Icarus011/internlm",
"minimum-generated-pig/llamaindex_rag_xtuner",
"Highthoughts/RAG",
"seachen/Intern_streamlit_rag",
"hannakhw/chatbot_demo",
"Vinutto/db_assistant",
"djlarsenradio/GABRIELE.AI",
"naitsirh/chatWithDoc",
"sanjion9/LlamaIndex_RAG",
"haidizym/internLM_RAG",
"haidizym/llamaIndex_demo",
"mteb/leaderboard_legacy",
"ilemon/Internlm2.5LLaMAindexRAG",
"CCCasEEE/LlamaIndex_RAG",
"nirusduddin/comparethai",
"FMY714/internlm2.5_llamaindex_RAG",
"Taoismimmortal/Llama",
"Flowryaan/jumpnfly_smart_chat",
"raflibagas/rag-vidavox",
"batosoft/Chat_with_your_Documents",
"hh1199/NomClass",
"ricky7372/internlm-LLamaindex-streamlit",
"sq66/leaderboard_legacy",
"borjaureta/RentIA_AIAgent",
"Chanjeans/vector",
"Chanjeans/vectorize",
"qasimgill/pakistan-laws-chatbot",
"alirayanfilms/Pak-Legal-Assist",
"quoc-khanh/chatbot4nct_test1",
"meraj12/TauzeehulMasail",
"MarcerMM/Phi-3.5-mini-ITA",
"fpaldrock/consultaPDF",
"quoc-khanh/chatbot4nct_test2",
"cdxxi/find_my_book_pr",
"Sergei-Ch/find_my_movie",
"lefuuu/series_rec",
"xefr762/Movie_finder",
"NaseemTahir/Manga_Proj",
"JessLimitLess/RAG_Assignment",
"harrymaringan/Semantic-Search",
"Cesar42/PreguntasDocumentos",
"Nekoko/NekoAI-Lab",
"buianh0803/NCT_chatbot_QA",
"mathaq/math-chatbot",
"jaot92/sofia-chat-api",
"wublewobble/genre-classifier",
"quoc-khanh/chatbot4nct",
"SergeyO7/Langchained_PGPS_RAG",
"copywr1ter/sentence-transformers-paraphrase-multilingual-MiniLM-L12-v2",
"SergeyO7/pure_RAG",
"jonathanjordan21/Qdrant-knowledge",
"ersanders/tutorSistemasOperativos2",
"valenottaviano/second-brain-chat",
"vikramronavrsc/RAG_ADVANCED_BY_BLOCKCHAIN",
"vikramronavrsc/BLOCHAIN_RAG_FOR_LASTDAY_EXAM_PREP",
"dig84128/OSCEvirtualPatient",
"ARYN26/LawPAL",
"LeedsLibraries/Soylatierra",
"LeedsLibraries/SouaTerra",
"sunnyball23/Semantic_Hunter",
"PresleyKoyaweda/vovodo-chinko-assistant",
"raniesolarevisky/ChatTesteLN",
"Loversofdeath/lore",
"NekoFengFeng/NekoStickers",
"theshresthshukla/rjchatbot",
"geet2507/TourismChatbot",
"geet2507/mharodesAI",
"lastsummerkape/LegalEasyAI",
"rressler/au_advisor",
"Soumyasarthak09/Dub",
"ametist20052002/rag-api",
"saran-2021/chat_service",
"SmileXing/leaderboard",
"geet2507/pdharomharedesAI",
"q275343119/leaderboard",
"Kanyakorn/multi-pdf-chatbot-v2",
"PinkPanpasa/pdf-chatbot",
"Bxmxr/TanyaBizSPM",
"Cansino/PDF_Insights",
"chaaim123/demo05-2",
"chaaim123/demo10",
"BastianFuh/HF_Agent_Course_Final_Assignment",
"farid678/PersianRAGA",
"Abdallah-22/recommendation_service",
"thibautmodrin/vitizen_chat",
"jalaj7nayan/analyser_emotion",
"FaizanArif/Bahishti_Zewar_RAG",
"melk2025/Chatbot",
"asfilcnx3/Do_questions_from_PDF_ES",
"FNEIT/Roboty",
"anastasia8888/Drama-bot",
"ersin1905/BilgeBot",
"ThatBoyReH/computoAI",
"asagasad/Rag_App_Doc",
"tensor-optima/project-mooc-group-2",
"saran-2021/backend_kitlang",
"anastasia8888/botik",
"AyushM6/leaderboard",
"MouadHSB/ResearchRAG",
"mahmut0105/b",
"mahmut0105/a",
"willwade/AACKGDemo",
"Prstm7/waelzlager-chatbot",
"Semfromkelbajar/IKTA_Bot",
"AhmedTarek1/ai",
"engrjamalakram/ai_urdu_legal_assistant",
"hdinguyen/nguyenh_embedding",
"pruebas2000/Juego",
"doga8524/Dogatest",
"doga8524/dogatest2",
"Arifeenz/rag-thai-tour-chat",
"ramysaidagieb/rag22v2",
"melk2025/New_MoodleChatbot",
"Sidoineko/cv-chatbot",
"Aseelalzaben03/sadaqai",
"SimoneP/J",
"milanakononowa/economist_assistant",
"solarisempresa/iasolaris",
"lol040604lol/TamilRestorer",
"Xaris75/textlab_app",
"anddrewzh/faq_bot",
"SlickSlick/Chatbot-1667287",
"DGID/NEXIA",
"conecta-ia/conecta",
"afnan-s/ai_saddiq",
"Turbiling/Curriculum_Assistant",
"Turbiling/CurriculumAssistant",
"ChamaraIresh/dhamma-search-bot",
"Ellab13/oneDrive-ai",
"legalxuan/LegalTech_Chatbot",
"william1324/1234",
"pmshoanghot/chat_bot_pbl5",
"soyeon18/hannam-chatbot-space1",
"ChantalMendivil/MonitoreaArgumentacion",
"pmshoanghot/pbl5_chat_bot_rag",
"svecchi/mio-rag-personale",
"geraldalivia/Blood-Connect-Assist",
"hajimammad/Mahon",
"thisispaperdoll/refeel",
"iansun-sh/tokenizers-languages",
"Zyr3x/nutriscan-backend",
"Agents-MCP-Hackathon/refeel",
"HYUNSYUN/ai-ethics-chatbot",
"loadedcheese/Omar_Rabie_Persona",
"ChamaraIresh/SearchSinhala",
"selinulusoy/leadership-coach",
"fisherman611/vietnamese-legal-chatbot",
"DheivaCodes/sanskrit-translator-semantic",
"DheivaCodes/multilang2sanskrit",
"DheivaCodes/multilingual",
"DheivaCodes/sanskrit-ai",
"Sarubobo/xatbot_basic",
"npuc/gobGPT",
"Jimmy11111/jp-keyword-extractor",
"jeevitha-app/Multilingual-Translator-App",
"jeevitha-app/Multilingual-translator",
"jeevitha-app/Translator-app",
"Sodagraph/YouTube_Transcript_Extraction",
"RTBHackaGeminiGymbros/Izazo",
"Yellowis/avaliador-jogo",
"amirulhazym/multilingual-auracart-ai-assistant",
"NSSSujith13/GAIA",
"Alexend/Stust",
"hawalurahman/bleu_rouge_bertsim",
"liyimichael/pdf-qa-bot",
"AkaniH/Constitution-RAG-System",
"Papp-Gergely/test_fajloka",
"paulinusjua/cm_penal_code",
"Ayush083/Vaatika-PD",
"d4nh5u/v0.6",
"Abiramii/MultilingualTranslator-app",
"navjotk/RAG_TextileVision",
"testyouwithlove/testshamsiamooz",
"d4nh5u/v0.6.2",
"als106/RagNa",
"Bassira/Esg_assistant",
"loringuyen/QA-system-in-Vietnamese-law",
"Basma3/sadeq-ai-fake-news",
"ishatothemoon/modelforpersonal",
"Hdelmonte/Agente-editorial-novela",
"TheGod-2003/legal-doc-backend",
"jeevitha-app/MULTILINGUAL_TRANSLATOR_APP",
"murtazamahboob/AiPdf",
"abdsaldia/Chatbot_assistance_orange_money",
"wibonela/Mama-Care-Assistant-Group1",
"francescoortame/SentEmbEval",
"kanninian/chatbot_test",
"kalyanbrat/semantic_rag",
"JARVISXIRONMAN/Legal-AI-Help-Agent",
"Ayesha-1/tazkirul-quran-chatbot",
"gfddddddd/sssaaaggffffinal",
"gfddddddd/chatbot",
"gfddddddd/chatttttt",
"gfddddddd/zahrafinal",
"Escinco1/pruebaadmisiones2",
"gfddddddd/zahra_chatbot",
"shiwan7788/leaderboard",
"ipepe/nomic-embeddings",
"d4nh5u/v0.8_Qwen3_14B",
"mo-456/FTCE-chatbot",
"zakihassan04/AGRO_chat",
"tacab/TACAB",
"Malek1ab/embedding_api",
"DSMLpulak/Captain-D",
"DSMLpulak/captain-d-chatbot",
"BramLeo/adminzyyy",
"MonikDuran/chatbot-powerbi",
"Chengyanci/11",
"thanhvandrit/Bot_Tham_Dinh",
"yanciyuyu/1",
"yyqzjys/lawsAgent",
"zakihassan04/tacab_ai",
"zakihassan04/tacab_api",
"DheivaCodes/Multilingual-translator",
"MonikDuran/ChatVie",
"vikramvasudevan/nalayiram_ai",
"marvinLan/pdf-cleaner-app",
"Frknblmz/Zanachatbot",
"aj-team4/project11",
"ramysaidagieb/brain247v1",
"Dama03/medical",
"FatimaFarooqGondal/ZameenDost",
"heliusdev/bnsinfoapi",
"ir12345/CustomChatBotLLM_GDOVER",
"Ebabar/zameendost",
"Ebabar/Zameendostupdated",
"dinhgia2106/chatbot",
"BulutKAYA/PersonalNoteAssitantAI",
"KaiSKX/revChatbot",
"vikramvasudevan/vedam_ai",
"okgunyang/multimodal-ai-service",
"neuralinteligent/torugo",
"n8n-1/8",
"reader-1/1",
"vikramvasudevan/sanatan_ai",
"roberto2000gg/ALADI-PMDER",
"Elcano/chatbot-banco-sol",
"saLeeh/RAG-Chat-Bot",
"Nuzwa/PakProEdu",
"mrcho98/ml-exam-prep",
"letaken-olam/Rabenu-Bot",
"AlexKD/Gita_chat",
"khudri/islamichat",
"vinayabc1824/AI-Voice-Cloning-for-Customer-Support",
"Said12qw/portfolio-chatbot",
"shimab/Class_test",
"Elcano/Chatbot_Sol",
"vi108/DrQ_chatbot",
"MrSimple01/AIEXP_RAG_1",
"Pracill/ai-document-qa-system",
"augustchuang/MyAICRS",
"0413mikey/Gradio_test",
"cyaro/test123",
"hy7haseeb/UrduRAGChatBot",
"namberino/mcq-gen-gpt",
"gooodiscovery/1",
"namberino/mcq-gen-docker",
"rathod31/multilingual-similarity",
"Bedarev/bedarev-clinic-bot",
"alekgomez/advanced14aug",
"kimddol/test1",
"crimacalo/testin",
"rathod31/kannada-english-sim",
"solarisempresa/tucuma",
"vydrking/ITMO-QA-Assistant",
"vydrking/test5",
"vydrking/test1",
"asr3232/Youtube_summarizer_model",
"ajain121/youtube_backemd",
"Ebabar/Zameen_dost",
"drrobot9/farmligua_AI",
"drrobot9/FARMLINGUA_AI_BRAIN",
"namberino/mcq-generator",
"luansouza4444/BibliaRAGAPI",
"motaseeem/Arabic-Main-Question-Generation",
"jatainkumar/ankur_the_agribot",
"hamzat12/indonesian-llm-avatar",
"PL2008017/Tutor_24_24",
"RAFAMANTANANTSOA/Cours-EGSS-MCI-M1",
"RAFAMANTANANTSOA/COURS-EGSS",
"Oustra/miniLawyer",
"XWF137/Zhenmu",
"Mustafakhaledi/Lost-Found-IQ",
"alexdudezxc/Construction-Assistant-RU",
"daksh1010/agribot",
"MuhammadHijazii/Samaaliiwhisper",
"MuhammadHijazii/faster_whisper_large_v3_post_processwith_advanced",
"Remostart/MILESTONE_ONE_FARMLINGUA_AI",
"oca-cibernetica/vector-owl",
"mithunkrishnan03/guvichatbot",
"CHUNYU0505/RAG_Test_System",
"LeshenLier/italiano-master",
"Yamang02/ai-portfolio-rag-demo",
"cwaltre/assistant-communal-pecc",
"Mohammadrwth/streamlit",
"Kushal-IIT-KGP/Ankur_AgriBot",
"Funscience123/I.R.A_2.0",
"MrSimple01/RAG_AIEXP_0",
"Alopmel/bookSearchLLM"
] |
[
"apache-2.0"
] | null |
[
"multilingual",
"ar",
"bg",
"ca",
"cs",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"it",
"ja",
"ka",
"ko",
"ku",
"lt",
"lv",
"mk",
"mn",
"mr",
"ms",
"my",
"nb",
"nl",
"pl",
"pt",
"ro",
"ru",
"sk",
"sl",
"sq",
"sr",
"sv",
"th",
"tr",
"uk",
"ur",
"vi"
] | 117,654,272
| null |
[
"sentence-similarity",
"feature-extraction"
] | null |
[
"AutoModel",
"BertModel",
"bert"
] |
[
"multimodal",
"text"
] |
[
"text"
] |
[
"embeddings",
"logits"
] |
free
|
university
|
[
"Germany"
] | null |
sentence-transformers/all-MiniLM-L12-v2
|
[
"Text"
] |
[
"Text Embedding"
] |
[
"Transformer: Text Encoder-only"
] |
[
"multilingual"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 6
|
641ab5d15d107c5c5f346372
|
ggerganov/whisper.cpp
|
ggerganov
| null | 0
| 0
|
False
| 2023-03-22T08:01:21Z
| 2024-10-29T18:25:17Z
| null | 1,089
| 10
| null |
automatic-speech-recognition
| null |
[
".gitattributes",
"README.md",
"ggml-base-encoder.mlmodelc.zip",
"ggml-base-q5_1.bin",
"ggml-base-q8_0.bin",
"ggml-base.bin",
"ggml-base.en-encoder.mlmodelc.zip",
"ggml-base.en-q5_1.bin",
"ggml-base.en-q8_0.bin",
"ggml-base.en.bin",
"ggml-large-v1-encoder.mlmodelc.zip",
"ggml-large-v1.bin",
"ggml-large-v2-encoder.mlmodelc.zip",
"ggml-large-v2-q5_0.bin",
"ggml-large-v2-q8_0.bin",
"ggml-large-v2.bin",
"ggml-large-v3-encoder.mlmodelc.zip",
"ggml-large-v3-q5_0.bin",
"ggml-large-v3-turbo-encoder.mlmodelc.zip",
"ggml-large-v3-turbo-q5_0.bin",
"ggml-large-v3-turbo-q8_0.bin",
"ggml-large-v3-turbo.bin",
"ggml-large-v3.bin",
"ggml-medium-encoder.mlmodelc.zip",
"ggml-medium-q5_0.bin",
"ggml-medium-q8_0.bin",
"ggml-medium.bin",
"ggml-medium.en-encoder.mlmodelc.zip",
"ggml-medium.en-q5_0.bin",
"ggml-medium.en-q8_0.bin",
"ggml-medium.en.bin",
"ggml-small-encoder.mlmodelc.zip",
"ggml-small-q5_1.bin",
"ggml-small-q8_0.bin",
"ggml-small.bin",
"ggml-small.en-encoder.mlmodelc.zip",
"ggml-small.en-q5_1.bin",
"ggml-small.en-q8_0.bin",
"ggml-small.en.bin",
"ggml-tiny-encoder.mlmodelc.zip",
"ggml-tiny-q5_1.bin",
"ggml-tiny-q8_0.bin",
"ggml-tiny.bin",
"ggml-tiny.en-encoder.mlmodelc.zip",
"ggml-tiny.en-q5_1.bin",
"ggml-tiny.en-q8_0.bin",
"ggml-tiny.en.bin"
] |
[
1477,
3196,
37922638,
59707625,
81768585,
147951465,
37950917,
59721011,
81781811,
147964211,
1177529527,
3094623691,
1174643458,
1080732091,
1656129691,
3094623691,
1175711232,
1081140203,
1173393014,
574041195,
874188075,
1624555275,
3095033483,
567829413,
539212467,
823369779,
1533763059,
566993085,
539225533,
823382461,
1533774781,
163083239,
190085487,
264464607,
487601967,
162952446,
190098681,
264477561,
487614201,
15037446,
32152673,
43537433,
77691713,
15034655,
32166155,
43550795,
77704715
] | 31,005,921,914
|
5359861c739e955e79d9a303bcbc70fb988958b1
|
[
"automatic-speech-recognition",
"license:mit",
"region:us"
] | null |
# OpenAI's Whisper models converted to ggml format for use with [whisper.cpp](https://github.com/ggerganov/whisper.cpp)
[Available models](https://huggingface.co/ggerganov/whisper.cpp/tree/main)
| Model | Disk | SHA |
| ------------------- | ------- | ------------------------------------------ |
| tiny | 75 MiB | `bd577a113a864445d4c299885e0cb97d4ba92b5f` |
| tiny-q5_1 | 31 MiB | `2827a03e495b1ed3048ef28a6a4620537db4ee51` |
| tiny-q8_0 | 42 MiB | `19e8118f6652a650569f5a949d962154e01571d9` |
| tiny.en | 75 MiB | `c78c86eb1a8faa21b369bcd33207cc90d64ae9df` |
| tiny.en-q5_1 | 31 MiB | `3fb92ec865cbbc769f08137f22470d6b66e071b6` |
| tiny.en-q8_0 | 42 MiB | `802d6668e7d411123e672abe4cb6c18f12306abb` |
| base | 142 MiB | `465707469ff3a37a2b9b8d8f89f2f99de7299dac` |
| base-q5_1 | 57 MiB | `a3733eda680ef76256db5fc5dd9de8629e62c5e7` |
| base-q8_0 | 78 MiB | `7bb89bb49ed6955013b166f1b6a6c04584a20fbe` |
| base.en | 142 MiB | `137c40403d78fd54d454da0f9bd998f78703390c` |
| base.en-q5_1 | 57 MiB | `d26d7ce5a1b6e57bea5d0431b9c20ae49423c94a` |
| base.en-q8_0 | 78 MiB | `bb1574182e9b924452bf0cd1510ac034d323e948` |
| small | 466 MiB | `55356645c2b361a969dfd0ef2c5a50d530afd8d5` |
| small-q5_1 | 181 MiB | `6fe57ddcfdd1c6b07cdcc73aaf620810ce5fc771` |
| small-q8_0 | 252 MiB | `bcad8a2083f4e53d648d586b7dbc0cd673d8afad` |
| small.en | 466 MiB | `db8a495a91d927739e50b3fc1cc4c6b8f6c2d022` |
| small.en-q5_1 | 181 MiB | `20f54878d608f94e4a8ee3ae56016571d47cba34` |
| small.en-q8_0 | 252 MiB | `9d75ff4ccfa0a8217870d7405cf8cef0a5579852` |
| small.en-tdrz | 465 MiB | `b6c6e7e89af1a35c08e6de56b66ca6a02a2fdfa1` |
| medium | 1.5 GiB | `fd9727b6e1217c2f614f9b698455c4ffd82463b4` |
| medium-q5_0 | 514 MiB | `7718d4c1ec62ca96998f058114db98236937490e` |
| medium-q8_0 | 785 MiB | `e66645948aff4bebbec71b3485c576f3d63af5d6` |
| medium.en | 1.5 GiB | `8c30f0e44ce9560643ebd10bbe50cd20eafd3723` |
| medium.en-q5_0 | 514 MiB | `bb3b5281bddd61605d6fc76bc5b92d8f20284c3b` |
| medium.en-q8_0 | 785 MiB | `b1cf48c12c807e14881f634fb7b6c6ca867f6b38` |
| large-v1 | 2.9 GiB | `b1caaf735c4cc1429223d5a74f0f4d0b9b59a299` |
| large-v2 | 2.9 GiB | `0f4c8e34f21cf1a914c59d8b3ce882345ad349d6` |
| large-v2-q5_0 | 1.1 GiB | `00e39f2196344e901b3a2bd5814807a769bd1630` |
| large-v2-q8_0 | 1.5 GiB | `da97d6ca8f8ffbeeb5fd147f79010eeea194ba38` |
| large-v3 | 2.9 GiB | `ad82bf6a9043ceed055076d0fd39f5f186ff8062` |
| large-v3-q5_0 | 1.1 GiB | `e6e2ed78495d403bef4b7cff42ef4aaadcfea8de` |
| large-v3-turbo | 1.5 GiB | `4af2b29d7ec73d781377bfd1758ca957a807e941` |
| large-v3-turbo-q5_0 | 547 MiB | `e050f7970618a659205450ad97eb95a18d69c9ee` |
| large-v3-turbo-q8_0 | 834 MiB | `01bf15bedffe9f39d65c1b6ff9b687ea91f59e0e` |
For more information, visit:
https://github.com/ggerganov/whisper.cpp/tree/master/models
|
[
"hf-audio/open_asr_leaderboard",
"RASMUS/Whisper-youtube-crosslingual-subtitles",
"RASMUS/Youtube-videos-with-crosslingual-transcriptions",
"biodatlab/whisper-thai-yt-subtitles",
"yaklion/youtube",
"shadow/Whisper-youtube-crosslingual-subtitles",
"radames/whisper.cpp-wasm",
"mikegarts/subs",
"Docfile/Whisper-youtube-crosslingual-subtitles",
"fraxy/chesswhisp",
"ggml-org/wchess",
"Nymbo/whisper.cpp-wasm",
"trysem/whisper.cpp-wasm",
"Nymbo/Whisper-Chess",
"Jinda/whisper-thai-mp3",
"storni/Whisper-youtube-crosslingual-subtitles",
"RossVanN/WYCS2",
"Skriller0208/AudioValidation",
"Gigaverse/ivrit-ai-streaming",
"AtPeak/realtime-stt-translation",
"RobinsAIWorld/whisper.cpp-wasm",
"AnyaSchen/whisper-websocket",
"langtech-innovation/WhisperLiveKitDiarization",
"husseinelsaadi/Codingo",
"IronaAI/hindi_asr_leaderboard",
"luguog/farttofly",
"vbrajon/whisperlivekit",
"Steveeeeeeen/open_asr_leaderboard_longform"
] |
[
"mit"
] | null | null | null | null |
[
"automatic-speech-recognition"
] | null | null |
[
"multimodal"
] |
[
"audio"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null |
openai/whisper-base
|
[
"Speech"
] |
[
"Text Generation"
] |
[
"Diffusion-based Network"
] |
[
"Multilingual"
] |
[
"Finetuning: Supervised"
] |
Disclosed: available
| 9
|
650d827e72afb1e60e8a8a6a
|
pyannote/segmentation-3.0
|
pyannote
| null | 20,215,768
| 240,665,501
|
auto
| 2023-09-22T12:03:10Z
| 2024-05-10T19:35:46Z
|
pyannote-audio
| 572
| 10
| null |
voice-activity-detection
| null |
[
".gitattributes",
"LICENSE",
"README.md",
"config.yaml",
"example.png",
"pytorch_model.bin"
] |
[
1519,
1061,
4648,
399,
69284,
5905440
] | 5,982,351
|
e66f3d3b9eb0873085418a7b813d3b369bf160bb
|
[
"pyannote-audio",
"pytorch",
"pyannote",
"pyannote-audio-model",
"audio",
"voice",
"speech",
"speaker",
"speaker-diarization",
"speaker-change-detection",
"speaker-segmentation",
"voice-activity-detection",
"overlapped-speech-detection",
"resegmentation",
"license:mit",
"region:us"
] | null | null |
[
"r3gm/SoniTranslate_translate_audio_of_a_video_content",
"JonnyTran/SoniTranslate",
"RO-Rtechs/Translate_Video_language",
"waloneai/VideoTranslate_translate_audio_of_a_video_content",
"avans06/whisper-webui-translate",
"dandrade/whisper-webui-translate",
"SoybeanMilk/whisper-webui-translate",
"bnriiitb/whisper-webui-translate",
"ombhojane/whisper-webui-translate",
"Valor/whisper-webui-translate",
"thak123/whisper-webui-translate",
"yvankob/whisper-webui-translate",
"tools4eu/asr",
"Nymbo/whisper-webui-translate",
"lodstar/SoniTranslate",
"sub314xxl/SoniTranslate_translate_audio_of_a_video_content",
"vunhucuongit/SoniTranslate_translate_audio_of_a_video_content",
"aikitty/SoniTranslate_translate_audio_of_a_video_content-sandbox",
"tob8008/SoniTranslate",
"RO-Rtechs/Elohe_video-dubb_tool",
"test-rtechs/soni_cloned",
"test-rtechs/ALEPH_WEO-WEBETA",
"sadegh-cdana1/SoniTranslate_translate_audio_of_a_video_content",
"qasim894/Omni_Gradio",
"WarriorWithin/SoniTranslate_translate_audio_of_a_video_content",
"RO-Rtechs/Aleph-Weo-Webeta",
"YetNak/SoniTranslate_translate_audio_of_a_video_content",
"Mopix/donotmindthis",
"Mopix/soni",
"Mopix/SoniT",
"Mopix/SONTT",
"ROGSOL/SoniTranslate_translate_audio_of_a_video_content",
"waloneai/wl-dub",
"k2-fsa/speaker-diarization",
"JasonAEKE/SoniTranslate",
"mesjavacca/Translate_Video_language",
"YetNak/SoniTranslate_translate_audio_of_a_video_contentiiii",
"CultriX/whisper-webui-translate",
"emilalvaro/whisper-webui-translate-note",
"YetNak/SoniTranslate_translate_audio_of_a_video",
"hoomancisco/SoniTranslate_translate_audio_of_a_video_content",
"pengjoe12802/SoniTranslate_translate_audio_of_a_video_content",
"MartsoBodziu1994/SoniTranslate_translate_audio_of_a_video_content",
"BhupXndra/SoniTranslate_translate_audio_of_a_video_content",
"Myxxxacc999/asr",
"arcanus/koala2",
"kel777/SoniTranslate_translate_audio_of_a_video_content",
"LAP-DEV/Demo",
"Dragunflie-420/SoniTranslate_translate_audio_of_a_video_content",
"lynnpia/SoniTranslate_translate_audio_of_a_video_content",
"cutechicken/whisper-webui-translate",
"Masterdqqq/whisper-webui-translate",
"Hehhdjeiehrhdhjf/SoniTranslate_translate_audio_of_a_video_content",
"waloneai/SoniTranslate_CPU",
"waloneai/SoniTranslate_translate_audio_of_a_video_content",
"gnosticdev/SoniTranslate_translate_audio_of_a_video_content",
"zooyf/speaker-diarization",
"Daniel9046/SoniTranslate",
"Stream999/my_whisper_demo",
"mahin777/SoniTranslate_translate_audio_of_a_video_content",
"G-Rost/SoniTranslate_2",
"Saiteja/SoniTranslate",
"rjx76/transcribes",
"imthedronelord/SoniTranslate",
"flausch/SoniTranslate_translate_audio_of_a_video_content",
"GillJatt123/latest_SoniTranslate",
"ngjianqing9789/whisper-webui-translate",
"djclarkson/diarize",
"odiaanubad/dubber",
"eusoualexander/VoxSplit",
"vbrajon/whisperlivekit",
"Faisut/Translate_Video_language"
] |
[
"mit"
] | null | null | null | null |
[
"voice-activity-detection"
] | null | null | null | null | null |
free
|
non-profit
|
[
"France"
] |
Other agreement/info requirements
| null |
[
"Speech"
] |
[
"Other"
] |
[
"Transformer: Speech Encoder-only"
] |
[
"en",
" zh",
" fr"
] |
[
"Pretraining: Supervised"
] |
Disclosed: available
| 12
|
66eaedefece5ee215637cc82
|
meta-llama/Llama-3.2-1B-Instruct
|
meta-llama
| null | 5,639,164
| 27,455,182
|
manual
| 2024-09-18T15:12:47Z
| 2024-10-24T15:07:51Z
|
transformers
| 1,049
| 10
| null |
text-generation
|
{"parameters": {"BF16": 1235814400}, "total": 1235814400}
|
[
".gitattributes",
"LICENSE.txt",
"README.md",
"USE_POLICY.md",
"config.json",
"generation_config.json",
"model.safetensors",
"original/consolidated.00.pth",
"original/params.json",
"original/tokenizer.model",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] |
[
1519,
7712,
41742,
6021,
877,
189,
2471645608,
2471677246,
220,
2183982,
296,
9085657,
54528
] | 4,954,705,597
|
9213176726f574b556790deb65791e0c5aa438b6
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"arxiv:2405.16406",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"Humbl3m33/meta-llama-Llama-3.2-1B-Instruct",
"eduagarcia/open_pt_llm_leaderboard",
"Nymbo/Serverless-TextGen-Hub",
"cvachet/pdf-chatbot",
"allenai/reward-bench",
"baconnier/prompt-plus-plus",
"HuggingFaceH4/blogpost-scaling-test-time-compute",
"bhaskartripathi/LLM_Quantization",
"K00B404/Text-2-Speech",
"logikon/open_cot_leaderboard",
"karths/types_issues",
"NiansuhAI/Main",
"cot-leaderboard/open-cot-dashboard",
"dwb2023/hf_extractor",
"ruslanmv/convert_to_gguf",
"LVKinyanjui/QueryYourDocs",
"codelion/optillm",
"Nymbo/Llama-3.2-1B-Instruct",
"thejagstudio/meta-llama-Llama-3.2-1B-Instruct",
"JiakaiDu/RAG_Test",
"Pavithiran/chat",
"huggingface/paper-central",
"emilalvaro/meta-llama-Llama-3.2-1B-Instruct",
"Saquib65/meta-llama-Llama-3.2-1B-Instruct",
"inteligenciamilgrau/juninho",
"iSaahil/trial",
"yordyi/meta-llama-Llama-3.2-1B-Instruct",
"LousyBook01/meta-llama-Llama-3.2-1B-Instruct",
"mvalssj/Assistente",
"aguinaldomavenda0/JoanaChatBot",
"rven7/Llama_1",
"JJWOLF00/Writer",
"boblemaz/lemaz_",
"bnwb/bestie",
"Deepri24/Photography_Learning_Assistant_1",
"SelwaValencia/Rostlab-prot_t5_xl_uniref50",
"wilwoap/meta-llama-Llama-3.2-1B-Instruct",
"Priyanshusrivastava/meta-llama-Llama-3.2-1B-Instruct",
"UPBYaroNemec/Practica4",
"davidbizzo/Adv",
"crystal99/meta-llama-Llama-3.2-1B-Instruct",
"Shanat/chtbt_rag",
"srinuksv/Main",
"Yashnik/ChatPDF",
"nicpopovic/ember_chat",
"Abrak/Controlled_Chat_CPU",
"hamsomp3/tecnicas2024-llama3.2-1b-instruct",
"rootshari/roots_gradio",
"GIZ/climate_vulnerability_analysis",
"K00B404/Flux-uncensored-Custom",
"Ahmed-El-Sharkawy/product_description",
"K00B404/BananaLahmah",
"Project-description/Project-Description",
"moctardiallo/autodocs",
"Chris4K/More_Advanced_Embeddings_Comparator",
"Chilliming/meta-llama-Llama-3.2-1B-Instruct",
"Madhuri123/s1",
"1ofteamos/meta-llama-Llama-3.2-1B-Instruct",
"JaphetHernandez/PotentialTalents_2",
"SagaMKM/Projekti",
"goin2cjb123/meta-llama-Llama-3.2-1B-Instruct",
"asm3515/talk-to-meta3.2",
"ashkck/meta-llama-Llama-3.2-1B-Instruct",
"LNT-Miguel/IA",
"Mattral/QuickResponseTest",
"julienokumu/o1-RAG",
"Kartheekb7/llava_chat",
"Penguin5681/meta-llama-Llama-3.2-1B-Instruct",
"Sonfire/meta-llama-Llama-3.2-1B-Instructasdad",
"yasserrmd/NotebookLlama",
"yasserrmd/NotebookLlamaGroq",
"KPDEV12/cucasmole",
"Ganesh09662/HealthGenie",
"lightmate/llm-chatbot",
"Ganesh89/Job_analyzer",
"mdowling/meta-llama-Llama-3.2-1B-Instruct",
"crystal99/dooe",
"sravyaa02/Psychological_Chatbot",
"transformers-ai/chatbot",
"Vikrant27/gitchat",
"Sathishkumartheta/dedekind-gradio-chat",
"Daeyongkwon98/chatbot_demo",
"Sathishkumartheta/dedekind-telegram-chat",
"gevans3000/meta-llama-Llama-3.2-1B-Instruct",
"Isaac2489/admin",
"svidhani/GenerativeAI",
"Yersel/llama3.2-1B",
"yalrashed/pdf-to-podcast-test",
"sudipta7276/meta-llama-Llama-3.2-1B-Instruct",
"ofani/meta-llama-Llama-3.2-1B-Instruct",
"KeanKaggle/meta-llama-Llama-3.2-1B-Instruct",
"juniorsereno/criativa",
"julienokumu/History_AI_Agent",
"Thziin/Tutorial",
"huggingface/keras-chatbot-arena",
"akhilsu/Chat_llama3",
"akhilsu/LLAMA3_AI_Chat",
"akhilsu/SummaryLLAMA",
"manumc/proyecto1",
"ebonywapp/meta-llama-Llama-3.2-1B-Instruct",
"AiActivity/AI-Assistant",
"API-Handler/test_api",
"macota1/axa",
"sanjithapatnaik/DocumentExtractor",
"yusufs/vllm-inference",
"akhilsu/Chat_With_AI",
"ashsk0110/meta-llama-Llama-3.2-1B-Instruct",
"AItool/ServerlessInferenceAPI",
"AlrdinBaby/ARU_Final_Project",
"Manojajj/Document-QA-without-RAG-Langchain",
"Kjoy11/ResumeChat",
"Chris4K/Events",
"Aroojzahra908/chatbotfarmers",
"Siddhant/Voice_Assistant_Demo",
"aj74yk/perf-analysis-chat",
"Pmf04/meta-llama-Llama-3.2-1B-Instruct",
"lytoet142/chatbot_tks",
"cslsselu/csls-llama",
"MojoHz/laibor",
"cslsselu/generative-llama",
"Andfres/llamaChatbot",
"lruiz44/meta-llama-Llama-3.2-1B-Instruct",
"hbsanaweb/lama-1403-10",
"sanbo1200/Main",
"sanbo1200/Main1",
"sanbo110/Main",
"MojoHz/Aced-Analytics-AI-Assistant",
"n3ffos/Llama",
"Guldmundur/meta-llama-Llama-3.2-1B-Instruct",
"Prgrmmer/ai-dungeon",
"kidsampson/halcydonia_tests",
"jaindivyansh/bioasq-1",
"PhamTy/Thesis-Meta_Llama",
"sanazafar1994/paraphraser_sz",
"KishoreK/space-test-local",
"ravidawade/AIchatapp",
"MojoHz/Grad_Trial1",
"sergiopaniego/LongerThinkingLLM",
"Tamim3/Test",
"MojoHz/Dija_Grad_Work",
"pavan-naik/RecipeGenie",
"AliGhadiri/LlammaEP",
"gnosticdev/meta-llama-Llama-3.2-1B-Instruct",
"gnosticdev/bothistoria",
"caiocsr/CaioDev",
"stevenijacobs/meta-llama-Llama-3.2-1B-Instruct",
"Chris4K/Test-Time-Compute-Toolkit",
"AnsarUllahAnas/TherapyAI",
"Chris4K/llm",
"sanbo110/Main1",
"ishaank123/meta-llama-Llama-3.2-1B-Instruct",
"Uener/My-Chatbot",
"loganvicky/meta-llama-Llama-3.2-1B-Instruct",
"AshwithPoojary/AutomationTestingChatbot",
"AliGhadiri/meta-llama-Llama-3.2-1B-Instruct",
"Zamax14/api_rag",
"Nevidu/IIT_ChatBot",
"AdenilsonSouza/MyAI",
"ankurkr12/llm1",
"sikeaditya/Krushi_Mitra",
"Jeff850/meta-llama-Llama-3.2-1B-Instruct",
"kiko2001/Finetuned-with-REFT-by-Kristijan-Boshev",
"YZ-TAN/flask-llama",
"sikeaditya/Krushi_Mitra_V2",
"cicero-im/synthetic-data-generator-new",
"Kjoy11/JoyDataSolutions",
"KBaba7/llama.cpp",
"KBaba7/Quant",
"totolook/Quant",
"fdaudens/meta-download-stats",
"ethiotech4848/experimental",
"Steven10429/apply_lora_and_quantize",
"rohansampath/basic-llama2-eval",
"ashishja/First_agent_template",
"david-clifford/00_Deploy_Practice_Agent_Basics",
"SIDS92/AgentForge",
"Toorop77/First_agent_template",
"anuragrawal/First_agent_template",
"zonca/First_agent_template_pub_2",
"BreadMaster101/Gulf-of-Mexico-GPT",
"umaiku/chatbot",
"akiollenberg/First_agent_template",
"ftshijt/Voice_Assistant_Demo",
"archuu/First_agent_template",
"achrafsn/First_agent_template",
"JerryGao/First_agent_template",
"quydm/Kyoukai",
"fasfous92/First_agent_template",
"alisvanni/First_agent_template",
"Jimateo/First_agent_template",
"Stefos44/BrightSites_Agent",
"Edmundoogaz/First_agent_template",
"federai/First_agent_template",
"Mykes/First_agent_template",
"MaxTymchii/First_agent_template",
"bnm77/First_agent_template",
"ChIrish06/First_agent_template",
"wphoenix/Crypto_Market_Data_Agent",
"hpal007/First_agent-hpal007",
"srijan9994/rag-application",
"Socialmediaprophet/synthetic-data-generator",
"oieieio/meta-llama-Llama-3.2-1B-Instruct",
"Unclejunkie/pdf-chatbot",
"akashshahade/talk-to-pdf",
"omarmalik347/Chat-Bot",
"Yuki-Chen/Lumi_ishere",
"albaarcos/synthetic-data-generator_3",
"laizacosta/mood_tracker_HF",
"ved-idrive/meta-llama-Llama-3.2-1B-Instruct",
"PyScoutAI/PyscoutAI",
"DoodDood/fine-tuned-llama-3-2-1b-NYCSCC",
"AI-man999/FastAPiWithdocker",
"javimarlop/pdf-chatbot",
"Akash190104/space_turtle",
"FallnAI/Quantize-HF-Models",
"Ts881188/Serverless-TextGen-Hub",
"AI-man999/Dynamic_bot",
"Fafafafafafa/rayssa",
"K00B404/LLM_Quantization",
"humane-intelligence/space-turtle",
"yusufs/llama32-3b-instruct",
"GuhanAein/program-solver-rag",
"willsh1997/context_window_POC",
"pankaj69/Ecom-detail-generator",
"fabioknipper/DragonIA",
"ChienChung/SmartRAG_Multi-Agent_Assistant_",
"pierrefdz/interactive-llm-wm",
"bimalpaudel/instruct-translator",
"noideatt/Ielts-Writing",
"heyjudy/2025_CityU_IS6620_Project3",
"Deepak002006/TPF_AI",
"aa2999587/pdf-chatbot",
"tingao/synthetic-data-generator",
"bang-bot/iiitdm_chatbot",
"Xilena/Tecnicas_LLMs-2025-1-Llama-3.2-1b-instruct",
"angelicaporto/tecnicas_LLMs_llama3.2_instruct",
"MaccaGPT/practicainstruct",
"thejarll/Prueba_2",
"Colossus515/Test_Instruct",
"victor1102/VI_2",
"miguel0614/llama_instruct",
"galileo389/Llama_3_2instruct",
"burman-ai/GradioChat",
"shreyankisiri/Literature",
"yusufs/sailor2-3b-chat",
"SaranRaj-12/PDF_BASED_QUESTION_GENERATION_ANSWERING_SYSTEM",
"RohitKeswani/react_agent",
"909ahmed/synthetic-data-generator",
"SaranRaj-12/PDF_CHAT_BOT_NEW",
"samarth-kamble/pdf-chatbot",
"VLAI-AIVN/AIO2024M10_Instruction_Tuning_SAT_Reading",
"yashsharmaa/CIRChat",
"getGO007/RAG-chatbot",
"BMH14/textgen1",
"ankanpy/DocuMind",
"georad/sbsmapper",
"OscarHernando/Llama_3.2_1B_Instruct",
"beazt/Final_Assignment",
"keeperballon/multi-llm",
"s12144251/xsg123",
"akdombrowski/hf-gr-ai-agent-chat",
"aizip-dev/SLM-RAG-Arena",
"seawolf2357/LLM_Quantization",
"openfree/LLM_Quantization",
"VLAI-AIVN/AIO2024M10_Tutorial_Tool_Calling",
"Luongsosad/chat_bot",
"joilton/criptoajuste",
"Kuberwastaken/AsianMOM",
"nadiagorlova/First_agent_template_Nadin",
"atulisoffline/CGI-POC-with-Reasoning",
"Anupam007/CGI-POC-with-Reasoning",
"NotSoundRated/meta-llama-Llama-3.2-1B-Instruct",
"sri0002/lang_chain_conversational_prompting",
"Ajay1100/chat_bot",
"DOMMETI/Ai-Mentor",
"Pasham123/CHAT_BOTS",
"MohamatmVyshnavi/Mentor_Chatbot",
"sree4411/Chat_bot",
"keerthanakothoju/Inno_mentoring",
"saikumar27/Mentor_BoT",
"echarif/education_chatbot",
"t2codes/titu_bot",
"Indhu27/Datascience_online_mentor",
"surekha-polarapu/Mentor_AI",
"AbbasAga/AI-Assistant",
"Harshitha-01/Ai_Mentor",
"vidya1990/Guidebot_AI",
"Mounisha/CHAT-BOT_MENTOR",
"kuruvabhageeerathashankar14/Online_mentor",
"Pavani31/INNO_MENTOR_CONNECT",
"srividyaPavuluri/InnoAI_Mentor",
"udaykiran2002/Ai_mentor",
"Meghana-16/Inno_Mentor_Support",
"Mounisha/AI-MENTOR",
"orijeetmukherjee/MED_RAG",
"onisj/jarvis_gaia_agent",
"Ramyamaheswari/Mentor_AI",
"MohamatmVyshnavi/Resume_Checker",
"EduuGomes/CachoeiraBot",
"vidyaPavuluri/InnoAI_Mentor",
"UmaKumpatla/ChatBuddy_AI",
"MUNESULA/ai-mentor-app",
"Pasham123/Resume_checker1",
"alyxsis/txt",
"Odhiambo/agent_playstore",
"gabrix00/grammarllm",
"BamaBoiii/AntlerAI",
"karu2302/Ai_mentor",
"gayathri0709/Resume_Checker",
"ivangabriele/trl-sandbox",
"Priyanka0001/Mentor_AI",
"Priyanka0001/Resume_Checker",
"MedinaArmando/DS_Results",
"Carlosbatista/avalia_oportunidade",
"abin253/mental-health-chatbot",
"Yadav122/llm-ai-agent",
"8kLovesShit/gradio_test",
"JaganathC/Smart_Assistant_for_Research_Summarization",
"Johnyquest7/medical-transcription-notes",
"ManoVignesh/Ai_mentor",
"lakshya-moka/Ai_Mentor",
"echarif/moroccan_student_assistant",
"Kunaboyina/MentorMitra",
"ReallyFloppyPenguin/AICodepen",
"Satvick/ChatBot_Pdf",
"Satvick/ChatBot_PDF_",
"Zkydriver/First_agent_template",
"shiprocket-ai/llama-address-intelligence",
"pritamdeka/Biomedical-Fact-Checker",
"tuliodisanto/Buscador_Rol_vs.2_IA",
"harpreetsahota/fiftyone-helper",
"K00B404/convert_to_gguf",
"patmcgee/patllm",
"QUT-GenAILab/context-window",
"gregorlied/medical-text-summarization",
"zohaibbb/FinanceChatbot",
"fair-forward/Easy2Read",
"sandeep-huggingface/RAG_CSV_Chatbot",
"Deddy/PromptSuite-AI",
"danhtran2mind/Vietnamese-Health-Chat-LoRA",
"Babu/llama32-revature-chat",
"Sreeja05/rag-llama3-chatbot",
"vishaljoshi24/trl-4-dnd",
"JamesKevinStar/HealthcareTranslation",
"BAKAI78/meta-llama-Llama-3.2-1B-Instruct",
"Yousra1/pharma-agent",
"collinsmile/chatbot_ureeka",
"vumichien/keras-chatbot-arena",
"Rishitha3/RAG_CHATBOT"
] |
[
"llama3.2"
] | null |
[
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th"
] | 1,235,814,400
| null |
[
"text-generation"
] | null |
[
"llama",
"AutoModelForCausalLM",
"LlamaForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
user
|
user
|
[
"user"
] |
Accept to share username & email
| null |
[
"Text"
] |
[
"Text Generation"
] |
[
"Transformer: Text Decoder-only"
] |
[
"en",
" de",
" fr",
" it",
" pt",
" hi",
" es",
" th"
] |
[
"Pretraining: Multimodal joint-embeddings",
" Finetuning: Supervised",
" Reinforcement learning from feedback"
] |
Disclosed: available
| 9
|
67ced65c9b9a3df71008da90
|
google/gemma-3-1b-it
|
google
|
{
"models": [
{
"_id": "67b79cc230e38c400f496b93",
"id": "google/gemma-3-1b-pt"
}
],
"relation": "finetune"
}
| 3,212,467
| 13,296,357
|
manual
| 2025-03-10T12:09:00Z
| 2025-04-04T13:12:40Z
|
transformers
| 593
| 10
| null |
text-generation
|
{"parameters": {"BF16": 999885952}, "total": 999885952}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"generation_config.json",
"model.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1676,
24265,
35,
899,
215,
1999811208,
662,
33384568,
4689074,
1156999
] | 2,039,069,601
|
dcc83ea841ab6100d6b47a070329e1ba4cf78752
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2311.12022",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2312.11805",
"base_model:google/gemma-3-1b-pt",
"base_model:finetune:google/gemma-3-1b-pt",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | null |
[
"umint/ai",
"seanpedrickcase/Light-PDF-Web-QA-Chatbot",
"Monster/gemma-3-1b-it",
"umint/o4-mini",
"giseldo/eliza_llm",
"lynx-analytics/lynxkite",
"wangda21c/basic-chatbot-gemma-3-1b",
"kimhyunwoo/gemma-3-1b-it-space",
"sitammeur/Gemma-llamacpp",
"bapfalraz/demo-cop-gemma",
"AFG473319/Gemma",
"Bradarr/csm-1b",
"swayam1925/workshop_project",
"Tomoniai/gemma-3-chat",
"Slyracoon23/what_is_prompt_engineering",
"fffefgegegegegeg/fefdf",
"Rohit1412/AirGPT1.04b",
"CognitiveScience/gemma-3-chat",
"kanneboinakumar/gemma3_finetuned",
"mohitkumarrajbadi/Finetune_Gemma_Model",
"hadadrjt/ai",
"alizoljodi/Potential_Talents",
"Intel/synthetic-data-generator",
"noideatt/gemma-3-1b-writing",
"fukugawa/indiebot-arena",
"infinitymatter/Synthetic_Data_Generator_SRIJAN",
"NanobotzAI/gemma-3-chat",
"NanobotzAI/gemma-3-chat-api",
"Pamudu13/gemma-3-chat-api",
"nitin-ss/gemma_finetuning",
"Pamudu13/gemma-3-chat-api-2",
"NanobotzAI/gemma-3-chat-api-2",
"domainbroker1991/gemma3-1b",
"adityadeshpande03/Gemma3-1b-Deployment",
"spuun/nagaluv",
"ievnsk/Llama_4_Scout_17B",
"kimhyunwoo/aaa",
"AshubhaiXd/DevAI",
"iryahayri/gemma32",
"shrey2105/ts-resume-checker-gemma-hf",
"nishantnayyar/sap-bdc-assistant-bot",
"plebias/RAG_U",
"DonLuisM/model_llama3.2_tecnicasIA",
"DonLuisM/Model_instructgemma",
"VitaliiPuzhenko/gemma-3-crm",
"Adityak204/gemma3-1b-GRPO-finetuned",
"teenysheep/chatbot",
"Chakron2006/chayenlm-demo",
"sierrafr/test",
"naxwinn/Aura-2",
"markredito/gemma-pip-finetuned",
"juancamval/graph_generator",
"acmc/ss-prompts",
"zasu87/hf3-it-fun",
"YAMITEK/gemma3_finetuned",
"NanobotzAI/gemma-3-chat-api-3",
"wahdia/medibot",
"adsurkasur/arina-hf-spaces-api",
"aizip-dev/SLM-RAG-Arena",
"Lakshmi16224/RAG-Based-NLP-Tutor-Model",
"alvarog1318/KD_USAC",
"LLMhacker/deepseek-r1dotcom",
"willwade/AACKGDemo",
"segestic/gemma-3-1b-it",
"HenryY2023/First_agent_template",
"neuralworm/GPT-Identity-Evaluation",
"pmshoanghot/chat_bot_pbl5",
"somosnlp-hackathon-2025/Iberotales-thinking-demo",
"pmshoanghot/pbl5_chat_bot_rag",
"VIDraft/Gemma-3-R1984-1B-0613",
"Wtvman/Ads4you",
"Agents-MCP-Hackathon/Ads-4-u",
"Wtvman/Ads4you-xoxo",
"kairusama/gemma-3-1b-it-qat",
"GreenRunchly/gemma-3-1b-it",
"xiaoyao9184/convert-to-genai",
"garage-lab/MCP_HTML2JSON",
"GreenStudio/kOB",
"kayfahaarukku/vtuber-tag-gen",
"navid72m/securedocai",
"daqc/Iberotales-thinking-demo",
"Stor11/google-gemma-3-4b-it",
"pritamdeka/Biomedical-Fact-Checker",
"garage-lab/MCP_STRUCTRA",
"electricsheepafrica/Gemma-3n-local-training",
"mcjhn/ai",
"blueda9232/ai",
"prasadmujumdar19/RentingBot",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"danhtran2mind/Vietnamese-Health-Chat-LoRA",
"woranit/docx-tokenizer",
"Bhavya077/Audit_Risk_Extractor",
"wuhuizgptamd/ai",
"ItsProtesilaus/gemma-3-270m-endpt",
"ByteMeHarder-404/firstbot",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"umint/openwebui"
] |
[
"gemma"
] | null | null | 999,885,952
| null |
[
"text-generation"
] | null |
[
"gemma3_text",
"Gemma3ForCausalLM",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
683f3c2354280d882006f816
|
google/gemma-3n-E4B-it
|
google
|
{
"models": [
{
"_id": "683f3c15d1e73e29fefdee1f",
"id": "google/gemma-3n-E4B"
}
],
"relation": "finetune"
}
| 130,935
| 490,387
|
manual
| 2025-06-03T18:17:07Z
| 2025-07-14T13:56:17Z
|
transformers
| 742
| 10
| null |
image-text-to-text
|
{"parameters": {"BF16": 7849978192}, "total": 7849978192}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"notebook.ipynb",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer.model",
"tokenizer_config.json"
] |
[
1570,
24467,
1626,
4536,
215,
3077103824,
4966792808,
4992870216,
2663414864,
171423,
3919090,
1152,
98,
769,
33442559,
4696020,
1202311
] | 15,743,647,548
|
c1221e9c62e34a43ab7ffacd1be0ea71f126ef10
|
[
"transformers",
"safetensors",
"gemma3n",
"image-text-to-text",
"automatic-speech-recognition",
"automatic-speech-translation",
"audio-text-to-text",
"video-text-to-text",
"conversational",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2210.03057",
"arxiv:2502.12404",
"arxiv:2411.19799",
"arxiv:2009.03300",
"arxiv:2502.21228",
"arxiv:2311.12022",
"arxiv:2403.07974",
"arxiv:2108.07732",
"arxiv:2107.03374",
"base_model:google/gemma-3n-E4B",
"base_model:finetune:google/gemma-3n-E4B",
"license:gemma",
"endpoints_compatible",
"region:us"
] | null | null |
[
"umint/ai",
"huggingface-projects/gemma-3n-E4B-it",
"Monster/gemma-3n-E4B-it",
"sido1991/apiagrilens",
"umint/o4-mini",
"ManojINaik/mixtral-46.7b-fastapiiii",
"shivam00109/Electrol_roll",
"ManishThota/gemma-3n-E4B-it",
"AC2513/gemma-demo",
"broadfield-dev/gemma-3n-alkdf",
"fastrtc/gemma-3n",
"Ofiroz91/live-Gemma-3n",
"flozi00/gemma-3n-E4B-it-asr",
"akhaliq/gemma-3n-E4B-it",
"echo3700/gemma-3n-E4B-it",
"ariG23498/gemma3n-image-audio",
"ReallyFloppyPenguin/AICodepen",
"praveen3/gemma-3n-E4B-it",
"KatyTryOf/PruebaDuplicacion",
"Fretful/gemma-3n-E4B-it",
"HibbaCenter/gemma3n-api",
"Sidoineko/AgriLensAI",
"Shago/pronunciation_assessment",
"Shago/basic_engineering_economics_agent",
"raksama19/Test-Dolphin-PDF",
"Nagarajan1/First_agent_template",
"mcjhn/ai",
"raksama19/Test-Gemma-3n",
"Fabian32/Diplo_IA_Proyecto_Final",
"HMWCS/Gemma3n-challenge-demo",
"blueda9232/ai",
"raksama19/Test-Voice-Chatbot",
"SarowarSaurav/Finetuned-SLM",
"durukan/scigpt",
"raksama19/Test_Voice",
"GF-John/video-caption",
"raksama19/Scholar-Express",
"kaiku03/audio_news_agent_demo",
"anand-kumar-007/gemma-paraphraser",
"SebastianSchramm/cozytales-backend",
"ericrisco/medical-gemma-3n-4b",
"ParulPandey/Smart_Asha_Form",
"kaiku03/gemma3n-2b-it-challenge-demo",
"omidwwer/gemma-3n-E4B-it",
"daniloedu/saludandina",
"daniloedu/GemmaTest",
"Amalsu0/GemmaGuard3n_demo",
"cong182/firstAI",
"mugi007/takumi",
"Werve/leaderboard_yourbench_Werve_ccnl",
"dvpearl/REFRAME",
"mainwhihoon/career_conv",
"wuhuizgptamd/ai",
"fokan/train-modle",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"umint/openwebui"
] |
[
"gemma"
] | null | null | 7,849,978,192
| null |
[
"automatic-speech-recognition",
"video-text-to-text",
"image-text-to-text"
] | null |
[
"Gemma3nForConditionalGeneration",
"gemma3n",
"AutoModelForImageTextToText"
] |
[
"multimodal",
"vision"
] |
[
"audio",
"text",
"image"
] |
[
"text"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6840ae27d4e16ff5f93d9dde
|
nvidia/diar_streaming_sortformer_4spk-v2
|
nvidia
| null | 6,360
| 6,360
|
False
| 2025-06-04T20:35:51Z
| 2025-08-14T17:21:44Z
|
nemo
| 32
| 10
|
[{"name": "diar_streaming_sortformer_4spk-v2", "results": [{"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "DIHARD III Eval (1-4 spk)", "type": "dihard3-eval-1to4spks", "config": "with_overlap_collar_0.0s", "input_buffer_lenght": "1.04s", "split": "eval-1to4spks"}, "metrics": [{"name": "Test DER", "type": "der", "value": 13.24, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "DIHARD III Eval (5-9 spk)", "type": "dihard3-eval-5to9spks", "config": "with_overlap_collar_0.0s", "input_buffer_lenght": "1.04s", "split": "eval-5to9spks"}, "metrics": [{"name": "Test DER", "type": "der", "value": 42.56, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "DIHARD III Eval (full)", "type": "dihard3-eval", "config": "with_overlap_collar_0.0s", "input_buffer_lenght": "1.04s", "split": "eval"}, "metrics": [{"name": "Test DER", "type": "der", "value": 18.91, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (2 spk)", "type": "CALLHOME-part2-2spk", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2-2spk"}, "metrics": [{"name": "Test DER", "type": "der", "value": 6.57, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (3 spk)", "type": "CALLHOME-part2-3spk", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2-3spk"}, "metrics": [{"name": "Test DER", "type": "der", "value": 10.05, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (4 spk)", "type": "CALLHOME-part2-4spk", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2-4spk"}, "metrics": [{"name": "Test DER", "type": "der", "value": 12.44, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (5 spk)", "type": "CALLHOME-part2-5spk", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2-5spk"}, "metrics": [{"name": "Test DER", "type": "der", "value": 21.68, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (6 spk)", "type": "CALLHOME-part2-6spk", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2-6spk"}, "metrics": [{"name": "Test DER", "type": "der", "value": 28.74, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "CALLHOME (NIST-SRE-2000 Disc8) part2 (full)", "type": "CALLHOME-part2", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "part2"}, "metrics": [{"name": "Test DER", "type": "der", "value": 10.7, "verified": false}]}, {"task": {"name": "Speaker Diarization", "type": "speaker-diarization-with-post-processing"}, "dataset": {"name": "call_home_american_english_speech", "type": "CHAES_2spk_109sessions", "config": "with_overlap_collar_0.25s", "input_buffer_lenght": "1.04s", "split": "ch109"}, "metrics": [{"name": "Test DER", "type": "der", "value": 4.88, "verified": false}]}]}]
|
audio-classification
| null |
[
".gitattributes",
"README.md",
"diar_streaming_sortformer_4spk-v2.nemo",
"figures/aosc_3spk_example.gif",
"figures/aosc_4spk_example.gif",
"figures/fifo.png",
"figures/sortformer-v1-model.png",
"figures/sortformer_intro.png",
"figures/streaming_steps.png"
] |
[
2332,
21595,
471367680,
5491128,
13560479,
122833,
486239,
325066,
637178
] | 492,014,530
|
59620264e008f2b06a0e969688e0af3e8705478b
|
[
"nemo",
"speaker-diarization",
"speaker-recognition",
"speech",
"audio",
"Transformer",
"FastConformer",
"Conformer",
"NEST",
"pytorch",
"NeMo",
"audio-classification",
"dataset:fisher_english",
"dataset:NIST_SRE_2004-2010",
"dataset:librispeech",
"dataset:ami_meeting_corpus",
"dataset:voxconverse_v0.3",
"dataset:icsi",
"dataset:aishell4",
"dataset:dihard_challenge-3-dev",
"dataset:NIST_SRE_2000-Disc8_split1",
"dataset:Alimeeting-train",
"dataset:DiPCo",
"arxiv:2409.06656",
"arxiv:2507.18446",
"arxiv:2408.13106",
"arxiv:2305.05084",
"arxiv:2310.12371",
"arxiv:1706.03762",
"license:cc-by-4.0",
"model-index",
"region:us"
] | null | null | null |
[
"cc-by-4.0"
] |
[
"fisher_english",
"NIST_SRE_2004-2010",
"librispeech",
"ami_meeting_corpus",
"voxconverse_v0.3",
"icsi",
"aishell4",
"dihard_challenge-3-dev",
"NIST_SRE_2000-Disc8_split1",
"Alimeeting-train",
"DiPCo"
] | null | null | null |
[
"audio-classification"
] |
[
"der"
] | null |
[
"audio"
] |
[
"audio"
] |
[
"logits"
] |
enterprise_plus
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
6848029d9a16b13edd1a3de4
|
nanonets/Nanonets-OCR-s
|
nanonets
|
{
"models": [
{
"_id": "6795ff8f7534713f94918fc5",
"id": "Qwen/Qwen2.5-VL-3B-Instruct"
}
],
"relation": "finetune"
}
| 319,678
| 732,766
|
False
| 2025-06-10T10:02:05Z
| 2025-06-20T19:15:33Z
|
transformers
| 1,491
| 10
| null |
image-text-to-text
|
{"parameters": {"BF16": 3754622976}, "total": 3754622976}
|
[
".gitattributes",
"Modelfile",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00002.safetensors",
"model-00002-of-00002.safetensors",
"model.safetensors.index.json",
"preprocessor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
424,
6327,
605,
1017,
2522,
214,
1671853,
4997750760,
2511587184,
65448,
575,
613,
11421896,
4756,
1730,
2776833
] | 7,525,294,327
|
3baad182cc87c65a1861f0c30357d3467e978172
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"OCR",
"pdf2markdown",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null |
Nanonets-OCR-s by [Nanonets](https://nanonets.com) is a powerful, state-of-the-art image-to-markdown OCR model that goes far beyond traditional text extraction. It transforms documents into structured markdown with intelligent content recognition and semantic tagging, making it ideal for downstream processing by Large Language Models (LLMs).
Nanonets-OCR-s is packed with features designed to handle complex documents with ease:
* **LaTeX Equation Recognition:** Automatically converts mathematical equations and formulas into properly formatted LaTeX syntax. It distinguishes between inline (`$...$`) and display (`$$...$$`) equations.
* **Intelligent Image Description:** Describes images within documents using structured `<img>` tags, making them digestible for LLM processing. It can describe various image types, including logos, charts, graphs and so on, detailing their content, style, and context.
* **Signature Detection & Isolation:** Identifies and isolates signatures from other text, outputting them within a `<signature>` tag. This is crucial for processing legal and business documents.
* **Watermark Extraction:** Detects and extracts watermark text from documents, placing it within a `<watermark>` tag.
* **Smart Checkbox Handling:** Converts form checkboxes and radio buttons into standardized Unicode symbols (`☐`, `☑`, `☒`) for consistent and reliable processing.
* **Complex Table Extraction:** Accurately extracts complex tables from documents and converts them into both markdown and HTML table formats.
📢 [Read the full announcement](https://nanonets.com/research/nanonets-ocr-s) | 🤗 [Hugging Face Space Demo](https://huggingface.co/spaces/Souvik3333/Nanonets-ocr-s)
## Usage
### Using transformers
```python
from PIL import Image
from transformers import AutoTokenizer, AutoProcessor, AutoModelForImageTextToText
model_path = "nanonets/Nanonets-OCR-s"
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
processor = AutoProcessor.from_pretrained(model_path)
def ocr_page_with_nanonets_s(image_path, model, processor, max_new_tokens=4096):
prompt = """Extract the text from the above document as if you were reading it naturally. Return the tables in html format. Return the equations in LaTeX representation. If there is an image in the document and image caption is not present, add a small description of the image inside the <img></img> tag; otherwise, add the image caption inside <img></img>. Watermarks should be wrapped in brackets. Ex: <watermark>OFFICIAL COPY</watermark>. Page numbers should be wrapped in brackets. Ex: <page_number>14</page_number> or <page_number>9/22</page_number>. Prefer using ☐ and ☑ for check boxes."""
image = Image.open(image_path)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image", "image": f"file://{image_path}"},
{"type": "text", "text": prompt},
]},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], padding=True, return_tensors="pt")
inputs = inputs.to(model.device)
output_ids = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return output_text[0]
image_path = "/path/to/your/document.jpg"
result = ocr_page_with_nanonets_s(image_path, model, processor, max_new_tokens=15000)
print(result)
```
### Using vLLM
1. Start the vLLM server.
```bash
vllm serve nanonets/Nanonets-OCR-s
```
2. Predict with the model
```python
from openai import OpenAI
import base64
client = OpenAI(api_key="123", base_url="http://localhost:8000/v1")
model = "nanonets/Nanonets-OCR-s"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def ocr_page_with_nanonets_s(img_base64):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"},
},
{
"type": "text",
"text": "Extract the text from the above document as if you were reading it naturally. Return the tables in html format. Return the equations in LaTeX representation. If there is an image in the document and image caption is not present, add a small description of the image inside the <img></img> tag; otherwise, add the image caption inside <img></img>. Watermarks should be wrapped in brackets. Ex: <watermark>OFFICIAL COPY</watermark>. Page numbers should be wrapped in brackets. Ex: <page_number>14</page_number> or <page_number>9/22</page_number>. Prefer using ☐ and ☑ for check boxes.",
},
],
}
],
temperature=0.0,
max_tokens=15000
)
return response.choices[0].message.content
test_img_path = "/path/to/your/document.jpg"
img_base64 = encode_image(test_img_path)
print(ocr_page_with_nanonets_s(img_base64))
```
### Using docext
```python
pip install docext
python -m docext.app.app --model_name hosted_vllm/nanonets/Nanonets-OCR-s
```
Checkout [GitHub](https://github.com/NanoNets/docext/tree/dev/markdown) for more details.
## BibTex
```
@misc{Nanonets-OCR-S,
title={Nanonets-OCR-S: A model for transforming documents into structured markdown with intelligent content recognition and semantic tagging},
author={Souvik Mandal and Ashish Talewar and Paras Ahuja and Prathamesh Juvatkar},
year={2025},
}
```
|
[
"prithivMLmods/Tiny-VLMs-Lab",
"prithivMLmods/Multimodal-OCR",
"davanstrien/ocr-time-machine",
"prithivMLmods/Multimodal-OCR2",
"ajforbes20/Multimodal-OCR",
"VIDraft/voice-trans",
"MohamedRashad/Nanonets-OCR",
"Souvik3333/Nanonets-ocr-s",
"Adun/typhoon-ocr-finetuned-v1.x",
"Dragunflie-420/Nanonets-OCR",
"Ivan000/Nanonets-OCR-s-Q4_K_M-GGUF",
"Groovygal73/MyFirstSpace",
"lyonsno/Nanonets-ocr-s-0ZEPU",
"tuanhqv123/final_agent_course",
"Sivasuriya/Image2TextOCR",
"Tonic/Nanonets-ocr-s",
"ArapCheruiyot/election_watch_narrative_classifyer_00",
"Shiv22/Multimodal-OCR",
"HealthifyLK/vedaMD",
"Toughen1/Nanonets-OCR",
"mqudokm6vg7l/Multimodal-OCR2",
"prodevroger/handwritten",
"tomvsindia/AOCR",
"zhangpeihao/nano",
"ndgold/Multimodal-OCR",
"Sanmath/text2",
"amberborici/Qwen-Qwen2-VL-7B-Instruct",
"apjanco/fantastic-futures",
"ZennyKenny/typhoon-ocr-finetuned-v1.x",
"storytracer/ocr-time-machine"
] | null | null |
[
"en"
] | 3,754,622,976
| null |
[
"image-to-text",
"image-text-to-text"
] | null |
[
"AutoModelForVision2Seq",
"Qwen2_5_VLForConditionalGeneration",
"qwen2_5_vl"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
687de260234339fed21e768a
|
Qwen/Qwen3-235B-A22B-Instruct-2507
|
Qwen
| null | 87,723
| 113,085
|
False
| 2025-07-21T06:46:56Z
| 2025-08-17T08:19:57Z
|
transformers
| 660
| 10
| null |
text-generation
|
{"parameters": {"BF16": 235093634560}, "total": 235093634560}
|
[
".gitattributes",
"LICENSE",
"README.md",
"config.json",
"config_1m.json",
"generation_config.json",
"merges.txt",
"model-00001-of-00118.safetensors",
"model-00002-of-00118.safetensors",
"model-00003-of-00118.safetensors",
"model-00004-of-00118.safetensors",
"model-00005-of-00118.safetensors",
"model-00006-of-00118.safetensors",
"model-00007-of-00118.safetensors",
"model-00008-of-00118.safetensors",
"model-00009-of-00118.safetensors",
"model-00010-of-00118.safetensors",
"model-00011-of-00118.safetensors",
"model-00012-of-00118.safetensors",
"model-00013-of-00118.safetensors",
"model-00014-of-00118.safetensors",
"model-00015-of-00118.safetensors",
"model-00016-of-00118.safetensors",
"model-00017-of-00118.safetensors",
"model-00018-of-00118.safetensors",
"model-00019-of-00118.safetensors",
"model-00020-of-00118.safetensors",
"model-00021-of-00118.safetensors",
"model-00022-of-00118.safetensors",
"model-00023-of-00118.safetensors",
"model-00024-of-00118.safetensors",
"model-00025-of-00118.safetensors",
"model-00026-of-00118.safetensors",
"model-00027-of-00118.safetensors",
"model-00028-of-00118.safetensors",
"model-00029-of-00118.safetensors",
"model-00030-of-00118.safetensors",
"model-00031-of-00118.safetensors",
"model-00032-of-00118.safetensors",
"model-00033-of-00118.safetensors",
"model-00034-of-00118.safetensors",
"model-00035-of-00118.safetensors",
"model-00036-of-00118.safetensors",
"model-00037-of-00118.safetensors",
"model-00038-of-00118.safetensors",
"model-00039-of-00118.safetensors",
"model-00040-of-00118.safetensors",
"model-00041-of-00118.safetensors",
"model-00042-of-00118.safetensors",
"model-00043-of-00118.safetensors",
"model-00044-of-00118.safetensors",
"model-00045-of-00118.safetensors",
"model-00046-of-00118.safetensors",
"model-00047-of-00118.safetensors",
"model-00048-of-00118.safetensors",
"model-00049-of-00118.safetensors",
"model-00050-of-00118.safetensors",
"model-00051-of-00118.safetensors",
"model-00052-of-00118.safetensors",
"model-00053-of-00118.safetensors",
"model-00054-of-00118.safetensors",
"model-00055-of-00118.safetensors",
"model-00056-of-00118.safetensors",
"model-00057-of-00118.safetensors",
"model-00058-of-00118.safetensors",
"model-00059-of-00118.safetensors",
"model-00060-of-00118.safetensors",
"model-00061-of-00118.safetensors",
"model-00062-of-00118.safetensors",
"model-00063-of-00118.safetensors",
"model-00064-of-00118.safetensors",
"model-00065-of-00118.safetensors",
"model-00066-of-00118.safetensors",
"model-00067-of-00118.safetensors",
"model-00068-of-00118.safetensors",
"model-00069-of-00118.safetensors",
"model-00070-of-00118.safetensors",
"model-00071-of-00118.safetensors",
"model-00072-of-00118.safetensors",
"model-00073-of-00118.safetensors",
"model-00074-of-00118.safetensors",
"model-00075-of-00118.safetensors",
"model-00076-of-00118.safetensors",
"model-00077-of-00118.safetensors",
"model-00078-of-00118.safetensors",
"model-00079-of-00118.safetensors",
"model-00080-of-00118.safetensors",
"model-00081-of-00118.safetensors",
"model-00082-of-00118.safetensors",
"model-00083-of-00118.safetensors",
"model-00084-of-00118.safetensors",
"model-00085-of-00118.safetensors",
"model-00086-of-00118.safetensors",
"model-00087-of-00118.safetensors",
"model-00088-of-00118.safetensors",
"model-00089-of-00118.safetensors",
"model-00090-of-00118.safetensors",
"model-00091-of-00118.safetensors",
"model-00092-of-00118.safetensors",
"model-00093-of-00118.safetensors",
"model-00094-of-00118.safetensors",
"model-00095-of-00118.safetensors",
"model-00096-of-00118.safetensors",
"model-00097-of-00118.safetensors",
"model-00098-of-00118.safetensors",
"model-00099-of-00118.safetensors",
"model-00100-of-00118.safetensors",
"model-00101-of-00118.safetensors",
"model-00102-of-00118.safetensors",
"model-00103-of-00118.safetensors",
"model-00104-of-00118.safetensors",
"model-00105-of-00118.safetensors",
"model-00106-of-00118.safetensors",
"model-00107-of-00118.safetensors",
"model-00108-of-00118.safetensors",
"model-00109-of-00118.safetensors",
"model-00110-of-00118.safetensors",
"model-00111-of-00118.safetensors",
"model-00112-of-00118.safetensors",
"model-00113-of-00118.safetensors",
"model-00114-of-00118.safetensors",
"model-00115-of-00118.safetensors",
"model-00116-of-00118.safetensors",
"model-00117-of-00118.safetensors",
"model-00118-of-00118.safetensors",
"model.safetensors.index.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1570,
11343,
16212,
964,
378776,
238,
1671839,
3991955880,
3994081856,
3994081856,
3988822448,
3994081784,
3994081856,
3994081856,
3994081856,
3988822456,
3994081784,
3994081856,
3994081856,
3994081944,
3988822776,
3994082088,
3994082176,
3994082176,
3994082176,
3988822776,
3994082088,
3994082160,
3994082176,
3994082176,
3939555920,
3993016808,
3994082160,
3994082176,
3994082176,
3998276288,
3997211632,
3994082160,
3994082176,
3994082176,
3994082200,
3988822680,
3994082152,
3994082176,
3994082176,
3994082200,
3988822696,
3994082144,
3994082176,
3994082176,
3994082192,
3988822704,
3994082144,
3994082176,
3994082176,
3994082184,
3988822712,
3994082136,
3994082176,
3994082176,
3994082184,
3988822720,
3994082128,
3994082176,
3994082176,
3994082176,
3988822736,
3994082128,
3994082176,
3994082176,
3994082176,
3988822744,
3994082120,
3994082176,
3994082176,
3994082176,
3988822752,
3994082120,
3994082176,
3994082176,
3994082176,
3988822752,
3994082112,
3994082176,
3994082176,
3994082176,
3988822760,
3994082104,
3994082176,
3994082176,
3994082176,
3988822760,
3994082104,
3994082176,
3994082176,
3994082176,
3988822768,
3994082096,
3994082176,
3994082176,
3994082176,
3988822776,
3994082088,
3994082176,
3994082176,
3994082176,
3988822776,
3994082088,
3994082168,
3994082176,
3994082176,
3952138960,
3993016808,
3994082160,
3994082176,
3994082176,
3998276288,
3997211632,
3994082160,
3994082176,
3994082176,
3994082200,
3988822680,
3994082152,
3070273928,
3332207,
11422654,
10825,
2776833
] | 470,211,498,501
|
97d5e9ab00193afeca402994df7706f9403b01f5
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
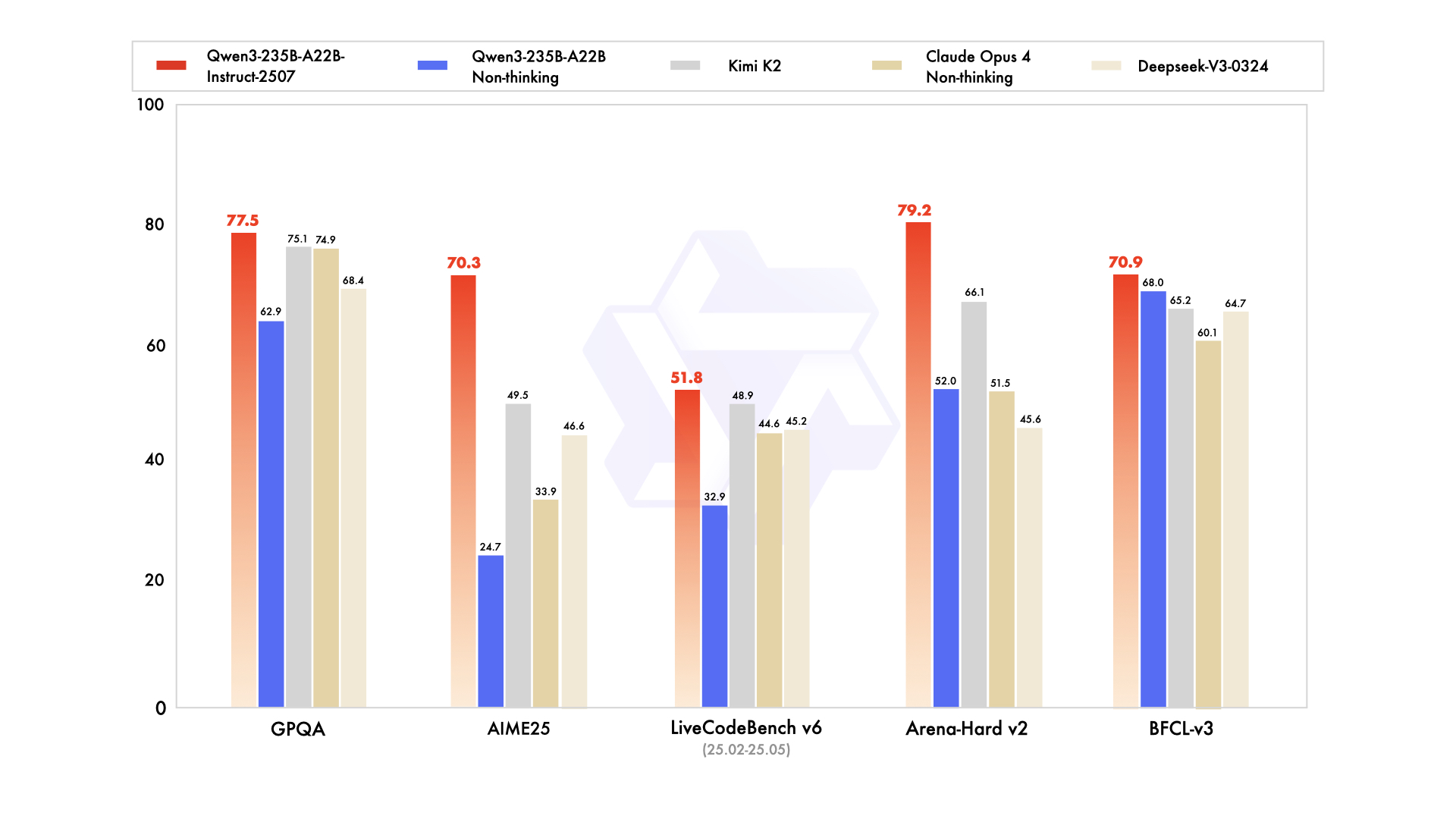
## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively and extendable up to 1,010,000 tokens**
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU1-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU1-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| TAU2-Retail | 71.1 | 66.7# | **75.5** | 70.6 | 64.9 | 74.6 |
| TAU2-Airline | 36.0 | 42.0# | 55.5 | **56.5** | 36.0 | 50.0 |
| TAU2-Telecom | 34.0 | 29.8# | 45.2 | **65.8** | 24.6 | 32.5 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **1000 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-235B-A22B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-235B-A22B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 8 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 8` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-235B-A22B (Non-Thinking) | 83.9 | 97.7 | 96.1 | 97.5 | 96.1 | 94.2 | 90.3 | 88.5 | 85.0 | 82.1 | 79.2 | 74.4 | 70.0 | 71.0 | 68.5 | 68.0 |
| Qwen3-235B-A22B-Instruct-2507 (Full Attention) | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-235B-A22B-Instruct-2507 (Sparse Attention) | 91.7 | 98.5 | 97.2 | 97.3 | 97.7 | 96.6 | 94.6 | 92.8 | 94.3 | 90.5 | 89.7 | 89.5 | 86.4 | 83.6 | 84.2 | 82.5 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
[
"multimodalart/Qwen-Image-Edit-Fast",
"zerogpu-aoti/Qwen-Image-Edit-Outpaint",
"multimodalart/Qwen-Image-Fast",
"zerogpu-aoti/Qwen-Image-Edit-Multi-Image",
"umint/ai",
"InstantX/Qwen-Image-ControlNet",
"bep40/Nano-Banana",
"LPX55/Qwen-Image-Edit_Fast-Presets",
"VirtualKimi/Nano-Banana",
"instaagent/Qwen-Image-Fast-8steps",
"aiqtech/kofaceid",
"zerogpu-aoti/Qwen-Image-Edit-aot-dynamic-fa3-fix-cfg",
"umint/o4-mini",
"Nymbo/Character-Generator",
"CasperCvO/Final_Assignment_agentcourse",
"Elias-CIC/Final_Assignment_Template",
"mgbam/builder",
"WilliamRabuel/GAIA_Agent",
"umint/Qwen3-235B-A22B-Instruct-2507",
"akhaliq/Qwen3-235B-A22B-Instruct-2507-gradio",
"laloadrianmorales/Qwen-Qwen3-235B-A22B-Instruct-2507",
"ReallyFloppyPenguin/Qwen-Qwen3-235B-A22B-Instruct-2507",
"spanexx/Qwen-Qwen3-235B-A22B-Instruct-2507",
"Domnoval/Qwen_Website_creator",
"qgyd2021/llm_eval_system",
"henady/agent",
"Diluvium777/Agent-evaluations",
"zhenchuan1/Qwen-Qwen3-235B-A22B-Instruct-2507",
"TheIndianGiant/Qwen-Qwen3-235B-A22B-Instruct-2507",
"alekgomez/advanced",
"alekgomez/yourbench10aug",
"alekgomez/advanced14aug",
"simata/webui",
"wwjph2018/Qwen-Qwen3-235B-A22B-Instruct-2507",
"Sahil5112/Fast-image-genrator",
"cpuai/Qwen-Image-Fast",
"wuhuizgptamd/ai",
"LLMhacker/Qwen-Image-Edit-Fast",
"VirtualKimi/Qwen-Image-Edit-Fast",
"VirtualKimi/Qwen-Image-Fast",
"hari7261/ChitraKala",
"mrbui1990/Qwen-Image-Edit-Fast",
"mahreenfarooq25/zuban-e-kisan-chatbot",
"mathiaseggert/Qwen-Image-Fast",
"cbensimon/Qwen-Image-Edit-aot-dynamic-fa3",
"jin-cai/Qwen-Image-Fast",
"Qasham08/Qwen-Image-Fast",
"nkjoy/Ai",
"sunny1997/Qwen-Image-Edit-Fast",
"datxy/Qwen-Image-Edit-Fast",
"umint/gpt-4.1-nano",
"umint/o3",
"stackway-ai/openwebui",
"umint/openwebui",
"bep40/Qwen-Image-Edit-Multi-Image",
"chengzhigang/Qwen-Image-Edit_Fast-Presets01",
"chengzhigang/Qwen-Image-Edit-Fast-02"
] |
[
"apache-2.0",
"https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE"
] | null | null | 235,093,634,560
| null |
[
"text-generation"
] | null |
[
"Qwen3MoeForCausalLM",
"qwen3_moe",
"AutoModelForCausalLM"
] |
[
"text"
] |
[
"text"
] |
[
"text"
] |
team
|
company
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
6887953344eb0fe075182f65
|
QuantStack/Wan2.2-T2V-A14B-GGUF
|
QuantStack
|
{
"models": [
{
"_id": "68824c2337a7b37f90914ed8",
"id": "Wan-AI/Wan2.2-T2V-A14B"
}
],
"relation": "quantized"
}
| 196,839
| 280,920
|
False
| 2025-07-28T15:20:19Z
| 2025-07-29T13:04:15Z
|
gguf
| 95
| 10
| null |
text-to-video
| null |
[
".gitattributes",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q2_K.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q3_K_M.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q3_K_S.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q4_0.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q4_1.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q4_K_M.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q4_K_S.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q5_0.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q5_1.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q5_K_M.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q5_K_S.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q6_K.gguf",
"HighNoise/Wan2.2-T2V-A14B-HighNoise-Q8_0.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q2_K.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q3_K_M.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q3_K_S.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q4_0.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q4_1.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q4_K_M.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q4_K_S.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q5_0.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q5_1.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q5_K_M.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q5_K_S.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q6_K.gguf",
"LowNoise/Wan2.2-T2V-A14B-LowNoise-Q8_0.gguf",
"README.md",
"VAE/Wan2.1_VAE.safetensors"
] |
[
4217,
5299319296,
7174468096,
6513373696,
8556458496,
9257693696,
9650090496,
8746512896,
10312823296,
11014058496,
10790416896,
10135876096,
12002013696,
15404970496,
5299319296,
7174468096,
6513373696,
8556458496,
9257693696,
9650090496,
8746512896,
10312823296,
11014058496,
10790416896,
10135876096,
12002013696,
15404970496,
607,
253815318
] | 249,969,971,438
|
73eafba53a1a8f29254e4c77f92e74ea27d7cd6f
|
[
"gguf",
"t2v",
"text-to-video",
"base_model:Wan-AI/Wan2.2-T2V-A14B",
"base_model:quantized:Wan-AI/Wan2.2-T2V-A14B",
"license:apache-2.0",
"region:us"
] |
{"total": 14288491584, "architecture": "wan"}
| null | null |
[
"apache-2.0"
] | null | null | null | 14,288,491,584
|
[
"text-to-video"
] | null |
[
"wan"
] |
[
"vision"
] |
[
"text"
] |
[
"video"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68a7c2bab21506a456d5294d
|
lodestones/Chroma1-Radiance
|
lodestones
| null | 0
| 0
|
False
| 2025-08-22T01:07:06Z
| 2025-08-22T01:07:06Z
| null | 15
| 10
| null | null | null |
[
".gitattributes",
"README.md"
] | null | null |
3f3f953df8334acf7461f1b3979392211f9137a3
|
[
"license:apache-2.0",
"region:us"
] | null | null |
[
"apache-2.0"
] | null | null | null | null | null | null | null | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
|
68abb20fbfb6854b4fbaecf2
|
zerofata/MS3.2-PaintedFantasy-Visage-v3-34B
|
zerofata
|
{
"models": [
{
"_id": "68799b22fd8b000e6d679798",
"id": "ConicCat/Mistral-Small-3.2-AntiRep-24B"
}
],
"relation": "finetune"
}
| 32
| 32
|
False
| 2025-08-25T00:45:03Z
| 2025-08-30T05:21:20Z
| null | 10
| 10
| null | null |
{"parameters": {"BF16": 34131758080}, "total": 34131758080}
|
[
".gitattributes",
"README.md",
"chat_template.jinja",
"config.json",
"generation_config.json",
"model-00001-of-00015.safetensors",
"model-00002-of-00015.safetensors",
"model-00003-of-00015.safetensors",
"model-00004-of-00015.safetensors",
"model-00005-of-00015.safetensors",
"model-00006-of-00015.safetensors",
"model-00007-of-00015.safetensors",
"model-00008-of-00015.safetensors",
"model-00009-of-00015.safetensors",
"model-00010-of-00015.safetensors",
"model-00011-of-00015.safetensors",
"model-00012-of-00015.safetensors",
"model-00013-of-00015.safetensors",
"model-00014-of-00015.safetensors",
"model-00015-of-00015.safetensors",
"model.safetensors.index.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
] | null | null |
1801814455ff66f5361c6c8672d1968827a7bef3
|
[
"safetensors",
"mistral",
"dataset:zerofata/Instruct-Anime",
"dataset:zerofata/Instruct-Anime-CreativeWriting",
"dataset:zerofata/Roleplay-Anime-Characters",
"dataset:zerofata/Summaries-Anime-FandomPages",
"base_model:ConicCat/Mistral-Small-3.2-AntiRep-24B",
"base_model:finetune:ConicCat/Mistral-Small-3.2-AntiRep-24B",
"region:us"
] | null |
<style>
.container {
--primary-accent: #C0C0C0;
--secondary-accent: #4A9EFF;
--glow-primary: rgba(192, 192, 192, 0.6);
--glow-secondary: rgba(74, 158, 255, 0.6);
--bg-main: #0B0A18;
--bg-container: #110F24;
--bg-card: rgba(20, 18, 40, 0.7);
--text-main: #DCDCDC;
--text-muted: #9E9E9E;
--white: #FFFFFF;
--border-color: #3C3A50;
--font-title: 'Cinzel', serif;
--font-body: 'EB Garamond', serif;
--font-code: 'Courier New', monospace;
font-family: var(--font-body);
color: var(--text-main);
line-height: 1.6;
font-weight: 400;
max-width: 1100px;
margin: 20px auto;
padding: 25px;
background-color: var(--bg-main);
background-image: linear-gradient(rgba(11, 10, 24, 0.95), rgba(11, 10, 24, 0.95)), url('https://www.transparenttextures.com/patterns/stardust.png');
min-height: calc(100vh - 40px);
border-radius: 8px;
box-shadow: 0 0 25px rgba(0,0,0,0.7);
border: 1px solid var(--border-color);
}
.container .title-container {
background: linear-gradient(135deg, rgba(20, 18, 40, 0.8), rgba(30, 28, 50, 0.6));
margin-bottom: 30px;
border: 1px solid var(--border-color);
border-radius: 6px;
padding: 25px;
text-align: center;
position: relative;
box-shadow: 0 5px 15px rgba(0,0,0,0.4);
overflow: hidden;
}
.container .title-main {
color: var(--white);
font-size: 2.5rem;
font-weight: 700;
margin: 0;
letter-spacing: 4px;
display: block;
text-transform: uppercase;
text-shadow: 0 0 4px var(--glow-primary), 0 0 8px var(--glow-primary), 0 0 12px var(--glow-primary);
font-family: var(--font-title);
}
.container .lemonade-text {
color: var(--secondary-accent);
text-shadow: 0 0 8px var(--glow-secondary);
}
.container .title-subtitle {
padding-left: 0;
margin-top: 15px;
}
.container .subtitle-text {
color: var(--text-muted);
font-size: 1.2rem;
font-family: var(--font-body);
font-style: italic;
font-weight: 400;
letter-spacing: 2px;
text-transform: uppercase;
opacity: 0.8;
}
.container img {
max-width: 100%;
border: 2px solid var(--border-color);
margin-bottom: 40px;
box-shadow: 0 5px 15px rgba(0,0,0,0.5);
border-radius: 4px;
}
.container .section-container {
margin-bottom: 25px;
padding-bottom: 25px;
border-bottom: 1px dashed var(--border-color);
}
.container .section-container:last-of-type {
border-bottom: none;
padding-bottom: 0;
margin-bottom: 0;
}
.container .section-header {
display: flex;
align-items: center;
padding: 0 0 15px 0;
}
.container .section-title {
font-family: var(--font-title);
background: linear-gradient(45deg, var(--secondary-accent), var(--primary-accent));
background-clip: text;
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
font-size: 1.4rem;
margin: 0 !important;
padding: 0 0 10px 0 !important;
letter-spacing: 1px;
font-weight: 700;
text-transform: uppercase;
border: none !important;
position: relative;
display: inline-block;
}
.container .section-title::after {
content: '';
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 2px;
background-image: linear-gradient(to right, var(--secondary-accent), var(--primary-accent));
box-shadow: 0 0 6px var(--glow-secondary), 0 0 6px var(--glow-primary);
border-radius: 2px;
}
.container .section-content {
padding: 20px 0 0 0;
}
.container .subheading {
color: var(--secondary-accent);
font-size: 1.1rem;
margin-top: 20px;
margin-bottom: 12px;
font-weight: 700;
display: block;
text-transform: uppercase;
letter-spacing: 2px;
font-family: var(--font-title);
border-bottom: 1px solid var(--secondary-accent);
padding-bottom: 6px;
text-shadow: 0 0 4px var(--glow-secondary);
}
.container .data-box {
background-color: var(--bg-card);
padding: 15px;
border: 1px solid var(--border-color);
border-left: 2px solid var(--primary-accent);
margin-bottom: 15px;
box-shadow: inset 0 0 6px rgba(0,0,0,0.4);
border-radius: 4px;
font-size: 1rem;
}
.container .data-row {
display: flex;
align-items: center;
margin-bottom: 6px;
padding: 5px 0;
}
.container .data-row:last-child {
margin-bottom: 0;
}
.container .data-arrow {
color: var(--secondary-accent);
font-weight: bold;
margin-right: 10px;
font-family: var(--font-code);
font-size: 1rem;
}
.container .data-label {
color: var(--white);
font-weight: 600;
font-family: var(--font-body);
margin-right: 8px;
min-width: 80px;
}
.container a {
color: var(--primary-accent);
text-decoration: none;
font-weight: 600;
transition: all .2s;
}
.container .data-row a {
border-bottom: 1px dotted var(--primary-accent);
}
.container a:hover {
text-decoration: none;
color: var(--white);
text-shadow: 0 0 5px var(--glow-primary);
}
.container .data-row a:hover {
border-bottom-style: solid;
}
.container .dropdown-container {
margin-top: 20px;
}
.container .dropdown-summary {
cursor: pointer;
padding: 10px 0;
color: var(--text-muted);
font-size: 1.1rem;
font-weight: 700;
text-transform: none;
font-family: var(--font-title);
letter-spacing: 1px;
list-style: none;
transition: color 0.2s ease;
}
.container .dropdown-summary:hover {
color: var(--primary-accent);
}
.container .dropdown-arrow {
color: var(--secondary-accent);
margin-right: 10px;
transition: transform 0.2s ease;
}
.container .dropdown-content {
margin-top: 15px;
padding: 20px;
background-color: var(--bg-card);
border: 1px solid var(--border-color);
border-radius: 4px;
}
.container .config-title {
color: var(--text-muted);
font-size: 1rem;
margin-bottom: 10px;
font-family: var(--font-body);
text-transform: uppercase;
letter-spacing: 1px;
font-weight: 700;
}
.container pre {
background-color: #1c1c1c;
padding: 15px;
border: 1px solid var(--border-color);
white-space: pre-wrap;
word-wrap: break-word;
color: #c5c8c6;
border-radius: 4px;
box-shadow: inset 0 0 5px rgba(0,0,0,0.5);
}
.container pre code {
background: none;
color: inherit;
padding: 0;
border-radius: 0;
}
.container code {
font-family: var(--font-code);
color: var(--primary-accent);
background: var(--border-color);
padding: 2px 5px;
border-radius: 4px;
}
</style>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Painted Fantasy</title>
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Cinzel:wght@400;700&family=MedievalSharp&family=EB+Garamond:ital,wght@0,400;0,500;1,400&display=swap" rel="stylesheet">
</head>
<body>
<div class="container">
<div class="title-container">
<div class="glitchy-overlay"></div>
<div class="title-wrapper">
<h1 class="title-main">
<span class="title-prefix">PAINTED FANTASY</span>
<span class="lemonade-text">VISAGE v3</span>
</h1>
<div class="title-subtitle">
<span class="subtitle-text">Mistrall Small 3.2 Upscaled 34B</span>
</div>
</div>
</div>

<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Overview</h2>
</div>
<div class="section-content">
<p>No layer left behind edition.</p>
<p>Upscale redone with the missing final layer included. The original upscales were always missing a layer, but I never troubleshooted to identify *what* layer was missing. Turns out it was the final layer. That's kind of an important one.</p>
<p>This model is an uncensored, creative writing and RP model. Compared to the older version, it is smarter and I think has a bit less repetition. The old V2 version though is slightly more creative due to the instability it had.</p>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">SillyTavern Settings</h2>
</div>
<div class="section-content">
<h3 class="subheading">Recommended Roleplay Format</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Actions:</span>
<span>In plaintext</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Dialogue:</span>
<span>"In quotes"</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Thoughts:</span>
<span>*In asterisks*</span>
</div>
</div>
<h3 class="subheading">Recommended Samplers</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Temp:</span>
<span>0.7-0.8</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">MinP:</span>
<span>0.05 - 0.1</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">TopP:</span>
<span>0.95</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Dry:</span>
<span>0.8, 1.75, 4</span>
</div>
</div>
<h3 class="subheading">Instruct</h3>
<div class="data-box">
<p style="margin: 0;">Mistral v7 Tekken</p>
</div>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Quantizations</h2>
</div>
<div class="section-content">
<div style="margin-bottom: 20px;">
<h3 class="subheading">GGUF</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/bartowski/zerofata_MS3.2-PaintedFantasy-Visage-v3-34B-GGUF">iMatrix (bartowski)</a>
</div>
</div>
</div>
<div>
<h3 class="subheading">EXL3</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B-exl3-3bpw">3bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B-exl3-4bpw">4bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B-exl3-4.25bpw">4.25bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B-exl3-5bpw">5bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B-exl3-6bpw">6bpw</a>
</div>
</div>
</div>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Creation Process</h2>
</div>
<div class="section-content">
<p>Creation Process: Upscale > CPT > SFT > DPO</p>
<p>Pretrained on approx 300MB of light novel and FineWeb-2 corpus.</p>
<p>SFT on approx 8 million tokens, SFW / NSFW RP, stories and creative instruct data.</p>
<p>DPO on a high quality RP / NSFW dataset with a focus on improving instruction following, reducing repetition and fixing common model mistakes.</p>
<div class="dropdown-container">
<details>
<summary class="dropdown-summary">
<span class="dropdown-arrow">></span>
Mergekit configs
</summary>
<div class="dropdown-content">
<p>Merge configurations used during the model creation process.</p>
<div class="config-title">Upscale (Passthrough)</div>
<pre><code>base_model: ConicCat/Mistral-Small-3.2-AntiRep-24B
merge_method: passthrough
dtype: bfloat16
slices:
- sources:
- model: ConicCat/Mistral-Small-3.2-AntiRep-24B
layer_range: [0, 29]
- sources:
- model: ConicCat/Mistral-Small-3.2-AntiRep-24B
layer_range: [10, 40]</code></pre>
</div>
</details>
</div>
<div class="dropdown-container">
<details>
<summary class="dropdown-summary">
<span class="dropdown-arrow">></span>
Axolotl configs
</summary>
<div class="dropdown-content">
<p>Not optimized for cost / performance efficiency, YMMV.</p>
<div class="config-title">Pretrain 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ../mergekit/pf_v3_upscale
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./data/pretrain_dataset_v5_stripped.jsonl
type: completion
<br>
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 32
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 1
micro_batch_size: 4
gradient_accumulation_steps: 1
learning_rate: 4e-5
optimizer: paged_adamw_8bit
lr_scheduler: rex
warmup_ratio: 0.05
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE & PACKING
# ====================
sequence_len: 12288
sample_packing: true
eval_sample_packing: false
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
# ====================
# EVALUATION & CHECKPOINTING
# ====================
save_strategy: steps
save_steps: 40
save_total_limit: 5 # Keep best + last few checkpoints
load_best_model_at_end: true
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V3-PT-1
logging_steps: 2
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V3-PT
# wandb_entity: your_entity
wandb_name: Visage-V3-PT-1</code></pre>
<div class="config-title">SFT 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ./Visage-V3-PT-1/merged
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
<br>
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./data/dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
<br>
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 128
lora_alpha: 128
lora_dropout: 0.1
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 3
micro_batch_size: 4
gradient_accumulation_steps: 1
learning_rate: 1e-5
optimizer: paged_adamw_8bit
lr_scheduler: rex
warmup_ratio: 0.05
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE & PACKING
# ====================
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
# ====================
# EVALUATION & CHECKPOINTING
# ====================
save_strategy: steps
save_steps: 20
save_total_limit: 5 # Keep best + last few checkpoints
load_best_model_at_end: true
metric_for_best_model: eval_loss
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V3-PT-1-SFT-2
logging_steps: 1
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V3-SFT
# wandb_entity: your_entity
wandb_name: Visage-V3-PT-1-SFT-2</code></pre>
<div class="config-title">DPO 2*H200</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ./Visage-V3-PT-1-SFT-2/merged
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
<br>
# ====================
# RL/DPO CONFIGURATION
# ====================
rl: dpo
rl_beta: 0.085
<br>
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./data/handcrafted_dataset_mistral_rep.jsonl
type: chat_template.default
field_messages: messages
field_chosen: chosen
field_rejected: rejected
message_property_mappings:
role: role
content: content
roles:
system: ["system"]
user: ["user"]
assistant: ["assistant"]
- path: ./data/approved_automated_l3_dataset.jsonl
type: chat_template.default
field_messages: messages
field_chosen: chosen
field_rejected: rejected
message_property_mappings:
role: role
content: content
roles:
system: ["system"]
user: ["user"]
assistant: ["assistant"]
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: lora
load_in_8bit: true
lora_r: 16
lora_alpha: 32
lora_dropout: 0.1
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 1
micro_batch_size: 2
gradient_accumulation_steps: 4
learning_rate: 2e-6
optimizer: adamw_torch_fused
lr_scheduler: cosine
warmup_steps: 5
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE CONFIGURATION
# ====================
sequence_len: 8192
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
tf32: false
flash_attention: true
gradient_checkpointing: offload
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
deepspeed: deepspeed_configs/zero1.json
<br>
# ====================
# CHECKPOINTING
# ====================
save_steps: 10
save_total_limit: 10
load_best_model_at_end: true
metric_for_best_model: eval_loss
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V3-PT-1-SFT-2-DPO-2
logging_steps: 1
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V3-DPO
# wandb_entity: your_entity
wandb_name: Visage-V3-PT-1-SFT-2-DPO-2</code></pre>
</div>
</details>
</div>
</div>
</div>
</div>
</body>
</html>
| null | null |
[
"zerofata/Instruct-Anime",
"zerofata/Instruct-Anime-CreativeWriting",
"zerofata/Roleplay-Anime-Characters",
"zerofata/Summaries-Anime-FandomPages"
] | null | 34,131,758,080
| null | null | null |
[
"MistralForCausalLM",
"mistral"
] | null | null | null |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ac918e5b81f96e98af8e77
|
OpenGVLab/InternVL3_5-30B-A3B-Instruct
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac918dcd5cacefdd03b125",
"id": "OpenGVLab/InternVL3_5-30B-A3B-Pretrained"
}
],
"relation": "finetune"
}
| 522
| 522
|
False
| 2025-08-25T16:38:38Z
| 2025-08-29T17:57:03Z
|
transformers
| 10
| 10
| null |
image-text-to-text
|
{"parameters": {"BF16": 30848730112}, "total": 30848730112}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"config.json",
"configuration.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"layer-0-ep-0-of-1.safetensors",
"layer-1-ep-0-of-1.safetensors",
"layer-10-ep-0-of-1.safetensors",
"layer-11-ep-0-of-1.safetensors",
"layer-12-ep-0-of-1.safetensors",
"layer-13-ep-0-of-1.safetensors",
"layer-14-ep-0-of-1.safetensors",
"layer-15-ep-0-of-1.safetensors",
"layer-16-ep-0-of-1.safetensors",
"layer-17-ep-0-of-1.safetensors",
"layer-18-ep-0-of-1.safetensors",
"layer-19-ep-0-of-1.safetensors",
"layer-2-ep-0-of-1.safetensors",
"layer-20-ep-0-of-1.safetensors",
"layer-21-ep-0-of-1.safetensors",
"layer-22-ep-0-of-1.safetensors",
"layer-23-ep-0-of-1.safetensors",
"layer-24-ep-0-of-1.safetensors",
"layer-25-ep-0-of-1.safetensors",
"layer-26-ep-0-of-1.safetensors",
"layer-27-ep-0-of-1.safetensors",
"layer-28-ep-0-of-1.safetensors",
"layer-29-ep-0-of-1.safetensors",
"layer-3-ep-0-of-1.safetensors",
"layer-30-ep-0-of-1.safetensors",
"layer-31-ep-0-of-1.safetensors",
"layer-32-ep-0-of-1.safetensors",
"layer-33-ep-0-of-1.safetensors",
"layer-34-ep-0-of-1.safetensors",
"layer-35-ep-0-of-1.safetensors",
"layer-36-ep-0-of-1.safetensors",
"layer-37-ep-0-of-1.safetensors",
"layer-38-ep-0-of-1.safetensors",
"layer-39-ep-0-of-1.safetensors",
"layer-4-ep-0-of-1.safetensors",
"layer-40-ep-0-of-1.safetensors",
"layer-41-ep-0-of-1.safetensors",
"layer-42-ep-0-of-1.safetensors",
"layer-43-ep-0-of-1.safetensors",
"layer-44-ep-0-of-1.safetensors",
"layer-45-ep-0-of-1.safetensors",
"layer-46-ep-0-of-1.safetensors",
"layer-47-ep-0-of-1.safetensors",
"layer-5-ep-0-of-1.safetensors",
"layer-6-ep-0-of-1.safetensors",
"layer-7-ep-0-of-1.safetensors",
"layer-8-ep-0-of-1.safetensors",
"layer-9-ep-0-of-1.safetensors",
"merges.txt",
"model.safetensors.index.json",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"others.safetensors",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vision.safetensors",
"vocab.json"
] | null | null |
83f9a51dbd940c291fb149debee61502f19444d2
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-30B-A3B-Pretrained",
"base_model:finetune:OpenGVLab/InternVL3_5-30B-A3B-Pretrained",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-30B-A3B-Instruct
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 30,848,730,112
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ac9193c440188d9001a0a9
|
OpenGVLab/InternVL3_5-2B
|
OpenGVLab
|
{
"models": [
{
"_id": "68ac9193cb035c54bcd1a524",
"id": "OpenGVLab/InternVL3_5-2B-MPO"
}
],
"relation": "finetune"
}
| 6,262
| 6,262
|
False
| 2025-08-25T16:38:43Z
| 2025-08-29T17:57:07Z
|
transformers
| 10
| 10
| null |
image-text-to-text
|
{"parameters": {"BF16": 2348347392}, "total": 2348347392}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"chat_template.jinja",
"config.json",
"configuration_intern_vit.py",
"configuration_internvl_chat.py",
"conversation.py",
"generation_config.json",
"merges.txt",
"model.safetensors",
"modeling_intern_vit.py",
"modeling_internvl_chat.py",
"preprocessor_config.json",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"video_preprocessor_config.json",
"vocab.json"
] |
[
1570,
53703,
892,
475,
2482,
5546,
4700,
15309,
69,
1671853,
4696775752,
18151,
16518,
666,
72,
744,
11424300,
7164,
1345,
2776833
] | 4,712,778,144
|
7d7bd7bcc35b77b391883ebd7f9686cfa0e25cc0
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"dataset:OpenGVLab/MMPR-Tiny",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2508.18265",
"base_model:OpenGVLab/InternVL3_5-2B-MPO",
"base_model:finetune:OpenGVLab/InternVL3_5-2B-MPO",
"license:apache-2.0",
"region:us"
] | null |
# InternVL3_5-2B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.

> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
See [quick start](#quick-start) for how to use our model.
## InternVL3.5 Family
In the following table, we provide an overview of the InternVL3.5 series.
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
### Github Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
### HuggingFace Format
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |

> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.

Here, we also open-source the model weights after different training stages for potential research usage.
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
| Model | Training Pipeline | HF Link | ModelScope Link |
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
The Flash version of our model will be released as soon as possible.
## Model Architecture
`InternVL3.5`:
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
`InternVL3.5-Flash`:
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.

## Training and Deployment Strategy
### Pre-Training
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
$$
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
$$
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
$$
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
$$
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
### Supervised Fine-Tuning
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
### Cascade Reinforcement Learning
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
$$
\mathcal{L}_{\text{MPO}}=
w_{p} \mathcal{L}_{p}
+
w_{q} \mathcal{L}_{q}
+
w_{g} \mathcal{L}_{g}
,
$$
where \\(w_{*}\\) represents the weight assigned to each loss component.
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
The training objective of GSPO is given by:
$$
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
$$
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Visual Consistency Learning
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
`Consistency training`:
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
$$
\mathcal{L}_\text{ViCO} =
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
\Big)
\Bigg],
$$
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
`Router training`:
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
Specifically, we first compute the loss ratio for each patch:
$$
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
$$
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
$$
y_i^\text{router} =
\begin{cases}
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
1, & r_i \ge \tau \; \text{(compression has significant impact)},
\end{cases}
$$
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
### Test-Time Scaling
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
This approach improves reasoning breadth.
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
### Decoupled Vision-Language Deployment
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.

As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image Understanding & Real-World Comprehension

### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Tasks

### Embodied Tasks

### SVG Tasks


## Evaluation on Language Capability

## Ablation Study
### Cascade Reinforcement Learning


### Decoupled Vision-Language Deployment

## Quick Start
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3_5-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
```
### Thinking Mode
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
```python
R1_SYSTEM_PROMPT = """
You are an AI assistant that rigorously follows this response protocol:
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
""".strip()
model.system_message = R1_SYSTEMP_PROMPT
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL3_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
pip install lmdeploy>=0.9.1
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
response = pipe(('describe this image', image))
print(response.text)
```
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, PytorchEngineConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
model = 'OpenGVLab/InternVL3_5-8B'
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2025internvl3_5,
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
journal={arXiv preprint arXiv:2508.18265},
year={2025}
}
```
| null |
[
"apache-2.0"
] |
[
"OpenGVLab/MMPR-v1.2",
"OpenGVLab/MMPR-Tiny"
] |
[
"multilingual"
] | 2,348,347,392
| null |
[
"feature-extraction",
"image-text-to-text"
] | null |
[
"modeling_internvl_chat.InternVLChatModel",
"AutoModel",
"InternVLChatModel",
"internvl_chat"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"embeddings",
"text"
] |
free
|
community
|
[
"China"
] | null | null | null | null | null | null | null | null | null |
68ada566f962e925e83c1534
|
Kwai-Keye/Keye-VL-1_5-8B
|
Kwai-Keye
| null | 490
| 490
|
False
| 2025-08-26T12:15:34Z
| 2025-08-28T04:44:51Z
| null | 10
| 10
| null |
image-text-to-text
|
{"parameters": {"BF16": 8696835648}, "total": 8696835648}
|
[
".gitattributes",
"README.md",
"added_tokens.json",
"asset/.DS_Store",
"asset/architecture.png",
"asset/keye_logo_2.png",
"asset/keyelogo/Keye-logo--black.png",
"asset/keyelogo/Keye-logo--white.png",
"asset/keyelogo/Keye-logo.png",
"asset/performance.png",
"asset/post1.jpeg",
"asset/post1.png",
"asset/post2.jpeg",
"asset/post2.png",
"asset/pre-train.png",
"asset/teaser.png",
"chat_template.json",
"config.json",
"configuration_keye_vl_1_5.py",
"generation_config.json",
"image_processing_keye_vl_1_5.py",
"merges.txt",
"model-00001-of-00004.safetensors",
"model-00002-of-00004.safetensors",
"model-00003-of-00004.safetensors",
"model-00004-of-00004.safetensors",
"model.safetensors.index.json",
"modeling_keye_vl_1_5.py",
"preprocessor_config.json",
"processing_keye_vl_1_5.py",
"processor_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] | null | null |
aea2b9f2efac71906cef2f599c0328ead7df5f7d
|
[
"safetensors",
"KeyeVL1_5",
"image-text-to-text",
"conversational",
"custom_code",
"zh",
"en",
"arxiv:2507.01949",
"license:apache-2.0",
"region:us"
] | null | null | null |
[
"apache-2.0"
] | null |
[
"zh",
"en"
] | 8,696,835,648
| null |
[
"image-text-to-text"
] | null |
[
"KeyeVL1_5ForConditionalGeneration",
"KeyeVL1_5"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"text"
] |
user
|
user
|
[
"user"
] | null | null | null | null | null | null | null | null | null |
68ae55fb63ae2d03c386b82a
|
unsloth/Hermes-4-70B-GGUF
|
unsloth
|
{
"models": [
{
"_id": "68a34925f057ffe5051b5b6b",
"id": "NousResearch/Hermes-4-70B"
}
],
"relation": "quantized"
}
| 5,027
| 5,027
|
False
| 2025-08-27T00:48:59Z
| 2025-08-27T06:29:13Z
|
transformers
| 10
| 10
|
[{"name": "Hermes-4-Llama-3.1-70B", "results": []}]
| null | null |
[
".gitattributes",
"BF16/Hermes-4-70B-BF16-00001-of-00003.gguf",
"BF16/Hermes-4-70B-BF16-00002-of-00003.gguf",
"BF16/Hermes-4-70B-BF16-00003-of-00003.gguf",
"Hermes-4-70B-IQ4_NL.gguf",
"Hermes-4-70B-IQ4_XS.gguf",
"Hermes-4-70B-Q2_K.gguf",
"Hermes-4-70B-Q2_K_L.gguf",
"Hermes-4-70B-Q3_K_M.gguf",
"Hermes-4-70B-Q3_K_S.gguf",
"Hermes-4-70B-Q4_0.gguf",
"Hermes-4-70B-Q4_1.gguf",
"Hermes-4-70B-Q4_K_M.gguf",
"Hermes-4-70B-Q4_K_S.gguf",
"Hermes-4-70B-Q5_K_M.gguf",
"Hermes-4-70B-Q5_K_S.gguf",
"Hermes-4-70B-UD-IQ1_M.gguf",
"Hermes-4-70B-UD-IQ1_S.gguf",
"Hermes-4-70B-UD-IQ2_M.gguf",
"Hermes-4-70B-UD-IQ2_XXS.gguf",
"Hermes-4-70B-UD-IQ3_XXS.gguf",
"Hermes-4-70B-UD-Q2_K_XL.gguf",
"Hermes-4-70B-UD-Q3_K_XL.gguf",
"Hermes-4-70B-UD-Q4_K_XL.gguf",
"Hermes-4-70B-UD-Q5_K_XL.gguf",
"Q6_K/Hermes-4-70B-Q6_K-00001-of-00002.gguf",
"Q6_K/Hermes-4-70B-Q6_K-00002-of-00002.gguf",
"Q8_0/Hermes-4-70B-Q8_0-00001-of-00002.gguf",
"Q8_0/Hermes-4-70B-Q8_0-00002-of-00002.gguf",
"README.md",
"UD-Q6_K_XL/Hermes-4-70B-UD-Q6_K_XL-00001-of-00002.gguf",
"UD-Q6_K_XL/Hermes-4-70B-UD-Q6_K_XL-00002-of-00002.gguf",
"UD-Q8_K_XL/Hermes-4-70B-UD-Q8_K_XL-00001-of-00002.gguf",
"UD-Q8_K_XL/Hermes-4-70B-UD-Q8_K_XL-00002-of-00002.gguf",
"imatrix_unsloth.gguf_file"
] |
[
3803,
49875754432,
49779916256,
41462247744,
40053623968,
37935500448,
26375113888,
26621365408,
34267499680,
30912056480,
40116538528,
44313595040,
42520399008,
40347225248,
49949822112,
48657452192,
17145875616,
15854029984,
24295197856,
19431115936,
27655621792,
26966740128,
34784726176,
42664578208,
49859710112,
49973949824,
7914199008,
49928000384,
25047054816,
10142,
49993608672,
11166457728,
49923737856,
31307383904,
24989760
] | 1,137,125,102,137
|
b5483741203956fbc0557a26429ee73bf4cb7944
|
[
"transformers",
"gguf",
"Llama-3.1",
"unsloth",
"instruct",
"finetune",
"reasoning",
"hybrid-mode",
"chatml",
"function calling",
"tool use",
"json mode",
"structured outputs",
"atropos",
"dataforge",
"long context",
"roleplaying",
"chat",
"en",
"arxiv:2508.18255",
"base_model:NousResearch/Hermes-4-70B",
"base_model:quantized:NousResearch/Hermes-4-70B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
{"total": 70553706560, "architecture": "llama", "context_length": 131072, "quantize_imatrix_file": "Hermes-4-70B-GGUF/imatrix_unsloth.gguf", "chat_template": "{#- Unsloth template fixes #}\n{%- set thinking_prompt = 'You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.' %}\n{%- set standard_prompt = 'You are Hermes, created by Nous Research.' %}\n{%- if enable_thinking is defined and enable_thinking is false %}{% set thinking = false %}\n{%- elif enable_thinking is defined and enable_thinking is true %}{% set thinking = true %}\n{%- elif not thinking is defined %}{% set thinking = false %}\n{% endif %}\n{%- if not keep_cots is defined %}{% set keep_cots = false %}{% endif %}\n{%- if thinking %}{%- set system_prompt = thinking_prompt %}{%- else %}{%- set system_prompt = standard_prompt %}{%- endif %}\n{%- if tools %}\n {{- bos_token + '<|start_header_id|>system<|end_header_id|>\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- system_prompt }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou are a function calling AI model. You may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": \\\"<function-name>\\\", \\\"arguments\\\": <args-json-object>}\\n</tool_call><|eot_id|>\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- bos_token + '<|start_header_id|>system<|end_header_id|>\\n\\n' + messages[0]['content'] + '<|eot_id|>' }}\n {%- else %}\n {{- bos_token + '<|start_header_id|>system<|end_header_id|>\\n\\n' + system_prompt + '<|eot_id|>' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|start_header_id|>' + message.role + '<|end_header_id|>\\n\\n' + message.content + '<|eot_id|>' }}\n {%- elif (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|start_header_id|>' + message.role + '<|end_header_id|>\\n' }}\n {%- if message.content %}\n {%- set content = message['content'] -%}\n {%- if thinking %}\n {%- if not keep_cots %}\n {%- set splitted = content.split('</think>') -%}\n {%- set second_part = splitted[1:] | join('</think>') -%}\n {%- set content = '<think> </think>' + second_part -%}\n {%- endif %}\n {%- endif %}\n {{- '\\n' + content + '<|eot_id|>' }}\n {%- endif %}\n {%- elif message.role == \"assistant\" %}\n {{- '<|start_header_id|>' + message.role + '<|end_header_id|>\\n' }}\n {%- if message.content %}\n {%- set content = message['content'] -%}\n {%- if thinking %}\n {%- if not keep_cots %}\n {%- set splitted = content.split('</think>') -%}\n {%- set second_part = splitted[1:] | join('</think>') -%}\n {%- set content = '<think> </think>' + second_part -%}\n {%- endif %}\n {%- endif %}\n {{- '\\n' + content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|eot_id|>' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|start_header_id|>user<|end_header_id|>\\n' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|eot_id|>' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}\n{%- endif %}\n{#- Copyright 2025-present Unsloth. Apache 2.0 License. #}", "bos_token": "<|begin_of_text|>", "eos_token": "<|eot_id|>"}
|
> [!NOTE]
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
>
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
</div>
# Hermes 4 — Llama-3.1 70B

## Model Description
Hermes 4 70B is a frontier, hybrid-mode **reasoning** model based on Llama-3.1-70B by Nous Research that is aligned to **you**.
Read the Hermes 4 technical report here: <a href="https://arxiv.org/abs/2508.18255">Hermes 4 Technical Report</a>
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
## What’s new vs Hermes 3
- **Post-training corpus**: Massively increased dataset size from 1M samples and 1.2B tokens to **~5M samples / ~60B tokens** blended across reasoning and non-reasoning data.
- **Hybrid reasoning mode** with explicit `<think>…</think>` segments when the model decides to deliberate, and options to make your responses faster when you want.
- **Reasoning** that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- **Schema adherence & structured outputs**: trained to produce valid JSON for given schemas and to repair malformed objects.
- **Much easier to steer and align**: extreme improvements on steerability, especially on reduced refusal rates.
## Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.

Hermes 4 achieves SOTA on RefusalBench across all popular closed and open models in being helpful and conforming to your values, without censorship.
## Benchmarks (Hermes 4 70B)

> Full tables, settings, and comparisons are in the technical report.
## Prompt Format
Hermes 4 uses Llama-3-Chat format with role headers and special tags.
**Basic chat:**
```
<|start_header_id|>system<|end_header_id|>
You are Hermes 4. Be concise and helpful.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Explain the photoelectric effect simply.<|im_end|>
<|start_header_id|>assistant<|end_header_id|>
```
### Reasoning mode
Reasoning mode can be activated with the chat template via the flag `thinking=True` or by using the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
Note that you can add any additional system instructions before or after this system message, and it will adjust the models policies, style, and effort of thinking, as well as its post-thinking style, format, identity, and more. You may also interleave the tool definition system message with the reasoning one.
When the model chooses to deliberate, it emits:
```
<|start_header_id|>assistant<|end_header_id|>
<think>
…model’s internal reasoning may appear here…
</think>
Final response starts here…<|eot_id|>
```
Additionally, we provide a flag to keep the content inbetween the `<think> ... </think>` that you can play with by setting `keep_cots=True`
## Function Calling & Tool Use
Hermes 4 supports function/tool calls *within* a single assistant turn, produced after it's reasoning:
**System message (example):**
```
<|im_start|>system
You are a function-calling AI. Tools are provided inside <tools>…</tools>.
When appropriate, call a tool by emitting a <tool_call>{...}</tool_call> object.
After a tool responds (as <tool_response>), continue reasoning inside <think> and produce the final answer.
<tools>
{"type":"function","function":{"name":"get_weather","description":"Get weather by city","parameters":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"]}}}
</tools><|im_end|>
```
Note that you may also simply place tool definitions into the "tools:" field of your messages, and the chat template will parse and create the system prompt for you. This also works with reasoning mode for improved accuracy of tool use.
The model will then generate tool calls within `<tool_call> {tool_call} </tool_call>` tags, for easy parsing. The tool_call tags are also added tokens, so it makes it easy to parse while streaming! There are also automatic tool parsers built-in to VLLM and SGLang for Hermes, just set the tool parser in VLLM to `hermes` and in SGLang to `qwen25`.
## Inference Notes
- **Sampling defaults that work well:** `temperature=0.6, top_p=0.95, top_k=20`.
- **Template:** Use the Llama chat format for Hermes 4 70B and 405B as shown above, or set `add_generation_prompt=True` when using `tokenizer.apply_chat_template(...)`.
### Transformers example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "NousResearch/Hermes-4-Llama-3.1-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
messages = [
{"role":"system","content":"You are Hermes 4. Be concise."},
{"role":"user","content":"Summarize CRISPR in 3 sentences."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
**inputs, max_new_tokens=400, temperature=0.6, top_p=0.95, top_k=20, do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For production serving on multi-GPU nodes, consider tensor parallel inference engines (e.g., SGLang/vLLM backends) with prefix caching.
## Inference Providers:
### Nous Portal:
<a href="https://portal.nousresearch.com"><img width=256 alt="chutes logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/6YytY7N0mjCnBQvWo3qtv.png"></a>
### Chutes:
<a href="https://chutes.ai/app"><img width=256 alt="chutes logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/l14AWPv6cSvaprpwK_IWY.png"></a>
### Nebius:
<a href="https://nebius.com/services/studio-inference-service">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/vhL0oAomFa_awBdt2KF_x.png">
<source media="(prefers-color-scheme: light)" srcset="https://cdn-uploads.huggingface.co/production/uploads/64b21cbb2fc8324fcb1dac03/LjAfeFfAz8ac5rV-iiwj5.png">
<img width=256 alt="nebius.com logo" src="https://cdn-uploads.huggingface.co/production/uploads/64b21cbb2fc8324fcb1dac03/LjAfeFfAz8ac5rV-iiwj5.png">
</picture>
</a>
### Luminal:
<a href="https://luminalai.com/">
<img width=256 alt="luminal logo" src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/FIHsRdjMMP0HUjebiuJyH.png">
</a>
# Quantized / Smaller Variants
Hermes 4 is available as BF16 original weights as well as BF16 as well as FP8 variants and GGUF variants by LM Studio.
FP8: https://huggingface.co/NousResearch/Hermes-4-70B-FP8
GGUF (Courtesy of LM Studio team!):
https://huggingface.co/lmstudio-community/Hermes-4-70B-GGUF
Hermes 4 is also available in smaller sizes (e.g., 70B) with similar prompt formats.
See the Hermes 4 collection to explore them all:
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
# How to cite
```bibtex
@misc{teknium2025hermes4technicalreport,
title={Hermes 4 Technical Report},
author={Ryan Teknium and Roger Jin and Jai Suphavadeeprasit and Dakota Mahan and Jeffrey Quesnelle and Joe Li and Chen Guang and Shannon Sands and Karan Malhotra},
year={2025},
eprint={2508.18255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.18255},
}
```
| null |
[
"llama3"
] | null |
[
"en"
] | null | 70,553,706,560
|
[
null
] | null |
[
"AutoModel",
"llama"
] | null | null | null |
team
|
company
|
[
"United States of America"
] | null | null | null | null | null | null | null | null | null |
621ffdc136468d709f17ea63
|
openai/clip-vit-large-patch14
|
openai
| null | 9,134,528
| 1,025,226,826
|
False
| 2022-03-02T23:29:05Z
| 2023-09-15T15:49:35Z
|
transformers
| 1,851
| 9
| null |
zero-shot-image-classification
|
{"parameters": {"I64": 334, "F32": 427616512}, "total": 427616846}
|
[
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"model.safetensors",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
] |
[
1229,
7947,
4519,
1710486359,
524619,
1710540580,
316,
1710671599,
389,
1711114176,
2224003,
905,
961143
] | 6,846,537,784
|
32bd64288804d66eefd0ccbe215aa642df71cc41
|
[
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"clip",
"zero-shot-image-classification",
"vision",
"arxiv:2103.00020",
"arxiv:1908.04913",
"endpoints_compatible",
"region:us"
] | null |
# Model Card: CLIP
Disclaimer: The model card is taken and modified from the official CLIP repository, it can be found [here](https://github.com/openai/CLIP/blob/main/model-card.md).
## Model Details
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
January 2021
### Model Type
The base model uses a ViT-L/14 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
### Documents
- [Blog Post](https://openai.com/blog/clip/)
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
### Use with Transformers
```python
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
### Data Mission Statement
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
## Performance and Limitations
### Performance
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
- Food101
- CIFAR10
- CIFAR100
- Birdsnap
- SUN397
- Stanford Cars
- FGVC Aircraft
- VOC2007
- DTD
- Oxford-IIIT Pet dataset
- Caltech101
- Flowers102
- MNIST
- SVHN
- IIIT5K
- Hateful Memes
- SST-2
- UCF101
- Kinetics700
- Country211
- CLEVR Counting
- KITTI Distance
- STL-10
- RareAct
- Flickr30
- MSCOCO
- ImageNet
- ImageNet-A
- ImageNet-R
- ImageNet Sketch
- ObjectNet (ImageNet Overlap)
- Youtube-BB
- ImageNet-Vid
## Limitations
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
### Bias and Fairness
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
## Feedback
### Where to send questions or comments about the model
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9)
|
[
"bytedance-research/USO",
"AI4Editing/MagicQuill",
"Kunbyte/OmniTry",
"ginigen/Fashion-Fit360",
"ameerazam08/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"fffiloni/InstantIR",
"Fabrice-TIERCELIN/SUPIR",
"yanze/PuLID-FLUX",
"multimodalart/flux-fill-outpaint",
"THUdyh/Ola",
"ByteDance/XVerse",
"oyly/LORE",
"MGZON/mgzon-app",
"PAIR/HD-Painter",
"levihsu/OOTDiffusion",
"multimodalart/cosxl",
"Fabrice-TIERCELIN/Text-to-Audio",
"burakcanbiner/SonicDiffusion",
"Doubiiu/tooncrafter",
"okaris/omni-zero",
"Sunday01/testapi",
"latentexplorers/latentnavigation-flux",
"aiqtech/kofaceid",
"fantaxy/flx-pulid",
"InstantX/flux-IP-adapter",
"jallenjia/flux-fill-outpaint",
"BoyuanJiang/FitDiT",
"fffiloni/DiffuEraser-demo",
"fffiloni/Light-A-Video",
"PrunaAI/InferBench",
"dkatz2391/TRELLIS_TextTo3D_Try2",
"Kunbyte/DRA-Ctrl",
"Kunbyte/Lumen",
"kontext-community/FLUX.1-Kontext-multi-image",
"azhan77168/mq-yin",
"Yossilevii100/CLIPLatent",
"bep40/USO",
"Jonny001/Fill-Images",
"ginigen/Fashion-Pose-Control",
"awacke1/Image-Semantic-Search",
"spencer/socm",
"taesiri/CLIPScore",
"micole66/owo",
"jracca/02-learning-space",
"AIZeroToHero/03-ImageSearchSimilar",
"bdp-AI/03-ImageSearchSimilar",
"panpan06/ImageSearchSimilar",
"Jack000/glid-3-xl-stable-classifier",
"keturn/diffusers-preview-demo",
"AIZ2H/06-Streamlit-NLP-Image-Semantic-Search-Images",
"manishjaiswal/06-Streamlit-NLP-Image-Semantic-Search-Images-Demo",
"pharmapsychotic/CLIP-Interrogator",
"lnyan/stablediffusion-infinity",
"Rothfeld/textual-inversion-init-token",
"MarketINK/MarketINK",
"timboie/test",
"lkc290/cs7150",
"GV05/stable-diffusion-mingle-prompts",
"AIZero2Hero4Health/4-ImageSimilaritySearch-SL",
"hizkifw/clipbooru",
"shi-labs/Versatile-Diffusion",
"osanseviero/Versatile-Diffusion",
"llama-vs-capybara/test",
"alecmueller/06-ImageSimilaritySearch-SL",
"dever/stablediffusion-infinity",
"LK666/CLIP-Interrogator",
"bigslime/stablediffusion-infinity",
"MartinRages/Versatile-Diffusion",
"Froleptan/stablediffusion-infinity",
"Wmcs91/Versatile-Diffusion",
"aayushmnit/diffedit",
"shadow/CLIP-Interrogator",
"unbee/Diffusion-Attentive-Attribution-Maps",
"vonbarnekowa/stable-diffusion",
"guoyang/stable-diffusion",
"voctor/CLIP-Interrogator",
"renatotn7/SearchSemanticaly",
"fffiloni/imagic-stable-diffusion",
"teddybearxzh/Versatile-Diffusion",
"JoshiaT/stablediffusion",
"shape-guided-diffusion/shape-guided-diffusion",
"anaclumos/CLIP-Interrogator",
"akhaliq/stable-dreamfusion",
"amankishore/sjc",
"MirageML/sjc",
"Sitydidit/Sity-Fusion-001",
"achterbrain/Intel-Generative-Image-Dashboard",
"absss/stable-diffusion-depth2img",
"YeOldHermit/Super-Resolution-Anime-Diffusion",
"bradarrML/stablediffusion-infinity",
"paracanthurus/lol",
"SaintPepe/oimkl",
"erwann/Face-editor",
"echo666/CLIP-Interrogator-echo",
"BlueRay525/CLIP-Interrogator2",
"BlueRay525/CLIP-Interrogator24",
"artspark/CLIP-Interrogatorr",
"daspartho/MagicMix",
"Korakoe/convert-sd-ckpt-cpu",
"xtcjunkie/CLIP-Interrogator",
"ismot/testaus4",
"konerusudhir/mp_art_classification",
"x17ah/openai-clip-vit-large-patch14",
"csncsn/AI_Gen_for_SG",
"deedax/Change-Your-Style",
"shadel/CLIP-Interrogator",
"ElixirRod/Versatile-Diffusion",
"konerusudhir/mp_art_search_1_1",
"asdf789/CLIP-Interrogator",
"ykrop/CLIP-Interrogator1",
"TRaw/digital-alchemy",
"sohojoe/soho-clip",
"popersfart/CLIP-Interrogator",
"metaboxers/CLIP-Interrogator",
"ismot/12t7",
"quintosh/CLIP-Interrogator",
"arsentap/openai-clip-vit-large-patch14",
"podsni/openai-clip-vit-large-patch14",
"Fr33d0m21/Remodel_Dreamer",
"tornadoslims/instruct-pix2pix",
"TwoPerCent/instruct-pix2pix",
"AmanSharma/instruct-pix2pix",
"benpalgi/instruct-pix2pix",
"Steljoka/instruct-pix2pix4444444",
"lylylyAI/instruct-pix2pix",
"thomasht86/instruct-pix2pix",
"devildredd/CLIP-Interrogator",
"Flyxion/CLIP-Interrogator",
"kadirnar/Video-Diffusion-WebUI",
"Gertie01/CLIP-Interrogator",
"Valenslimes/CLIP-Interrogator",
"nazih/openai-clip-vit-large-patch14",
"nazih/openai-clip-vit-large-patch14-gradio",
"LowTech360/openai-clip-vit-large-patch14",
"onzalito/CLIP-Interrogator",
"kjartanw/openai-clip-vit-large-patch14",
"Aikrissada677/CLIP-Interrogator",
"panda98/CLIP-Interrogator",
"Hallucinate/demo",
"liangsu9988/test_SD1.5",
"Salesforce/EDICT",
"mahmuod/CLIP-Interrogator",
"Andre52/openai-clip-vit-large-patch14",
"Purple11/Grounded-Diffusion",
"RamAnanth1/T2I-Adapter",
"alvanlii/FROMAGe",
"wendys-llc/CLIP-Interrogator",
"jykoh/fromage",
"PaulArn/CLIP-Interrogator",
"xianbao/demo_test",
"Adapter/T2I-Adapter",
"zhuqingyu/CLIP_Interrogator_imagetotext",
"Thaweewat/ControlNet-Architecture",
"omegaodin/openai-clip-vit-large-patch14",
"xiaozeng/lora_test",
"1toTree/lora_test",
"pripishchik/clip-image",
"pripishchik/clip-text",
"christopherbfrance/CLIP-Interrogator",
"gligen/demo",
"pysunny/test_sd",
"returnfalse/teset-webui",
"kingpreyansh/multinet",
"stanno/stablediffusion-infinity-capstonetest",
"ntcwai/T2I-Adapter",
"ELITE-library/ELITE",
"kingpreyansh/Stable_Diffusion",
"bobzheng/understandImage",
"antonovmaxim/text-generation-webui-space",
"Persing/CLIP-Interrogator",
"baulab/Erasing-Concepts-In-Diffusion",
"ethansmith2000/MegaEdit",
"jyseo/3DFuse",
"awacke1/Model-Easy-Button1-ZeroShotImageClassifier-Openai-clip-vit-large-patch14",
"ceckenrode/Model-Easy-Button1-ZeroShotImageClassifier-Openai-clip-vit-large-patch14",
"ceckenrode/Easy-Button-openai-clip-vit-large-patch14",
"awacke1/EasyButton-openai-clip-vit-large-patch14",
"JerEpoch/Button-openai-clip-vit-large-patch14",
"rholtwo/Model-Easy-Button1-ZeroShotImageClassifier-Openai-clip-vit-large-patch14",
"Adapter/CoAdapter",
"PushkarA07/Cover-Gen-text2img",
"PushkarA07/Cover-Gen-audio2image",
"slopppy/openai-clip-vit-large-patch14",
"cvlab/zero123-live",
"songweig/rich-text-to-image",
"daviddemeij/openai-clip-vit-large-patch14",
"PAIR/PAIR-Diffusion",
"guidel/CLIP",
"DeepCoreB4/stable-diffusion-webui-master",
"lychees/Stable-Diffusion-ControlNet-WebUI",
"Seiriryu/Erasing-Concepts-In-Diffusion",
"theholycityweb/openai-clip-vit-large-patch14",
"HiPer0/HiPer",
"jennysun/jwsun-multisubject-render-model",
"Hdfb/CLIP-Interrogator",
"awacke1/3D.Live.Image.To.Model.Generator",
"CrucibleAI/ControlNetMediaPipeFaceSD21",
"nvishurl/nvishessa-AI",
"VideoCrafter/VideoCrafter",
"neriiacopo/T2I-Adapter",
"RamAnanth1/videocrafter",
"VincentZB/Stable-Diffusion-ControlNet-WebUI",
"microsoft/HuggingGPT",
"keaneu/HuggingGPT",
"viscosity/HuggingGPT",
"Mcdof/HuggingGPT",
"BMukhtar/BMA",
"chrisW6825/HuggingGPT",
"Shenziqian/HuggingGPT",
"lokutus/HuggingGPT",
"ccarr0807/HuggingGPT",
"mimiqiao/HuggingGPT",
"tsgbalakarthik/HuggingGPT",
"wowochkin/HuggingGPT",
"Msp/HuggingGPT",
"domnguyen/openai-clip-vit-large-patch14",
"jnkr36/demo",
"BAAI/vid2vid-zero",
"ryan12439/HuggingGPTpub",
"FANCHIYU/HuggingGPT",
"Betacuckgpt/HuggingGPT",
"cashqin/HuggingGPT",
"felixfriday/MICROSOFTT_JARVIS_HuggingGPT",
"Meffordh/HuggingGPT",
"shaokun/training-playground",
"lzqfree/HuggingGPT",
"bountyfuljr/HuggingGPTplaypublic",
"rzzgate/Stable-Diffusion-ControlNet-WebUI",
"mearjunsha/HuggingGPT",
"next-social/audio_img",
"luckli/openai-clip-vit-large-patch14",
"shgao/EditAnything",
"editoraapp/test-zero-shot",
"turbowed/HuggingGPT",
"Chokyounghoon/HuggingGPT",
"mair-lab/mapl",
"lollo21/Will-GPT",
"Pfs2021Funny/HuggingGPT",
"irritablebro/HuggingGPT",
"MagKoz/HuggingGPT",
"zhangdream/HuggingGPT",
"n0r9st/sa-clip-v0",
"calliber/HuggingGPT",
"theholycityweb/HuggingGPT",
"Pitak/HuggingGPT",
"gaocegege/HuggingGPT",
"apgarmd/jarvis",
"apgarmd/jarvis2",
"mukulnag/HuggingGPT1",
"jgfly/openai-clip-vit-large-patch14",
"jsscclr/CLIP-Interrogator",
"morantis/test",
"lugifudun/HuggingGPT",
"leadmaister/HuggingGPT",
"pors/HuggingGPT",
"vs4vijay/HuggingGPT",
"aggaranu/clip-image",
"mckeeboards/HuggingGPT",
"albertsoma/vicuna",
"superspark/openai-clip-vit-large-patch14",
"mastere00/JarvisMeetsProfessor",
"Hoodady/3DFuse",
"passthebutter/HuggingGPT",
"AndyMage/kwg",
"manu1435/HuggingGPT",
"trhacknon/HuggingGPT",
"taesiri/HuggingGPT-Lite",
"JEANAPR/openai-clip-vit-large-patch14",
"NaamanSaif/HuggingGPT",
"declare-lab/tango2",
"wssb/EDICT",
"CollaalloC/HuggingGPT",
"stanno/capstone",
"silentfox/openai-clip-vit-large-patch14",
"cc46808/CLIP-Interrogator",
"dwolfe66/HuggingGPT",
"dorkai/textgen",
"xian-sheng/HuggingGPT",
"Aygtljl518866/HuggingGPT",
"haokey/Demo-KhoaLuanTotNghiep",
"eugenevinitsky/openai-clip-vit-large-patch14",
"hirol/controlnetOverMask",
"PlanetHades361/Change-Your-Style",
"Hemi1403/HuggingGPT",
"Vito99/HuggingGPT-Lite",
"Kurosaadsa/CLIP-Interrogatoras",
"rickbhardwaj/openai-clip-vit-large-patch14",
"EinfachOlder/HuggingGPT-Lite",
"yrjjun/cs1",
"Alfasign/HuggingGPT-Lite",
"kalyas/openai-clip-vit-large-patch14",
"innovativeillusions/HuggingGPT",
"Jaumaklix/openai-clip-vit-large-patch14",
"Jerryxs/CLIP-Interrogator",
"LinHanjiang/lama",
"the6star/ElderFussion",
"dorkai/text-generation-webui-main",
"hanaum/clip-test",
"hanaum/clip-test-csv",
"amber3/openai-clip-vit-large-patch14",
"davidmunechika/latentblending",
"Make-A-Protagonist/Make-A-Protagonist-inference",
"editing-images/ledits",
"AIGText/GlyphControl",
"shi-labs/Prompt-Free-Diffusion",
"hahahafofo/controlnetOverMask",
"Amram/CLIP-Interrogator",
"hinatahyuga/openai-clip-vit-large-patch14",
"saurshaz/HuggingGPT",
"altndrr/vic",
"kbora/minerva-generate-docker",
"noamelata/Nested-Diffusion",
"JingyeChen22/TextDiffuser",
"attention-refocusing/Attention-refocusing",
"maihua-cf/sd-cpu-101",
"Jackflack09/diffuse-custom",
"fffiloni/ControlVideo",
"aieye/emotion_classifier_tutorial",
"darrenbritton/CLIP-Interrogator",
"ml-energy/leaderboard",
"ylavie/HuggingGPT3",
"ylavie/HuggingGPT-Lite",
"Charming13/openai-clip-vit-large-patch14",
"charlestonX/openai-clip-vit-large-patch14",
"Vijish/test",
"benissen/latentblending",
"atatakun/ControlNet-v1-1-Annotators-cpu",
"baotrinh/text-generation-webui-main",
"jykoh/gill",
"imjunaidafzal/VideoCrafter",
"imjunaidafzal/TextDiffuser",
"hcc13714155878/openai-clip-vit-large-patch14",
"PSLD/PSLD",
"CCYAO/HuggingGPT",
"amarsaikhan/document-classifier",
"Alesx/document",
"coreml-community/ControlNet-v1-1-Annotators-cpu",
"yaoshining/text-generation-webui",
"37am/demo-sd",
"yuaiyu/Versatile-Diffusion",
"pppppppppp2/instruct-pix2pix",
"zideliu/styledrop",
"brianlorenzo/ledits",
"sub314xxl/CLIP-Interrogator",
"dcams/HuggingGPT",
"BarkAi/openai-clip-vit-large-patch14",
"itexpert2210/stable-diffusion-stream",
"ZackBradshaw/Isaac-Text-Gen",
"Udjxjz/Ai1",
"Ruby-ml/openai-clip-vit-large-patch14",
"YousufRasheed/ledits",
"Arkan0ID/dreambooth-dmitry-thumbs-up",
"JijoJohn/webui",
"Bluishoul/openai-clip-vit-large-patch14",
"renan3989/maagledits",
"sahilverma0696/Nika",
"Yabo/ControlVideo",
"rshrott/openai-clip-vit-large-patch142",
"rshrott/openai-clip-vit-large-patch1423",
"arunmurali/openai-clip-vit-large-patch14",
"Charris71/text-generation-webui",
"guoyww/AnimateDiff",
"xswu/HPSv2",
"vrothenbergUCSD/openai-clip-vit-large-patch14",
"heyitskim/stable_defusion",
"faisalhr1997/Koboldcpp",
"wrdias/Video-Diffusion-WebUI",
"algovenus/text-generation-webui",
"fffiloni/AnimateDiff-Image-Init",
"TRaw/text-gen-webui-clone",
"TRaw/text-generation-webui-space-clone",
"ashercn97/AsherTesting",
"imjunaidafzal/AnimateDiff",
"memef4rmer/edit_anything",
"vittorio-paolella/openai-clip-vit-large-patch14",
"pikto/Elite-text-gen-web",
"jke94/demo-openai-clip-vit",
"jdonovan/text-generation-webui",
"juanma1907/la-llama-que-llama",
"Joeythemonster/AnimateDiff",
"Joeythemonster/Animatejoeythemonste",
"Gayngel/oogaboogatest",
"aehwanc/whiskey_chatbot",
"Joeythemonster/Video-Diffusion-WebUI",
"Baso84/CLIP-Interrogator",
"rahultah/osaigpt",
"TNR-5/Image-Semantic-Search",
"TNR-5/Image-Semantic-Searchj",
"allen1994/text-generation-webui",
"minister79/CLIP-Interrogator",
"Androidonnxfork/CivitAi-to-Diffusers",
"do-dong-park/vicuna-v1.5-demo",
"Kikastrophe/CLIP-Interrogator1",
"cndavy/HuggingGPT",
"bczhou/clip-gpt2",
"danishshaik/openai-clip-vit-large-patch14",
"Ateras/kohya_ss",
"AnirudhDaya/Daya_HR_v2",
"Seyedehsara/text-generation-webui",
"gotgitgood/rich-text-to-image-With-my-rich-RICH.AF.ASS",
"raoulduke420/SD_webui",
"Sambhavnoobcoder/final_IIITA",
"Sambhavnoobcoder/StyleForge",
"anubhav100rao/flipkart-grid-team-asi",
"ArishOp/FashionGenie",
"LongGGGGGG/openai-clip-vit-large-patch14",
"slmnpl/yeahdude",
"gjohnsdss/llm",
"fangjiajia/AAAADjj_3",
"laceymac/rich-text-to-image",
"wchai/StableVideo",
"IvanAbramov/Fooocus-image",
"slmnpl/webui333",
"anhduy412/inno",
"Ywung/llm-webui",
"asgeorges/ll-create",
"zipingl/synthethics",
"wxige/test-docker",
"egub/text-generation-webui",
"jashing/Josh_RIC_GenA_Demo",
"PPLSWG/AnimateDiff",
"dev9669/text-generation-webui",
"jashing/JoshGenA",
"AlexchIA/text-generation-webui",
"khussairiee/H2O",
"Omnibus/Video-Diffusion-WebUI",
"liuyuan-pal/SyncDreamer",
"fox2048/smc",
"nupurkmr9/concept-ablation",
"NSect/Animagine-XL",
"Thunderhell/CLIP-Interrogator3",
"Anonym0usDev/openai-clip-vit-large-patch14",
"XCLiu/InstaFlow",
"zhangcheng666/openai-clip-vit-large-patch14",
"iccv23-diffusers-demo/rich-text-to-image",
"adr2432/lets_try",
"3vanse/CLIP-Interrogator",
"Kayson/InstructDiffusion",
"colornative/AnimateDiff",
"enochianborg/stable-diffusion-webui",
"ML-INTA/ML-Image",
"AP123/dreamgaussian",
"absinc/diffuse-custom",
"pablodawson/ldm3d-inpainting",
"anon4757/BiasTestVQA",
"editing-images/ai-halloween-photobooth",
"sainteye/openai-clip-vit-large-patch14",
"LanguageBind/LanguageBind",
"Iceridge/capstone-sd",
"editing-images/leditsplusplus",
"mikonvergence/theaTRON",
"jiawei011/dreamgaussian",
"mittalneha/SD_Styles_Assignment",
"jingwora/CLIP-Interrogator",
"ZackBradshaw/omni_bot",
"Aadi1149/openai-clip-vit-large-patch14",
"jvaddi/stablediffusion",
"GunaKoppula/Session20",
"wgetdd/Stable_Diffusion",
"adil22jaleel/StableDiffusion_Space",
"Omnibus/AnimateDiff",
"mkthoma/StableDiffusion_with_VibranceLoss",
"RashiAgarwal/GenerativeArt_StableDiffusion",
"MadhurGarg/GenerativeArt_StableDiffusion",
"VarunSivamani/Stable_Diffusion",
"TharunSivamani/Stable-Diffusion",
"shashnk/dreamstream",
"crystalai/openai-clip-vit-large-patch14",
"Navyabhat/Session20",
"mpratiek93/ERA_V1_Assignment",
"Kud0/Gen_Art",
"ankoder/Generative_Art_and_Stable_Diffusion",
"DmitrMakeev/Animagine-XL",
"srikanthp07/s20stabledif",
"tulsi0897/ERA20_stable_diffusion",
"LN1996/S20-ERA-Phase-I-Stable-Diffusion",
"ennov8ion/Animagine-XL",
"Frantz103/CaptionQuest",
"PShankar/ERA_v1_Session_stablediff_art",
"elanoqi/AnimateDiff",
"Doa-doa/grad",
"gupta1912/StableDiffusion",
"AnishKumbhar/ChatBot",
"navpreetnp/ERA-S20",
"shaoyuc3/stableVideo",
"RaviNaik/ERA-SESSION20",
"piyushgrover/Stable-Diffusion-Image-Generation",
"Sparkles-AI/sd-automatic111",
"padmanabhbosamia/Stable_Diffusion",
"PrarthanaTS/stable_diffusion",
"ToletiSri/TSAI_S20",
"Navya/SESSION20",
"nkanungo/stable_diffusion_experiment",
"raghunc0/textual-inversion-sd",
"venkat-natchi/Generative-art",
"rohithb/stable_diffuion_styles",
"svaddi/StableDiffusion",
"gdeotale/StableDiffusion",
"moltenglass/Animagine-XL",
"divya-22/Image_to_ThreeDimension-Model",
"kitrinx/CLIP-Interrogator",
"Gosula/Stable_diffusion_model",
"flamehaze1115/Wonder3D-demo",
"Ahalya002/openai-clip-vit-large-patch14",
"DmitrMakeev/AnimateDiff",
"radames/Real-Time-Latent-Consistency-Model",
"Yatendra3192/openai-clip-vit-large-patch14",
"Fernandezola/Animagine-XL",
"neggles/clip-tokenizer-util",
"luis112/text-generation-webui",
"raaraya/AnimateDiff",
"chriscec/AnimateDiff",
"MoonQiu/FreeNoise",
"0xSparked/yungpunks",
"ydlmzsound/CLIP-Interrogator",
"s-potato/CLIP-Interrogator",
"W404NET/My-Chat",
"StanislavMichalov/ControlNet-v1-1-Annotators-cpu",
"DiscloseAI/ChatAnything",
"Persovt/openai-clip-vit-large-patch14",
"declare-lab/mustango",
"azdyqwoovo/Wonder3D-demo",
"Brijendra09/stable-diffusion-webui",
"Maikou/Michelangelo",
"DonCC/Fooocus",
"TheVilfer/stable-video-diffusion",
"Taf2023/stable-video-diffusion",
"yangzzay/HydroxApp_t2p",
"zparadox/stable-video-diffusion",
"piralocoplasticone/Fooocus",
"Zhouyan248/lavie_gradio",
"brunvelop/ComfyUI",
"Nymbo/stable-video-diffusion",
"piaoyu2011/stable-video-diffusion",
"quantumcontrol/stable-video-diffusion",
"haodongli/LucidDreamer",
"raisahil/stable-difusion-scunge-v1",
"Imran1/dog_classifiers",
"miron258/Elite-text-gen-web-duplicate",
"aswanthachooz/LucidDreamer",
"Vchitect/LaVie",
"amcr14714/openai-clip-vit-large-patch14",
"rngd/text-generation-webui",
"cocktailpeanut/leditsplusplus",
"awqwqwq/Fooocus",
"tsi-org/LaVie",
"Doubiiu/DynamiCrafter",
"jbilcke-hf/ai-tube-model-lavie",
"ZYMPKU/UDiffText",
"Tanaymishra/foocus",
"Arifzyn/CLIP-Interrogator",
"rohitg00/Fooocus",
"Hulapunk/dreamgaussian",
"darshanjani/EE267_Stable_Diffusion",
"markqiu/text-generation-webui",
"Simaregele/rich-text-to-image",
"radames/Enhance-This-DemoFusion-SDXL",
"LRhinehart/text-generation-webui",
"liuhuohuo/StyleCrafter",
"cocktailpeanut/Enhance-This-DemoFusion-SDXL",
"nova-sqoin/Fooocus",
"Datasculptor/Enhance-This-DemoFusion-SDXL",
"monkey9000/text-generation",
"Apier/Enhance-This-DemoFusion-SDXL",
"akatukime/ChatLei",
"supernlp/Enhance-This-DemoFusion-SDXL",
"Wolodimirec/sdxl_tonio",
"wangyanghan/Enhance-This-DemoFusion-SDXL",
"AlexSlim666/Enhance-This-DemoFusion-SDXL",
"Mysterious-Alien/Enhance-This-DemoFusion-SDXL-dupl",
"vtv1corporation/Enhance-This-DemoFusion-SDXL",
"JVice/try-before-you-bias",
"navervision/LinCIR",
"interactdiffusion/interactdiffusion",
"fataler/Enhance-This-DemoFusion-SDXL",
"burhaant/Fooocus",
"AIADC/Enhance-This-DemoFusion-SDXL",
"cool299/Wonder3D-demo",
"osmunphotography/Enhance-This-DemoFusion-SDXL",
"xsigus24/text-generation-webui",
"mrsaloma/CLIP-Interrogator",
"Amesssjiao/Enhance-This-DemoFusion-SDXL",
"ozgurkara/RAVE",
"igotech/rich-text-to-image",
"MykolaL/evp",
"TianxingWu/FreeInit",
"Cometo/Enhance-This-DemoFusion-SDXL",
"SashaDes94/Enhance-This-DemoFusion-SDXL",
"byeongjun-park/HarmonyView",
"jadechip/anydoor",
"shatrunjai/EDIT_IMAGE",
"AeroXi/mist-v2",
"blaketm/text-generation-webui",
"xichenhku/AnyDoor-online",
"awqwqwq/foooocus4",
"sahirp/AnyDoor-online",
"TencentARC/MotionCtrl",
"Leoxing/PIA",
"Akhwat/CLIP-Interrogator",
"Nightwing25/Enhance-This-DemoFusion-SDXL",
"awacke1/ControlNet-v1-1-Annotators-cpu",
"AbdulQadoos/Image_Classification",
"AsadullaH777/HuggingGPT",
"modelscope/AnyText",
"jasonddd123/Wonder3D",
"Wakarimashita01/HD-Painter",
"rayochoajr/dreamgaussian",
"rayochoajr/dreamgaussian-1",
"rayochoajr/dreamgaussian3",
"craigwu/vstar",
"SergioSCA/openai-clip-vit-large-patch14",
"HarborYuan/ovsam",
"cocktailpeanut/DragNUWA",
"terrapretapermaculture/HD-Painter",
"devesg/LongAnimateDiff",
"onlineformapro/anydoor",
"Snyr0/Image_Prompt",
"tytyoi/dreamgaussian",
"SSI/openai-clip-vit-large-patch14",
"TencentARC/MotionCtrl_SVD",
"smrgrghf/img-gen-with-fooocus-space",
"dharmendraGupta/VideoCrafter",
"Neu256/text-generation-webui",
"LXT/OMG_Seg",
"Pusheen/LoCo",
"Francel/CLIP-Interrogator",
"xzxzxiaoo/Wonder3D",
"jpenyil65/dreamgaussian",
"mattb512/fastai-lesson-10-diffusers",
"jianfuzhang233/controlnet",
"3DTopia/3DTopia",
"wezyai/naked",
"Adamir/3d",
"Stevada24/ELITE-IpAdapter",
"tikcrimhg/testai",
"basit123796/apnadalle3",
"johnygoddard/Enhance-This-DemoFusion-SDXL-Duplicated",
"shapermindai/SinGPTUltimate",
"biaggi/CLIP-Interrogator",
"Yiyuan/InteractiveVideo",
"HumbleWolf/DockerFooocus",
"anshuln/peekaboo-demo",
"johnygoddard/Enhance-This-DemoFusion-SDXL",
"darkknightxi/grand-theft-photo",
"Tzuyuan/openai-clip-vit-large-patch14",
"JOHANhuynhhhhh/Test1",
"wangfuyun/AnimateLCM",
"taoki/tiny-ja-trans-sd",
"cocktailpeanut/AnimateLCM",
"fazzebo/fooocus",
"Naarsil/openai-clip-vit-large-patch",
"TroubleDz/dzai",
"soonyau/visconet",
"killah-t-cell/EditAnything",
"Jemand/openai-clip-vit-large-patch14",
"cocktailpeanut/DynamiCrafter",
"NahFam13/webbyuu",
"jbilcke-hf/ai-tube-model-animatelcm",
"jbilcke-hf/ai-tube-model-dynamicrafter",
"Moldwebs/stable-video-diffusion",
"nwmjncs/DynamiCrafter",
"SensoredRooster/openai-clip-vit-large-patch14",
"Verias/testing_space",
"treylonwofford/openai-clip-vit-large-patch14",
"merve/EVACLIP",
"maksymalist/openai-clip-vit-large-patch14",
"ysharma/3DTopia",
"Taper5749/Music_Generator",
"youngwoo-dev/test1",
"Drewart/dreamgaussian",
"VictorFS82/TestCHIn",
"firzaelbuho/elbuhoui",
"yoloy/openai-clip-vit-large-patch14",
"Prgckwb/tokenvisor",
"exx8/differential-diffusion",
"Moustached/Risovallllka",
"Moustached/Vengery",
"ameerazam08/Stable-Cascade-Super-Resolution",
"MKFMIKU/CoDi",
"visionMaze/Magic-Me",
"anasazasaa/openai-clip-vit-large-patch14",
"aletrn/lisa-on-cuda",
"OmarhAhmed/leditsplusplus",
"deadcrowd/fooocusspace",
"cocktailpeanut/differential-diffusion",
"ahadi/ledits",
"ahadi/3DFuse",
"Nymbo/MagicMix",
"mrfakename/TTTS",
"Xuweiyi/UniCtrl",
"tristan-aeschbach/Test",
"dreamer-technoland/object-to-object-replace",
"SerenaTOUM/Zero-shot-image-classification",
"dan237/zero_classification_image",
"elontusk404/HD-Painter-6",
"visconet/visconet",
"mkaszkowiak/agrofag-classifier",
"vansonhk/CLIP-Interrogator",
"SRDdev/CLIP-Search",
"markhristov/diffusion_model_from_scratch",
"Zhengyi/CRM",
"tsi-org/tango",
"Nymbo/OOTDiffusion",
"AI4future/CLIP-Interrogator",
"DJONG-WANG/application-intelligent",
"cocktailpeanut/OOTDiffusion",
"Adityadn/KB",
"SD-online/Fooocus-Docker",
"naver-ai/VisualStylePrompting",
"naver-ai/VisualStylePrompting_Controlnet",
"seawolf2357/aifah",
"Adityadn/AI-Describe-Image",
"ABANDA-OMGBA-Ulrich-Michel/TechVerse",
"dan237/multiapp",
"SerenaTOUM/SM_Multifional_APP_Streamlit",
"radames/LayerDiffuse-gradio-unofficial",
"Adityadn/AIImages",
"Doubiiu/DynamiCrafter_interp_loop",
"rayli/DragAPart",
"zhenghong/OOTDiffusion",
"anasazasaa/openai-clip-vit-large-patch14321",
"kobotawind/pruebavisionfinal",
"parsee-mizuhashi/mangaka",
"tsi-org/OOTDiffusion",
"TechManiac/openai-clip-vit-large-patch14",
"hk12345/Wonder3D-demo",
"Taf2023/AnimateLCM",
"skdanisht/AUTOMATIC1111",
"dreamer-technoland/object-to-object-replace-1",
"nat997/fashion-diffusion",
"nat997/fashion-diff",
"nat997/OOTDiffusion",
"Ravi21/Revo-Diffusion",
"omer11a/bounded-attention",
"Applesam4/NETO-AI",
"Applesam4/NETO_AI",
"tsi-org/LayerDiffuse-gradio-unofficial",
"Shashank777/openai-clip-vit-large-patch14",
"S-Del/TokenCounter",
"hikerxu/OOTDiffusion",
"rlawjdghek/StableVITON",
"BasicNp/Dragreal",
"Shuaizhang7/Surveillance_scene_recognition",
"Mayureshd/dreamgaussian2",
"Katiyar48/OOTDiffusion-VirtualTryOnClothing",
"Clifx/PS2.ai",
"bhohbaum/text-generation-webui",
"TIGER-Lab/AnyV2V",
"syntizo/CLIP-Interrogator",
"mukeshpandey2628/GT_VTR3_1",
"Abdullah-Habib/SDXL-NSFW",
"TencentARC/CustomNet",
"LanguageBind/Open-Sora-Plan-v1.0.0",
"fffiloni/Open-Sora-Plan-v1-0-0",
"adityavipradas/stable_diffusion_gradio",
"cocktailpeanut/Open-Sora-Plan-v1-0-0",
"cocktailpeanut/CustomNet",
"BestWishYsh/MagicTime",
"lbjocson/OOTDiffusion-Test",
"Taf2023/Open-Sora-Plan-v1.0.0",
"cocktailpeanut/MagicTime",
"lylosn/Open-Sora-Plan-v1.0.0",
"Nymbo/MagicTime",
"mridulk/phylo-diffusion",
"cocktailpeanut/cosxl",
"timmyd69buck2/openai-clip-vit-large-patch14",
"tsi-org/cosxl",
"egg22314/object-to-object-replace",
"declare-lab/tango2-full",
"chiru-maddala/cosxl",
"jigme02210199/cosxl",
"abkhallat/openai-clip-vit-large-patch14",
"briaai/BRIA-Background-Generation",
"mkaszkowiak/agrofag-classifier-v2",
"karthik45456e/phi2",
"bjx1/INT2094",
"Mathdesenvnonimate/dreamgaussian",
"fffiloni/miniGPT4-Video-Zero",
"Saad0KH/OOTDiffusion",
"raznal/OOTDiffusion",
"ID-Animator/ID-Animator",
"Vision-CAIR/MiniGPT4-video",
"wfdwed/ClipIMPL",
"wfdwed/openai-clip-vit-large-patch14",
"Baron-GG/LLAUS",
"ChandraP12330/Surveillance-Image-Caption-2024",
"ChandraP12330/image-caption",
"LykCloud/image",
"SahilCarterr/ImageRevamp",
"bala0o8o0/CLIP-Interrogator",
"javakhangnguyen/Llama2",
"tttoaster/SEED-X-17B",
"Thwanx/CLIP-Interrogator1",
"benweissig/webui",
"LittleFrog/IntrinsicAnything",
"NithishRaja/rich-text-driven-image-generation",
"LukeStiN/Zero-Shot-Image",
"hehao13/CameraCtrl-svd",
"sidd-genmo/Open-Sora-Plan-v1.0.0",
"PergaZuZ/openai-clip-vit-large-patch14",
"fantasyfish/dreamgaussian",
"pathikpatel54/VTON",
"Tencent-Hunyuan/HunyuanDiT",
"cocktailpeanut/HunyuanDiT",
"liuq641968816/OOTSD",
"thobuiq/OOTDiffusion",
"vakilrathod67/Kapdechange",
"ChrisJohnson111/test5",
"BrennerFjors/VFX_IZZY_TRAUB",
"oria12/CLIP-Interrogator",
"tharms/Fooocus",
"jchen8000/text-webui-CPUBasic",
"scribbyotx/klkl",
"Mabhish/CLIP-Interrogator",
"wyysf/CraftsMan3D",
"tharms/generative-media-ai",
"LanguageBind/Open-Sora-Plan-v1.1.0",
"Integrated/openai-clip-vit-large-patch14",
"OjciecTadeusz/OOTDiffusion",
"TypeGPT/Image-Gen-Pro",
"sachinbluechip/Zero_shot_image_classification",
"TIGER-Lab/T2V-Turbo",
"Honglee003/BRIA-Background-Generation2",
"tsi-org/pixio-toon",
"Honglee003/BRIA-Background-Generation8",
"TheNetherWatcher/Vid2Vid-using-Text-prompt",
"kxic/EscherNet",
"RO-Rtechs/Rtechs_Open-Sora-Plan-v1.1.0",
"jarnot/EasyAnimate",
"xichenhku/MimicBrush",
"aletrn/samgis-lisa-on-zero",
"sachinkidzure/PowerPaint",
"MasterDee/openai-clip-vit-large-patch14",
"Honglee003/BRIA-Background-Generation4",
"AIMage2024/tooncrafter",
"YUIUUOP/tooncrafter",
"marselgames9/marselgames9-gif135",
"marselgames9/marselgames9-gif135animation",
"marselgames9/marselgames9-1234567gif",
"Bai-YT/ConsistencyTTA",
"Mr-Bhaskar/test3",
"jiawei011/dreamgaussian4d",
"BobLLM/Sora",
"czl/generative-data-augmentation-demo",
"TRaw/tooncrafter",
"rogerxavier/Lama-Cleaner-Locally",
"rerun/Vista",
"aforabbasi/Fooocus",
"emilwojtaszek/OOTDiffusion",
"bewizz/SD3_Batch_Imagine",
"Gaejoon/openai-clip-vit-large-patch14",
"Jaeyo03/FitFit",
"Yiwen-ntu/MeshAnything",
"KleinZxA/IDK2",
"yuhj95/resshift",
"aichampions/omni-zero",
"eclipsepoc/omni-zero",
"Gaejoon/openai-clip-vit-large-patch14-sample",
"atnikos/motionfix-demo",
"HarrysonIA/OOTDDiffusion",
"whiteviperx/dreamgaussian",
"Rebecasarai/instant-virtual-try-on",
"SIGMitch/ModelMan",
"DeletedUser8688/tango2",
"ymzhang319/FoleyCrafter",
"ChristianHappy/tooncrafter",
"OscarRP/GaussianTest",
"not-lain/image-retriever",
"EPFL-VILAB/ViPer",
"ilya94prok/comf2",
"TDN-M/DimCart",
"malvika2003/openvino_notebooks",
"jantriage/omni-zero-public",
"giusebello/garment_designer",
"giusebello/garment_designer_webapp",
"Freak-ppa/obj_rem_inpaint_outpaint",
"jeasinema/UltraEdit-SD3",
"SamuelDelgato/AnimateDiff",
"lgiavedoni/OOTDiffusion",
"declare-lab/Tango-Music-AF",
"3rdaiOhpinFully/AnimateDiff-Image-Init",
"nowsyn/AnyControl",
"Al00f/DynamiCrafter_interp_loop",
"ZennyKenny/NatalieDiffusion",
"gokaygokay/Kolors",
"linkpharm/modules",
"Gyufyjk/FoleyCrafter",
"1ssb/stablediffusion-infinity",
"gokaygokay/KolorsPlusPlus",
"MoonQiu/FreeTraj",
"Gopalagarwal/Deradh",
"gokaygokay/360PanoImage",
"eggacheb/neko-image-gallery",
"UltraMarkoRJ/ImageToPrompt",
"Smiley0707/OOTDiffusion",
"yotty22/dreamgaussian4d",
"vsrinivas/Determine_Best_Label_from_Set_of_Given_Labels",
"dawood/mesh-test",
"sanya-mahajan/dreamgaussian",
"rimjhimittal/final",
"li-qing/PQ3D-Demo",
"ysimjo35/image2image_demos",
"dawood/MeshAnything",
"michaelcostacardozo/OOTDiffusion-cpu",
"zheyangqin/VADER",
"John6666/sdxl-to-diffusers-v2",
"DamarJati/Remove-watermark",
"multimodalart/Kolors-IPAdapter",
"fantaxy/ipkol",
"xinglilu/rekol",
"thorfinn0330/DiffusionModel",
"Raiden223145/Edits",
"ucaslx/Kolors-IP-Adapter-Plus",
"LiruiZhao/Diffree",
"ArtioOfficial/AnimateDiff",
"Kwai-Kolors/Kolors",
"banyapon/Pana360gen",
"fantaxy/AnyV2V",
"jimjonesbabyfreshout/ImageEditor",
"Kwai-Kolors/Kolors-Inpainting",
"pysolver33/ocr_gpt4o",
"NoQuest/QP_AN",
"NoQuest/QP_ANmixtao",
"maxin-cn/Cinemo",
"xinglilu/Vadhwid",
"Mikaelson36/T2V",
"NoQuest/QP_ANpicto",
"JoJoMonroe/openai-clip-vit-large-patch14",
"fffiloni/AccDiffusion",
"SeemG/StableDiffusion",
"AYYasaswini/stable_Diffusion_Assignment",
"zyt334/Adaface",
"yasaswiniay/Stable_Diffusion_Assignment24",
"AYYasaswini/Stable_Diffusion_Assignment24",
"cocktailpeanut/AccDiffusion",
"cocktailpeanut/Diffree",
"strikergtr/pano360",
"HighCWu/control-lora-v3",
"Kwai-Kolors/Kolors-Controlnet",
"Kwai-Kolors/Kolors-FaceID",
"theaiinstitute/theia",
"ChristianHappy/FLUX.1-schnell",
"cocktailpeanut/flux",
"Kwai-Kolors/Kolors-Controlnet_and_IPA",
"ZENLLC/videodiffusion",
"AkashDataScience/SD_Textual_Inversion",
"Chintan-Shah/SD_Style_Exploration",
"alexff91/Virtual-Try-On-Advanced",
"HimankJ/StableDiffusionStyles",
"walnash/S24-SD",
"Shivdutta/S24-StableDiffusion",
"AideepImage/360_Virtual_Image_prediction",
"Freak-ppa/ioatol",
"AYYasaswini/StableDiffusionAssignment24",
"Yiwen-ntu/MeshAnythingV2",
"AiGuaratuba/Cinema-Guaratuba-imagem-para-video",
"RunJJang/image_to_text",
"fantaxy/VADER",
"harshkidzure/PowerPaint",
"Zafaflahfksdf/_",
"Fabrice-TIERCELIN/for-pinokio",
"DamarJati/FLUX.1-DEV-Canny",
"hhhwmws/test_Idiot-Cultivation-System",
"briaai/BRIA-2.3-ControlNet-Inpainting",
"gaur3009/Knight_Engine",
"Freak-ppa/krosp",
"sayanbanerjee32/stable-diffusion-textual-inversion-demo",
"fantaxy/dynamcraf2",
"DhrubaAdhikary1991/S24_StableDiffusion_model",
"seawolf2357/dynamcraf2",
"moyabill/OOTDiffusion",
"seawolf2357/kaimoviestud",
"nyanko7/flux1-dev-nf4",
"sbdie/QP_AN",
"Vaibhav333/Geo_guessr_helper",
"silk-road/Idiot-Cultivation-System",
"Erururi/mist-v2",
"basimbashir/SyncDreamer",
"Eugeoter/ControlNeXt",
"mrbeliever/Schneller",
"yslan/LN3Diff_I23D",
"Nithish310/Image-Gen-Pro",
"rifairlordra/ioatol1",
"rifairlordra/ioatol2",
"Freak-ppa/obj_rem_inpaint_outpaint2",
"Freak-ppa/obj_rem_inpaint_outpaint3",
"nsfwai4me/openai-clip-vit-large-patch14",
"rifairlordra/ioatol3",
"rifairlordra/ioatol4",
"flatcherlee/ioatol1",
"flatcherlee/obj_rem_inpaint_outpaint1",
"Dhdb/test-webui-hd",
"dusaurabh/ERA-V2-Stable-Diffusion",
"Deadmon/FLUX.1-DEV-Canny",
"korp123/HD-Painter",
"Zhatei/Oilkkkkbb",
"flatcherlee/ioatol2",
"seawolf2357/FoleyCrafter",
"Sebastiankay/controlnet-preprocessors-only",
"TFSID/blank-docker",
"ginipick/AccDiffusion",
"MakiAi/Kolors-IPAdapter",
"capagio/garment_designer",
"Deadmon/HD-Painter",
"Vvaann/Assignment_24-StableDiffusion",
"guardiancc/flux-advanced-explorer",
"Xuroo/openai-clip-vit-large-patch14",
"Xuroo/openai-clip-vit-large-patch",
"Xuroo/openai-clip-vit-large-patch1",
"yanranxiaoxi/booxel",
"waloneai/WLMotionCtrl_SVD",
"umerkk164/OOTDiffusion",
"patrickbdevaney/Fonte",
"Resuulsari/Kolors-FaceID",
"anusreepi/StableVITON",
"pundhirdevvrat/KLINGIMG",
"fantos/EveryText",
"rifairlordra/jorag",
"Freak-ppa/jorag",
"K00B404/Versatile-Diffusion-game-assets-gen",
"imados51/TW",
"Rinkal4/SD_Style_Inversion",
"waloneai/Walone-Inpainting",
"Freak-ppa/jorag2",
"rifairlordra/jorag2",
"flatcherlee/jorag",
"rifairlordra/jorag3",
"aiqtech/cinevid",
"gaur3009/FLUX.1-DEV-Canny",
"cybtek/openai-clip-vit-large-patch14",
"Doubiiu/ViewCrafter",
"AmpleBasis/SUPIR",
"rishh76/new-tryon",
"SUHHHH/Kolors",
"aliceblue11/Kolors111",
"Upscaler/SUPIR",
"jsoncm/OOTDiffusion",
"anusreepi/Kolors",
"SunderAli17/SAKFaceTransform",
"venkatesa/First_Project",
"Azreal18/Stable_Diffusion-Textual_Inversion",
"Rebecasarai/try-on",
"flosstradamus/FluxMusicGUI",
"Jason233/Cinemo",
"John6666/Xlabs-Gradio-error",
"netsol/otoz-smart-search",
"Dragunflie-420/LaVie",
"ahmadsuyadi/Virtual-Try-On-Advanced",
"ahmadsuyadi/OOTDiffusion",
"PAIR/StreamingSVD",
"Qdssa/good_upscaler",
"ThomasSimonini/Roblox-test",
"ThomasSimonini/MeshAnythingV2ForRoblox",
"Vchitect/Vchitect-2.0",
"AndreSchu/cosxl",
"Potre1qw/bad_space_test",
"Potre1qw/ioatol",
"Potre1qw/jorag",
"addsw11/klocher",
"addsw11/obj_rem_inpaint_outpaint1",
"addsw11/upapa",
"Etrwy/universal_space_test",
"Etrwy/universal_space_test2",
"addsw11/obj_rem_inpaint_outpaint2",
"Potre1qw/bad_space_test2",
"Etrwy/cucumberUpscaler",
"gusgeneris/3dart",
"ibrim/StableDiffusionBrightnessControl",
"smartfeed/image2image",
"marktow/run",
"Cozzzzy/Prompt_Trainer",
"ginipick/Time-Stream",
"ProgrammerParamesh/VirtualDress",
"FahadAmin/openai-clip-vit-large-patch14",
"SunderAli17/ToonMage",
"moniazamla/PuLID-FLUXw",
"ehenley/ai",
"My-AI-Projects/text2image",
"anvilarth/Garage",
"roubaofeipi/UltraPixel-demo",
"Manikandan97/StickerCreation",
"xogaurav/PuLID-FLUX",
"Deddy/PuLid-FLX-GPU",
"sofianhw/PuLID-FLUX",
"hcl26081999/latentnavigation-flux",
"xogaurav/PuLID-FLUX-New",
"mrvero/UltraPixel-demo",
"Rakoo04/PuLID-FLUX",
"ErnestoST5/PAIR-Diffusion",
"lnyan/flux-dev-flax",
"ethanpwood29/ModelTrainer",
"rupal009/Testdemo",
"lnyan/flax-text-encoder",
"lnyan/flux-text-encoder",
"haodongli/Lotus_Depth",
"MohamedTalaat91/2B-EG-FLUX",
"serhatyalcin/OOTDiffusion",
"Shad0ws/PuLID-FLUX",
"Nov8v/RC_UltraPixelTest",
"THUdyh/Oryx",
"smartfeed/turbo_fm",
"MohamedTalaat91/2B-EG-FLUX-stores",
"okaris/omni-zero-couples",
"cbensimon/omni-zero-couples",
"huanhoang/PuLID-FLUX",
"ShubhankarMUS/OOTDiffusion",
"GrantMeAccess/HunyuanDiT",
"openfree/ultpixgen",
"MohamedTalaat91/2B-EG-FLUX-stores-video",
"briaai/BRIA-Eraser-API",
"mahdimokhtari/stable-diffusion-webui",
"RanAlh443/Landmark_Recognition",
"sky24h/FLATTEN-unofficial",
"ShahadFawaz99/LandmarkRecognition",
"adminx/PuLID-FLUX",
"ameerazam08/FLUX.1-dev-De-Distill",
"WodeDadao/PuLID-FLUX",
"Minecraft3193092/dreamgaussian",
"haodongli/Lotus_Normal",
"aiqcamp/fash-old",
"acaycioglu/DiffEdit",
"acaycioglu/diffedit-v2",
"pixeldustlux/CLIP-Interrogatorq",
"TirthGPT/6tr",
"MiraLiza/HuggingGPT",
"Hondatsubasa1/sdwebui",
"JOY-Huang/InstantIR",
"bghira/FluxBooru-CFG3.5",
"TIGER-Lab/T2V-Turbo-V2",
"Sham786/flux-inpainting-with-lora",
"ameerazam08/FLUX.1-dev-Inpainting-Model-Alpha-GPU",
"Ftml/Wonder3D-demo",
"fffiloni/ReNO",
"NikhilJoson/Add-it",
"kevinppaulo/PuLID",
"John6666/sdxl-to-diffusers-v2-cliptest",
"K00B404/EasyAnimate_custom",
"multimodalart/flux-outpainting",
"DeFactOfficial/T2V-Turbo-V2",
"sidhi251287/FLATTEN-unofficial",
"CyberJerk/FoleyCrafter",
"jon-pascal/Marees-Magical-Photo-Tool-Free",
"John6666/FLUX.1-dev-De-Distill",
"qiuzhi2046/PuLID-FLUX",
"InfomericaInc/tx2videoapi2",
"Omerta420/HD-Painter",
"qyoo/AID-v2",
"Nymbo/flux-outpainting",
"sukalovpro/OOTDiffusion2",
"John6666/webui_test3",
"1124yu/PuLID-FLUX_test",
"BloodyInside/ComicMTL",
"Sergidev/360PanoImage",
"AI-Platform/tooncrafter",
"JohnyLahente/flux-outpainting",
"John6666/safetensors_to_diffusers",
"cycomaniacs/CLIP-Interrogator",
"nroggendorff/latentnavigation-flux-uncensored",
"michellemoorre/tvar-demo-test",
"AI-Platform/Mochi1",
"Junaid423/zero123-face",
"dubiousx/SUPIR",
"mtperna/MotionCtrl_SVD",
"amos1088/test_gradio",
"John6666/test_clip",
"WildanJR/HBS_V2",
"EX4L/T2V-Turbo",
"royalx/VirtualTryClothing",
"royalx/OOTDiffusion-VirtualTryOnClothing",
"cjy666/openai-clip-vit-large-patch14",
"rahulch1502/StableDiffusionStyles",
"wylupek/Test",
"qihoo360/HiCo_T2I",
"Az1zT/StableVITON",
"meepmoo/StreamingSVD",
"fffiloni/X-Portrait",
"KVAkash/project",
"KVAkash/operaex1",
"KVAkash/operaex2",
"Baraaqasem/Imag",
"Sebastiankay/FLUX.1-DEV-NF4",
"thincamel/IOTA_OOTDiffusion",
"cocktailpeanut/InstantIR",
"Sebastiankay/controlnet-and-ip-adapter-plus",
"hehe9801209/UDiffText",
"RobinsAIWorld/Instant-Image-Restoration",
"MNE-Zone/InstantIR",
"blanchon/rgb2x",
"blanchon/x2rgb",
"ArvindJi/openai-clip-vit-large-patch14",
"stazizov/XFluxSpace",
"SunderAli17/Blind_Image_Restoration",
"smartfeed/image_fe",
"Soljawritten/FLUX.1-DEV-Canny",
"Nymbo/X-Portrait",
"RyzenCore/CLIP-Interrogator-3",
"svjack/MotionCtrl_SVD",
"svjack/MotionCtrl",
"huanhoang/flux-outpainting",
"svjack/ToonCrafter-fp16",
"CiaraRowles/stylecodes-sd15-demo",
"mindhugo0810/openai-clip-vit-large-patch14",
"bep40/CONTROL-IPA",
"svjack/ControlNeXt-Genshin-Impact-XL-Demo",
"NJU/RAG-Diffusion",
"iamahmadsaboor/OOTDiffusion",
"InstantX/SD35-IP-Adapter",
"MartsoBodziu1994/PuLID-FLUX",
"zarroug/X-Portrait",
"CYF200127/RxnIM",
"whaohan/bpt",
"bedead/CoAdapter",
"Nymbo/Kolors-IPAdapter",
"John6666/flux-inpainting-with-lora",
"jaimin/UDiffText",
"jarvislk/OOTDiffusion",
"Vaibhavnaik12/conDiffusion",
"arj7192/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"arj7192/inpaint",
"arj7192/NativDemo",
"Nymbo/SD35-IP-Adapter",
"Nymbo/flux-IP-adapter",
"Hello20241119/bpt",
"ginipick/time-machine",
"Djrango/qwen2vl-flux-mini-demo",
"FlowChef/FlowChef-Flux1-dev",
"John6666/qwen2vl-flux-zero",
"takarajordan/DiffusionTokenizer",
"cocktailpeanut/qwen2vl-flux-mini-demo",
"phxdev/dark-pixe",
"yslan/ObjCtrl-2.5D",
"svjack/qwen2vl-flux-mini-demo",
"themanas021/OOTDiffusion",
"aryan2184/MagicQuill",
"K00B404/flux-IP-adapter",
"wjs0725/RF-Solver-Edit",
"duongve/Spatial_Control_for_SD",
"RiponSamadder/OOTD",
"FlowChef/FlowChef-InstaFlow-Edit",
"FlowChef/FlowChef-InstaFlow-InverseProblem-Inpainting",
"kheloo/HD-Painter",
"ginipick/AccuVision-Diffusion",
"prs-eth/rollingdepth",
"maccmaccmaccc/5428-p-llamaindexRAG",
"dbaranchuk/Switti",
"tahu321/saepul-ir",
"Deepak7376/OOTDiffusion",
"Nymbo/flux-fill-outpaint",
"MartsoBodziu1994/qwen2vl-flux-mini-demo",
"l-li/NVComposer",
"qitaoz/SparseAGS",
"dmolino/XGeM",
"jmanhype/musev-demo",
"fantaxy/tango2",
"jmanhype/MuseV",
"TencentARC/NVComposer",
"MartsoBodziu1994/SUPIR",
"rhfeiyang/Art-Free-Diffusion",
"fbnnb/ToonCrafter_Sketch",
"ParimalX/InfinixA",
"adityas2410/Zero-Shot_Classification_App",
"dominojirotka/hw_10_negative_prompt",
"fantaxy/Sound-AI-SFX",
"GHGFDSA/openai-clip-vit-large-patch14",
"Toniska/FLUXllama2",
"abhishek-kumar/flux-inpainting-with-lora",
"gradiopro/flux-fill-outpaint",
"marlonbarrios/latentnavigation-flux",
"willchain/MimicBrush",
"marlonbarrios/Sound-AI-SFX",
"azhan77168/mq",
"motivas/openai-clip-vit-large-patch14",
"joelshanky/CLIP-Interrogator",
"MagicBag/FireFlow",
"TencentARC/ColorFlow",
"ZetaWolf2003/flux-fill-outpaint",
"ScoutMeteor7408/MagicQuill",
"svjack/FireFlow",
"Chaitanya-02/Synthetic-data-gen",
"hasankara14/FLUXllama",
"LTT/Kiss3DGen",
"michieda725shunsuke/PuLID-FLUX",
"officialkep1er/FLUXllama",
"vjsiddhufp/flux-fill-outpaint",
"diorbeauty/PuLID-FLUX",
"gunvattagurukulqci/flux-fill-outpaint",
"skinnymixes/flux-fill-outpaint",
"xragejp/flux-fill-outpaint",
"MoonQiu/FreeScale",
"ginigen/FLUXllama-Multilingual",
"rphrp1985/PuLID-FLUX",
"Altairdes/Chetak",
"neeraj810/MagicQuill",
"John6666/sdxl-to-diffusers-v3",
"habibio/Flux-new",
"josharo/FoleyCrafter",
"0xCrafter/openai-clip-vit-large-patch14",
"dazzleun-7/Bigdatacapstone_24-2",
"romadanskiy/open-source-models-hg",
"fotobr/MagicQuillla5",
"RED-AIGC/InstantID-XS",
"mancai/InstantIR",
"fbnnb/TC_1024",
"aki-0421/character-360",
"John6666/gradio_uitest1",
"Cmescobar27/minerva-generate-docker",
"wambugu71/FLUXllama",
"NightRaven109/PBRFUSIONTextureUpscale",
"Hayloo9838/uno-recognizer",
"aminss29/flux-outpainting",
"svjack/ColorFlow",
"mstraughan/FLUXllama-Multilingual",
"Runinno/MagicQuill",
"nuwandaa/Kolors-IPAdapter",
"fbnnb/tooncrafter_1024",
"HuiZhang0812/CreatiLayout",
"IVolt/MagicQuill_Plus",
"dbaranchuk/Switti-1024",
"innoai/Switti-ZeroGPU",
"rchved/GainAi",
"user19991/openai-clip-vit-large-patch14",
"AnonTnf/MotionCtrl_SVD",
"JarvisOnSolana/Jarvis",
"maroun97/rich-text-to-image",
"babebrilliant/openai-clip-vit-large-patch14",
"Kahledgad/openai-clip-vit-large-patch14",
"hongliveje/Kolors-FaceID",
"naonauno/groundbi-factory",
"Fotiboa/Music-TTA",
"Fotiboa/music",
"WhiteAiZ/sdxl-to-diffusers-v32",
"boohababa/SyncDreamer",
"Jolly123/ToonCrafter",
"tejastake/cp-ep",
"fffiloni/MangaNinja-demo",
"valegro/sam-mechanical-parts-segmentation",
"raulsenaferreira/OOTDiffusion",
"kitsune1612/openai-clip-vit-large-patch14",
"yotty22/ControlNet-Architecture",
"guardiancc/flux-inpainting-with-lora",
"byliutao/1Prompt1Story",
"svjack/DiffuEraser-demo",
"Neyvan001/FitDiT5",
"MartsoBodziu1994/flx-pulid",
"Aditya21057w/Defooocus",
"AmyTheKamiwazaGirl2001/WEBUI_STABLE_DIFFUSION",
"Himanshu806/fluxInpaint-testing",
"ekimbasoglu/OOTDiffusion-test-again",
"Roshan-Twinn09/tango2",
"batkovdev/i2v-vtk",
"felipevictal/FitDiT007",
"MegaTronX/FLuxGym",
"UPstud/ColorCtrl",
"Nymbo/webui_test",
"fffiloni/auffusion",
"Aatricks/LightDiffusion-Next",
"Oshuboi/OOTDiffusion",
"a7md2del/inpaintingv1",
"waloneai/LaVie",
"waloneai/LaVieVid",
"waloneai/LaVieVidPro",
"Perry1323/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"waloneai/LaVie2",
"haowu11/Kolors-Controlnet-Pose-Tryon",
"donong05/MagicQuill",
"CrisRaz/SUPIR",
"yiren98/MakeAnything",
"rafael424/rostos23",
"elismasilva/mixture-of-diffusers-sdxl-tiling",
"PizzaMonster555/text-generation-webui",
"Indulge-Bai/Weak-to-Strong-Diffusion",
"yiren98/MakeAnything-AsymmertricLoRA",
"ginigen/Flux-LayerDiffuse",
"Perry1323/flux-fill-outpaint",
"snyderline/FoleyCrafter",
"moralec/MagicQuill",
"fantos/Panorama",
"AdiY97/ldm_t2i",
"svjack/MakeAnything",
"iamahmadsaboor/FitDiT",
"Alyaboelnasr/Landmark_Recognition",
"Mariam-Elz/Model-Demo",
"svjack/Hunyuan_Video_Lora_Demo",
"Keshabwi66/SmartLuga",
"YoussefAnso/CRM",
"piton13332/Video-Diffusion-WebUI",
"xsantox/img2dream",
"yeq6x/MakeAnything",
"ginipick/Panorama",
"QHL067/CrossFlow",
"mikusama23/FLUX.1-dev-Inpainting-Model-Beta-GPU",
"svjack/MotionClone-Text-to-Video",
"ValerianFourel/StableFaceEmotion",
"ginigen/panorama-images",
"Lokesh84/OOTDiffusion202",
"svjack/Light-A-Video",
"RP-Azul/IMAGE",
"Wangdangel/openai-clip-vit-large-patch14",
"svjack/MotionClone-Image-to-Video",
"xilluill/KV-Edit",
"ositamiles/Fashion-Pose-Control",
"mashroo/CRM",
"YoBatM/FastStableDifussion",
"naonauno/GroundBi",
"ameerazam08/PhotoDoodle-Image-Edit-GPU",
"SaMeT1693/Deneme16",
"nuwandaa/flux-fill-outpaint",
"swoyam2609/InPaiting_with_mask",
"sariyam/flux-fill-outpaint",
"tight-inversion/tight-inversion",
"Hatman/InstantStyle-FLUX-SDXL",
"aleafy/RelightVid",
"Shilpaj/StableDiffusion",
"elismasilva/mod-control-tile-upscaler-sdxl",
"VelaTest/Look-A-Like_Image-Finder",
"naveen678/Multimodal-GPT",
"breslavsky/PuLID-FLUX",
"piyushgrover/StableDiffusion-S17ERAv3",
"TDN-M/PaintMask",
"Alptekinege/qwen2vl-flux-mini-demo",
"xyxingx/LumiNet",
"ara666/MagicQuill",
"lutfiplay/MagicQuill",
"13ze/PuLID-FLUX",
"PiperMy/PuLID-FLUX",
"primecai/diffusion-self-distillation",
"pandaphd/generative_photography",
"kinsung/imggen",
"tight-inversion/tight-inversion-pulid-demo",
"eBlessings/PuLID-FLUX",
"dbvb2k/artisticstyletransfer",
"kulashekar123/VirtuTry",
"hazael00/mod-control-tile-upscaler-sdxl",
"cocktailpeanut/DiffuEraser-demo",
"Uthar/John6666_sdxl-to-diffusers-v3",
"tennant/old_tok",
"mgbam/NeuroResearch_AI",
"VIDraft/tight-inversion-pulid-demo",
"AkashKumarave/uu",
"PiperMy/tight-inversion-pulid-demo",
"gitesh-grover/stable-diffusion-textual-inversion-image-generator",
"mumtaz535/demo",
"wanesoft/PuLID-FLUX",
"JohnWeck/medsegfactory",
"MartsoBodziu1994/mod-control-tile-upscaler-sdxl",
"Brokie1234comp/FoleyCrafter",
"ashish-001/text-embedding-api",
"jarinschnierl/JS_AI_Appliaction",
"kafef30763/FitDiT007",
"kafef30763/FitDiT007a",
"latterworks/meta",
"Yuanshi/URAE",
"sjtu-deepvision/Dereflection-Any-Image",
"PerceptCLIP/models_demo",
"Yuanshi/URAE_dev",
"PietroC01/ImgEnhance",
"weepiess2383/CFG-Zero-Star",
"mathminakshi/chromatic-diffusion-studio",
"Rakavi12/Stable-Diffusion",
"Westlake-AGI-Lab/Detail-plus-plus",
"vdvdvdubey/OOTDiffusion",
"John6666/OOTDiffusion",
"LPX55/Diptych-FLUX.1-merged_8step",
"woak-oa/DeepDubber-V1",
"ayuszh/MagicQuill",
"nezahatkorkmaz/turkce-llava-med",
"nighan2labs/MagicQuill",
"Vladislavo/MagicQuill",
"diswarin/MagicQuill-EditByDiswarin",
"adaface-neurips/adaface",
"adaface-neurips/adaface-animate",
"saakshigupta/deepfake-explainer-app",
"ahmedahres-nativ/inpaint",
"ysrhameed/Animatethings",
"makululinux/Panorama",
"makululinux/ImageGen-Flux",
"hehe9801209/wenchuang",
"makululinux/Inpainting",
"kuhs/dogofs25",
"tanmayddeshmukh/MagicQuill1",
"falihwish/MagicQuill",
"falihwish/MagicQuil",
"abdullahalioo/MagicQuilll",
"IamCreateAI/LayerAnimate",
"tomidsp/FoleyCrafter",
"skk2/KeshriMagicQuill",
"razzaqx17/MagicQuill",
"huserluk/ComputerVisionExercise",
"kaisest1/ComputerVision",
"wencheng256/DiffusionRAWSpace",
"Jackeylovebot/Wonder3D-demo2",
"pecziflo/aiApplicationsW7",
"n1kooo/gradio-oxford-pet-app",
"thini77/vit-base-oxford-iiit-pets",
"kleemyan/pets",
"theSure/Omnieraser",
"MattiaSavoia/ImgEnhanceProva",
"Manireddy1508/imagetoimage",
"ashish-001/Frame_Finder",
"deepfakedetection/deepfake_uq",
"zekicalb/pets_classifier_zekic",
"affal01/Gradio_Application_SW07",
"wiwiddd/test",
"Monyrak/Block_Computer_Vision",
"amirhosenes2002/Open-Meme-Studio",
"MaxPowerUnlimited/vit-vs-clip-pet-classifier",
"innoai/flux-fill-outpaint",
"Dynamatrix/DiffBIR-OpenXLab",
"weileluc/pet-classifier",
"chrisis2/blockcomputervis",
"cavargas10/TRELLIS-Texto3D",
"LPX55/qwen2vl-flux",
"alpercagann/SonicDiffusionClean",
"balaram17/tooncrafter",
"Balaram27/tooncrafter",
"dewiri/Pet_Classification_Comparison",
"dewiri/pet_classification_comparison_dewiri",
"itsJasminZWIN/gradio-oxford-pet-app",
"kitty365/dawgorcat",
"holendar/aiappweek7",
"pecziflo/aiApplicationsW7SecondTry",
"thamnt/COMFY_WINDOW",
"VisualCloze/VisualCloze",
"nishawarschonvergeben/Woche08AbgabePlease",
"Schram03/ComputerVision",
"007Marlon2000/PetClassifier",
"Weberm/dogsandcat",
"halimalm/oxford-pet-app",
"ninjaonsteroids/Ghibli",
"PUM4CH3N/TRELLIS_TextTo3D",
"ISxOdin/Petidentifier-FS25",
"armikaeili/cora",
"ford442/SD35-IP-Adapter",
"JunhaoZhuang/Cobra",
"steffchi/image_classification_dogs",
"viazzana/week7",
"rolloraq/Week7",
"zuegemi2/week7",
"ismdal/Leistungsnachweis2Model",
"gitnub/image_classification",
"fdrmic/computervision",
"Granitagushi/Image_detector",
"loretyan/detectment",
"maceythm/aisw07_pet_img_classification",
"Marc-Hagenbusch/zhaw-ai-application-week7",
"lautenad/Zhaw-ai-application-week7",
"mikonvergence/MESA",
"LukeXOTWOD/vit-pet-classifier-lukexotwod",
"blaxe191/vit-pet-classifier-blaxe191",
"remonemo/week7petstuff",
"groebmic/AnimalPredict",
"patronmoses/Week7",
"fischm04/BlockComputerVision",
"muellje3/Pets",
"bloecand/week7",
"Fadri/Week07",
"schlenat/Dog",
"hindero1/week07",
"Thivjan11/LN2-oxford-pets-transfer",
"caccaluc/week7",
"jarinschnierl/LN2",
"selintyrs/ai-applications-2",
"Mavangu/Logo",
"Betim24/Transferment",
"mizikfischer/oxford-pet-app",
"marinrad/LN2",
"norburay/exercise7",
"Tharsana/ai-application-week7",
"kornmayer/dogofs25",
"kvlwrn1979/RemoveWMCPUDriven",
"Venojah/Task7",
"222dunja/dogsfs25",
"Straueri/BlockComputerVision",
"bodmedam/ComputerVisionClassification",
"gutkia01/PetPrediction_KILN2",
"kabboabb/gradio-oxford-pet-app",
"toninio19/keysync-demo",
"albertstudy/zero_shot_classification",
"pereilea/gesstheanimal",
"Mavangu/PetPrediction",
"Abeesan/pet-exercise",
"Dalmatiner/Abgabe2",
"babicami/week7",
"BerkeOek/week7petsapp",
"hamid267/MagicQuill",
"ferzanagehringer/ai-applications",
"detorcla/oxford-pet-classifier",
"thoeppner/petmodel",
"ElioBaserga/elioClassify",
"ovogoeky/week7",
"Nikolamitrovic/oxford-pets-comparison-app-nikola",
"alimoh02/ai-applications_exercise2",
"raveendran-shajiran/exercise_2",
"bastiansteingruber/ai-applications-exercise2",
"fffiloni/Cobra",
"walzsil1/dogofs25",
"MichaelMM2000/PetClassification",
"martivic/oxford-pet-comparator",
"Vinci96/KI-Stuff",
"Joveljic/pet-classifier-comparison",
"Flogoro/LN2",
"joyjkl/oxford-pets-gradio",
"schuegia/dogidentificator",
"Mathunan/pet-classifier-comparison",
"Manireddy1508/uno-final",
"ginhang2209/kitchen-style-transform",
"Skorm/LN2_computer_vision",
"macbaileys/oxfordpets",
"gashiari/oxford-pets-comparison",
"BSJ2004/3DTopia2",
"soiz1/dreamgaussian",
"tejani/fastsdcpu",
"tejani/NewApp",
"tejani/Another",
"K00B404/InstantStyle_custom",
"souging/TRELLIS_TextTo3D",
"Sathwik456/latent-diffusion",
"GUOXIZHAO/InstantIR",
"GaborMadarasz/bookcovers",
"nikkoyabut/clip_zero_shot_classifier",
"mkrystal/Real-Time-Latent-Consistency-Model",
"ginigen/VisualCloze",
"Abhi0420/Basic_Diffusion_Model",
"LTT/DiMeR",
"FengHou97/Cross-Domain-Recognition",
"haharta/BRIA-Eraser-API",
"nag225/flux_with_controlnets",
"malizec/RuinedFooocus",
"Granitagushi/AI_Project_fruits",
"mazen2100/imagecaptionerpretrained",
"chrisis2/testest",
"mariz1237654/Remove-watermark",
"uvadavey79/CLIP-Interrogator",
"alimoh02/AI-Applications-Project",
"tungbillee/StableVITON",
"hyz317/PrimitiveAnything",
"rainele/computervision",
"fabfacal/computervision",
"BerkantBaskaya/Visual_Pet2",
"Scaryplasmon96/DoodlePix",
"kabboabb/oxford-pet-app.v2",
"wencheng256/DiffusionRAWSpaceZeroGPU",
"K00B404/VisualCloze",
"Granitagushi/Clothing_Detector",
"Mildclimate/Follow-Your-Emoji",
"ginigen/3D-VIDEO",
"stepfun-ai/Step1X-3D",
"PlagueEvgeny/TextTo3D",
"abidlabs/PrimitiveAnythingCachedExamples",
"LindiSimon/vit-beans-app",
"quantumiracle-git/test",
"Hayyyyyden/AnomalyAnything",
"tejani/OOTDiffusion-VirtualTryOnClothing",
"hehe9801209/wenchuang_new",
"lohith-reddy/CLIP-Interrogator",
"saakshigupta/deepfake_detection_uq",
"Tojichok/diplom",
"ElioBaserga/Fruit_and_Vegetable_Classifier",
"anonymous-upload-neurips-2025/PinPoint",
"VOIDER/Image-Evaluator",
"inoculatemedia/Spatiotemporal-Diffusion-HunyuanVideo",
"chrisis2/ComputerVisionProject",
"maceythm/vit-90-animals",
"DRgaddam/background_remove",
"Tharsana/brain-tumor-classifier",
"BLIP3o/blip-3o",
"Fadri/Computervision",
"tejani/FaceMask",
"SoftServe/open-flux-schnell",
"d-matrix/clip_eval",
"Boese0601/ByteMorph-Demo",
"Examplejohn/Diffree",
"Boese0601/ByteMorpher-Demo",
"gutkia01/fruits-vs-junkfood-computervision-app",
"lautenad/flower-classifier",
"minhtung/Step1X-3D",
"QusaiALBahri/ledits",
"Weberm/Snake_MultiModel",
"yejunliang23/ShapLLM-Omni",
"Skorm/computer-vision-project",
"zaikivla/trashsnap",
"jvachez/Dereflection-Any-Image",
"Rausda6/cucumberUpscaler",
"n1kooo/image_classification",
"thini77/food_classifier",
"kleemyan/sportballs",
"fdrmic/plant-classifier-vit",
"jingyangcarl/matgen",
"ismdal/AI-Application-Exam",
"mlactimel/tr",
"Dalmatiner/cv_animals",
"LukeXOTWOD/gradio-fruits-360-app",
"halimalm/vogue",
"Schram03/Fruit-Classification",
"viazzana/end-of-module-exam-fruits",
"Marc-Hagenbusch/CaltechBirdsZeroShotSchifma1",
"Flogoro/ZeroShotStanfordDogsGoemaflo",
"Williams75/CFG-Zero-Star",
"MaxPowerUnlimited/vit-vs-clip-superhero-villain-classifier",
"ginigen/3D-LLAMA",
"AbstractPhil/shunt-adapter-testing",
"FlowChef/RefEdit-SD3",
"ferzanagehringer/food-classifier",
"BerkantBaskaya/Computer_Vision_Watch",
"ferzanagehringer/ComputervisionLN",
"ferzanagehringer/Computervision",
"Bencraft/clasificador-residuo-api",
"sirikan/gradio",
"nvidia/difix",
"DPM1987/ACT-images",
"Clone04/FitTon",
"MohitG012/Ecomerce_Customer_Support_Chatbot",
"weiyi01191/DeepOperateAI-Video",
"HuBuTabg/Wonder3D-demo",
"tejani/FitTon",
"clone3/FastGUI",
"surokpro2/sae_flux",
"RihemXX/TRELLIS_TextTo3D",
"matibangladeshmym/kolors-kwai-photo-duplicated-space-FLUX",
"cikefallinos/try-api",
"mixtao/text-generation-webui",
"ivangabriele/trl-sandbox",
"rmoxon/strandtest",
"multimodalart/Cosmos-Predict2-2B",
"multimodalart/diptych-zero-shot-subject-driven",
"k-aidios/AI-RAY",
"BREINER12/mejia-t2v-generator",
"yupengtang/flux-poc",
"kythours/app",
"Tranchillo/Latent_Space_Bridging_Illustrious-Flux",
"MagnaSC/ImgSearch",
"MagnaSC/Img_emb_clip",
"0xArctic/emotion_art_bot_v2",
"jujutechnology/wanloratrainer-gui",
"Jadson/beauty-AB-testing",
"yangjoe/ootd",
"kontext-community/FLUX.1-Kontext-portrait",
"l1006986533/Wonder3D-demo",
"cpuai/FLUX.1-Kontext-portrait",
"poptoz/FLUX.1-Kontext-portrait-explorer",
"wangpangintsig/prembed_sd3.5",
"bishtk07/Viroshorts",
"bep40/FLUX.1-Kontext-multi-image",
"HAL1993/MDFploteso67890abcdef1234567890abcdef1234567890abcdef1234567890abcdef1234567",
"rianameensaif/text-to-image-rm",
"ginigen/Flux-Kontext-FaceLORA",
"Speshal89/CLIP-LARGE",
"6Morpheus6/FLUX.1-Kontext-Dev",
"acceptee/DiT4SR",
"Hamnivore/IntrinsicAnything",
"whoiamAayush/my-stylemirror-engine",
"bep40/FLUX.1-Kontext-Dev-relight",
"tia0016/tia-vibecho-clip",
"Meismaxandmaxisme/Testing",
"seawolf2357/eawolf2357-git",
"tortinaa2002/MagicQuill",
"goryhon/DiffuEraser-demo",
"LPX55/Kontext-Multi_Lightning_4bit-nf4",
"eftal/Cosmos-Predict2-2BASD",
"soiz1/gligen",
"Meismaxandmaxisme/Jurgiok",
"SahilCarterr/Calligrapher",
"Przemyslaw2115/MagicQuills",
"wadmjada/kao-to-bunsho-ai",
"wwg1wga/Flux-Kontext-FaceLORA",
"memeformer/Flux-Kontext-FaceLORA",
"wistlercopy/SUPIR",
"JasonSmithSO/FooocusEnhanced",
"Calligrapher2025/Calligrapher",
"rahul7star/PusaV1",
"Nomad2082/Magic-plus-1",
"jbilcke-hf/ReCamMaster",
"kymamediagroup/IDLSmileGenerator",
"Maya0808/UserStudy1",
"Mjafari80/BRIA-Background-Generation",
"NTUST-DDRC/VTON360",
"smzerbe/stable-diffusion-webui",
"Palaiotatos/palamia",
"imperiusrex/PrintedTextOCR",
"imperiusrex/PrintedOCR",
"huashenhuajia/FLUX.1-Kontext-multi-image",
"wooyakim0725/AIDY",
"lquraish33/CLIP-Interrogator",
"vishaljoshi24/trl-4-dnd",
"sanjayravichander/Meme_Classification",
"cavargas10/Step1X-Boceto3D",
"bhomik7/Video-NSFW_content_moderation",
"MMD-Coder/MagicQuill",
"Fifafan1/CalorieCalculatorGradio",
"Alen432/SD_Imagic",
"tuan2308/FLUX.1-Kontext-Dev-relight",
"r3gm/stablediffusion-infinity",
"jingyangcarl/docker_test20",
"jingyangcarl/docker_test21",
"anushbadii/FLUX.1-Kontext-multi-image",
"lukmanabdh21/Image-Embed",
"Humphreykowl/newGPU",
"cavargas10/Step1X-TextureGeneration",
"jingyangcarl/docker_test27",
"jingyangcarl/docker_test28",
"jingyangcarl/docker_test29",
"jingyangcarl/docker_test30",
"jingyangcarl/docker_test31",
"jingyangcarl/docker_test32",
"jingyangcarl/docker_test33",
"jingyangcarl/docker_test34",
"jingyangcarl/docker_test35",
"jingyangcarl/docker_test36",
"jingyangcarl/docker_test37",
"reagvis/clip-deepfakedetector",
"Weswey/mq",
"CarlosGRoman/The-Imitation-Game",
"diocal/FLUX.1-Kontext-multi-image",
"diocal/FLUX.1-Kontext-multi-image2",
"bao19/AI-API",
"bep40/OmniTry",
"diocal/FLUX.1-Kontext-multi-image3",
"adminuser742150/Animate",
"zoro008/flux-fill-outpaint",
"MURATBAGLAN/OOTDiffusion",
"svjack/USO"
] | null | null | null | 427,616,846
| null |
[
"zero-shot-image-classification"
] | null |
[
"AutoModelForZeroShotImageClassification",
"clip",
"CLIPModel"
] |
[
"multimodal"
] |
[
"text",
"image"
] |
[
"logits"
] |
enterprise
|
company
|
[
"United States of America"
] | null | null |
[
"Image",
" Text"
] |
[
"Image Classification"
] |
[
"Transformer: Image Encoder-only",
" Transformer: Text Encoder-only"
] |
[
"en"
] | null |
Partially disclosed: unavailable
| 6
|
6447e75e3e498d669191db01
|
suno/bark
|
suno
| null | 24,497
| 1,789,598
|
False
| 2023-04-25T14:44:46Z
| 2023-10-04T14:17:55Z
|
transformers
| 1,409
| 9
| null |
text-to-speech
| null |
[
".gitattributes",
"README.md",
"coarse.pt",
"coarse_2.pt",
"config.json",
"fine.pt",
"fine_2.pt",
"generation_config.json",
"pytorch_model.bin",
"speaker_embeddings/announcer_coarse_prompt.npy",
"speaker_embeddings/announcer_fine_prompt.npy",
"speaker_embeddings/announcer_semantic_prompt.npy",
"speaker_embeddings/de_speaker_0_coarse_prompt.npy",
"speaker_embeddings/de_speaker_0_fine_prompt.npy",
"speaker_embeddings/de_speaker_0_semantic_prompt.npy",
"speaker_embeddings/de_speaker_1_coarse_prompt.npy",
"speaker_embeddings/de_speaker_1_fine_prompt.npy",
"speaker_embeddings/de_speaker_1_semantic_prompt.npy",
"speaker_embeddings/de_speaker_2_coarse_prompt.npy",
"speaker_embeddings/de_speaker_2_fine_prompt.npy",
"speaker_embeddings/de_speaker_2_semantic_prompt.npy",
"speaker_embeddings/de_speaker_3_coarse_prompt.npy",
"speaker_embeddings/de_speaker_3_fine_prompt.npy",
"speaker_embeddings/de_speaker_3_semantic_prompt.npy",
"speaker_embeddings/de_speaker_4_coarse_prompt.npy",
"speaker_embeddings/de_speaker_4_fine_prompt.npy",
"speaker_embeddings/de_speaker_4_semantic_prompt.npy",
"speaker_embeddings/de_speaker_5_coarse_prompt.npy",
"speaker_embeddings/de_speaker_5_fine_prompt.npy",
"speaker_embeddings/de_speaker_5_semantic_prompt.npy",
"speaker_embeddings/de_speaker_6_coarse_prompt.npy",
"speaker_embeddings/de_speaker_6_fine_prompt.npy",
"speaker_embeddings/de_speaker_6_semantic_prompt.npy",
"speaker_embeddings/de_speaker_7_coarse_prompt.npy",
"speaker_embeddings/de_speaker_7_fine_prompt.npy",
"speaker_embeddings/de_speaker_7_semantic_prompt.npy",
"speaker_embeddings/de_speaker_8_coarse_prompt.npy",
"speaker_embeddings/de_speaker_8_fine_prompt.npy",
"speaker_embeddings/de_speaker_8_semantic_prompt.npy",
"speaker_embeddings/de_speaker_9_coarse_prompt.npy",
"speaker_embeddings/de_speaker_9_fine_prompt.npy",
"speaker_embeddings/de_speaker_9_semantic_prompt.npy",
"speaker_embeddings/en_speaker_0_coarse_prompt.npy",
"speaker_embeddings/en_speaker_0_fine_prompt.npy",
"speaker_embeddings/en_speaker_0_semantic_prompt.npy",
"speaker_embeddings/en_speaker_1_coarse_prompt.npy",
"speaker_embeddings/en_speaker_1_fine_prompt.npy",
"speaker_embeddings/en_speaker_1_semantic_prompt.npy",
"speaker_embeddings/en_speaker_2_coarse_prompt.npy",
"speaker_embeddings/en_speaker_2_fine_prompt.npy",
"speaker_embeddings/en_speaker_2_semantic_prompt.npy",
"speaker_embeddings/en_speaker_3_coarse_prompt.npy",
"speaker_embeddings/en_speaker_3_fine_prompt.npy",
"speaker_embeddings/en_speaker_3_semantic_prompt.npy",
"speaker_embeddings/en_speaker_4_coarse_prompt.npy",
"speaker_embeddings/en_speaker_4_fine_prompt.npy",
"speaker_embeddings/en_speaker_4_semantic_prompt.npy",
"speaker_embeddings/en_speaker_5_coarse_prompt.npy",
"speaker_embeddings/en_speaker_5_fine_prompt.npy",
"speaker_embeddings/en_speaker_5_semantic_prompt.npy",
"speaker_embeddings/en_speaker_6_coarse_prompt.npy",
"speaker_embeddings/en_speaker_6_fine_prompt.npy",
"speaker_embeddings/en_speaker_6_semantic_prompt.npy",
"speaker_embeddings/en_speaker_7_coarse_prompt.npy",
"speaker_embeddings/en_speaker_7_fine_prompt.npy",
"speaker_embeddings/en_speaker_7_semantic_prompt.npy",
"speaker_embeddings/en_speaker_8_coarse_prompt.npy",
"speaker_embeddings/en_speaker_8_fine_prompt.npy",
"speaker_embeddings/en_speaker_8_semantic_prompt.npy",
"speaker_embeddings/en_speaker_9_coarse_prompt.npy",
"speaker_embeddings/en_speaker_9_fine_prompt.npy",
"speaker_embeddings/en_speaker_9_semantic_prompt.npy",
"speaker_embeddings/es_speaker_0_coarse_prompt.npy",
"speaker_embeddings/es_speaker_0_fine_prompt.npy",
"speaker_embeddings/es_speaker_0_semantic_prompt.npy",
"speaker_embeddings/es_speaker_1_coarse_prompt.npy",
"speaker_embeddings/es_speaker_1_fine_prompt.npy",
"speaker_embeddings/es_speaker_1_semantic_prompt.npy",
"speaker_embeddings/es_speaker_2_coarse_prompt.npy",
"speaker_embeddings/es_speaker_2_fine_prompt.npy",
"speaker_embeddings/es_speaker_2_semantic_prompt.npy",
"speaker_embeddings/es_speaker_3_coarse_prompt.npy",
"speaker_embeddings/es_speaker_3_fine_prompt.npy",
"speaker_embeddings/es_speaker_3_semantic_prompt.npy",
"speaker_embeddings/es_speaker_4_coarse_prompt.npy",
"speaker_embeddings/es_speaker_4_fine_prompt.npy",
"speaker_embeddings/es_speaker_4_semantic_prompt.npy",
"speaker_embeddings/es_speaker_5_coarse_prompt.npy",
"speaker_embeddings/es_speaker_5_fine_prompt.npy",
"speaker_embeddings/es_speaker_5_semantic_prompt.npy",
"speaker_embeddings/es_speaker_6_coarse_prompt.npy",
"speaker_embeddings/es_speaker_6_fine_prompt.npy",
"speaker_embeddings/es_speaker_6_semantic_prompt.npy",
"speaker_embeddings/es_speaker_7_coarse_prompt.npy",
"speaker_embeddings/es_speaker_7_fine_prompt.npy",
"speaker_embeddings/es_speaker_7_semantic_prompt.npy",
"speaker_embeddings/es_speaker_8_coarse_prompt.npy",
"speaker_embeddings/es_speaker_8_fine_prompt.npy",
"speaker_embeddings/es_speaker_8_semantic_prompt.npy",
"speaker_embeddings/es_speaker_9_coarse_prompt.npy",
"speaker_embeddings/es_speaker_9_fine_prompt.npy",
"speaker_embeddings/es_speaker_9_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_0_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_0_fine_prompt.npy",
"speaker_embeddings/fr_speaker_0_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_1_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_1_fine_prompt.npy",
"speaker_embeddings/fr_speaker_1_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_2_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_2_fine_prompt.npy",
"speaker_embeddings/fr_speaker_2_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_3_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_3_fine_prompt.npy",
"speaker_embeddings/fr_speaker_3_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_4_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_4_fine_prompt.npy",
"speaker_embeddings/fr_speaker_4_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_5_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_5_fine_prompt.npy",
"speaker_embeddings/fr_speaker_5_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_6_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_6_fine_prompt.npy",
"speaker_embeddings/fr_speaker_6_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_7_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_7_fine_prompt.npy",
"speaker_embeddings/fr_speaker_7_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_8_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_8_fine_prompt.npy",
"speaker_embeddings/fr_speaker_8_semantic_prompt.npy",
"speaker_embeddings/fr_speaker_9_coarse_prompt.npy",
"speaker_embeddings/fr_speaker_9_fine_prompt.npy",
"speaker_embeddings/fr_speaker_9_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_0_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_0_fine_prompt.npy",
"speaker_embeddings/hi_speaker_0_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_1_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_1_fine_prompt.npy",
"speaker_embeddings/hi_speaker_1_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_2_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_2_fine_prompt.npy",
"speaker_embeddings/hi_speaker_2_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_3_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_3_fine_prompt.npy",
"speaker_embeddings/hi_speaker_3_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_4_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_4_fine_prompt.npy",
"speaker_embeddings/hi_speaker_4_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_5_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_5_fine_prompt.npy",
"speaker_embeddings/hi_speaker_5_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_6_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_6_fine_prompt.npy",
"speaker_embeddings/hi_speaker_6_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_7_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_7_fine_prompt.npy",
"speaker_embeddings/hi_speaker_7_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_8_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_8_fine_prompt.npy",
"speaker_embeddings/hi_speaker_8_semantic_prompt.npy",
"speaker_embeddings/hi_speaker_9_coarse_prompt.npy",
"speaker_embeddings/hi_speaker_9_fine_prompt.npy",
"speaker_embeddings/hi_speaker_9_semantic_prompt.npy",
"speaker_embeddings/it_speaker_0_coarse_prompt.npy",
"speaker_embeddings/it_speaker_0_fine_prompt.npy",
"speaker_embeddings/it_speaker_0_semantic_prompt.npy",
"speaker_embeddings/it_speaker_1_coarse_prompt.npy",
"speaker_embeddings/it_speaker_1_fine_prompt.npy",
"speaker_embeddings/it_speaker_1_semantic_prompt.npy",
"speaker_embeddings/it_speaker_2_coarse_prompt.npy",
"speaker_embeddings/it_speaker_2_fine_prompt.npy",
"speaker_embeddings/it_speaker_2_semantic_prompt.npy",
"speaker_embeddings/it_speaker_3_coarse_prompt.npy",
"speaker_embeddings/it_speaker_3_fine_prompt.npy",
"speaker_embeddings/it_speaker_3_semantic_prompt.npy",
"speaker_embeddings/it_speaker_4_coarse_prompt.npy",
"speaker_embeddings/it_speaker_4_fine_prompt.npy",
"speaker_embeddings/it_speaker_4_semantic_prompt.npy",
"speaker_embeddings/it_speaker_5_coarse_prompt.npy",
"speaker_embeddings/it_speaker_5_fine_prompt.npy",
"speaker_embeddings/it_speaker_5_semantic_prompt.npy",
"speaker_embeddings/it_speaker_6_coarse_prompt.npy",
"speaker_embeddings/it_speaker_6_fine_prompt.npy",
"speaker_embeddings/it_speaker_6_semantic_prompt.npy",
"speaker_embeddings/it_speaker_7_coarse_prompt.npy",
"speaker_embeddings/it_speaker_7_fine_prompt.npy",
"speaker_embeddings/it_speaker_7_semantic_prompt.npy",
"speaker_embeddings/it_speaker_8_coarse_prompt.npy",
"speaker_embeddings/it_speaker_8_fine_prompt.npy",
"speaker_embeddings/it_speaker_8_semantic_prompt.npy",
"speaker_embeddings/it_speaker_9_coarse_prompt.npy",
"speaker_embeddings/it_speaker_9_fine_prompt.npy",
"speaker_embeddings/it_speaker_9_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_0_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_0_fine_prompt.npy",
"speaker_embeddings/ja_speaker_0_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_1_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_1_fine_prompt.npy",
"speaker_embeddings/ja_speaker_1_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_2_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_2_fine_prompt.npy",
"speaker_embeddings/ja_speaker_2_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_3_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_3_fine_prompt.npy",
"speaker_embeddings/ja_speaker_3_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_4_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_4_fine_prompt.npy",
"speaker_embeddings/ja_speaker_4_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_5_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_5_fine_prompt.npy",
"speaker_embeddings/ja_speaker_5_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_6_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_6_fine_prompt.npy",
"speaker_embeddings/ja_speaker_6_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_7_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_7_fine_prompt.npy",
"speaker_embeddings/ja_speaker_7_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_8_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_8_fine_prompt.npy",
"speaker_embeddings/ja_speaker_8_semantic_prompt.npy",
"speaker_embeddings/ja_speaker_9_coarse_prompt.npy",
"speaker_embeddings/ja_speaker_9_fine_prompt.npy",
"speaker_embeddings/ja_speaker_9_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_0_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_0_fine_prompt.npy",
"speaker_embeddings/ko_speaker_0_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_1_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_1_fine_prompt.npy",
"speaker_embeddings/ko_speaker_1_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_2_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_2_fine_prompt.npy",
"speaker_embeddings/ko_speaker_2_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_3_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_3_fine_prompt.npy",
"speaker_embeddings/ko_speaker_3_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_4_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_4_fine_prompt.npy",
"speaker_embeddings/ko_speaker_4_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_5_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_5_fine_prompt.npy",
"speaker_embeddings/ko_speaker_5_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_6_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_6_fine_prompt.npy",
"speaker_embeddings/ko_speaker_6_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_7_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_7_fine_prompt.npy",
"speaker_embeddings/ko_speaker_7_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_8_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_8_fine_prompt.npy",
"speaker_embeddings/ko_speaker_8_semantic_prompt.npy",
"speaker_embeddings/ko_speaker_9_coarse_prompt.npy",
"speaker_embeddings/ko_speaker_9_fine_prompt.npy",
"speaker_embeddings/ko_speaker_9_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_0_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_0_fine_prompt.npy",
"speaker_embeddings/pl_speaker_0_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_1_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_1_fine_prompt.npy",
"speaker_embeddings/pl_speaker_1_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_2_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_2_fine_prompt.npy",
"speaker_embeddings/pl_speaker_2_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_3_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_3_fine_prompt.npy",
"speaker_embeddings/pl_speaker_3_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_4_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_4_fine_prompt.npy",
"speaker_embeddings/pl_speaker_4_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_5_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_5_fine_prompt.npy",
"speaker_embeddings/pl_speaker_5_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_6_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_6_fine_prompt.npy",
"speaker_embeddings/pl_speaker_6_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_7_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_7_fine_prompt.npy",
"speaker_embeddings/pl_speaker_7_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_8_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_8_fine_prompt.npy",
"speaker_embeddings/pl_speaker_8_semantic_prompt.npy",
"speaker_embeddings/pl_speaker_9_coarse_prompt.npy",
"speaker_embeddings/pl_speaker_9_fine_prompt.npy",
"speaker_embeddings/pl_speaker_9_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_0_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_0_fine_prompt.npy",
"speaker_embeddings/pt_speaker_0_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_1_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_1_fine_prompt.npy",
"speaker_embeddings/pt_speaker_1_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_2_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_2_fine_prompt.npy",
"speaker_embeddings/pt_speaker_2_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_3_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_3_fine_prompt.npy",
"speaker_embeddings/pt_speaker_3_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_4_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_4_fine_prompt.npy",
"speaker_embeddings/pt_speaker_4_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_5_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_5_fine_prompt.npy",
"speaker_embeddings/pt_speaker_5_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_6_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_6_fine_prompt.npy",
"speaker_embeddings/pt_speaker_6_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_7_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_7_fine_prompt.npy",
"speaker_embeddings/pt_speaker_7_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_8_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_8_fine_prompt.npy",
"speaker_embeddings/pt_speaker_8_semantic_prompt.npy",
"speaker_embeddings/pt_speaker_9_coarse_prompt.npy",
"speaker_embeddings/pt_speaker_9_fine_prompt.npy",
"speaker_embeddings/pt_speaker_9_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_0_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_0_fine_prompt.npy",
"speaker_embeddings/ru_speaker_0_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_1_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_1_fine_prompt.npy",
"speaker_embeddings/ru_speaker_1_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_2_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_2_fine_prompt.npy",
"speaker_embeddings/ru_speaker_2_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_3_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_3_fine_prompt.npy",
"speaker_embeddings/ru_speaker_3_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_4_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_4_fine_prompt.npy",
"speaker_embeddings/ru_speaker_4_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_5_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_5_fine_prompt.npy",
"speaker_embeddings/ru_speaker_5_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_6_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_6_fine_prompt.npy",
"speaker_embeddings/ru_speaker_6_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_7_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_7_fine_prompt.npy",
"speaker_embeddings/ru_speaker_7_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_8_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_8_fine_prompt.npy",
"speaker_embeddings/ru_speaker_8_semantic_prompt.npy",
"speaker_embeddings/ru_speaker_9_coarse_prompt.npy",
"speaker_embeddings/ru_speaker_9_fine_prompt.npy",
"speaker_embeddings/ru_speaker_9_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_0_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_0_fine_prompt.npy",
"speaker_embeddings/tr_speaker_0_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_1_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_1_fine_prompt.npy",
"speaker_embeddings/tr_speaker_1_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_2_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_2_fine_prompt.npy",
"speaker_embeddings/tr_speaker_2_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_3_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_3_fine_prompt.npy",
"speaker_embeddings/tr_speaker_3_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_4_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_4_fine_prompt.npy",
"speaker_embeddings/tr_speaker_4_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_5_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_5_fine_prompt.npy",
"speaker_embeddings/tr_speaker_5_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_6_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_6_fine_prompt.npy",
"speaker_embeddings/tr_speaker_6_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_7_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_7_fine_prompt.npy",
"speaker_embeddings/tr_speaker_7_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_8_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_8_fine_prompt.npy",
"speaker_embeddings/tr_speaker_8_semantic_prompt.npy",
"speaker_embeddings/tr_speaker_9_coarse_prompt.npy",
"speaker_embeddings/tr_speaker_9_fine_prompt.npy",
"speaker_embeddings/tr_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/de_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/de_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/de_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/en_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/en_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/en_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/es_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/es_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/es_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/fr_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/fr_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/fr_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/hi_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/hi_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/hi_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/it_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/it_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/it_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/ja_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/ja_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/ja_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/ko_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/ko_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/ko_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/pl_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/pl_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/pl_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/pt_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/pt_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/pt_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/ru_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/ru_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/ru_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/tr_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/tr_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/tr_speaker_9_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_0_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_0_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_0_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_1_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_1_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_1_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_2_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_2_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_2_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_3_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_3_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_3_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_4_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_4_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_4_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_5_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_5_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_5_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_6_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_6_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_6_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_7_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_7_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_7_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_8_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_8_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_8_semantic_prompt.npy",
"speaker_embeddings/v2/zh_speaker_9_coarse_prompt.npy",
"speaker_embeddings/v2/zh_speaker_9_fine_prompt.npy",
"speaker_embeddings/v2/zh_speaker_9_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_0_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_0_fine_prompt.npy",
"speaker_embeddings/zh_speaker_0_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_1_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_1_fine_prompt.npy",
"speaker_embeddings/zh_speaker_1_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_2_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_2_fine_prompt.npy",
"speaker_embeddings/zh_speaker_2_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_3_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_3_fine_prompt.npy",
"speaker_embeddings/zh_speaker_3_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_4_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_4_fine_prompt.npy",
"speaker_embeddings/zh_speaker_4_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_5_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_5_fine_prompt.npy",
"speaker_embeddings/zh_speaker_5_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_6_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_6_fine_prompt.npy",
"speaker_embeddings/zh_speaker_6_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_7_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_7_fine_prompt.npy",
"speaker_embeddings/zh_speaker_7_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_8_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_8_fine_prompt.npy",
"speaker_embeddings/zh_speaker_8_semantic_prompt.npy",
"speaker_embeddings/zh_speaker_9_coarse_prompt.npy",
"speaker_embeddings/zh_speaker_9_fine_prompt.npy",
"speaker_embeddings/zh_speaker_9_semantic_prompt.npy",
"speaker_embeddings_path.json",
"special_tokens_map.json",
"text.pt",
"text_2.pt",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
] |
[
1477,
6642,
1251939909,
3934534533,
8806,
1107111557,
3741740229,
4908,
4486643861,
3128,
12128,
1126,
9472,
18816,
3240,
9472,
18816,
3240,
6944,
13760,
2400,
8608,
17088,
2952,
5984,
11840,
2080,
10416,
20704,
3552,
9408,
18688,
3216,
17696,
35264,
5976,
7424,
14720,
2560,
6544,
12960,
2264,
6608,
13088,
2288,
5408,
10688,
1888,
10048,
19968,
3432,
11328,
22528,
3856,
6256,
12384,
2168,
4544,
8960,
1600,
3920,
7712,
1392,
10416,
20704,
3552,
5584,
11040,
1944,
10672,
21216,
3640,
8176,
16224,
2808,
7520,
14912,
2592,
8176,
16224,
2808,
7840,
15552,
2696,
7216,
14304,
2488,
7360,
14592,
2536,
10336,
20544,
3528,
6368,
12608,
2208,
5488,
10848,
1912,
6688,
13248,
2312,
9072,
18016,
3104,
8688,
17248,
2976,
15216,
30304,
5152,
9328,
18528,
3192,
10800,
21472,
3680,
13104,
26080,
4448,
12960,
25792,
4400,
16064,
32000,
5432,
9808,
19488,
3352,
9264,
18400,
3168,
9664,
19200,
3304,
6800,
13472,
2352,
7936,
15744,
2728,
8496,
16864,
2912,
7232,
14336,
2496,
9792,
19456,
3344,
7360,
14592,
2536,
8896,
17664,
3048,
7376,
14624,
2544,
8944,
17760,
3064,
13872,
27616,
4704,
7360,
14592,
2536,
13472,
26816,
4568,
15696,
31264,
5312,
6608,
13088,
2288,
12720,
25312,
4320,
10144,
20160,
3464,
12272,
24416,
4168,
8880,
17632,
3040,
10672,
21216,
3640,
7360,
14592,
2536,
7456,
14784,
2568,
13136,
26144,
4456,
7328,
14528,
2528,
11280,
22432,
3840,
6704,
13280,
2320,
7264,
14400,
2504,
9904,
19680,
3384,
15056,
29984,
5096,
8752,
17376,
3000,
7136,
14144,
2464,
7808,
15488,
2688,
9472,
18816,
3240,
16880,
33632,
5704,
6896,
13664,
2384,
8592,
17056,
2944,
9040,
17952,
3096,
6544,
12960,
2264,
7232,
14336,
2496,
6464,
12800,
2240,
11824,
23520,
4024,
7840,
15552,
2696,
12816,
25504,
4352,
12576,
25024,
4272,
12656,
25184,
4296,
10096,
20064,
3448,
13488,
26848,
4576,
11104,
22080,
3784,
9904,
19680,
3384,
10800,
21472,
3680,
9616,
19104,
3288,
17440,
34752,
5888,
6368,
12608,
2208,
10480,
20832,
3576,
14592,
29056,
4944,
10224,
20320,
3488,
16880,
33632,
5704,
10096,
20064,
3448,
8976,
17824,
3072,
17488,
34848,
5904,
17248,
34368,
5824,
7168,
14208,
2472,
15392,
30656,
5208,
8640,
17152,
2960,
8272,
16416,
2840,
6896,
13664,
2384,
13616,
27104,
4616,
7504,
14880,
2584,
12768,
25408,
4336,
11440,
22752,
3896,
7696,
15264,
2648,
7136,
14144,
2464,
9712,
19296,
3320,
5920,
11712,
2056,
4720,
9312,
1656,
8656,
17184,
2968,
6368,
12608,
2208,
6272,
12416,
2176,
10608,
21088,
3616,
5728,
11328,
1992,
11776,
23424,
4008,
8128,
16128,
2792,
7312,
14496,
2520,
9280,
18432,
3176,
9088,
18048,
3112,
9280,
18432,
3176,
6848,
13568,
2368,
11920,
23712,
4056,
8448,
16768,
2896,
15216,
30304,
5152,
8320,
16512,
2856,
7456,
14784,
2568,
7760,
15392,
2672,
10384,
20640,
3544,
7024,
13920,
2424,
7312,
14496,
2520,
7552,
14976,
2600,
6704,
13280,
2320,
6880,
13632,
2376,
8944,
17760,
3064,
6496,
12864,
2248,
7424,
14720,
2560,
7760,
15392,
2672,
7024,
13920,
2424,
6896,
13664,
2384,
7600,
15072,
2616,
6064,
12000,
2104,
6496,
12864,
2248,
7520,
14912,
2592,
5872,
11616,
2040,
13632,
27136,
4624,
7600,
15072,
2616,
15552,
30976,
5264,
15120,
30112,
5120,
14864,
29600,
5032,
13424,
26720,
4552,
16672,
33216,
5632,
9648,
19168,
3296,
12864,
25600,
4368,
9520,
18912,
3256,
9664,
19200,
3304,
7648,
15168,
2632,
8224,
16320,
2824,
8832,
17536,
3024,
7504,
14880,
2584,
15312,
30496,
5184,
7808,
15488,
2688,
8704,
17280,
2984,
11712,
23296,
3984,
6944,
13760,
2400,
8512,
16896,
2920,
10032,
19936,
3424,
12128,
24128,
4120,
9120,
18112,
3120,
8512,
16896,
2920,
9024,
17920,
3088,
8784,
17440,
3008,
13008,
25888,
4416,
12704,
25280,
4312,
11184,
22240,
3808,
7216,
14304,
2488,
9264,
18400,
3168,
7120,
14112,
2456,
7232,
14336,
2496,
7904,
15680,
2720,
7376,
14624,
2544,
12128,
24128,
4120,
7408,
14688,
2552,
5968,
11808,
2072,
9232,
18336,
3160,
7856,
15584,
2704,
7792,
15456,
2680,
5648,
11168,
1968,
11760,
23392,
4000,
6832,
13536,
2360,
6848,
13568,
2368,
7808,
15488,
2688,
8256,
16384,
2832,
9232,
18336,
3160,
6992,
13856,
2416,
7360,
14592,
2536,
10288,
20448,
3512,
8464,
16800,
2904,
12320,
24512,
4184,
9120,
18112,
3120,
11344,
22560,
3864,
11536,
22944,
3928,
8608,
17088,
2952,
5728,
11328,
1992,
9184,
18240,
3144,
8208,
16288,
2816,
10240,
20352,
3496,
10944,
21760,
3728,
7984,
15840,
2744,
7808,
15488,
2688,
8368,
16608,
2872,
9120,
18112,
3120,
8320,
16512,
2856,
8448,
16768,
2896,
11824,
23520,
4024,
11856,
23584,
4032,
16880,
33632,
5704,
8656,
17184,
2968,
5872,
11616,
2040,
8352,
16576,
2864,
13280,
26432,
4504,
6032,
11936,
2096,
7696,
15264,
2648,
11616,
23104,
3952,
10288,
20448,
3512,
6512,
12896,
2256,
7232,
14336,
2496,
7376,
14624,
2544,
8496,
16864,
2912,
9840,
19552,
3360,
5056,
9984,
1768,
7472,
14816,
2576,
5968,
11808,
2072,
6064,
12000,
2104,
8352,
16576,
2864,
6080,
12032,
2112,
5840,
11552,
2032,
6208,
12288,
2152,
9280,
18432,
3176,
8880,
17632,
3040,
5120,
10112,
1792,
4960,
9792,
1736,
6208,
12288,
2152,
5680,
11232,
1976,
4736,
9344,
1664,
5776,
11424,
2008,
6304,
12480,
2184,
5728,
11328,
1992,
9712,
19296,
3320,
5792,
11456,
2016,
16256,
32384,
5496,
6944,
13760,
2400,
6656,
13184,
2304,
6064,
12000,
2104,
5408,
10688,
1888,
61095,
125,
2315982725,
5353258741,
2919362,
353,
995526
] | 22,203,122,295
|
70a8a7d34168586dc5d028fa9666aceade177992
|
[
"transformers",
"pytorch",
"bark",
"text-to-audio",
"audio",
"text-to-speech",
"en",
"de",
"es",
"fr",
"hi",
"it",
"ja",
"ko",
"pl",
"pt",
"ru",
"tr",
"zh",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
# Bark
Bark is a transformer-based text-to-audio model created by [Suno](https://www.suno.ai).
Bark can generate highly realistic, multilingual speech as well as other audio - including music,
background noise and simple sound effects. The model can also produce nonverbal
communications like laughing, sighing and crying. To support the research community,
we are providing access to pretrained model checkpoints ready for inference.
The original github repo and model card can be found [here](https://github.com/suno-ai/bark).
This model is meant for research purposes only.
The model output is not censored and the authors do not endorse the opinions in the generated content.
Use at your own risk.
Two checkpoints are released:
- [small](https://huggingface.co/suno/bark-small)
- [**large** (this checkpoint)](https://huggingface.co/suno/bark)
## Example
Try out Bark yourself!
* Bark Colab:
<a target="_blank" href="https://colab.research.google.com/drive/1eJfA2XUa-mXwdMy7DoYKVYHI1iTd9Vkt?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Colab:
<a target="_blank" href="https://colab.research.google.com/drive/1dWWkZzvu7L9Bunq9zvD-W02RFUXoW-Pd?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
* Hugging Face Demo:
<a target="_blank" href="https://huggingface.co/spaces/suno/bark">
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/open-in-hf-spaces-sm.svg" alt="Open in HuggingFace"/>
</a>
## 🤗 Transformers Usage
You can run Bark locally with the 🤗 Transformers library from version 4.31.0 onwards.
1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers) and scipy:
```
pip install --upgrade pip
pip install --upgrade transformers scipy
```
2. Run inference via the `Text-to-Speech` (TTS) pipeline. You can infer the bark model via the TTS pipeline in just a few lines of code!
```python
from transformers import pipeline
import scipy
synthesiser = pipeline("text-to-speech", "suno/bark")
speech = synthesiser("Hello, my dog is cooler than you!", forward_params={"do_sample": True})
scipy.io.wavfile.write("bark_out.wav", rate=speech["sampling_rate"], data=speech["audio"])
```
3. Run inference via the Transformers modelling code. You can use the processor + generate code to convert text into a mono 24 kHz speech waveform for more fine-grained control.
```python
from transformers import AutoProcessor, AutoModel
processor = AutoProcessor.from_pretrained("suno/bark")
model = AutoModel.from_pretrained("suno/bark")
inputs = processor(
text=["Hello, my name is Suno. And, uh — and I like pizza. [laughs] But I also have other interests such as playing tic tac toe."],
return_tensors="pt",
)
speech_values = model.generate(**inputs, do_sample=True)
```
4. Listen to the speech samples either in an ipynb notebook:
```python
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_values.cpu().numpy().squeeze(), rate=sampling_rate)
```
Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
```python
import scipy
sampling_rate = model.config.sample_rate
scipy.io.wavfile.write("bark_out.wav", rate=sampling_rate, data=speech_values.cpu().numpy().squeeze())
```
For more details on using the Bark model for inference using the 🤗 Transformers library, refer to the [Bark docs](https://huggingface.co/docs/transformers/model_doc/bark).
## Suno Usage
You can also run Bark locally through the original [Bark library]((https://github.com/suno-ai/bark):
1. First install the [`bark` library](https://github.com/suno-ai/bark)
2. Run the following Python code:
```python
from bark import SAMPLE_RATE, generate_audio, preload_models
from IPython.display import Audio
# download and load all models
preload_models()
# generate audio from text
text_prompt = """
Hello, my name is Suno. And, uh — and I like pizza. [laughs]
But I also have other interests such as playing tic tac toe.
"""
speech_array = generate_audio(text_prompt)
# play text in notebook
Audio(speech_array, rate=SAMPLE_RATE)
```
[pizza.webm](https://user-images.githubusercontent.com/5068315/230490503-417e688d-5115-4eee-9550-b46a2b465ee3.webm)
To save `audio_array` as a WAV file:
```python
from scipy.io.wavfile import write as write_wav
write_wav("/path/to/audio.wav", SAMPLE_RATE, audio_array)
```
## Model Details
The following is additional information about the models released here.
Bark is a series of three transformer models that turn text into audio.
### Text to semantic tokens
- Input: text, tokenized with [BERT tokenizer from Hugging Face](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer)
- Output: semantic tokens that encode the audio to be generated
### Semantic to coarse tokens
- Input: semantic tokens
- Output: tokens from the first two codebooks of the [EnCodec Codec](https://github.com/facebookresearch/encodec) from facebook
### Coarse to fine tokens
- Input: the first two codebooks from EnCodec
- Output: 8 codebooks from EnCodec
### Architecture
| Model | Parameters | Attention | Output Vocab size |
|:-------------------------:|:----------:|------------|:-----------------:|
| Text to semantic tokens | 80/300 M | Causal | 10,000 |
| Semantic to coarse tokens | 80/300 M | Causal | 2x 1,024 |
| Coarse to fine tokens | 80/300 M | Non-causal | 6x 1,024 |
### Release date
April 2023
## Broader Implications
We anticipate that this model's text to audio capabilities can be used to improve accessbility tools in a variety of languages.
While we hope that this release will enable users to express their creativity and build applications that are a force
for good, we acknowledge that any text to audio model has the potential for dual use. While it is not straightforward
to voice clone known people with Bark, it can still be used for nefarious purposes. To further reduce the chances of unintended use of Bark,
we also release a simple classifier to detect Bark-generated audio with high accuracy (see notebooks section of the main repository).
|
[
"amendolajine/OPIT",
"Mi-Ni/PDFtoAudio",
"gabrielchua/open-notebooklm",
"yangheng/Super-Resolution-Anime-Diffusion",
"kadirnar/Audio-WebUI",
"suno/bark",
"FriendlyUser/bark",
"monad-one/bark",
"jacek312/barkd",
"SHornoiu/bark",
"drakmail/bark",
"mechiland/bark",
"marcinnocode/bark",
"raaec/bark-ra",
"Gertie01/bark",
"rson/B2",
"Dulor/bark",
"noahzev/bark",
"usamakenway/bark-Ai-audio",
"daveokpare/bark",
"CrowAI/bark-demo",
"wrldreform/Text2Audio",
"amongusrickroll68/bark",
"kevinwang676/Bark-with-Voice-Cloning",
"DevKB/bark",
"Fan555/bark",
"mkami2828/bark",
"popflamingo/bark",
"Freeabt19/bark",
"dr-code/bark",
"gauravmahto/bark",
"trhacknon/bark",
"chezboris/bark",
"phaylali/bark",
"JonathanFly/bark",
"emcalcuadrado/bark",
"kevinwang676/voice-conversion-yourtts",
"kevinwang676/Bark-UI-with-Voice-Cloning-2",
"internetsignal/Bark-w-voice-clone",
"RomanL/bark",
"kevinwang676/Bark-Voice-Cloning",
"mrstuffandthings/Bark-Voice-Cloning",
"hankzero101/bark",
"hankzero101/barkclone",
"gradio-client-demos/bark",
"marker22/Bark-Voice-Cloning",
"PeepDaSlan9/Bark-Voice-Cloning",
"Zhijunv2/Bark-with-Voice-Cloning",
"jbilcke-hf/bark",
"tellview/suno-bark",
"OkamiFeng/Bark-with-Voice-Cloning",
"Maploti/suno-bark",
"jixiaolu/suno-bark",
"devthedeveloper/Bark-with-Voice-Cloning",
"ZeroTwo3/scrAI",
"jamalsenouci/bark",
"Olavogiamp/myMark",
"akashAD/bark",
"rahgadda/bark-voice-generator",
"PeepDaSlan9/Language-Learn-Idea",
"drdanilosa/Bark-with-Voice-Cloning",
"Zazbhai/bark",
"Audio-AGI/WavJourney",
"94insane/tts-fastspeech2-mydata",
"gersooonn/barkk",
"fffiloni/bark-transformers-example",
"mrolando/text_to_speach",
"dmeck/RVC-Speakers",
"michellelychan/bark_voice_cloning",
"CodingBillionaire/Bark-with-Voice-Cloning",
"Tuxifan/bark",
"Omnibus-archive/TTS-voice-clone",
"michellelychan/bark_voice_clone",
"Omnibus/bark",
"BlockLM/Bark-with-Voice-Cloning",
"aeuhhh/Bark-Voice-Cloning2",
"malmstudio/instant-TTS-Bark-cloning",
"menghuiguxiang/image_to_story_audio",
"1littlecoder/instant-TTS-Bark-cloning",
"alx-d/bark",
"ZeroTwo3/WavJourney",
"bhagatsuryainatom/3Xf9ZbQ7wL1oT6yR2eV4mU5pA8cD0jK",
"aegon-h/instant-TTS-Bark-cloning",
"pydev2007/Bark-Voice-Cloning",
"SKYTAR/meow",
"Zannriell/bark",
"niganuga/bark-kureiji",
"ylacombe/children-story",
"Shamus/bark",
"jrjyc1/bark",
"VuAI/text2speed",
"zongxiao/speech-to-speech",
"hf-audio/vocos-bark",
"ZeroTwo3/suno-bark",
"OnceUponAYawn/Bark-with-Voice-Cloning",
"JDWebProgrammer/bark",
"Shanuka01/Bark-with-Voice-Cloning_test_01",
"wizetechnologiez/testing-text-to-speech-app",
"Gonguroo/suno-bark",
"feassh/suno-bark",
"SlumberPenguin/suno-bark",
"Artsnom/bark",
"Pieerepeng/suno-bark",
"robert123231/Bark-with-Voice-Cloning",
"RealJoeRogan/bark",
"CKM12/suno-bark",
"yuziyue/bark",
"ggyyss/Bark-with-Voice-Cloning",
"MattGPT/ClassUI",
"neuroama/Bark-with-Voice-Cloning",
"PH83/image_to_speech_pen",
"marcogallen/tutorial",
"gjin10969/tts_and_vtv_test1-bygjin",
"Annvasileva/speech-to-speech-translation",
"NoahIsDaBomb/Bark-with-Voice-Cloning",
"e-1/bark",
"thivav/image-to-audio",
"Benji918/suno-bark",
"Ayush10mehta/bark",
"harshgupta33/suno-bark",
"qatiba/bark",
"thehunter911/suno-bark-space",
"vishal2002/suno-bark",
"iblfe/test",
"Omnibus-archive/vocos-bark",
"pixchat/bark-clone",
"lpfxyy/suno-bark",
"computroidai/bark",
"ejkilroy/suno-bark",
"product2204/bark",
"morecreative/suno-bark",
"CarrotFlower/suno-bark",
"pauldv/suno-bark",
"aakashch0179/video",
"ivylol1231/bark",
"Natthathida/project-image-captioning",
"alevaroz/suno-bark",
"ZackBradshaw/Tools",
"the237/text2speech_ISJS",
"OMGJ/Text-to-speech",
"santheboss9/suno-bark",
"hexular/babel-fish",
"thomasf/bark",
"thomasf/bark2",
"NeuralNewsForge/nnf_text_to_speech_v1",
"ryacw/translator",
"uglying/suno-bark",
"Schmiddy/suno-bark",
"tabish543/suno-bark",
"Steven-GU-Yu-Di/ISOM5240-Group4-Project-Version2",
"Steven-GU-Yu-Di/ISOM5240-Group4-git-base-vqa",
"leofltt/speech-to-speech-translation",
"bertolt/bark",
"zhouquan/bark",
"ChancesYuan/Suno_ChanceYuan_Test",
"luke890602/suno-bark",
"ZenTrekker/suno-bark",
"intchrome/Sunobark-text-to-speech-and-Whisper-audio-to-translation",
"ai-chen/suno-bark",
"prakharC47/texttoaudioapi",
"clinteroni/bark-with-custom-voice",
"ziyadmohammed/suno-bark",
"nubifere/suno-bark",
"vaaryu/gaana.ai",
"Zacharytrackmaster/bark",
"sundi/suno-bark",
"Aitek/bark",
"CarPeAs/mms_bark",
"sredevops/bark",
"antumanipadam/suno-bark",
"robinmia/suno-bark",
"xia01eng/demo",
"singoojiang/test3",
"singoojiang/bark-001",
"Nikhil0987/suno_bark",
"sgsgs/suno-bark",
"Ghstys/suno-bark",
"Nymbo/Audio-WebUI",
"devilent2/bark",
"devilent2/Bark-with-Voice-Cloning",
"sinmu/suno-bark",
"yemobey/suno-bark",
"euqns/barktest-transformer",
"manoj32/suno-bark",
"tmk3268/suno-bark",
"bflooreonline/ceAI.suno-bark",
"spyderotb/suno-bark",
"abderrahimbrighal/testt_speech3",
"redfr/suno-bark",
"Krishna79939/text-to-speech-1",
"omarfouad/suno-bark",
"mrdivyansh/suno-bark",
"zhuzhuboy/suno-bark",
"neutrinoless/Bark-Voice-Cloning",
"Masterdqqq/suno-bark",
"HermesTres1998/suno-bark",
"daftcount/suno-bark",
"DigitalsDazzle/bark",
"Hituu/suno-bark",
"gauravpandeyuit/suno-bark",
"nia2/cozi",
"jerzysobski/suno-bark",
"devbijay/suno-bark",
"Zeroxdesignart/bark",
"abis90/suno-bark",
"dbarks/open-notebooklm",
"cybercody/open-notebooklm",
"cls7908/open-notebooklm",
"iukea/open-notebooklm",
"zohairy/open-notebooklm",
"elciudadano/suno-bark",
"cagiraudo56789/open-notebooklm",
"neuromod0/open-notebooklm",
"AI-Platform/open-notebooklm",
"WodeDadao/open-notebooklm",
"addyosmani/open-notebooklm",
"slkreddy/open-notebooklm",
"J43243432435/suno-bark",
"wagnergod/open-notebooklm",
"MartsoBodziu1994/suno-bark",
"LelakiKirimanTuhan/suno-bark",
"Mscoder/suno-bark",
"Nishant1807/suno-bark",
"abis90/suno-bark-abi",
"yingmuting/suno-bark",
"rohanphulari/suno-bark",
"Ngakak/suno-bark",
"Cipher29/TheySpeak",
"vuxuanhoan/Bark-with-Voice-Cloning",
"HernanDL/Bark-with-Voice-Cloning2",
"Neear1337/suno-bark",
"nmjp82/Bark-with-Voice-Cloning",
"kasap61/suno-bark",
"rajaqib01/suno-bark",
"mukeshkr5/suno-bark-mk",
"emilalvaro/emilio-music",
"Keesiepie/suno-barktest",
"RafaelJaime/SherezIAde",
"skdjhfvvewhuisol/suno-bark",
"Krish778/bark",
"id2223-SE/id2223-lab2",
"BigBerryAce/suno-bark",
"Automatewta/suno-bark",
"ajit282/AISongs",
"ajit282/AISongsStreamlit",
"wzasd/suno-bark",
"pepper200pepper/suno-bark",
"adelatorre84/suno-bark",
"manancoed/ttsmodel",
"Shamlan321/suno-bark",
"Shamlan321/suno-barkyi",
"arielo18/app_nlp",
"Humuuu/bark",
"Masterdqqq/vepp-bark",
"MGuerz/suno-bark",
"ARtOrias11/Music-generation",
"nareshnayak123456/suno-bark",
"K00B404/3Luik",
"Dragunflie-420/suno-bark",
"GTimothee/tts-test",
"sofi2023ia/fondo_musical",
"sofi2023ia/suno_bark-TTS",
"bhargav2024/suno-bark",
"hackulos/suno-bark",
"Sas2323/audio",
"Ricky1088/sensai",
"redeaux/suno-bark",
"naveen678/Multimodal-GPT",
"yewacer802/bark",
"Masterdqqq/m0-Voice-Cloning",
"nisimbit/suno-bark",
"preston-cell/imagetext-to-audio",
"Deepakraj2006/News_Scraper_TTS",
"brianOtweyoB/bark",
"brianOtweyoB/suno-bark",
"meraj12/cloningapp",
"sreepathi-ravikumar/mentormind-t2v",
"yaashutosh211/bark",
"The-ch0sen/Qwen2-Audio-7B-Instruct",
"Vaishnavi0404/text_to_songgg",
"ArseniyPerchik/Agent_Control_with_Language",
"yitongwu73/assignment",
"Noracle/111",
"KaoticFocus/bark-tts",
"WorkTimer/Bark-with-Voice-Cloning",
"helloWorld199/TextToSerbian",
"rmiucic/TTS3",
"Arman2020Arman1388V/bark",
"friearn21/xttx-free-backend",
"latterworks/bark",
"Maggie2002/WavJourney",
"kimchoongil/centerpull-voicebot",
"flausch/Bark-Voice-Cloning",
"suprimedev/cloner2",
"parikshit16383/Conversational_AI",
"rohitptnk/V2V-Translate",
"RehanPaila/LumexAI",
"KKKONNK/fastapi",
"NitinBot001/bark",
"ivxivx/HF-story-generator",
"tonybur/my-voice-generator",
"Madi7a/AI-Interviewer",
"igoroliosi/bark",
"eagien/Index-TTS-Deploy",
"gazegaze/open-notebooklm-clone",
"sleeper371/bark_with_batch_inference",
"Fancellu/bark-pytorch2.6-compatible",
"HananAli11111111111111111/video",
"musclemind27/chatterbox",
"yuthrb/suno-bark",
"husseinelsaadi/ai-interviewer-demo",
"muktaai458/Mukta-AI-Studio",
"Vgjkmhf/Mippppfggg",
"Toowired/text2speech-gradio-app",
"Riy777/Gtts",
"okgunyang/multimodal_app",
"miseon1/multimodal",
"Prince-khan/lazy-chemist-video-lab",
"pgits/tts-gpu-service",
"John6666/bark2025",
"ducnguyen1978/Test_Voice",
"nobi-1987/bark",
"Toowired/Ty-talky-demo"
] |
[
"mit"
] | null |
[
"en",
"de",
"es",
"fr",
"hi",
"it",
"ja",
"ko",
"pl",
"pt",
"ru",
"tr",
"zh"
] | null | null |
[
"text-to-audio",
"text-to-speech"
] | null |
[
"bark",
"BarkModel",
"AutoModelForTextToWaveform"
] |
[
"audio",
"text"
] |
[
"text"
] |
[
"audio"
] |
free
|
company
|
[
"United States of America"
] | null |
google-bert/bert-base-uncased
|
[
"Text"
] |
[
"Speech Generation"
] |
[
"Transformer: Text Encoder-only",
" Transformer: Speech Encoder-only"
] |
[
"EN",
" DE",
" FR",
" IT",
" ES",
" PT",
" NL",
" RU",
" JA",
" KO",
" ZH",
" AR",
" HI"
] |
[
"Pretraining: Causal Language Modeling (CLM)",
" Pretraining: Multimodal joint-embeddings"
] |
Not disclosed
| 8
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.